R语言文本挖掘-万字详细解析tm包
tm包(Text Mining Package)是R语言中用于文本挖掘的强大工具包,它提供了一系列的功能来处理和分析文本数据。偶然看到这个包,我们一起看看其中的基本功能:
-
数据载入:tm包支持从多种数据源载入文本数据,包括本地文件、数据库、网络资源等。
-
语料库处理:tm包的核心概念之一是语料库(Corpus),它代表了一系列文档的集合。用户可以通过
Corpus()或VCorpus()函数创建动态或静态语料库。 -
数据预处理:tm包提供了丰富的数据预处理功能,包括文本清洗、分词、去除停用词、词干提取、词形还原等。
-
元数据管理:tm包允许用户管理和访问文档的元数据,这些元数据可以用于进一步的分析和分类。
-
文档-词条矩阵:tm包支持创建文档-词条矩阵(Document-Term Matrix, DTM),这是一种常用的数据结构,用于表示文本数据中的文档和词条之间的关系。
目录
1.文本挖掘
2.tm包安装
3. acq、crude数据集
4.content_transformer、tm_map函数模式筛选
5.语料库(Corpora)
6.DataframeSource函数创建语料库
7.DirSource函数创建目录源
8.Docs等函数处理词项矩阵
词项
9.findAssocs函数寻找词项关联
10. findFreqTerms函数寻找频繁出现的词项
11.findMostFreqTerms函数 寻找最频繁词项
12.读取稀释矩阵
13.分词器与预定义文本转换方法
14.高性能计算-hpc
15. inspect函数检查
16.meta函数meta类操作
17.PCorpus创建永久语料库
1.文本挖掘
文本挖掘,也称为文本数据挖掘,是指从大量文本数据中抽取事先未知的、可理解的、最终可用的知识的过程。它涉及将非结构化文本转换为结构化格式,以便发现有意义的模式和全新洞察。文本挖掘通常包括以下几个主要任务:
- 文本分类:将文本分配到预定义的类别中,这通常是一个有监督的学习过程。
- 文本聚类:将文本分组到不同的簇中,这是一个无监督的学习过程。
- 信息抽取:从文本中提取特定的信息片段,如命名实体识别、关系抽取等。
- 情感分析:确定文本的情感倾向,如正面、负面或中性。
- 文本摘要:生成文本的简短摘要,保留关键信息。
文本挖掘是一个多学科交叉的领域,它结合了数据挖掘技术、信息抽取、信息检索、机器学习、自然语言处理、计算语言学、统计数据分析等多种技术。
2.tm包安装
首先进行tm 包安装,由于是新包,镜像等比较慢,因此推荐手动安装,相关包安装问题可以看之前的博客文章:
一站式解决R包安装的各种方法及常见问题(Bioconductor、github、手动安装等)-CSDN博客
#普通安装
install.packages("tm")
#手动安装
download.file("https://cran.r-project.org/src/contrib/tm_0.7-14.tar.gz","tm_0.7-14.tar.gz")
install.packages("tm_0.7-14.tar.gz",repos = NULL)3. acq、crude数据集
(1)acq
这个数据集包含50篇新闻文章及其附加的元信息,这些文章来源于著名的Reuters-21578数据集。所有文档都属于“acq”主题,即涉及公司收购的内容。它是一个包含50篇文本文档的语料库(AVCorpus)。其来源是Reuters-21578文本分类集合分发版1.0,采用XML格式。
(2)crude
crude 是一个包含20篇文本文档的VCorpus对象。
该数据集来源于Reuters-21578文本分类集合分发版1.0(XML格式)。
library(tm)
data("acq")
acq
data("crude")crude4.content_transformer、tm_map函数模式筛选
以一个例子学习内容转换器函数
data("crude")
#查看第一篇文章
crude[[1]]
(f <- content_transformer(function(x,pattern) gsub(pattern,"",x)))
new <- tm_map(crude,f,"[[:digit:]]+")[[1]]
new
as.character(crude[[1]])
as.character(new)函数内部定义了一个匿名函数,该函数接受两个参数:x(要处理的文本)和pattern(要匹配的模式)。使用gsub函数将文本中符合模式的部分替换为空字符串,即删除这些部分。这里的模式"[[:digit:]]+"是一个正则表达式,匹配一个或多个数字字符。
在使用crude[[1]]命令的时候,我们能发现控制台的返回小白看不懂,我们进行简单解释:

<<PlainTextDocument>> 是一个 R 语言中的 S3 对象,属于文本挖掘或自然语言处理领域的一个特定类。这种对象通常用来存储和处理纯文本数据,其中包含文本内容以及与之相关的元数据(Metadata)。
crude[[1]] 就是访问该列表中的第一个 PlainTextDocument 对象。这个对象可能包含一段文本内容和它的元数据,元数据的长度为 15(15个不同的元),而内容部分包含 527 个字符。

