Redis核心知识点
Redis核心知识点
- Redis核心知识点大全
- 五种数据类型
- redis整合SpringBoot
- 序列化问题
- 渐进式扫描
- 慢查询
- 缓存相关问题
- 数据库和缓存谁先更新
- 缓存穿透
- 缓存雪崩
- 缓存击穿
- 实际应用
- 超卖问题
- 分布式锁
- 全局唯一ID
- 充当消息队列
- Feed流
- 附近商户
- 签到
- HyperLogLog实现UV统计
- 持久化
- RDB
- AOF
- 持久化小结
- 事件循环
- 过期键
- 数据库
- 过期键保存
- 删除策略
- RDB和AOF
- 复制
- 主从复制
- 同步
- 命令传播
- 部分重同步实现
- PSYNC命令
- 完整复制过程
- 优化
- 哨兵
- 分片集群
- 多级缓存
- 缓存同步
- 底层数据结构
- SDS(简单动态字符串)
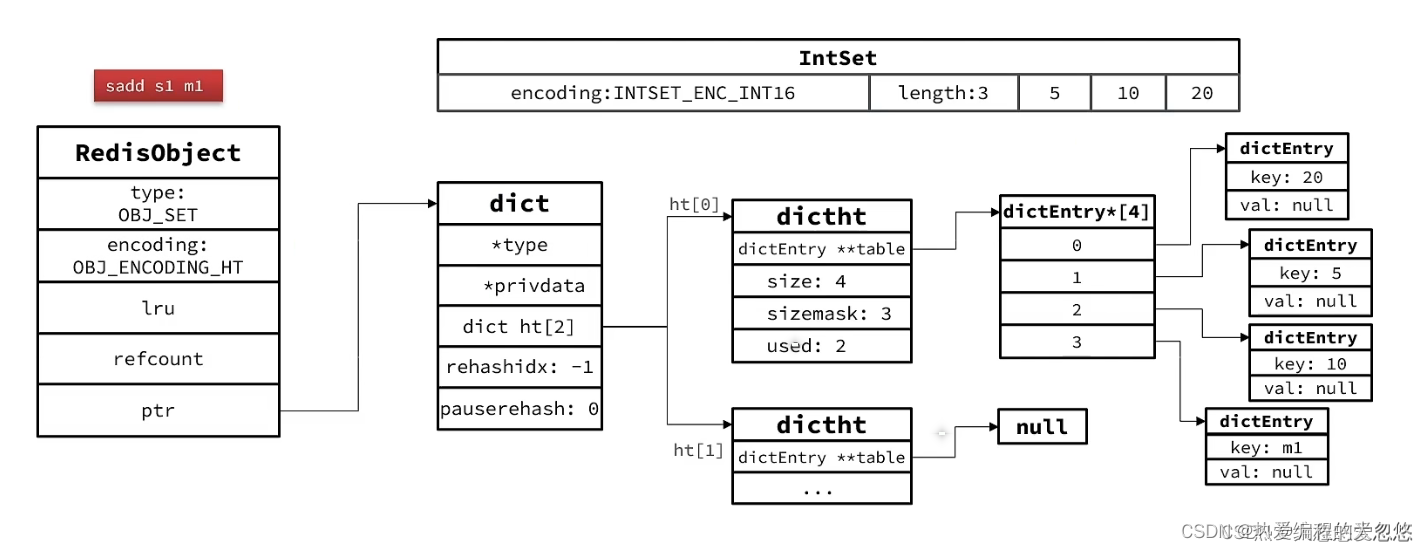
- IntSet(整数集合)
- Dict(字典)
- zipList(压缩列表)
- quickList(快速链表)
- skipList(跳跃表)
- Redis对象系统
- String对象
- 列表对象
- 集合对象
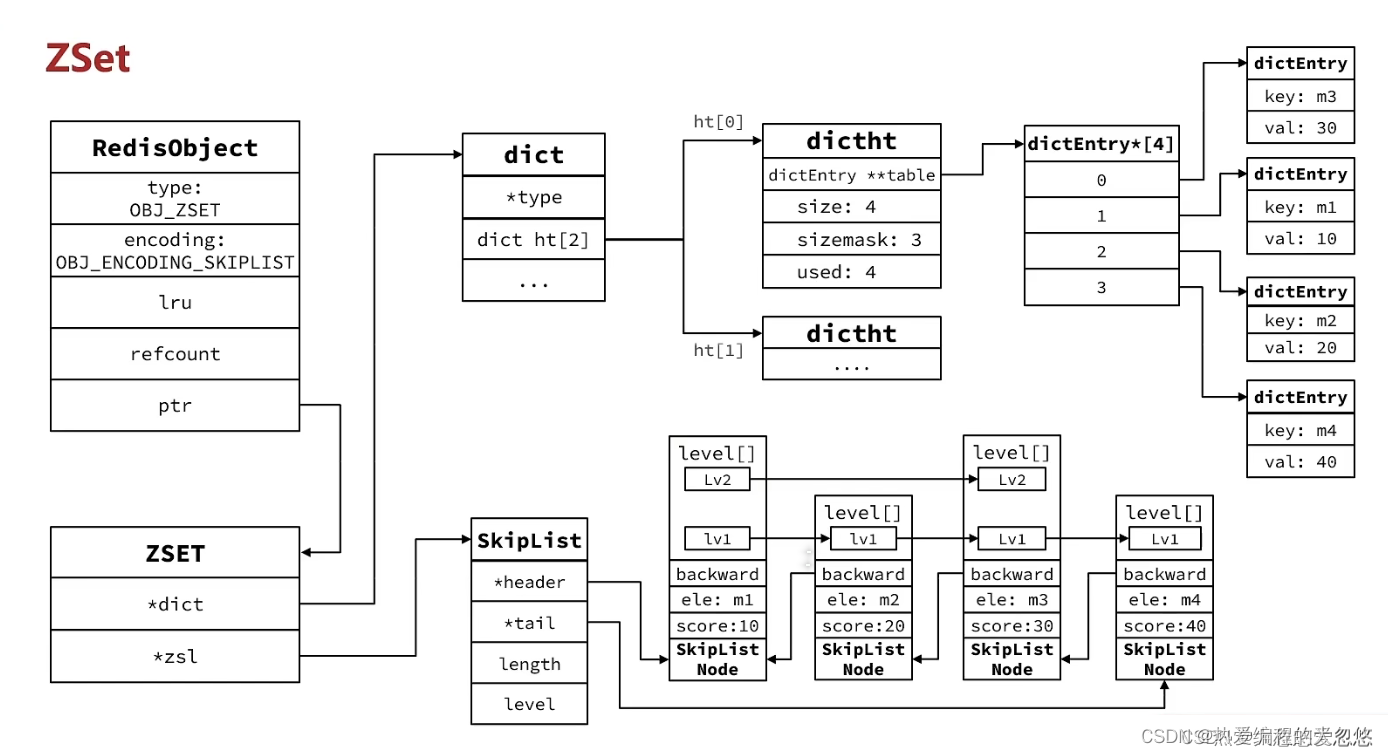
- 有序集合
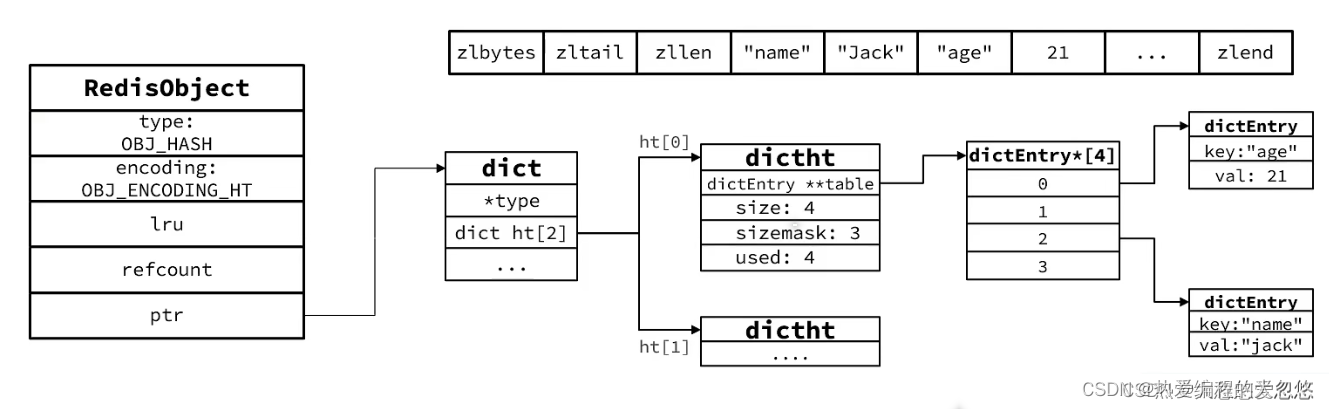
- hash对象
- Redis最佳实践
- bigKey问题
- 批处理
- 内存淘汰策略
- 发布订阅和事务
整理的只是一部分核心知识点,不全。
Redis核心知识点大全
tips: 只列举核心知识点的概要,完整知识点可以参考 redis设计与实现一书以及随篇附上的文章链接
五种数据类型
1.字符串
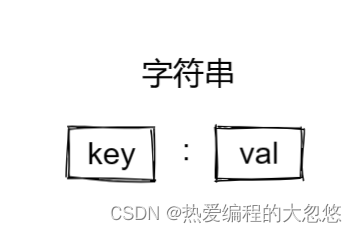
- 常用命令:
set key valget keymset key1 val1 key2 val2 ...mget key1 key2 ...incr key1 #自增1incrby key1 num #让key1自增numsetnx key val #key存在不执行,否则执行setex key ttl val #指定过期时间
2.列表
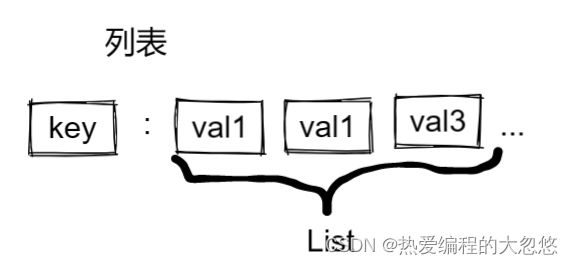
- 常用命令:
lpush key val1 val2 ... #左侧插入多个元素
lpop key #从左边移除一个元素,没有元素返回nil
rpush key val1 val2 ... # 右侧插入多个元素
rpop key #右边移除一个元素
lrange key start end
blpop key timeout 和 brpop key timeout #弹出元素,如果列表为空就阻塞指定时间
3.集合
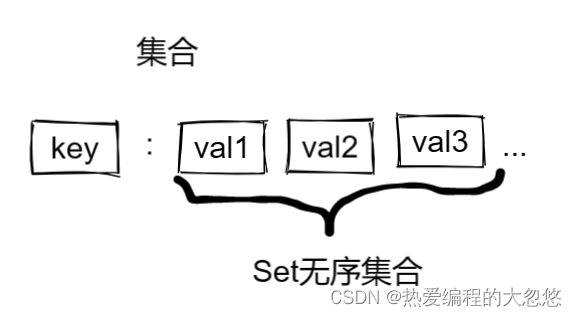
- 常用命令:
sadd key val1 val2 ....
srem key val1 val2 ... # 移除set中指定元素
scard key #返回set中元素个数
sismember key val1 #判断一个元素是否存在于set中
smembers key #获取set中所有元素
sinter key1 key2... # 求多个set集合之间的交集
sdiff key1 key2... # 求多个set集合之间的差集
sunion key1 key2... # 求讴歌set集合之间的并集
4.散列
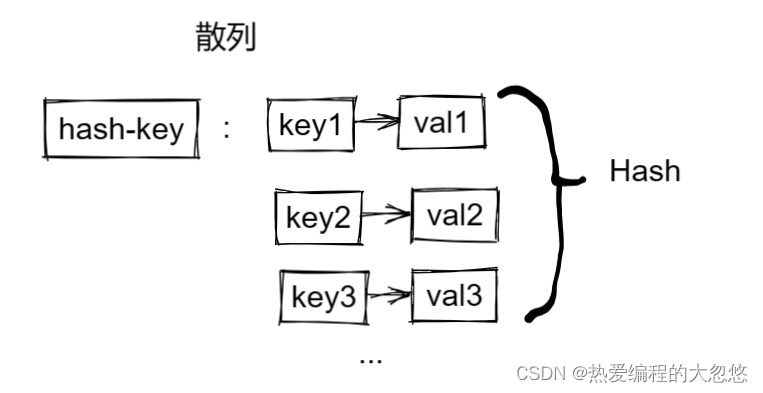
常用命令:
hset hash-key field value
hget hash-key field
hmset hash-key field1 value1 field2 value2 ...
hmget hash-key field1 field2 ...
hgetall hash-key
hkeys hash-key
hvals hash-key
hincrby hash-key field num
hsetnx hash-key filed value #添加field成功的前提是不存在
5.有序集合
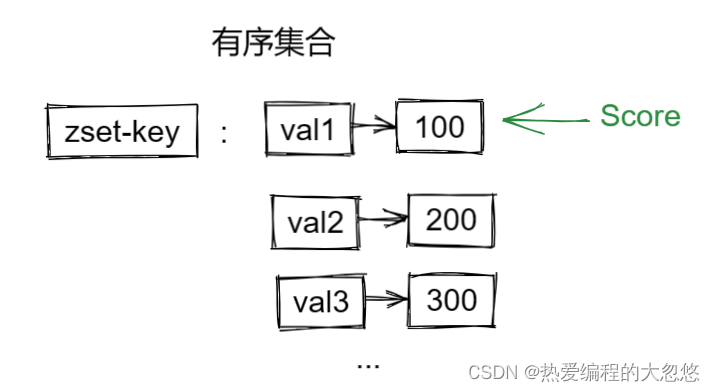
常用命令:
zadd zset-key score val # 还可以附加额外参数控制,参考官方文档
zrem zset-key val
zscore zset-key val # 获取某个val的score
zrank zset-key val # 获取某个val的排名
zcard zset-key #获取zset中的元素个数
zcount zset-key min max # 统计score在给定范围内的val个数
zincrby zset-key num val # 让指定val对应的score增加指定值
zrange key min max # 按照score排序后,获取指定排名范围内的元素
zrangebyscore key min max # 按照score排序后,获取指定score范围内的元素
zdiff,zinter,zunion #求差集,交集和并集
#注意: 所有的排名默认都是升序,如果要降序,在命令的Z后面添加REV即可
redis整合SpringBoot
序列化问题
RedisTemplate底层默认使用JDK序列化来将key和value输出为字节数组:
通过向容器中注入一个RedisTemplate替换默认的redis自动配置:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){//创建templateRedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();//设置连接工厂redisTemplate.setConnectionFactory(redisConnectionFactory);//设置序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();//key和hashKey采用String序列化redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());//value和hashValue用JSON序列化redisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;}}
如果你的key也想存对象,那么就不要使用RedisSerializer.string(),转而使用jsonRedisSerializer
渐进式扫描
keys命令会遍历所有键,在数据量很大的情况下会阻塞redis主线程执行,并且还可能会造成网络拥塞。
scan命令采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,通过类似分页的处理方式,每次扫描一部分key。
scan cursor [match pattern] [count number]
- cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标值,直到游标值为0,表示遍历结束
- match pattern是可选参数,过滤出符合条件的指定key
- count number指明每次遍历的键的个数,默认为10
Redis提供了面向哈希类型,集合类型,有序集合的扫描遍历命令:
- hgetall —> hscan
- smembers —> sscan
- zrange —> zscan
ps: 如果在scan过程中有键增删改变化,那么遍历过程可能会遇到新增的键没有遍历到,遍历出现重复键的情况,也就是说scan过程不保证完整遍历出来所有的键。
慢查询
redis执行一条命令的过程大体分为以下四个部分:
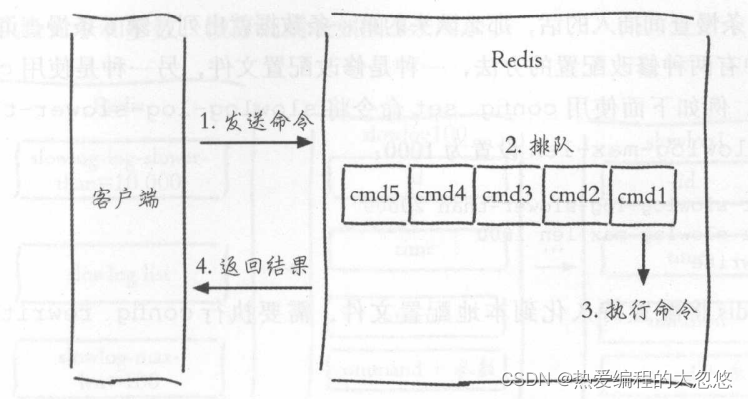
慢查询只统计第三步命令执行过程,所以没有慢查询不代表客户端没有超时问题。
我们需要关心慢查询两件事:
1.相关阈值如何设置?
- slowlog-log-slower-than : 默认值为10000 , 单位是微秒 , 如果某个命令执行时间超过了10毫秒,那么该命令会被记录在慢查询日志中。
slowlog-log-slower-than=0会记录所有命令,小于0不会记录任何命令
- slowlog-max-len: 说明慢查询日志最多存储多少条记录, redis使用一个列表来存储慢查询日志,该参数就是用来控制该列表的最大长度,一个新的慢查询命令被插入列表时,如果此时慢查询日志列表已经处于最大长度,那么最早插入的一个漫查询命令会从列表中移出 , 默认值为128。
在Redis中有两种修改配置的方法,一种是修改配置文件,另一种是使用config set命令动态修改:
config set slowlog-slower-than 20000
config set slowlog-max-len 1000
config rewrite
config rewrite命令负责将配置持久化到本地配置文件:
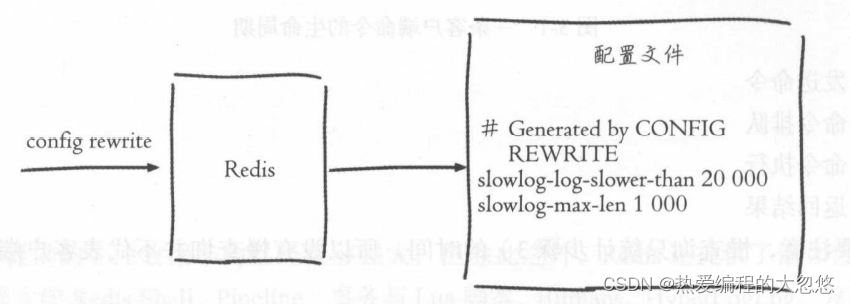
Redis没有暴露存储慢查询日志的列表键,我们只能通过下面一组命令来实现对慢查询日志的访问和管理:
-
获取慢查询日志
slowlog get [n]

