Vitis AI 基本认知(训练过程)
目录
1. 目的
2. TensorBoard
2.1 In TensorFlow
2.2.1 安装 TensorBoard
2.2.2 导入必要的库
2.2.3 初始化
2.2.4 记录数据
2.2.5 启动 TensorBoard
2.2.6 刷新间隔
2.2 In PyTorch
2.2.1 安装 setuptools
2.2.2 记录数据
2.2.3 查看 Tensorboard
3. 训练周期 Epoch
3.1 Epoch
3.2 Batch
3.3 Iteration
4. 梯度累加
4.1 解释训练代码
4.2 累加 or 分批
5. 总结
1. 目的
- 介绍和使用TensorBoard
- 解释一些训练概念
- 梯度累加
2. TensorBoard
2.1 In TensorFlow
2.2.1 安装 TensorBoard
pip install tensorboard查看是否安装 TensorBoard:
>> pip show tensorboard
---
Name: tensorboard
Version: 2.8.0
Summary: TensorBoard lets you watch Tensors Flow
Home-page: https://github.com/tensorflow/tensorboard
Author: Google Inc.
Author-email: packages@tensorflow.org
License: Apache 2.0
Location: /opt/vitis_ai/conda/envs/vitis-ai-tensorflow2/lib/python3.7/site-packages
Requires: absl-py, google-auth, google-auth-oauthlib, grpcio, markdown, numpy, protobuf, requests, setuptools, tensorboard-data-server, tensorboard-plugin-wit, werkzeug, wheel
Required-by: tensorflow2.2.2 导入必要的库
import time
import tensorflow as tf2.2.3 初始化
# 初始化 TensorBoard 的 SummaryWriter
log_dir = "./"
writer = tf.summary.create_file_writer(log_dir)2.2.4 记录数据
# 记录数据
with writer.as_default():for i in range(100):tf.summary.scalar('Incremental Data', i, step=i)time.sleep(1) # 延迟 1 秒2.2.5 启动 TensorBoard
在 Jupyter Lab 中 Terminal 运行以下命令来启动 TensorBoard:
tensorboard --logdir=./
---
NOTE: Using experimental fast data loading logic. To disable, pass"--load_fast=false" and report issues on GitHub. More details:https://github.com/tensorflow/tensorboard/issues/4784Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.8.0 at http://localhost:6006/ (Press CTRL+C to quit)在浏览器中打开显示的 URL(直接单击链接地址即可),查看数据:

2.2.6 刷新间隔
勾选 “Reload data” 选项,并设置 “Reload period” 为你希望的刷新间隔(最少 30 秒)。
2.2 In PyTorch
2.2.1 安装 setuptools
在 Vitis AI 2.5 中,默认安装的 setuptools 版本是 59.8.0,和 Torch 环境不符。
需要降级 setuptools:
pip install setuptools==59.5.02.2.2 记录数据
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter# 输入数据
X = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
Y = torch.tensor([[10.0], [20.0]])# 定义模型
class LinearRegressionModel(nn.Module):def __init__(self):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(3, 1)# 初始化权重和偏置为零nn.init.zeros_(self.linear.weight)nn.init.zeros_(self.linear.bias)def forward(self, x):return self.linear(x)model = LinearRegressionModel()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)log_dir = "./"
writer = SummaryWriter('log_dir')# 训练模型
for epoch in range(500):model.train()optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, Y)loss.backward()optimizer.step()writer.add_scalar('Incremental Data', loss, epoch)writer.close()# 打印模型变量
for name, param in model.named_parameters():print(f"{name}: {param.data}")在 Jupyter Lab 中 Terminal 运行以下命令来启动 TensorBoard:
tensorboard --logdir=./
---请访问 http://workspace.featurize.cn:18245 来访问 TensorBoard 面板
如果无法访问面板,清参考文档 https://docs.featurize.cn/docs/manual/tensorboard 解决2024-08-14 16:25:28.403920: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
2024-08-14 16:25:28.404023: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (featurize): /proc/driver/nvidia/version does not existNOTE: Using experimental fast data loading logic. To disable, pass"--load_fast=false" and report issues on GitHub. More details:https://github.com/tensorflow/tensorboard/issues/4784TensorBoard 2.7.0 at http://0.0.0.0:6006/ (Press CTRL+C to quit)2.2.3 查看 Tensorboard

