YoloV8改进策略:Block改进|LeYOLO,一种用于目标检测的新型可扩展且高效的CNN架构|复现LeYolo,轻量级Yolo改进
摘要
LeYOLO是在YOLO系列,特别是可能受到YOLOv8启发的基础上进行的一系列改进,旨在提升目标检测模型的高效性、可扩展性和精度。其主要特点包括:
-
高效骨干网络缩放方法:
- LeYOLO借鉴了倒置瓶颈(Inverted Bottleneck)和信息瓶颈原理,设计了一种高效的骨干网络缩放方法。通过优化通道数,减少计算需求,特别是在大空间特征图尺寸下。
-
快速金字塔架构网络(FPAN):
- 提出了FPAN(Fast Pyramid Architecture Network),旨在促进快速多尺度特征共享的同时减少计算资源。FPAN简化了传统PANet或FPN的结构,通过减少卷积层和通道数,提高语义信息共享的效率。
-
解耦网络中的网络(DNiN)检测头:
- 设计了DNiN检测头,为分类和回归任务提供快速且轻量级的计算。这种设计优化了检测头的计算效率,使其更适合于嵌入式和移动设备。
-
高效的模块和步长策略:
- 在模型的主干部分,使用逐点卷积与标准卷积的组合,并严格限制较低的通道数,以从大特征图尺寸上有效地使用卷积。此外,采用特定的通道扩展策略,通过按比例增加通道数来丰富信息流。
-
卓越的性能和可扩展性:
- LeYOLO在各种资源限制条件下表现出色,提供了从超低神经网络配置(<1 GFLOP)到高效但要求苛刻的目标检测设置(>4 GFLOPs)的可扩展性。例如,LeYOLO-Small在COCO验证集上以仅4.5 GFLOP的计算量达到了具有竞争力的38.2% mAP分数,与最新的YOLOv9-Tiny模型相比,计算负载降低了42%,同时实现了相似的精度。
-
高可复现性和无ImageNet预训练:
- 使用来自ultralytics API的可重用训练方法实现结果,无需进行ImageNet预训练,提高了研究的可复现性。
-
特别组件组合:
- LeYOLO不仅关注精度与计算成本的最佳比例,还通过参考已发现的所有选项,提出了不同的替代方案,以满足不同的应用场景需求。
综上所述,LeYOLO通过一系列创新的设计和优化,实现了在保持或提高精度的同时,显著降低计算成本,为移动和嵌入式设备上的高效目标检测提供了新的解决方案。
论文翻译:《LeYOLO,一种用于目标检测的新型可扩展且高效的CNN架构》
在目标检测中,深度神经网络的计算效率至关重要,尤其是随着新型模型越来越注重速度而非有效计算量(FLOP)。这一发展趋势在某种程度上忽视了嵌入式和面向移动设备的AI目标检测应用。在本文中,我们基于FLOP关注于高效目标检测计算所需的神经网络架构设计选择,并提出了一些优化措施以增强基于YOLO模型的效率。首先,我们借鉴了倒置瓶颈和来自信息瓶颈原理的理论见解,引入了一种高效的骨干网络缩放方法。其次,我们提出了快速金字塔架构网络(FPAN),旨在促进快速多尺度特征共享的同时减少计算资源。最后,我们设计了一种解耦网络中的网络(DNiN)检测头,旨在为分类和回归任务提供快速且轻量级的计算。基于这些优化并利用更高效的骨干网络,本文为目标检测和以YOLO为中心的模型贡献了一种新的缩放范式,称为LeYOLO。我们的贡献在各种资源限制条件下始终优于现有模型,实现了前所未有的精度和FLOP比。特别是,LeYOLO-Small在COCO验证集上以仅4.5 FLOP(G)的计算量达到了具有竞争力的 38.2 % 38.2\% 38.2% mAP分数,与最新的最先进的YOLOv9-Tiny模型相比,计算负载降低了 42 % 42\% 42%,同时实现了相似的精度。我们的新型模型家族实现了前所未有的FLOP-精度比,提供了从超低神经网络配置(<1 GFLOP)到高效但要求苛刻的目标检测设置(>4 GFLOPs)的可扩展性,分别实现了0.66、1.47、2.53、4.51、5.8和8.4 FLOP(G)下的25.2、31.3、35.2、38.2、39.3和41 mAP。
1、引言
在目标检测中,深度神经网络旨在从原始输入图像中提取出每个感兴趣对象周围的一组边界框,并将它们分类到正确的类别中。因此,为了精确定位不同的感兴趣对象,收集丰富的空间信息是必要的。
尽管深度神经网络已经取得了令人瞩目的进展,但它们严重依赖于计算资源昂贵的设备,从而限制了在不那么强大的设备上的部署。云计算提供了一种替代方案,可以将强大模型的执行卸载到云端,但它也带来了延迟、带宽限制和安全担忧等不便之处[3, 80, 74]。事实上,在自动驾驶、监控系统、医学成像和智能农业等实际应用中,高效的计算、实时处理和低计算延迟至关重要。在资源受限的环境中,如移动设备和边缘计算设备,轻量级但健壮的目标检测器具有实用价值。
1.1、最新技术进展
深度神经网络在解决分类、回归、分割和目标检测问题方面一直竞争激烈。许多为移动使用而设计的最先进分类模型[25, 54, 24, 41, 77, 43, 69, 10, 77, 10, 61, 18, 65]使用SSDLite神经网络[38]作为低成本目标检测器。另一方面,为执行速度优化的YOLO类型模型[50-52, 2, 30, 32, 71, 73, 9, 78, 29]则随着计算资源的发展而发展,放弃了嵌入式设备。幸运的是,新颖的基于YOLO的架构采用了高效计算,重点关注MAC和FLOP[45, 12, 14, 76, 16, 75]。这些架构为边缘AI和工业应用提供了强有力的证据,增强了嵌入式设备的功能,并实现了直接模型响应。
事实上,“YOLO”模型在工业和非计算研究领域都同样受欢迎,因此受到了强烈的关注。实际上,YOLO被应用于医学[1, 46, 67, 60]、葡萄栽培[56, 34, 55, 48, 22]和其他领域[47, 33, 49]。此外,YOLO的易用性和快速执行特性使其成为研究人员的绝佳选择。
目标检测器的可能性范围扩展到多个选项:专为速度设计的目标检测器[52, 2, 32, 9, 78, 71, 14, 51, 50, 73, 8, 30, 29]、精确检测器[53, 39, 6, 19],以及以最佳精度(mAP)与计算成本(FLOP)比[12, 45, 38, 16, 14, 76, 75, 40]为目标,尽可能降低计算成本(FLOP)。最后一点应该使我们考虑将“低成本”和“快速”模型分开,好像它们之间没有关联一样。
最近,我们注意到YOLO模型的研究焦点出现了一个有趣的现象,即越来越注重执行速度,但代价是计算成本的增加[71, 73, 9, 78]。这种计算成本的一个主要缺点是必须考虑内存访问以及卷积操作并行化的可能性。随着GPU或更广泛地说,计算资源的显著发展,大多数作者都得出了无可辩驳的结论,即在制定其架构时,现在可以添加更多过滤器和参数,以尽可能紧密地并行化神经网络的操作。这一现象增加了模型计算成本(MAC或FLOP),但主要得益于近年来GPU的升级,模型执行速度得以保持或提高。
最新的YOLO模型[73, 8, 71],以令人印象深刻的执行速度和在高性能计算资源上的优化为幌子,在“轻量级”模型中展现了最先进的水平,但仍需针对边缘移动设备进行改进。
我们将轻量级模型定义为具有较少FLOP的神经网络,无论其参数数量或执行速度如何。一些论文可能会使用参数来证明其模型的“轻量级”能力。然而,相同数量的过滤器参数可能会因输入空间大小的不同而有非常不同的计算需求,从而使这种解决方案失效。至于速度,虽然这个指标很有趣,但它也受到了计算资源的偏见。因此,我们专注于FLOP来构建像EfficientDet[64]这样高效的目标检测器,并且我们还提供了参数和速度,以便读者能够进行广泛的比较(第B.1章)。

