MySQL慢查询的查找语法
一、引言
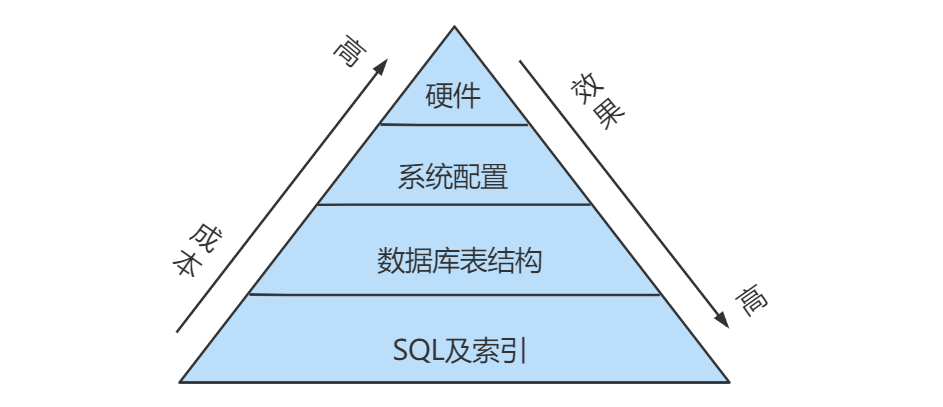
数据库查询快慢是影响项目性能的一大因素,对于数据库,我们除了要优化SQL,更重要的是得先找到需要优化的SQL语句。
性能优化的思路
- 首先需要使用慢查询功能,去获取所有查询时间比较长的SQL语句
- 其次使用explain命令去查询由问题的SQL的执行计划
- 最后可以使用show profile[s] 查看由问题的SQL的性能使用情况
- 优化SQL语句
二、慢查询分析
数据库查询快慢是影响项目性能的一大因素,对于数据库,我们除了要优化SQL,更重要的是得先找到需要优化的SQL语句。
2.1、SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
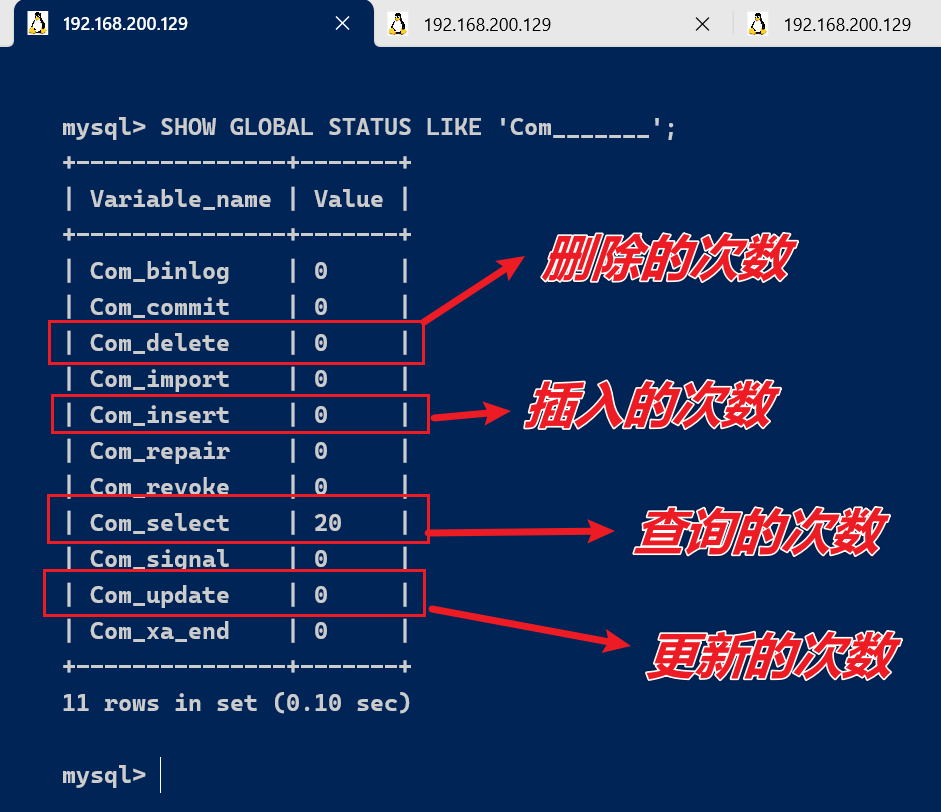
我们可以在当前数据库再执行几次查询操作,然后再次查看执行频次,看看 Com_select 参数会不会变化。
SHOW GLOBAL STATUS LIKE 'Com_______';
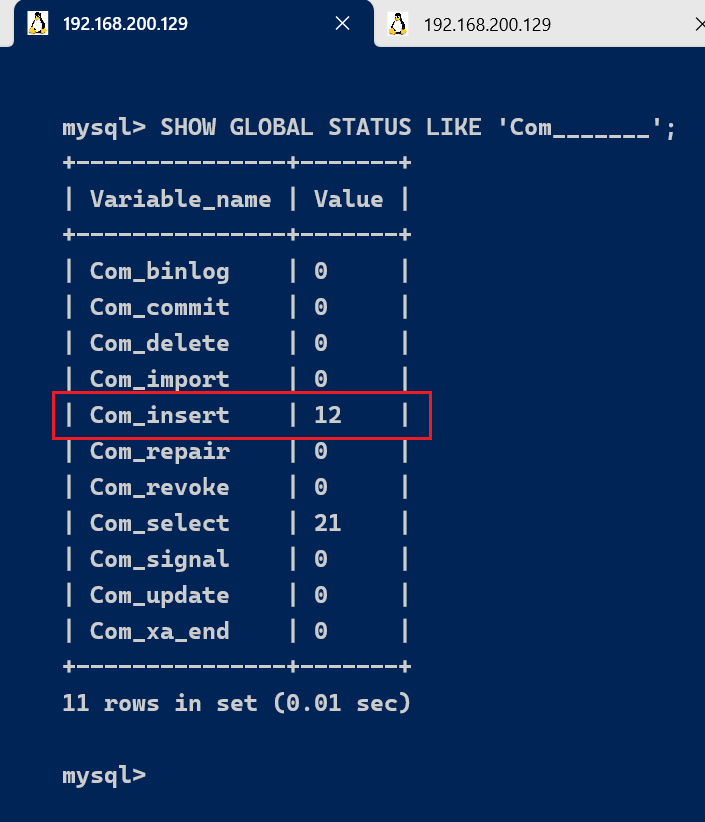
通过上述指令,我们可以查看到当前数据库到底是以查询为主,还是以增删改为主,从而为数据库优化提供参考依据。 如果是以增删改为主,我们可以考虑不对其进行索引的优化。 如果是以查询为主,那么就要考虑对数据库的索引进行优化了。
那么通过查询SQL的执行频次,我们就能够知道当前数据库到底是增删改为主,还是查询为主。 那假如说是以查询为主,我们又该如何定位针对于那些查询语句进行优化呢?
2.2、查看 SQL 执行成本:SHOW PROFILE
show profiles 是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优测量,show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。
通过 have_profiling 参数,能够看到当前MySQL是否支持profile:
select @@have_profiling;
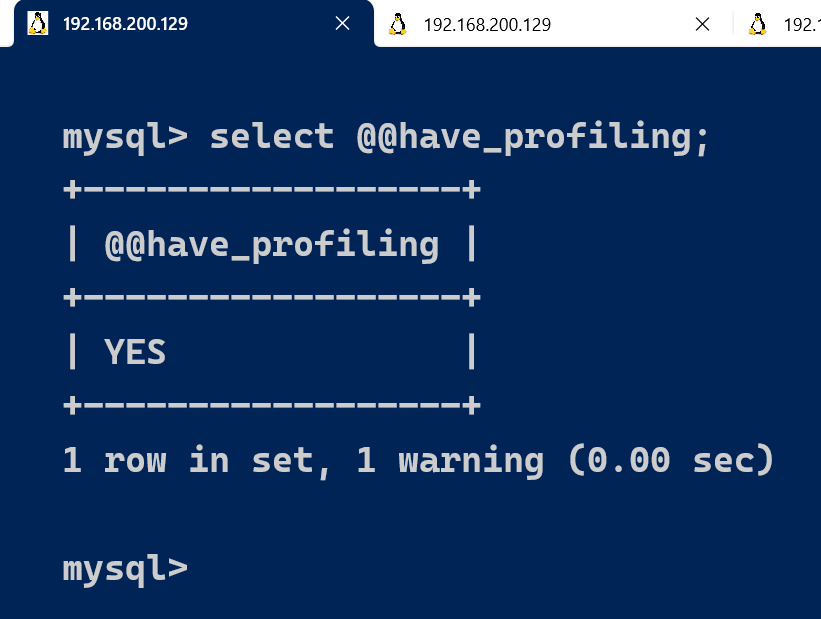
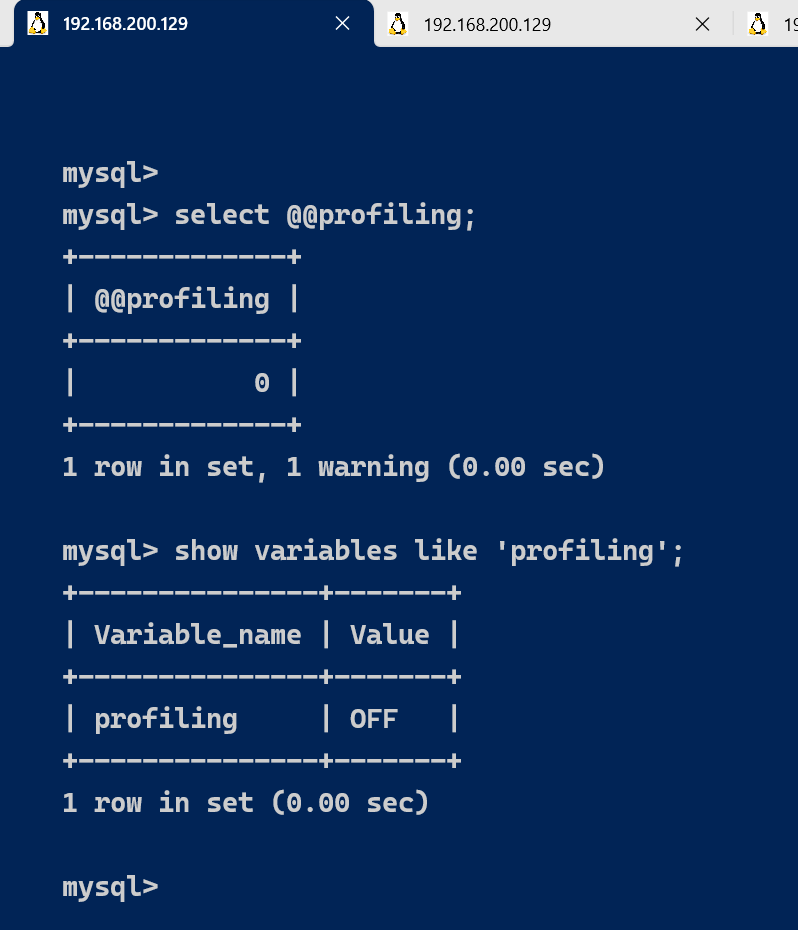