我们发现函数将原本内容中的数字内容都去除了。
我们再通过一个例子来加深理解:
documents <- c("Hello @name, how are you?", "I am @name, nice to meet you.")
# 创建一个Corpus对象
corpus <- Corpus(VectorSource(documents))
# 创建一个content_transformer,它将@name替换为实际的名称
replace_name <- content_transformer(function(x,Name){gsub("@name",Name,x)
})
processed <- tm_map(corpus,replace_name,"david")
# 打印处理后的文档
print(sapply(processed, as.character))
5.语料库(Corpora)
在自然语言处理和文本挖掘领域,语料库(Corpora)是一个重要的概念,它指的是包含(自然语言)文本的文档集合。在R语言的tm包中,语料库通过虚拟S3类Corpus来表示,而其他扩展包则提供继承自这个基础类的S3语料库类,例如tm包自身提供的VCorpus类。
语料库类必须提供访问器以提取子集([])、单个文档([[]])以及元数据(meta)。函数length用于返回文档的数量,as.list则构造一个持有文档的列表。
语料库可以有两种类型的元数据,均可通过meta访问:
(1)语料库元数据:包含特定于语料库的元数据,形式为标签-值对。
(2)文档级元数据:包含特定于文档的元数据,但在语料库中以数据框的形式存储。文档级元数据通常出于语义原因(例如,由于某些高级信息如可能值的范围,文档分类形成独立实体)或性能原因(单次访问而非提取每个文档的元数据)使用。
此外,tm包还提供了其他几种语料库类:
SimpleCorpus:一种简单的语料库类。
VCorpus:tm包提供的另一种语料库类。
PCorpus:tm包提供的另一种语料库类。
DCorpus:由tm.plugin.dc包提供的一种分布式语料库类。
6.DataframeSource函数创建语料库
DataframeSource 函数允许用户创建一个数据源对象,该对象将数据框(data frame)中的每一行视为一个文档。这个功能特别适用于那些已经拥有或生成了包含文档内容和元数据的结构化数据集的场景。
使用说明
当你调用 DataframeSource(x) 时,你需要提供一个名为 x 的数据框作为参数。这个数据框必须满足以下条件:
第一列必须命名为 "doc_id",包含每个文档的唯一字符串标识符。
第二列必须命名为 "text",包含代表文档内容的 UTF-8 编码的字符串。
可以选择性地添加额外的列,这些列将被用作文档元数据。
返回值
DataframeSource 函数返回一个对象,该对象继承自 DataframeSource、SimpleSource 和 Source 类。这意味着返回的对象不仅包含了数据框源的特性,还具备了简单源和源对象的基本属性和方法,便于后续进行文本处理和分析。
相关函数
Source:提供关于 tm 包所使用的源基础设施的基本信息。
meta:用于处理不同类型的元数据。
readtext:用于读取多种格式的文本文件,使其适合被 DataframeSource 处理。
以下是一个简单的例子,展示了如何创建一个 DataframeSource 对象并用它来构建一个语料库(Corpus):
# 创建一个包含文档 ID、文本内容以及一些元数据的数据框
docs <- data.frame(doc_id = c("doc_1", "doc_2"),text = c("This is a text.", "This another one."),dmeta1 = 1:2,dmeta2 = letters[1:2],stringsAsFactors = FALSE
)# 使用 DataframeSource 创建数据源对象
ds <- DataframeSource(docs)# 利用数据源对象创建语料库
x <- Corpus(ds)# 检查语料库的内容
inspect(x)# 查看语料库的元数据
meta(x)
我们通过一个更复杂的例子进行理解:
#创建DF
docs <- data.frame(doc_id = c("doc_1", "doc_2", "doc_3"),title = c("R语言简介", "文本挖掘技术", "数据科学应用"),text = c("R语言是一种统计计算和图形的环境...的语言", "文本挖掘是从大量文本数据中提取有用信息的过程...","数据科学是一门多学科领域,它使用科学方法、过程、算法和系统..."),author = c("张三", "李四", "王五"),date = as.Date(c("2023-01-01", "2023-02-15", "2023-03-20")),stringsAsFactors = FALSE
)# 使用DataframeSource创建数据源对象
ds <- DataframeSource(docs)# 创建语料库
corpus <- Corpus(ds)# 查看语料库中的文档
inspect(corpus)# 对语料库中的文本进行预处理
# 例如,去除标点符号、数字、停用词等
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removeWords, stopwords("en"))# 创建文档-词项矩阵
dtm <- DocumentTermMatrix(corpus)# 查看文档-词项矩阵
inspect(dtm)