我们提出了LeYOLO,这是一个概念上简单但高效的架构,它采用了计算高效的组件来进行目标检测,其核心思想源于EfficientNets[62, 63]、MobileNets[54, 25, 24]以及类似的创新[35, 38, 77, 72, 28, 36, 20, 26, 41, 79, 23]。我们的目标是为YOLO模型引入一种新的架构方法,优先考虑高效的扩展性。这一举措旨在增强移动和嵌入式设备的功能。
我们将LeYOLO与其他最先进的高效目标检测器进行了比较,如YOLO系列、EfficientDet等[25, 24, 14, 61, 12, 30, 64, 71, 2]。我们的评估重点放在MSCOCO[37]验证集的mAP和FLOP比率上,突出了嵌入式设备所需的最小计算量的重要性。如图1所示,LeYOLO在广泛的神经网络范围内表现出卓越的性能,超越了超低网络(小于 1 FLOP ( G ) 1 \operatorname{FLOP}(\mathrm{G}) 1FLOP(G))、中档网络( 1 1 1到 4 F L O P ( G ) 4 \mathrm{FLOP}(\mathrm{G}) 4FLOP(G)之间)甚至超过 4 F L O P ( G ) 4 \mathrm{FLOP}(\mathrm{G}) 4FLOP(G)的模型。
在LeYOLO的所有版本中,如表3所示,对于 0.66 , 1.126 , 1.47 , 2.53 , 3.27 , 4.51 , 5.8 0.66, 1.126, 1.47, 2.53, 3.27, 4.51, 5.8 0.66,1.126,1.47,2.53,3.27,4.51,5.8和 8.4 F L O P ( G ) 8.4 \mathrm{FLOP}(\mathrm{G}) 8.4FLOP(G),在MSCOCO验证数据集上分别实现了 25.2 % , 29 % , 31.3 % , 35.2 % , 36.4 % , 38.2 % , 39.3 % 25.2 \%, 29 \%, 31.3 \%, 35.2 \%, 36.4 \%, 38.2 \%, 39.3 \% 25.2%,29%,31.3%,35.2%,36.4%,38.2%,39.3%和 41 % 41 \% 41%的mAP。
我们的主要贡献如下:
-
轻量级:在每FLOP的准确率方面,LeYOLO与最先进的轻量级目标检测神经网络(在 0.5 0.5 0.5到 8 F L O P ( G ) 8 \mathrm{FLOP}(\mathrm{G}) 8FLOP(G)之间)相比,实现了最佳的准确率。
-
可扩展性:LeYOLO为工业、边缘和嵌入式设备提供了使用具有最先进扩展效率的轻量级YOLO模型的新机会。
-
特别组件组合:尽管我们的研究重点是精度与计算成本的最佳比例,但我们通过参考已发现的所有选项,提出了不同的替代方案。
-
新架构:我们为LeYOLO提出了新的计算高效块,并通过实验提供了证明。
-
高可复现性:我们的研究重点是改进深度神经网络的架构。我们使用来自ultralytics API的可重用训练方法实现了这些结果,而无需进行ImageNet[31]预训练。
2、LeYOLO架构描述
2.1、模块定义
2.1.1、基本构建块
倒置瓶颈(Inverted Bottleneck),最初由MobileNetV2[25, 54]提出,因其轻量级计算和简单性而成为许多最新先进模型[62, 63, 18, 65, 43, 38, 69]的精髓。在FLOP计算方面,要实现超越深度可分离卷积的效果水平是复杂的。逐点卷积解决了缺少通道间相关性的问题,这是无法回避的难题。然而,在我们的倒置瓶颈块实验中,我们观察到优化通道数可以有效地减少计算需求,特别是在大空间特征图尺寸下。实际上,如果一个块的扩展比等于一,或者通过连接效应,输入通道 C i n C_{in} Cin等于计算出的扩展层数 C m i d C_{mid} Cmid,则无需在我们块中使用第一个逐点卷积。只要输入 C in C_{\text{in}} Cin和输出 C out C_{\text{out}} Cout张量相等(如图2和公式(1)所示),我们始终使用残差连接,即使第一个逐点卷积不存在。我们在图2©中描绘了LeYOLO的基本构建块,突出了经典瓶颈(图2(a))、倒置瓶颈(图2(b))[25, 54, 24]和我们提出的方法(图2©)之间的区别。

我们将 ⊗ \otimes ⊗表示为两个值之间的卷积。对于 F in ∈ R 1 , 1 , C in , C mid F_{\text {in }} \in \mathbb{R}^{1,1, C_{\text {in }}, C_{\text {mid }}} Fin ∈R1,1,Cin ,Cmid , F out ∈ R 1 , 1 , C mid , C out F_{\text {out }} \in \mathbb{R}^{1,1, C_{\text {mid }}, C_{\text {out }}} Fout ∈R1,1,Cmid ,Cout 和 F mid ∈ R k , k , 1 , C mid F_{\text {mid }} \in \mathbb{R}^{k, k, 1, C_{\text {mid }}} Fmid ∈Rk,k,1,Cmid ,其中卷积涉及的 C i n C_{i n} Cin为输入通道数, C mid C_{\text {mid }} Cmid 为倒置瓶颈中的扩展通道数, C out C_{\text {out }} Cout 为输出通道数,卷积操作可以表示为:
y = { F out ⊗ [ F mid ⊗ ( F in ⊗ x ) ] 如果 C in ≠ C mid F out ⊗ [ F mid ⊗ ( F in ⊗ x ) ] 如果 C in = C mid 且 F in = True F out ⊗ [ F mid ⊗ ( x ) ] 如果 C in = C mid 且 F in = False y=\left\{\begin{array}{ll} F_{\text {out }} \otimes\left[F_{\text {mid }} \otimes\left(F_{\text {in }} \otimes x\right)\right] & \text { 如果 } C_{\text {in }} \neq C_{\text {mid }} \\ F_{\text {out }} \otimes\left[F_{\text {mid }} \otimes\left(F_{\text {in }} \otimes x\right)\right] & \text { 如果 } C_{\text {in }}=C_{\text {mid }} \text { 且 } F_{\text {in }}=\text { True } \\ F_{\text {out }} \otimes\left[F_{\text {mid }} \otimes(x)\right] & \text { 如果 } C_{\text {in }}=C_{\text {mid }} \text { 且 } F_{\text {in }}=\text { False } \end{array}\right. y=⎩ ⎨ ⎧Fout ⊗[Fmid ⊗(Fin ⊗x)]Fout ⊗[Fmid ⊗(Fin ⊗x)]Fout ⊗[Fmid ⊗(x)] 如果 Cin =Cmid 如果 Cin =Cmid 且 Fin = True 如果 Cin =Cmid 且 Fin = False
与最新的目标检测神经网络技术[71, 73]类似,我们在整个模型中一致地实现了SiLU[11]激活函数。
2.1.2、步长策略
多个模型在倒置瓶颈中融入了步长概念[25, 54, 24, 75, 63, 43, 70, 44]。然而,我们采用了一种特定的通道扩展策略。
每个语义级别的信息,标记为 P i P_{i} Pi,在其所有隐藏层中始终具有相同数量的输入 C in P i C_{\text {in }} P_{i} Cin Pi、输出 C out P i C_{\text {out }} P_{i} Cout Pi和扩展通道 C mid P i C_{\text {mid }} P_{i} Cmid Pi。我们的目标是通过按比例增加通道 C i n P i C_{i n} P_{i} CinPi(根据从 C m i d P i + 1 C_{m i d} P_{i+1} CmidPi+1预期的通道扩展),来丰富从语义信息级别 P i P_{i} Pi的隐藏层 h i h_{i} hi到后续隐藏层 h i + 1 h_{i+1} hi+1的信息流。
在倒置瓶颈中,采取以下步骤:
h i = F out ⊗ [ F mid ⊗ ( F in ⊗ x ) ] h_{i}=F_{\text {out }} \otimes\left[F_{\text {mid }} \otimes\left(F_{\text {in }} \otimes x\right)\right] hi=Fout ⊗[Fmid ⊗(Fin ⊗x)]
标记为 P P P的带步长的倒置瓶颈内的语义信息如下 - 图3所示:
P i → P i + 1 → P i + 1 P_{i} \rightarrow P_{i+1} \rightarrow P_{i+1} Pi→Pi+1→Pi+1
因此,步长大于1的通道扩展策略可能呈现以下形式:
C in P i → C mid P i + 1 → C out P i + 1 其中 C mid P i + 1 > C mid P i C_{\text {in }} P_{i} \rightarrow C_{\text {mid }} P_{i+1} \rightarrow C_{\text {out }} P_{i+1} \quad \text { 其中 } \quad C_{\text {mid }} P_{i+1}>C_{\text {mid }} P_{i} Cin Pi→Cmid Pi+1→Cout Pi+1 其中 Cmid Pi+1>Cmid Pi
我们可以简单地对每个块应用一个较大的扩展比,而不仅仅是那些步长大于1的块,但这样做会显著增加整个网络的成本。

