PostgreSQL数据库内核(三):缓冲区管理器
文章目录
- 共享缓冲区基础知识
- 逻辑读和物理读
- LRU算法和CLOCK时钟算法
- 共享缓冲区管理器结构
- 共享缓冲表层
- 共享缓冲区描述符层
- 共享缓冲页层
- 共享缓冲区管理器工作流程
- 初始化缓冲区
- 读缓冲区
- 淘汰策略
- 共享缓冲区锁
共享缓冲区基础知识
通常数据库系统都会在内存中预留buffer缓冲空间用于提升读写效率,因为与内存读写交互效率远大于与磁盘的读写效率,而缓冲区管理器管理着缓冲区内存空间,将热数据加载到内存中以减少直接的磁盘读写,并维持这部分数据在缓冲池中的状态/锁管理,充当着读写进程和操作系统之间的协同者角色;
共享缓冲区管理器在设计上需要考虑的核心问题是:缓冲区大小设计+提升缓冲区命中率+制定合理缓冲区回收策略+保证多并发下的一致性问题。
在开始需要先了解一些基础知识。
逻辑读和物理读
逻辑读和物理读的区别在pg后台进程获取数据的过程中是否涉及到磁盘读,逻辑读过程中pg后台进程直接读从共享缓冲区获取到的数据页,物理读需要从借助操作系统从磁盘读取数据并加载到内存中再返回给读写程序。
做个实验先创建表并插入数据,通过expain analyze分析看一下物理读和逻辑读的差异。
postgres=# create table yzg(a int ,b varchar);
postgres=# insert into yzg (1,'a');
postgres=# insert into yzg select * from yzg;
INSERT 0 1
...
postgres=# insert into yzg select * from yzg;
INSERT 0 524288
构造查询语句SELECT * FROM yzg,发现命中了缓冲池中的4640个页(这里的yzg整个表大小也是4640个页,因为新建的pg环境没有其他并行连接和查询),这里就是逻辑读的过程;
postgres=# EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM yzg;QUERY PLAN
---------------------------------------------------------------------------------------------------------------Seq Scan on yzg (cost=0.00..15125.76 rows=1048576 width=6) (actual time=0.015..140.675 rows=1048576 loops=1)Buffers: shared hit=4640Planning Time: 0.051 msExecution Time: 222.198 ms
(4 rows)postgres=# SELECT
postgres-# nspname AS schema_name,
postgres-# relname AS table_name,
postgres-# pg_total_relation_size(C.oid) AS total_size, -- 包括表、索引、toast表等的总大小
postgres-# pg_relation_size(C.oid) AS heap_size, -- 表的堆大小
postgres-# (pg_relation_size(C.oid) / (1024 * 8))::bigint AS pages -- 表占用的页面数(假设页面大小为8KB)
postgres-# FROM g_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname || '.' || relname = 'public.yzg';schema_name | table_name | total_size | heap_size | pages
-------------+------------+------------+-----------+-------public | yzg | 38060032 | 38010880 | 4640
(1 row)如果我们把数据库down掉后再启动数据库,缓冲区数据就会被清理,再看执行计划产生了物理读;
postgres=# EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM yzg;QUERY PLAN
---------------------------------------------------------------------------------------------------------------Seq Scan on yzg (cost=0.00..15125.76 rows=1048576 width=6) (actual time=0.032..161.956 rows=1048576 loops=1)Buffers: shared read=4640Planning:Buffers: shared hit=15 read=8Planning Time: 2.666 msExecution Time: 243.906 ms
(6 rows)LRU算法和CLOCK时钟算法
将磁盘数据页block加载到内存以提升查询效率的必要性已经不言而喻了,但是通常内存肯定没有磁盘空间充足,其能够缓存的数据空间有限,需要一定策略来决定当内存满时应该替换掉哪些页面,也就是缓存置换算法。
LRU(Least Recently Used)算法是一种常用的决定当内存满时应该替换掉哪个页面的置换算法,其核心思想是优先淘汰最近最少使用的页面,假设如果一个页面最近被访问过那么它很可能很快会被再次访问,反之如果一个页面很久没被访问那么它很可能在未来也不会被访问。
CLOCK时钟算法是另一种在数据库缓冲池中使用的更节省资源的LRU替代方案,它试图在访问历史和内存中维持一个平衡,其再内存页面上维护一个“引用位”(reference bit)来判断页面是否最近被访问过,不需要维护完整的访问历史链表,而是通过简单的位标志来判断页面的使用情况,在实现上更加简单消耗的资源也更少但可能不如 LRU 算法精确。
两者都是缓存置换算法,但CLOCK算法在实现上更简单,并且可以减少内存访问次数,但LRU算法在实现上更复杂,pg使用时钟算法,oracle使用LRU算法。
共享缓冲区管理器结构
共享内存缓冲区可以被数据库多个子进程共享访问,缓冲区管理器维护着这块缓冲区的数据一致性并返回真实的数据页page,按照《PostgreSQL指南》将缓冲区管理器分三层:缓冲表、缓冲区描述符、缓冲页,但这里的层次划分是为了便于理解而进行的逻辑划分,如下图。