<<DocumentTermMatrix (documents: 3, terms: 3)>> 表示这个文档-词项矩阵(DTM)包含了3个文档和3个术语。接下来的一些描述性统计信息提供了矩阵的更多细节:
Non-/sparse entries: 3/6 指出矩阵中有3个非零元素和6个稀疏(即零)元素。
Sparsity : 67% 表明矩阵的稀疏度为67%,意味着大多数的词项-文档交叉点是空的,这在文本数据中是很常见的,因为一个特定的词项往往不会出现在所有文档中。
Maximal term length: 29 指的是矩阵中最长的术语长度为29个字符。
Weighting : term frequency (tf) 说明矩阵使用的是词频(term frequency, tf)权重,即每个单元格中的数值代表了相应术语在对应文档中出现的次数。
7.DirSource函数创建目录源
DirSource是一个函数,通常用于创建一个目录源(Directory Source)。它允许用户指定一个目录,并从该目录中读取文件作为文档进行处理。以下是DirSource函数的参数及其描述:
directory:一个字符向量,包含完整的路径名;默认值对应于工作目录(通过getwd()获得)。
encoding:一个字符串,描述当前的编码。这个参数被传递给iconv来将输入转换为UTF-8编码。
pattern:一个可选的正则表达式。只有匹配该正则表达式的文件名会被返回。
recursive:逻辑值。是否应该递归地列出子目录中的文件?
ignore.case:逻辑值。模式匹配是否应该是大小写不敏感的?
mode:一个字符串,指定文件应该如何被读取。可用的模式有:"":不读取。在这种情况下,getElem和pGetElem只返回URI。
"binary":以二进制原始模式读取文件(通过readBin)。
"text":以文本形式读取文件(通过readLines)。
使用DirSource时,它会获取通过dir命令获得的文件列表,并将每个文件解释为一个文档。
返回值是一个对象,它继承自DirSource、SimpleSource和Source类。
例如,以下代码会创建一个指向tm包中texts/txt目录的DirSource:
DirSource(system.file("texts", "txt", package = "tm"))
$encoding属性表示这些文本文件的编码方式
$length属性显示该目录中有5个文件
$position属性是用来追踪当前读取位置的,初始值为0。
$reader属性是一个函数,它定义了如何从源中读取文件并将其转换为PlainTextDocument对象。如果元素有URI,它会使用URI的基本名称作为文档ID。
$mode属性指示这个源是用于文本文件的。
$filelist属性列出了目录中的所有文件路径。
最后显示了DirSource对象的类属性,表明它是DirSource、SimpleSource和Source类的实例。
# 假设我们有一个包含多种类型文件的目录路径
my_directory <- "C:/Users/Huzhuocheng/Documents"directory_source = DirSource(directory=my_directory, # 指定要读取的目录路径encoding="utf-8", # 指定文件的编码格式pattern="*.txt", # 使用正则表达式匹配文件名mode="text" # 指定文件的处理模式
)
directory_source8.Docs等函数处理词项矩阵
Docs(x): 这个函数用于获取文档-词项矩阵或词项-文档矩阵中的文档ID。参数x是矩阵对象,返回值是一个包含文档ID的字符向量。
nDocs(x): 这个函数用于获取矩阵中文档的数量。参数x同样是矩阵对象,返回值是一个整数,表示文档的数量。
nTerms(x): 这个函数用于获取矩阵中词项的数量。参数x是矩阵对象,返回值是一个整数,表示词项的数量。
Terms(x): 这个函数用于获取词项-文档矩阵或文档-词项矩阵中的词项。参数x是矩阵对象,返回值是一个包含词项的字符向量。
示例代码展示了如何创建一个词项-文档矩阵的子集,并使用上述函数获取相关信息:
data("crude") # 加载示例数据
tdm <- TermDocumentMatrix(crude)[1:10,1:20] # 创建词项-文档矩阵的子集# 获取文档ID
Docs(tdm)# 获取文档数量
nDocs(tdm)# 获取词项数量
nTerms(tdm)# 获取词项
Terms(tdm)
词项
词项(Term)在信息检索、文本挖掘和自然语言处理等领域中,通常指的是构成文本的基本单位,它可以是单词、短语或其他有意义的词汇片段。词项是构建索引、执行搜索和分析文本内容的基础元素。
在构建词项-文档矩阵(Term-Document Matrix)或文档-词项矩阵(Document-Term Matrix)时,词项作为矩阵的一维,代表文档集合中出现的所有不同的词汇。每个词项与文档之间的关联通过矩阵中的数值来表示,如词频(Term Frequency)或逆文档频率(Inverse Document Frequency)等统计量,从而揭示词项在文档集合中的分布情况和重要性。
例如,在处理一组文档时,首先会对文档进行分词处理,将连续的文本流切分成一个个独立的词项。随后,这些词项会被用来构建矩阵,其中每一行对应一个词项,每一列对应一个文档,矩阵中的每个元素则表示该词项在对应文档中出现的次数或权重。
让我们通过一个简单的例子来更好地理解词项(Term)的概念。
假设我们有一组关于动物的小型文档集合,包含以下三个文档:
文档1(D1): "猫喜欢追逐老鼠。"
文档2(D2): "狗经常吠叫。"
文档3(D3): "猫和狗都是宠物。"
首先,我们对这组文档进行分词处理,将每个文档分解成单独的词项:
文档1的词项: ["猫", "喜欢", "追逐", "老鼠"]
文档2的词项: ["狗", "经常", "吠叫"]
文档3的词项: ["猫", "和", "狗", "都", "是", "宠物"]
接下来,我们可以构建一个词项-文档矩阵,如下所示:

9.findAssocs函数寻找词项关联
findAssocs 是一个用于在文档-词项或词项-文档矩阵中寻找关联的函数,它属于文本挖掘领域中的常用工具。该函数主要用于分析词项之间的相关性,并能够根据指定的相关性阈值来筛选出强相关的词项对。
描述
findAssocs 函数通过计算词项之间的相关性,帮助用户发现文档集合中词项之间的潜在联系。这对于理解文档的主题、进行关键词提取或者构建词项间的关联网络等任务非常有用。
用法
findAssocs 函数有两种S3方法,分别适用于 DocumentTermMatrix 和 TermDocumentMatrix 类对象:
## S3 method for class 'DocumentTermMatrix'
findAssocs(x, terms, corlimit)## S3 method for class 'TermDocumentMatrix'
findAssocs(x, terms, corlimit)参数
x: 一个 DocumentTermMatrix 或 TermDocumentMatrix 对象,包含了文档集合的词项频率信息。
terms: 一个字符向量,包含了用户希望查找其关联词项的目标词项。
corlimit: 一个数值向量,指定了每个目标词项的相关性下限(包含),范围从0到1。如果 corlimit 的长度与 terms 不同,则会被循环使用。
返回值
findAssocs 返回一个命名列表,其中每个列表组件以 terms 中的一个词项命名,并包含一个命名的数值向量。这个向量持有来自 x 的匹配词项及其满足 corlimit 下限的相关性值(经过四舍五入)。
示例
以下是一个使用 findAssocs 函数的例子
data("crude") # 加载示例数据集
tdm <- TermDocumentMatrix(crude) # 创建词项-文档矩阵
# 查找与"oil", "opec", "xyz"这些词项相关且相关性至少为0.7, 0.75, 0.1的词项
findAssocs(tdm, c("oil", "opec", "xyz"), c(0.7, 0.75, 0.1))
10. findFreqTerms函数寻找频繁出现的词项
该函数的目的是从给定的矩阵中找出频繁出现的词项,即那些出现频率在指定范围内的词项。
使用方法:
findFreqTerms(x, lowfreq = 0, highfreq = Inf)x:一个DocumentTermMatrix或TermDocumentMatrix对象,包含了文档和词项之间的关联信息。
lowfreq:一个数值参数,表示词项出现的最低频率界限。默认值为0,意味着不考虑频率的下限。
highfreq:一个数值参数,表示词项出现的最高频率界限。默认值为无穷大(Inf),意味着不考虑频率的上限。
此方法适用于所有数值权重,但对于标准的词频(term frequency,简称tf)权重来说可能最有意义。词频权重是指某个词项在文档中出现的次数,它是文本挖掘中常用的一个度量标准。
data("crude") # 加载示例数据集
tdm <- TermDocumentMatrix(crude) # 创建词项-文档矩阵
# 查找与"oil", "opec", "xyz"这些词项相关且相关性至少为0.7, 0.75, 0.1的词项
findAssocs(tdm, c("oil", "opec", "xyz"), c(0.7, 0.75, 0.1))11.findMostFreqTerms函数 寻找最频繁词项
findMostFreqTerms 函数用于在一个文档-词项或词项-文档矩阵中,或者一个词频向量中找到最频繁出现的词项。这个函数可以根据不同的输入类型(如DocumentTermMatrix、TermDocumentMatrix或词频向量)采用不同的方法来执行。
使用方法:
findMostFreqTerms(x, n = 6L, INDEX = NULL, ...)x:可以是DocumentTermMatrix、TermDocumentMatrix对象,或者是通过termFreq()获得的词频向量。
n:一个整数,指定返回的最频繁词项的最大数量,默认为6。
INDEX:一个指定文档分组的对象,用于汇总;如果为NULL(默认),则每个文档被单独考虑。
...:传递给方法的额外参数。
只有具有正频率的词项会被包括在结果中。
data("crude")## 词频:
tf <- termFreq(crude[[14L]])
findMostFreqTerms(tf)## 文档-词项矩阵:
dtm <- DocumentTermMatrix(crude)## 每个文档中最频繁的词项:
findMostFreqTerms(dtm)## 前10个和后10个文档中最频繁的词项:
findMostFreqTerms(dtm, INDEX = rep(1 : 2, each = 10L))
12.读取稀释矩阵
read_dtm_Blei_et_al 和 read_dtm_MC 是两个用于读取存储在特殊文件格式中的文档-词项矩阵的函数。这些函数通常用于处理由特定软件包生成的稀疏矩阵数据。
(1)read_dtm_Blei_et_al
用途:读取由Blei等人开发的潜在狄利克雷分配(LDA)和相关主题模型C代码使用的(列表中的列表类型稀疏矩阵)格式。
参数:file:要读取的文件名。
vocab:词汇表文件名,每行给出一个术语,或者为NULL。
详情:该函数读取由Blei等人开发的LDA和CTM模型使用的特定格式的稀疏矩阵。
(2)read_dtm_MC
用途:读取由MC工具包创建的稀疏矩阵信息,该工具包用于从文本文档创建向量模型。
参数:file:提供基础文件名的路径。
scalingtype:指定使用的缩放类型的字符串,或者为NULL(默认),在这种情况下,缩放将从具有非零条目的文件的名称推断出来。
详情:MC工具包使用压缩列存储(CCS)稀疏矩阵格式的变体,将数据写入具有适当名称的多个文件中。非零条目存储在文件中,其名称表明了使用的缩放类型。例如,_tfx_nz 表示按词频('t')、逆文档频率('f')和无归一化('x')进行缩放。有关更多信息,请参阅MC源代码中的README。
返回值
这两个函数都返回一个文档-词项矩阵。
13.分词器与预定义文本转换方法
(1)getTokenizers() 函数是 R 语言中 tm 包提供的一个函数,用于获取该包提供的预定义分词器(tokenizers)列表。
getTokenizers()当你运行上述代码时,它将列出 tm 包中可用的所有分词器。分词器是在文本挖掘过程中用于将文本分割成单词或短语的工具,这对于后续的文本分析至关重要。
参见
Boost_tokenizer:基于 Boost 库的分词器。
MC_tokenizer:基于 MC 工具包的分词器。
scan_tokenizer:基于 R 语言内置 scan 函数的分词器。