3. 训练周期 Epoch
3.1 Epoch
Epoch,即训练周期是一个非常重要的概念。它指的是整个训练数据集被完整地送入神经网络进行一次前向传播和反向传播的过程。简单来说,就是模型在所有训练数据上训练了一遍。
随着 epoch 数量的增加,模型会逐渐从欠拟合状态(underfitting)转变为过拟合状态(overfitting)。因此,选择合适的epoch数量对于模型的性能至关重要。
可以将训练过程想象成学习一本书。一个 epoch 就像是从头到尾读完这本书一次。每次读完一遍(一个 epoch),你都会对书中的内容理解得更深刻。然而,如果你反复读这本书太多次(过多的epoch),你可能会开始记住每一个细节和句子,而不是理解书的整体意义。这就像是你在考试中只记住了书中的例子,而不是掌握了解决问题的方法。
3.2 Batch
假设你把一本书分成了多个章节(batch),每次你读完一个章节并做笔记(一次 Iteration),你会对这部分内容有更深的理解。完成所有章节的阅读和笔记(所有 Iteration)后,你就完成了一次完整的阅读(一个 epoch)。
- 训练数据会被分成多个小批次(batch)进行训练,每个小批次包含一定数量的样本。
- 只有当前批次的数据会被加载到内存中进行处理。
- 训练中,每个小批次上会进行前向传播和反向传播,更新权重。
3.3 Iteration
如果你的训练数据集有1000个样本,你将其分成每个包含100个样本的10个批次(batch)。那么,完成一个 epoch 需要10次 iteration。
4. 梯度累加
4.1 解释训练代码
在训练模型这部分代码中:
# 训练模型
for epoch in range(500):model.train() # 将模型设置为训练模式。这会启用一些特定于训练的行为,比如dropout。optimizer.zero_grad() # 清除优化器中累积的梯度。每次反向传播之前都需要清除梯度,否则梯度会累积。outputs = model(X)loss = criterion(outputs, Y) # 计算模型输出outputs和真实标签Y之间的损失。loss.backward() # 反向传播,计算损失相对于模型参数的梯度。optimizer.step() # 使用计算出的梯度更新模型参数。其中,optimizer.zero_grad() 用于清除优化器中累积的梯度。
那么,不清除梯度是否有别的用途?
是的,特别是在处理大模型和有限GPU内存时非常有用。
4.2 累加 or 分批
梯度累加的情况:
- 一个epoch被分成10个mini-batch。
- 每个mini-batch进行一次前向传播和反向传播,但不立即更新参数,而是累积梯度。
- 在处理完第10个mini-batch后,使用累积的梯度更新模型参数。
不分batch的情况:
- 直接使用整个数据集进行一次前向传播和反向传播。
- 完成整个epoch后,使用计算出的梯度更新模型参数。
这两种方法在理论上是等价的,但在实践中可能会有一些差异:
- 计算效率和内存使用:
- Mini-batch:每次只处理一部分数据(mini-batch),因此内存需求较小,并且可以利用现代计算架构(如GPU)的并行处理能力,提高计算效率。
- 不分batch:每次迭代处理整个训练集,这在数据集很大时可能会导致内存问题,并且每次迭代的计算成本非常高。此外,对于非常大的数据集,使用全量数据进行每次更新可能并不是最高效的方法。
- 收敛速度:
- Mini-batch:由于每次只使用一部分数据来估计梯度,可能会引入噪声,这种噪声有时可以帮助模型跳出局部最小值,提高算法的收敛速度和可能达到的全局最小值的概率。
- 不分batch:每次使用整个数据集精确计算梯度,收敛过程较为平稳,但可能容易陷入局部最小值。
- 泛化能力:
- 使用mini-batch可以增加模型的泛化能力,因为每次更新都引入了一定的噪声,相当于对模型进行了一定程度的正则化。相比之下,使用全数据集的方法可能会导致模型过于拟合训练数据。
5. 总结
本文介绍了TensorBoard的使用方法及其在TensorFlow和PyTorch中的应用,同时解释了训练周期(Epoch)、批量(Batch)和迭代(Iteration)等基本概念,并探讨了梯度累加的技术细节和实际应用。通过使用TensorBoard,我们能够有效地监控和分析模型训练过程中的各种指标,如损失和准确率等,这对于模型优化和调试非常有帮助。
我们还讨论了Epoch的重要性,它代表模型在整个数据集上训练一次的过程,以及如何通过调整Epoch的数量来控制模型的拟合程度。此外,Batch和Iteration的概念帮助我们理解数据是如何被分批处理的,以及每个批次如何影响模型学习的效率和效果。
最后,梯度累加的讨论揭示了在资源受限或处理大型数据集时优化模型训练的一种策略。通过累积小批量数据的梯度,然后统一更新模型参数,可以有效管理内存使用,同时可能帮助模型达到更好的训练效果。
这些技术和工具的掌握对于深度学习模型的开发和优化至关重要。

