第八周:机器学习笔记
第八周机器学习笔记
- 摘要
- Abstract
- 机器学习
- 1. 鱼和熊掌和可兼得的机器学习
- 1.1 Deep network v.s. Fat network
- 2. 为什么用来验证集结果还是不好?
- Pytorch学习
- 1. 卷积层代码实战
- 2. 最大池化层代码实战
- 3. 非线性激活层代码实战
- 总结
摘要
本周学习对李宏毅机器学习视频与Pytorch的CNN部分知识进行了学习,在李宏毅的机器学习中,主要进行了理论方面的知识,了解到了深度学习中Deep和Shallo类型network的区别,以及Deep network的优势所在,并对以往的知识进行了复习并对前几周验证集知识的补充。此外,在Pytorch中对CNN进行了继续的学习,进行了卷积层、最大池化层和非线性激活层的代码实战,并在tensorboard中图像化的显示了各层操作后图片的变化。
Abstract
This week, I learned about Li Hongyi’s machine learning videos and Pytorch’s CNN knowledge. In Li Hongyi’s machine learning, I mainly focused on theoretical knowledge, learned about the differences between Deep and Shallo type networks in deep learning, and the advantages of Deep networks. I also reviewed previous knowledge and supplemented the validation set knowledge in the previous weeks. In addition, further learning of CNN was conducted in Pytorch, including code practice of convolutional layers, max pooling layers, and non-linear activation layers. The changes in images after each layer operation were visualized in TensorBoard.
机器学习
1. 鱼和熊掌和可兼得的机器学习
其实这一小节主要是想说明深度学习到底好在哪
1、如果今天在optimization的时候可以选择的function比较多,我们的理想的状的Loss可以得出一个比较低的值,但是最终的结果h(train)可能会得到与理想结果h(all)相差甚远的情况
2、 可以选择的function比较少,那么就大大减少了理想与现实差距太大的风险。

我们有没有可能既有一个Loss很低的情况,同时又让我们得到一个现实与理想差距不大的结果呢?
即做到candidates(候选集)很少的同时(function选择比较少),任然保持一个很小的loss

接下来,我们要讲深度学习如何做到鱼与熊掌兼得的。
在深度学习中,我们第一周就有学习过,所以我们在这里进行一下相应的复习
那为什么我们要deep learning,为什么我们要加hidden layer?
理由是如下:可以透过一个hidden layer就制造出所有可能的function
比如如下图,我们要找一个function,它的输入就是这个图上的x轴,它的输出是这个图上的y轴,么找一个function或者说怎么用一个net work来逼近这一条线呢?

首先,把这条线呢分成一段一段
然后,把每一个线段,它的这个端点间连起来得到一个linear的方式
在这个例子里面,linear可能跟黑色的线没有非常的接近
但如果它的线段够多,切的够碎,那绿色的线跟黑色的线就就会足够接近。

我们用deep hidden neural network轻易的制造出绿色的这一条的线段
那一个hidden network怎么制造出绿色的这个线段呢?
如下图
我们经过观察发现这个绿色的线段可以看作是一个常数项加上一堆这样形状的蓝色的function。

首先你要有一个这个常数项。
这个常数项的高度就跟这边这个绿色的线段,最左边的这个端点的地方一样高。

那接下来加上第一个阶梯型的function
第1个阶梯型的function呢,是为了要产生下图的线段。

再加第二个阶梯型的function,第2个阶梯型的function是为了产生第二个线段

以此类推,我们再加上第3、4、5…个线段,来不断逼近我们原来的绿色线段

所以可以用常数项加上一堆阶梯型的function组合来逼近任何的function
所以任何的function其实都有办法用组合出来
那怎么表示这一个阶梯型的function呢?
那我们可以用一个叫做sigmoid的function来近似这个阶梯型的方式

线段型又叫hard sigmoid function
两个ReLU function组成一个hard sigmoid,如下图
ReLu有个转角的位置。
在转角的地方,其中一边都是零,另外一边是一条直线
用两个ReLu叠起来可以产生一个hard sigmoid function

假设我们的hidden layer neural network的每一个neuron,都可以制造出一个function
假设现在选择的activation function是sigmoid的话,可以通过设定不同的weight和bias就可以制造一个阶梯型的function

每制造出合适的function,把他们通通加起来,再加上常数项,就以产生任何的的function
那就可以用这个的方式去逼近任何的function

就算是我们的neuron是ReLu也没有关系,把够多的ReLu组组合起来,就可以变成任何的function。

你只要有足够多的neuron你就可以想办法去产生任何的function
1.1 Deep network v.s. Fat network
但是我们会发现一个问题,我们的hidden layer只要neuron足够多就可以逼近任何的function,但是我们为什么deep 而不是 fat 呢?难道是Deep听起来好听吗?