在代码上共享内存缓冲区的目录地址是src/backend/storage/buffer/,总代码量6000行+,其中:
1.buf_init.c 是缓冲区管理器的初始化入口,在启动数据库进程时候会初始化并分配1个共享内存缓冲区,并初始化缓冲表、缓冲区描述符和缓冲页。
2.buf_table.c 是缓冲表管理器,维护着缓冲区管理器中缓冲区的索引,缓冲区管理器通过缓冲表获取缓冲区描述符的索引项。
3.bufmgr.c 是缓冲区管理器核心代码,处理缓冲区管理器中缓冲区的访问并返回真实的数据页page。
4.freelist.c 是缓冲区管理器中缓冲区的淘汰策略,缓冲区不够用时调用淘汰策略来淘汰缓冲区。
5.localbuf.c 是本地缓冲区管理器,用于管理本地缓冲区,本地缓冲区是进程私有的缓冲区,用于缓存进程自己访问的数据.。

共享缓冲表层
共享缓冲表层代码实现在buf_table.c文件中,其函数都是针对hash表(dynahash.c)的查/增/删操作,这个hash表是全局共享的在InitBufferPool()中创建。

其中BufTableHashCode函数将在hash表中找到入参buffer_tags对应的buffer_id:
uint32 BufTableHashCode(BufferTag *tagPtr)
{return get_hash_value(SharedBufHash, (void *) tagPtr);
}
buffer_tag数据库子进程对于共享缓冲区的输入,能够唯一标识请求的page页,其中RelFileNode的属性分别是表对象oid/数据块oid/表空间oid,页面的forknumber(分别为0、1、2)(0=表和索引块,1=fsm,2=vm)页面number(页面属于哪个块)。例如{(16888, 16389, 39920), 0, 8}标签表示在某个表空间(oid=16888)某个数据库(oid=16389)的某表(oid=39920)的0号分支( 0代表关系表本体)的第8号页面。
// 映射关系
typedef struct
{BufferTag key; /* Tag of a disk page */int id; /* Associated buffer ID */
} BufferLookupEnt;
// BufferTag结构定义在buf_internals.h中,可以唯一标识数据页
typedef struct buftag
{RelFileNode rnode; /* physical relation identifier */ForkNumber forkNum;BlockNumber blockNum; /* blknum relative to begin of reln */
} BufferTag;
// 关系定义包含表空间id+dbid+表id
typedef struct RelFileNode
{Oid spcNode; /* tablespace */Oid dbNode; /* database */Oid relNode; /* relation */
} RelFileNode;
共享缓冲区描述符层
共享缓冲区描述符层也维护了1个BufferDesc元素构成的BufferDescriptors数组,该数组是所有数据库进程共享的,数组创建后由BufferStrategyControl负责管理,每个BufferDesc包含BufferTag和buf_id信息以及freeNext。