(2)getTransformations() 函数用于获取该包提供的预定义文本转换方法列表。这些方法通常用于文本预处理,以便于后续的文本分析或挖掘工作。
这些转换方法可以用于 tm_map 函数,以对文本数据进行各种转换处理。
例如,removeNumbers 用于删除文本中的数字,removePunctuation 用于删除标点符号,removeWords 可以删除指定的单词,stemDocument 用于将单词还原为其词干形式,而 stripWhitespace 则用于去除多余的空白字符。
此外,如果你需要创建自定义的转换方法,可以使用 content_transformer 函数。
# 获取预定义的转换方法列表
available_transformations <- getTransformations()
print(available_transformations)
-
removeNumbers:
这个方法的作用是从文本中移除所有的数字字符。在处理自然语言文本时,数字往往不携带与主题直接相关的信息,因此去除它们可以减少噪声,并可能帮助改善后续文本分析任务的效果,如情感分析、主题建模等。 -
removePunctuation:
此方法旨在从文本中删除所有的标点符号。标点符号虽然对于书面语言的语法结构至关重要,但在许多文本分析任务中,它们并不包含对理解文本内容有实质性帮助的信息。去除标点符号有助于统一词汇的格式,简化分析过程。 -
removeWords:
这是一种更灵活的方法,允许用户指定要从文本中删除的单词或短语。这可以用于去除停用词(stop words),即那些在文本中频繁出现但通常不承载重要意义的词汇,如“the”、“is”、“in”等。通过移除这些词汇,可以减少数据的维度,同时聚焦于更有意义的词汇。 -
stemDocument:
这个方法将文本中的词汇还原到它们的词干形式。词干提取是一种常见的文本规范化技术,目的是将词汇的不同形态(如动词的各种时态、名词的单复数等)统一为一个基本形式。这样做可以减少词汇的多样性,从而简化模型并提高某些文本分析任务的性能。 -
stripWhitespace:
该方法的功能是去除文本中的多余空白字符,包括空格、制表符、换行符等。清理空白字符有助于标准化文本数据,确保在进行诸如词频统计、文本向量化等操作时的准确性。
14.高性能计算-hpc
hpc 是一个用于高性能计算的R包,它提供了一系列函数来支持并行计算,从而加速数据处理和分析任务。其中,tm_parLapply 和 tm_parLapply_engine 是两个关键的函数,它们允许用户根据注册的并行化引擎对列表或向量应用函数。
功能描述
tm_parLapply 函数旨在并行化地应用一个函数到一个列表或向量的每个元素上。这种并行化可以显著提高执行效率,尤其是在处理大量数据时。
使用方法
tm_parLapply(X, FUN, ...): 这个函数接受三个主要参数:
X:一个原子向量、列表或其他适合当前并行化引擎的对象。
FUN:将要应用到X的每个元素上的函数。
...:传递给FUN的可选参数。
tm_parLapply_engine(new): 这个函数用于获取(无参数)或设置(带new参数)使用的并行化引擎。
new:可以是makeCluster()创建的类cluster对象,或者是带有形式参数X、FUN和...的函数,或者是NULL,后者表示不使用并行化引擎。
细节说明
在tm包中,一些易于并行的计算可以通过使用tm_parLapply和tm_parLapply_engine来自定义并行化,以充分利用可用资源。
如果设置了继承自类cluster的对象作为引擎,tm_parLapply将调用parLapply()函数,并将该集群和给定的参数传递给它。如果设置为函数,则tm_parLapply将用给定的参数调用该函数。否则,它将简单地调用lapply()。
示例
为了通过parLapply()实现并行化,可以使用以下方式注册默认集群:
tm_parLapply_engine(function(X, FUN, ...)
parallel::parLapply(NULL, X, FUN, ...))或者重新注册集群,例如名为cl的集群:
tm_parLapply_engine(cl) 要实现负载平衡的并行化,可以使用parLapplyLB()与注册的默认集群或给定集群:
tm_parLapply_engine(function(X, FUN, ...)
parallel::parLapplyLB(NULL, X, FUN, ...))或者
tm_parLapply_engine(function(X, FUN, ...)
parallel::parLapplyLB(cl, X, FUN, ...)) 要在Unix类平台上通过fork实现并行化,可以使用makeForkCluster()创建的集群,或者使用mclapply():
tm_parLapply_engine(parallel::mclapply)或者:
tm_parLapply_engine(function(X, FUN, ...)
parallel::mclapply(X, FUN, ..., mc.cores = n))我们通过一个例子来看一下:
documents <- list(doc1 = "This is the first document.",doc2 = "This document is the second document.",doc3 = "And this is the third one."# ... 假设有更多的文档
)
library(tm)
stem_text <- function(x) {stemDocument(x, language = "english")
}
#现在,我们可以使用tm_parLapply来并行地对每篇文档应用stem_text函数:
# 假设我们已经有了一个名为cl的并行计算集群
# cl <- makeCluster(detectCores() - 1) # 创建一个使用除主核外所有核心的集群# 设置并行引擎为我们的集群
# tm_parLapply_engine(cl)# 并行处理文档
stemmed_documents <- tm_parLapply(documents, stem_text)# 关闭集群