但在实验上,可以发现Deep确实效果好很多
如下图是一个论文上的结果:
越深错误率越低。所以越深表现越好
但是就有一个疑问:
当越深的时候,它的参数量就越多。当参数量越多的时候,你可以让你的理想越来越美好,但是不是会导致理想与现实的差距大的风险增加吗?
但是理想跟现实的差距,取决于两件事:
1、模型有多大,如果太大差距就会很大
2、取决于你有多少的训练资料,如果你今天收集的到足够多的。训练资料,就算你的模型很大,理想跟现实也会是接近的
那如果模型很大,但是有足够的资料量理想跟现实也不会差太多。

深度学习都是大模型,大模型往往伴随着需要大量的资料(没有大量的资料会导致Over fitting),所以其越深越好
又有一个疑问:
但是制造大模型一定要变“深”吗?我变胖(一层多放neuron)也是大模型啊?

所以刚才在同一篇论文里面,他就做了以下这个实验。
比较结果如下:
可以看到深的模型它的错误率还是比较低的,这个就是深度学习真正的力量
当你有同样大小的模型的时候,与其把network变胖,不如把network变高会得到比较好的结果。
那为什么为什么把network变高比把network变胖更加的有效呢?
虽然一个hidden layer可以表示任何function
但是当你要表示某一个function的时候,往往用一个的架构会是比较有效率的。
举例来说,假设你有某一个绿色的function,你可以用一个矮胖的来产生这个function,你也可以用一个高瘦的来产生这个function。
但是往往使用高瘦的需要的参数量是比较少的,矮胖的反而会需要比较多的参数
(这也Deep Learning的核心优。比较少的参数意味着你比较不会overfitting,或者是你只需要比较少的训练资料)
所以你会发现说你要做到同一件事,你要产生某一个function用高瘦的反而是比较有效率的

那我们来讲一下为什么deep(把network叠多层)会得到这样的效果呢?
我们用程序的方式举例:
我们在写程序的时候,程序里面也是会有架构的,你不会把所有的东西都放在你的main function里
除了main function 我们会写很大的Class,当我们需要的时候就可以取调用这些Class

有这种结构的好处是什么呢?
有这种结构的好处是它会避免你的程序太过拢长。增加它的可读性,那如果同一个功能在一个程序里面需要被反复使用的话可以让你的程序更为简洁好,所以在写程序的时候,其实你也会用到顶的结构。
下边还有一个例子是剪窗花
这个复杂的图案,你也可以直接去剪它,那你要直接剪出这个复杂的图案那是很麻烦的,你要剪很多刀。
但如果我们把纸折起来,我们只需要剪几刀就可以剪出复杂的图案,我们会比较有效率。
所以今天这个折纸的过程,把纸对折再对折,这个对折的过程,其实就是你deep hidden layer在做的。

那接下来我们就来看当一个network把它弄成deep的时候,会发生什么样的事情?
我们先来看一个只有一层的network
的输入为x,它的输出为a₁
假设它的参数我们都已经知道了
它有两个neuro
第一个neuron,它的weight = 1;bias = -0.5
第二个neuron,它的weight = -1;bias = 0.5
进入这两个的数值分别是 x- 0.5 跟 -x+0.5
activation function是ReLu
然后这两个的值经过ReLu,然后这两个都乘上1再加起来得到a₁

那这个x跟a₁之间的关系是长什么样子的?
假设我们的横轴是x(转90度来看的)
第一个neuron:输入的x>0.5的时候,输出就会跟输入一样,输入的x<0.5的时候输出就会是0(ReLu的特性)
第二个neuron:输入的x<0.5的时候,输出就会跟输入一样,输入的x>0.5的时候输出就会是0

我们再加第二层的neuron ,重复同样的操作(只不过第二层的输入是a₁),输出为a₂

我们可以很简单的得到a₁与a₂之间的关系

x跟a₂间现在会有什么样的关系呢?
所以x从0挪到0.5的时候,绿色这一条线也就是a₁,它是从1变到0。
所以x从0.5挪到1的时候,绿色这一条线也就是a₁,它是从0变到1。