虽然这种策略并不是整个模型所必需的,但在某些节点(如主干部分)上这样做是有意义的,可以最大限度地从昂贵的特征图空间尺寸中扩展信息,特别是通过最终的逐点卷积。
2.2、主干(STEM)
我们通常用“STEM”一词来描述第一层,这些层直接处理输入图像和低语义信息,以快速有效地减小空间尺寸,并将初始信息通道数(通常是红、绿、蓝各3个通道)激发到更高的通道数。主要好处是降低了计算成本,因为如果处理的层在空间上太大,对象检测的总成本会迅速增加。只有YOLOv7[71]没有从第一层开始就使用带步长的卷积。初始的P0(640x640 - 1280x1280)空间尺寸成本太高。
观察一些最先进的YOLO模型样本,只有YOLOv6[32]和YOLOv8[29]是低计算资源主干的良好示例,当将通道数和层数缩放到x0.25时,它们的总成本均为0.32 GFLOP。这两个模型迅速将特征图缩放到160x160像素,以补偿在过高空间尺寸上进行滑动卷积的成本。
为了在大特征图尺寸上有效地使用卷积,我们在整个主干部分都使用逐点卷积与标准卷积的组合,并严格限制较低的通道数,以从P0(640x640)转换到P2(160x160)-如表1所示。

2.3、高效的主干特征提取器
历史上,目标检测器被广泛用于分类任务的补充[53, 19, 38],这导致了使用经典分类模型作为特征提取器的观测模型的出现。
首先,我们采用倒置瓶颈结构,因为它具有无与伦比的计算成本和成本-精度比。
最后,在层数选择方面,我们基于神经网络的最新技术状态做出了一个明显的观察:焦点集中在 P 4 \mathbf{P 4} P4层或其等效层上的层重复上。
更有趣的是,使用NAS(神经网络架构搜索)类型的算法来选择层数或重复次数时,我们观察到了同样的现象: P 4 \mathbf{P 4} P4层的层比其他层更重要[25, 62, 63, 61, 15, 4]。我们基于YOLO系列[52, 2, 30, 32](如表2.3所示)的观察,同时也基于使用卷积的分类模型[77, 41, 58, 57, 59]、自注意力模型[42-44, 68, 39],以及最终基于ResNet[20]的DETR[6]等目标检测器(也关注等效的 P 4 \mathbf{P 4} P4中流)的观察,得出了这一结论。
我们不能像[52, 2, 32]那样过于依赖 P 3 \mathbf{P 3} P3层来构建基于低计算成本的神经网络。因此,我们的主干采用了表2.3中所示的重复次数(包括带步长的倒置瓶颈)。

2.3.1、信息瓶颈特性
来自[66]的信息瓶颈原理理论强调了学习理论中与信息相关的两个关键方面。首先,作者认识到深度神经网络(DNNs)并不严格遵循马尔可夫链 X → X ~ → Y X \rightarrow \tilde{X} \rightarrow Y X→X~→Y的形式,其中 X X X、 X ~ \tilde{X} X~和 Y Y Y分别是输入、从 X X X中提取的最小充分统计量和输出。
因此,为了推导出 X ~ \tilde{X} X~作为提取有意义特征以处理 Y Y Y的最小充分统计量,DNNs需要学习如何使用最小充分统计量来提取特征,并采用尽可能紧凑的架构[66]。
其次,由于DNNs仅处理来自前一层 h i − 1 h_{i-1} hi−1的输入,这直接意味着可能会丢失后续层无法恢复的信息(方程(5))。
I ( Y ; X ) ≥ I ( Y ; h i ) ≥ I ( Y ; h i + j ) 其中 i + j ≥ i I(Y ; X) \geq I\left(Y ; h_{i}\right) \geq I\left(Y ; h_{i+j}\right) \quad \text { 其中 } \quad i+j \geq i I(Y;X)≥I(Y;hi)≥I(Y;hi+j) 其中 i+j≥i
像YOLOv9[73]中最近所见的那样,昂贵的解决方案,如列式网络[5, 21],通过在每个块之间进行密集的特征共享,并通过在信息分割的关键点添加密集训练块或额外的检测头来解决这个问题。由于实现上述方程中的等值是可行的,该理论[66]表明,每一层都应在最大化自身内部信息 I ( Y ; h i ) I\left(Y ; h_{i}\right) I(Y;hi)的同时,尽可能减少层间信息交换 I ( h i − 1 ; h i ) I\left(h_{i-1} ; h_{i}\right) I(hi−1;hi)。因此,我们没有像[71, 73, 21, 5]那样增加模型的计算复杂度,而是选择更高效地扩展它,集成了Dangyoon等人的倒置瓶颈理论[17]。
我们的实现涉及以 I ( h 0 ; h n ) I\left(h_{0} ; h_{n}\right) I(h0;hn)的形式最小化层间信息交换,其中 n n n等于神经网络的最后一个隐藏层,通过确保输入/输出通道的数量从第一个隐藏层到最后一个隐藏层永远不会超过一个差异比率。隐藏层通道的数量应保持在由P1的输入通道和P5的输出通道定义的限制内,差异比率小于6,以 I ( h 1 ; h n ) I\left(h_{1} ; h_{n}\right) I(h1;hn)的形式最小化 I ( h i − 1 ; h i ) I\left(h_{i-1} ; h_{i}\right) I(hi−1;hi)。
C h i ∈ [ C h 1 ; C h n ] 其中 C h n C h 1 ≤ 6 C_{h_{i}} \in\left[C_{h_{1}} ; C_{h_{n}}\right] \quad \text { 其中 } \quad \frac{C_{h_{n}}}{C_{h_{1}}} \leq 6 Chi∈[Ch1;Chn] 其中 Ch1Chn≤6
相反,Dangyonn等人的倒置瓶颈通道扩展实验[17]表明,扩展或缩减比率不应超过6。因此,我们在整个网络中通过扩展3来最大化 I ( Y ; h i ) I\left(Y ; h_{i}\right) I(Y;hi)。此外,在采用逐点通道扩展策略的带步长倒置瓶颈中,信息通过总共6的扩展被进一步激发,从而在 ( P i ; P i + 1 ) \left(P_{i} ; P_{i+1}\right) (Pi;Pi+1)之间最大化 I ( Y ; h i ) I\left(Y ; h_{i}\right) I(Y;hi)。然而,我们从P4到P5的倒置瓶颈中进一步激发信息,通过在P4到P5之间以9的扩展(与6的扩展相比,mAP提高了+0.5,更多信息见第B.3和B.4章)来最大化 I ( Y ; h i ) I\left(Y ; h_{i}\right) I(Y;hi)。
在块之间实现残差连接有助于通过提供来自前一层 h i − 1 h_{i-1} hi−1的信息来最小化 I ( h i − 1 ; h i ) I\left(h_{i-1} ; h_{i}\right) I(hi−1;hi)。密集连接[16, 27]可能会增强模型,但它们需要额外的内存。
2.4、颈部
在目标检测中,我们称模型的“颈部”为聚合多个层级语义信息的部分,它能够将来自更远层的提取层级共享到第一层。
历史上,研究人员使用PANet[79]或FPN[36]来高效地共享特征图,通过将多个语义信息 P i P_{i} Pi链接到PANet及其各自的输出(如图4(a)所示),从而实现多个检测层级。
在本文中,我们主要关注两个竞争对手:BiFPN[64]和YOLOF的SiSO[8]。BiFPN与我们的模型核心理念相同:使用计算成本较低的层(拼接和加法、深度可分离卷积和逐点卷积)。然而,BiFPN需要太多的语义信息和太多的阻塞状态(等待前一层,复杂的图),这使得它难以跟上快速的执行速度。