相关文章:
Vitis AI 基本认知(训练过程)
目录 1. 目的 2. TensorBoard 2.1 In TensorFlow 2.2.1 安装 TensorBoard 2.2.2 导入必要的库 2.2.3 初始化 2.2.4 记录数据 2.2.5 启动 TensorBoard 2.2.6 刷新间隔 2.2 In PyTorch 2.2.1 安装 setuptools 2.2.2 记录数据 2.2.3 查看 Tensorboard 3. 训练周期 E…...

《SQL 约束:保障数据完整性与准确性的关键防线》
在数据库管理的世界里,SQL 约束(Constraints)就像是守护数据城堡的卫士,确保数据的完整性、准确性和一致性。主键、外键和唯一约束是其中最为重要的几种约束类型,它们在数据库设计和数据操作中发挥着至关重要的作用。本…...

Temu半托管即将开通日韩站点,Temu半托管怎么上产品?
Temu是拼多多旗下的跨境电商平台,截至2024上半年,Temu的销售额达到了200亿美元左右。目前,Temu已进入了50多个国家和地区,是跨境卖家掘金海外市场的重要平台。 Temu半托管即将开通日韩站点 今年3月,Temu跟随速卖通正式…...

谷歌、火狐、Edge浏览器使用allWebPlugin中间件加载ActiveX控件
安装allWebPlugin中间件 1、请从下面地址下载allWebPlugin中间件产品 链接:百度网盘 请输入提取码百度网盘 请输入提取码百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百…...

Python利用openpyxl复制Excel文件且保留样式—另存为副本(附完整代码)
目录 专栏导读库的介绍库的安装前言结果预览目录结构完整代码总结专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系列文章专栏:请点击——>Python办公自动化专…...

ITL-Internet Technology Letters
文章目录 一、期刊简介二、征稿信息三、投稿须知四、咨询 一、期刊简介 Internet Technology Letters本期旨在涵盖所有用于提高物联网性能的新兴或现代学习算法。在此背景下,我们打算收集有关物联网学习进展的研究论文。强烈鼓励与机器学习、计算智能、概率学习、统…...

Mapreduce_wordcount自定义单词计数
自定义的wordcount 数据处理过程 加载jar包 查看后面的pom文件 以上为需要的jar包路径,将其导入至idea中 Map package com.hadoop;import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; im…...