所以表现在a₂相当于经历了两次轮回

以此类推,我们再用相同的方式得到第三层,就得到了如下图的情况
可以得出 a₃有2^3个线段

同理可得,以同样的方式叠k层(一层2个neuron,共2k个neuron),就有2^k个线段

如果你想要用一个shallow(浅层的)network要怎么做到生成这样锯齿状的线段呢?
其实shallow network也可以制造出任何可能的function 但是需要大量的neuron
假设你用的neuron是ReLu那每一个neuron只能制造一个线段出来。
2k次方的线段就需2k个neuron
但用deep只需要2k个neuron
所以差距还是非常大的。
所以今天要产生同样的function的时候
deep network参数量比较小,只需比较简单的模型。
而shallow network的参数量比较大,需要一个比较复杂的模型
而复杂的模型比较容易overfitting,需要大量的资料去避免
如果你的目标的function,也就是可以让你的loss很低的那个方式,它是复杂而且有规律的。那deep的network会优于shallow的network。
语音影像等等这些问题,会让loss低的那些function是复杂而有规律的,那这可以解释说为什么深度学习在视频、语音上,尤其是效果非常的好,因为那些可以让loss特别低的function,正好是复杂而有规律的。
2. 为什么用来验证集结果还是不好?
有了validation的概念以后,往往会觉得说我只要有用validation set,那就一定是最好的
但是有时候我们用来validation set以后把结果传到Kaggle上
在testing set上,却还是overfitting了,为什么会这样呢?
在了解这个问题之前,我们先对validation set进行复习
第四周的周报中我们提到了Cross Validation(交叉验证)
就是可以把training的资料分成两部分:
一部分叫做training set,另一部分叫做validation set(校验集)
90%的资料用于training set里面,有10%的资料会被拿来做validation set。

然后还了解到了N-fold Cross Validation(N倍交叉验证法),来解决怎么分training set的问题?
就是把data切成n等份,在这个例子里面就是3倍
我们切成三等份,切完以后你拿其中一份当做validation set。另外两份当做训练集
然后这件事情你要重复三次。
也就是说,你先第一、二份当trian,第三份当Val。
然后第一、三份当train,第二份当val
以此类推

整个过程如下图所示:
下图有3个Model,其中都通过Gradient descent选出了最佳的参数,记为h₁*、h₂*等等
然后再通过Validation Set对这3个模型进行评估,选出最佳的模型,然后上传到Testing Set中
总的来说Validation Set就是把Training data以及选好最佳参数的各个模型提前逐一验证,从而挑出最优的模型,再上传到Kaggle的Testing Set中。

其实validation set来挑选model的过程,其实也可以想成是一种training
我们把这个集合叫做H,里面找到某一个h,这个h可以让上的loss最低。
其实这个过程类似于我们Training data中某个Model通过Gradient Descent中挑选最佳参数的过程
就是在上从我们定好的model(大H)里面,找一个h它可以让最低,所以其实这件事情也可以看作是在上做训练,只是我们现在的模型可以选择的方向非常的少。

那这跟overfitting有什么关系呢?
先拿training data来说
如果你抽到一个不好的training data的时候,理想跟现实会有你没办法接受的差距。
那抽到不好的data取决于哪些因素呢?
1、取决于训练资料
2、你的模型有多复杂(complexity有多大)
3、你的模型里面可以选择的function的candidate(候选集)有多少?
(如果你可以选择的function的candidate越多、模型越复杂,抽到不好的data几率会很大,会即得不到理想的training set几率很大)
同理我们如果把validation set想成是training set
1、什么时候你在validation set上看到的现实会跟你的理想差距很大呢?
就是当你拿到的validation set是不好的data set的时候
2、那什么时候validation set不好呢?
①.validation set大小
②.validation set对应的这个模型(大H)复杂的程度(通常不会太大,像我们刚才举的例子,里面大H只有三个选择)

但Hval它总是很小吗?
如果你今天呢Hval太大,比如说架构的时候,你做的太大。
比如我的架构要从一层到十层的network,那每一层有一到1000个neuron(那每一层有一到1000个选择),我决定跑这个1000个1000^10的模型validation set来选模型。
这个时候你的Hval就有1000^10方那么大了,那也很有可能会overfitting。
在validation set看到结果也可能跟真正的data差距非常的大。
所以今天如果你用validation set决定模型的时候,待选择的模型太多了,你仍然有可能会overfitting
Pytorch学习
1. 卷积层代码实战
上一周,我们学习了卷积层的计算方式跟代码的基础运用,但是对于卷积层的细节理解尚为短浅,所以我们需要更进一步的学习。
在pytorch官网中,点击找到torch.nn中的CONV2D(即卷积的二维),查看一下文档说明
我们可以对上一周的知识进行复习
这里的卷积层主要包含kernel_size(卷积核大小)、stride(步长)、padding(填充)等参数都是上一周学习过的。
其中这些参数有一定的关系,就比如我们上周学会了一道公式
该公式可以计算出经过卷积核后图片输出的大小为多少?
假设
输入图片(Input)大小为I * I
卷积核(Filter)大小为K * K
步长(stride)为S
填充(Padding)为P
那卷积层输出(Output)的特征图大小为多少呢?
O = ( I − K + 2 P ) S + 1 ,结果向下取整 {\color{Red} O= \frac{(I-K+2P)}{S} +1},结果向下取整 O=S(I−K+2P)+1,结果向下取整