另一方面,SiSO[8]在目标检测的方法上很有趣。事实上,我们可以看到YOLOF的作者决定为模型“颈部”使用单一的输入和输出。与YOLOF论文中提出的其他解决方案相比,我们观察到具有多个输出的“颈部”(单输入、多输出 - SiMO)与具有单个输出的“颈部”(单输入、单输出 - SiSO)之间存在显著的退化。我们特别关注他们关于SiMO潜在效率的工作,证明了通过仅用一个丰富的输入来优化语义信息流,有可能改进YOLO模型“颈部”的第一层。
受PAN和FPNnet的启发,我们提出了一种快速PANnet(FPANet),其特点是卷积层更少、通道数更少且语义信息共享更高效。我们的方法与YOLOv8[29]中的“颈部”概念相似。我们减少了骨干网络之后、头部之前 P 3 P_3 P3和 P 5 P_5 P5之间的计算流,直接将语义信息层强化到 P 4 P_4 P4,如图4(b)所示。此外,我们还简化了“颈部”,最大限度地减少了锁定和等待时间,因为架构的并行化机会有限且结构复杂。此外,如图4©所示,我们优化了通道数以减少 P 3 P_3 P3中的计算量,因为在 P 4 P_4 P4和 P 3 P_3 P3中自下而上的路径信息与骨干网络在 P 3 P_3 P3处的PAN倒瓶颈中的扩展通道相匹配时,初始的逐点步骤是不必要的,即 C out P 4 + C in P 3 = C mid P 3 C_{\text{out}}P_4+C_{\text{in}}P_3=C_{\text{mid}}P_3 CoutP4+CinP3=CmidP3。
通过以最小的计算量从 P 3 P_3 P3和 P 5 P_5 P5强化单个输入( P 4 P_4 P4)来指导“颈部”信息,我们实现了SiMO和MiMO方法之间的中间方案,并显著减少了MiMO的变化。
2.5、网络头部的解耦网络
在YOLOv5[50-[52, 2, 30]之前,我们只有一个用于分类和目标检测的模型头部。然而,自YOLOv6[32]以来,模型头部已成为一个更强大的工具,它将模块分为两部分:一个用于分类的分支和一个用于目标回归的分支。虽然这种方法非常高效,但几乎将成本翻倍,因为分类和检测都需要进行卷积操作。
我们认为,除了使用轻量级深度可分离卷积按通道细化骨干网络和“颈部”提取的特征外,没有必要添加其他空间信息。
历史上,YOLO模型以网格的形式工作,通过每个点上的锚框为每个网格像素提出分类。锚框提供了几种可能的检测尺寸,而不仅仅是逐像素检测。
通过YOLO的点对点网格操作,我们提出理论假设,认为可以使用逐点卷积作为滑动多层感知器解决方案,逐像素地简化检测头,类似于为每个像素提出的分类建议——使用仅针对空间指令的几个深度可分离卷积,细化两个逐点分类之间的空间关系,并对每个像素进行回归。
通过消融研究(见第B.4章),我们证明在模型头部仅使用逐点卷积在LeYOLO-Nano@640尺度上取得了令人印象深刻的33.4 mAP结果。在逐点卷积之间使用深度可分离卷积来细化空间信息,将模型性能提升至34.3 mAP。

如图5所示,我们提出了DNiN(解耦网络内网络头),这是一种以逐点为中心的方法,每个网络建议包含两个独立的逐点操作:分类和回归(边界框)。逐点操作在目标检测中至关重要,它们在网络内网络框架中作为逐像素分类器和回归器。与单个 5 × 5 5 \times 5 5×5卷积相比,深度可分离卷积被拆分为两个 3 × 3 3 \times 3 3×3卷积以降低总体成本。
我们运行两个独立的逐点卷积:一个专门用于分类,另一个用于回归。这种区别源于分类和边界框提取之间的不同要求。我们提出的DNiN头部在保持 P i P_{i} Pi层空间维度的同时,扩展通道以匹配类别数量。因此,每个像素都代表一个潜在的预测。使用 1 × 1 1\times1 1×1卷积源于神经网络,特别是NiN模型[35],其中逐点卷积作为传统多层感知器的替代品出现。
2.6、结果
2.6.1、架构缩放
对于LeYOLO,我们提供了多种受上述架构基础启发的模型。一种经典方法是缩放通道数、层数和输入图像大小。传统上,缩放强调通道和层配置,有时会融入各种缩放模式。由于LeYOLO模型的茎干、颈部和头部都经过了优化,因此将图像大小增加到640以上并不会带来极高的浮点运算次数(FLOP)。我们提供了LeYOLO的八个版本,其缩放情况在第B.4.4章中讨论,图像大小从320到768像素,浮点运算次数从0.66到8.4 FLOP(G),如表3所示。

