缓存学习
缓存基本概念
概念
对于缓存,最普遍的理解是能让打开某些页面速度更快的工具。从技术角度来看,其本质上是因为缓存是基于内存建立的,而内存的读写速度相比之于硬盘快了xx倍,因此用内存来代替硬盘作为读写的介质当然能大大提高访问数据的速度。
应用读取数据时,首先会从缓存中查询数据,如果有则执行,没有则需要从数据库中查找,而数据库的读写操作比缓存的数据慢得多,因此通过缓存把访问量较高的热点数据从传统的关系型数据库中加载到内存中,对同样的数据进行二次访问时,就相当于从内存中加载数据,减少了对数据库的访问量,解决了高并发场景下容易造成数据库宕机的问题
缓存优点
-
- 降低冗余的数据传输:访问处于高并发场景下的一个原始服务期页面时,服务器会传输多次同一份文档,这使得每次传输过程中,一些相同的字节会在网络中重复多次传输,这会消耗昂贵的网络带宽,降低传输速度,家中web服务器负载。缓存可以保留第一次服务器响应的副本,后继请求就可以用副本来应对,减少了服务器的流入流出的重复流量
- 降低带宽瓶颈:缓存缓解了网络瓶颈的问题,不需要更多的带宽就能够更快地加载页面,缓存还可以缓解网络的瓶颈问题,很多网络为本地网络客户端提供的带宽比为远程服务器提供的带宽要宽,客户端会以路径上最慢的网速访问服务器,如果客户端从一个快速局域网的缓存中得到了一份副本,那么缓存就可以提高性能,尤其是要传输比较大的文件时
- 降低瞬间堵塞:很多人同时访问同一个Web文档是,就会出现瞬间堵塞,由此造成的过多流量峰值可能会使网络和Web服务器产生灾难性的崩溃,而缓存降低了对原始服务器的要求,服务器可以更快地响应,避免了过载
- 降低距离时延:从较远的地方加载页面会慢一点,除了带宽,距离本身使得所要传输的数据经过的每台路由器都会增加因特网流量的时延,甚至光速也会造成时延,缓存则可以减少数据从服务器流入流出的流量
分类
缓存基本上分为三类:本地缓存、分布式缓存、多级缓存
本地缓存
本地缓存:指和应用程序在同一个进程内的内存空间取存储数据,数据的读写都是在同一个进程内完成的
优点:读取速度快,但是不能进行大数据量存储(本地缓存不需要远程网络请求取操作内存空间,没有额外的性能消耗,因此读取速度快,但是由于本地缓存占用了应用进程的内存空间,故不能进行大数据量的存储)
缺点:应用程序集群部署时,会存在数据更新问题(数据更新不一致),数据会随着应用程序的重启而丢失
(本地缓存一般只能被同一个应用进程的程序访问,不能被其他应用程序进程访问。
在单体应用集群部署时,如果数据库有数据需要更新,就要同步更新不同服务器节点上的本地缓存的数据来保证数据的一致性,但是这种操作的复杂度较高,容易出错。
本地缓存的数据是存储在应用进程的内存空间的,因此当应用进程重启时,本地缓存的数据会丢失)
分布式缓存
分布式缓存:分布式缓存是独立部署的服务进程,并且和应用程序没有部署在同一台服务器上,所以是需要通过远程网络请求来完成分布式缓存的读写操作,并且分布式缓存主要应用在应用程序集群部署的环境下。
优点:支持大数据量存储,数据不会随着应用程序重启而丢失,数据集中存储保证数据的一致性,数据读写分离,高性能,高可用
(分布式缓存是独立部署的进程,拥有自身独自的内存空间,不需要占用应用程序进程的内存空间,并且还支持横向扩展的集群方式部署,因此可以进行大数据量存储。
分布式缓存和本地缓存不同,拥有自身独立的内存空间,不会收到应用程序进程重启的影响,在应用程序重启时,分布式缓存的存储数据仍然存在。
当应用程序采用集群方式部署时,集群的每个部署节点都有一个统一的分布式缓存进行数据的读写操作,所以不会存在像本地缓存中数据更新问题,保证了不同服务器节点的数据一致性。
分布式缓存一般支持数据副本机制,实现读写分离,可以解决高并发场景中的数据读写性能问题。而且在多个缓存节点冗余存储数据,提高了缓存数据的可用性,避免某个节点宕机导致数据不可用问题)
缺点:数据跨网络传输,读写性能不如本地缓存
(分布式缓存是一个独立的服务进程,并且和应用程序进程不在同一台机器上,所以数据的读写要通过远程网络请求,这样相对于本地缓存的数据读写来说,性能要低一些)
分布式缓存典例:MemCached和Redis
多级缓存
基于本地缓存和分布式缓存的优缺点,在实际的业务开发中,一般采用多级缓存(注:本地缓存一般存储更新频率低,访问频率高的数据,分布式缓存一般存储更新频率很高的数据)
多级缓存请求流程:本地缓存作为一级缓存,分布式缓存作为二级缓存。用户获取数据时,先从一级缓存中获取数据,乳沟一级缓存有数据则返回数据,否则从二级缓存中获取数据。如果二级缓存中有数据则更新一级缓存,并将数据返回给客户端。如果二级缓存没有数据则去数据库查询数据,然后更新二级缓存,接着再更新一级缓存,最后将数据返回给客户端
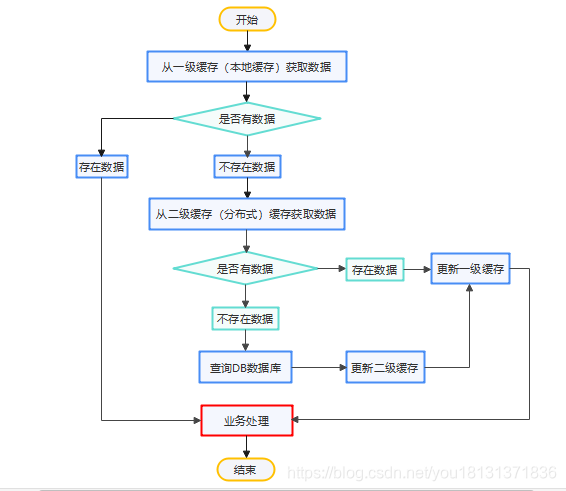
多级缓存的实现:可以使用Guava或者Caffeine作为一级缓存,Redis作为二级缓存
注:在应用程序集群部署时,如果数据库的数据有更新的情况,一级缓存的数据更新容易出现数据不一致的情况。因为是集群部署,多个部署节点实现一级缓存数据更新难度比较大,不过可以通过Redis的消息发布/订阅机制来实现多个节点缓存数据一致性问题
Java标准库中的缓存
Java 的 java.util 包提供了多个集合类,这些类在不同的场景下使用,具有各自的特性和适用范围。下面详细介绍 HashMap、WeakHashMap、ConcurrentHashMap 集合类的 Java 缓存机制。
1. HashMap缓存
优点
- 简单易用:
-
HashMap是 Java 标准库中的常用类,API 简单,容易上手。开发者无需引入外部库即可实现基本的缓存功能。- 可以快速存取数据,插入和读取操作的平均时间复杂度为 O(1),非常适合用于简单的、无需复杂缓存逻辑的场景。
- 无额外依赖:
-
- 使用
HashMap作为缓存不需要依赖外部库,这使得代码更加轻量级,适合那些希望避免外部依赖的项目。
- 使用
- 灵活性:
-
- 可以根据需求灵活地进行扩展,例如可以手动实现缓存过期、最大容量限制等功能。
缺点
- 无缓存失效机制:
-
HashMap不提供任何内置的缓存失效机制,如时间过期、LRU(最近最少使用)策略等。需要开发者必须手动管理缓存项的有效期,这增加了实现的复杂性。
- 线程安全问题:
-
HashMap不是线程安全的,在多线程环境下同时进行读写操作可能导致数据不一致或其他并发问题。
- 内存管理:
-
HashMap会占用内存,而不会自动清理无用的缓存项。随着缓存数据的增加,可能导致内存占用过多。如果长时间不进行处理,可能会导致内存泄漏。
- 无持久化支持:
-
HashMap在内存中存储数据,应用程序关闭后数据将丢失。如果需要持久化缓存,必须额外实现文件存储或数据库支持。
示例代码:
首先创建一个管理缓存的类,定义一个hashmap,并将其进行初始化,决定缓存内一开始有哪些数据
交给springboot管理,进行测试(@PostConstruct注解可以使这个方法默认执行)
@Component
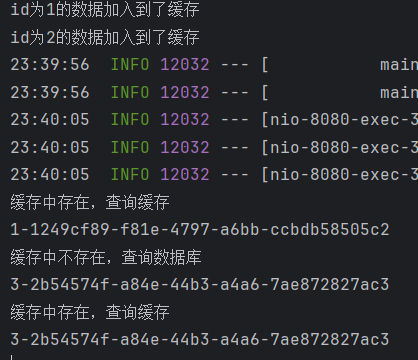