其实在实际应用中,我们一般只设置前五个参数的值(标蓝的部分),因为其他都有默认值且一般都不用怎么修改。

下面我们来大致认识一下这些参数的含义:
1、in_channels (int类型) – 输入图像中的通道数
2、out_channels (int类型) – 卷积产生的通道数
3、kernel_size (int or tuple类型) - 卷积内核的大小,当kernel size = 3的时候,就意味着卷积核的大小为3×3。其里面的参数是通过分布当中采样得到的,会随着训练不断的改变
(上一周的知识中基于neuron的理解其实这里的值就是weight(w₁、w₂…)通过gradient descent得到)
4、stride (int 或 tuple类型) - 卷积的步幅。默认值:1
5、padding (int 或 tuple类型) – 在 的两侧添加零填充 输入。默认值:0
6、padding_mode(字符串类型) – 、 或 .默认值:‘zeros’(即填充出来的格子的默认值为0,可以修改)
7、dilation(膨胀)(int 或 tuple类型) - 内核元素之间的间距。默认值:1
8、groups (int类型) – 来自输入的阻塞连接数 通道到输出通道。默认值:1
9、bias (bool类型), 加偏置值然后输出。默认为true
其中6、7、8、9在实际应用应用中很少使用,都是使用默认值。
补充:在Python中,元组(tuple)是一种内置的数据结构,它类似于列表(list)
但有一个关键的不同点:元组是不可变的(不可修改)。

我们可以点击官方给出的link进行图像化的理解,点击箭头的link
或者点击这里也可以进入

点击进入后,可以看到都是动态图片,这里很形象的展示了stride和padding有或无的对比,可以加深我们的理解。

其中在dilation中,我们可以看到卷积核都是间隔的(不同于之前是连续的,所以称为空洞卷积)

现在我们在上周pytorch的卷积学习,唯一没有学习的重要参数就只剩下in_channels(输入通道数) 与 out_channels(输出通道数)
但在机器学习视频中我们可以了解到
1、in_channels(输入通道数):如果是作为一开始的输入,就是图片的通道数。
彩色图片是3通道(rgb),黑白图片是1通道。
2、out_channels(输出通道数):上一周学习到的是跟filter(卷积核)的个数有关(一个filter生成一组数据,64个filter就生产64组数据,就会有64个channel)
所以输出通道数 = 卷积核个数
(也就是out_channels = 1时,生成1个卷积核;out_channels = 2时,生成2个卷积核…以此类推,卷积核里面的参数不相同)
如下图所示:

接下来我们通过代码去详细学习一下卷积层
这段代码将将结合前几周的所学习到的知识,顺便可以进行复习
代码如下:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./datasets', train=False, transform=torchvision.transforms.ToTensor(),download=True)# dataloader
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)# 定义网络架构类
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, stride=1, kernel_size=3, padding=0)def forward(self, x):x = self.conv1(x)return x# 声明对象
net = Net()
# 使用Tensorboard
writer = SummaryWriter("logs_conv2d")
# 循环结构输入tensorboard
step = 0
for data in test_loader:imgs, targets = dataoutput = net(imgs)writer.add_images("input", imgs, step)# 因为在tensorboard不能输出6通道的图片,所以要改为3通道(多出来的通道放到batch_size里面),但是batch_size = -1,就是让机器自己计算。output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output", output, step)step += 1writer.close()启动tensorboard
tensorboard --logdir=logs_conv2d --port=6007
结果如下图所示:
可以看到经过卷积后的图片还是很有意思的。

疑问及解答:
因为在tensorboard上显示的也是彩色图片(RGB,3通道),所以我们无法显示6通道图片。因此要转换为3通道输出,那为什么通道数变少,batch_size会变大?
例如,这是一个2通道的图片

将2通道变为1通道(相当于把叠加的拿下来铺展开),所以batch_size会变大。

2. 最大池化层代码实战
上一小节中,我们学习了卷积层的配合数据集的应用,这一小节我们继续学习CNN里面比较重要的池化层。
在上一周中我们在机器学习的视频里面也学习到了Pooling(池化层)
下面是复习时间:
其描述如下:
Pooling其实就是把图片变小,降低复杂度、防止过拟合。

其中也学习了最常见的池化层——最大池化层(Max Pooling)
大概的意思就是把数字分为几个几个一组(也就是池化核的大小),然后再挑选里面最大的数值作为代表
如下图所示:

接下来,我们通过代码继续学习
我们在torch.nn找到池化层

因为我们卷积层用的是conv2d,所以在池化层的学习中,我们也使用2d

其参数如下:

和之前的卷积层差不多
如下:
1、kernel_size – 要占用最大值的窗口的大小
(比如给定一个3,会生成33的窗口。如果tuple为(2,3)会生成23的窗口)
2、stride – 窗口的步幅。默认值为kernel_size
3、padding – 在两侧添加隐式零填充
4、膨胀 – 控制窗口中元素步幅的参数
5、return_indices – 如果为true将返回最大索引和输出。
6、ceil_mode – 当为 True 时,将使用 ceil 而不是 floor 来计算输出形状
其中ceil表示向上取整,floor表示向下取整