# stopCluster(cl)15. inspect函数检查
inspect 是一个在文本分析中常用的函数,主要用于显示语料库(corpus)、词条-文档矩阵(term-document matrix)或文本文档(text document)的详细信息。这个函数的目的是帮助用户更好地理解和检查他们的文本数据结构。
使用方法
inspect 函数根据不同的类有不同的方法,具体包括:
对于 PCorpus 类的对象,使用 inspect(x) 来查看其细节。
对于 VCorpus 类的对象,同样使用 inspect(x)。
对于 TermDocumentMatrix 类的对象,也是通过 inspect(x) 来展示信息。
对于 TextDocument 类的对象,使用 inspect(x) 来查看单个文档的细节。
data("crude") # 加载示例数据集
inspect(crude[1:3]) # 检查语料库中的前三个文档
inspect(crude[[1]]) # 检查语料库中的第一个文档
tdm <- TermDocumentMatrix(crude)[1:10, 1:10] # 创建一个词条-文档矩阵
inspect(tdm) # 检查词条-文档矩阵
16.meta函数meta类操作
meta 是一个用于访问和修改文本文档和语料库元数据的函数。它有多种不同的方法,适用于不同类型的对象,如 PCorpus, SimpleCorpus, VCorpus, PlainTextDocument, 和 XMLTextDocument。这些方法允许用户获取或设置特定的元数据标签(tag),或者获取所有可用的元数据。
DublinCore 是一个方便的包装器,用于使用简单的都柏林核心模式(支持来自都柏林核心元数据元素集的15个元数据元素)来访问和修改文本文档的元数据。
元数据可以分为三种类型:
corpus:包含特定于语料库的元数据,以标签-值对的形式存储。
indexed:包含特定于文档的元数据,但以数据框的形式存储在语料库中。这种元数据通常用于语义原因(例如,文档分类形成一个独立的实体,因为有一些高级信息,如可能值的范围)或性能原因(单次访问而不是提取每个文档的元数据)。这可以看作是一种索引形式,因此得名“indexed”。
local:直接存储在各个文档中的标签-值对形式的文档元数据。
data("crude")# 获取 crude 语料库中第一个文档的所有元数据。
meta(crude[[1]])# 获取 crude 语料库中第一个文档的都柏林核心元数据。
DublinCore(crude[[1]])# 获取 crude 语料库中第一个文档的 "topics" 元数据。
meta(crude[[1]], tag = "topics")# 设置 crude 语料库中第一个文档的 "comment" 元数据为 "A short comment."。
meta(crude[[1]], tag = "comment") <- "A short comment."# 删除 crude 语料库中第一个文档的 "topics" 元数据。
meta(crude[[1]], tag = "topics") <- NULL# 设置 crude 语料库中第一个文档的 "creator" 元数据为 "Ano Nymous"。
DublinCore(crude[[1]], tag = "creator") <- "Ano Nymous"# 设置 crude 语料库中第一个文档的 "format" 元数据为 "XML"。
DublinCore(crude[[1]], tag = "format") <- "XML"# 获取 crude 语料库中第一个文档的都柏林核心元数据,以查看所做的更改。
DublinCore(crude[[1]])# 获取 crude 语料库中第一个文档的所有元数据,以查看所做的更改。
meta(crude[[1]])# 获取整个 crude 语料库的所有元数据。
meta(crude)# 获取整个 crude 语料库的语料库级别元数据。
meta(crude, type = "corpus")# 设置整个 crude 语料库的 "labels" 元数据为从 21 到 40 的序列。
meta(crude, "labels") <- 21:40# 获取整个 crude 语料库的所有元数据,以查看所做的更改。
meta(crude)
17.PCorpus创建永久语料库
参数
x: 一个 ASource 对象,代表要读取的文本数据源。
readerControl: 一个命名列表,包含从 x 读取内容的控制参数。
reader: 一个函数,能够读取并处理 x 提供的格式。
language: 一个字符,表示文档的语言(最好使用 IETF 语言标签,例如 "en" 表示英语)。默认语言假设为英语。
dbControl: 一个命名列表,包含底层数据库存储的控制参数。dbName: 一个字符,指定数据库文件的名称。
dbType: 一个字符,指定数据库的格式(可能的格式参见 filehashOption)。
PCorpus 创建的永久性语料库将文档存储在 R 外的数据库中。这意味着可以在内存中同时存在多个指向同一底层数据库的 PCorpus R 对象,对一个对象所做的更改会传播到所有相应的对象,这与 R 的默认语义不同。
返回值
该函数返回一个继承自 PCorpus 和 Corpus 的对象。
txt <- system.file("texts", "txt", package = "tm")
PCorpus(DirSource(txt),dbControl = list(dbName = "pcorpus.db", dbType = "DB1"))在这个例子中,DirSource(txt) 创建了一个指向特定目录下文本文件的数据源对象,然后 PCorpus 使用这个数据源和指定的 dbControl 参数创建了一个永久性语料库。
通过这种方式,PCorpus 提供了一种灵活且持久的方式来管理和分析大量的文本数据。
文本挖掘的tm包内容实在太多,更多的函数功能可以见英语原版文档:
tm.pdf (r-project.org)
实在肝不动了 。
相关文章:
R语言文本挖掘-万字详细解析tm包
tm包(Text Mining Package)是R语言中用于文本挖掘的强大工具包,它提供了一系列的功能来处理和分析文本数据。偶然看到这个包,我们一起看看其中的基本功能: 数据载入:tm包支持从多种数据源载入文本数据&…...

