Python3网络爬虫开发实战(10)模拟登录(需补充账号池的构建)
文章目录
- 一、基于 Cookie 的模拟登录
- 二、基于 JWT 模拟登入
- 三、账号池
- 四、基于 Cookie 模拟登录爬取实战
- 五、基于JWT 的模拟登录爬取实战
- 六、构建账号池
很多情况下,网站的一些数据需要登录才能查看,如果需要爬取这部分的数据,就需要实现模拟登入的一些机制;模拟登录现在主要分为两种方式,一种是基于 Session 和 Cookie 的模拟登入,一种是基于 JWT(Json Web Token)的模拟登录。
对于第一种模式,打开网页后模拟登录,服务器会返回带有 Set-Cookie 字段的响应头,客户端会生成对应的 Cookie,其中保存着与 SessionID 相关的信息,之后发送给服务器的请求都会携带这个生成的 Cookie。服务器接收到请求后,会根据 Cookie 中保存的 SessionID 找到对应的 Session,同时效验 Cookie 里的相关信息,如果当前 Session 是有效的并且效验成功,服务器就判断当前用户已经登录,返回请求的页面信息,所以这种模式的核心是获取客户端登录后生成的 Cookie;
对于第二种模式,是因为现在有很多的网站采取的开发模式是前后端分离模式,所以使用 JWT 进行登录效验越来越普遍,在请求数据时,服务器会效验请求中携带的 JWT 是否有效,如果有效,就返回正常的数据,所以这种模式其实就是获取 JWT;
一、基于 Cookie 的模拟登录
如果要使用爬虫实现基于 Session 和 Cookie 的模拟登录,最为主要的是要维护好 Cookie 的信息,因为爬虫相当于客户端的浏览器;
- 如果在浏览器中登录了自己的账号,可以直接把网页中的 Cookie 复制给爬虫,就相当于手动在浏览器中登录;
- 如果让爬虫完全自动化操作,可以直接使用爬虫模拟登录过程,这个过程基本上就是一个 POST 请求,用爬虫把用户名,密码等信息提交给服务器,服务器会返回一个 Set-Cookie 字段,我们只需要将该字段保存下来,然后提交给爬虫请求就好;
- 如果 POST 请求难以构造,我们可以使用自动化工具来模拟登录,例如使用 Selenium,Playwright 来发送请求,然后获取 Cookie 进行发送请求;
二、基于 JWT 模拟登入
JWT 的字符串就是用户访问的凭证,所以模拟登录只需要做到以下几步:
- 模拟登录操作,例如拿着用户名和密码信息请求登录接口,获取服务器返回的结果,这个结果中通常包含 JWT 信息,将其保存下来即可;
- 之后发送给服务器的请求均携带 JWT,在 JWT 不过期的情况下,通常能正常访问和执行操作,携带方式多种多样,因网站而异;
- 如果 JWT 过期了,可能需要再次做第一步,重新获取 JWT;
三、账号池
如果爬虫要求爬取的数据量比较大,或者爬取速度比较快,网站又有单账号并发限制或者访问状态检测等反爬虫手段,我们的账号可能就无法访问网站或者面临封号的风险;
这时我们建立一个账号池进行分流,用多个账号随机访问网站或爬取数据,这样能大幅提高爬虫的并发量,降低被封号的风险,例如准备 100 个账号,将这 100 个账号都模拟登录,并保存对应的 Cookie 和 JWT,每次都随机抽取一个来访问,账号多,所以每个账号被选取的概率就小,也就避免了单账号并发量过大的问题,从而降低封号风险;
四、基于 Cookie 模拟登录爬取实战
目标网址:Scrape | Movie
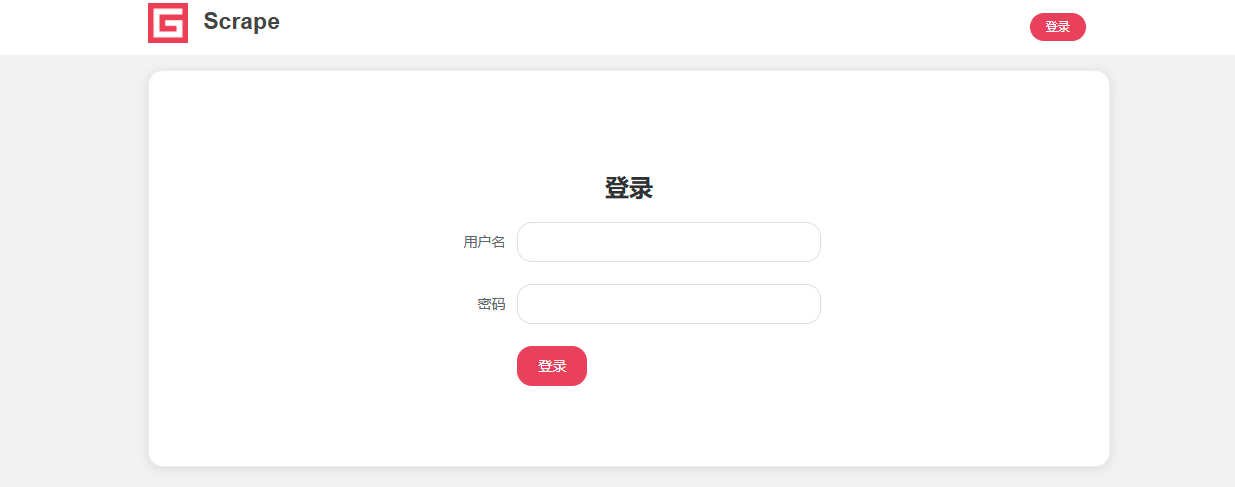
账号:admin
密码:admin
这里由于登入请求构造并没有涉及到加密过程,因此我们可以直接构造 requests 请求来执行请求;仔细分析后可以发现登入请求返回的状态码是 302,同时登入完毕后页面自动发生了跳转,因此在使用 requests 够着 post 请求的时候,需要将 allow_redirects 参数设置为 False;
import requests
import parselheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Origin': 'https://login2.scrape.center','Referer': 'https://login2.scrape.center/login','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}data = {'username': 'admin','password': 'admin',
}response = requests.post('https://login2.scrape.center/login', headers=headers, data=data, allow_redirects=False)# 得到 cookies
cookies = response.cookies.get_dict()# 将获取到的 cookie 放入 requests 的 get 请求中
response = requests.get('https://login2.scrape.center/', cookies=cookies, headers=headers)# 解析网页数据
