PyTorch 基础学习(5)- 神经网络
系列文章:
PyTorch 基础学习(1) - 快速入门
PyTorch 基础学习(2)- 张量 Tensors
PyTorch 基础学习(3) - 张量的数学操作
PyTorch 基础学习(4)- 张量的类型
PyTorch 基础学习(5)- 神经网络
介绍
PyTorch 提供了一套强大的工具来构建和训练神经网络。其中的核心组件之一是 torch.nn,它提供了模块和类以帮助您创建和定制神经网络。
参数和模块
torch.nn.Parameter
torch.nn.Parameter()是一种特殊的Variable,常用于模块参数。- 当
Parameter被赋值给模块的属性时,它会自动添加到模块的参数列表中,成为模型可学习的参数。 Variable与Parameter的区别:Parameter不能是 volatile,并且默认requires_grad=True,而Variable默认requires_grad=False。
torch.nn.Module
- 所有神经网络模块的基类。
- 您的模型应继承此类。
- 模块可以包含其他模块,形成树形结构。将子模块赋值为属性会自动注册它们。
示例
import torch.nn as nn
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))
模块方法
- add_module(name, module): 向当前模块添加子模块。
- children(): 返回当前模块的子模块迭代器。
- modules(): 返回网络中所有模块的迭代器,包括自身和所有子模块。
移动模块
- cpu(): 将模块参数和缓冲区移动到 CPU。
- cuda(device_id=None): 将模块参数和缓冲区移动到 GPU。
- double(): 将参数和缓冲区的数据类型转换为
double。 - float(): 将参数和缓冲区的数据类型转换为
float。 - half(): 将参数和缓冲区的数据类型转换为
half。
评估和训练模式
- eval(): 将模块设置为评估模式,影响诸如 Dropout 和 BatchNorm 等模块。
- train(mode=True): 将模块设置为训练模式。
保存和加载模型
- load_state_dict(state_dict): 从状态字典中加载参数和缓冲区。
- state_dict(): 返回包含模块状态的字典。
线性层
torch.nn.Linear
- 对输入数据进行线性变换:( y = Ax + b )。
示例
import torch.nn as nn
m = nn.Linear(20, 30)
卷积层
torch.nn.Conv2d
- 进行 2D 卷积操作。
示例
import torch.nn as nn
m = nn.Conv2d(16, 33, 3, stride=2)
池化层
torch.nn.MaxPool2d
- 进行 2D 最大池化操作。
示例
import torch.nn as nn
m = nn.MaxPool2d(3, stride=2)
torch.nn.AvgPool2d
- 进行 2D 平均池化操作。
示例
import torch.nn as nn
m = nn.AvgPool2d(3, stride=2)
激活函数
常用激活函数
- ReLU: 修正线性单元, R e L U ( x ) = m a x ( 0 , x ) ReLU(x)=max(0,x) ReLU(x)=max(0,x)
- Sigmoid: S i g m o i d ( x ) = 1 / 1 + e − x Sigmoid(x)=1/1 + e^{-x} Sigmoid(x)=1/1+e−x
- Tanh: 双曲正切函数, t a n h ( x ) tanh(x) tanh(x)
示例
import torch.nn as nn
m = nn.ReLU()
循环神经网络层
循环神经网络(RNN)是一类用于处理序列数据的神经网络。PyTorch 提供了多种循环层,包括 RNN、LSTM 和 GRU,用于构建复杂的序列模型。下面我们详细介绍这些循环层及其使用方法。
torch.nn.RNN
torch.nn.RNN 实现了多层 Elman RNN,适用于输入序列的处理。它通过循环连接来保持序列中每个时间步的信息。可以选择使用 tanh 或 relu 作为激活函数。
示例
import torch
import torch.nn as nn
from torch.autograd import Variable# 创建一个 RNN 层,输入维度为 10,隐状态维度为 20,使用两层堆叠
rnn = nn.RNN(input_size=10, hidden_size=20, num_layers=2)# 输入数据,形状为 (序列长度, 批量大小, 特征维度)
input = Variable(torch.randn(5, 3, 10))# 初始隐状态,形状为 (层数, 批量大小, 隐状态维度)
h0 = Variable(torch.randn(2, 3, 20))# 前向传播,计算输出和新的隐状态
output, hn = rnn(input, h0)# 输出是最后一层的输出,hn 是最后一个时间步的隐状态
torch.nn.LSTM
torch.nn.LSTM 实现了长短时记忆网络(LSTM),用于处理更复杂的序列模式,特别是长序列。LSTM 使用门控机制(包括输入门、遗忘门和输出门)来控制信息的流动,从而有效地捕捉序列中的长期依赖关系。
示例
import torch
import torch.nn as nn
from torch.autograd import Variable# 创建一个 LSTM 层,输入维度为 10,隐状态和细胞状态维度为 20,使用两层堆叠
lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2)# 输入数据,形状为 (序列长度, 批量大小, 特征维度)
input = Variable(torch.randn(5, 3, 10))# 初始隐状态和细胞状态,形状为 (层数, 批量大小, 隐状态维度)
h0 = Variable(torch.randn(2, 3, 20))
c0 = Variable(torch.randn(2, 3, 20))# 前向传播,计算输出、最后的隐状态和细胞状态
output, (hn, cn) = lstm(input, (h0, c0))# 输出是最后一层的输出,hn 和 cn 分别是最后一个时间步的隐状态和细胞状态
torch.nn.GRU
torch.nn.GRU 实现了门控循环单元(GRU)网络,是一种比 LSTM 更简单的结构,常用于处理序列数据。GRU 通过合并输入门和遗忘门,简化了门控机制,同时保持了捕捉长期依赖的能力。
示例
import torch
import torch.nn as nn
from torch.autograd import Variable# 创建一个 GRU 层,输入维度为 10,隐状态维度为 20,使用两层堆叠
gru = nn.GRU(input_size=10, hidden_size=20, num_layers=2)# 输入数据,形状为 (序列长度, 批量大小, 特征维度)
input = Variable(torch.randn(5, 3, 10))# 初始隐状态,形状为 (层数, 批量大小, 隐状态维度)