public class LocalCache {public static HashMap<String,String> cache = new HashMap<>();static {String name = 1 + "-" + UUID.randomUUID().toString();LocalCache.cache.put(String.valueOf(1),name);System.out.println("id为" + 1 + "的数据加入到了缓存");}@PostConstructpublic void init(){String name = 2 + "-" + UUID.randomUUID().toString();LocalCache.cache.put(String.valueOf(2),name);System.out.println("id为" + 2 + "的数据加入到了缓存");}
}编写接口进行测试:
@RestController
public class CacheController {@RequestMapping("/test/{id}")public String test(@PathVariable Long id) {String name = LocalCache.cache.get(String.valueOf(id));if(name != null) {System.out.println("缓存中存在,查询缓存");System.out.println(name);return name;}System.out.println("缓存中不存在,查询数据库");name = id + "-" + UUID.randomUUID().toString();System.out.println(name);LocalCache.cache.put(String.valueOf(id), name);return name;}
}效果:
2. WeakHashMap
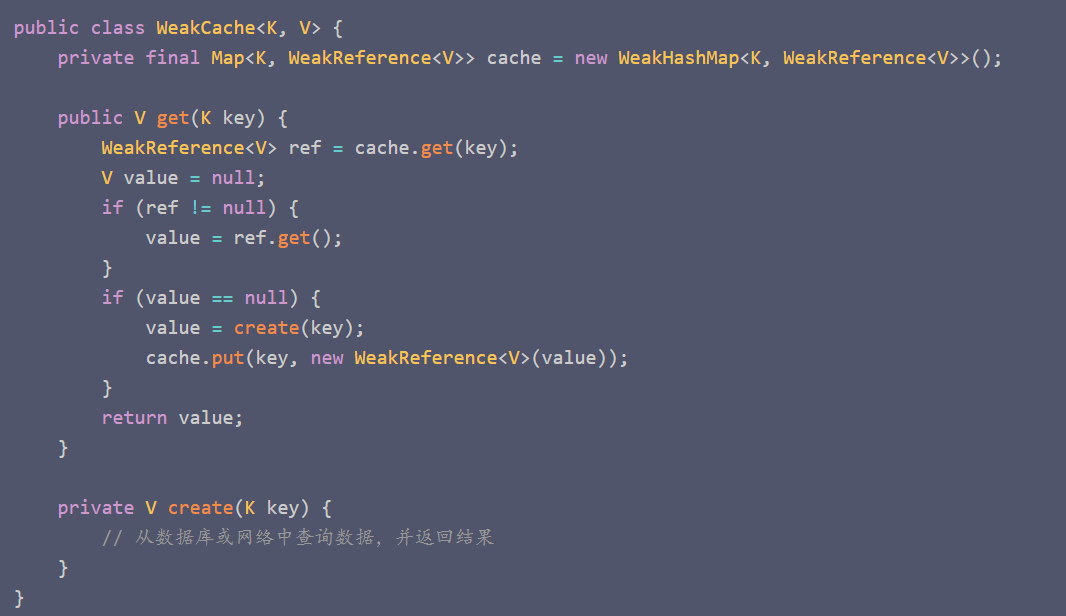
Java中WeakHashMap类是一种基于弱引用实现的Map集合(弱引用:当一个对象只被弱引用所引用时,它就可以被垃圾回收器回收),它的特点是:当Map中的某个键值对的键不再被强引用指向时,该键值对就会被自动清除。
示例代码:使用WeakHashMap来实现缓存,当一个缓存项中的键不再被强引用指向时,该缓存项就会被自动清除。当某个键对应的值已经被清除时,我们就需要重新创建(从网络或数据库中搜索)这个值,将其放入缓存中。
3. ConcurrentHashMap
ConcurrentHsshMap是 Java 中的一个线程安全的哈希表实现,通常用于在多线程环境下缓存数据。通过分段锁等技术允许多个线程并发的访问或修改不同的桶,减少了锁的争用,提升了并发性能。
- 线程安全:
ConcurrentHashMap内部使用了多把锁(默认情况下是16把),每个锁控制一部分数据(即一个桶),多个线程可以并发地操作不同的部分,而不会相互干扰。 - 高效的并发操作:在大多数情况下,读操作是无锁的(除了少数特定的场景)。而写操作只会锁住当前操作的部分(桶),而不会锁住整个表。
- 支持高效的并发遍历:虽然
ConcurrentHashMap不会抛出ConcurrentModificationException,但是在遍历期间,结构的修改(如插入或删除)可能不会被遍历时立即反映出来,但遍历操作本身仍然是线程安全的。
优点:
线程安全:
-
- 使用
ConcurrentHashMap确保了缓存的线程安全性,多线程环境下的并发读写操作不会引发数据不一致或死锁问题。
- 使用
TTL支持:
-
- 提供了 TTL的功能,可以设置缓存项的存活时间,自动删除过期的缓存项
内存管理:
-
- 在缓存项过期时,会自动从
ConcurrentHashMap中移除,避免过期数据占用内存,虽然实现上是懒删除,但已经能够在一定程度上控制内存的使用。
- 在缓存项过期时,会自动从
缺点:
没有主动清理机制:
-
- 当前实现是惰性删除,即只有在调用
get方法时才会检查并删除过期的缓存项。如果不频繁访问,可能会有大量的过期数据滞留在缓存中,导致内存占用增加。可以通过定期扫描或后台线程清理来改进。
- 当前实现是惰性删除,即只有在调用
没有容量控制:
-
- 这个实现没有设置缓存的容量上限,在数据量非常大时可能导致内存溢出。通常,缓存需要有一个容量限制,并通过 LRU等策略来管理缓存中的对象。
TTL粒度有限:
-
- 当前的 TTL 实现是基于系统时间的,对于精确性要求较高的场景(比如需要精确到毫秒级别的过期管理),可能不够准确。此外,TTL 是全局的,并没有提供按需调整的能力。
无统计功能:
-
- 缺乏缓存命中率等统计信息。通常在使用缓存时,我们希望能够知道缓存的命中率、失效率等,以便优化系统性能。
未支持序列化:
-
- 当前的实现不支持缓存项的序列化和反序列化,对于分布式缓存或持久化缓存的需求,这种实现不适用。
适用场景:
- 小型应用:适用于简单的单机应用或开发阶段的临时缓存需求。
- 低并发环境:尽管
ConcurrentHashMap是线程安全的,但当并发度很高时,可能仍需要更为复杂的缓存管理机制来保证性能和可靠性。 - 短生命周期的缓存:特别适合那些缓存数据生命周期较短,且缓存大小相对可控的场景。
常用缓存框架
1、Guava Cache
Guava Cache 是由 Google 提供的一个轻量级内存缓存实现,作为 Guava 库的一部分。它主要用于单机内存缓存管理,提供了多种灵活的缓存回收和失效策略。
主要特点:
- 缓存回收策略:支持基于时间的回收策略(如基于访问时间
expireAfterAccess和写入时间expireAfterWrite)以及基于缓存大小的回收策略(maximumSize)。 - 缓存加载:可以通过
CacheLoader实现自动缓存加载,当缓存中没有对应的值时自动加载数据。 - 统计信息:提供缓存命中率、加载时间等详细的统计信息。
- 柔性引用:支持软引用和弱引用,允许 JVM 在内存不足时回收缓存对象。
private static LoadingCache<String, String> cache = CacheBuilder.newBuilder().maximumSize(1000) // 最大缓存条目数.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期.expireAfterAccess(5, TimeUnit.MINUTES) // 最后一次访问后5分钟过期.refreshAfterWrite(1, TimeUnit.MINUTES) // 写入后1分钟刷新.weakKeys() // 使用弱引用存储键.weakValues() // 使用弱引用存储值.concurrencyLevel(4) // 设置并发级别.recordStats() // 开启统计信息.build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {return fetchDataFromDatabase(key);}});2、Ehcache
Ehcache 是一个广泛使用的 Java 缓存框架,主要用于 JVM 进程内的缓存管理。它提供了灵活的配置选项,支持磁盘持久化,并且可以通过集成第三方库实现分布式缓存。
主要特点:
- 持久化支持:Ehcache 支持将缓存的数据持久化到磁盘,适用于需要长时间保留缓存数据的场景。
- 分布式缓存:通过与 Terracotta 集成,Ehcache 可以实现分布式缓存,支持多节点之间的数据同步。
- 丰富的缓存策略:Ehcache 支持LRU、LFU、FIFO等缓存驱逐策略。
