数据库:深入解析SQL分组与聚合——提升数据查询效率的关键技巧
数据库:深入解析SQL分组与聚合——提升数据查询效率的关键技巧
在数据分析和数据库管理中,SQL 的分组与排序操作是不可或缺的工具。本篇博客将深入探讨
GROUP BY和ORDER BY的使用方法,并通过实际案例说明如何通过分组实现数据聚合以及如何对结果进行排序。此外,还将分析HAVING与WHERE子句在过滤数据时的区别和联系,帮助开发者在实际应用中更高效地处理复杂查询。
一、概述
在 SQL 查询中,GROUP BY 子句用于将记录按照指定的列进行分组,并对每组记录进行聚合操作,如计数、求和、取平均值等。而 ORDER BY 子句用于对查询结果按照指定的列进行排序。当需要对聚合后的数据进行过滤时,HAVING 子句是一个常用的工具。掌握这些操作对于处理复杂查询和优化数据分析流程至关重要。
二、SQL中的聚合函数
2.1 常用聚合函数
聚合函数在分组查询中发挥关键作用,可以对每组数据进行统计和汇总操作,使得我们能够从大数据集中提取有用的信息。这些聚合函数不仅可以与 GROUP BY 子句配合使用,也可以单独使用。下面是常见的聚合函数及其用途,并配合示例说明如何使用。
| 聚合函数 | 描述 | 是否可以单独使用 | 示例 | 解释 |
|---|---|---|---|---|
COUNT() | 计算某一列中的非空记录数量。 | 可以 | SELECT COUNT(*) FROM Employees; | 该查询返回 Employees 表中的总记录数。COUNT(*) 计算表中的所有记录数,包括 NULL 值。 |
SUM() | 计算某一列的数值总和。 | 可以 | SELECT SUM(sale_amount) FROM Sales; | 该查询返回 Sales 表中所有销售记录的总金额。SUM(sale_amount) 计算 sale_amount 列的总和。 |
AVG() | 计算某一列的平均值。 | 可以 | SELECT AVG(sale_amount) FROM Sales; | 该查询返回 Sales 表中销售金额的平均值。AVG(sale_amount) 计算 sale_amount 列的平均值。 |
MAX() | 返回某一列中的最大值。 | 可以 | SELECT MAX(salary) FROM Employees; | 该查询返回 Employees 表中的最高工资。MAX(salary) 返回 salary 列的最大值。 |
MIN() | 返回某一列中的最小值。 | 可以 | SELECT MIN(salary) FROM Employees; | 该查询返回 Employees 表中的最低工资。MIN(salary) 返回 salary 列的最小值。 |
2.2 示例
示例 1:使用 COUNT() 统计记录数量
假设我们有一个 Orders 表,其中包含订单编号 (order_id) 和客户编号 (customer_id) 等信息。我们希望统计所有订单的数量。
SELECT COUNT(*) AS total_orders
FROM Orders;
解释:
COUNT(*)计算Orders表中的所有记录数。- 该查询不需要分组,因此
COUNT()聚合函数可以单独使用。
背景说明:
统计订单数量有助于了解业务的整体情况,例如在某个时间段内处理的订单总数。
示例 2:使用 SUM() 计算销售总额
假设我们仍然使用之前的 Sales 表。我们想要计算所有产品的总销售额,而不是按照产品分组。
SELECT SUM(sale_amount) AS total_sales
FROM Sales;
解释:
SUM(sale_amount)计算Sales表中sale_amount列的总和。- 该查询不需要分组,因此
SUM()聚合函数可以单独使用。
背景说明:
计算总销售额可以帮助企业衡量销售业绩,制定销售策略。
示例 3:使用 AVG() 计算平均销售额
继续使用 Sales 表,我们想要计算每个产品的平均销售额。
SELECT product_name, AVG(sale_amount) AS average_sales
FROM Sales
GROUP BY product_name;
解释:
AVG(sale_amount)计算每种产品的平均销售额。GROUP BY product_name将销售记录按产品名称分组,然后计算每组的平均值。
背景说明:
分析平均销售额有助于确定哪些产品表现较好,哪些产品需要改进销售策略。
示例 4:使用 MAX() 和 MIN() 查找最大和最小值
假设我们有一个 Employees 表,包含员工的薪资信息。我们希望找出最高和最低的薪资。
SELECT MAX(salary) AS highest_salary, MIN(salary) AS lowest_salary
FROM Employees;
解释:
MAX(salary)返回salary列中的最大值,即最高工资。MIN(salary)返回salary列中的最小值,即最低工资。
背景说明:
了解工资范围可以帮助企业制定薪资策略,确保员工薪酬的公平性。
三、分组
3.1 GROUP BY
GROUP BY 子句主要用于将查询结果根据某一列或多列进行分组,并对每一组数据进行聚合操作。分组后的数据可以应用聚合函数来进行统计和汇总操作。常见的场景包括按照某个字段对数据进行分类统计,如统计每个部门的员工数量、每个产品的销售总额等。
示例:
假设我们有一个 Sales 表,其中包含产品名称 (product_name)、销售日期 (sale_date) 和销售金额 (sale_amount) 等信息。我们想要统计每种产品的总销售额。