其中有个概念是freelist数组用于缓存空闲的BufferDesc,是BufferDescriptors数组中某些描述符的引用,当缓冲池管理器需要一个空闲的缓冲区时会首先检查freelist并从中取出空闲缓冲区的引用,这个描述符将从freelist中移除并被标记为已分配状态,当一个缓冲区不再需要时它的描述符会被放回freelist中。
共享缓冲页层
共享缓冲页层即buffers[]数组,存储真实的数据页page,并与共享描述符一一对应。
共享缓冲区管理器工作流程
初始化缓冲区
shared_buffers参数是基于系统内存大小动态计算的,对于<8GB内存的系统默认值为 128MB,对于>8GB,<16GB内存的系统默认值为系统内存的 1/4,对于>16GB内存的系统默认值为 4GB。
postgres=# show shared_buffers ;shared_buffers
----------------128MB
初始化流程如下:
main(int argc, char *argv[])
--> PostmasterMain(argc, argv);--> reset_shared(); // Set up shared memory and semaphores.--> CreateSharedMemoryAndSemaphores(); // Creates and initializes shared memory and semaphores.--> CalculateShmemSize(&numSemas); // Calculates the amount of shared memory and number of semaphores needed.--> add_size(size, BufferShmemSize());--> PGSharedMemoryCreate(size, &shim);--> InitShmemAccess(seghdr);--> InitBufferPool(); // 初始化缓冲池// 1. 初始化buffer descriptor--> ShmemInitStruct("Buffer Descriptors",NBuffers * sizeof(BufferDescPadded),&foundDescs); // 2. 初始化buffer pool--> ShmemInitStruct("Buffer Blocks", NBuffers * (Size) BLCKSZ, &foundBufs);--> StrategyInitialize(!foundDescs); // 3. 初始化 buffer table--> InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);--> ShmemInitHash("Shared Buffer Lookup Table", size, size, &info, HASH_ELEM | HASH_BLOBS | HASH_PARTITION);--> hash_create(name, init_size, infoP, hash_flags);
读缓冲区
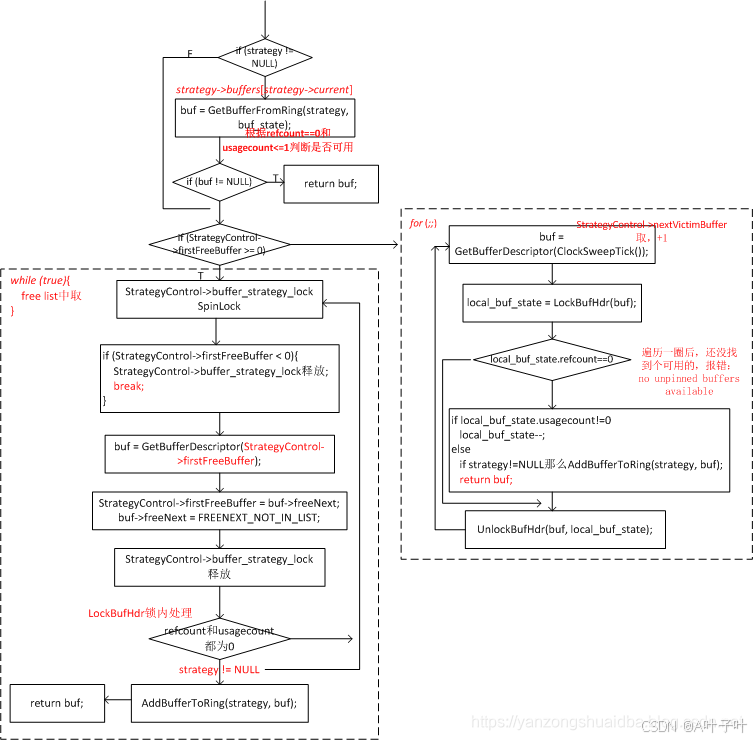
读取缓冲区的流程比较简单,缓冲表根据输入(buftag)输出缓冲区描述符buf_id并找到缓冲区描述符,若buf_id值大于0表示命中,命中后pin住该页使之不能被淘汰掉,修改BufferDesc->state值,refcount+1,usage+1,没有命中根据淘汰策略淘汰页再从磁盘读取页到缓冲区槽位,然后根据缓存区槽位返回对应的buf_id。
数据库子进程调用ReadBufferExtended ->ReadBuffer_common函数读取buffer,其中ReadBuffer_common会调用核心函数BufferAlloc来真正意义上进行缓冲区扫描与加载,其流程图如下:

函数梳理:
Buffer ReadBuffer(Relation reln, BlockNumber blockNum)
--> ReadBufferExtended(reln, MAIN_FORKNUM, blockNum, RBM_NORMAL, NULL);--> ReadBuffer_common(RelationGetSmgr(reln), reln->rd_rel->relpersistence,forkNum, blockNum, mode, strategy, &hit);--> BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found);--> INIT_BUFFERTAG(newTag, smgr->smgr_rnode.node, forkNum, blockNum); /* create a tag so we can lookup the buffer */--> BufTableHashCode(&newTag); // 哈希函数输入buftag,输出哈希值--> get_hash_value(SharedBufHash, (void *) tagPtr);--> buf_id = BufTableLookup(&newTag, newHash); // 根据buftag,查找缓冲表,获得bug_id,如果命中的话,如果找不到,返回-1--> hash_search_with_hash_value(SharedBufHash,(void *) tagPtr,hashcode,HASH_FIND,NULL);// 如果命中,返回,如果没有命中,继续执行--> StrategyGetBuffer(strategy, &buf_state); // 获取一个空闲可用的buffer,返回bufferdesc, 默认策略是NULL--> GetBufferFromRing(strategy, buf_state);--> BufTableInsert(&newTag, newHash, buf->buf_id); // 将新获取的buf_id,插入到缓冲表中--> smgrread(smgr, forkNum, blockNum, (char *) bufBlock); // 从磁盘读到buffer
pinbuffer函数用于“pin”一个缓冲区,当缓冲区被pin时意味着它正被一个或多个事务或查询使用,因此不能被缓冲池管理器淘汰或替换:

startBufferIo函数用于启动一个缓冲区I/O操作,当缓冲区中的数据需要从磁盘读取或写入磁盘时StartBufferIO()会被用来发起从磁盘读取数据的 I/O 请求,同样当缓冲区中的数据被修改并且需要持久化到磁盘时也会调用此函数来执行写操作:

淘汰策略
strategygetbuffer函数是缓冲区管理策略的一部分用于获取一个缓冲区,决定从缓冲池中获取哪个缓冲区,如果缓冲区不存在或已被淘汰那么它会根据当前的策略选择一个空闲或可替换的缓冲区,并可能触发 I/O 操作以加载或写入数据。
共享缓冲区锁
待续。
相关文章:
PostgreSQL数据库内核(三):缓冲区管理器
文章目录 共享缓冲区基础知识逻辑读和物理读LRU算法和CLOCK时钟算法 共享缓冲区管理器结构共享缓冲表层共享缓冲区描述符层共享缓冲页层 共享缓冲区管理器工作流程初始化缓冲区读缓冲区淘汰策略共享缓冲区锁 共享缓冲区基础知识 通常数据库系统都会在内存中预留buffer缓冲空间…...
[log4cplus]: 快速搭建分布式日志系统
关键词: 日志系统 、日志分类、自动分文件夹、按时间(月/周/日/小时/分)轮替 一、引言 这里我默认看此文的我的朋友们都已经具备一定的基础,所以,我们本篇不打算讲关于log4cplus的基础内容,文中如果涉及到没有吃透的点,需要朋友们动动自己聪明的脑袋和发财的手指,进一…...
redis I/O复用机制
I/O复用模型 传统阻塞I/O模型 串行化处理,就是要等,假如进行到accept操作,cpu需要等待客户端发送的数据到tcp接收缓冲区才能进行read操作,而在此期间cpu不能执行任何操作。 I/O复用 用一个进程监听大量连接,当某个连…...