h0 = Variable(torch.randn(2, 3, 20))# 前向传播,计算输出和新的隐状态
output, hn = gru(input, h0)# 输出是最后一层的输出,hn 是最后一个时间步的隐状态
以上这些循环层可以用于处理序列数据,如时间序列预测、自然语言处理等。选择合适的循环层和参数设置可以帮助您构建出性能优异的序列模型。
Dropout 层
torch.nn.Dropout
- 随机将输入张量中的部分元素置零。
示例
import torch.nn as nn
m = nn.Dropout(p=0.5)
损失函数
常用损失函数
- L1Loss: 平均绝对误差损失。
- MSELoss: 均方误差损失。
- CrossEntropyLoss: 将 LogSoftMax 和 NLLLoss 集成在一个类中。
示例
import torch.nn as nn
criterion = nn.MSELoss()
工具
torch.nn.utils.clip_grad_norm
- 裁剪参数梯度的范数。
torch.nn.utils.rnn
- 用于处理变长序列的 RNN 的函数。
序列的打包和填充
- **pack_padded_sequence
应用实例:多项式回归
以下是一个使用 PyTorch 构建和训练循环神经网络(RNN)进行简单时间序列预测的完整示例。该脚本展示了如何使用 LSTM 层来处理序列数据,包括数据准备、模型定义、训练和评估。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from torch.autograd import Variable
from sklearn.preprocessing import MinMaxScaler# 生成示例数据:一个正弦波
# 设置随机种子以确保可重复性
np.random.seed(0)
torch.manual_seed(0)# 生成一个正弦波序列
def generate_data(seq_length=50, num_samples=1000):x = np.linspace(0, 100, num_samples)y = np.sin(x) + 0.1 * np.random.randn(num_samples) # 添加一些噪声return y# 数据预处理:将数据归一化到 [0, 1] 区间,并构造序列样本
def create_dataset(data, seq_length):scaler = MinMaxScaler(feature_range=(0, 1))data_normalized = scaler.fit_transform(data.reshape(-1, 1)).flatten()sequences = []targets = []for i in range(len(data_normalized) - seq_length):sequences.append(data_normalized[i:i+seq_length])targets.append(data_normalized[i+seq_length])return np.array(sequences), np.array(targets), scaler# 定义 LSTM 模型
class LSTMModel(nn.Module):def __init__(self, input_size=1, hidden_size=50, num_layers=1):super(LSTMModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, 1)def forward(self, x):# 初始化隐藏状态和细胞状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).requires_grad_()c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).requires_grad_()# 前向传播 LSTMout, _ = self.lstm(x, (h0.detach(), c0.detach()))# 从最后一个时间步提取输出out = self.fc(out[:, -1, :])return out# 参数设置
seq_length = 50
num_samples = 1000
batch_size = 16
num_epochs = 200
learning_rate = 0.01# 生成和处理数据
data = generate_data(seq_length, num_samples)
sequences, targets, scaler = create_dataset(data, seq_length)# 转换为 PyTorch 的张量格式
sequences = torch.from_numpy(sequences).float().unsqueeze(2) # (样本数, 序列长度, 特征数)
targets = torch.from_numpy(targets).float().unsqueeze(1) # (样本数, 1)# 构造数据集和数据加载器
dataset = torch.utils.data.TensorDataset(sequences, targets)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)# 创建模型、定义损失函数和优化器
model = LSTMModel(input_size=1, hidden_size=50, num_layers=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(num_epochs):for batch_seqs, batch_targets in dataloader:# 前向传播outputs = model(batch_seqs)loss = criterion(outputs, batch_targets)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 20 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 评估模型
model.eval()
with torch.no_grad():# 使用训练数据进行预测train_pred = model(sequences).detach().numpy()train_pred_rescaled = scaler.inverse_transform(train_pred)# 原始数据逆归一化targets_rescaled = scaler.inverse_transform(targets.numpy())# 绘制结果
plt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
plt.plot(range(seq_length, seq_length + len(train_pred_rescaled)), train_pred_rescaled, label='LSTM Prediction')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
输出结果:

代码说明
-
生成数据:
- 生成一个正弦波,并添加噪声以模拟真实数据。
- 使用
np.linspace创建一个线性间隔的数组来表示时间。
-
数据预处理:
- 使用
MinMaxScaler将数据归一化到 [0, 1] 区间,以帮助模型更快地收敛。 - 将数据转换为固定长度的序列样本,每个样本的长度为
seq_length。
- 使用
-
LSTM 模型定义:
- 定义
LSTMModel类,继承自nn.Module。 - 使用 LSTM 层和全连接层来实现序列到序列的映射。
- 定义
-
训练过程:
- 使用 MSELoss 作为损失函数,Adam 作为优化器。
- 在每个 epoch 内,迭代数据加载器进行批次训练,并更新模型参数。
-
评估和可视化:
- 在训练结束后,用训练数据进行预测,并将结果与原始数据对比。
- 使用
matplotlib绘制原始数据和预测结果。
该示例展示了如何使用 PyTorch 实现基本的时间序列预测任务,您可以根据需要对数据和模型进行调整以适应不同的应用场景,如:股票预测。
相关文章:
PyTorch 基础学习(5)- 神经网络
系列文章: PyTorch 基础学习(1) - 快速入门 PyTorch 基础学习(2)- 张量 Tensors PyTorch 基础学习(3) - 张量的数学操作 PyTorch 基础学习(4)- 张量的类型 PyTorch 基础学…...