默认profiling是关闭的,可以通过set语句在Session级别开启profiling:
select @@profiling;
或者
show variables like 'profiling';
set profiling=1;
或者:
set profiling = 'ON';
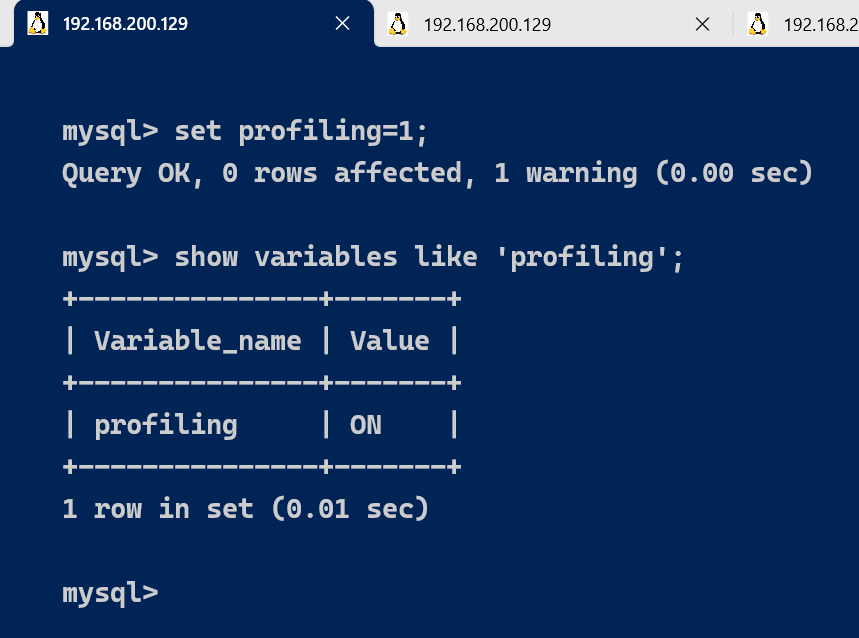
通过profile,我们能够更清楚地了解SQL执行的过程。
首先,我们可以执行一系列的操作,如下所示:
show databases;
select * from tb_seller;
select count(*) from tb_seller;
select count(0) from tb_sku;
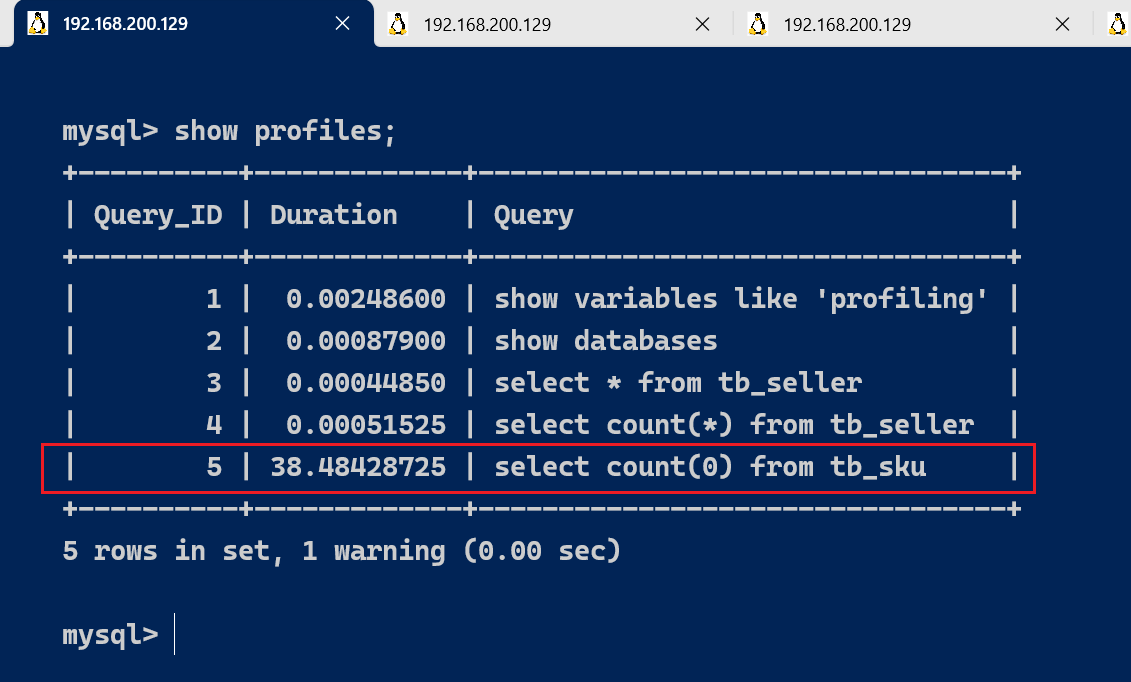
执行完上述命令之后,执行show profiles 指令, 来查看SQL语句执行的耗时:
show profiles;
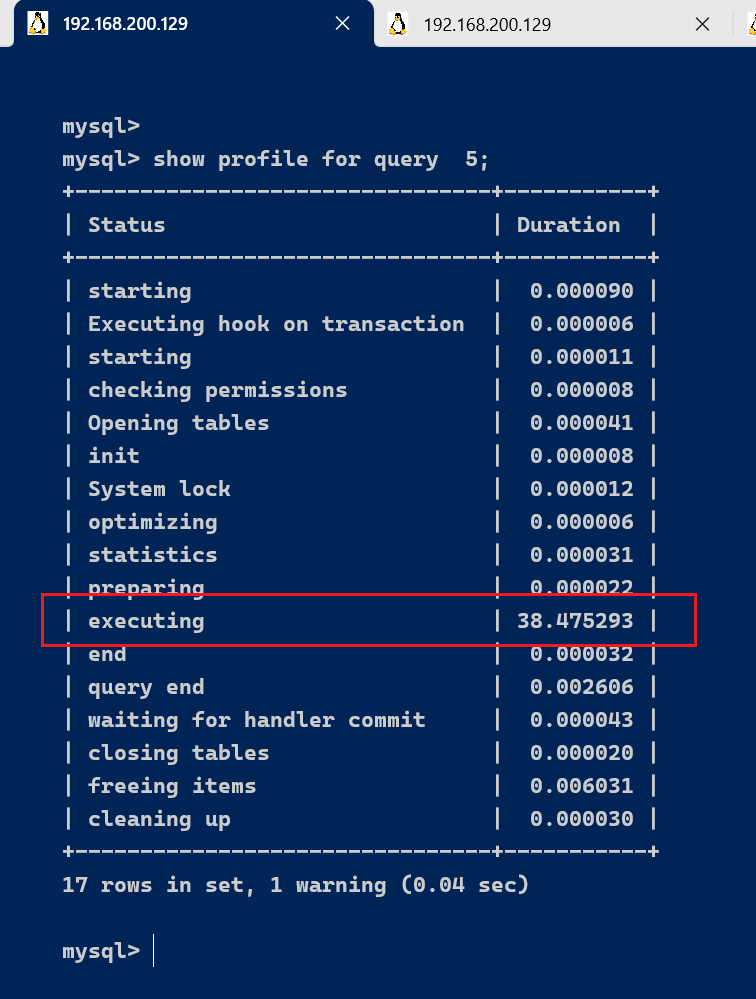
通过show profile for query query_id 语句可以查看到该SQL执行过程中每个线程的状态和消耗的时间:
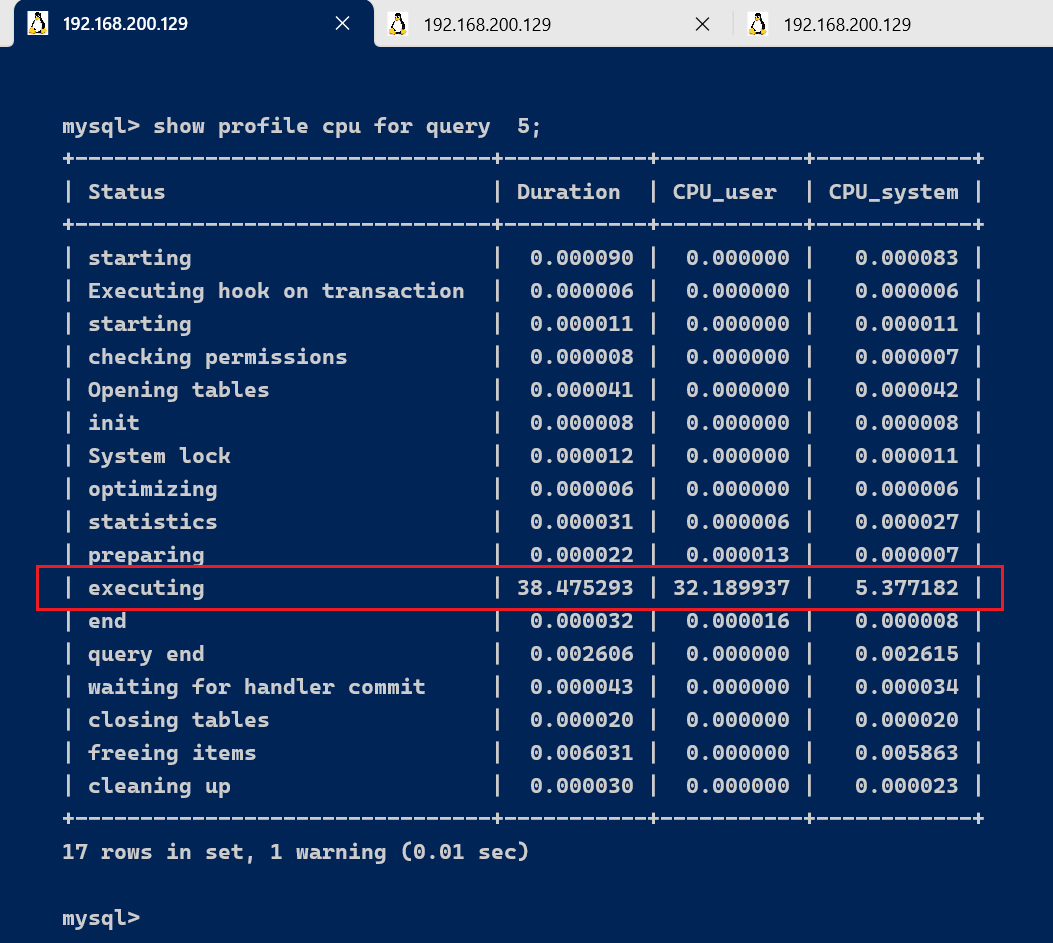
show profile for query 5;
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io 、context switch、page faults
等明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :
show profile cpu for query 5;
show profile的常用查询参数:
- ① ALL:显示所有的开销信息。
- ② BLOCK IO:显示块IO开销。
- ③ CONTEXT SWITCHES:上下文切换开销。
- ④ CPU:显示CPU开销信息。
- ⑤ IPC:显示发送和接收开销信息。
- ⑥ MEMORY:显示内存开销信息。
- ⑦ PAGE FAULTS:显示页面错误开销信息。
- ⑧ SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息。
- ⑨ SWAPS:显示交换次数开销信息。