- 灵活配置:Ehcache 提供了 XML 和 Java API 两种配置方式,可以根据应用需求进行精细化配置。
- 与 Spring 集成良好:Ehcache 可以与 Spring 框架无缝集成,作为 Spring 的缓存管理器。
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"updateCheck="true"monitoring="autodetect"dynamicConfig="true"><diskStore path="java.io.tmpdir/ehcache"/><cache name="myCache"maxEntriesLocalHeap="1000"maxEntriesLocalDisk="10000"eternal="false"timeToIdleSeconds="300"timeToLiveSeconds="600"overflowToDisk="true"diskSpoolBufferSizeMB="30"memoryStoreEvictionPolicy="LFU"transactionalMode="off"><persistence strategy="localRestartable"/></cache></ehcache>
CacheManager cacheManager = CacheManager.create("path/to/ehcache.xml");Cache cache = cacheManager.getCache("myCache");// 添加缓存条目cache.put(new Element("key", "value"));// 获取缓存条目Element element = cache.get("key");if (element != null) {System.out.println(element.getObjectValue());}// 关闭缓存管理器cacheManager.shutdown();3、Caffeine
Caffeine 是一个高性能的 Java 缓存库,被认为是 Guava Cache 的升级版。它提供了更高效的缓存策略,支持异步加载和复杂的缓存淘汰机制。
主要特点:
- 高性能:Caffeine 在设计上经过了大量优化,提供了比 Guava Cache 更快的读写性能。
- 灵活的缓存策略:支持基于时间、访问频率和缓存权重的淘汰策略,使用Window TinyLFU算法进行缓存管理。
- 异步支持:支持异步缓存加载和刷新,适用于高并发场景。
- 统计信息:提供详细的缓存统计信息,包括命中率、加载时间、淘汰次数等。
- 可定制性:Caffeine 的配置非常灵活,几乎可以满足任何缓存需求。
private static AsyncLoadingCache<String, String> cache = Caffeine.newBuilder().maximumSize(1000) // 最大缓存条目数.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期.expireAfterAccess(5, TimeUnit.MINUTES) // 最后一次访问后5分钟过期.refreshAfterWrite(1, TimeUnit.MINUTES) // 写入后1分钟刷新.weakKeys() // 使用弱引用存储键.weakValues() // 使用弱引用存储值.recordStats() // 开启统计信息.buildAsync(key -> fetchDataFromDatabase(key)); // 异步加载数据分布式缓存
1、Redis
Redis 是一个开源的、高性能的分布式内存缓存数据库,支持多种数据结构(如字符串、哈希、列表、集合等),并且具有持久化特性。Redis 不仅可以用作缓存,还可以用作消息队列、会话存储等。
主要特点:
- 分布式支持:Redis 原生支持分布式,可以在多个节点之间实现数据复制和高可用性。
- 持久化:虽然 Redis 是内存数据库,但它支持将数据持久化到磁盘,防止数据丢失。
- 丰富的数据结构:Redis 支持多种数据结构,不仅限于键值对,还支持哈希、列表、集合、有序集合等复杂数据结构。
- 高性能:由于 Redis 数据存储在内存中,读写操作非常快速,适用于高并发场景。
- 丰富的生态:Redis 提供了丰富的功能,如发布/订阅、事务、Lua 脚本等,生态系统非常完善。
@Beanpublic RedisTemplate<String, Object> redisTemplate() {RedisTemplate<String, Object> template = new RedisTemplate<>();template.setConnectionFactory(redisConnectionFactory);template.setKeySerializer(new StringRedisSerializer());template.setValueSerializer(new StringRedisSerializer());template.setHashKeySerializer(new StringRedisSerializer());template.setHashValueSerializer(new StringRedisSerializer());template.afterPropertiesSet();return template;}2、Memcached
使用场景:
- 分布式缓存:Memcached 主要用于分布式系统中的缓存需求,适合需要在多个节点之间共享缓存数据的场景。它广泛用于提升数据库查询性能,减少数据库负载。
- Web 应用加速:在大型网站和高并发的应用中,Memcached 常用于缓存数据库查询结果、API 响应、会话数据等,以加速页面加载时间和响应速度。
- 简单数据结构:适用于缓存简单的数据结构,如字符串、整数和序列化后的对象数据。它不支持复杂的数据类型(如列表、集合等),通常用于键值对形式的数据缓存。
特点:
- 高性能:Memcached 是一个纯内存的缓存系统,具有极高的读写性能,适用于高并发的场景。
- 分布式特性:Memcached 支持将缓存分布在多个服务器节点上,通过一致性哈希算法来分布和查找缓存数据。
- 数据非持久化:Memcached 的数据仅存储在内存中,重启或崩溃后数据会丢失,因此它主要用于缓存临时性数据,而不是用于存储关键的持久性数据。
- 简单协议:Memcached 使用简单的文本协议或二进制协议,与各种编程语言(如 Java、Python、PHP 等)有良好的兼容性。
- 缺乏高级功能:与 Redis 等更复杂的缓存系统相比,Memcached 不支持数据持久化、复杂数据结构、发布订阅等高级功能。