Adobe PhotoShop - 制图操作
1. 排布照片 菜单 - 视图 - 对齐:打开后图层将会根据鼠标的移动智能对齐 菜单 - 视图 - 标尺:打开后在页面出现横纵标尺,方便图层的对齐与排列 2. 自动生成全景照 在日常处理中,我们常常想要将几张图片进行拼接获得一张全景图&…...

Mysql 中的Undo日志
在 MySQL 的 InnoDB 存储引擎中,Undo Log 是用于实现数据库事务的回滚功能的一种日志。Undo Log 记录了对数据的修改,以便在事务出现问题时可以恢复到之前的状态。下面将介绍 Undo Log 的结构和样本数据。 Undo Log 的基本概念 目的: Undo Log 的主要目…...

虹软科技25届校招笔试算法 A卷
目录 1. 第一题2. 第二题3. 论述题 ⏰ 时间:2024/08/18 🔄 输入输出:ACM格式 ⏳ 时长:2h 本试卷分为不定项选择,编程题,必做论述题和选做论述题,这里只展示编程题和必做论述题,一共三…...

C++ | Leetcode C++题解之第345题反转字符串中的元音字母
题目: 题解: class Solution { public:string reverseVowels(string s) {auto isVowel [vowels "aeiouAEIOU"s](char ch) {return vowels.find(ch) ! string::npos;};int n s.size();int i 0, j n - 1;while (i < j) {while (i < …...
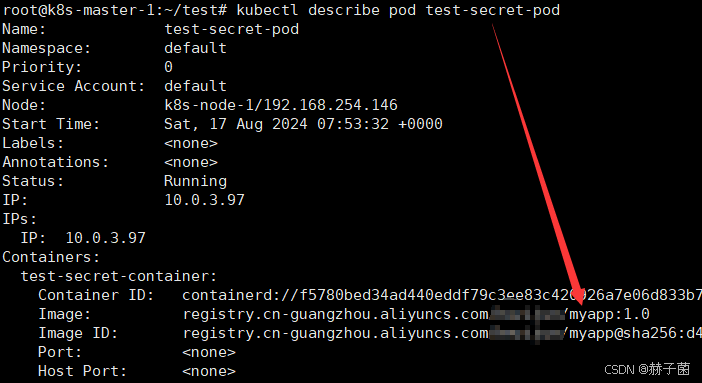
Kubernetes拉取阿里云的私人镜像
前提条件 登录到阿里云控制台 拥有阿里云的ACR服务 创建一个命名空间 获取仓库的访问凭证(可以设置固定密码) 例如 sudo docker login --usernameyourAliyunAccount registry.cn-guangzhou.aliyuncs.com 在K8s集群中创建一个secret 使用kubectl命令行…...
Leetcode每日刷题之118.杨辉三角
1.题目解析 杨辉三角作为一个经典的数学模型,其基本原理相信大家已经耳熟能详,这里主要是在学习了vector之后,对于本题有了新的解法,更加简便。关于vector的基本使用详见 面向对象程序设计(C)之 vector(初阶࿰…...