2.3、定位执行慢的 SQL:慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志。long_query_time 默认为 10 秒,最小为 0, 精度可以到微秒。
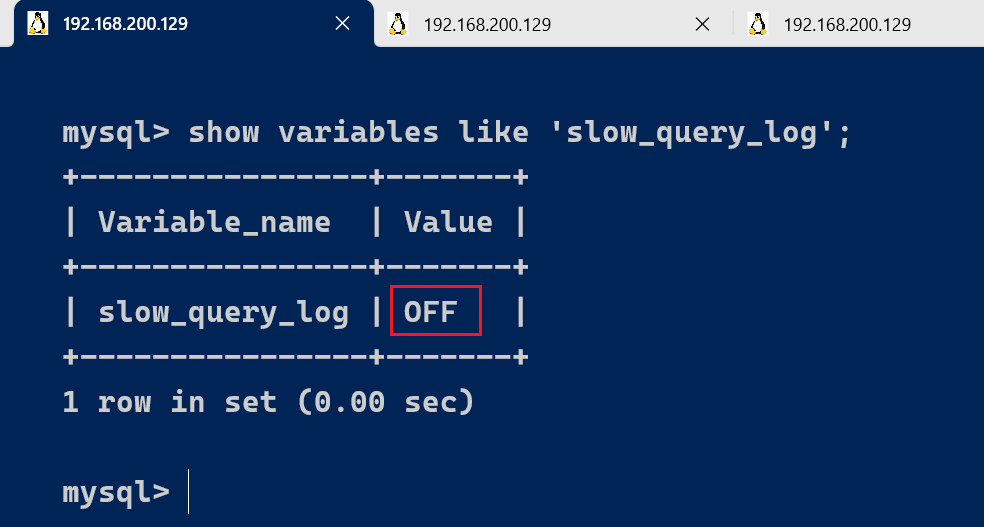
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。
show variables like 'slow_query_log';
2.3.1 开启慢查询日志
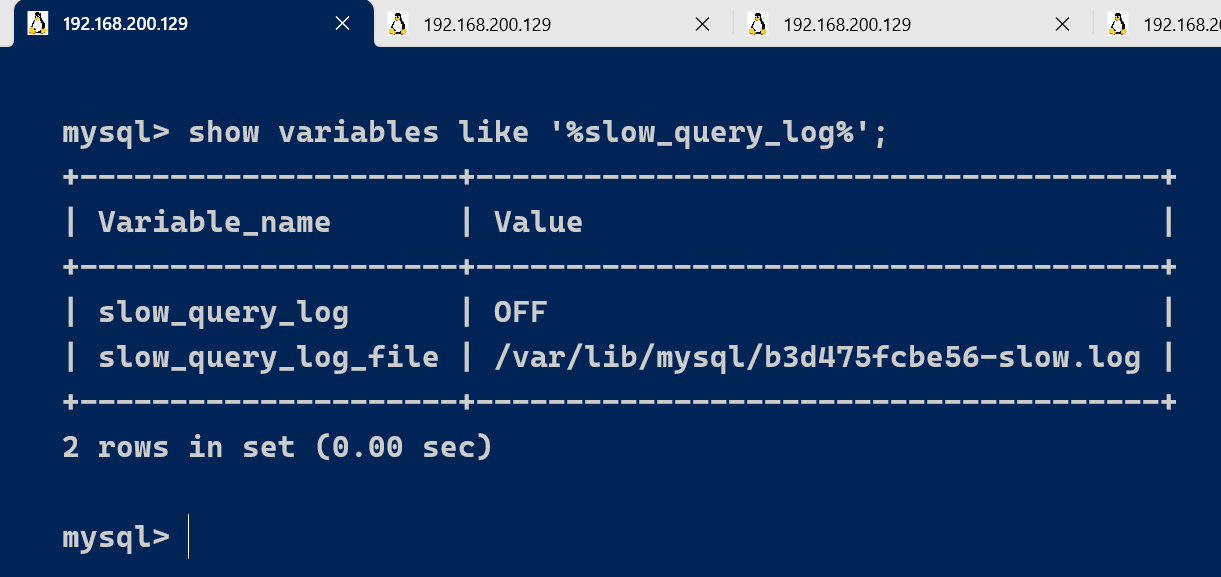
查看下慢查询日志是否开启,以及慢查询日志文件的位置:
show variables like '%slow_query_log%';
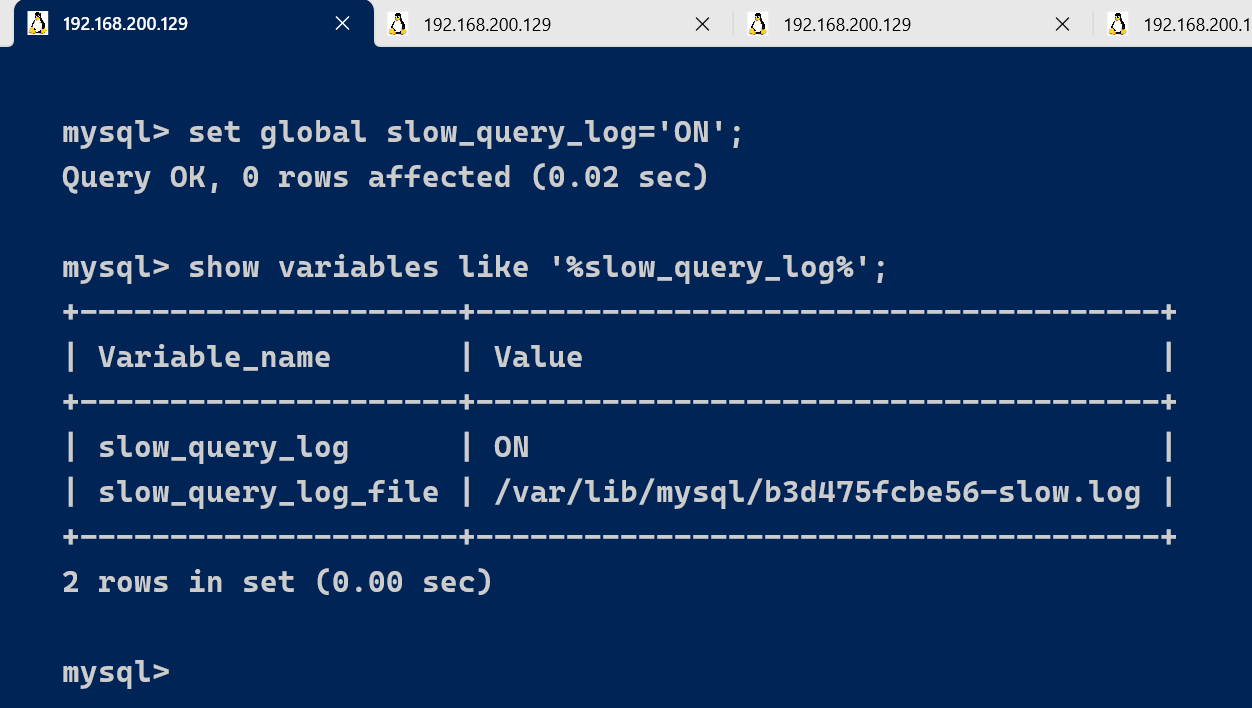
set global slow_query_log='ON';
show variables like '%slow_query_log%';
2.3.2、修改long_query_time阈值
show variables like '%long_query_time%';
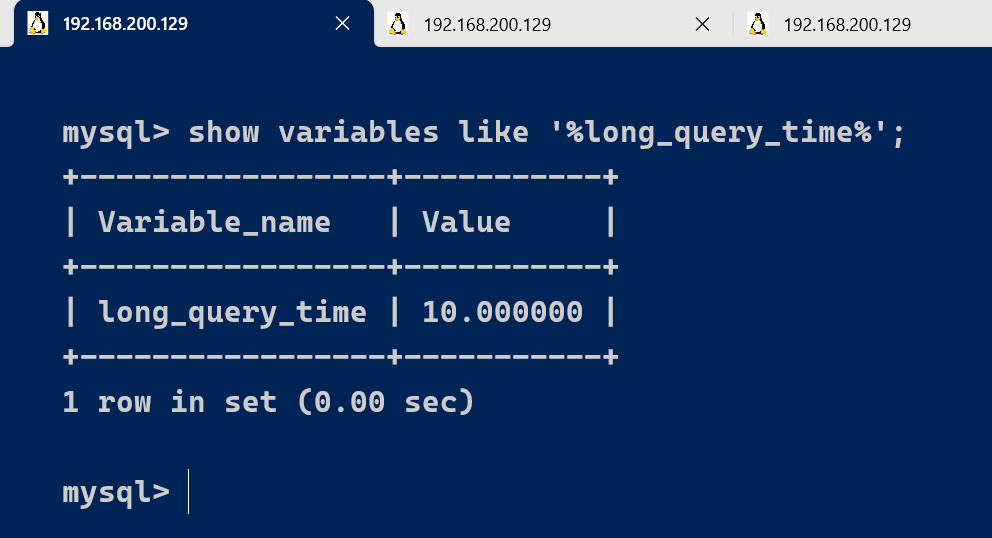
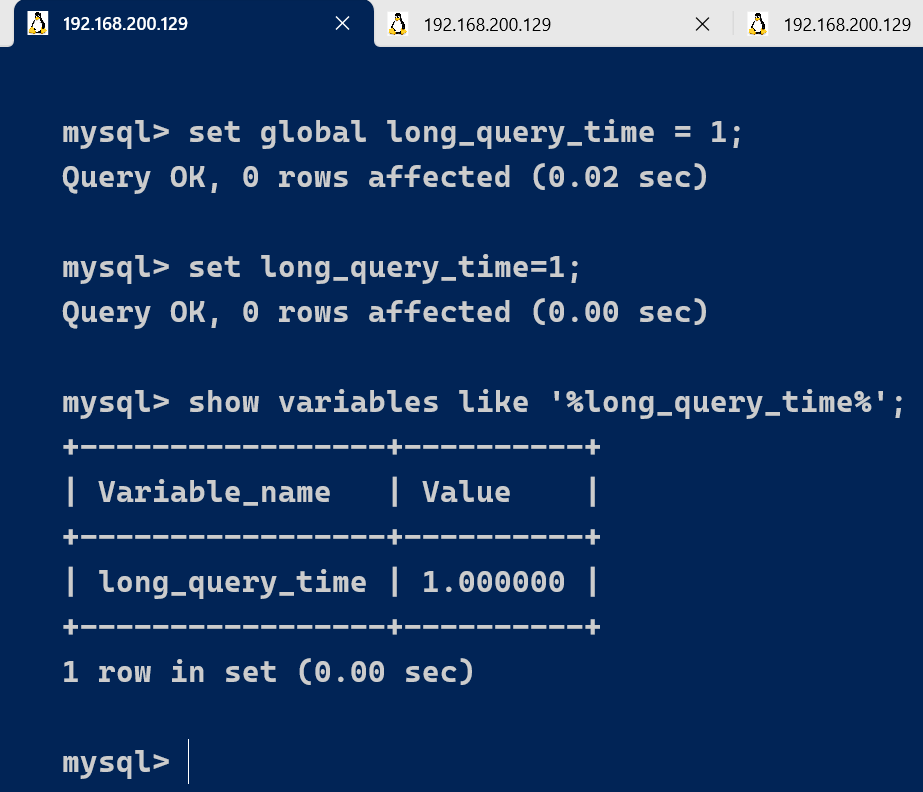
这里如果我们想把时间缩短,比如设置为 1 秒,可以这样设置:
- 测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并执行下述语句
set global long_query_time = 1;
set long_query_time=1;
show variables like '%long_query_time%';
2.3.3、开启慢查询日志(永久)
我们上述的的设置的开启慢查询的方式属于临时的,如果重启MySQL的话会失效。
如果要永久开启慢查询日志,需要在MySQL的配置文(/etc/mysql/my.cnf)中配置如下信息,我们为了不影响当前的测试环境,我们重新拉一台MySQl服务器作为演示:
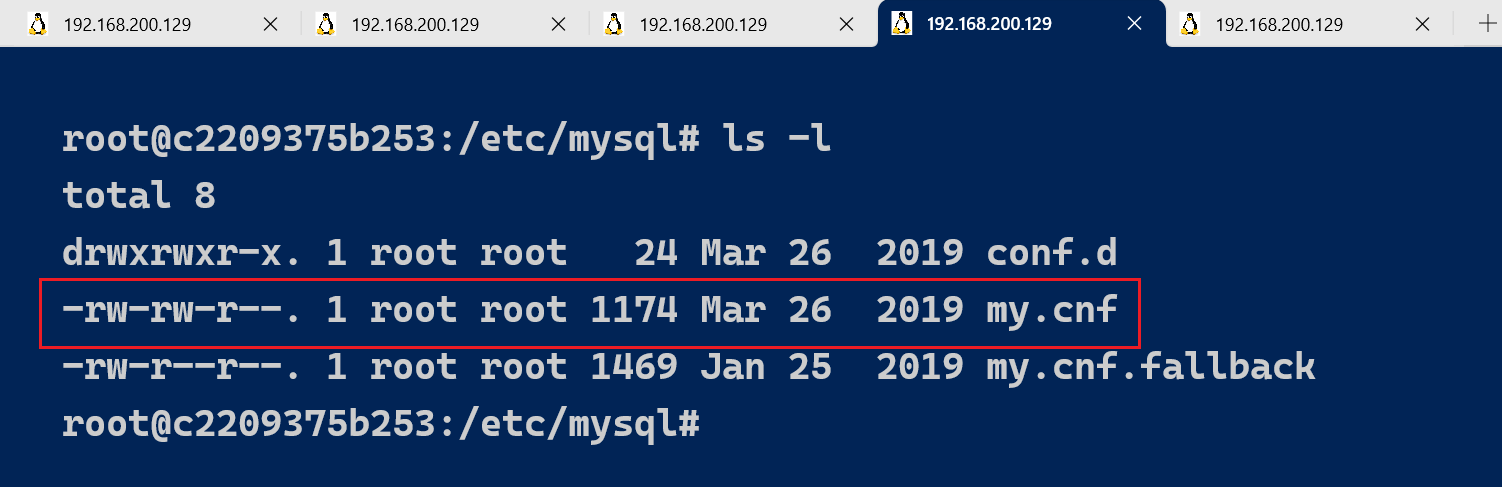
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2