SELECT product_name, SUM(sale_amount) AS total_sales
FROM Sales
GROUP BY product_name;
解释:
product_name是分组依据,按照产品名称对数据进行分组。SUM(sale_amount)是聚合函数,用于计算每种产品的销售总额,并将结果命名为total_sales。
背景说明:
该查询帮助我们了解每种产品的销售表现,便于进行销售分析和库存管理。
3.2 示例—— 统计每个客户的地址数量
假设我们有一个 Customers 表,包含客户的姓名 (cust_name)、地址 (cust_address) 和订单信息。我们希望统计每个客户下有多少个不同的地址。
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers
GROUP BY cust_name;
解释:
cust_name是分组依据,即对每个客户的记录进行分组。COUNT(cust_address)是聚合函数,用于计算每个客户下不同地址的数量,并将结果命名为addr_num。
背景说明:
Customers 表可能包含重复的地址记录,使用 GROUP BY 分组后,可以统计每个客户的唯一地址数量。这个查询帮助我们了解客户分布情况,为后续市场营销策略提供数据支持。
3.3 示例—— 统计每个客户的地址数量并排序
在使用 GROUP BY 进行分组后,我们可能需要对聚合后的结果进行排序,以便更好地分析数据。这时可以使用 ORDER BY 子句进行排序操作。
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers
GROUP BY cust_name
ORDER BY cust_name DESC;
解释:
ORDER BY cust_name DESC将结果按照客户名称的降序排列。DESC表示降序排列,ASC表示升序排列。
背景说明:
在分析客户数据时,我们可能希望按字母顺序或相反顺序查看客户信息。通过对分组结果进行排序,可以更清晰地呈现数据,从而便于进一步的业务决策。
四、使用HAVING进行聚合结果过滤
4.1 基础知识:什么是 HAVING
HAVING 子句用于对聚合后的结果进行过滤,通常与 GROUP BY 联合使用。在 SQL 查询中,WHERE 子句用于过滤原始数据,而 HAVING 则用于过滤聚合后的数据。HAVING 可以与聚合函数一起使用,而 WHERE 不能。
4.2 HAVING 与 WHERE 的区别
在 SQL 查询中,WHERE 和 HAVING 都可以用于数据过滤,但它们的作用范围和用法有明显区别。
| 对比维度 | HAVING | WHERE |
|---|---|---|
| 用途 | 对汇总后的 GROUP BY 结果进行过滤 | 对原始数据进行过滤 |
| 使用位置 | 在 GROUP BY 之后使用,通常与聚合函数一起使用 | 在 GROUP BY 之前使用,不能与聚合函数一起使用 |
| 应用场景 | 过滤聚合后的数据,如筛选统计结果 | 过滤原始数据,如删除不符合条件的记录 |
4.3 示例1——筛选订单数量大于 1 的客户
在实际应用中,我们可能需要筛选出符合某些聚合条件的记录,例如筛选出订单数量大于 1 的客户。
SELECT cust_name, COUNT(*) AS NumberOfOrders
FROM Customers
WHERE cust_email IS NOT NULL
GROUP BY cust_name
HAVING COUNT(*) > 1;
解释:
WHERE cust_email IS NOT NULL先过滤掉电子邮件为空的记录。GROUP BY cust_name按客户名称分组。HAVING COUNT(*) > 1筛选出订单数量大于 1 的客户。
背景说明:
这个查询示例展示了如何通过 HAVING 子句筛选出符合特定条件的聚合结果,例如,筛选出至少有两个订单的客户。这对于了解高价值客户群体非常有用,有助于精准营销。
4.4 示例2——进一步筛选:客户订单金额
在上一例的基础上,我们可以进一步筛选出订单金额超过一定值的客户。
SELECT cust_name, SUM(order_amount) AS TotalAmount
FROM Orders
GROUP BY cust_name
HAVING SUM(order_amount) > 1000;
解释:
SUM(order_amount)计算每个客户的订单总金额,并将结果命名为TotalAmount。HAVING SUM(order_amount) > 1000筛选出订单总金额超过1000的客户。
背景说明:
此查询有助于识别高价值客户,进一步细化目标客户群。通过筛选订单总金额,我们可以更好地理解客户的购买行为,优化资源配置。
五、总结与应用场景
5.1 总结
通过本篇博客,我们深入探讨了 SQL 中 GROUP BY 和 ORDER BY 的基本用法,并分析了 HAVING 子句在聚合结果过滤中的作用。掌握这些SQL操作,能够帮助开发者在处理复杂数据时,更好地组织和分析信息,从而提高查询效率和数据分析的准确性。
5.2 实际应用中的注意事项
- 合理使用聚合函数:在处理大数据量时,聚合操作可能非常耗时,需合理设计查询结构。
- 分组和排序时注意性能优化:过多的分组和排序操作可能会导致性能下降,需结合索引优化查询。
- 适时使用
HAVING:仅在需要对聚合结果进行过滤时使用HAVING,避免不必要的开销。
😊通过以上的介绍和示例分析,读者应能够更好地理解和应用 SQL 中的分组与排序操作,从而在实际工作中提升数据库操作的效率和数据处理能力。感谢大家的阅读,希望可以点赞、收藏和关注!👍📚
相关文章:

数据库:深入解析SQL分组与聚合——提升数据查询效率的关键技巧
数据库:深入解析SQL分组与聚合——提升数据查询效率的关键技巧 在数据分析和数据库管理中,SQL 的分组与排序操作是不可或缺的工具。本篇博客将深入探讨 GROUP BY 和 ORDER BY 的使用方法,并通过实际案例说明如何通过分组实现数据聚合以及如何…...

【CSS】数字英文css没有转换成...换行点、没有换行、拆分的问题(非常常见的需求)
默认情况下,连续的英文或数字文本不会在空格处换行,这可能导致布局问题。 解决方案 要解决这个问题,可以使用以下几种CSS属性: word-break: 控制单词如何换行。设置为break-all可以让任何字符都能成为换行点。word-wrap: 控制是…...

C++ string模拟实现
一 如何区分自定义类与标准库中的同名类 // string.h #define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include<iostream> using namespace std;namespace bit {class string{} }// Test.cpp include "string.h"int main() {return 0; } 既然要模拟实现str…...

Lora 全文翻译
作者: 地点:hby 来源:https://arxiv.org/pdf/2106.09685 工具:文心 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 摘要 自然语言处理的一个重要范式包括在通用领域数据上进行大规模预训练,并适应特定任务或…...
)
结题阶段(2024年8月)
海门区教育科学 “十四五”规划2022年度立项课题 结题鉴定材料 课 题 名 称 高中信息技术项目化教学的研究与应用 课题负责人 郭书艳 所 在 单 位 江苏省包场高级中学 报 送 日 期 2024 年 6 月 20 日…...

贪吃蛇(C语言详解)
贪吃蛇游戏运行画面-CSDN直播 目录 贪吃蛇游戏运行画面-CSDN直播 1. 实验目标 2. Win32 API介绍 2.1 Win32 API 2.2 控制台程序(Console) 2.3 控制台屏幕上的坐标COORD 2.4 GetStdHandle 2.5 GetConsoleCursorlnfo 2.5.1 CONSOLE_CURSOR_INFO …...
与国际专线(IPLC)服务)
国际以太网专线(IEPL)与国际专线(IPLC)服务
中国联通国际公司产品: 国际以太网专线 (IEPL)/国际专线(IPLC) 在全球化的今天,企业越来越依赖于高速、稳定且安全的国际网络连接来支持其跨国业务活动。中国联通国际公司作为中国领先的电信运营商之一,在这一领域提供了多种优质…...

vue 子父组件互相改值
在Vue.js中,子组件想要修改父组件的状态(如数据属性的值)时,通常遵循以下步骤: 父组件向子组件传递数据:通过props(属性)将需要被子组件操作的值传入子组件。例如,在父组…...

java之拼图小游戏(开源)
public class LoginJFrame extends JFrame {//表示登录界面,以后所有跟登录相关的都写在这里public LoginJFrame() {//设置界面的长和宽this.setSize(603,680);//设置界面的标题this.setTitle("拼图登陆界面");//设置界面置顶this.setAlwaysOnTop(true);/…...

Linux Shell批量测试IP连通性
Linux 通过Shell脚本来实现读取txt文件中的IP地址,并使用telnet对其后的所有端口进行测试,判断是否可以连接。每个IP地址的端口测试时间限制为5秒。 IP文件 : ips.txt 192.168.1.1 22,80,443 192.168.1.2 21,25,110 192.168.1.3 8080每一行包含一个IP地…...

已解决:anaocnda如何备份环境与安装环境
1.使用pip进行备份 激活对应的虚拟环境,切换到桌面或者想备份的位置。 备份即可: pip freeze > requirements.txt如何安装备份? pip install -r requirements.txt2.使用conda进行备份 激活对应的虚拟环境,切换到桌面或者想…...
自动化与高效设计:推理技术在FPGA中的应用
想象一下,你正在设计一个复杂的电路系统,就像在搭建一座精巧的积木城堡。你手头有各种形状和功能的积木块,这些积木块可以组合成任何你需要的结构。在这个过程中,你有两种主要的方法:一种是手动挑选和搭建每一块积木&a…...