JWT中的Token
1.JWT是什么? jwt(json web token的缩写)是一个开放标准(rfc7519),它定义了一种紧凑的、自包含的方式,用于在各方之间以json对象安全地传输信息,此信息可以验证和信任,因…...

苹果在iOS 18.1中向第三方开发者开放iPhone的NFC芯片
苹果公司今天宣布,开发者很快就能首次在自己的应用程序中提供 NFC 交易功能,而目前这主要是Apple Pay独有的功能。从今年晚些时候的 iOS 18.1 开始,开发者将可以使用新的 API 提供独立于 Apple Pay 和 Apple Wallet 的应用内非接触式交易。 这…...

系统开发之禁止卸载应用名单
本文目的主要是记录自己系统(Android7.1系统)开发实现代码,以便后期通用的功能可以直接使用,不需要再去通过搜索然后筛选再验证的繁琐流程,大大减小自己的开发时间。 我实现思路是在系统内新增自己的数据库用来记录禁止…...

wait 和 notify
目录 wait() 方法 notify() 方法 notifyAll() 方法 nofity 和 notifyAll wait 和 notify wait 和 sleep 的区别 wait 和 join 的区别 由于线程之间是抢占式执行的,因此,线程之间执行的先后顺序难以预知,但是,在实际开发中&…...

docker 启动 mongo,redis,nacos.
docker run --name mymongodb -e MONGO_INITDB_ROOT_USERNAMEadmin -e MONGO_INITDB_ROOT_PASSWORDXiaoyusadsad -p 27017:27017 -v /path/to/mongo-data:/data/db -d mongodb/mongodb-community-server:4.4.18-ubuntu2004-v 的目录必须是绝对目录 目录必须 chmod 777 /path/…...

Docker Swarm 搭建
Docker Swarm 搭建 1. 环境介绍 操作系统Centos 7Centos 7Centos 7内核版本Linux 3.10.0-957.el7.x86_64Linux 3.10.0-957.el7.x86_64Linux 3.10.0-957.el7.x86_64主机名称swarm-managerswarm-worker1swarm-worker2IP192.168.1.100192.168.1.200192.168.1.250Docker Domain20…...

浅述TSINGSEE青犀EasyCVR视频汇聚平台与海康安防平台的区别对比
在我们的很多项目中都遇到过用户的咨询:TSINGSEE青犀EasyCVR视频汇聚平台与海康平台的区别在哪里?确实,在安防视频监控领域,EasyCVR视频汇聚平台与海康威视平台是两个备受关注的选择。它们各自具有独特的功能和优势,适…...

设计模式系列:策略模式的设计与实践
一、背景 策略模式(Strategy Pattern)是一种行为设计模式,它定义了一系列的算法,并将每一个算法封装起来,使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户。 二、结构 策略模式主要包含三个角色&…...