show variables like '%slow_query_log%';
show variables like '%long_query_time%';
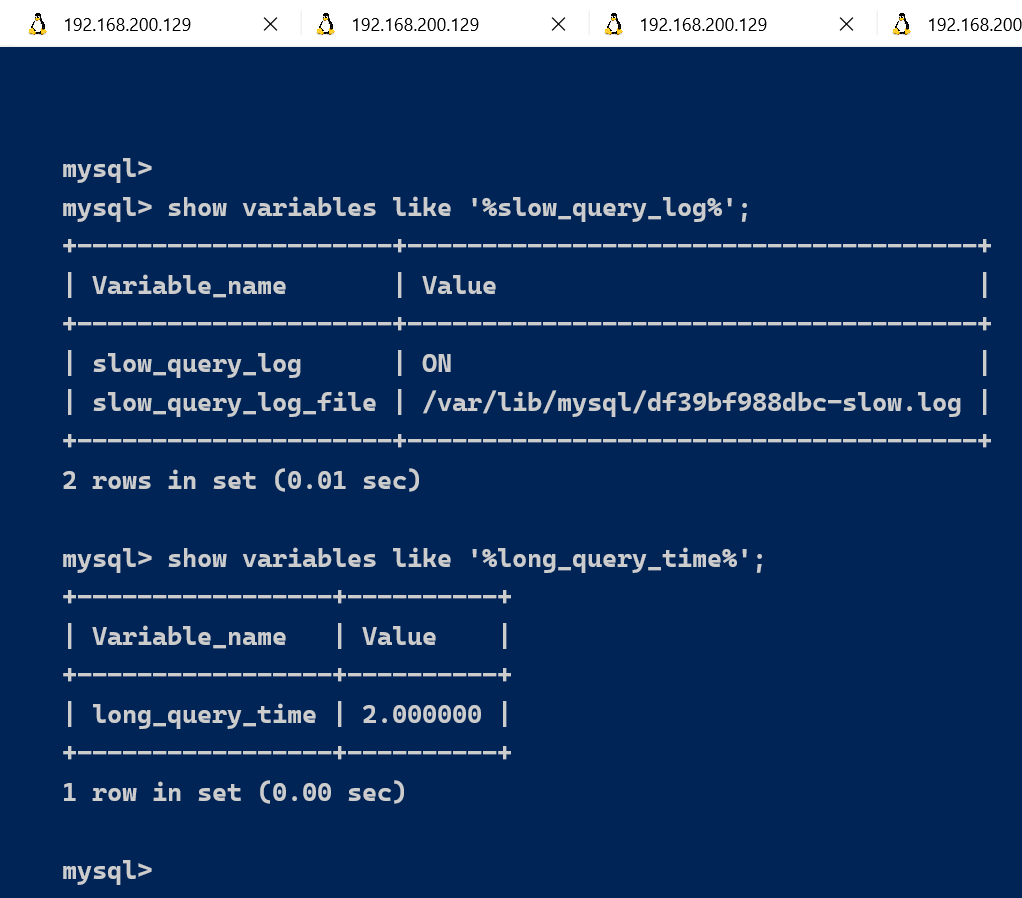
2.3.4、案例的演示
select * from tb_sku where id = '100000030074'\G
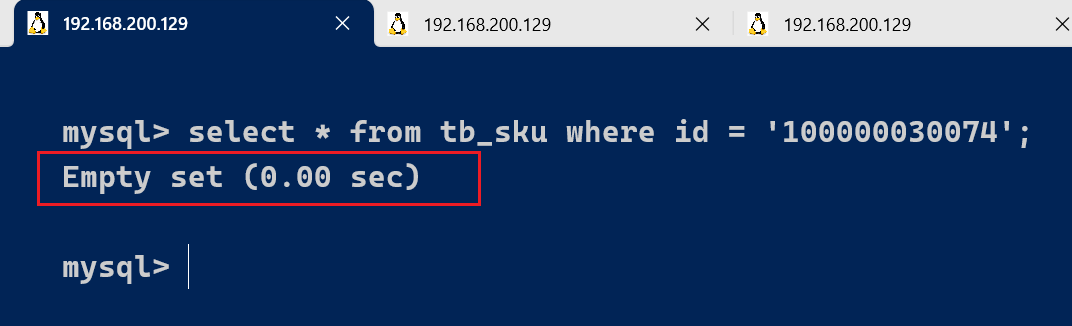
由于该语句执行时间很短,为0s , 所以不会记录在慢查询日志中。
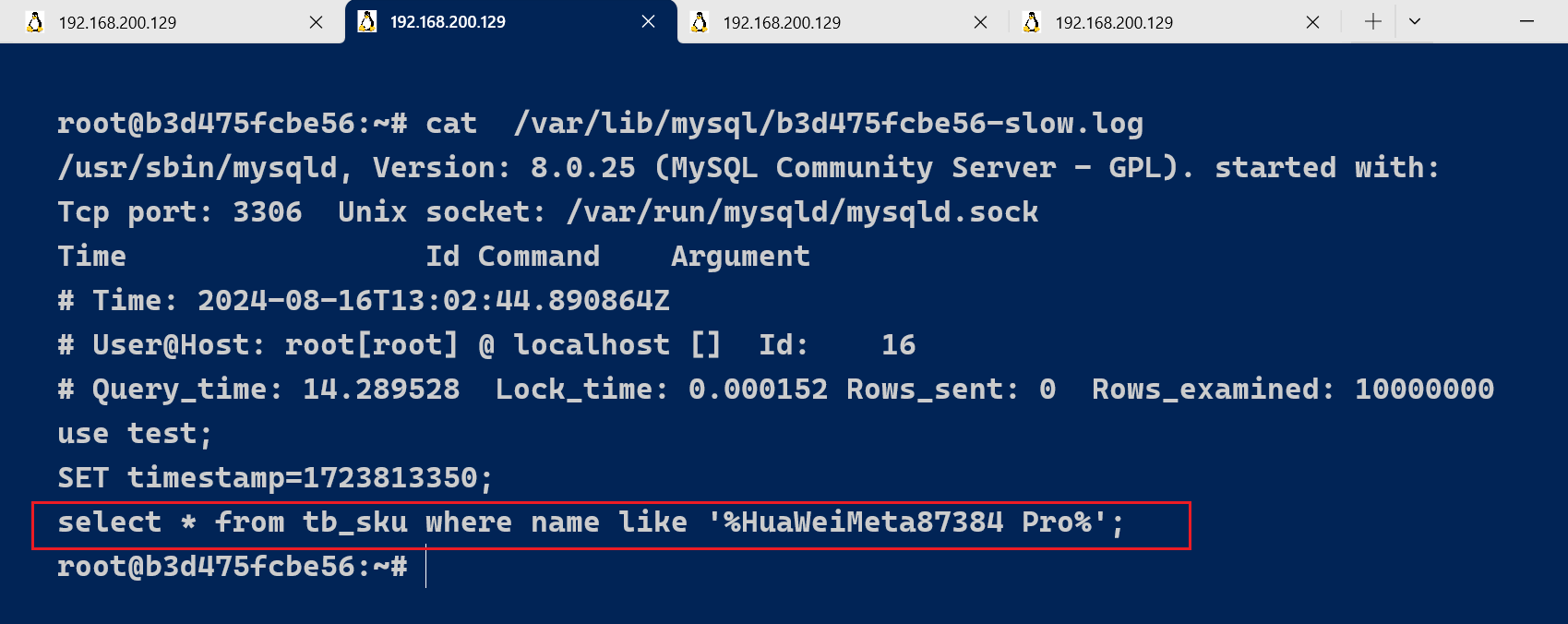
select * from tb_sku where name like '%HuaWei手机Meta87384 Pro%';
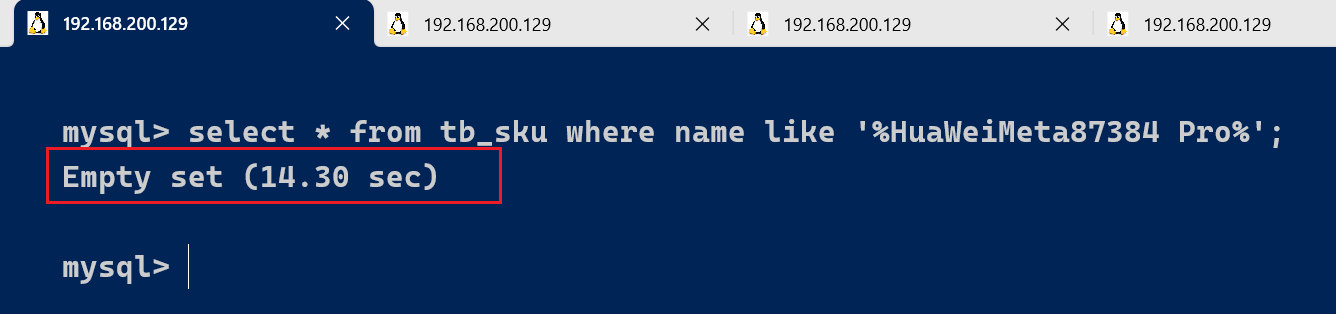
该SQL语句 , 执行时长为 14.30s ,超过10s , 所以会记录在慢查询日志文件中。
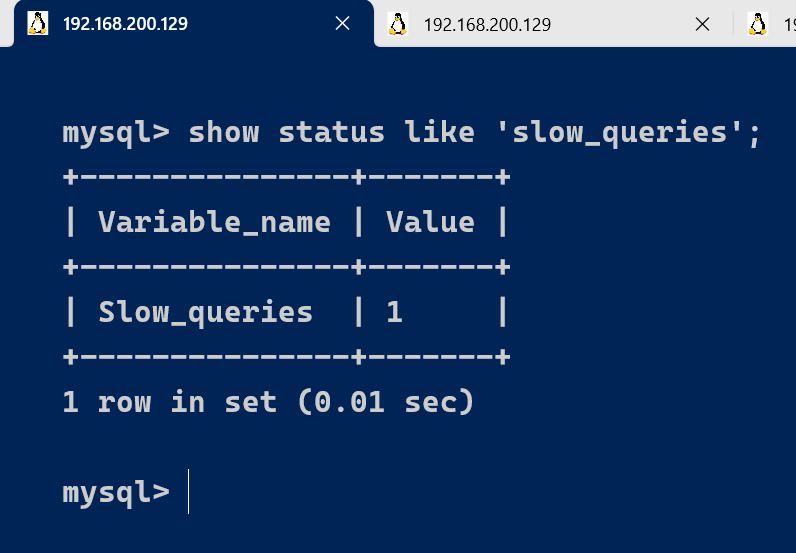
查询当前系统中有多少条慢查询记录:
show status like 'slow_queries';
2.3.5、看慢查询日志文件
2.3.5.1、直接通过cat
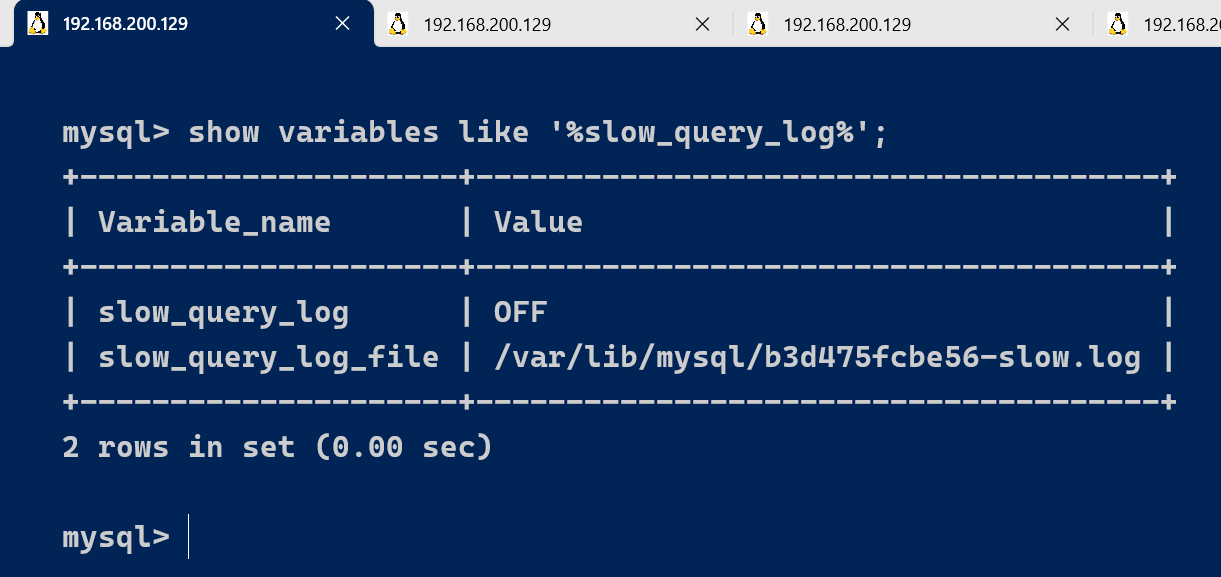
cat /var/lib/mysql/b3d475fcbe56-slow.log
2.3.5.2、慢查询日志分析工具:mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow 。
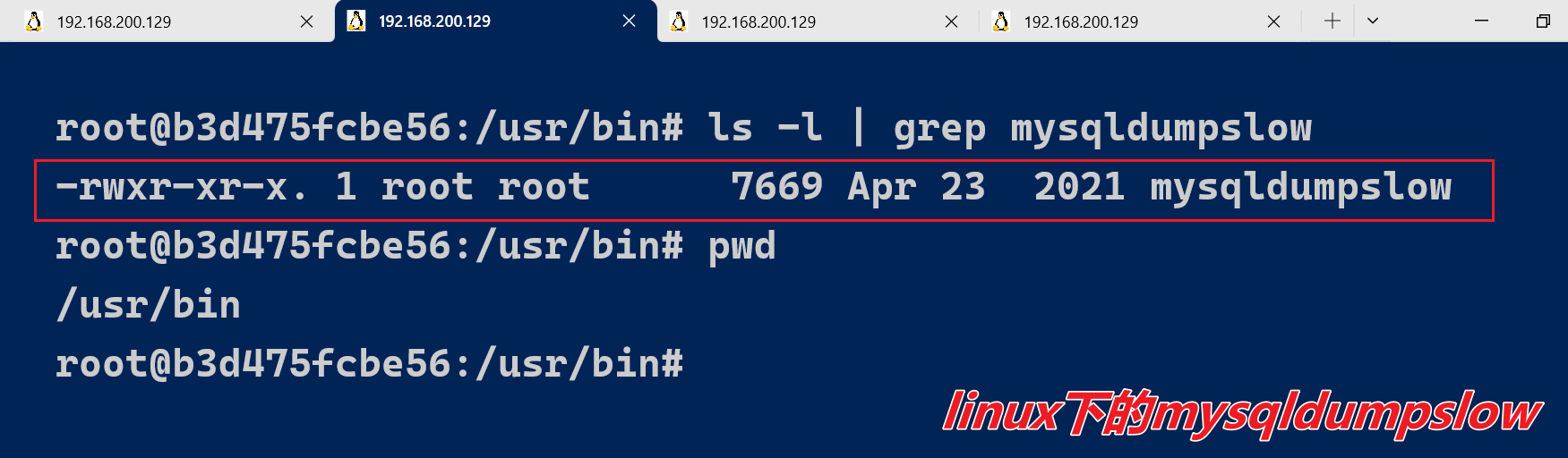
查看mysqldumpslow的帮助信息
mysqldumpslow --help
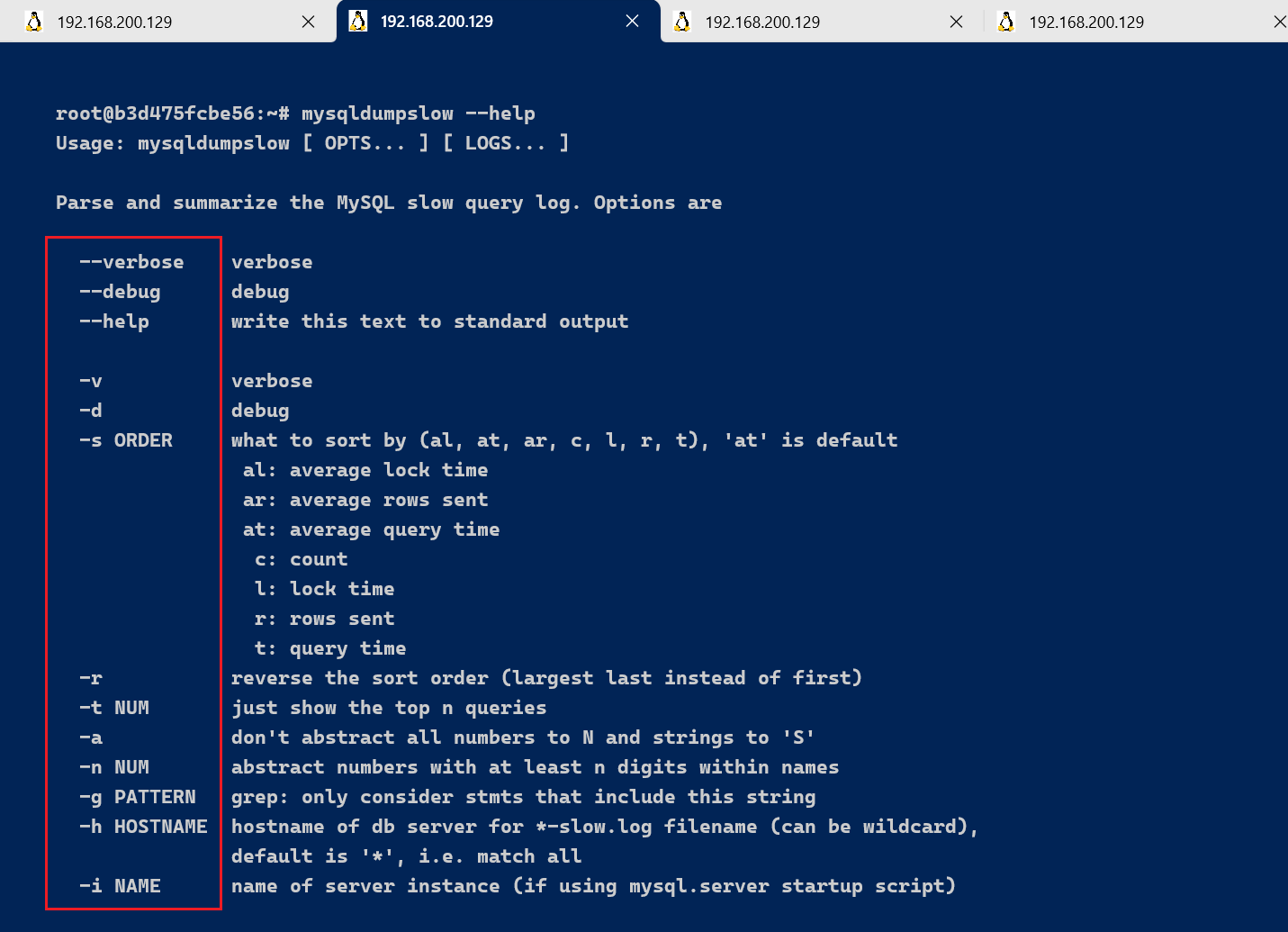
mysqldumpslow 命令的具体参数如下:
- -a: 不将数字抽象成N,字符串抽象成S
- -s: 是表示按照何种方式排序:
- c: 访问次数
- l: 锁定时间
- r: 返回记录
- t: 查询时间
- al:平均锁定时间
- ar:平均返回记录数
- at:平均查询时间 (默认方式)
- ac:平均查询次数
- -t: 即为返回前面多少条的数据;
- -g: 后边搭配一个正则匹配模式,大小写不敏感的;
举例:我们想要按照查询时间排序,查看前五条 SQL 语句,这样写即可:
mysqldumpslow -s t -t 5 /var/lib/mysql/b3d475fcbe56-slow.log
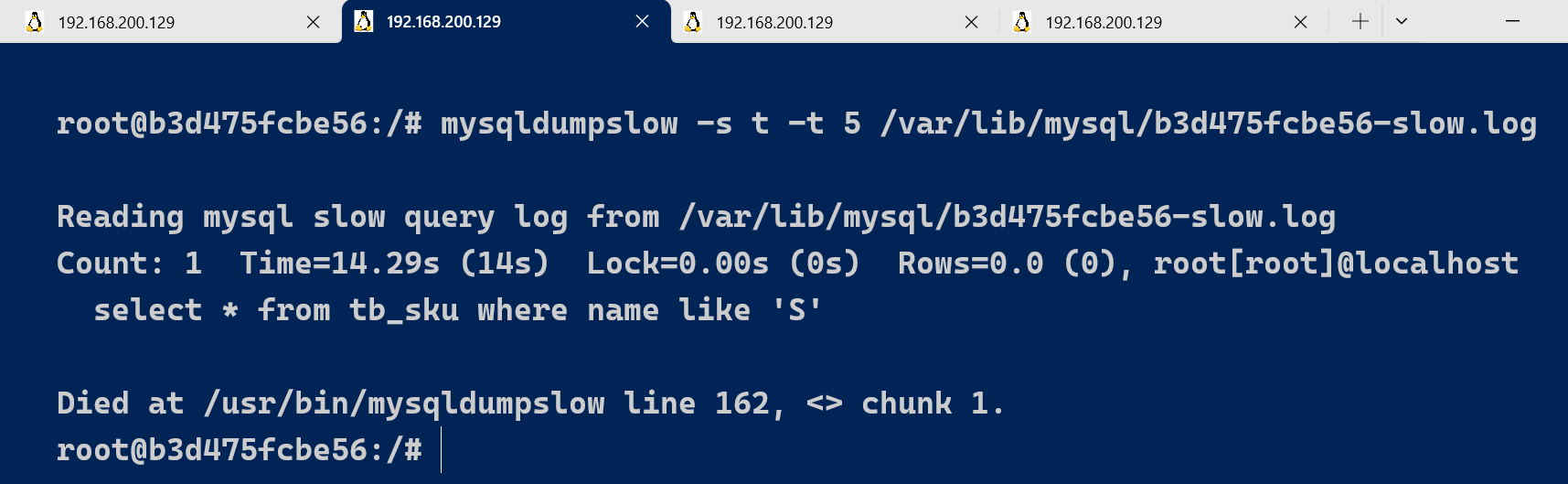
常用参考:
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
2.4、统计SQL的查询成本:last_query_cost
如果我们想要查询 id=9999024的记录,然后看下查询成本,我们可以直接在聚簇索引上进行查找:
select * from tb_sku where id =9999024;
运行结果(1 条记录,运行时间为 0.01s )
然后再看下查询优化器的成本,实际上我们只需要检索一个页即可:
SHOW STATUS LIKE 'last_query_cost';
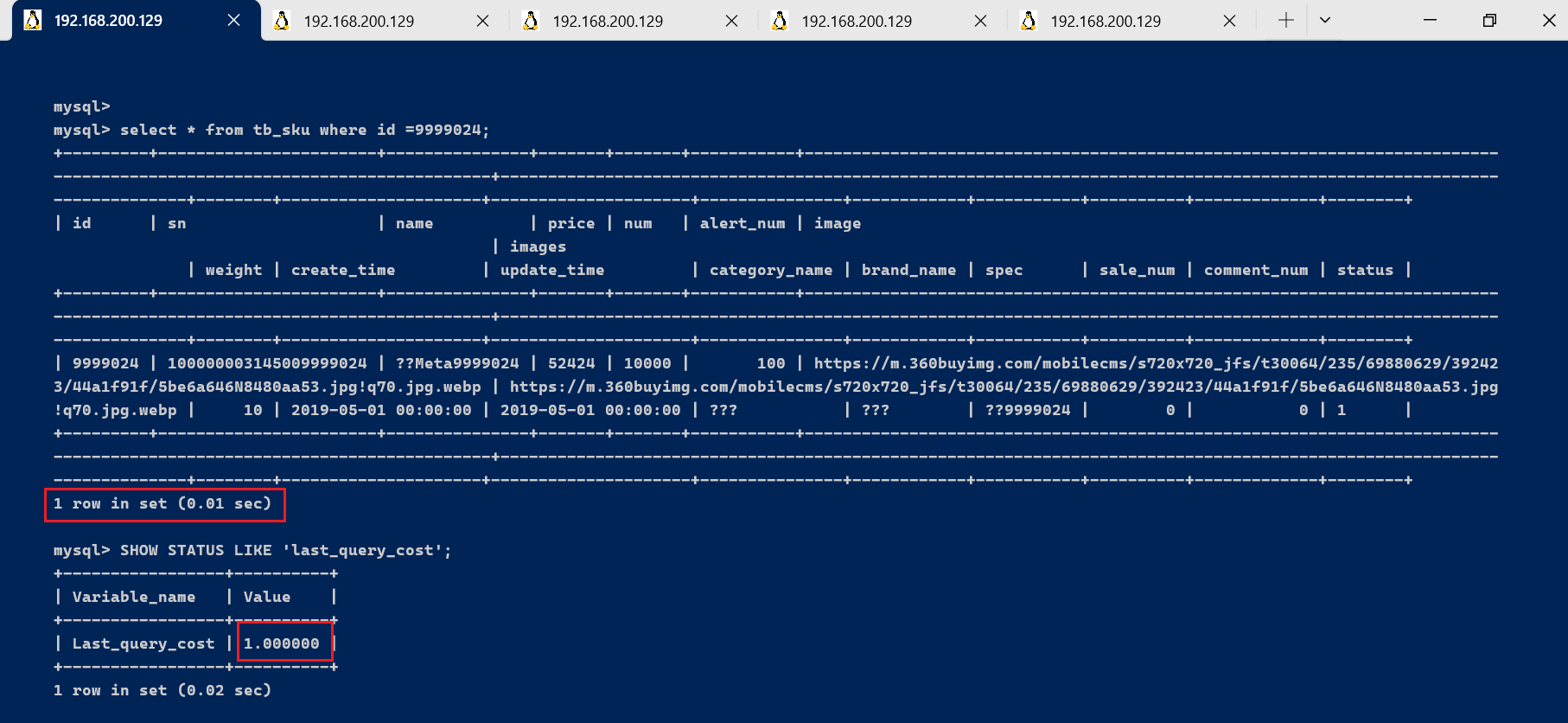
如果我们想要查询 id 在 9999024到 9999730之间的记录呢?