CI/CD 自动化:最大限度地提高极狐GitLab 群组的“部署冻结”影响
极狐GitLab 是 GitLab 在中国的发行版,专门面向中国程序员和企业提供企业级一体化 DevOps 平台,用来帮助用户实现需求管理、源代码托管、CI/CD、安全合规,而且所有的操作都是在一个平台上进行,省事省心省钱。可以一键安装极狐GitL…...

单元训练10:定时器实现秒表功能-数组方式
蓝桥杯 小蜜蜂 单元训练10:定时器实现秒表功能-数组方式 /** Description:* Author: fdzhang* Email: zfdcqq.com* Date: 2024-08-15 21:58:53* LastEditTime: 2024-08-16 19:07:27* LastEditors: fdzhang*/#include "stc15f2k60s2.h"#define LED(x) …...
国外项目管理软件最佳实践:选型与应用
国内外主流的10款国外项目管理软件对比:PingCode、Worktile、Asana、Trello、Monday.com、ClickUp、Wrike、ProofHub、Zoho Projects、Hive。 在寻找适合的国外项目管理软件时,你是否感到不知从何选择?市场上琳琅满目的选项往往令人眼花缭乱&…...

Angular组件概念
Angular 是一个由 Google 维护的开源前端框架,用于构建单页面应用(SPA)和移动Web应用。Angular 应用由多个组件(Components)组成,这些组件是 Angular 应用构建块的基本单位。 1. Angular 组件的基本概念 …...

嵌入式人工智能ESP32(4-PWM呼吸灯)
1、PWM基本原理 PWM(Pulse-width modulation)是脉冲宽度调制的缩写。脉冲宽度调制是一种模拟信号电平数字编码方法。脉冲宽度调制PWM是通过将有效的电信号分散成离散形式从而来降低电信号所传递的平均功率的一种方式。所以根据面积等效法则,…...

继承 (上)【C++】
文章目录 继承的定义继承的语法继承权限和继承到子类后父类成员的访问限定符的变化继承到子类后父类成员的访问限定符的变化 子类继承到了父类的什么?继承中的作用域子类和父类之间的赋值转换子类对象可以直接赋值给父类对象,但是父类对象不能直接赋值给…...

WPF打印控件内容
当我们想打印控件内容时,如一个Grid中的内容,可以用WPF中PrintDialog类的PrintVisual()方法来实现 界面如下: XAML代码如下 <Grid><Grid.ColumnDefinitions><ColumnDefinition/><ColumnDefinition Width"300"…...

[C++][opencv]基于opencv实现photoshop算法图像剪切
【测试环境】 vs2019 opencv4.8.0 【效果演示】 【核心实现代码】 //图像剪切 //参数:src为源图像, dst为结果图像, rect为剪切区域 //返回值:返回0表示成功,否则返回错误代码 int imageCrop(InputArray src, OutputArray dst,…...

四十、大数据技术之Kafka3.x(3)
🌻🌻 目录 一、Kafka Broker1.1 Kafka Broker工作流程1.1.1 Zookeeper 存储的Kafka信息1.1.2 Kafka Broker 总体工作流程1.1.3 Broker 重要参数 1.2 生产经验——节点服役和退役1.2.1 服役新节点1.2.2 退役旧节点 1.3 Kafka 副本1.3.1 副本基本信息1.3.2…...

redis——基本命令
什么是Reids(REmote Dictionary Server) Redis是现在主流的数据库之一,是一个使用ANSI C编写的开源、包含多种数据结构、支持网络的、基于内存、可选持久性的键值对存储数据。 特性 1.速度快 :Redis的数据全部存储瑜内存中。 …...

pytorch实现单层线性回归模型
文章目录 简述代码重构要点 数学模型、运行结果数据构建与分批模型封装运行测试 简述 python使用 数值微分法 求梯度,实现单层线性回归-CSDN博客 python使用 计算图(forward与backward) 求梯度,实现单层线性回归-CSDN博客 数值微分…...

智能小家电能否利用亚马逊VC搭上跨境快车?——WAYLI威利跨境助力商家
智能小家电行业在全球化背景下,正迎来前所未有的发展机遇。亚马逊为品牌商和制造商提供的一站式服务平台,为智能小家电企业提供了搭乘跨境快车、拓展国际市场的绝佳机会。 首先,亚马逊VC平台能够帮助智能小家电企业简化与亚马逊的合作流程&am…...
顺丰科技25届秋季校园招聘常见问题答疑及校招网申测评笔试题型分析SHL题库Verify测评
Q:顺丰科技2025届校园招聘面向对象是? A:2025届应届毕业生,毕业时间段为2024年10月1日至2025年9月30日(不满足以上毕业时间的同学可以关注顺丰科技社会招聘或实习生招聘)。 Q:我可以投递几个岗…...