安卓开发中的AppCompat框架使用详解
引言 在安卓开发中,为了确保应用能够在不同版本的安卓系统上保持一致的外观和行为,Google 推出了 AppCompat 支持库。AppCompat 支持库提供了一系列兼容性组件和行为,允许开发者使用较新的 UI 组件和功能,同时保持应用向后兼容旧…...

docker中挂桶什么意思
“挂桶”是指在 Docker 容器中挂载一个存储桶(通常指的是云存储桶,如 AWS S3、阿里云 OSS 等)或本地存储目录的操作。通过挂载,Docker 容器可以直接访问存储桶中的文件,就像访问本地文件系统一样。 具体来说ÿ…...
如何设置)
鸿蒙开发Location Kit(位置服务)如何设置
鸿蒙Location Kit 是一个强大的位置服务工具包,允许开发者在应用程序中集成精确的定位功能。Location Kit 提供了多种定位模式,支持室内和室外定位,并结合了GPS、Wi-Fi、蓝牙和基站等多种定位技术。 核心功能 精确定位:支持高精…...
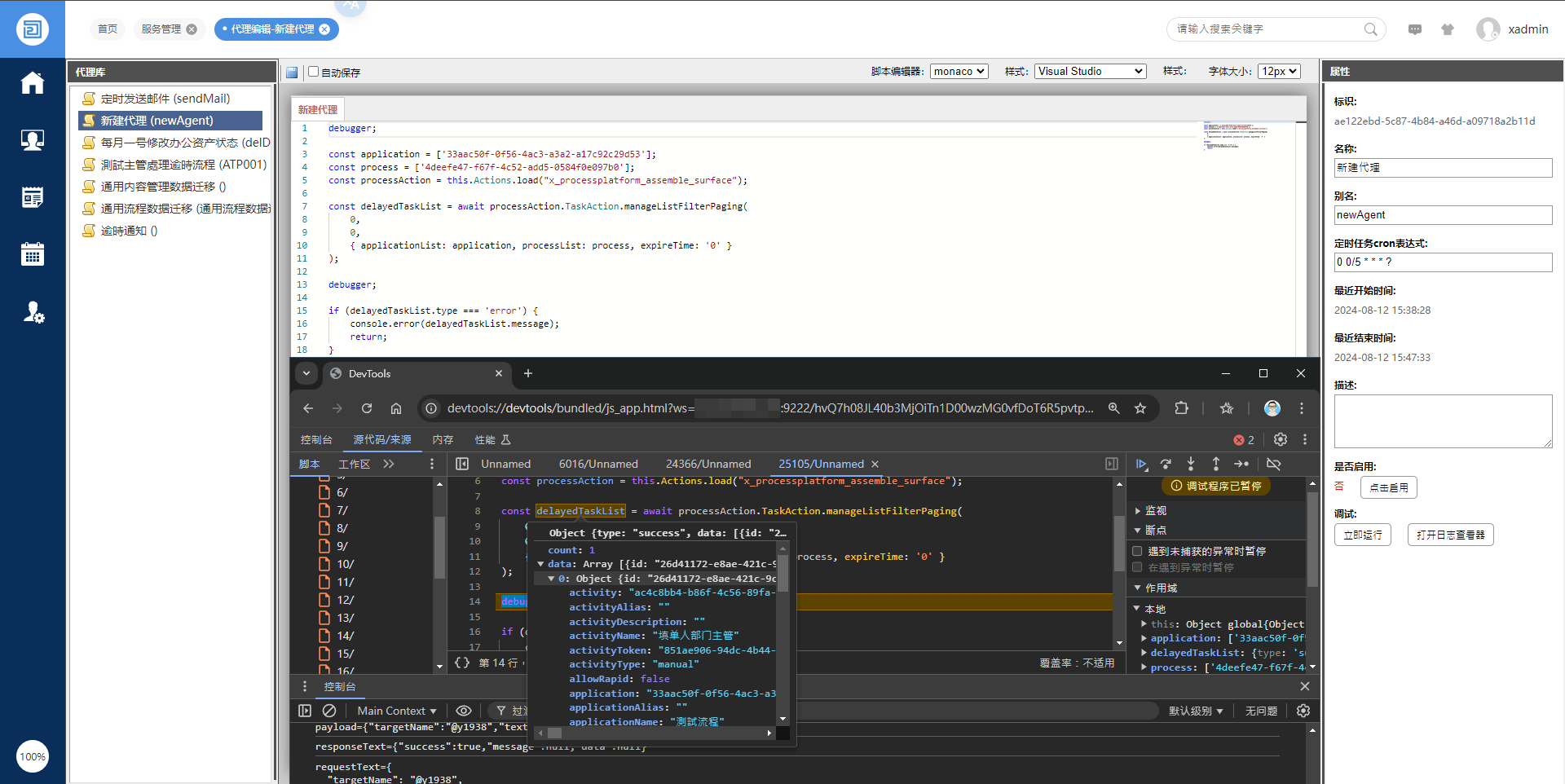
O2OA开发知识-后端代理/接口脚本编写也能像前端一样用上debugger
在o2oa开发平台中,后端代理或者接口的脚本编写也能像前端一样用上debugger,这是来自藕粉社区用户的宝贵技术支持。 感谢藕粉社区论坛用户提供的技术分享!tzengsh_BTstthttps://www.o2oa.net/forum/space-uid-4410.html 论坛地址:…...