每个慢查询日志由四部分组成:
-
慢查询日志标识id
-
发生时间戳
-
命令耗时
-
执行命令和参数
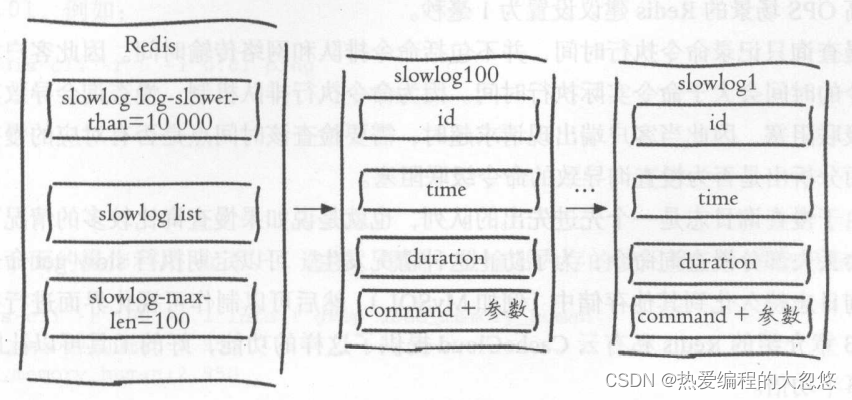
-
获取慢查询日志列表当前的长度
slowlog len -
慢查询日志重置
slowlog reset
缓存相关问题
数据库和缓存谁先更新
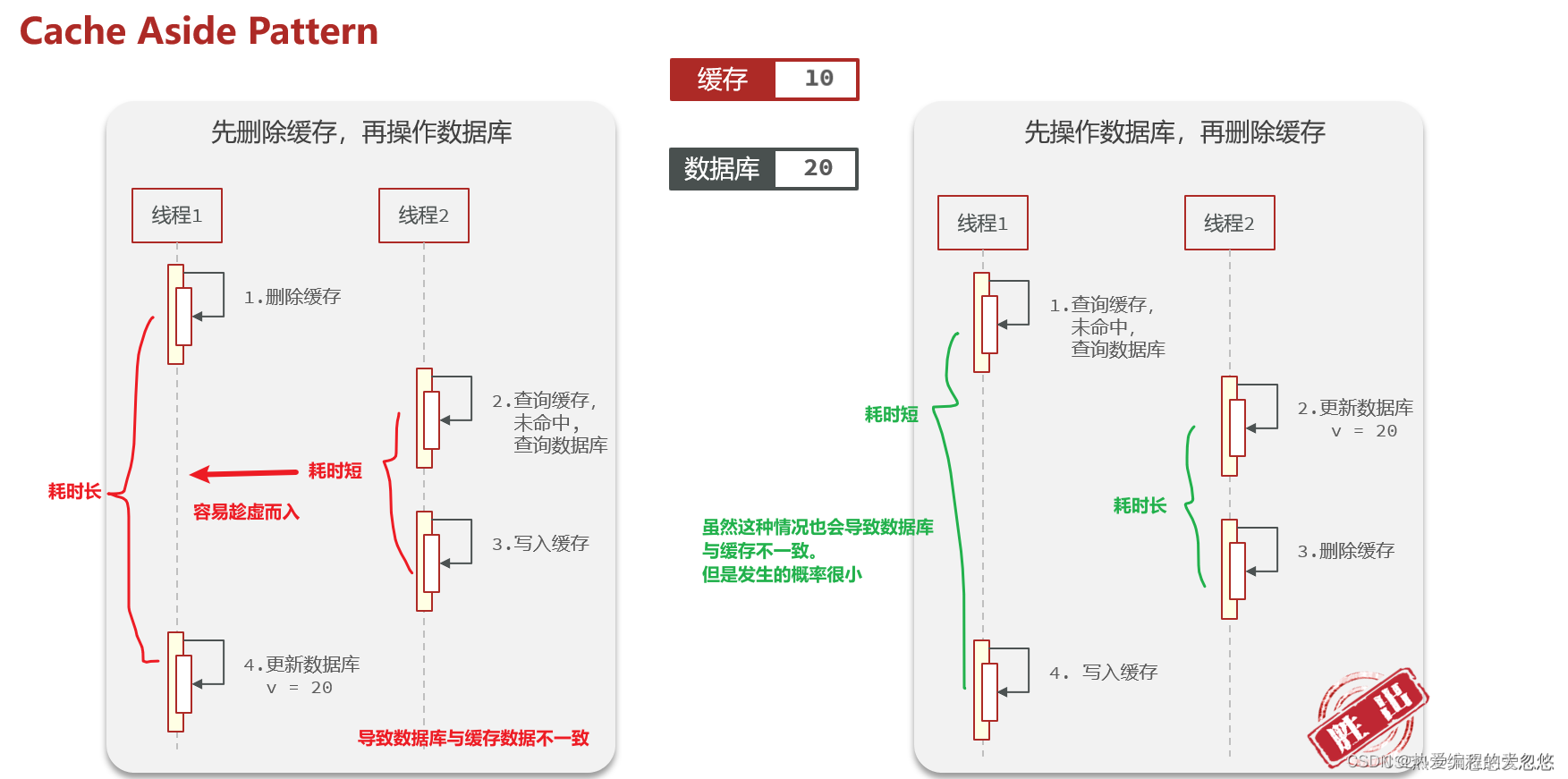
Innodb存储引擎采用了change buffer延迟写操作,这样一来写入更新操作未必一定比查询慢 ,如果buffer pool此时没有缓存对应页面,而需要从磁盘加载,那么查询速度反而会比更新慢。
缓存穿透
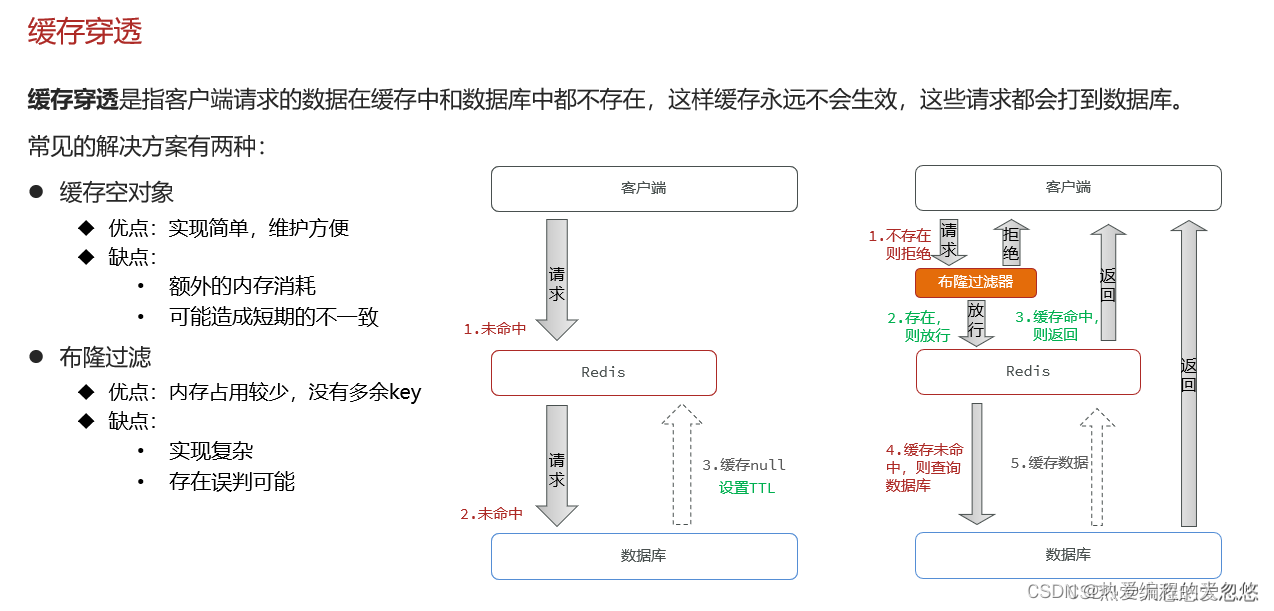
布隆过滤器的特点: 如果布隆过滤器告诉你某个key不存在,那么就一定不存在,如果说存在,那么可能存在也可能不存在。
在业务层面做好参数合法性校验,避免恶意攻击伪造的非法参数,同时拉黑攻击者的IP。
spring-cache模块默认是开启了缓存空对象功能的
缓存雪崩
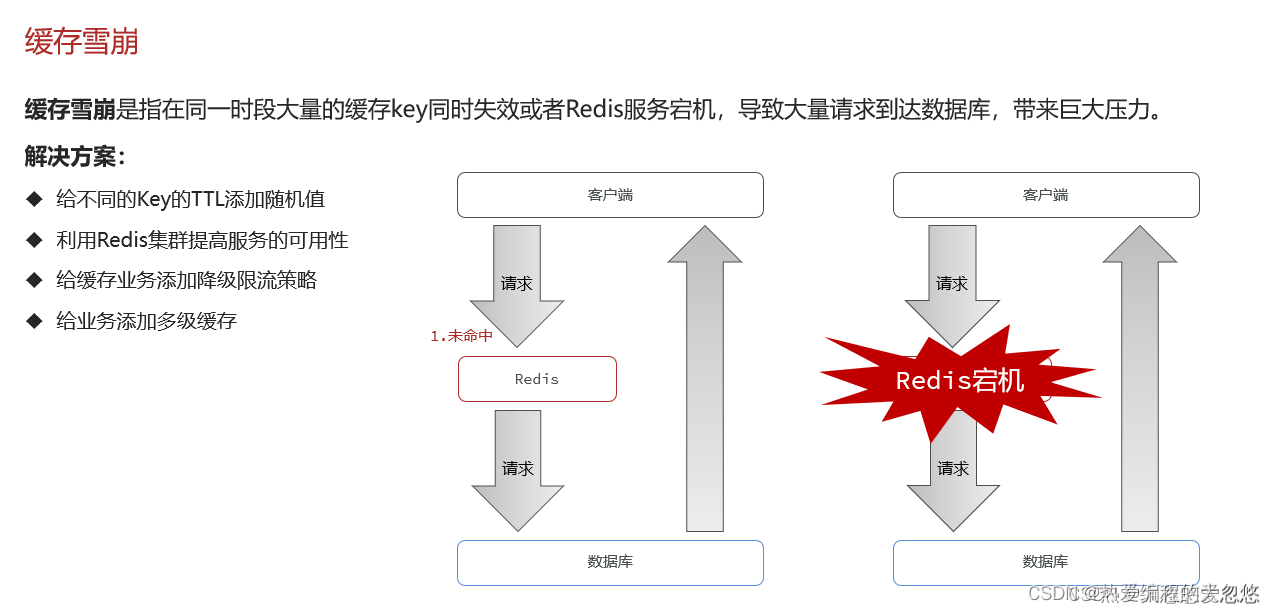
还可以利用定时任务定时刷新缓存过期时间。
缓存击穿
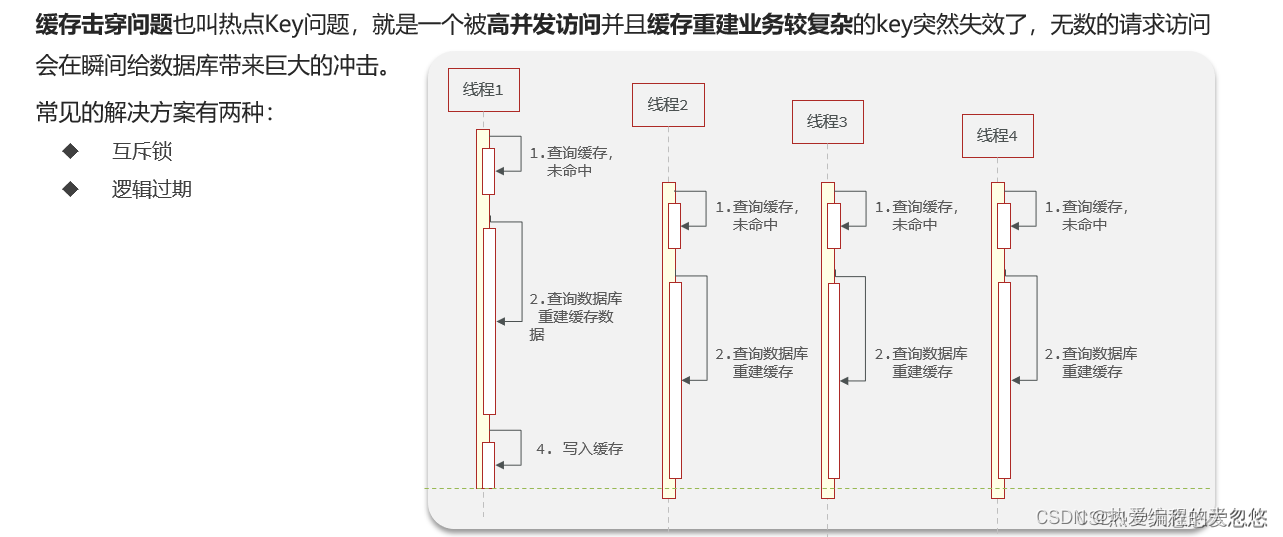
互斥锁和逻辑过期解决缓存击穿的思路
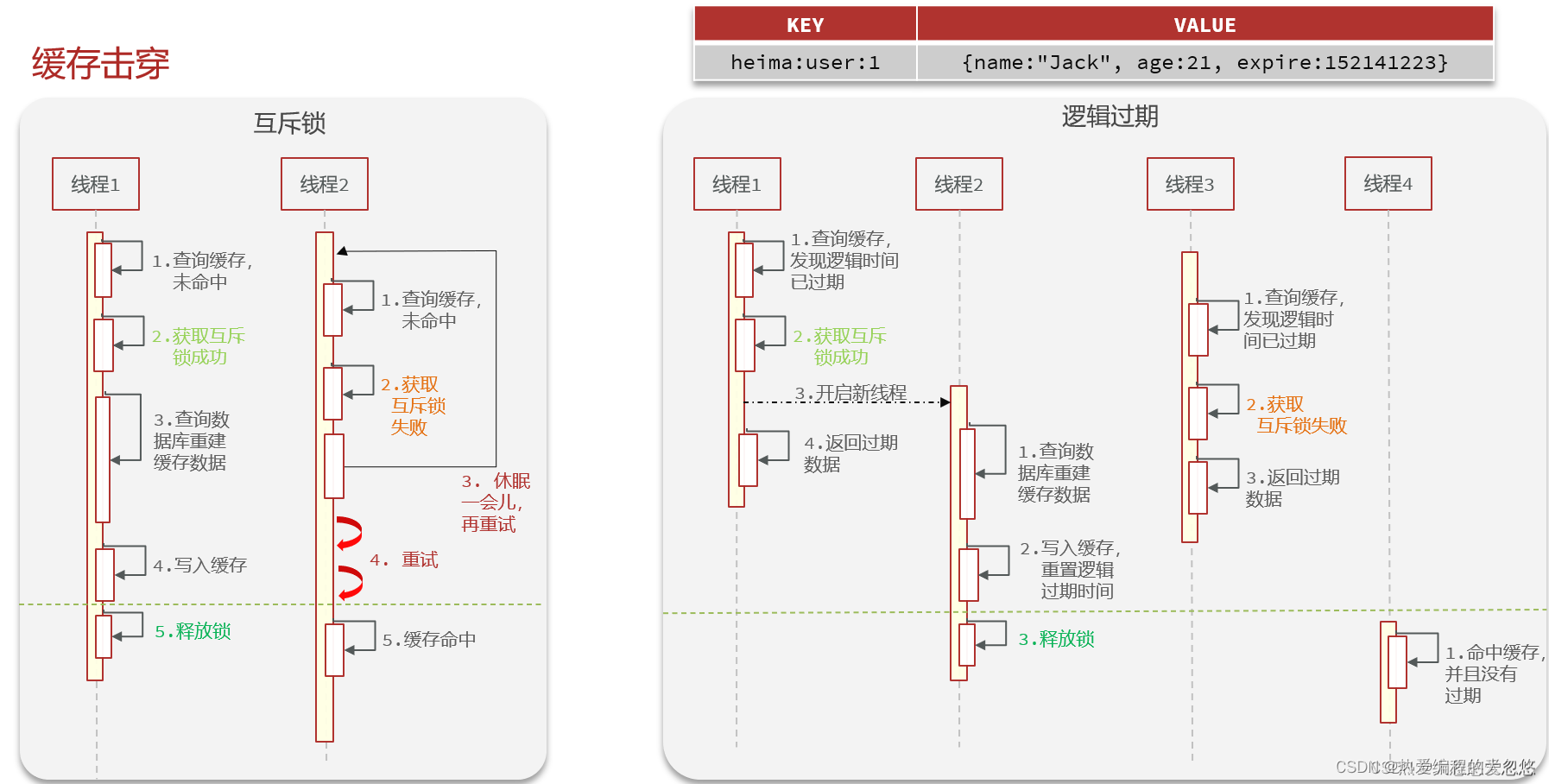
互斥锁的实现其实很简单,既然热点key过期失效了,并且同时有很多个请求打进来,尝试重构缓存,那么就用一把锁,只让第一个请求去重构缓存,其余的请求线程就等待加重试,直到缓存重构成功
而对于逻辑过期的思路来讲,既然是因为热点key过期导致的缓存击穿,那我我就让这些热点key不会真的过期,而通过增加一个逻辑过期字段,每一次获取的时候,先去判断是否过期,如果过期了,就按照上图的流程执行。
实际应用
超卖问题
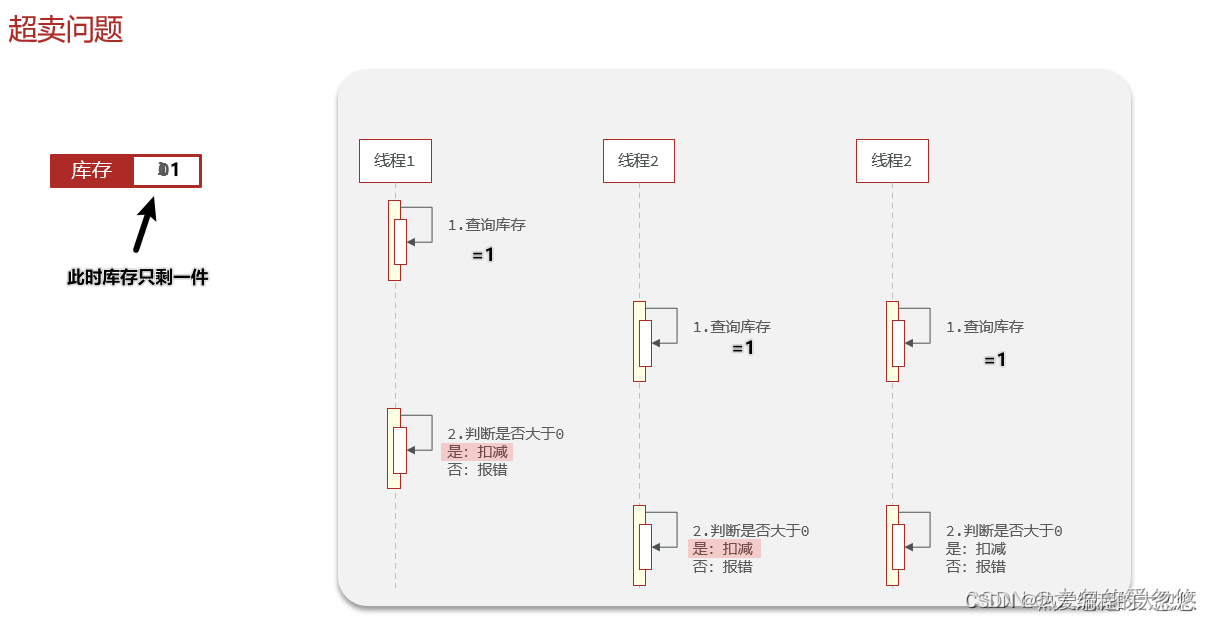
超卖问题实际是典型的 "查询-修改-写入"原子性问题。
- 乐观锁解决