select * from tb_sku where id between 9999024 and 9999730;
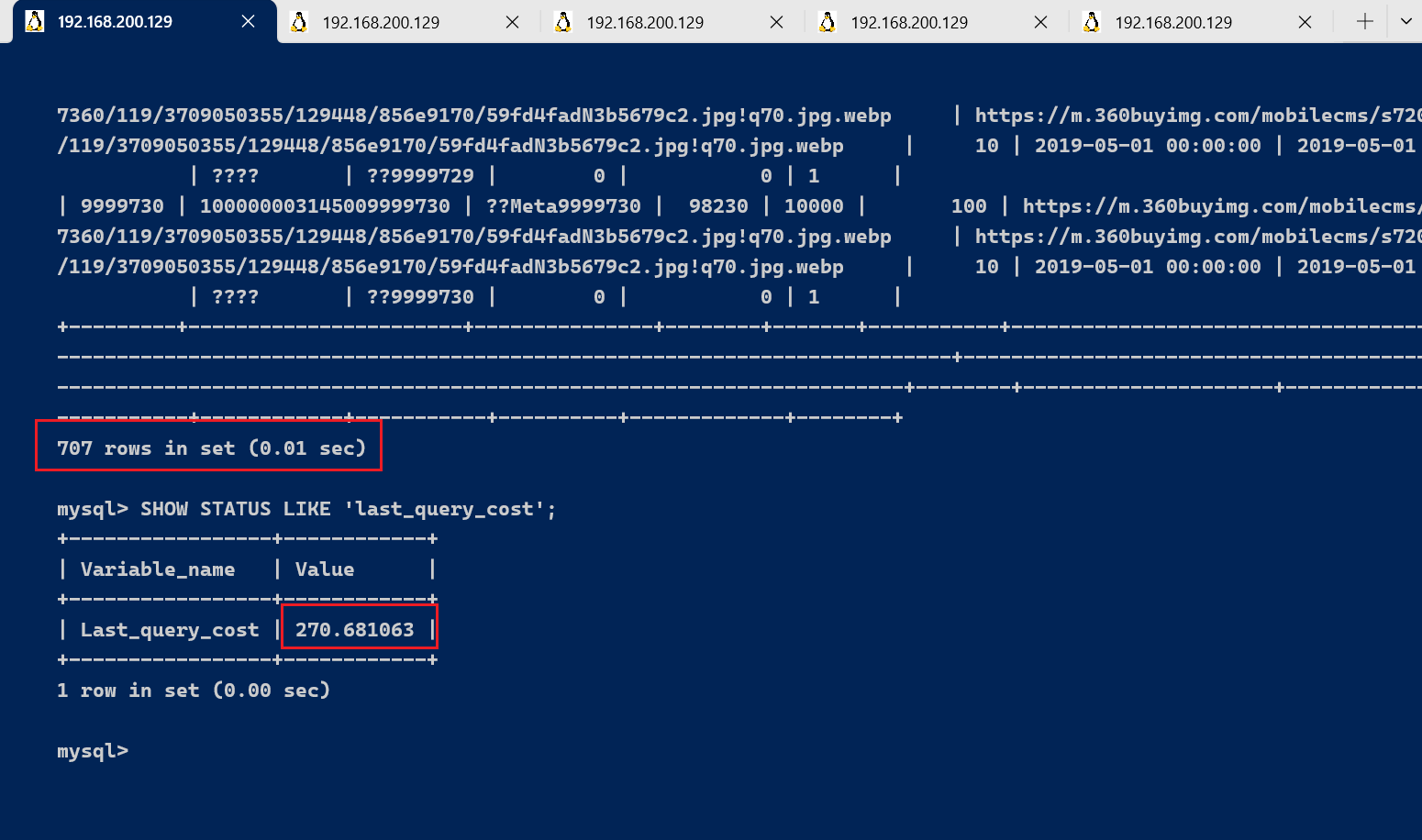
运行结果(707 条记录,运行时间为 0.01s ):
然后再看下查询优化器的成本,这时我们大概需要进行 270 个页的查询。
总结:
能看到页的数量是刚才的 270 倍,但是查询的效率并没有明显的变化,实际上这两个 SQL 查询的时间基本上一样,就是因为采用了顺序读取的方式将页面一次性加载到缓冲池中,然后再进行查找。虽然页数量(last_query_cost)增加了不少,但是通过缓冲池的机制,并没有增加多少查询时间。
使用场景:它对于比较开销是非常有用的,特别是我们有好几种查询方式可选的时候。
三、开发环境准备
https://github.com/shixiaochuangjob/markdownfile/tree/main/20240816
准备tb_sku表, 导入数据 - 数据1000w
CREATE DATABASE test CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
use test;
CREATE TABLE `tb_sku` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',`sn` varchar(100) NOT NULL COMMENT '商品条码',`name` varchar(200) NOT NULL COMMENT 'SKU名称',`price` int(20) NOT NULL COMMENT '价格(分)',`num` int(10) NOT NULL COMMENT '库存数量',`alert_num` int(11) DEFAULT NULL COMMENT '库存预警数量',`image` varchar(200) DEFAULT NULL COMMENT '商品图片',`images` varchar(2000) DEFAULT NULL COMMENT '商品图片列表',`weight` int(11) DEFAULT NULL COMMENT '重量(克)',`create_time` datetime DEFAULT NULL COMMENT '创建时间',`update_time` datetime DEFAULT NULL COMMENT '更新时间',`category_name` varchar(200) DEFAULT NULL COMMENT '类目名称',`brand_name` varchar(100) DEFAULT NULL COMMENT '品牌名称',`spec` varchar(200) DEFAULT NULL COMMENT '规格',`sale_num` int(11) DEFAULT '0' COMMENT '销量',`comment_num` int(11) DEFAULT '0' COMMENT '评论数',`status` char(1) DEFAULT '1' COMMENT '商品状态 1-正常,2-下架,3-删除',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
由于1000w的数据量较大 , 如果直接加载1000w , 会非常耗费CPU及内存 ; 已经拆分为5个部分 , 每一个部分为
200w数据 , load 5次即可 ;文件上传至 /opt/mysql-data