然后我们上面提到过,池化实际上就是将输入的图像分组后
所谓的分组实际上就是也就是池化核的大小(因为代码中池化层是由kernel_size的)

然后把这个核套在输入图像上,选取这个区域的最大值(因为是最大池化操作Max Pooling),
如下图就是取最大值2 后续的操作跟卷积差不多,就是根据stride(默认值为kernel_size大小)与padding一步一步的移动,最后生成一个输出
后续的操作跟卷积差不多,就是根据stride(默认值为kernel_size大小)与padding一步一步的移动,最后生成一个输出
但下面要说明一个点,就是ceil_model(一般情况下为false)
如下图所示
当值为2.31时,floor的计算为2;ceil的计算为3

所以在最大池化层中计算的ceil与floor,是这样的
当池化核移动到这个位置时,会有很大差别了

最终池化结果如下图所示:

下面是池化层的输入与输出格式,以及输出的高度、宽度计算公式(论文可能会用到)
其中
N为batch_size
C为channel
H为高度
W为宽度

下面进入代码环节:
先按照上述的图像输入如下矩阵

总体代码如下:
import torch
from torch import nn
from torch.nn import MaxPool2dinput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)# 通过reshape转换为(N,C,H,W)的格式
input = torch.reshape(input, (-1, 1, 5, 5))class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 定义池化层self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=True)# 使用在forward中加入池化层def forward(self, x):x = self.maxpool1(x)return xnet = Net()
output = net(input)
print(output)可以看到,当ceil_mode=True时,跟我们上面手动的推算结果是一样的。

当ceil_mode=False时,结果是一样的。

接下来我们结合CIFAR10数据集一同使用
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./datasets', train=False, transform=torchvision.transforms.ToTensor(),download=True)# dataloader
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 定义池化层self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=False)# 使用在forward中加入池化层def forward(self, x):x = self.maxpool1(x)return xnet = Net()
# 使用Tensorboard
writer = SummaryWriter("logs_pool")# 循环结构输入tensorboard
step = 0
for data in test_loader:imgs, targets = datawriter.add_images("input", imgs, step)output = net(imgs)writer.add_images("output", output, step)step += 1writer.close()启动tensorboard
tensorboard --logdir=logs_pool --port=6007
结果如下图所示,可以见到图片模糊了一些,但是可以大致看的清楚是什么东西。
因为最大池化层就是用来提取特征的

3. 非线性激活层代码实战
非线性激活层主要是为了给我们的网络模型引入一些非线性特质

如上图,很多数据并不是一条直线可以解决的。所以我们需要加入非线性。
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像、视频、语音等信号数据的分类与识别任务。其核心思想在于通过卷积和池化等操作提取特征,将输入数据映射到高维特征空间中。
非线性激活函数在卷积神经网络中扮演着至关重要的角色。它们不仅增强了模型的非线性建模能力,使得网络能够学习和逼近复杂的函数,同时也有效地解决了数据的不可分性问题,从而提高了模型的泛化能力和整体性能。如果没有激活函数,神经网络将仅能进行线性变换,这将极大限制其处理复杂问题的能力。
具体而言,每一层的输出将仅为输入的线性组合,无论网络的层数如何,其整体输出仍然只会是输入的线性组合。这意味着,缺乏激活函数的神经网络无法捕捉和表示数据中的非线性关系,进而大大削弱了其学习和拟合复杂模式的能力。
常见的激活函数有我们之前学习过的ReLu(也成为hard sigmoid),其形状如下:

还有一个时sigmoid函数,形状如下:

接下来进行代码实战:
可以看到在ReLu函数中有一个inplace变量需要输入(默认值为false)

其作用如下:

import torch
import torch.nn.functional as F
from torch import nninput = torch.tensor([[-1, 2, 0, 3, 1],[0, 1, 2, 3, -1],[1, 2, 1, 0, 0],[5, 2, -3, 1, 1],[2, 1, 0, 1, -1]])input = torch.reshape(input, (-1, 1, 5, 5))class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 定义池化层self.relu1 = nn.ReLU()# 使用在forward中加入池化层def forward(self, x):x = self.relu1(x)return xnet = Net()
output = net(input)
print(output)结果如下:

因为sigmoid对图像的变化比较明显,所以我们使用sigmoid结合CIFAR10数据集使用
代码如下:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./datasets', train=False, transform=torchvision.transforms.ToTensor(),download=True)# dataloader
test_loader = DataLoader(dataset=test_data, batch_size=64)class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 定义sigmoidself.sigmoid1 = nn.Sigmoid()# 使用在forward中加入sigmoiddef forward(self, x):x = self.sigmoid1(x)return xnet = Net()
# 使用Tensorboard
writer = SummaryWriter("logs_sigmoid")# 循环结构输入tensorboard
step = 0
for data in test_loader:imgs, targets = datawriter.add_images("input", imgs, step)output = net(imgs)writer.add_images("output", output, step)step += 1writer.close()启动tensorboard
tensorboard --logdir=logs_sigmoid --port=6007
结果如下:

其他的无非就是非线性的处理公式不同,在代码上是一样的道理。
主要要理解具体函数的公式内容
总结
这一周按照上一周的规划,继续对李宏毅的机器学习视频进行了和B站上的Pytorch视频进行了学习。学习的内容代码部分与前几周比较多,主要是对pytorch的代码实战的工作量上增加了。
在机器学习的理论部分中,学习了鱼和熊掌兼得的机器学习,其中复习了Deep learning的知识并分析了Deep为什么比Fat好,并在最后了解到了使用验证集后效果还是不好是由于用validation set决定模型的时候,待选择的模型太多造成的。在Pytorch学习中,对CNN的代码部分进行了学习,上一周引入了CNN结构和卷积的概念,这一周就对卷积层、池化层、非线性激活层进行了学习。其中卷积层和池化层在代码中需要注意的参数并不多,都是前几个参数,比如:kernel_size、batch_size、channel等等参数,其他的参数大多都是默认即可。但是需要注意的是卷积层的kernel_size是指卷积核的大小(其值是根据分布采样得到的);而池化层的kernel_size是指池化窗口的大小(就是一个窗口)需要区分清楚,然后非线性激活层,在代码层面很简单,但是后续如果要发论文,后续还要搞懂其函数公式以及细节内容。
最后计划还是按部就班继续对李宏毅的机器学习视频进行学习,争取学习到注意力机制(self-attention)的内容。Pytorch的学习也会持续跟进,下一周会把CNN部分完结并争取做一个小项目练练手,顺便复习之前的内容。尽量在开学前把Pytorch的内容学习完,但是进度也不会盲目加快,遵循一步三回头,多多复习之前的内容。
相关文章:
第八周:机器学习笔记
第八周机器学习笔记 摘要Abstract机器学习1. 鱼和熊掌和可兼得的机器学习1.1 Deep network v.s. Fat network 2. 为什么用来验证集结果还是不好? Pytorch学习1. 卷积层代码实战2. 最大池化层代码实战3. 非线性激活层代码实战 总结 摘要 本周学习对李宏毅机器学习视…...

音乐怎么剪切掉一部分?5个方法,轻松学会音频分割!(2024全新)
音乐怎么剪切掉一部分?音频文件是娱乐和创作的重要基础。音频在我们日常生活中发挥着重要作用,从音乐播放列表到有趣的视频,它无处不在。无论是音乐爱好者还是内容创作者,我们常常需要对音频文件进行剪切和编辑。想象一下…...

洛谷 CF295D Greg and Caves
题目来源于:洛谷 题目本质:动态规划dp,枚举 解题思路:将整个洞分成两半,一半递增,一半递减。我们分别 DP 求值,最后合并。状态转移方程为:dpi,jk2∑j(j−k1)dpi−1,k1。枚举极…...

【图像处理】在图像处理算法开发中,有哪些常见的主观评价指标和客观评价指标?
主观评价指标 在图像处理算法开发中,主观评价指标依赖于观察者的个人感受和判断,通常用于评估图像的视觉质量。以下是一些常见的主观评价指标: 平均意见分数 (Mean Opinion Score, MOS):通过收集多个评价者的评分并计算平均值来评…...

从零开始学cv-6:图像的灰度变换
文章目录 一,简介:二、图像的线性变换三、分段线性变换四,非线性变换4.1 对数变换4.2 Gamma变换 五,效果: 一,简介: 图像灰度变换涉及对图像中每个像素的灰度值执行数学运算,进而调整图像的视觉…...
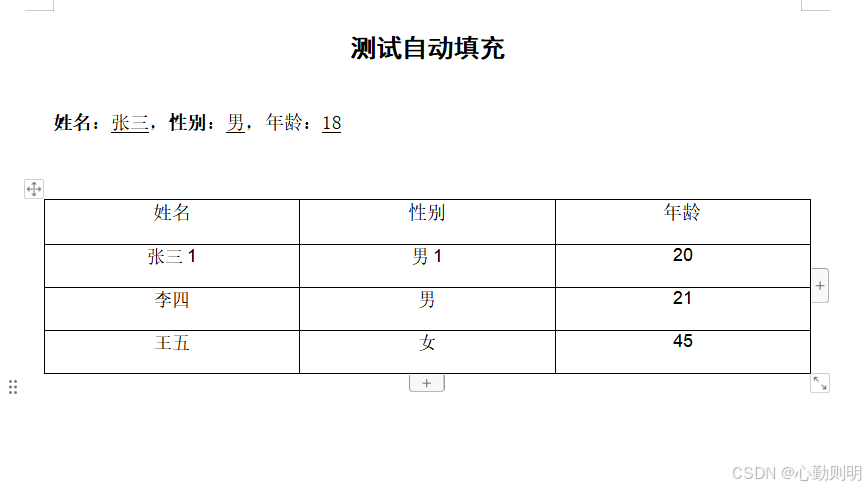
使用Apache POI和POI-OOXML实现word模板文档自动填充功能
最近接到一个新的需求,用户创建好模板文件保存到模板库,然后使用在线文档编辑器打开模板时,将系统数据填充到模板文件并生成新的word文件,然后在线编辑,研究使用Apache POI和POI-OOXML实现了这个功能。 Maven依赖 <…...