深入理解 Kibana 配置文件:一份详尽的指南
Kibana 是一个强大的数据可视化平台,它允许用户通过 Elasticsearch 轻松地探索和分析数据。Kibana 的配置文件 kibana.yml 是定制和优化 Kibana 行为的关键。在这篇博客中,我们将深入探讨 kibana.yml 文件中的各个配置项,并提供示例说明。 服…...

算法的学习笔记—链表中倒数第 K 个结点(牛客JZ22)
😀前言 在编程过程中,链表是一种常见的数据结构,它能够高效地进行插入和删除操作。然而,遍历链表并找到特定节点是一个典型的挑战,尤其是当我们需要找到链表中倒数第 K 个节点时。本文将详细介绍如何使用双指针技术来解…...
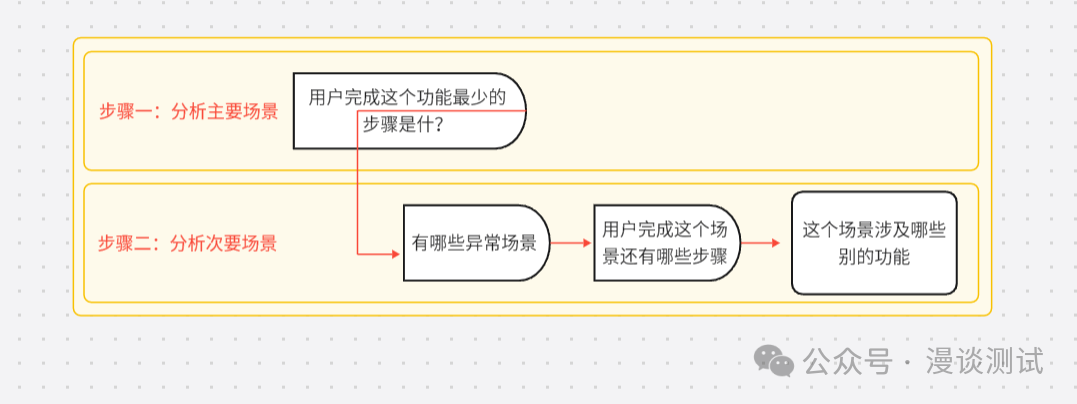
聊聊场景及场景测试
在我们进行测试过程中,有一种黑盒测试叫场景测试,我们完全是从用户的角度去理解系统,从而可以挖掘用户的隐含需求。 场景是指用户会使用这个系统来完成预定目标的所有情况的集合。 场景本身也代表了用户的需求,所以我们可以认为…...

Spring Web MVC入门(中)
1. 请求 访问不同的路径, 就是发送不同的请求. 在发送请求时, 可能会带⼀些参数, 所以学习Spring的请求, 主要 是学习如何传递参数到后端以及后端如何接收. 传递参数, 咱们主要是使⽤浏览器和Postman来模拟; 1.1 传递单个参数 接收单个参数,在Spring MV…...

Django后端架构开发:后台管理与会话技术详解
🌟 Django后端架构开发:后台管理与会话技术详解 🔹 后台管理:自定义模型类 Django的后台管理系统提供了强大的模型管理功能,你可以通过自定义模型类来控制模型在后台管理界面的显示和操作。自定义模型类通过继承admin…...
)
挑战Infiniband, 爆改Ethernet(2)
挑战Infiniband, 爆改Ethernet之物理层 前面说过UE为了挑战Infiniband在AI集群和HPC领域的优势地位,计划爆改以太网技术,以适应AI和HPC集群对高性能、可扩展网络的需求。正如UE联盟关于愿景的说明中宣称的:”提供一个完整的架构,通…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...