对react模块和模块化理解
在React开发中,模块化和React模块是两个紧密相关但又有区别的概念。理解它们对于构建高效、可维护的React应用至关重要。 模块化 模块化是一种将大型代码库拆分成更小、更易于管理的部分(即模块)的软件设计技术。每个模块都封装了特定的功能…...

CAN总线-----帧格式
目录 前言 一、CAN总线帧格式分类 1.数据帧(重点) 2.遥控帧 3.错误帧 4.过载帧 5.间隔帧 二、位填充 三、波形实例 前言 本期我们就开始学习CAN总线的帧格式,对应帧格式的话,在前面我们学习I2C协议和SPI协议等协议的时候…...

UE网络同步(一) —— 一个项目入门UE网络同步之概念解释
最近在学习UE网络同步,发现了一个非常好的教程,并且附带了项目文件,这里从这个小项目入手,理解UE的网络同步 教程链接:https://www.youtube.com/watch?vJOJP0CvpB8w 项目链接:https://github.com/awforsyt…...
MATLAB中rsf2csf函数用法
目录 语法 说明 示例 将实数 Schur 形式变换为复数 Schur 形式 rsf2csf函数的功能是将实数 Schur 形式转换为复数 Schur 形式。 语法 [Unew,Tnew] rsf2csf(U,T) 说明 [Unew,Tnew] rsf2csf(U,T) 将实矩阵 X 的 [U,T] schur(X) 的输出从实数 Schur 形式变换为复数 Sc…...

Java基础 文字小游戏
souf System.out.printf("你好啊%s","张三") 输出你好啊张三 System.out.printn()放在中间可以换行 System.out.printf("%s你好啊%s","张三","李四") 输出 张三你好啊李四 只有输出没有换行效果。 制作一个文字小游戏…...
)
「数组」归并排序 / if语句优化|小区间插入优化(C++)
概述 在上一篇文章中,我们介绍了快速排序以及随机快速排序: 「数组」快速排序 / 随机值优化|小区间插入优化(C) 今天,我们来介绍归并排序。 相比于快速排序是冒泡排序融合了分治思想后形成的究极promax进化版&…...
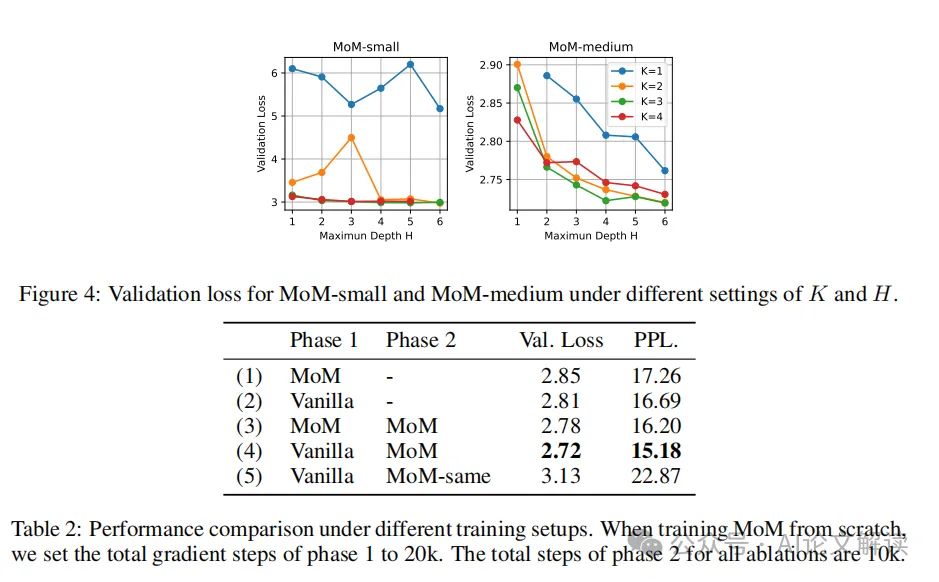
颠覆传统 北大新型MoM架构挑战Transformer模型,显著提升计算效率
挑战传统的Transformer模型设计 在深度学习和自然语言处理领域,Transformer模型已经成为一种标准的架构,广泛应用于各种任务中。传统的Transformer模型依赖于一个固定的、按深度排序的层次结构,每一层的输出都作为下一层的输入。这种设计虽然…...

接口优化笔记
索引 添加索引 where条件的关键自动或者order by后面的排序字段可以添加索引加速查询 索引只能通过删除新增进行修改,无法直接修改。 # 查看表的索引 show index from table_name; show create table table_name; # 添加索引 alter table table_name add index …...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...