3、讨论
在我们努力从最先进的神经网络中提供深入的理论见解以制定优化解决方案时,我们认识到几个潜在的改进领域,并期待看到LeYOLO在进一步研究中的进展。
通道选择:尽管我们的网络设计基于最优信息原理理论,但我们的研究仍存在不确定性。观察关于神经网络架构搜索(NAS)的论文可以发现,通道配置的潜在选择非常广泛,往往超出了人类的直觉。没有NAS,很难用坚实的理论证据来肯定特定数量通道的选择。我们预计NAS可以促进发现更好的层重复和通道配置。
LeYOLO FPANet + DNiN头部:考虑到我们FPANet和模型头部的成本效益,在不同最新分类模型的主干上进行实验存在巨大的机会。LeYOLO已成为SSD和SSDLite的有前途的替代品。我们在MSCOCO上使用我们的解决方案取得的良好结果表明,它可能适用于其他面向分类的模型。我们特别针对MSCOCO和YOLO导向的网络进行了优化工作。然而,我们也鼓励在其他数据集上对我们的解决方案进行实验。
计算效率:我们为YOLO模型实现了一种新的缩放方式,证明了在使用非常少的计算资源(FLOP)的同时,可以达到非常高的精度水平。然而,我们并不是最先进的,因为由于(故意)缺乏像前辈们[54, 24, 64]那样的可并行化架构,我们的速度存在缺陷。我们可以进一步分析不同边缘功率的缩放,以提出可并行化的列和块缩放。
因此,我们鼓励对我们的提议进行进一步的实验,在深入实验结果的同时,探索适应特定行业需求(如智能农业和医学)的各种数据集变体。
4、结论
本文介绍了适用于移动应用的轻量级目标检测技术的进展,并为YOLO模型引入了一种新颖的缩放方法。我们提出的架构FPAN和DNiN采用了诸如逐点卷积和深度可分离卷积等轻量级操作,提供了一个专为目标检测而设计的、与基于SSDLite的解决方案一样轻量级的、高度有效的神经网络。这在成本与精度的比例上开创了新局面。构建这些优化措施利用了更高效的YOLO缩放。我们提出了一个新的YOLO模型系列,在MSCOCO上实现了具有竞争力的mAP分数,同时注重一系列FLOP资源约束。我们的缩放版LeYOLOSmall在比最新最先进的目标检测器少42%的FLOP的情况下,实现了相似的准确性。这样,我们证明了在不同级别的语义信息之间进行缩放和优化通道选择,可以使我们超越前所未有的每mAP FLOP比例。LeYOLO-Medium在mAP上比最新的YOLOv9-Tiny最先进模型高出 39.3 m A P ( + 2.61 % ) 39.3 \mathrm{mAP}(+2.61 \%) 39.3mAP(+2.61%),而在FLOP上减少了 5.8 F L O P ( G ) ( − 24.67 % ) 5.8 \mathrm{FLOP}(\mathrm{G})(-24.67 \%) 5.8FLOP(G)(−24.67%)。
A 附录 / 补充材料
B 符号说明
在本文中,我们使用了多种符号来描述深度学习的关键组件,特别是在目标检测领域——例如,不同张量的空间大小被描述为 P i P_{i} Pi。本章涵盖了论文中使用的所有符号。由于深度学习符号的规范并不统一,我们认为在附录中对其进行更深入的描述对于需要进一步解释的读者来说是有意义的。
首先,我们想对本文的主要组成部分——计算公式进行更多解释。在整篇论文中,我们始终使用浮点运算次数(FLOP,Floating Point Operations)这一指标来比较我们的工作与其他最先进的神经网络。通过基于神经网络所需的乘法和加法次数进行计算,我们为有效的模型比较建立了坚实的基础。FLOP指标与所使用的硬件无关,因此是衡量计算效率的良好指标。尽管我们可以使用其他指标(如速度),但这些指标高度依赖于神经网络架构的并行化、所使用的硬件、加速器软件(如TensorRT、CoreML、TFLite)以及内存使用量和传输速度等因素。
我们在整篇论文中始终使用的第二个主要元素是平均精度均值( m A P \mathbf{mAP} mAP,mean Average Precision)。研究人员广泛使用该指标来比较基于目标检测的神经网络。mAP通过评估提出的边界框与实际标注的边界框之间的重叠度来衡量模型的精度。虽然一些论文使用固定阈值(如50%重叠度,即mAP50)来比较模型,但我们主要使用mAP50-95。该指标在不同重叠度阈值(从50%到95%)下对精度进行平均,覆盖了更广泛的评估标准。
在目标检测中,特征图的空间尺寸至关重要,我们将 P i P_{i} Pi定义为我们的深度神经网络中的特征图尺寸。对于LeYOLO-Small到Medium,尺寸范围从 P 0 P_{0} P0( 640 × 640 640 \times 640 640×640像素)到 P 5 P_{5} P5( 20 × 20 20 \times 20 20×20像素),其中 i i i代表步长的数量。类似地, P i − 1 P_{i-1} Pi−1表示明确描述的特征图 i i i之前的特征图尺寸。
同样,在描述神经网络中的隐藏层时,我们指的是整个块而不是单个卷积。例如,本文中将一个单个倒置瓶颈描述为一个隐藏层 h i h_{i} hi,该层由两个逐点卷积和一个深度可分离卷积组成。在整篇论文中,这使我们能够直接引用前面的倒置瓶颈为 h i − 1 h_{i-1} hi−1。
请注意,我们可能会结合所有符号来突出架构的特定组件。例如,我们将每个语义级别 P P P的通道数 C C C表示为 C P i C_{P_{i}} CPi。我们将每个语义级别 P i P_{i} Pi的特征图的高度和宽度分别指定为 H P i H_{P_{i}} HPi和 W P i W_{P_{i}} WPi。
B. 1、最新技术全面对比
本节将LeYOLO与YOLO主线模型、专为目标检测设计的微型神经网络,以及在320x320分辨率下运行的领先分类模型SSDLite进行了全面比较。
我们使用两个主要指标来评估我们的性能与其他模型的性能:平均精度均值(mAP)和浮点运算次数(FLOPs)。mAP的计算涉及多种参数,包括交并比(IOU)为0.5的情况。然而,对于FLOPs而言,乘累加(MAC)和FLOPs公式的交织性导致了不一致性,研究人员错误地使用FLOPs而不是MAC来标注他们的模型。这意味着模型的计算成本至少是所声明的初始量的两倍。

我们还增加了在轻量级最新目标检测模型中使用的参数数量。除了拥有两百万个参数的YOLOv9-Tiny取得了令人印象深刻的结果外,我们的贡献与其他模型相比使用的参数非常少。表4展示了所有结果。
B. 2 总体架构
为了可读性,我们省略了对颈部中语义共享策略的讨论。在自下而上的路径中,我们采用轻量级块对特征图进行上采样,而自上而下的路径则使用标准卷积。尽管标准卷积的成本较高,但由于空间尺寸较小且使用的通道数受限,因此在这种情况下证明是有效的。

我们尝试使用倒置瓶颈(inverted bottlenecks)代替卷积,但发现这样做成本更高且精度更低。此外,我们避免在第一次 20 × 20 20 \times 20 20×20上采样之前使用任何卷积,这与大多数YOLO架构所采用的方法不同。我们质疑在空间金字塔池化融合(Spatial Pyramid Pooling Fusion,SPPF)[30, 29]之后是否还需要另一个卷积,因为主干网络可能已经足够高效。最后, 80 × 80 80 \times 80 80×80的方面资源消耗大,需要仔细考虑。基于类似的推理,我们避免了 80 × 80 80 \times 80 80×80自上而下路径的计算,因为在消融研究中,FPANet的 80 × 80 80 \times 80 80×80逐点组件的成本似乎与边际精度提升不成比例。图6展示了LeYOLO的完整架构。

B. 3 架构差异
我们提出了我们的提议与几种受倒置瓶颈启发的骨干网络的比较。尽管大多数当代最先进的目标检测器都忽略了它们,但MobileNetv2[54]、MobileNetv3[24]和EfficientNets[75, 63, 64]都采用了使用倒置瓶颈进行目标检测的理念。

如引言中所述,GPU的进步推动了强大且快速的神经网络的发展。然而,倒置瓶颈在并行化多个计算块时提供的深度有限。在嵌入式设备上并行化深度神经网络仍然具有挑战性,但未来充满希望。研究主要集中在减少MAC和FLOP成本,有时甚至是内存访问成本。自然,执行速度仍然是一个重大问题。然而,我们旨在使用一致的符号将我们的骨干网络(表5)与具有“类似”架构的模型(表6、7和8)进行简要比较,特别是那些使用倒置瓶颈的模型。
通过这一比较,我们可以观察到步长倒置瓶颈策略。在代码验证过程中,我们确实注意到,在从一层 ( h i ; P i ) \left(h_{i} ; P_{i}\right) (hi;Pi)过渡到另一层 ( h i + 1 ; P i + 1 ) \left(h_{i+1} ; P_{i+1}\right) (hi+1;Pi+1)时,如果步长大于1,则通道扩展会存在对比。此外,大多数倒置瓶颈都使用6的扩展率,而我们只在一个块内扩展到3。这减少了整体计算量,并允许倒置瓶颈步长策略在深度卷积的步长内最后一次扩展通道数。