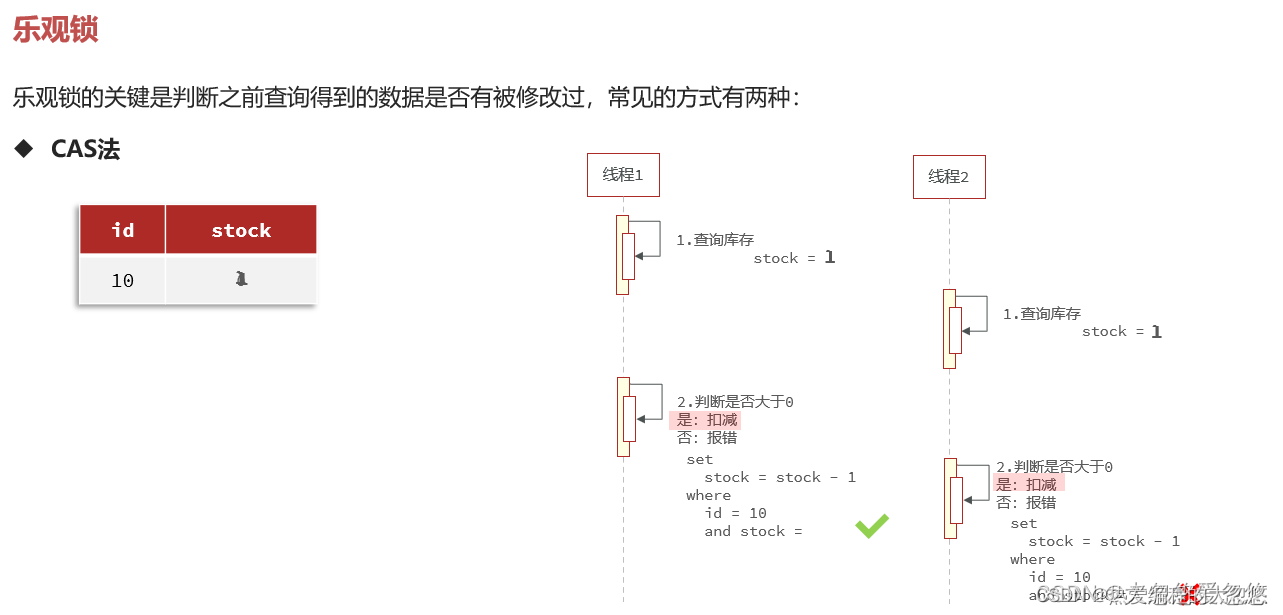
上面做法存在的问题在于多个线程同时购买商品时,只有一个线程能成功,即使在商品还剩余多份的情况下。
采用cas法时,可以stock=一开始查询出的stock值 改为 stock>0
分布式锁
超卖问题的悲观锁解法就是采用锁机制,而在分布式环境下肯定不能采用JVM级别的锁,需要采用分布式锁。
redis实现分布式锁最简单的方式就是采用setnx key val的方式 , 但是考虑到锁无法被释放的情况,需要给锁加上过期时间。
为了让获取锁和设置过期时间两个操作原子化执行,防止获取完锁后系统奔溃导致分布式锁无法被释放的情况发生,可以采用: set lock thread1 NX EX 10 的方式。
释放分布式锁时存在因为锁超时提前释放,导致锁被误删的情况发生, 解决这个问题的办法是给分布式锁加上标识, 可以是单个运行的程序实例通过一个特定的UUID加上当前线程ID作为锁标识进行区分,然后释放锁时判断当前锁是否还是自己持有,如果是才会进行释放。
释放锁时,判断标识和释放锁两个步骤如果不能原子化执行,也会存在锁被误删情况发生。
因此,最终我们采用lua脚本的方式,来确保释放锁的多条命令间的原子化执行。
在主从环境下,可能会因为主节点突然奔溃,导致分布式锁丢失情况发生,这样情况下可以考虑采用分片集群,通过联锁的方式解决上面的问题。
还包括锁重入问题,可以将存储锁的数据结构改为hash,从而可以额外存储一个锁计数,通过锁标识判断当前是否是锁重入,思路和jdk的可重入锁一致。
Redis进阶学习03—Redis完成秒杀和Redis分布式锁的应用
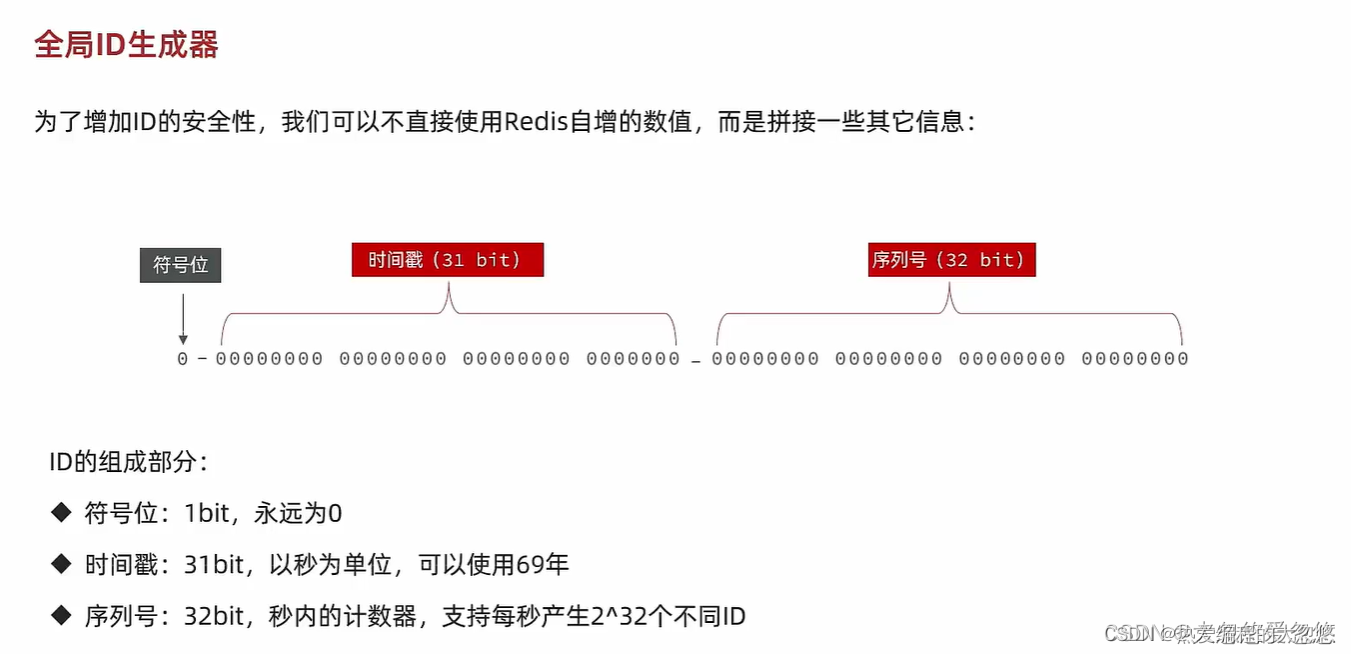
全局唯一ID
在分布式环境下,如果有需要生成全局唯一ID的需求,有下面几种解决办法:

使用Redis生成全局唯一ID可以采用下面的方法:
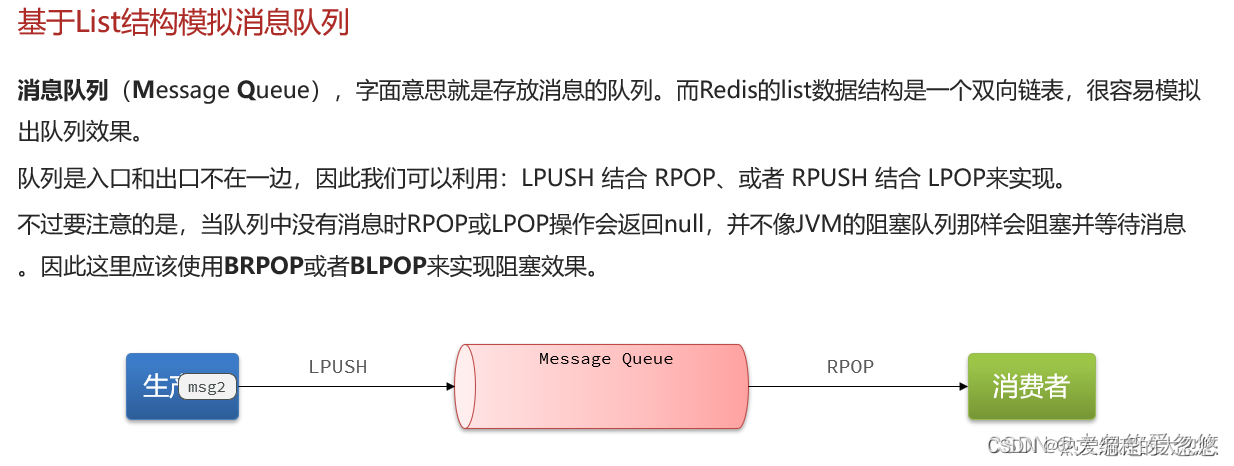
充当消息队列
redis实现消息队列有三种方式:
- list列表