mkdir -p /opt/mysql-data
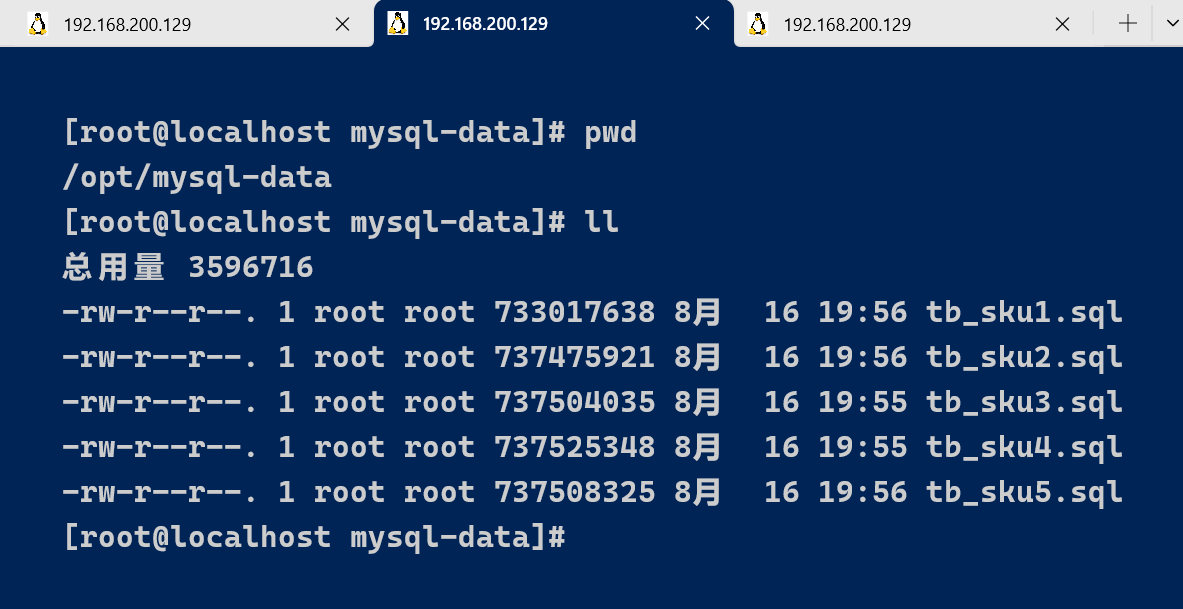
load data local infile '/opt/mysql-data/tb_sku1.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile '/opt/mysql-data/tb_sku2.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile '/opt/mysql-data/tb_sku3.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile '/opt/mysql-data/tb_sku4.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile '/opt/mysql-data/tb_sku5.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
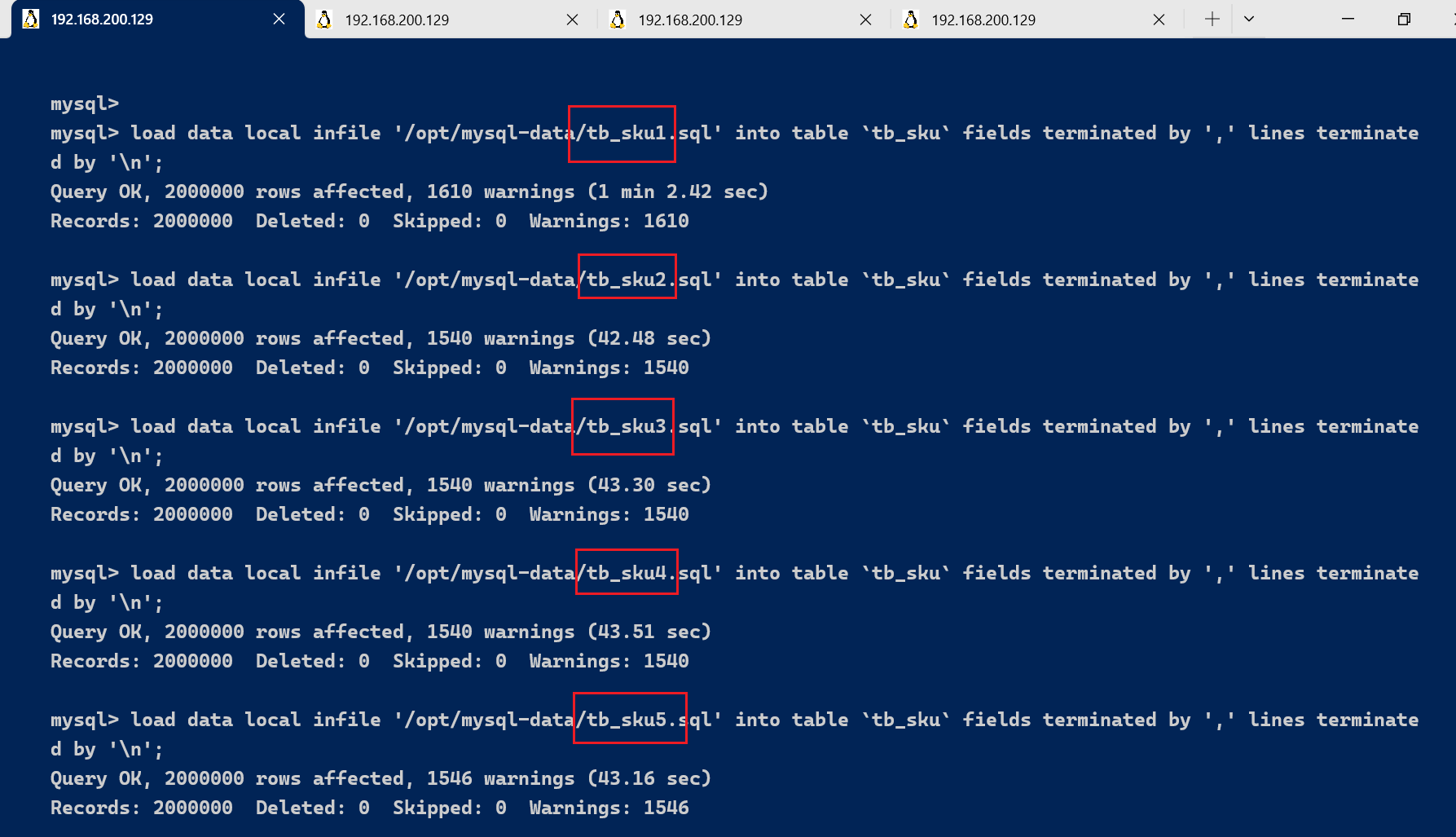
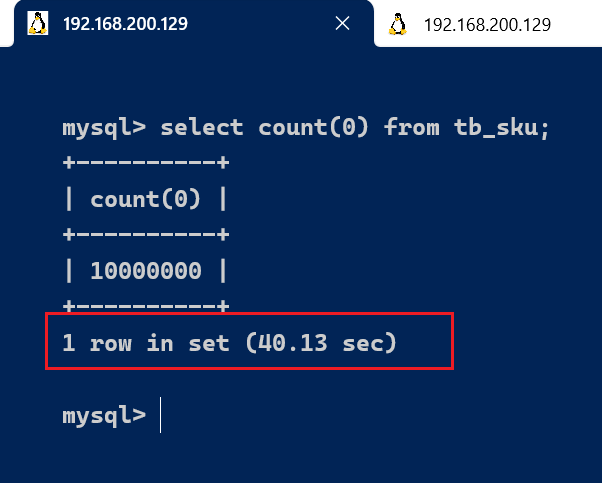
select count(0) from tb_sku;
https://mp.weixin.qq.com/s?__biz=MzkwOTczNzUxMQ==&mid=2247483991&idx=1&sn=d556f73d4ee09487dc93b28764ef5148&chksm=c137691ff640e009a8798c481d12dd1ad8973008374e64a8152e2bf10b881f41bc4dda06a9e8#rd