B. 4 消融研究
要数学证明普遍真理,如一个神经网络架构是否比另一个未经过训练的架构表现更好,是困难的。然而,我们并不认为这是一个问题;相反,我们使用消融研究来证明我们的架构是有效的。此外,我们还遇到过比我们最终提出的贡献表现更好的架构,但它们的计算成本更高。本消融研究代表了我们能够开展的最相关的实验。然而,我们已将选择权留给读者,让他们在未来研究中选择最有效但成本更高的架构,以更有效地指导研究人员。
B.4.1 内核大小
内核滤波器大小:为了叙述清晰,我们直接在论文中概述了为达到最佳准确率和每秒浮点运算次数(FLOP)效率而选择的最终架构。然而,我们的研究始于基于倒置瓶颈的最小化架构。最初,当特征图大小达到 80 × 80 80 \times 80 80×80时,我们尝试了 5 × 5 5 \times 5 5×5和 7 × 7 7 \times 7 7×7的内核大小。我们的消融研究表明,较大的内核大小能带来令人满意的结果,如表9所示。虽然 7 × 7 7 \times 7 7×7内核在性能上优于 3 × 3 3 \times 3 3×3(提升 + 2.4 +2.4 +2.4 mAP点)和 5 × 5 5 \times 5 5×5(提升 + 0.4 +0.4 +0.4 mAP点),但它显著增加了FLOP需求。因此,我们选择了 5 × 5 5 \times 5 5×5内核以平衡FLOP利用率和准确性。
内核大小消融研究:
- minimal:具有经典倒置瓶颈和全部 3 × 3 3 \times 3 3×3卷积的最小化架构。
- 5 × 5 5 \times 5 5×5:在P3及之后使用 5 × 5 5 \times 5 5×5卷积的最小化架构。
- 7 × 7 7 \times 7 7×7:在P3及之后使用 7 × 7 7 \times 7 7×7卷积的最小化架构。
在MSCOCO数据集上达到 34.9 \mathbf{34.9} 34.9 mAP和 3 , 293 \mathbf{3,293} 3,293 FLOP(G)的情况下,最佳选择是在从语义级别P3到P5的整个模型中一致使用 5 × 5 \mathbf{5 \times 5} 5×5内核大小(主干和FPANet中的Stem部分仍使用 3 × 3 3 \times 3 3×3内核大小)。
内核大小和特征图大小成本:P3( 80 × 80 80 \times 80 80×80)特征图产生了相当大的计算成本,因此需要在该模型阶段减少计算量。一个目标是仅从P4到P5(而不是从P3到P5)在主干和FPANet中使用 5 × 5 5 \times 5 5×5卷积,以优化模型效率。
此外,在FPANet的自上而下路径中使用步长为2的两个 5 × 5 5 \times 5 5×5卷积的有效性仍需证明。我们通过在FPANet中使用 3 × 3 3 \times 3 3×3卷积进行下采样来探索不同内核大小的有效性。我们的消融研究确定了在当前阶段内核大小的最佳折衷方案,如表9所示。
内核大小消融研究:
- 5 x 5 @ P 4 5 \mathrm{x} 5 @ \mathrm{P} 4 5x5@P4:在P4及之后使用 5 × 5 5 \times 5 5×5卷积的最小化架构。
- FPANet 3 × 3 ↓ 3 \times 3 \downarrow 3×3↓:在P4使用 5 × 5 5 \times 5 5×5卷积,并且仅在FPANet中使用 3 × 3 3 \times 3 3×3卷积进行下采样的最小化架构。
关于mAP与FLOP的比率,我们观察到通过结合使用从P4到P5的 5 × 5 5 \times 5 5×5内核大小(其中Stem和P3使用一致的 3 × 3 3 \times 3 3×3内核大小),以及使用 3 × 3 3 \times 3 3×3内核大小进行FPANet下采样卷积,可以获得更好的内核滤波器大小选择。这些选择将mAP与FLOP的比率提升至 m A P F L O P ( G ) = 11.49 \frac{m A P}{F L O P(G)}=11.49 FLOP(G)mAP=11.49,在 3 , 011 3,011 3,011 FLOP(G)下实现了 34 , 6 \mathbf{34,6} 34,6 m A P \mathbf{~mAP} mAP。
B.4.2 架构改进
为了改进架构,我们旨在简化P4之前的所有计算。在已经对P3的内核大小进行调整之后,我们移除了P2( 160 × 160 160 \times 160 160×160)中STEM的初始逐点操作,因为输入通道数与深度卷积所需的通道数相匹配。利用我们倒置瓶颈构建块的效率,结合可选的逐点操作,意外地改进了模型,达到了 34.7 34.7 34.7 mAP,并减少了 66 66 66 MFLOP的计算量(即 2 , 945 \mathbf{2,945} 2,945 FLOP(G))。
根据这一优化过程,我们在最小化和最终架构中都选择了通道配置,该配置与压缩的信息瓶颈 I ( h 1 ; h n ) I\left(h_{1} ; h_{n}\right) I(h1;hn)(方程(6))保持一致,限制了每个块的输入通道数。通过这种方式,从骨干网络中保留在内存中的P4 C out C_{\text {out }} Cout 和P3 C out C_{\text {out }} Cout 自下而上路径的特征图拼接,已经与FPANet中P3块所需扩展的通道数 C mid C_{\text {mid }} Cmid 相匹配。因此,我们将架构精简到P4之前的必要组件,从而为惊人的 34.1 34.1 34.1 mAP释放了计算资源,此时FLOP为 2 , 823 \mathbf{2,823} 2,823 FLOP(G)。

表9描述了所有结果。
最小化架构改进:
- n o p w @ S T E M n o_{p w} @ S T E M nopw@STEM:在P1的第一个倒置瓶颈中的stem中没有逐点卷积。
- n o p w @ F P A N − P 3 n o_{p w} @ F P A N-P 3 nopw@FPAN−P3:在自下而上的FPAN路径中,P3的第一个倒置瓶颈中没有逐点卷积。
虽然一些研究可能主张保留之前的配置,认为移除逐点卷积会损害准确性,但我们进行了其他实验以提高准确性与FLOP的比率。尽管可能存在争议,但我们保持了消融研究的完整性,保留了所有发现,以便研究人员或读者可以从我们实验的不同方面中获益。
B.4.3 通道选择
我们的目标是确定最佳通道数,而不诉诸于像NAS那样昂贵的训练算法,而是依赖于基于先前架构选择的迭代实验。因此,我们进行了各种实验,包括探索FPANet内的理想通道数。表10描述了以下所有解释。
骨干网络通道选择:我们期望优化通道选择,并发现将P3到P4的信息扩展因子从6改为3(尽管效果稍弱),但所需的计算量更少。在本次实验中,我们保持了在P2到P3(从 16 C i n P 2 16 C_{in} P_{2} 16CinP2通道到 96 C m i d P 3 96 C_{mid} P_{3} 96CmidP3)和P4到P5(对于LeYOLO-Nano基础通道选择,从 64 C i n P 4 64 C_{in} P_{4} 64CinP4到576 C m i d P 5 C_{mid} P_{5} CmidP5通道)之间步长为6的倒置瓶颈通道扩展比。
颈部网络通道选择:以我们在所有模型中一致的通道扩展选择3为例,我们在颈部网络内部测试了扩展比为2和2.5的不同扩展比。通过这些实验,我们想要比较在骨干网络或颈部网络中添加更多扩展通道的好处。就我们的选择而言,我们将神经网络在P5处的骨干网络上的支持更多(以扩展比为6为例)与在整个FPAN颈部网络内的压力更小(以整个FPAN颈部网络内扩展比为2而不是3为例)的性能进行了比较。
从表10中提出的消融实验来看,我们观察到全局上,将颈部网络内的通道数简化为扩展比为2是更好的选择,因为P5处瓶颈内的更大扩展策略带来了更好的准确性和mAP与FLOP比。
通道选择:
- CC:通道选择 - 我们将P3到P4的扩展比从6减少到3。
- CCx6:我们将P5内所有块的扩展比从3增加到6。
- FPANx2:所有FPAN倒置瓶颈块使用2的扩展比而不是3。
- FPANx2.5:所有FPAN倒置瓶颈块使用2.5的扩展比而不是3。
关于实验所选的初始最小架构,我们从2.877 GFLOP下的32.9 mAP开始。经过通过训练实验验证的迭代优化,我们将LeYOLONano的准确率提升至 34.3 m A P \mathbf{34.3 \, mAP} 34.3mAP,同时将计算需求降低至 2.64 G F L O P \mathbf{2.64 \, GFLOP} 2.64GFLOP。这表明在模型优化过程中,准确率得到了提升,同时计算复杂度也有所降低。

B.4.4 架构缩放选择
本节将更深入地探讨我们在贡献中提出的模型缩放方法。如第2.6.1章所述,我们提出了四种不同的缩放方法,将架构压缩至10 GFLOP以下。表11展示了四种训练缩放可能性(Nano至Large),而表12则展示了八种最终提出的推理缩放方案。

我们可以有效地将核心架构从之前提到的消融研究转移到不同的输入尺寸上进行推理和验证。例如,一个明确在640p下训练的神经网络,在压缩到320p并进行验证时,可能比一个在320p下从头开始训练的神经网络产生更好的结果。因此,我们测试了表11中LeYOLO的Nano、Small、Medium和Large等不同训练规模的神经网络,以确定最优的输入和训练组合。表13中展示的结果突出了本研究的最佳成果。

B.4.5 速度测试
正如论文中所讨论的,我们提出了一系列高效的神经网络模型家族,这些模型仅关注FLOP计算,而忽略了执行速度。倒置瓶颈(Inverted bottlenecks)本质上降低了神经网络的并行化潜力,导致GPU需要顺序等待后续操作。因此,尽管我们的模型在最新技术中可能不是最快的,但它们提供了各种执行速度不同的模型。我们专注于嵌入式设备上的目标检测器,因此我们建议使用配备TensorRT软件加速器的4GB Jetson TX2进行比较,以观察最新的并行化能力。我们可以在表14和图7中找到执行速度、准确率、每秒查询次数(qps)、FLOP和qps的详细信息。