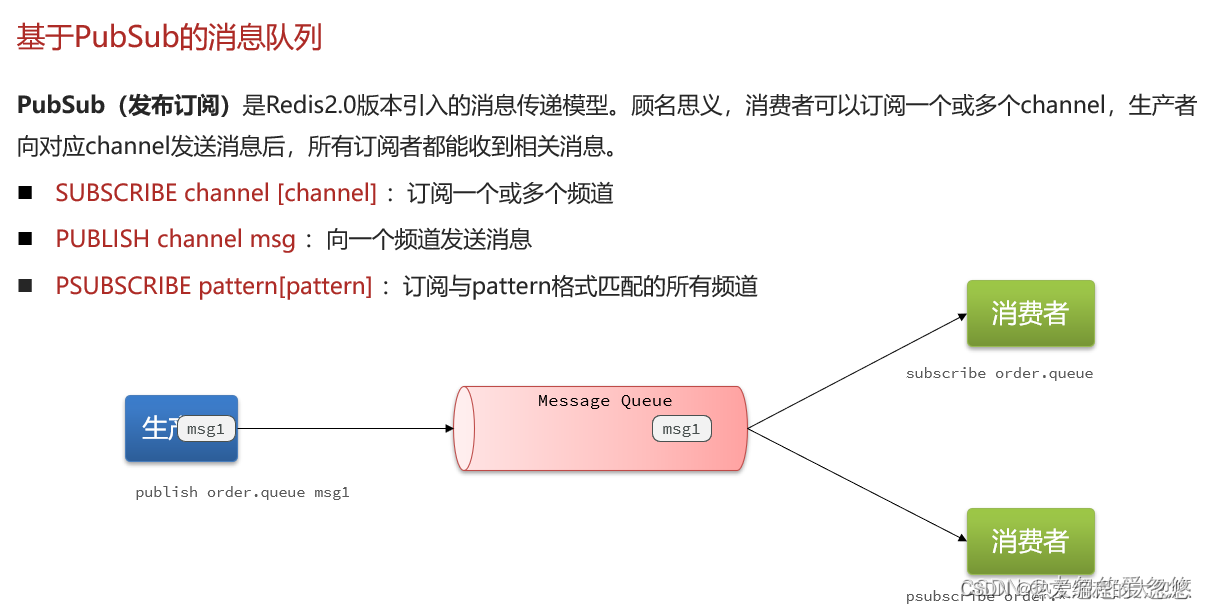
- PubSub机制

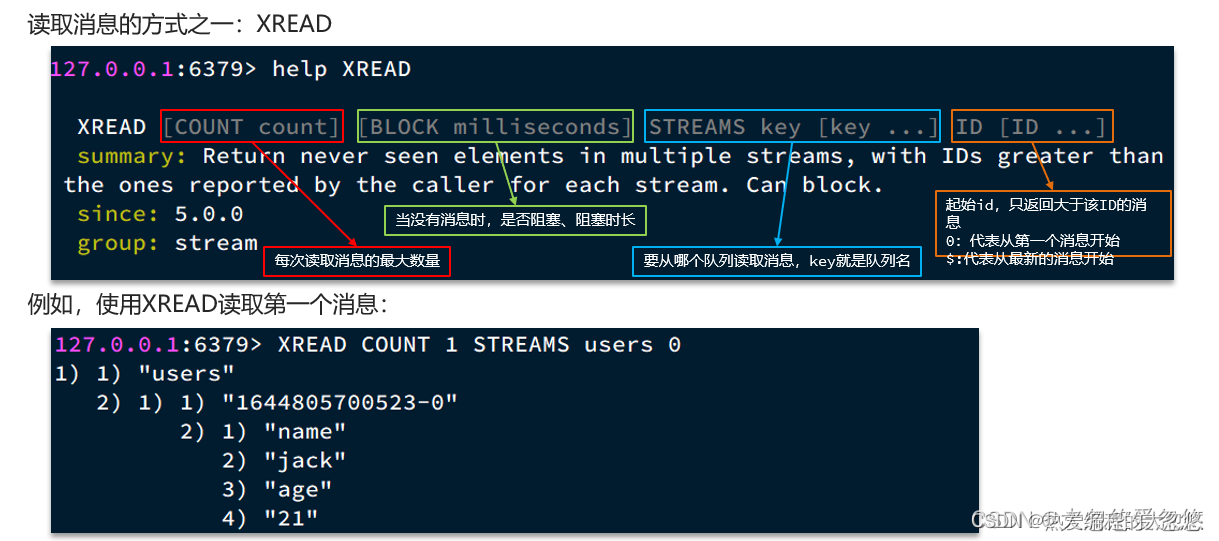
- stream实现消息队列


Redis进阶学习04—秒杀优化和消息队列
Feed流
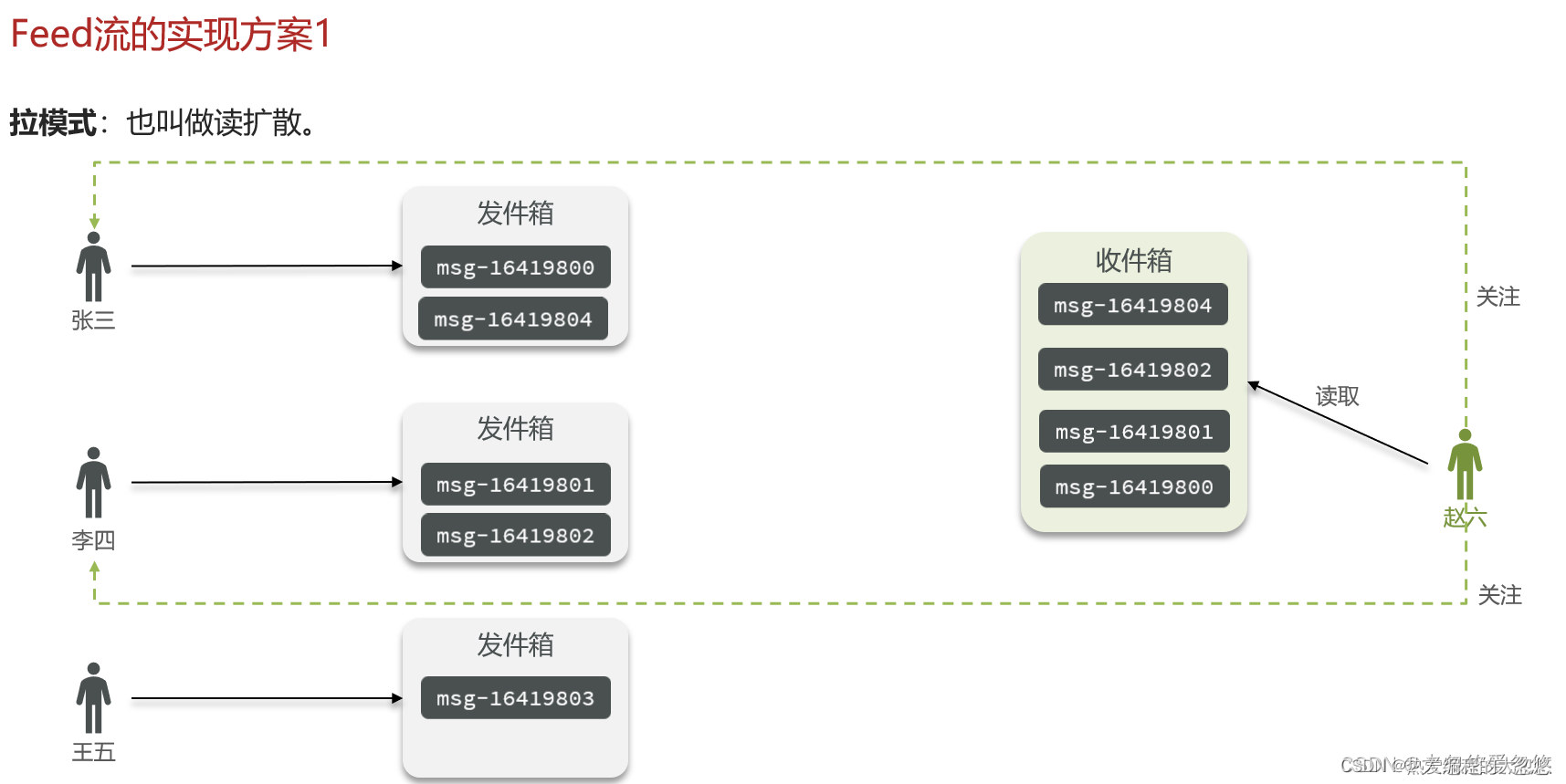
拉模式顾名思义就是用户主动去拉取他所关注的用户发布的信息,该模式最大缺点是延迟高,因为一下子需要去拉取大量的消息,优点是占用内存少,因为消息只需要存一份在发件箱
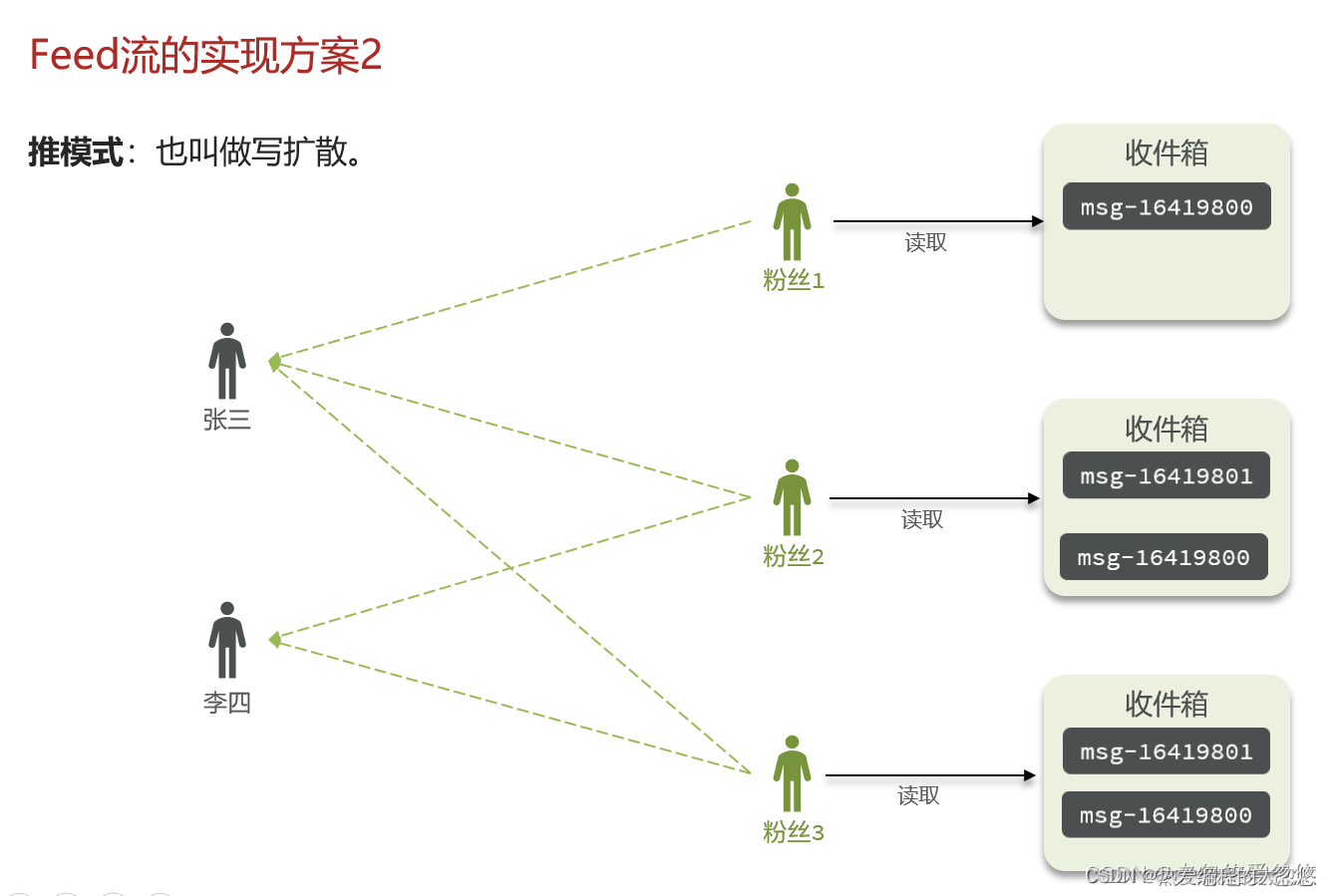
推模式就是用户在发消息的时候,不会先将消息放入收件箱等着粉丝来取,而是直接把这些消息发送给所有关注了他的粉丝们,这样粉丝读取消息的延迟低了,因为不需要再去拉取一遍了。最大的缺点是每一份消息都需要被赋值多份进行存储,对内存消耗大
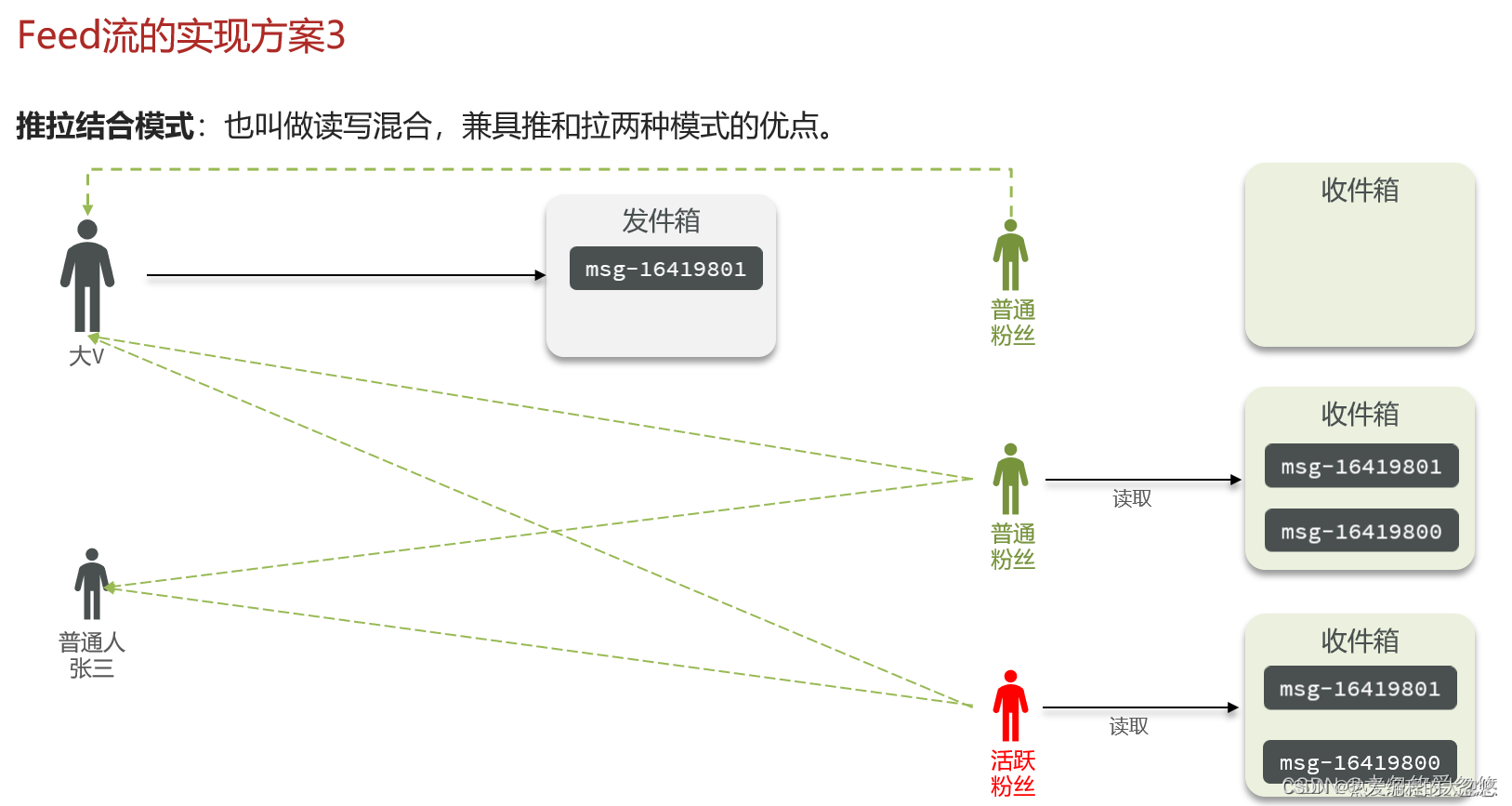
活跃用户可以采用推模式,减少每次获取消息的延迟。
不活跃用户可以采用拉模式,节约内存。
对于大V可以采用拉模式,避免同一份消息保存多份。
对于Feed流中涉及到的收件箱和发件箱可以采用redis进行实现,利用zset实现用户端分页下拉刷新。
附近商户

Geo底层采用zset进行存储。
可以在商户注册时,将对应实际物理店铺位置导入redis的geo数据结构保存,然后利用该数据结构完成附近商铺查询功能。
签到
可以利用bitmap完成签到,如果是按月统计签到信息,可以在每个用户初次登录时,在redis为该用户分配一个当前月大小的BitMap,然后设置当前天对应的位置为1。
利用bitmap相关命令可以统计本月签到的总天数,利用利用位运算可以快速计算出本月连续签到天数。
HyperLogLog实现UV统计

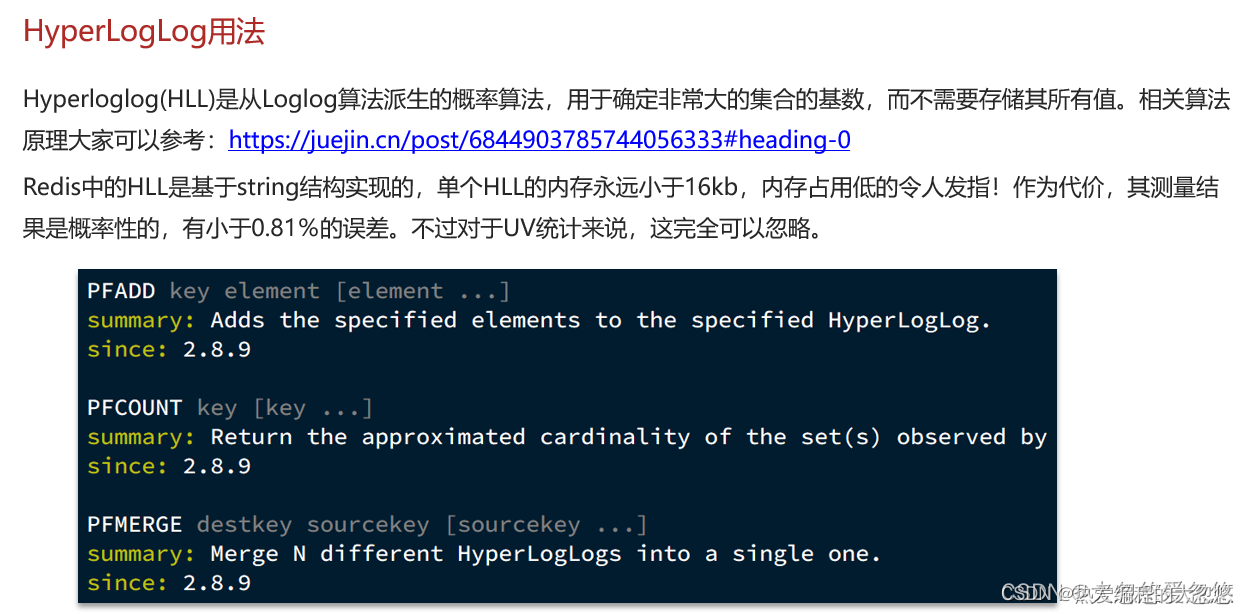

Redis进阶学习05—Feed流,GEO地理坐标的应用,bitmap的应用,HyperLogLog实现
持久化
RDB
tips: RDB全称为 Redis Database Backup file
rdb持久化会在以下四种情况下执行:
- 执行save命令(由服务器进程执行,会阻塞服务器)
- 执行bgsave命令(由fork出的子进程执行)
- redis停机时
- 触发RDB条件时
# redis默认开启RDB持久化,默认配置如下
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
tips: 因为BGSAVE命令不会阻塞服务器进程执行,因此Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令
Redis服务器周期性操作函数serverCron默认每隔100毫秒执行一次,该函数用于对正在运行的服务器进行维护,它其中一项工作就是检查save选项设置的保存条件是否满足,如果满足的话,就执行BGSAVE命令:
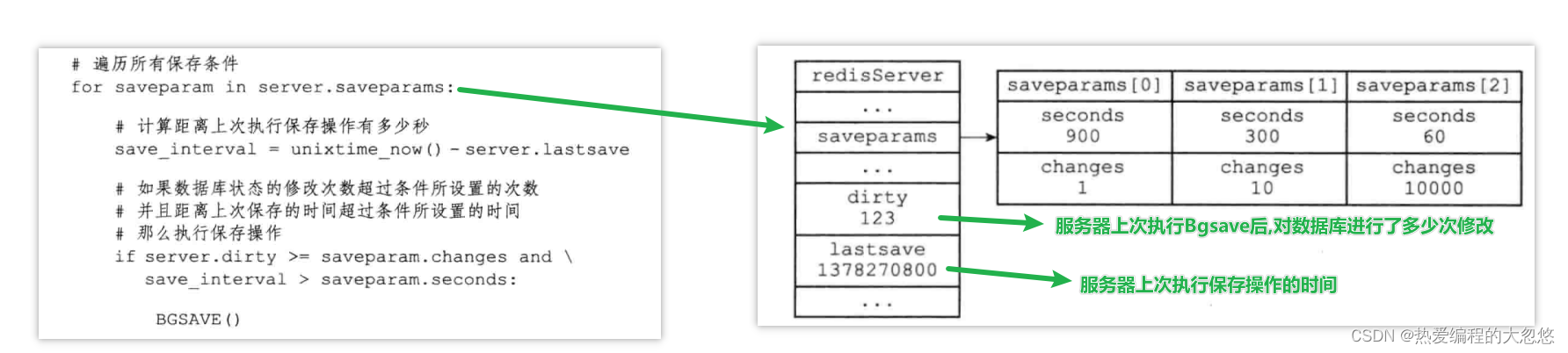
RDB文件载入时机 : Redis服务器在启动时如果检测到RDB文件存在,它就会自动载入RDB文件。
RDB文件是一个经过压缩的二进制文件,生成RDB文件的过程就是遍历redis数据库中所有key,然后根据key代表的不同数据类型,将其序列化为不同格式的二进制数据,最终用新生成的RDB文件替换旧的RDB文件。
缺点:
- RDB是间隔执行的,存在数据丢失风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF
AOF全称为Append Only File ,采用追加的方式,将redis执行的所有命令都记录在AOF文件中。
AOF默认是关闭的,我们可以通过修改配置开启:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
tips: 与RDB将键值对按照指定格式序列化保存为二进制文件不同,AOF是将每次执行的命令按照redis通信协议格式简单记录到命令日志文件中保存的
AOF原理:
- 服务器每执行完一个写命令,会以命令请求协议格式将被执行的写命令追加到服务器的aof_buf缓冲区的末尾

- Redis服务器进程就是一个事件循环,这个循环中文件事件负责接收客户端命令请求,然后进行命令回复,而时间事件负责执行像serverCron函数这样需要定时运行的函数。因为服务器处理文本事件时会产生写命令,使得一些内容被追加到aof_buf缓冲区,因此在服务器每次结束一个事件循环前,都会调用相关函数检查是否需要将aof_buf缓冲区内容同步到AOF文件里面。

flushAppendOnlyFile判断是否同步的依旧结束我们在配置文件中配置的appendfsync选项的值:

tips:

AOF还原过程:
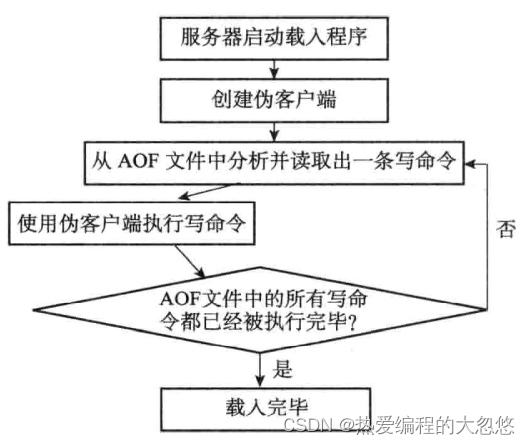
tips: redis命令只能在客户端上下文中执行,命令通常来自网络连接,此处来自AOF文件
AOF重写机制:
- 为了避免AOF文件因为大量冗余命令占据存储空间,可以采用redis提供的AOF重写机制解决冗余命令重复存储。
AOF重写机制是通过遍历数据库当前所有键,然后用一条命令去记录键值对代替之前记录这个键值对的多条命令:


因为aof_rewrite函数生成的新的AOF文件只包含还原当前数据库状态所必须的命令,所以新的AOF文件不会浪费任何磁盘存储空间。
aof_rewrite函数中涉及大量写入操作,如果放在redis主进程执行会阻塞客户端命令处理,因此redis是将aof执行过程放到子进程中完成的。
aof后台重写过程中,主进程处理的客户端写请求命令会被保存到aof重写缓冲区中,当子进程完成AOF重写工作后,通过向父进程发出一个信号,父进程收到后,会调用一个信号处理函数,并执行以下工作:
- 将aof重写缓冲区中的内容写入到新的aof文件
- 对新的aof文件进行改名,原子地替换现有的aof文件
tips: aof重写过程中只有信号处理函数执行时会阻塞redis主进程执行
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
持久化小结
因为AOF更新频率通常比RDB文件更高,因此如果服务器开启了AOF持久化功能,那么会优先使用AOF文件还原数据库状态。
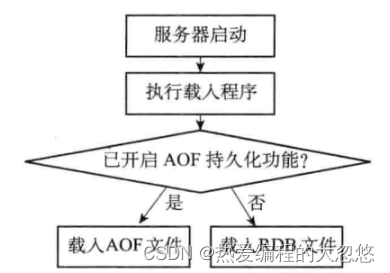
事件循环
Redis事件循环
过期键
数据库
- redisServer记录redis服务器全局状态,其中db是redis管理的数据库列表,默认创建16个,一般只使用0号数据库
- redisClient记录redis客户端状态
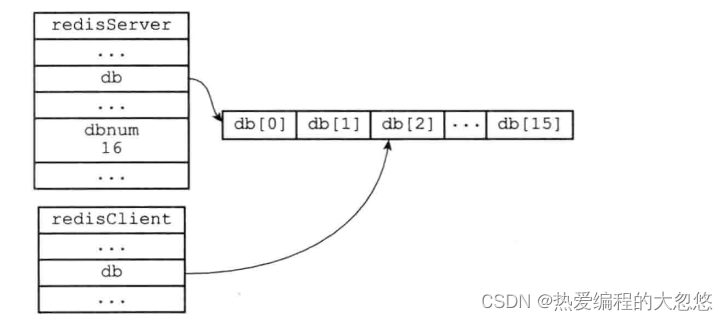
- redisDb记录redis单个数据库的状态,其中的dict字典记录当前数据库所有键值对
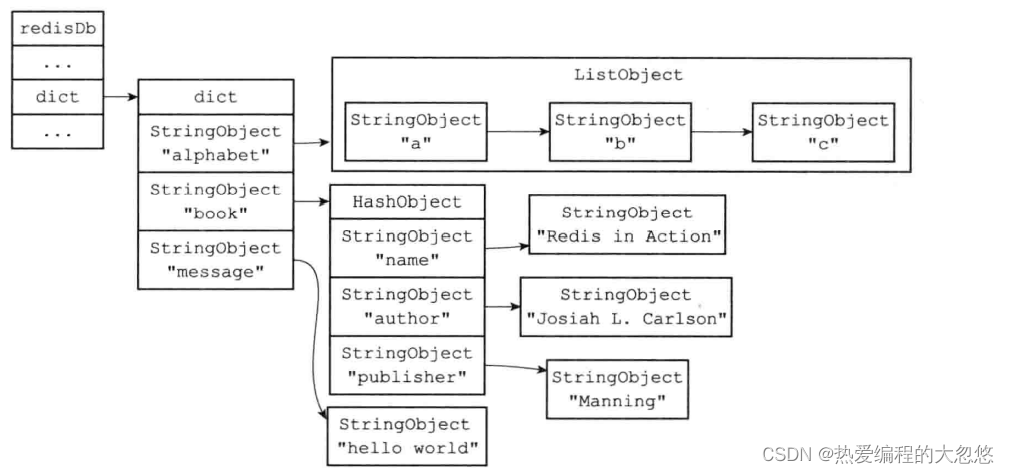
过期键保存
-
过期时间命令内部转换关系如下,最终都会通过pexpireat来生成当前键的毫秒级过期时间戳
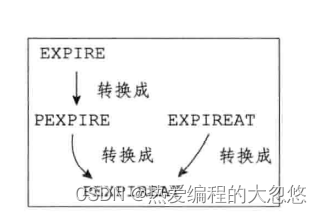
-
过期键由redisDb中的expires过期字典进行保存
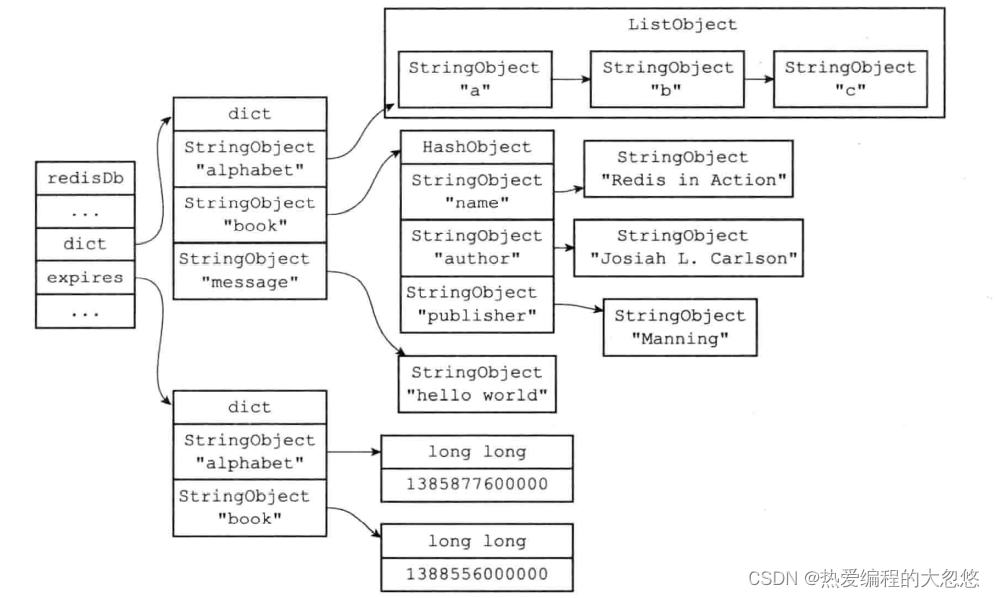
删除策略
redis采用定期删除和惰性删除两种策略结合完成过期键的清理。
-
惰性删除策略
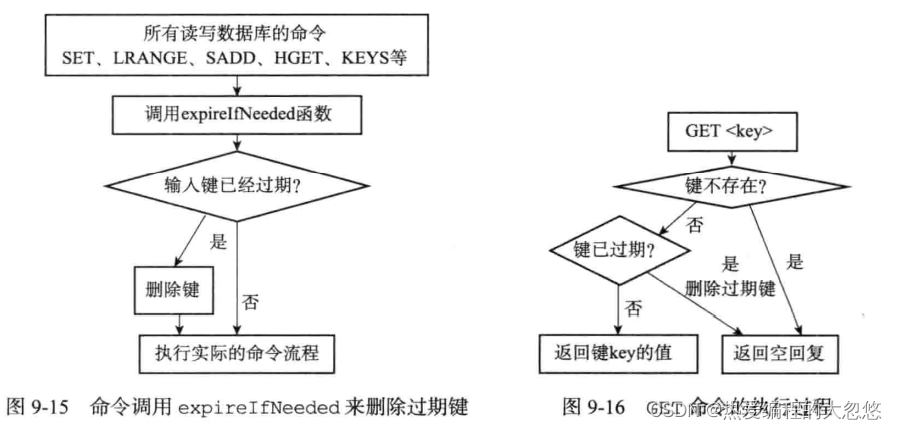
-
定期删除策略: serverCron周期性时间事件每次执行时,会调用activeExpireCycle函数进行一波定期删除


RDB和AOF
save,bgsave和aof文件重写时都会忽略数据库中已经过期的键。
当某个键被惰性删除或者定期删除时,会向aof文件写入一个DEL命令,来显示删除该键。
复制

主从复制
通过执行slaveof命令或者在配置文件中配置slaveof让一个服务器去复制另一个服务器:
slaveof masterIp masterPort
Redis复制过程分为同步和命令传播两步:
同步

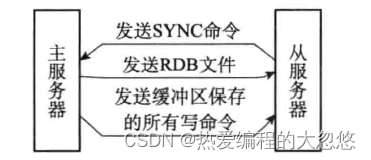
命令传播
在初次复制完毕后,后续每当主服务器接收到客户端的写命令时,都需要将命令传播给从服务器。
复制分为两种情况:

2.8版本之前的redis在断线后重复制时会通过发送SYNC命令进行完全同步复制,而不是进行增量同步。
新版本redis实现: 使用PSYNC命令替代SYNC命令来执行复制时的同步操作。

部分重同步实现
部分重同步需要用到三个值:

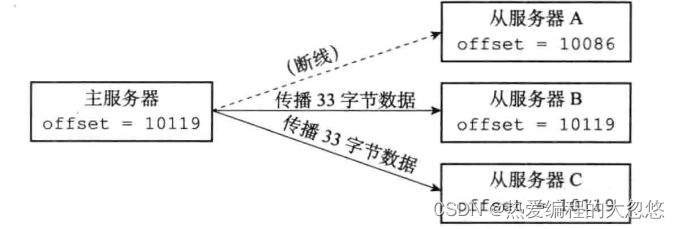
- 复制偏移量: 主服务器每次向从服务器传播N字节数据时,就将自己的复制偏移量加上N,从服务器每次收到主服务器传播的N个字节数据时,就将自己的复制偏移量加上N。
- 复制积压缓冲区: 固定大小的先进先出队列,默认大小为1MB,主服务器进行命令传播时,会将命令同时记录一份到复制积压缓冲区中保存。
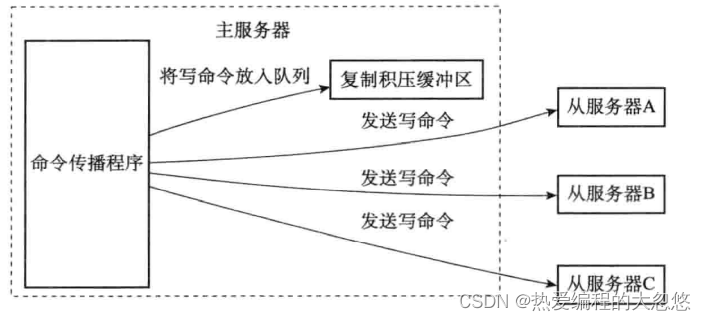
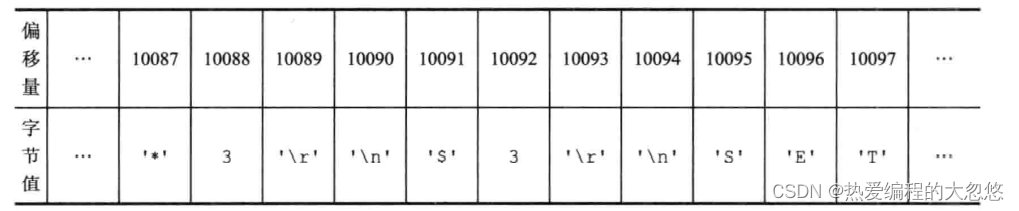
复制积压缓冲区保存最近最近一部分传播的写命令,并且复制积压缓冲区会为队列中每个字节记录相应的复制偏移量:

- 服务器运行ID

PSYNC命令
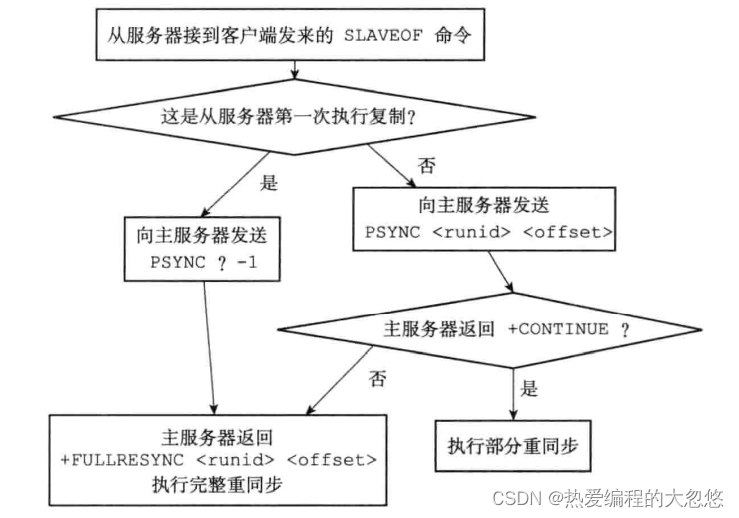
完整复制过程
- 从服务器发出slaveof命令,同时在从服务器会记录下主服务器的ip和port

-
建立套接字连接成功后,从服务器会为该套接字关联一个文本事件处理器,专门处理后续复制工作,如: 接收RDB文件和传播的命令。
-
主服务器在建立套接字成功后,会为该套接字创建对应的客户端状态,即主服务器会将从服务器看做是一个特殊的客户端。
-
从服务器发送ping命令,验证连接可用性
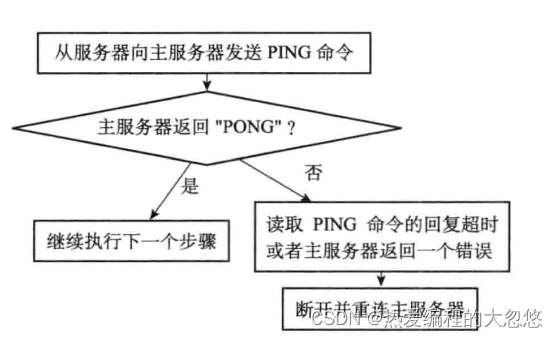
-
身份验证: 如果主服务器需要密码验证,从服务器需要配置masterauth选项
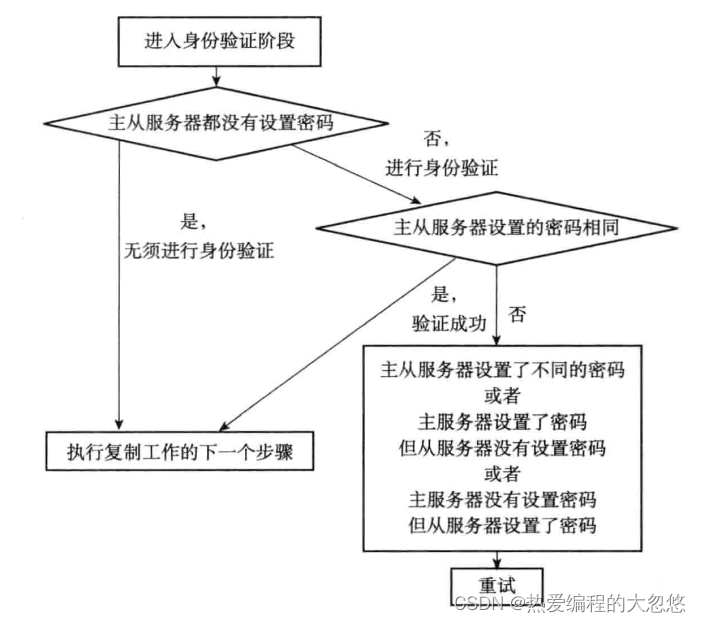
- 从服务器向主服务器发送自己监听的端口号,主服务器会在对应的从服务器客户端中保存该端口号

- 同步

tips: 只有通过客户端方式才能发送命令,redis也可以进行统一处理,而无须特殊对待
-
不断进行命令传播
-
心跳检测

- 通过Info replication命令,可以通过lag选项看到距离从服务器最后一次发送心跳包过去了多久


优化
- repl-diskless-sync启用无磁盘复制,避免全量同步时的磁盘IO,不通过先写RDB文件,再发送该文件到网络IO的方式,而是直接将数据发送到网络IO。
- 可以提高复制积压缓冲区大小,减少slave故障恢复进行全量同步的概率。
哨兵
redis哨兵
redis设计与实现第16章 Sentinel
分片集群
分片集群
多级缓存
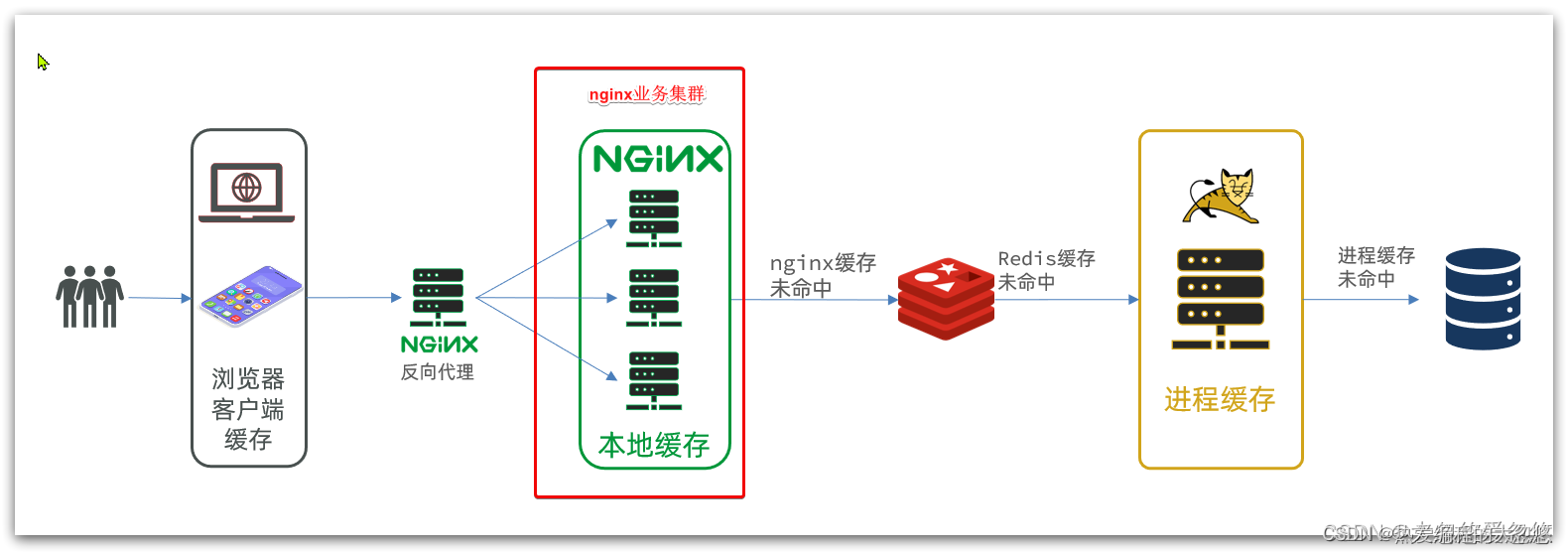
-
Nginx做反向代理和静态资源缓存
-
Nginx结合OpenResty完成对redis的操作,通过nginx查询redis,并且结果缓存在本地
-
tomcat利用caffeine完成本地进程缓存
-
以上缓存均未命中,最终请求打到数据库
多级缓存
缓存同步
canal实现缓存同步
底层数据结构
SDS(简单动态字符串)
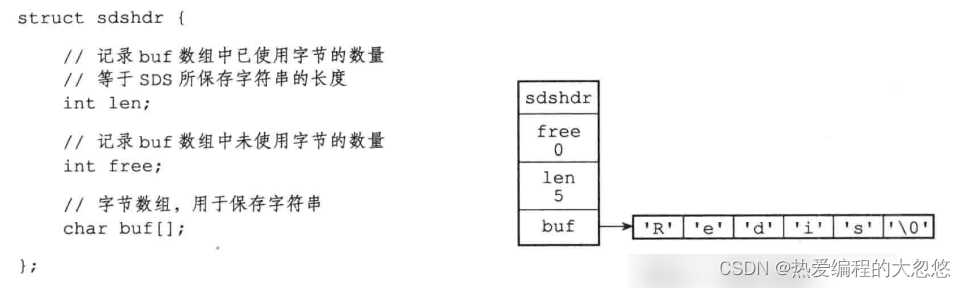
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 通过内存预分配,惰性空间释放来减少修改字符串长度时所需内存重分配次数
- 二进制安全 , SDS使用len而非’\0’判断字符串是否结束
- 兼容部分C字符串函数
IntSet(整数集合)
IntSet是vlaue集合的底层实现之一,当一个集合只包含整数值元素,并且这个集合元素数量不多的情况下,Redis就会使用IntSet作为该value集合的底层实现。
typedef struct intset {//编码方式,支持存放16位,32位,64位整数uint32_t encoding;//元素个数uint32_t length;//整数数组,保存集合数据int8_t contents[];
} intset;
如果插入的新元素大小比当前编码大小大,那么会进行升级,即选取适合当前新元素大小的编码,并将数组进行扩容,每个元素都按照该编码大小进行存储。
redis整数集合不支持降级,因为会产生内存碎片,当然可以考虑采用free字段标记空闲空间,但是redis没有这样做
intset具备以下特点:
- Redis会确保intset中的元素唯一,有序
- 具备类型升级机制,可以节约内存空间
- 底层采用二分查找方式来查询
Dict(字典)
//字典
typedef struct dict {//dict类型,内置不同的hash函数dictType *type;//私有数据,在做特殊运算时使用void *privdata;//一个Dict包含两个哈希表,其中一个是当前数据,另一个一般为空,rehash时使用dictht ht[2];//rehash的进度,-1表示未开始long rehashidx; /* rehashing not in progress if rehashidx == -1 *///rehash是否暂停,1则暂停,0则继续int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;
结构:
- 数组加链表
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
伸缩过程:


zipList(压缩列表)
压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis底层就会使用ziplist存储存储结构。