private static MemcachedClient memcachedClient;// 初始化 Memcached 客户端static {memcachedClient = new MemcachedClient(new InetSocketAddress("localhost", 11211));}// 缓存数据public void cacheData(String key, Object value, int expiration) {OperationFuture<Boolean> future = memcachedClient.set(key, expiration, value);try {future.get(5, TimeUnit.SECONDS); // 等待操作完成} catch (Exception e) {e.printStackTrace();}}public static void main(String[] args) {MemcachedExample example = new MemcachedExample();// 设置缓存example.cacheData("key", "value", 3600);// 获取缓存System.out.println(example.getData("key"));// 删除缓存example.deleteData("key");// 关闭客户端example.shutdown();}// 获取缓存数据public Object getData(String key) {return memcachedClient.get(key);}// 删除缓存数据public void deleteData(String key) {memcachedClient.delete(key);}// 关闭客户端public void shutdown() {memcachedClient.shutdown();}
}缓存一致性
缓存一致性是指 缓存中的数据与后端数据源(如数据库)之间保持一致的状态。当数据库中的数据发生变化时,如何保证缓存中的数据及时更新或者失效,以避免缓存中的数据与数据库中的数据不一致,是缓存一致性需要解决的问题。缓存一致性是分布式系统中常见且复杂的问题,特别是在高并发环境下。
下面借用两篇文章:如何保证缓存和数据库的一致性 缓存和数据库的一致性问题
缓存策略
LRU(Least Recently Used,最近最少使用)
-
- 描述:淘汰最近最少使用的数据。
- 适用场景:适合常见的缓存场景,假设最近使用的数据更可能被再次使用。
LFU(Least Frequently Used,最少频繁使用)
-
- 描述:淘汰访问频率最低的数据。
- 适用场景:适合数据访问频率较为固定的场景。
FIFO(First In First Out,先进先出)
-
- 描述:按照数据进入缓存的时间顺序进行淘汰,最早进入的数据优先被淘汰。
- 适用场景:适合简单的时间序列或队列式缓存。
TTL(Time to Live,存活时间)
-
- 描述:每个缓存项都有固定的过期时间,到期后自动失效。
- 适用场景:适合动态数据缓存,如配置文件或临时数据。
MRU(Most Recently Used,最近最常使用)
-
- 描述:优先淘汰最近最常使用的数据。
- 适用场景:适合某些更新频繁的数据场景。
Random Replacement(随机替换)
-
- 描述:随机淘汰缓存中的一项数据。
- 适用场景:适合对淘汰数据没有明确偏好的场景。
缓存的设计与实现设计和实现一个缓存系统需要考虑多个方面,包括缓存的大小、过期策略、缓存粒度等。下面将详细介绍这些方面的设计考量以及如何实现缓存逻辑。
1. 缓存的设计
1.1 缓存大小
缓存大小决定了可以存储的数据量。缓存太小会导致频繁的缓存失效和加载,降低系统性能;缓存太大会占用过多内存资源。缓存大小的设计通常需要考虑以下因素:
- 可用内存: 需要确保缓存占用的内存不会影响系统的其他重要功能。
- 数据访问模式: 如果某些数据被频繁访问,可以优先缓存这些数据,即采用热点数据缓存的策略。
- 性能要求: 需要平衡缓存命中率和内存消耗,以满足系统的性能要求。
在设计时,可以使用一些缓存替换算法,如LRU(Least Recently Used,最近最少使用)、LFU(Least Frequently Used,最不经常使用)等,来决定在缓存满时如何移除旧数据。
1.2 过期策略
缓存的过期策略决定了缓存中数据的有效时间。常见的过期策略有:
- TTL(Time to Live,生存时间): 每个缓存项都有一个生存时间,过了这个时间数据就会失效。
- LRU过期: 根据最近访问时间决定哪些数据应该被淘汰。
- 手动过期: 开发者可以在特定条件下手动清除或更新缓存。
结合使用这些策略可以灵活管理缓存的有效性。例如,可以使用TTL保证数据不会过期过久,同时使用LRU来移除不常用的数据。
1.3 缓存粒度
缓存粒度指的是缓存中存储数据的大小和结构。缓存粒度的设计通常需要在以下几个方面进行权衡:
- 缓存命中率: 细粒度缓存可以更精确地存储和检索数据,但可能导致缓存项过多而增加管理复杂性。
- 存储开销: 粗粒度缓存(例如整页缓存)可以减少缓存项的数量,但可能会导致不必要的数据缓存,从而增加存储和带宽开销。
- 一致性要求: 细粒度缓存更容易管理数据的一致性,但维护成本较高。
在设计时,可以根据业务需求选择适合的粒度,比如将整个网页缓存作为一个缓存项,或者将用户会话数据细分为多个缓存项。
2. 缓存的实现
2.1 缓存加载
缓存加载涉及将数据加载到缓存中的过程,这通常发生在以下情况:
- 缓存不命中: 当请求的数据不在缓存中时,需要从数据源(如数据库)中加载数据并存入缓存。
- 预加载: 在系统初始化时或在预测某些数据即将被频繁访问时,可以提前加载数据到缓存中。
实现缓存加载的关键点在于确保数据的一致性和及时性。例如,在分布式系统中,需要考虑多个实例之间缓存的一致性问题。
2.2 缓存更新
缓存更新指的是在数据源发生变化后,更新缓存中的数据。常见的更新策略有:
- 写通(Write-Through): 数据在写入缓存的同时,也会同步写入数据源。
- 写回(Write-Back): 数据先写入缓存,稍后再异步写入数据源。
- 写旁路(Write-Around): 数据直接写入数据源,而不更新缓存,通常在读操作时才更新缓存。
缓存更新策略的选择需要根据系统对数据一致性和延迟的要求进行调整。
2.3 缓存失效
缓存失效是指缓存项不再有效,需要从缓存中移除或更新。失效策略通常与过期策略密切相关:
- 主动失效: 通过TTL或LRU等策略,自动判断缓存项是否需要失效。
- 被动失效: 通过业务逻辑判断某些条件是否满足,从而手动触发缓存失效。
- 分布式失效: 在分布式系统中,缓存失效可能需要广播或一致性协议来通知各个实例更新缓存。
3. 实现缓存系统的示例
以Java中的Redis为例,展示如何实现一个简单的缓存系统:
import redis.clients.jedis.Jedis;public class CacheSystem {private Jedis jedis;private int ttl; // 缓存的生存时间(秒)public CacheSystem(String redisHost, int redisPort, int ttl) {this.jedis = new Jedis(redisHost, redisPort);this.ttl = ttl; // 默认缓存时间}public static void main(String[] args) throws InterruptedException {CacheSystem cacheSystem = new CacheSystem("localhost", 6379, 30); // 缓存时间设置为30秒// 获取缓存,如果没有则加载System.out.println(cacheSystem.get("user:1001"));// 等待10秒后再获取Thread.sleep(10000);System.out.println(cacheSystem.get("user:1001"));// 使缓存失效cacheSystem.invalidate("user:1001");// 再次获取缓存,应该重新加载System.out.println(cacheSystem.get("user:1001"));}// 获取缓存public String get(String key) {String value = jedis.get(key);if (value == null) {System.out.println("Cache miss for key: " + key);value = loadFromSource(key);set(key, value);} else {System.out.println("Cache hit for key: " + key);}return value;}// 设置缓存public void set(String key, String value) {jedis.setex(key, ttl, value);System.out.println("Set cache for key: " + key + " with TTL: " + ttl + " seconds");}// 模拟从数据源加载数据private String loadFromSource(String key) {return "Value for " + key + " from source";}// 使缓存失效public void invalidate(String key) {jedis.del(key);System.out.println("Invalidated cache for key: " + key);}
}
实际案例的缓存实践
在实际项目中,缓存系统的设计和实现需要根据具体的业务场景进行细致的调整,以确保系统的高效性、稳定性和一致性。下面对上述的最佳实践进行更详细的说明。
1. 合理选择缓存策略
缓存策略决定了哪些数据应该被保留在缓存中,哪些应该被淘汰。根据业务访问模式选择合适的缓存策略是优化缓存系统的重要一步。
- LRU(Least Recently Used): 最近最少使用算法。适用于那些数据访问有时间局限性的场景,即最近访问的数据更有可能被再次访问。例如,在电商网站上,用户最近浏览过的商品很可能会再次被查看,因此适合使用LRU缓存策略。
- LFU(Least Frequently Used): 最少频繁使用算法。适用于那些访问频率决定数据重要性的场景。例如,热门新闻或文章的访问频率高,可以优先保存在缓存中,而冷门内容可以较快淘汰。
- FIFO(First In First Out): 先进先出算法。适合那些数据有固定有效期的场景,例如缓存某些定期更新的数据,如实时天气信息,每隔一段时间进行刷新。
选择缓存策略时,需要综合考虑系统的访问模式和数据的生命周期,尽可能提高缓存的命中率。
2. 监控缓存性能
缓存的性能直接影响系统的响应速度,因此对缓存性能的监控至关重要。以下是一些常见的缓存性能指标及其监控方法:
- 缓存命中率: 这是缓存系统的核心指标,表示从缓存中获取到的数据占总请求数据的比例。命中率越高,系统性能提升越明显。可以通过定期检查缓存命中率来判断缓存配置是否合理。如果命中率低,可能需要调整缓存策略或扩大缓存容量。
- 缓存加载时间: 当缓存未命中时,数据从数据源加载到缓存所需的时间。如果加载时间过长,会导致响应延迟,可能需要优化数据加载的过程或提高数据源的响应速度。
- 缓存失效和淘汰: 监控哪些数据被淘汰,什么时间淘汰,为什么被淘汰(如过期、达到容量限制等)。通过分析这些数据,可以更好地理解缓存的使用情况,进一步优化缓存策略。
监控工具可以使用如Prometheus结合Grafana进行实时监控,也可以通过日志分析工具对缓存系统进行离线分析。
3. 处理缓存穿透和击穿
在高并发场景下,缓存系统可能会遇到缓存穿透、击穿和雪崩等问题,需要采取有效措施进行预防和处理。
- 缓存穿透: 发生在对数据库或其他数据源中不存在的数据进行频繁请求时,这些请求直接落到数据库上,绕过缓存,造成数据库压力。处理方法包括:
-
- 缓存空结果: 当查询结果为空时,仍然将其缓存,但设置一个较短的TTL,避免频繁请求同样的数据。
- 布隆过滤器: 在访问缓存之前,使用布隆过滤器判断数据是否存在于数据源中,从而减少对无效请求的处理。
- 缓存击穿: 发生在某个热点数据在缓存失效时,突然大量请求打到数据库,导致数据库压力激增。处理方法包括:
-
- 设置互斥锁: 在缓存失效时,只有一个线程去加载数据,其他线程等待,避免并发加载。
- 热点数据预加载: 对一些热点数据定时刷新,确保在高峰期不会失效。
- 缓存雪崩: 发生在大量缓存同时失效时,所有请求直接打到数据库,导致数据库崩溃。处理方法包括:
-
- 随机化过期时间: 为不同的缓存设置不同的TTL,避免在同一时间大量缓存失效。
- 多级缓存架构: 通过引入多级缓存,如本地缓存和远程缓存相结合,分散请求压力。
4. 考虑分布式一致性
在分布式系统中,缓存的一致性问题尤为复杂,因为数据可能同时存在于多个节点的缓存中。以下是一些常见的解决方法:
- 一致性哈希: 将数据按照哈希分布到不同的缓存节点上,以减少缓存节点变更时的数据重新分配量。通过一致性哈希,可以确保即使某些缓存节点发生变化,仍然有大部分数据保持在原有节点上,从而提高缓存命中率和稳定性。
- 分布式锁: 在缓存更新或失效时使用分布式锁(如Redis的RedLock算法)来确保只有一个节点能够更新缓存,从而防止并发写入造成的数据不一致问题。
- 订阅发布机制: 通过使用Redis的订阅发布(Pub/Sub)功能或消息队列(如Kafka、RabbitMQ),当某个缓存节点的缓存失效或更新时,通知其他节点进行同步更新,确保全局缓存的一致性。
- 双写一致性: 在写入数据库和缓存时,确保两者同步写入。可以在数据库事务提交之后更新缓存,以确保数据的一致性。对于复杂场景,还可能需要采用最终一致性方案,通过异步方式在一定时间内保证数据一致。
总结
缓存系统在提升系统性能的同时,也带来了诸如一致性、穿透、击穿等复杂性问题。在实际项目中,必须根据业务特点选择合适的缓存策略和技术手段,进行合理的设计和优化,才能真正发挥缓存的优势,并确保系统的稳定性和高效性。通过监控和不断调整,可以实现最佳的缓存效果,为系统提供有力的性能保障。
附:其他学习文档
Java HashMap详解
锁学习:synchronized隐式锁,Lock显式锁、volatile、CAS
什么是死锁,如何解决
架构之高并发:缓存
Java:强引用,软引用,弱引用和虚引用
HashMap学习(JDK7)
ConcurrentHashMap学习
弱引用实现弱缓存策略
ConcurrentHashMap为什么放弃了分段锁
高并发解决方案详解
Java缓存机制
相关文章:
缓存学习
缓存基本概念 概念 对于缓存,最普遍的理解是能让打开某些页面速度更快的工具。从技术角度来看,其本质上是因为缓存是基于内存建立的,而内存的读写速度相比之于硬盘快了xx倍,因此用内存来代替硬盘作为读写的介质当然能大大提高访…...
亚世光电:消费电子年度表演
机圈风云再起,消费电子乘风而起? 今天我们来聊——亚世光电 最近,华为mate60突然降价,被大家怀疑是为新品上市做准备,算算时间,下半年的消费电子大战也即将拉开帷幕,而亚世光电所在的光电显示领…...