树莓集团:引领数字影像技术培训的标杆
在当今数字化的时代,数字影像技术已经成为了各个领域中不可或缺的一部分。从电影、广告到游戏、虚拟现实,数字影像的应用无处不在。而在这个充满机遇与挑战的领域中,树莓集团凭借其卓越的实力,成为了引领数字影像技术培训的标杆。…...

为什么老实人普遍难拿高薪?这个答案让我醍醐灌顶!30岁的我决定开始改变
大家好,我是灵魂画师向阳 先问大家一个老生常谈的问题:老实人真的很难拿高薪吗?实话说,答案是一定的… 当然不是所有老实人都这样,但起码有一大部分人会面临这样的困境,原因也不外乎是以下几种࿱…...

react的pdf转图片格式上传到后端
这个东西做的我真的是头昏脑涨 主要需求是,upload上传pdf,pdf转图片格式展示,以图片格式上传到后端 封装了组件代码,父组件直接放就可以了 使用的插件pdfjs-dist,版本是 "pdfjs-dist": "2.5.207",node:14.13.0/18.17.0/16.14.2都可以你们要注意n…...

【STM32 FreeRTOS】任务通知
任务通知简介 任务通知:用来通知任务的,任务控制块中的结构体成员变量ulNotifiedValue(32位)就是这个通知值。 #if( configUSE_TASK_NOTIFICATIONS 1 )volatile uint32_t ulNotifiedValue;volatile uint8_t ucNotifyState;#endi…...

51单片机学习
定时器流水灯 #include <REGX52.H> #include "Timer0.h" #include "Key.h" #include <INTRINS.H> unsigned char KeyNum,LEDMode; void main() { P20xFE; Timer0Init(); while(1) { KeyNumKey(); if(KeyNum)…...

vue项目实现postcss-pxtoremvue大屏适配
1.安装依赖 npm install postcss-pxtorem autoprefixer postcss-loader --save-dev # 或者 yarn add postcss-pxtorem autoprefixer postcss-loader --dev2.配置 PostCSS 在项目根目录下创建一个 .postcssrc.js 文件,并添加以下配置: module.exports …...

如何打造爆款游戏?开发由你操刀,运维交由我托管,合作共赢创造更大成功
Linode提供的云计算服务都有哪里的哪些人在用,又都用来做什么?简而言之:世界各地!各行各业!!丰富多彩!!! 今天我们将关注云计算在游戏行业的应用。在这篇文章里…...