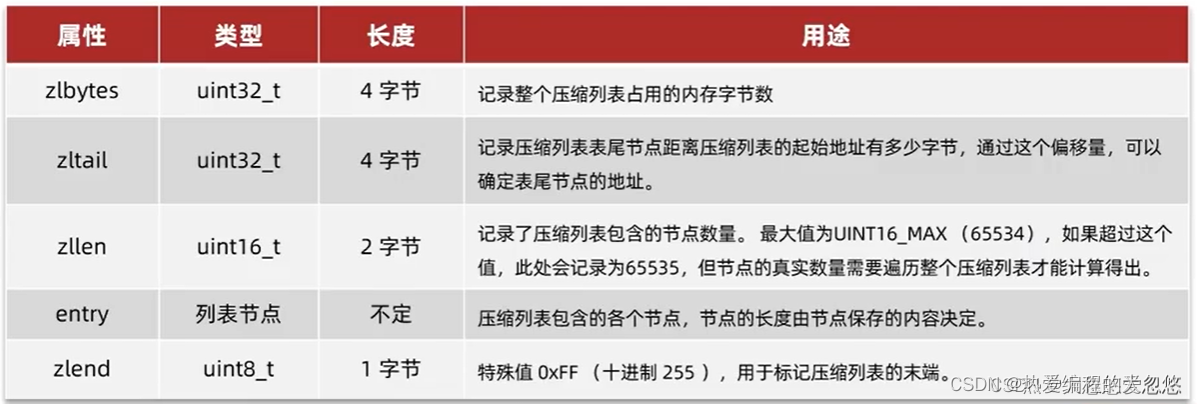
entry构成:
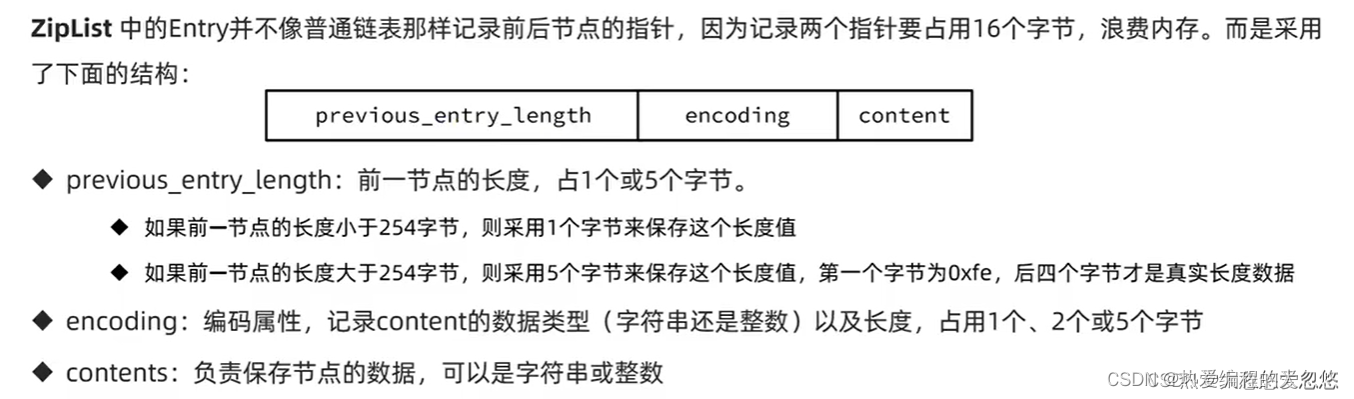
连锁更新问题:


- 此时,如果我们将一个长度大于254字节的新节点设置插入进来,称为压缩列表头节点,那么旧头节点的pre_entry_len需要扩展到5字节表示新节点的大小.
- 旧节点加上4字节后变成了254,那么后面的节点需要再次扩展…直到某个节点pre_entry_len扩展到5字节后长度并没有超过254为止

新增,删除都可能导致连锁更新的发生。
连锁更新虽然复杂度高,会大大降低性能,但是由于产生概率较低,并且及时出现了,只要被更新节点数量不多,性能上不会有太大影响。
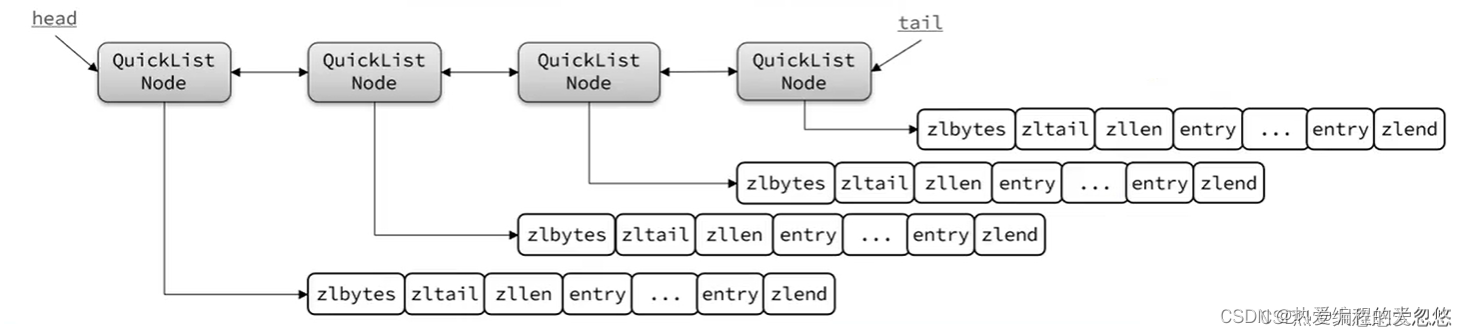
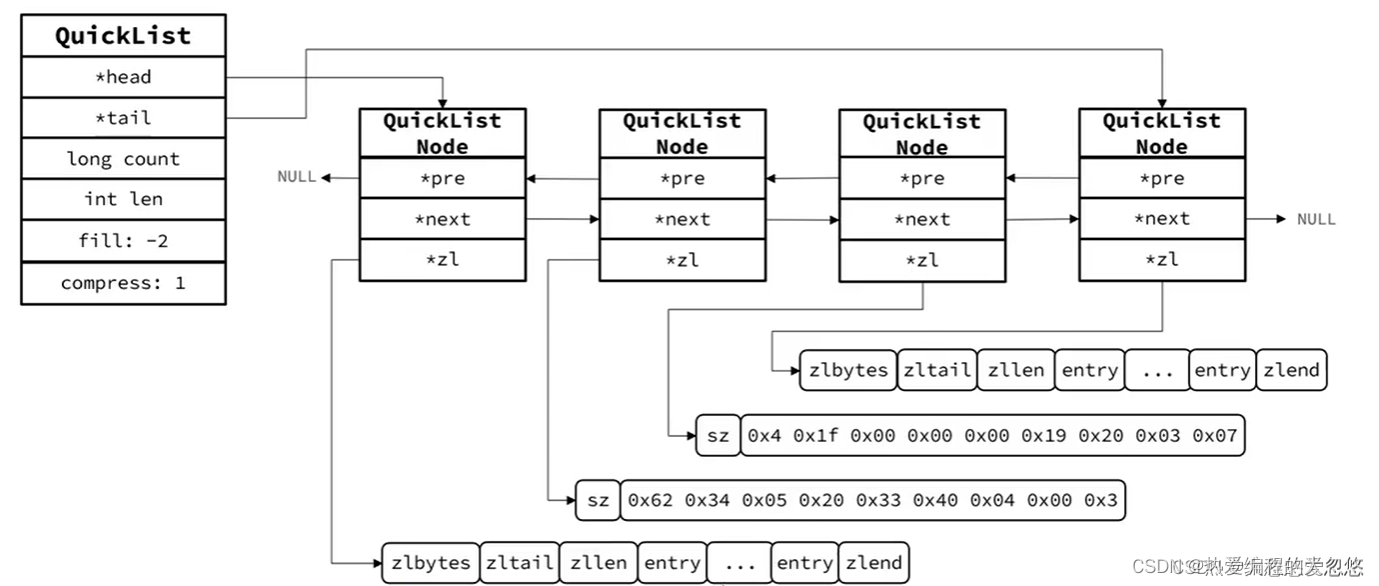
quickList(快速链表)


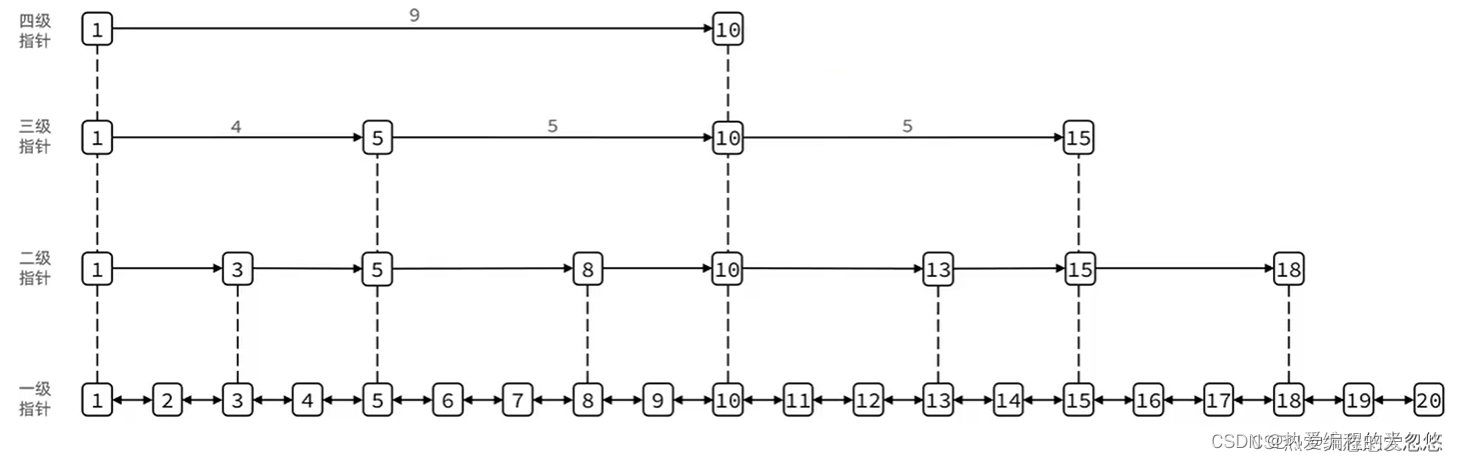
skipList(跳跃表)
SkipList首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
Redis目前只在两处地方使用到了SkipList,分别是 :
-
实现有序集合键
-
在集群节点中用作内部数据结构
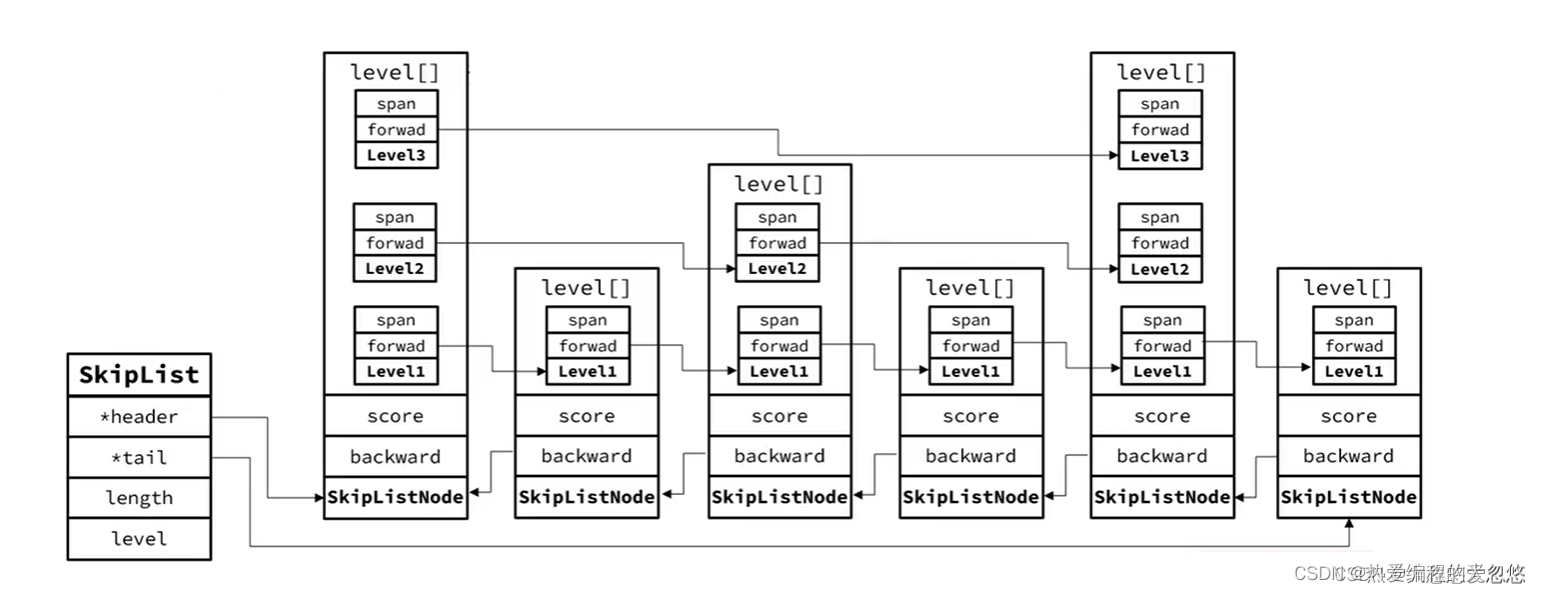
-
跳跃表是一个双向链表,每个节点都包含score和ele值
-
节点按照score排序
-
每个节点都可以包含多层指针,层数是1到32之间的随机数
-
不同层指针到下一个节点的跨度不同,层级越高,跨度越大
-
增删改成效率与红黑树基本一致,实现却更为简单
Redis对象系统

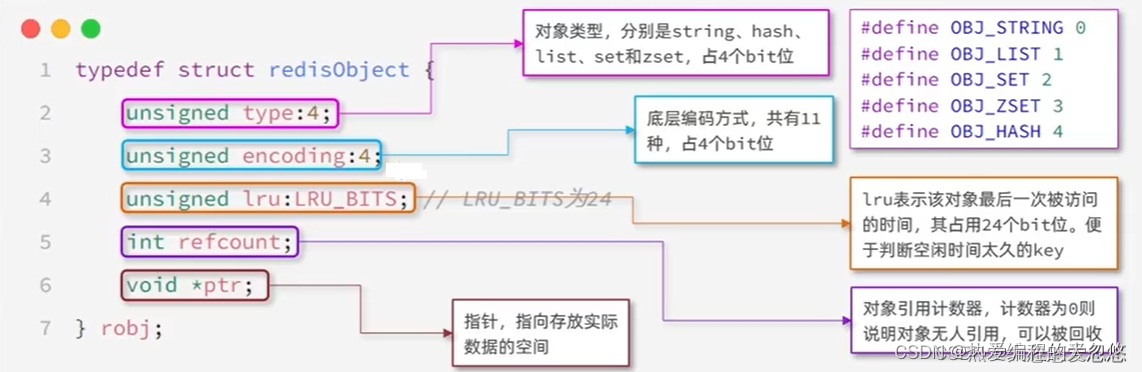
Reids中会根据存储的数据类型不同,选择不同的编码方式,功包含11种不同的类型:
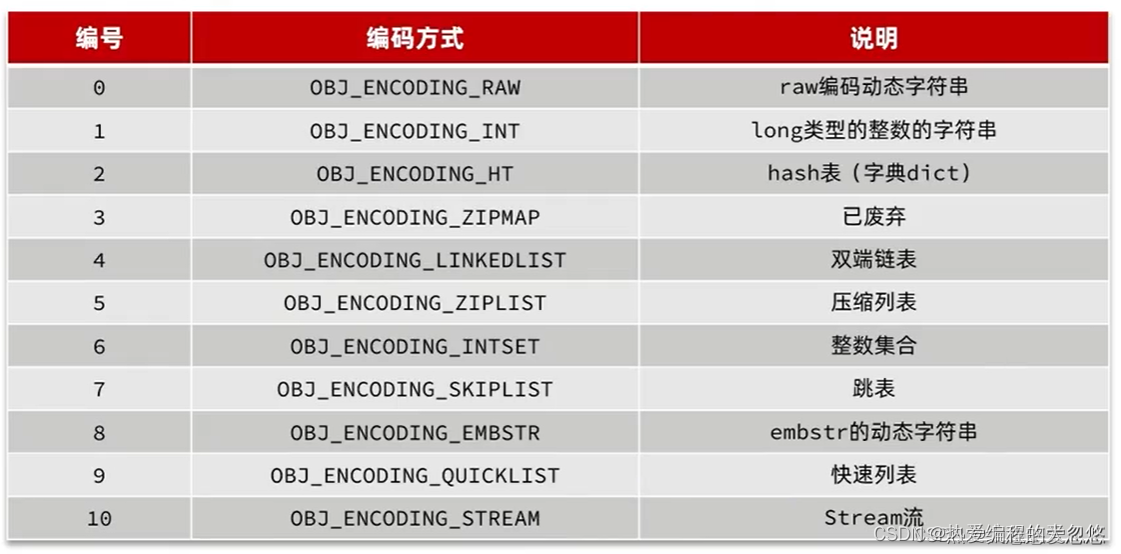
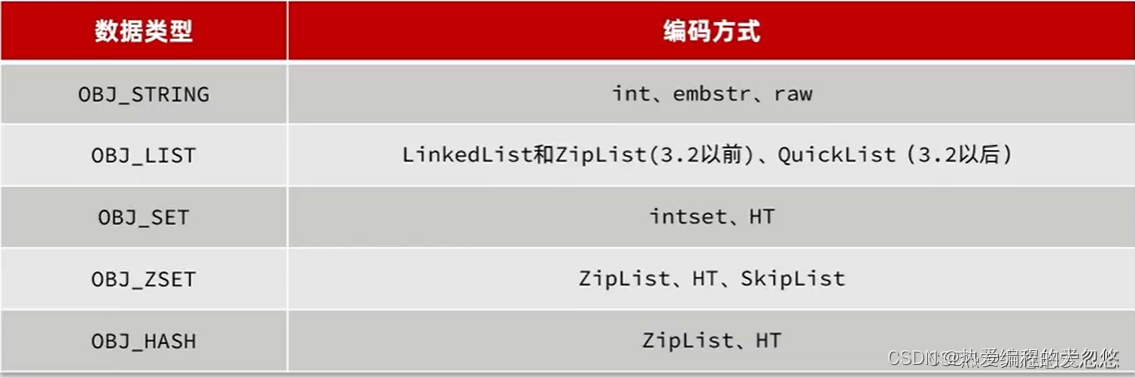
每种数据类型使用的编码方式如下:
String对象
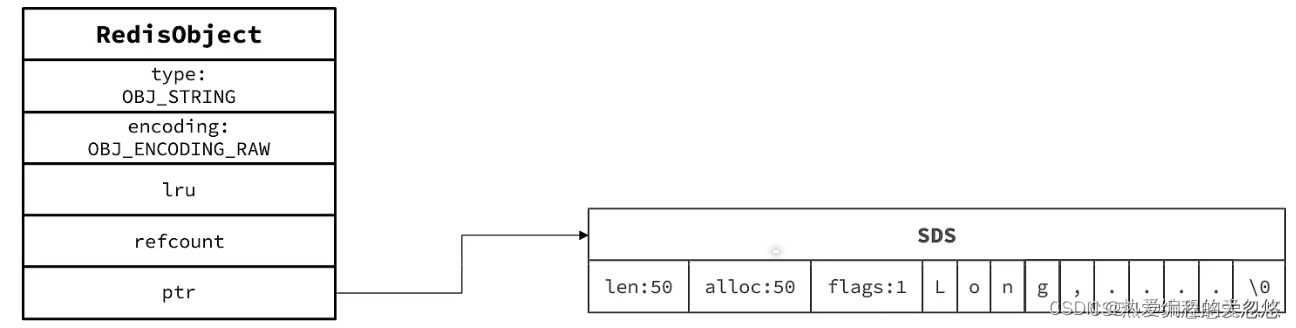
- 如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时Object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。