相关文章:
MySQL慢查询的查找语法
一、引言 数据库查询快慢是影响项目性能的一大因素,对于数据库,我们除了要优化SQL,更重要的是得先找到需要优化的SQL语句。 性能优化的思路 首先需要使用慢查询功能,去获取所有查询时间比较长的SQL语句其次使用explain命令去查…...

SQL中的聚合方法与Pandas的对应关系
在SQL和Pandas中,聚合方法是用来对数据进行汇总统计的重要工具。下面是SQL中的各种聚合方法及其与Pandas中相应操作的对应关系: 1. COUNT SQL: COUNT(*) 返回表中的行数。COUNT(column) 返回指定列中非空值的数量。 Pandas: count() 方法用于计算非空值…...

计算机毕业设计选题推荐-计算中心高性能集群共享平台-Java/Python项目实战
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

仿RabbitMq实现简易消息队列基础篇(future操作实现异步线程池)
TOC 介绍 std::future 是C11标准库中的一个模板类,他表示一个异步操作的结果,当我们在多线程编程中使用异步任务时,std::future可以帮助我们在需要的时候,获取任务的执行结果,std::future 的一个重要特性是能…...
经典算法题总结:数组常用技巧(双指针,二分查找和位运算)篇
双指针 在处理数组和链表相关问题时,双指针技巧是经常用到的,双指针技巧主要分为两类:左右指针和快慢指针。所谓左右指针,就是两个指针相向而行或者相背而行;而所谓快慢指针,就是两个指针同向而行…...