颈部按摩仪语音播报芯片方案,高品质语音IC,NV080D
想要利用碎片化的时间按摩肩颈,颈部按摩仪是很好的选择。然而,随着科技的不断进步,一些新的技术也开始被应用于颈部按摩仪中,以提升它们的功能和用户体验。 例如,NV080D语音播放芯片在颈部按摩仪上的应用,…...

Opencv模板匹配
使用OpenCV和C来识别彩色图片中的特定物体,如黑桃♠,通常涉及几个步骤:预处理图像、特征提取、对象检测等。下面是一个基本的示例代码,演示如何使用OpenCV的模板匹配方法来识别图片中的黑桃♠。 函数原型 void matchTemplate(Inp…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...
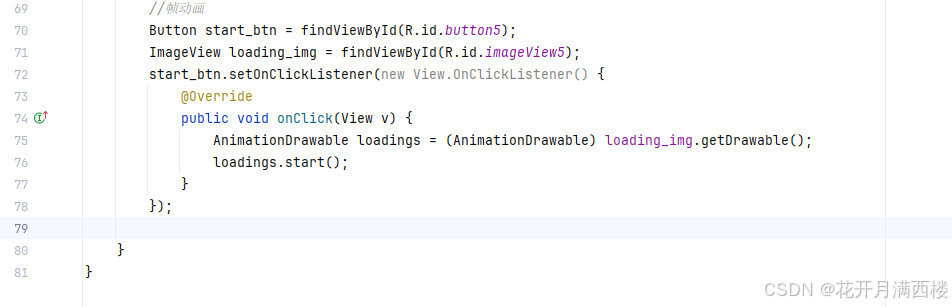
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...