AI 工程应用 建筑表面检测及修复
文章目录 1 项目概述(必写):2 技术方案与实施步骤2.1 模型选择(必写):2.2 数据的构建:2.3 功能整合(进阶): 3 实施步骤:3.1 环境搭建(…...

Qt-Qt中的小事项(7)
目录 命名风格 快捷键 查询文档 坐标系 代码理解 move 命名风格 这个也是老生常谈的问题了,入乡随俗就好啦 快捷键 这里是一些常用的快捷键,用多了自然就熟悉了 • 注释:ctrl/ • 运行:ctrlR • 编译:ctrlB …...
Android MediaRecorder 视频录制及报错解决
目录 一、start failed: -19 二、使用MediaRecorder录制视频 2.1 申请权限 2.2 布局文件 2.3 MediaRecordActivity 2.4 运行结果 三、拓展 3.1 录制视频模糊(解决) 3.2 阿里云OSS上传文件 3.2.1 权限(刚需) 3.2.2 安装SDK 3.2.3 使用 相关链接 一、start failed…...

HarmonyOS应用程序访问控制探究
关于作者 白晓明 宁夏图尔科技有限公司董事长兼CEO、坚果派联合创始人 华为HDE、润和软件HiHope社区专家、鸿蒙KOL、仓颉KOL 华为开发者学堂/51CTO学堂/CSDN学堂认证讲师 开放原子开源基金会2023开源贡献之星 一、引言 随着信息技术的飞速发展,移动应用程序已经成为…...