B.5 代码
由于我们可以使用PyTorch、Tensorflow或任何其他API,因此我们使用YOLOv8版本的Ultralytics代码来开发我们的LeYOLO版本。使用这些工具并实现代码将非常简单,可以将研究集中在单个工具上。
B.6 训练特异性
在MSCOCO上进行训练。我们使用MSCOCO数据集[37]对模型进行训练,采用标准的数据增强方法[49],在四个GPU上使用随机梯度下降(SGD)和128的批量大小。学习率最初设置为0.01,动量设置为0.9。权重衰减设置为0.001。
马赛克数据增强:在整个训练过程中,我们通过多次实验发现,马赛克数据增强对准确率的影响微乎其微。这一现象主要出现在数据样本有限的小物体上,如MSCOCO中的牙刷,其中马赛克增强可能会产生不利影响。在我们的实验中,我们注意到mAP的潜在变化为0.4。
- epochs: 500
- patience: 50
- batch: 128
- imgsz: 640
- gpu count: 4
- workers: 8
- optimizer: SGD
- seed: 0
- close mosaic: 10
- training iou: 0.7
- max detectections: 300
- lr 0 : 0.01 \operatorname{lr} 0: 0.01 lr0:0.01
- lrf: 0.01
- momentum: 0.9
- weight decay: 0.001
- warmup epochs: 3.0
- warmup momentum: 0.8
- warmup bias lr: 0.1
- box: 7.5
- cls: 0.5
- dfl: 1.5
- pose: 12.0
- kobj: 1.0
- label smoothing: 0.0
- nbs: 64
- hsv h: 0.015
- hsv s: 0.7
- hsv v: 0.4
- degrees: 0.0
- translate: 0.1
- scale: 0.5
- shear: 0.0
- perspective: 0.0
- flipud: 0.0
- fliplr: 0.5
- mosaic: 1.0
- mixup: 0.0
- copy paste: 0.0
- erasing: 0.4
- crop fraction: 1.0
相关文章:
YoloV8改进策略:Block改进|LeYOLO,一种用于目标检测的新型可扩展且高效的CNN架构|复现LeYolo,轻量级Yolo改进
摘要 LeYOLO是在YOLO系列,特别是可能受到YOLOv8启发的基础上进行的一系列改进,旨在提升目标检测模型的高效性、可扩展性和精度。其主要特点包括: 高效骨干网络缩放方法: LeYOLO借鉴了倒置瓶颈(Inverted Bottleneck&am…...
简介)
ODX(Open Diagnostic Data Exchange)简介
ODX(Open Diagnostic Data Exchange)是一种由ASAM制定的开放标准,用于描述和交换ECU(电子控制单元)诊断数据,广泛应用于车辆诊断。ODX文件采用XML格式,包含通讯参数,如ISO15765-2/3时间参数。 ASAM(Association for Standardisation of Automation and Measuring Syst…...

记一次CSDN认证模块后端未校验漏洞
前言 作为一个程序员,一直充满好奇心,没事就喜欢找找漏洞,试想一下某些程序是否存在某些鉴权等漏洞,目前该漏洞已提交官方,且影响不大,现分享分析过程用于各位技术学习。 漏洞分析 https://i.csdn.net/#…...

【图机器学习系列】(一)图机器学习简介
微信公众号:leetcode_algos_life,代码随想随记 小红书:412408155 CSDN:https://blog.csdn.net/woai8339?typeblog ,代码随想随记 GitHub: https://github.com/riverind 抖音【暂未开始,计划开始】…...

全网最详细,从一堆字符串,精确抓取想要日期时间的实战2.0
前言: 前面我们知道了,怎么从一堆带有中文、英文、日期时间的字符串里面抓取需要的日期时间,但是我们实现的只是抓取第一个日期时间,那我们怎么实现,抓取第二个,或者任一一个日期时间呢? 一、思路分析 1、数…...

24/8/15算法笔记 dp策略迭代 价值迭代
策略迭代: 策略迭代从某个策略开始,计算该策略下的状态价值函数。它交替进行两个步骤:策略评估(Policy Evaluation)和策略改进(Policy Improvement)。在策略评估阶段,计算给定策略下…...

【MMdetection改进】换遍MMDET主干网络之SwinTransformer-Tiny(基于MMdetection)
OpenMMLab 2.0 体系中 MMYOLO、MMDetection、MMClassification、MMSelfsup 中的模型注册表都继承自 MMEngine 中的根注册表,允许这些 OpenMMLab 开源库直接使用彼此已经实现的模块。 因此用户可以在MMYOLO 中使用来自 MMDetection、MMClassification、MMSelfsup 的主…...

FL Studio21.2.4最新中文版免费下载汉化包破解补丁
🎉 FL Studio 21中文版新功能全解析!让你的音乐制作更加高效! 嘿,各位音乐制作的小伙伴儿们,今天我要安利一款你们绝对会爱上的神器——FL Studio 21中文版!这款软件不仅功能强大,而且操作简便…...

私域场景中的数字化营销秘诀
在当今的商业世界,私域场景的营销变得愈发重要。今天咱们就来深入探讨一下私域场景中的几个关键营销手段。 一、会员管理与营销 企业一旦拥有完善的会员体系,数字化手段就能大放异彩。它可以助力企业对会员进行精细划分,深度了解会员的消费…...

一键换肤(Echarts 自定义主题)
一键换肤(Echarts 自定义主题) 一、使用官方主题配置工具 官方主题配置工具:https://echarts.apache.org/zh/theme-builder.html 如果以上主题不满足使用,可以自己自定义主题 例如:修改背景、标题等,可…...
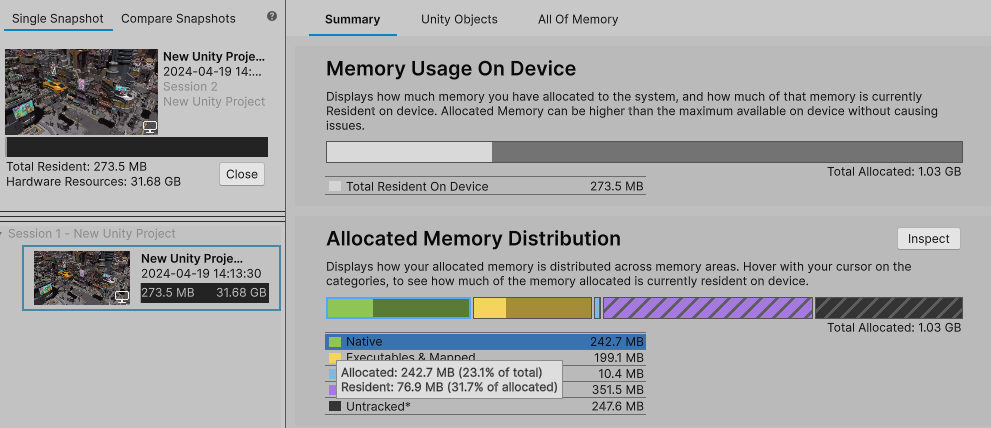
Unity 6 预览版正式发布
Unity 6 预览版发布啦,正式版本将于今年晚些时候正式发布! 下载链接: https://unity.com/releases/editor/whats-new/6000.0.0 Unity 6 预览版是 Unity 6 开发周期的最后一个版本,在去年 11 月 Unite 大会上,我们宣…...