- 如果存储的字符串是整数值,并且大小在LONG—MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了

- 其基本编码方式是RAW,基于简单动态字符串SDS实现,存储上限为512mb.
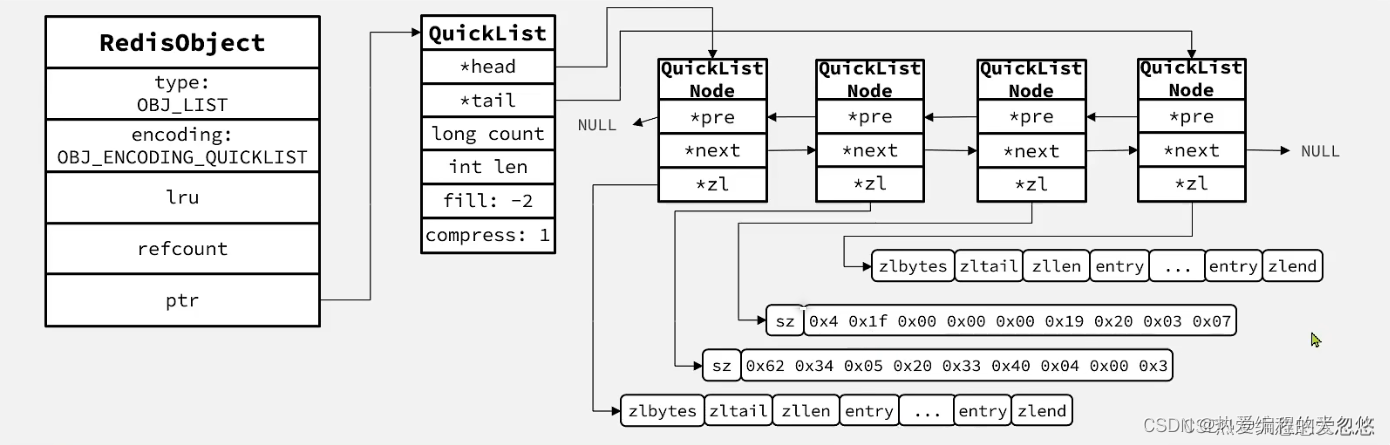
列表对象


集合对象

编码转换:
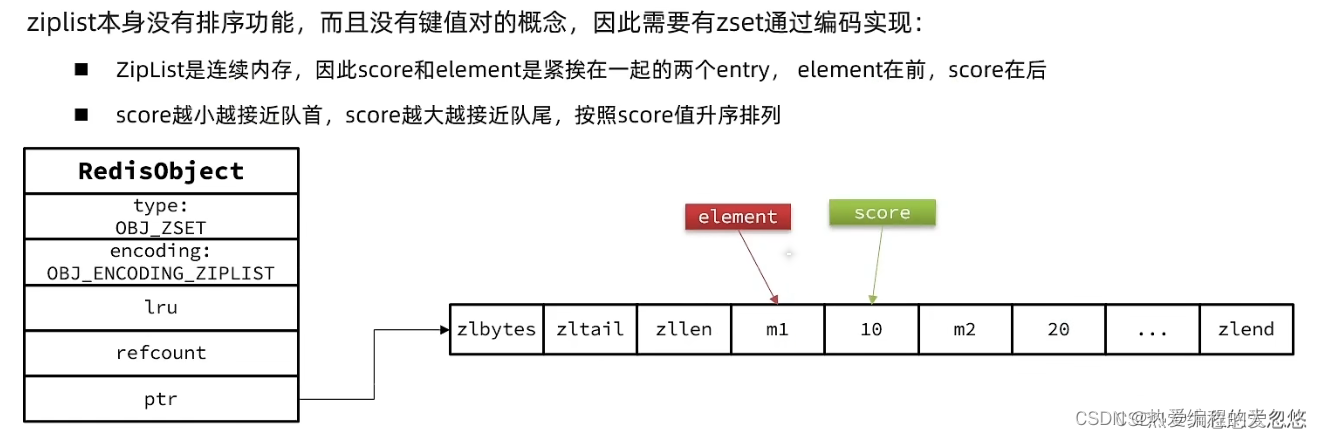
有序集合


当数据量比较小的时候,ZSet采用ziplist作为底层结构

hash对象
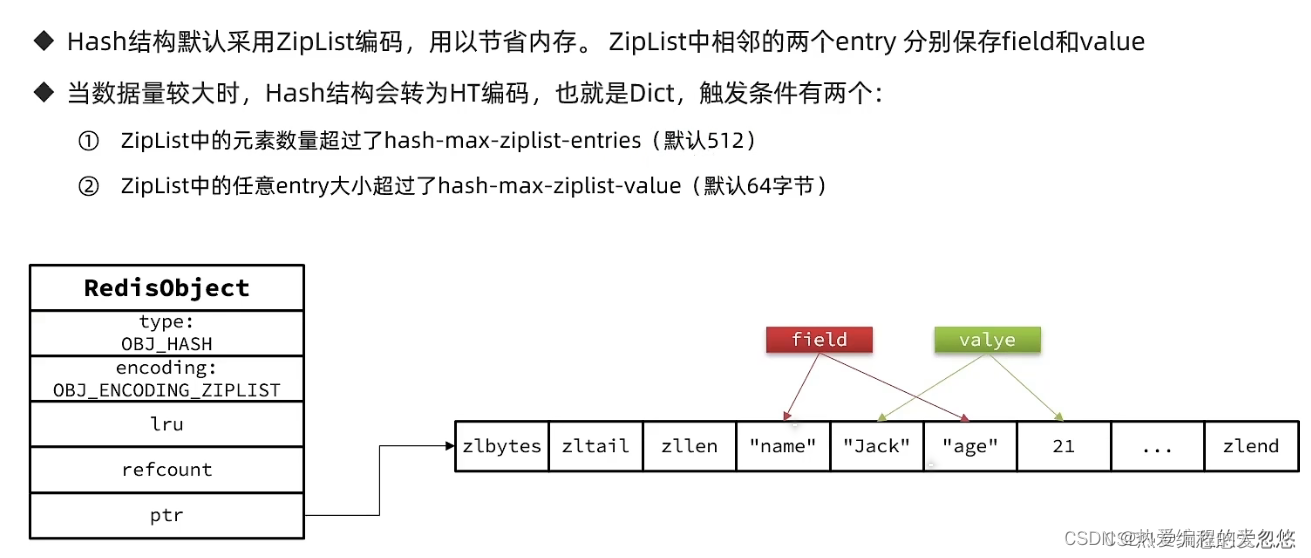
当超过限制后,底层编码会变成HT
Redis最佳实践
bigKey问题
Key的最佳实践:
- 固定格式:[业务名]:[数据名]:[id]
- 足够简短:不超过44字节
- 不包含特殊字符
Value的最佳实践:
- 合理的拆分数据,拒绝BigKey
- 选择合适数据结构
- Hash结构的entry数量不要超过1000
- 设置合理的超时时间
tips: 字符串对象尽量底层采用embstr编码 , 哈希对象底层尽量采用ziplist编码
批处理
批量处理的方案:
- 原生的M操作
- Pipeline批处理
注意事项:
- 批处理时不建议一次携带太多命令
- Pipeline的多个命令之间不具备原子性
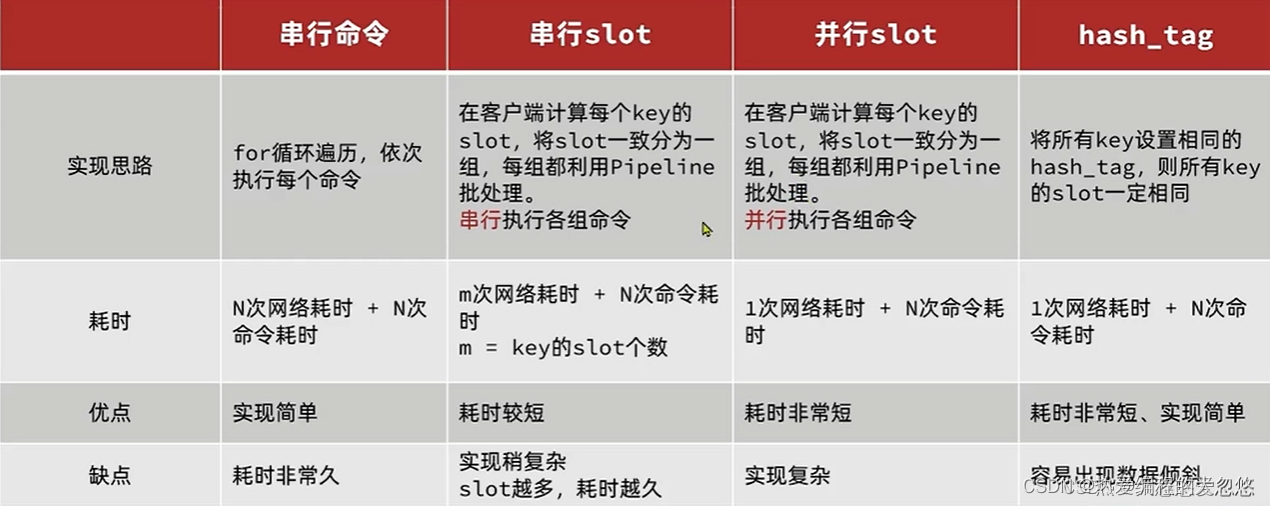
分片集群下的批处理:
如MSET或Pipeline这样的批处理需要在一次请求中携带多条命令,而此时如果Redis是一个集群,那批处理命令的多个key必须落在一个插槽中,否则就会导致执行失败。
redis最佳实践
内存淘汰策略

LRU和LFU是通过redisObject对象中的lru属性进行判断完成key淘汰的。
Redis原理篇之通信协议和内存回收
发布订阅和事务
Redis发布订阅和事务实现原理
相关文章:
Redis核心知识点
Redis核心知识点Redis核心知识点大全五种数据类型redis整合SpringBoot序列化问题渐进式扫描慢查询缓存相关问题数据库和缓存谁先更新缓存穿透缓存雪崩缓存击穿实际应用超卖问题分布式锁全局唯一ID充当消息队列Feed流附近商户签到HyperLogLog实现UV统计持久化RDBAOF持久化小结事…...

14. 最长公共前缀
14. 最长公共前缀 一、题目描述: 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: …...
SignalR注册成Windows后台服务,并实现web前端断线重连
注意下文里面的 SignalR 不是 Core 版本,而是 Framework 下的 本文使用的方式是把 SignalR 写在控制台项目里,再用 Topshelf 注册成 Windows 服务 这样做有两点好处 传统 Window 服务项目调试时需要“附加到进程”,开发体验比较差…...
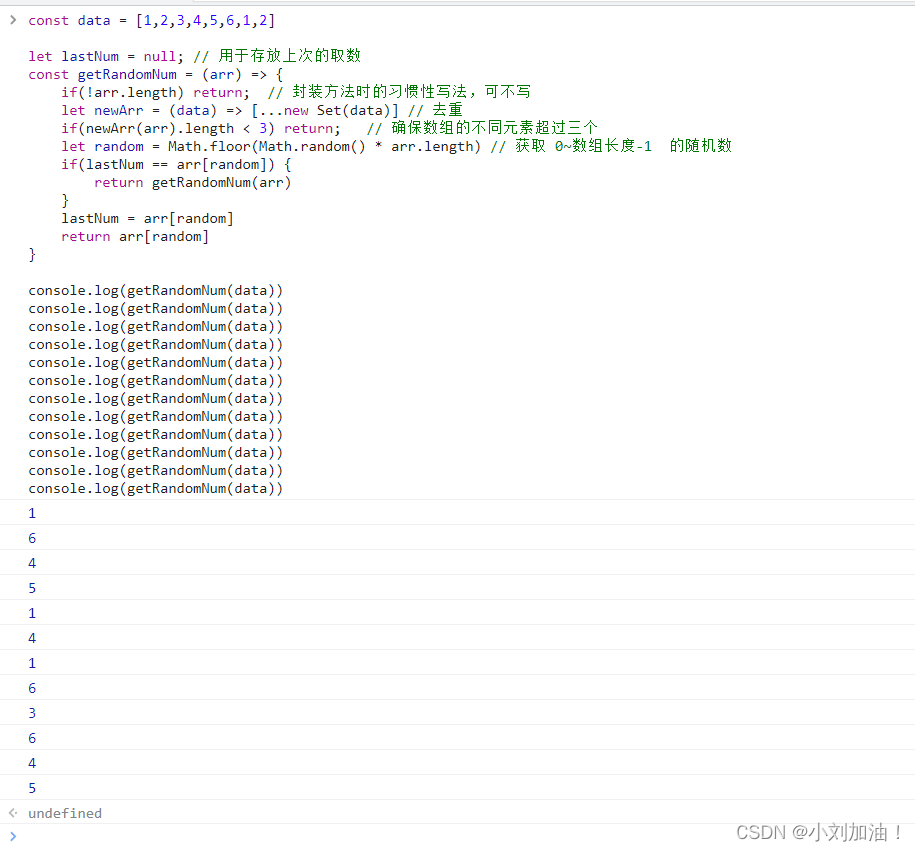
【前端笔试题二】从一个指定数组中,每次随机取一个数,且不能与上次取数相同,即避免相邻取数重复
前言 本篇文章记录下我在笔试过程中遇到的真实题目,供大家参考。 1、题目 系统给定一个数组,需要我们编写一个函数,该函数每次调用,随机从该数组中获取一个数,且不能与上一次的取数相同。 2、思路解析 数组已经有了…...

专栏关注学习
Node学习专栏(全网最细的教程) 【spring系列】 SpringCloud 前端框架Vue java学习过程 RocketMQ Spring Tomcat websocket 从头开始学Redisson 从头开始学Oracle 跟着大宇学Shiro 吃透Shiro源代码 Git基础与进阶 Java并发编程 Spring系列 手写…...
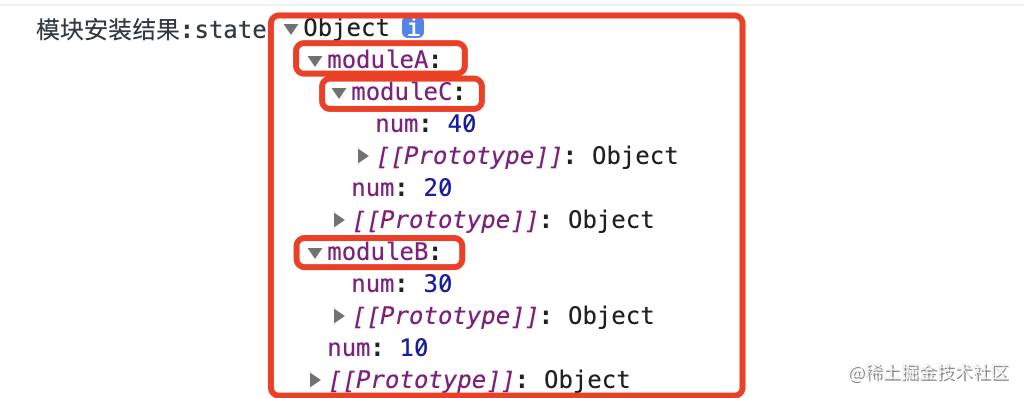
【手写 Vuex 源码】第八篇 - Vuex 的 State 状态安装
一,前言 上一篇,主要介绍了 Vuex 模块安装的实现,针对 action、mutation、getter 的收集与处理,主要涉及以下几个点: Vuex 模块安装的逻辑;Vuex 代码优化;Vuex 模块安装的实现;Vue…...
Mac下拉式终端的安装与配置 (iTerm2)
Mac下拉式终端的安装与配置 使用效果如图所示 安装前置软件 iTerm2 很可惜,如此炫酷的功能在原终端中并不能实现,我们需要借助iTerm2这个软件来实现。 官网链接:iTerm2 - macOS Terminal Replacement 我们点击download下载即可 配置 当我…...