董卫民赴考拉悠然等企业调研,强调加快发展人工智能产业
8月14日,按照省政府重点产业链协同推进机制有关工作安排,省委常委、常务副省长董卫民在成都市调研人工智能产业发展情况,并召开座谈会。他强调,要坚决落实党的二十届三中全会精神和省委省政府决策部署,充分把握人工智能…...

MFC将类A中的事件在类B中处理采用回调函数实现
需求: 在类A的界面上有一个tab控件。tab控件上面有那个页面。在MFC编程中一个tab的一个页面就应该是一个新的类。在tab的一个页面上有一个list控件。现在需要将list控件的点击事件,双击事件等在类A里面处理。 解决: 在类B里面给控件list添加…...

公众号 微信登录
export function getWxCode(that, localhostUrl) { // localhostUrl 当前页面的路径 传这个也可以this.$route.fullPath// console.log(that.$store.state.wxSessionData)// console.log(that.$store.state.wxSessionData.openId)//openId为undefine执行获取openid判断是否没有…...

sanic + webSocket:股票实时行情推送服务实现
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

Unity动态给按钮各个状态下的图片赋值
Unity动态给按钮各个状态下的图片赋值 using UnityEngine; using UnityEngine.UI; public class ButtonOnClickTest : MonoBehaviour {public Button btn;public Sprite _highlighterSprite;public Sprite _pressedSprite;public Sprite _selectesdSprite;public Sprite _disa…...

xiaomi pad 6PRO 小米平板6 pro hyperOS降级 澎湃os 降级MIUI 14 教程 免解锁BL 降级,168小时解锁绑定
小米平板 6 Pro 机型代号 :liuqin 降级MIUI 14 小米澎湃 OS 正式版 澎湃OS安卓发布日期卡刷包线刷包OS1.0.7.0.UMYCNXM14.02024-07-13miui_LIUQIN_OS1.0.7.0.UMYCNXM_d618a5c980_14.0.zipliuqin_images_OS1.0.7.0.UMYCNXM_20240705.0000.00_14.0_cn_8cbf5920be.…...

MySQL 备份一个表
语法(创建一个与table1结构相同的新表table2,并且将table1的数据复制到table2): create table table2 as select * from table1 举例(备份tb_log表到tb_log_20240815中去): create table tb_log_20240815 as select * from tb_log...

鸿蒙开发入门day10-组件导航
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,还请三连支持一波哇ヾ(@^∇^@)ノ) 目录 组件导航 (Navigation) 设置页面显示模式 设置标题栏模式 设置菜…...

虚拟机Linux的坑 | VMware无法从主机向虚拟机 跨系统复制粘贴拖动 文件/文本
这个情况下,还是没办法跨系统拖拽文件 解决办法: 在终端中输入命令 sudo apt-get autoremove open-vm-tools sudo apt-get install open-vm-tools sudo apt-get install open-vm-tools-desktop过程中只要需要选择是否覆盖的地方,都输入&…...
Chat App 项目之解析(二)
Chat App 项目介绍与解析(一)-CSDN博客文章浏览阅读76次。Chat App 是一个实时聊天应用程序,旨在为用户提供一个简单、直观的聊天平台。该应用程序不仅支持普通用户的注册和登录,还提供了管理员登录功能,以便管理员可以…...

数据结构与算法 - 双指针
一、移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例 1: 输入: nums [0,1,0,3,12]输出: [1,3,12,0,0]示例 2: 输入: nums …...
Python3网络爬虫开发实战(10)模拟登录(需补充账号池的构建)
文章目录 一、基于 Cookie 的模拟登录二、基于 JWT 模拟登入三、账号池四、基于 Cookie 模拟登录爬取实战五、基于JWT 的模拟登录爬取实战六、构建账号池 很多情况下,网站的一些数据需要登录才能查看,如果需要爬取这部分的数据,就需要实现模拟…...