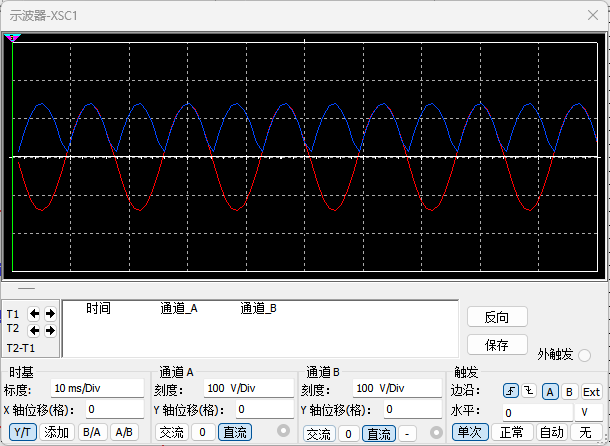
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...
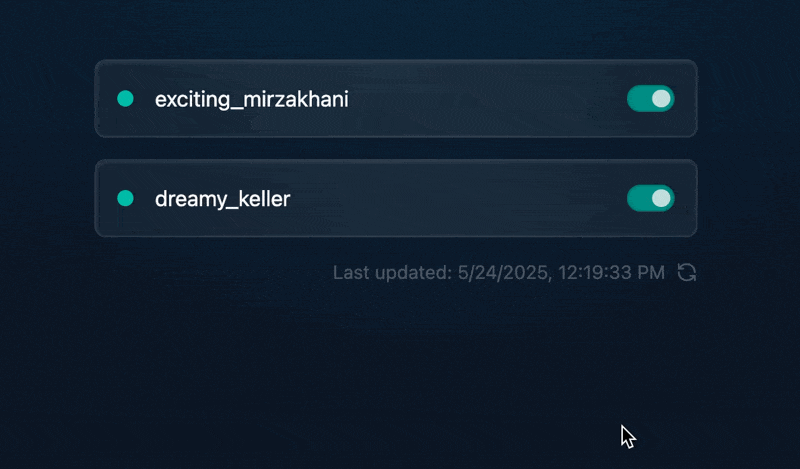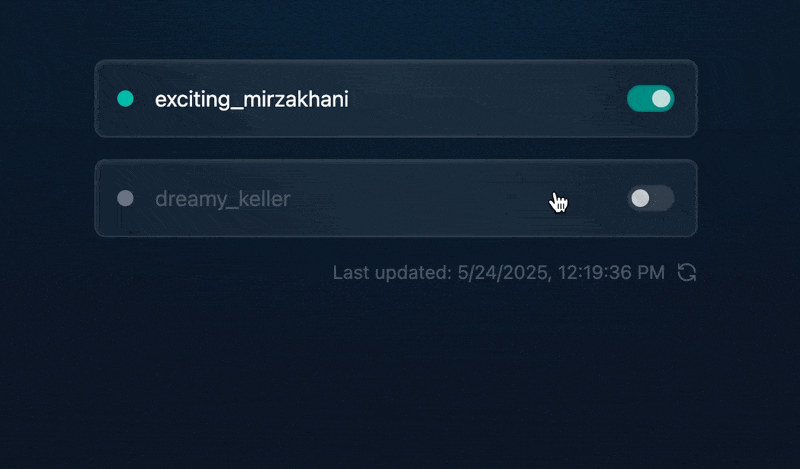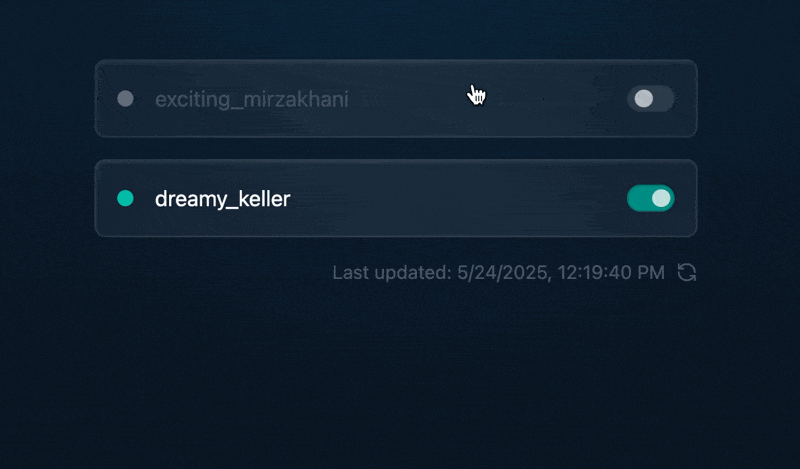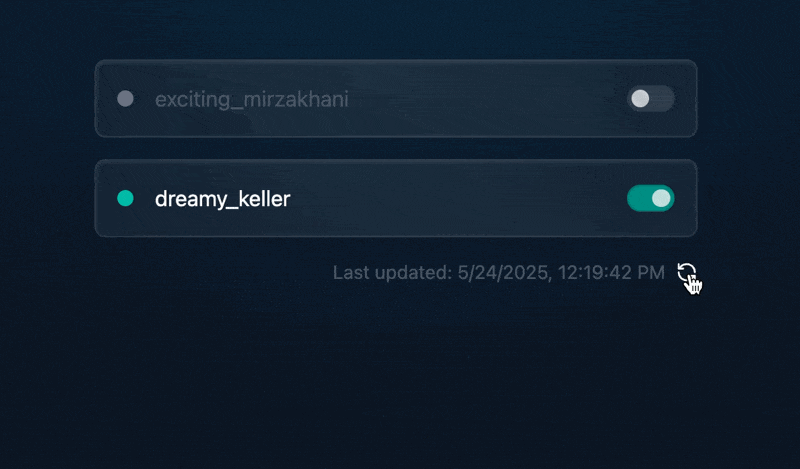
轻量级Docker管理工具Docker Switchboard
简介 什么是 Docker Switchboard ? Docker Switchboard 是一个轻量级的 Web 应用程序,用于管理 Docker 容器。它提供了一个干净、用户友好的界面来启动、停止和监控主机上运行的容器,使其成为本地开发、家庭实验室或小型服务器设置的理想选择…...