版本控制基础理论
一、本地版本控制 在本地记录文件每次的更新,可以对每个版本做一个快照,或是记录补丁文件,适合个人使用,如RCS. 二、集中式版本控制(代表SVN) 所有的版本数据都保存在服务器上,协同开发者从…...

微分方程(Blanchard Differential Equations 4th)中文版Section1.4
1.4 NUMERICAL TECHNIQUE: EULER’S METHOD 上一节中讨论的斜率场的几何概念与近似微分方程解的基本数值方法密切相关。给定一个初值问题 d y d t = f ( t , y ) , y ( t 0 ) = y 0 , \frac{dy}{dt}=f(t,y), \quad y(t_0) = y_0, dtdy=f(t,y),y(t0)=y0, 我们可以通过首…...

求职Leetcode算法题(7)
1.搜索旋转排序数组 这道题要求时间复杂度为o(log n),那么第一时间想到的就是二分法,二分法有个前提条件是在有序数组下,我们发现在这个数组中存在两部分是有序的,所以我们只需要对前半部分和后半部分分别…...

ActiveMQ、RabbitMQ、Kafka、RocketMQ在事务性消息、性能、高可用和容错、定时消息、负载均衡、刷盘策略的区别
ActiveMQ、RabbitMQ、Kafka、RocketMQ这四种消息队列在事务性消息、性能、高可用和容错、定时消息、负载均衡、刷盘策略等方面各有其特点和差异。以下是对这些方面的详细比较: 1. 事务性消息 ActiveMQ:支持事务性消息。ActiveMQ可以基于JMS(…...

HanLP分词的使用与注意事项
1 概述 HanLP是一个自然语言处理工具包,它提供的主要功能如下: 分词转化为拼音繁转简、简转繁提取关键词提取短语提取词语自动摘要依存文法分析 下面将介绍其分词功能的使用。 2 依赖 下面是依赖的jar包。 <dependency><groupId>com.ha…...

Python 的进程、线程、协程的区别和联系是什么?
一、区别 1. 进程 • 定义:进程是操作系统分配资源的基本单位。 • 资源独立性:每个进程都有独立的内存空间,包括代码、数据和运行时的环境。 • 并发性:可以同时运行多个进程,操作系统通过时间片轮转等方式在不同…...

实时数据推送:Spring Boot 中两种 SSE 实战方案
在 Web 开发中,实时数据交互变得越来越普遍。无论是股票价格的波动、比赛比分的更新,还是聊天消息的传递,都需要服务器能够及时地将数据推送给客户端。传统的 HTTP 请求-响应模式在处理这类需求时显得力不从心,而服务器推送事件&a…...

数据守护者:SQL一致性检查的艺术与实践
标题:数据守护者:SQL一致性检查的艺术与实践 在数据驱动的商业世界中,数据的一致性是确保决策准确性和业务流程顺畅的关键。SQL作为数据查询和操作的基石,提供了多种工具来维护数据的一致性。本文将深入探讨如何使用SQL进行数据一…...

jenkins配置+vue打包多环境切换
jenkins配置流水线过程 1.新建item 加入相关的参数就行了。 流水线脚本设置 后端脚本 node {stage checkoutsh"""#每次打包清空工作空间目录rm -rf $workspace/*cd $workspace#到工作空间下从远端svn服务端拉取代码svn co svn://10.1.19.21/repo/技术中台/低…...

idea和jdk的安装教程
1.JDK的安装 下载 进入官网,找到你需要的JDK版本 Java Downloads | Oracle 中国 我这里是windows的jdk17,选择以下 安装 点击下一步,安装完成 配置环境变量 打开查看高级系统设置 在系统变量中添加两个配置 一个变量名是 JAVA_HOME …...

HTML静态网页成品作业(HTML+CSS)——电影网首页网页设计制作(1个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有1个页面。 二、作品演示 三、代…...

大数据系列之:Flink Doris Connector,实时同步数据到Doris数据库
大数据系列之:Flink Doris Connector,实时同步数据到Doris数据库 一、版本兼容性二、使用三、Flink SQL四、DataStream五、Lookup Join六、配置通用配置项接收器配置项查找Join配置项 七、Doris 和 Flink 列类型映射八、使用Flink CDC访问Doris的示例九、…...
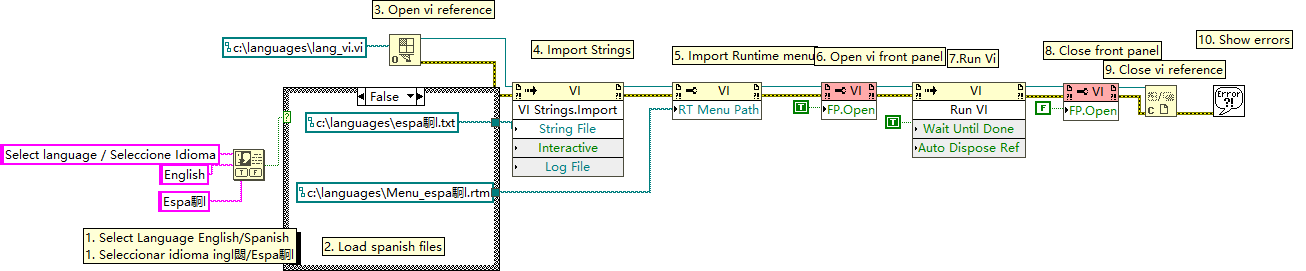
LabVIEW VI 多语言动态加载与运行的实现
在多语言应用程序开发中,确保用户界面能够根据用户的语言偏好动态切换是一个关键需求。本文通过分析一个LabVIEW程序框图,详细说明了如何使用LabVIEW中的属性节点和调用节点来实现VI(虚拟仪器)界面语言的动态加载与运行。此程序允…...

Unity引擎基础知识
目录 Unity基础知识概要 1. 创建工程 2. 工程目录介绍 3. Unity界面和五大面板 4. 游戏物体创建与操作 5. 场景和层管理 6. 组件系统 7. 脚本语言C# 8. 物理引擎和UI系统 学习资源推荐 Unity引擎中如何优化大型游戏项目的性能? Unity C#脚本语言的高级编…...

练习题- 探索正则表达式对象和对象匹配
正则表达式(Regular Expressions)是一种强大而灵活的文本处理工具,它允许我们通过模式匹配来处理字符串。这在数据清理、文本分析等领域有着广泛的应用。在Python中,正则表达式通过re模块提供支持,学习和掌握正则表达式对于处理复杂的文本数据至关重要。 本文将探索如何在…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...