【ARM 芯片 安全与攻击 5.2 -- 芯片中侧信道攻击与防御方法介绍】
文章目录 什么是 Speculation Barriers?如何使用 Speculation Barriers?什么是 PAN?如何启用 PAN?使用 PAN 保护操作系统Spectre 攻击防御示例Meltdown 攻击防御示例Summary什么是 Speculation Barriers? Speculation Barriers,是一种防止处理器在投机执行中泄漏敏感信息…...
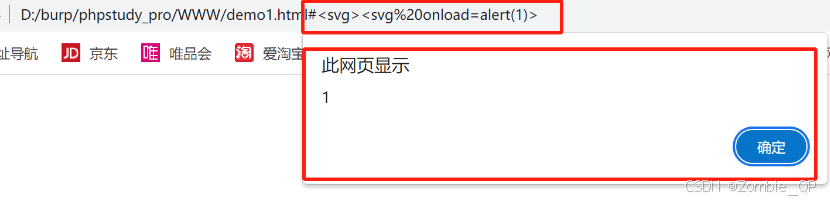
XSS-games
XSS 1.XSS 漏洞简介2.XSS的原理3.XSS的攻击方式4.XSS-GAMESMa SpaghetJefffUgandan KnucklesRicardo MilosAh Thats HawtLigmaMafiaOk, BoomerWW3svg 1.XSS 漏洞简介 XSS又叫CSS(Cross Site Script)跨站脚本攻击是指恶意攻击者往Web页面里插入恶意Sc…...
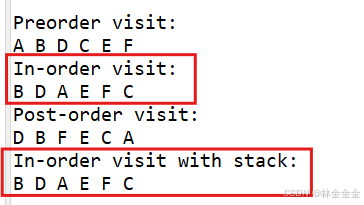
日撸Java三百行(day25:栈实现二叉树深度遍历之中序遍历)
目录 一、栈实现二叉树遍历的可行性 二、由递归推出栈如何实现中序遍历 1.左子树入栈 2.根结点出栈 3.右子树入栈 4.实例说明 三、代码实现 总结 一、栈实现二叉树遍历的可行性 在日撸Java三百行(day16:递归)中,我们讲过…...
【vue讲解:ref属性、动态组件、插槽、vue-cli创建项目、vue项目目录介绍、vue项目开发规范、es6导入导出语法】
0 ref属性(组件间通信) # 1 ref属性放在普通标签上<input type"text" v-model"name" ref"myinput">通过 this.$refs[myinput] 拿到的是 原生dom对象操作dom对象:改值,换属性。。。# 2 ref属…...

ubuntu:最新安装使用docker
前言 系统:ubuntu 22.04 desktop 目的:安装使用docker 安装小猫猫 没有安装包的,可以自己去瞅瞅,这里不提供下载方式 sudo dpkg -i ./cat-verge_1.7.5_amd64.deb 在应用里,打开这个软件,并开启系统猫猫 配…...

Linux ssh 免密失效
sudo chmod -R 777 /home/xxx sudo chown -R xxx:xxx /home/xxx 为什么我输入这两条指令后,ssh免密失效了? 当你使用 sudo chmod -R 777 /home/xxx 和 sudo chown -R xxx:xxx /home/xxx 这两条指令后,可能会导致 SSH 免密登录失效的原因有以…...

k8s上部署ingress-controller
一、安装helm仓库 # helm pull ingress-nginx/ingress-nginx 二、修改 三、运行 # kubectl label nodes node01.110111.cn ingresstrue# kubectl label nodes node02.110112.cn ingresstrue# helm upgrade --install ingress-nginx -n ingress-nginx . -f values.yaml 四、检…...
)
Android 13 about launcher3 (1)
Android 13 Launcher3 android13#launcher3#分屏相关 Launcher3修改 wm density界面布局不改变 /packages/apps/Launcher3/src/com/android/launcher3/InvariantDeviceProfile.java Launcher的默认配置加载类,通过InvariantDeviceProfile方法可以看出,…...

服务器数据恢复—raid5阵列热备盘未全部启用导致阵列崩溃的数据恢复案例
服务器存储数据恢复环境: 一台EMC某型号存储中有一组RAID5磁盘阵列。该raid5阵列中有12块硬盘,其中2块硬盘为热备盘。 服务器存储故障: 该存储raid5阵列中有两块硬盘离线,只有1块热备盘启用替换掉其中一块离线盘,另外…...

HTML—css
css概述 C S S 是 C a s c a d i n g S t y l e S h e e t s ( 级 联 样 式 表 ) 。 C S S 是 一 种 样 式 表 语 言 , 用 于 为 H T M L 文 档 控 制 外 观 , 定 义 布 局 。 例 如 , C S S 涉 及 字 体 、 颜 色 、…...
)
IO多路复用(Input/Output Multiplexing)
IO多路复用(Input/Output Multiplexing) 是一种在单个线程中管理多个输入/输出通道的技术。它允许一个线程同时监听多个输入流(如网络套接字、文件描述符等),并在有数据可读或可写时进行相应的处理,而不需要为每个通道创建一个独立的线程。这种技术主要用于处理并发连接…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...