SQL 调优最佳实践笔记
定义与重要性 SQL 调优:提高SQL性能,减少查询时间和资源消耗。目标:减少查询时间和扫描的数据行数。 基本原则 减少扫描行数:只扫描所需数据。使用合适索引:确保WHERE条件命中最优索引。合适的Join类型:…...
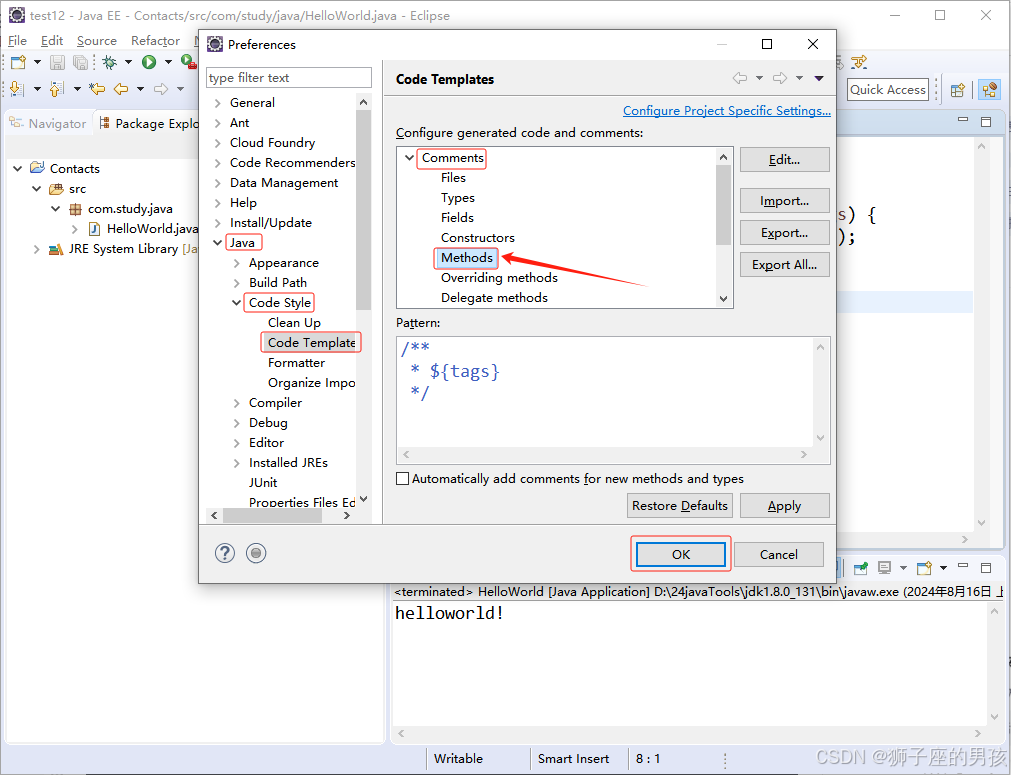
Eclipse的使用配置教程:必要设置、创建工程及可能遇到的问题(很详细,很全面,能解决90%的问题)
Eclipse的使用配置: Ⅰ、Eclipse 的必要配置:1、Eclipse 的安装:其一、将 Eclipse 解压或安装到没有中文且没有空格的路径下。其二、拿到 eclipse.exe 文件,傻瓜式安装即可; 2、设置工作空间(workspace):其一、首次启动…...

计算机毕业设计springboot长春的地铁综合服务管理系统 基于SpringBoot的城市轨道交通智慧运维管理平台 SpringBoot框架下的地铁运营调度与设备管控系统
计算机毕业设计springboot长春的地铁综合服务管理系统 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着城市化进程的加速推进,长春市作为东北地区的重要交通枢纽&…...
)
Verilog有限状态机实战:5分钟搞定红绿灯控制器(附完整代码)
Verilog有限状态机实战:从红绿灯控制器掌握FPGA设计精髓 红绿灯控制器是数字电路设计的经典案例,也是学习Verilog有限状态机(FSM)的最佳切入点。作为FPGA初学者,你可能已经看过各种理论讲解,但真正动手时依…...

【实用技巧】-Mac系列设备自定义鼠标指针颜色与动态效果指南
1. 为什么需要自定义鼠标指针? 作为一个用了十年Mac的老用户,我深知默认的白色指针在复杂界面中经常"消失"的烦恼。特别是做设计时,盯着色彩斑斓的PS画布,那个小箭头简直像在玩捉迷藏。更糟的是在演示场景,观…...

WLAN——从零到一:深度解析CAPWAP隧道建立与AP上线全流程
1. 初识CAPWAP:无线网络的隐形桥梁 第一次接触CAPWAP协议时,我盯着拓扑图上AP和AC之间的虚线发愣——这条看似简单的连接线背后,竟然藏着无线网络最精妙的控制逻辑。CAPWAP(Control And Provisioning of Wireless Access Points P…...

Claude Code 是怎么跑起来的:从 Agent Loop 理解代理循环实现
如果你已经会调用大模型、也知道 tool calling 和 agent 的基本概念,那接下来最值得看的问题通常不是“怎么再包一层 prompt”,而是:一个真正能跑任务的 agent,到底是怎么在代码里运转起来的。 这篇文章不从抽象定义讲起ÿ…...

AI 焦虑别乱投!3 个问题秒懂要不要养「虾」
作者 | 张辉清 责编 | 梦依丹出品 | 程序人生(ID:coder_life)当下 AI 热度居高不下,企业该如何抉择?是大举投入布局,还是保持观望?我们借以下三个问题来展开思考。AI 当下处在什么阶段…...

降AI率工具哪个好用知网维普万方分开对比
很多同学只关心"知网通没通过",但2026年越来越多学校开始同时要求知网和维普双重检测,部分学校还加了万方。 问题在于:一款工具在知网效果好,不代表在维普和万方也同样好。这是因为三个平台的AIGC检测算法不同。 这篇…...

低显存福音:实测Neeshck轻量化工具,16G显卡流畅跑Z-Image模型
低显存福音:实测Neeshck轻量化工具,16G显卡流畅跑Z-Image模型 1. 轻量化方案的诞生背景 1.1 大模型与小显存的矛盾 Z-Image作为国产文生图模型的代表,其强大的生成能力有目共睹。但原生部署对显存的高要求(通常需要20GB以上&am…...

Stata实操:用GARCH模型预测沪深300波动率,手把手教你从数据清洗到结果解读
Stata金融实战:从沪深300数据到GARCH波动率预测全流程解析 沪深300指数作为中国股市的风向标,其波动率预测对风险管理至关重要。去年一位私募基金研究员曾向我展示过他们的发现:当使用GARCH模型捕捉到波动率聚集特征时,对冲策略的…...

3个颠覆性策略实现网站到Figma设计的智能双向转换
3个颠覆性策略实现网站到Figma设计的智能双向转换 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 你是否曾为设计还原度低、开发周期长、团队协作效率低下而困扰?Figm…...