【HarmonyOS NEXT星河版开发学习】综合测试案例-各平台评论部分
目录 前言 功能展示 整体页面布局 最新和最热 写评论 点赞功能 界面构建 初始数据的准备 列表项部分的渲染 底部区域 index部分 知识点概述 List组件 List组件简介 ListItem组件详解 ListItemGroup组件介绍 ForEach循环渲染 列表分割线设置 列表排列方向设…...

垂直行业数字化表现抢眼 亚信科技全年利润展望乐观
大数据产业创新服务媒体 ——聚焦数据 改变商业 2024年8月14日,亚信科技控股有限公司(股票代码:01675.HK)公布了公司截至2024年6月30日的中期业绩。 财报数据显示,2024年上半年,亚信科技的营业收入为人民币…...

EmguCV学习笔记 VB.Net 4.1 颜色变换
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 教程VB.net版本请访问:EmguCV学习笔记 VB.Net 目录-CSDN博客 教程C#版本请访问:EmguCV学习笔记 C# 目录-CSD…...

【MySQL进阶之路】表结构的操作
目录 创建表 查看表 查看数据库有哪些表 查看表结构 查看表的详细信息 修改表 表的重命名 添加一列 修改某一列的属性 删除某一列 对列进行重命名 删除表 个人主页:东洛的克莱斯韦克-CSDN博客 【MySQL进阶之路】MySQL基础——从零认识MySQL-CSDN博客 创…...
3分钟搞定PDF转PPT!你一定要知道的3款转换神器!
在数字办公成为主流的当下,我们每天会收到各类基于数字化方式存储的办公文档,如PDF、PPT、Word、Excel文档等。 日常处理这些文档时,经常需要在不同格式的文档之间进行切换和转换,其中将PDF转换为PPT就是一个非常高频的需求&…...

【EasyExcel】导出excel-设置动态表头并导出数据
需求背景: 导出excel的设置某些表头动态导出(可以根据筛选条件或一些属性的数据量),方便导出后用户查看想看的信息。 一、技术选型: easyExcel的原生数据处理 二、方案设计: 根据EasyExcel支持的表头List<List<String>…...

深入探索 Elasticsearch 8:新特性与核心原理剖析(上)
深入探索 Elasticsearch 8:新特性与核心原理剖析 目录 一、引言 (二)版本 8 的重要意义 二、Elasticsearch 8 的新特性 三、Elasticsearch 的核心原理 一、引言 (一)Elasticsearch 简介 在大数据处理和搜索领域…...

瑜伽馆预约小程序,在线预约,提高商业价值
随着大众生活质量的提高,对休闲运动的关注逐渐加大,瑜伽作为一种身心放松、改善体态的运动,深受女性用户的喜爱。目前,各大瑜伽馆开始结合数字化,建立了新型的线上小程序,帮助大众快速预约体验瑜伽…...

Python--数据类型转换
在Python中,数据类型的转换是一个常见的操作,涉及将一种数据类型转换为另一种数据类型。Python提供了多种内置函数用于执行这种转换,如 int()、str()、float()、list()、tuple()、set()、dict() 等。下面详细讨论Python的基本数据类型及它们之…...

域控ntdsutil修改架构、域命名、PDC、RID、结构主机
#笔记记录# FSMO盒修改 1、提示访问特权不够,不能执行该操作,0x2098 清除缓存账号密码并修改新架构管理员账号密码即可。 背景:更替架构主机、域命名主机 C:\Windows\system32>ntdsutil ntdsutil: roles fsmo maintenance: ?? …...

解决 Swift 6 全局变量不能满足并发安全(concurrency-safe)读写的问题
概述 WWDC 24 终于在 Swift 十岁生日发布了全新的 Swift 6。这不仅意味着 Swift 进入了全新的“大”版本时代,而且 Swift 编译器终于做到了并发代码执行的“绝对安全”。 不过,从 Swift 5 一步迈入“新时代”的小伙伴们可能对新的并发检查有些许“水土不…...