selector = parsel.Selector(response.text)
names = selector.xpath('//*[@id="index"]/div[1]/div[1]/div/div/div/div[2]/a/h2/text()').getall()# 打印名字
print(names)# ['霸王别姬 - Farewell My Concubine',
# '这个杀手不太冷 - Léon',
# '肖申克的救赎 - The Shawshank Redemption',
# '泰坦尼克号 - Titanic',
# '罗马假日 - Roman Holiday',
# '唐伯虎点秋香 - Flirting Scholar',
# '乱世佳人 - Gone with the Wind',
# '喜剧之王 - The King of Comedy',
# '楚门的世界 - The Truman Show',
# '狮子王 - The Lion King']
在这里我们首先获得了 cookies,然后又手动要将 cookies 放入到后续的请求之中,这里我们可以构建 Session 请求来自动化添加 cookies;如下
import requests
import parselheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Origin': 'https://login2.scrape.center','Referer': 'https://login2.scrape.center/login','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}data = {'username': 'admin','password': 'admin',
}# 构建 session
session = requests.Session()# 发送登入请求
response = session.post('https://login2.scrape.center/login', headers=headers, data=data, allow_redirects=False)# 无需手动配置 cookies,发送页面请求
response = session.get('https://login2.scrape.center/', headers=headers)# 解析网页数据
selector = parsel.Selector(response.text)
names = selector.xpath('//*[@id="index"]/div[1]/div[1]/div/div/div/div[2]/a/h2/text()').getall()# 打印名字
print(names)# ['霸王别姬 - Farewell My Concubine',
# '这个杀手不太冷 - Léon',
# '肖申克的救赎 - The Shawshank Redemption',
# '泰坦尼克号 - Titanic',
# '罗马假日 - Roman Holiday',
# '唐伯虎点秋香 - Flirting Scholar',
# '乱世佳人 - Gone with the Wind',
# '喜剧之王 - The King of Comedy',
# '楚门的世界 - The Truman Show',
# '狮子王 - The Lion King']
这里是对于请求未涉及到加密或者带有验证码的网站,如果涉及到加密但是又不会解密,我们可以使用自动化工具来获取 Cookie;这里以 Playwright 为例子;
import requests
import parsel
from playwright.sync_api import sync_playwrightdef get_cookies():with sync_playwright() as playwright:cookies = {}browser = playwright.chromium.launch(headless=True)context = browser.new_context()page = context.new_page()page.goto("https://login2.scrape.center/login")page.locator('input[name="username"]').fill("admin")page.locator('input[name="password"]').fill("admin")page.locator('input[type="submit"]').click()cookieList = context.cookies()context.close()browser.close()for cookie in cookieList:cookies[cookie['name']] = cookie['value']return cookiesheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Origin': 'https://login2.scrape.center','Referer': 'https://login2.scrape.center/login','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}cookies = get_cookies()