如何跳过极狐GitLab 密钥推送保护功能?
极狐GitLab 是 GitLab 在中国的发行版,专门面向中国程序员和企业提供企业级一体化 DevOps 平台,用来帮助用户实现需求管理、源代码托管、CI/CD、安全合规,而且所有的操作都是在一个平台上进行,省事省心省钱。可以一键安装极狐GitL…...
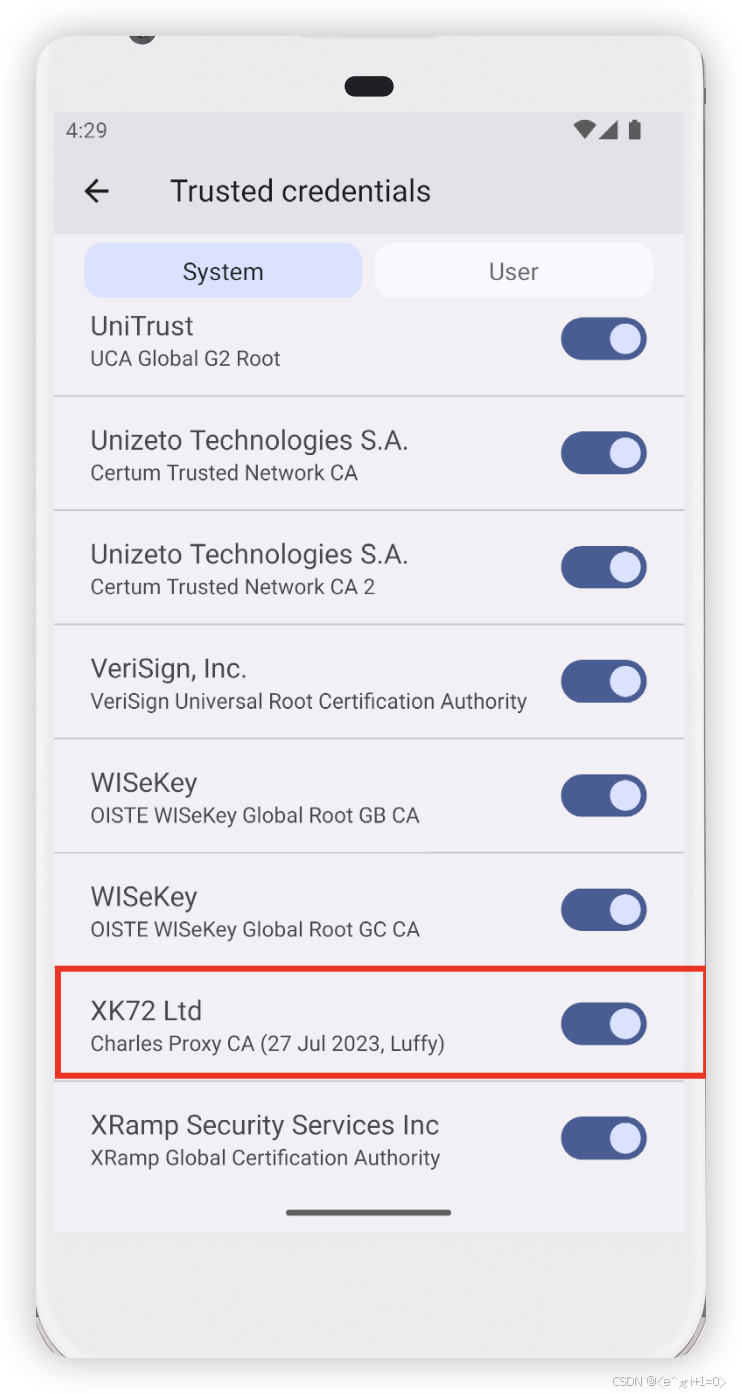
Android高版本抓包总结
方案1 CharlesVirtualXposedJustTrustMe 推荐使用三星手机此方案 VirtualXposed下载链接:https://github.com/android-hacker/VirtualXposed/releases JustTrustMe下载链接:https://github.com/Fuzion24/JustTrustMe/releases/ 下载完成后使用adb命令…...
《AI视频类工具之五—— 开拍》
一.简介 官网:开拍 - 用AI制作口播视频用AI制作口播视频https://www.kaipai.com/home?ref=ai-bot.cn 开拍是一款由美图公司在2023年推出,利用AI技术制作的短视频分享应用。这款工具通过AI赋能,为用户提供了从文案创作、视频拍摄到视频剪辑、包装的一站式解决方案,极大地…...

面试经典算法150题系列-最后一个单词的长度
最后一个单词的长度 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 示例 1: 输入:s "Hello World&qu…...

RTT学习
电源管理组件 嵌入式系统低功耗管理的目的在于满足用户对性能需求的前提下,尽可能降低系统功耗以延长设备待机时间。 高性能与有限的电池能量在嵌入式系统中矛盾最为突出,硬件低功耗设计与软件低功耗管理的联合应用成为了解决矛盾的有效手段。 现在的各…...
|附赠完整面试流程)
前端面试题(二十五)|附赠完整面试流程
📝📝今日分享:前端面试题系列继续更新啦! 🤔🤔面试题是什么呢?这份前端面试题主要是上海某银行的中级前端面试题,面试时长属实没想到,挺短的!但从整个面试流程…...

【分布式系统】关于主流的几款分布式链路追踪工具
Jaeger 标准化与兼容性: Jaeger 支持 OpenTracing 和 OpenTelemetry 标准,这意味着它可以与各种微服务架构和应用框架无缝集成,提供了广泛的兼容性和灵活性。 数据存储选项: Jaeger 支持多种数据存储后端,如 Cassandra…...

【吸引力法则】探究人生欲:追求深度体验与宇宙链接
文章目录 什么是人生欲?唤醒人生欲:克服配得感的三大障碍1 第一大障碍:法执的压制2 第二大障碍:家庭的继承2.1 家庭创伤的代际传递2.2 家庭文化基因的传递2.2.1 “成年人最大的美德是让自己的生活过得更加精彩。”2.2.2 荷欧波诺波…...

REST framework-通用视图[Generic views]
Django’s generic views… were developed as a shortcut for common usage patterns… They take certain common idioms and patterns found in view development and abstract them so that you can quickly write common views of data without having to repeat yourself…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
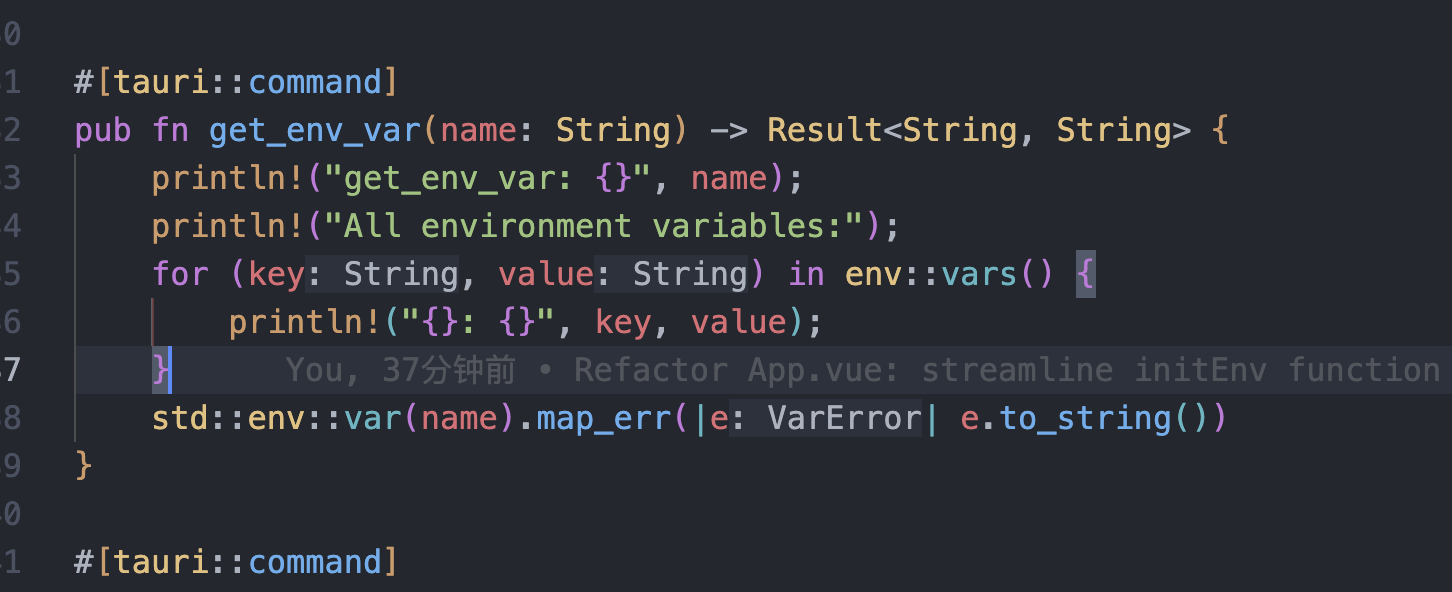
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...