迈入退休生活,全职开发ue独立游戏上架steam
决定退休了。算了算睡后收入,也可以达到每月一万一,正好可以养家糊口。 既然退休了,那就做些想做的事情,别人养花养草,而我打算开发独立游戏上架steam。 一,盘点下目前的技术体系。 1,图形学底…...

什么是光伏气象站——仁科测控
【仁科测控,品质保障】光伏气象站,这一专门为光伏发电系统设计的监测设备,其核心能力在于精确且实时地捕捉那些对光伏发电效率产生关键影响的气象因素。这些数据不仅为评估光伏电站的发电性能提供了重要依据,更是优化运维…...

webshell免杀--免杀入门
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 本文主要整理webshell免杀的一些基础思路 入门级,不是很深入,主要是整理相关概念 免杀对象 1.各类杀毒软件 类似360,火绒等,查杀己方webshell的软件。 2.各类流量…...

从休眠到唤醒:深入解读AUTOSAR CanNm的Bus Load Reduction与Immediate Restart机制
从休眠到唤醒:深入解读AUTOSAR CanNm的Bus Load Reduction与Immediate Restart机制 在新能源汽车和智能座舱快速发展的今天,车载电子系统的功耗优化与实时响应能力成为工程师面临的核心挑战。AUTOSAR CanNm模块作为车载网络管理的关键组件,其…...

消息队列的缓冲作用:不止于临时暂存
在分布式系统架构中,消息队列常被提及的一个核心价值是“解耦”。然而,除了降低系统间的直接依赖之外,消息队列还承担着另一个关键角色——缓冲。很多人直观地感受到“消息队列能起到缓冲效果”,但这种缓冲究竟意味着什么…...

避坑指南:通达信指标加密的4种方法实测,哪种最难被破解?
通达信指标加密技术深度测评:从入门到防破解实战 在量化交易和个性化指标分析领域,通达信作为国内主流证券分析软件,其自定义指标功能一直备受投资者青睐。但随之而来的指标被盗用、滥用问题也让许多开发者头疼不已——一个经过数月验证的高胜…...

CIC-IDS-2018数据集 代码预处理
CIC-IDS-2018数据集 预处理 数据集的获取地址在 https://aistudio.baidu.com/datasetdetail/60692 第一次登陆,注册就行,内容随便填就能注册 create_sample_data() 在代码中被注释,没有添加数据之前,可以跑一下这个函数&…...

开源串流新选择:用Sunshine打造跨设备游戏共享系统
开源串流新选择:用Sunshine打造跨设备游戏共享系统 【免费下载链接】Sunshine Sunshine: Sunshine是一个自托管的游戏流媒体服务器,支持通过Moonlight在各种设备上进行低延迟的游戏串流。 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine …...
)
FPGA开发实战:GT收发器配置避坑指南(附8B10B与64B66B编码对比)
FPGA开发实战:GT收发器配置避坑指南(附8B10B与64B66B编码对比) 在高速数字电路设计中,GT收发器作为FPGA与外部世界的高速数据通道,其配置的精确性直接决定了系统稳定性。本文将深入探讨GT收发器配置中的关键细节&#…...
)
告别混乱标注!手把手教你定制LabelImg的标注框颜色与样式(附打包exe完整流程)
视觉标注效率革命:LabelImg高级定制与团队部署实战指南 在计算机视觉项目的标注环节中,混乱的视觉呈现往往成为效率瓶颈。当标注员面对数百张包含"车辆"、"行人"、"交通标志"等多类别的图像时,系统随机分配的标…...

PCL2-CE社区版启动器:终极指南打造个性化Minecraft游戏中心
PCL2-CE社区版启动器:终极指南打造个性化Minecraft游戏中心 【免费下载链接】PCL-CE PCL2 社区版,可体验上游暂未合并的功能 项目地址: https://gitcode.com/gh_mirrors/pc/PCL-CE PCL2-CE社区版启动器是一款功能强大的开源Minecraft启动工具&…...

如何突破抖音内容保存限制?开源工具douyin-downloader的创新解决方案
如何突破抖音内容保存限制?开源工具douyin-downloader的创新解决方案 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 在数字内容爆炸的时代,抖音已成为知识传播与创意展示的重要平台。…...

告别默认ResNet-50:为你的病理图像特征提取,升级CLAM+CONCH v1.5的保姆级指南
告别默认ResNet-50:为你的病理图像特征提取,升级CLAMCONCH v1.5的保姆级指南 在病理图像分析领域,特征提取的质量直接影响下游任务的性能表现。许多研究者发现,使用默认的ImageNet预训练ResNet-50模型提取的特征,往往…...