数据挖掘之数据预处理
数据预处理是数据挖掘中的一个关键步骤,它的主要目的是对原始数据进行清洗、转换和格式化,以确保其质量和一致性,从而为后续的数据挖掘任务(如分类、回归、聚类等)提供可靠的数据基础。数据预处理一般包括以下几个主要…...

RocketMQ核心知识点整理,值得收藏!
1. 基本概念 Topic: 消息类别的集合,如订单消息发送到order_topic。标签(Tag): 同一Topic下区分不同消息的标志,实现精细化消息管理。ConsumeGroup: 消息消费组,可订阅多个Topic,一个Topic可被多个消费组订…...

微信小程序骨架屏
骨架屏是常用的一种优化方案,针对于页面还未加载完时给用户的一种反馈方式。如果自己要写骨架屏有点复杂因为页面的元素过多且不稳定,这边直接使用微信开发工具生成骨架屏。也不只有微信开发工具有像常用的抖音开发工具,字节开发工具都有对应…...

Window下node安装以及配置
在 Windows 下安装 Node.js 非常简单,你可以通过官方提供的安装程序或者使用多版本管理工具(如 NVM-Win)来进行安装。下面是两种方法的具体步骤: 1. 安装 Node.js程序 步骤如下: 访问官方网站: 访问 Node…...

校园疫情防控系统--论文pf
TOC springboot432校园疫情防控系统--论文pf 课题的来源 2019年在我国武汉爆发了一场规模非常庞大、传播速度十分迅速、对人体危害及其严重的新冠肺炎疫情。引发此次急性感染性新冠肺炎疫情的冠状病毒传播性较强,其传播主要是通过呼吸道飞沫和密切接触这两个途径…...

在Debian 9上使用Apt安装Java的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 介绍 Java 和 JVM(Java 虚拟机)是许多软件的必备组件,包括 Tomcat、Jetty、Glassfish、Cassandra 和…...

人工智能在网络安全中的三大支柱
人工智能 (AI) 席卷了网络安全行业,各种供应商都在努力将 AI 融入其解决方案中。但 AI 与安全之间的关系不仅仅在于实现 AI 功能,还在于攻击者和防御者如何利用该技术改变现代威胁形势。它还涉及如何开发、更新和保护这些 AI 模型。如今,网络…...

rk3568mpp终端学习笔记
RK3568Terminal封装MppGraph 通过脚本取和设置音量/zigsun/bin/linux/bin.debug.Linux.rk3568/get_record_voice_value.sh /zigsun/bin/linux/bin.debug.Linux.rk3568/set_record_voice_value.sh class RK3568Terminal : public IAVLinkManager, p…...

【C++继承】赋值兼容转换作用域派生类的默认成员函数
1.继承的概念 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类(或子类)。继承呈现了面向对象程序设计的层次结构…...
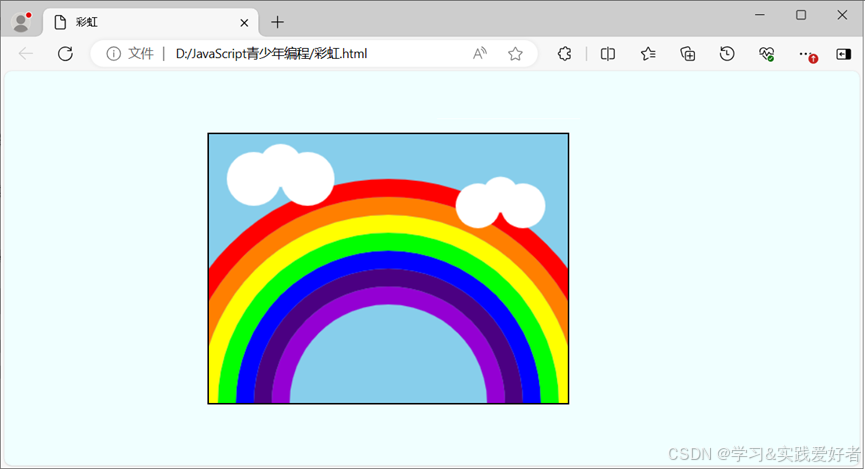
HTML5+JavaScript绘制彩虹和云朵
HTML5JavaScript绘制彩虹和云朵 彩虹,简称虹,是气象中的一种光学现象,当太阳光照射到半空中的水滴,光线被折射及反射,在天空上形成拱形的七彩光谱,由外圈至内圈呈红、橙、黄、绿、蓝、靛、紫七种颜色。事实…...
按条件查询(2)带 IN 关键字的查询)
MySQL——单表查询(二)按条件查询(2)带 IN 关键字的查询
IN 关键字用于判断某个字段的值是否在指定集合中,如果字段的值在集合中,则满足条件,该字段所在的记录将被查询出来。其语法格式如下所示: SELECT *|字段名 1,字段名 2,… FROM 表名 WHERE 字段名 [NOT〕IN(元素 1,元素 2,…) 在上…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...