使用 Spring 框架结合阿里云 OSS 实现文件上传的代码示例
使用 Spring 框架结合阿里云 OSS 实现文件上传的代码示例POM文件配置文件上传工具类控制层使用yaml配置文件(第二种用法,看公司要求)注入 OSSClient 对象及工具类(第二种用法,看公司要求)使用 Vue 前端代码…...
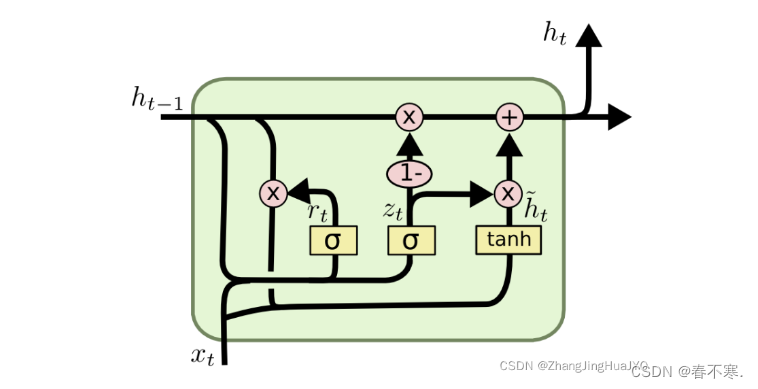
神经网络基础知识
神经网络基础知识 文章目录神经网络基础知识一、人工神经网络1.激活函数sigmod函数Tanh函数Leaky Relu函数分析2.过拟合和欠拟合二、学习与感知机1.损失函数与代价函数2. 线性回归和逻辑回归3. 监督学习与无监督学习三、优化1.梯度下降法2.随机梯度下降法(SGD)3. 批量梯度下降法…...
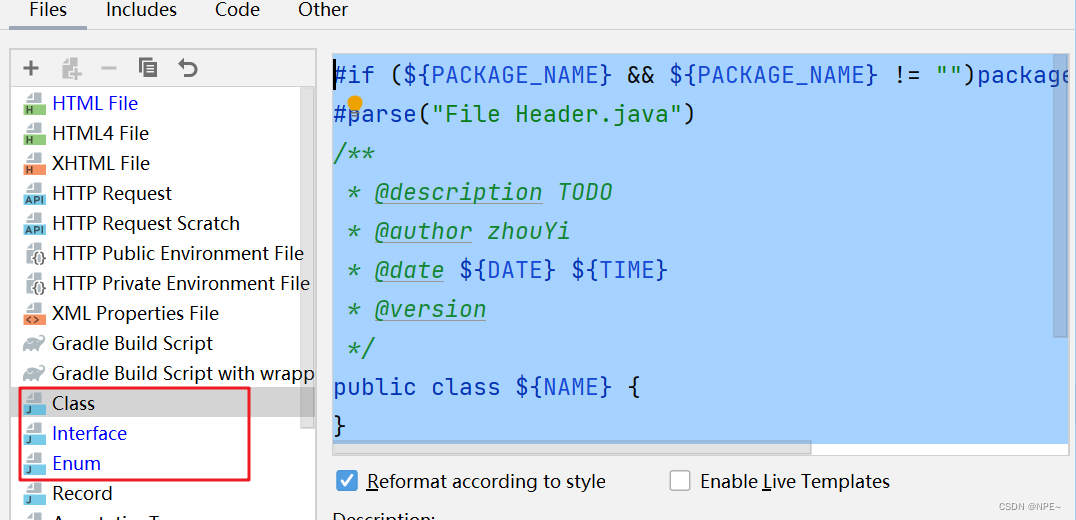
SpringBoot开发规范部分通用模板+idea配置【项目通用-1】
SpringBoot开发规范通用模板 1 分页插件使用 通过MybatisPlus配置分页插件拦截器 Configuration MapperScan("com.xuecheng.content.mapper") //拦截的mapper层 public class MybatisPlusConfig {//定义分页的拦截器Beanpublic MybatisPlusInterceptor getMybatisPl…...

程序的机器级表示part3——算术和逻辑操作
目录 1.加载有效地址 2. 整数运算指令 2.1 INC 和 DEC 2.2 NEG 2.3 ADD、SUB 和 IMUL 3. 布尔指令 3.1 AND 3.2 OR 3.3 XOR 3.4 NOT 4. 移位操作 4.1 算术左移和逻辑左移 4.2 算术右移和逻辑右移 5. 特殊的算术操作 1.加载有效地址 指令效果描述leaq S, DD…...

基于YOLOV5的钢材缺陷检测
数据和源码见文末 1.任务概述 数据集使用的是东北大学收集的一个钢材缺陷检测数据集,需要检测出钢材表面的6种划痕。同时,数据集格式是VOC格式,需要进行转化,上传的源码中的数据集是经过转换格式的版本。 2.数据与标签配置方法 在数据集目录下,train文件夹下有训练集数据…...
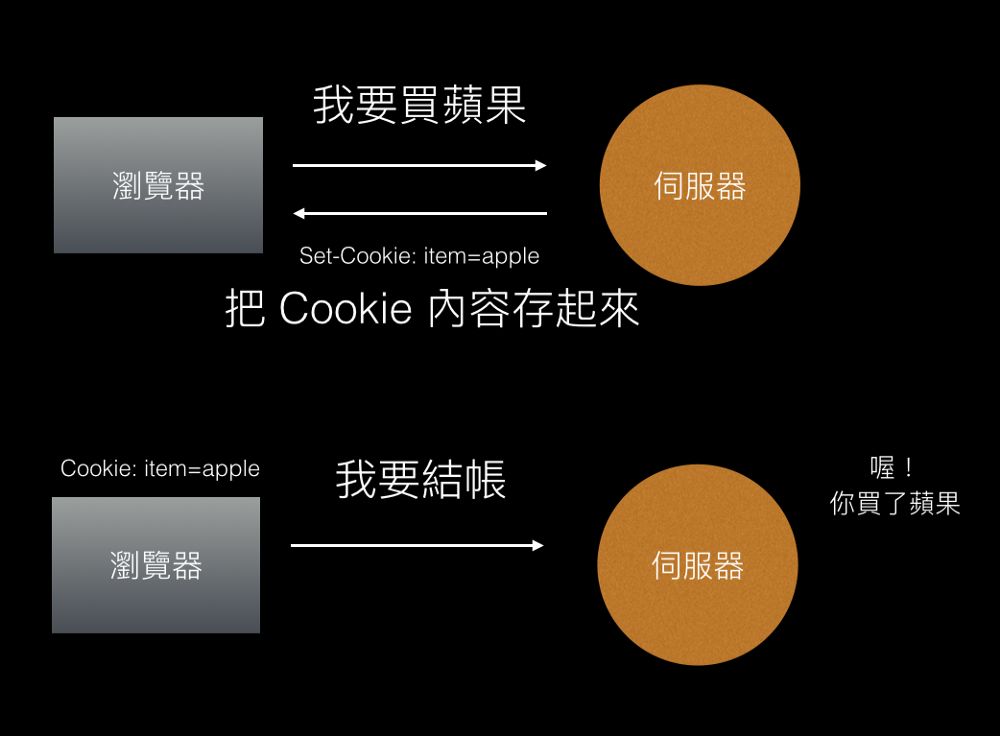
Session与Cookie的区别(三)
中场休息 让我们先从比喻回到网络世界里,HTTP 是无状态的,所以每一个 Request 都是不相关的,就像是对小明来说每一位客人都是新的客人一样,他根本不知道谁是谁。 既然你没办法把他们关联,就代表状态这件事情也不存在。…...
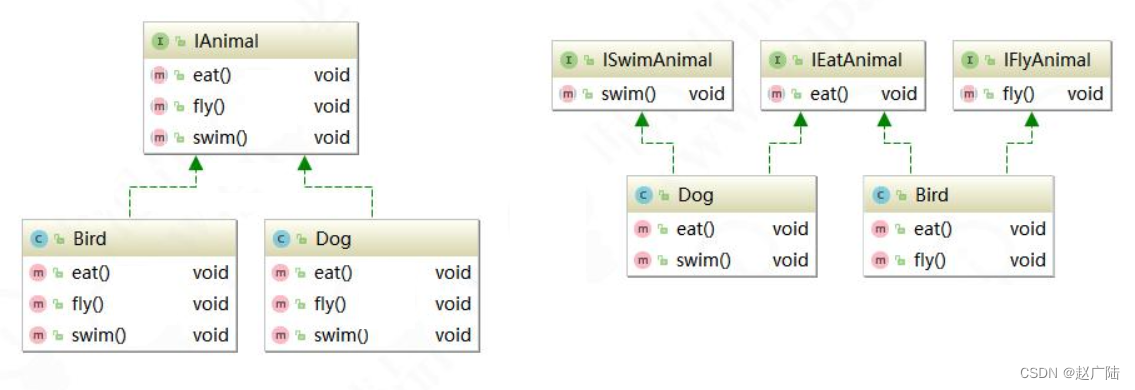
七大设计原则之接口隔离原则应用
目录1 接口隔离原则介绍2 接口隔离原则应用1 接口隔离原则介绍 接口隔离原则(Interface Segregation Principle, ISP)是指用多个专门的接口,而不使用单一的总接口,客户端不应该依赖它不需要的接口。这个原则指导我们在设计接口时…...
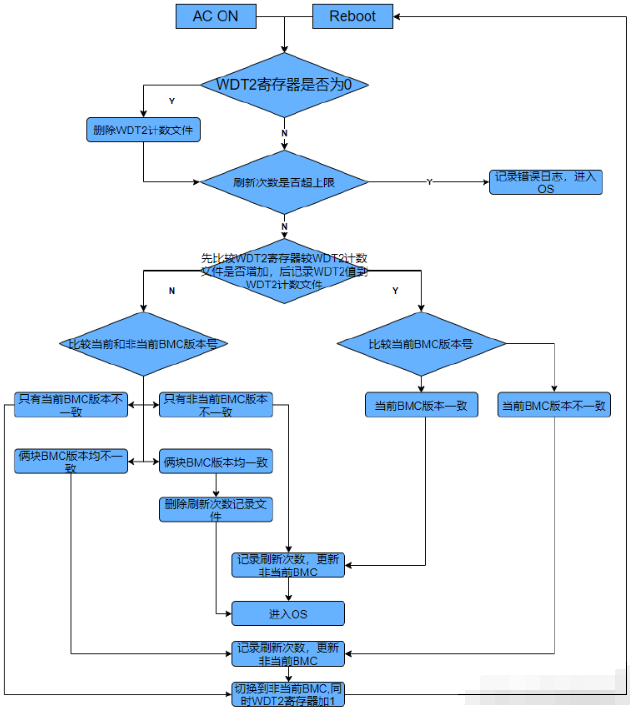
【Shell1】shell语法,ssh/build/scp/upgrade,环境变量,自动升级bmc
文章目录1.shell语法:shell是用C语言编写的程序,是用户使用Linux的桥梁,硬件>内核(os)>shell>文件系统1.1 变量:readonly定义只读变量,unset删除变量1.2 函数:shell脚本传递的参数中包含空格&…...

JavaScript HTML DOM - 改变CSS
JavaScript 是一种动态语言,它可以动态地修改网页的外观,并且使用HTML DOM(文档对象模型)可以更方便地控制HTML元素的样式。 JavaScript 通过在HTML DOM中更改CSS属性来更改样式,这些CSS属性包括颜色、位置、字体大小…...
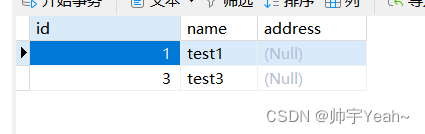
mycat连接mysql 简单配置
mycat三个配置文件位于conf下 可通过Notepad操作 首先配置service.xml中的user标签,设置用户名,密码,查询权限,是否只读等 只是设置了root用户,有所有权限 配置schema.xml <?xml version"1.0"?&g…...

Spring常用注解
文章目录一、Bean交给Spring管理1、Component2、Bean3、Controller4、Service5、Repository6、Configuration7、ComponentScan二、作用域1、Lazy(false)Scope三、依赖注入1、Autowired2、Resource3、Qualifier四、读取配置文件值1、Value一、Bean交给Spring管理 1、Component …...
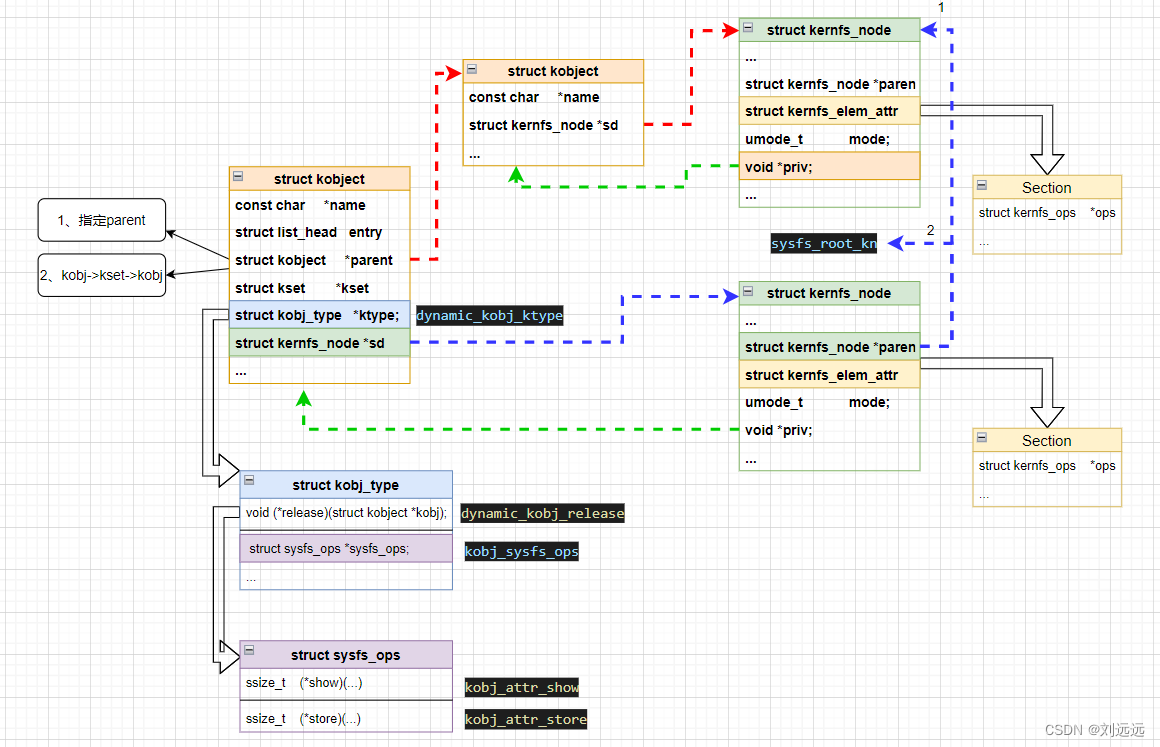
I.MX6ULL内核开发9:kobject-驱动的基石
目录 一、摘要 二、重点 三、驱动结构模型 四、关键函数分析 kobject_create_and_add()函数 kobject_create()函数 kobject_init()函数 kobject_init_internal()函数 kobject_add()函数 kobject_add_varg&am…...
Docker-harbor私有仓库
一、Harbor概述 1、Harbor的概念 • Harbor是VMware公司开源的企业级Docker Registry项目,其目标是帮助用户迅速搭建一个企业级的Docker Registry服务 • Harbor以 Docker 公司开源的Registry 为基础,提供了图形管理UI、基于角色的访问控制(Role Base…...
)
别再盲目quantize!Python模型边缘部署前必须做的4层静态分析(含自研QuantSim-Analyzer v2.1开源工具链)
第一章:边缘Python量化部署性能的底层挑战与认知重构在边缘设备上直接部署Python量化模型,表面看是精度压缩与推理加速的简单叠加,实则直面硬件资源、运行时约束与语言语义三重张力的交汇点。CPython解释器的全局解释器锁(GIL&…...

代码遗产规划师:在技术断代潮收割焦虑税
在AI驱动的技术迭代浪潮中,软件测试行业正经历前所未有的断代危机:传统手工测试岗位需求锐减,而AI测试能力成为新分水岭。据统计,AI测试覆盖率突破80%后,初级测试岗位需求同比下降30%,而测试开发与质量效能…...

追觅精神:BE NO.1,OR NOTHING|以极致之心,筑行业之巅
追觅精神:BE NO.1,OR NOTHING|以极致之心,筑行业之巅在浮躁逐利的商业浪潮中,总有一种精神,拒绝平庸,摒弃妥协,以“要么第一,要么归零”的决绝,在科技赛道上劈波斩浪。这…...

打造无缝漫画阅读体验:Jasmine用户账户体系全攻略
打造无缝漫画阅读体验:Jasmine用户账户体系全攻略 【免费下载链接】jasmine A comic browser,support Android / iOS / MacOS / Windows / Linux. 项目地址: https://gitcode.com/gh_mirrors/jas/jasmine Jasmine作为一款跨平台漫画阅读应用&…...

093华为黄大年茶思屋第3期·难题一:AI大模型训练 – 多维度混合并行策略的自动搜索算法
华为黄大年茶思屋第3期难题一:AI大模型训练 – 多维度混合并行策略的自动搜索算法 双思路解题方案:常规行业解法 本源动态原点解法,双框架对照,专家级可落地、可验证 核心亮点:直击大模型并行策略搜索产业卡点&#x…...

EcomGPT电商智能助手从零开始:Python 3.10+环境搭建与Gradio界面调用
EcomGPT电商智能助手从零开始:Python 3.10环境搭建与Gradio界面调用 1. 项目介绍与环境准备 EcomGPT电商智能助手是基于阿里EcomGPT-7B多语言电商大模型开发的Web应用,专门为电商从业者打造。这个工具能帮你自动处理商品分类、属性提取、标题翻译和营销…...

XUnity.AutoTranslator完全指南:如何为Unity游戏实现实时多语言翻译
XUnity.AutoTranslator完全指南:如何为Unity游戏实现实时多语言翻译 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一款功能强大的Unity游戏实时翻译插件,…...

AgentCPM在软件开发生命周期中的应用:自动生成迭代复盘与技术债分析报告
AgentCPM在软件开发生命周期中的应用:自动生成迭代复盘与技术债分析报告 每次Sprint结束,团队是不是都要花上半天甚至一天的时间来开复盘会?产品经理、开发、测试围坐一圈,对着Jira看板、Git提交记录和一堆图表,试图从…...
)
MacOS下Parallel Desktop显卡驱动安装失败?手把手教你手动挂载Parallel Tools(附截图)
MacOS下Parallel Desktop显卡驱动安装失败?手把手教你手动挂载Parallel Tools 最近在Mac上使用Parallel Desktop运行Windows虚拟机的用户可能会遇到一个棘手问题——显卡驱动未能自动安装,导致显示效果卡顿、分辨率异常。这种情况通常发生在Parallel Too…...

TruePWM:LPC1768上实现精确n脉冲计数的硬件级PWM库
1. TruePWM库概述:面向LPC1768的精确脉冲计数型PWM驱动框架TruePWM是一个专为NXP LPC1768微控制器设计的轻量级、高精度PWM脉冲生成库。其核心设计理念并非提供连续占空比可调的模拟式PWM输出,而是精确控制并发送指定数量(n)的完整…...