response = requests.get('https://login2.scrape.center/', cookies=cookies, headers=headers)# 解析网页数据
selector = parsel.Selector(response.text)
names = selector.xpath('//*[@id="index"]/div[1]/div[1]/div/div/div/div[2]/a/h2/text()').getall()# 打印名字
print(names)# ['霸王别姬 - Farewell My Concubine',
# '这个杀手不太冷 - Léon',
# '肖申克的救赎 - The Shawshank Redemption',
# '泰坦尼克号 - Titanic',
# '罗马假日 - Roman Holiday',
# '唐伯虎点秋香 - Flirting Scholar',
# '乱世佳人 - Gone with the Wind',
# '喜剧之王 - The King of Comedy',
# '楚门的世界 - The Truman Show',
# '狮子王 - The Lion King']
五、基于JWT 的模拟登录爬取实战
目标网址:Scrape | Movie
账号:admin
密码:admin
import requestsheaders = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection": "keep-alive","Content-Type": "application/json;charset=UTF-8","Origin": "https://login3.scrape.center","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0","sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',"sec-ch-ua-mobile": "?0","sec-ch-ua-platform": '"Windows"',
}json_data = {"username": "admin","password": "admin",
}# 这里使用 json 而不是使用 data 传参是因为 headers 中的 Content-Type 接受的是 application/json 数据
response = requests.post("https://login3.scrape.center/api/login", headers=headers, json=json_data
)# 获取 token 构建 headers 中的 Authorization
token = response.json()["token"]
Authorization = "jwt " + token
headers = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Authorization": Authorization,"Connection": "keep-alive","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0","sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',"sec-ch-ua-mobile": "?0","sec-ch-ua-platform": '"Windows"',
}params = {"limit": "18","offset": "0",
}# 直接使用 get 请求获取数据
response = requests.get("https://login3.scrape.center/api/book", params=params, headers=headers
)print(response.json())# {
# "count": 9200,
# "results": [
# {
# "id": "34473697",
# "name": "R数据科学实战:工具详解与案例分析",
# "authors": ["刘健", "邬书豪"],
# "cover": None,
# }
# ],
# }
在这里由于使用的是 JWT,响应头中并不会返回一个 Set-Cookies 参数,因此使用 Session 来完成 JWT 是没有效果的,只能单个请求进行构建;
六、构建账号池
相关文章:
Python3网络爬虫开发实战(10)模拟登录(需补充账号池的构建)
文章目录 一、基于 Cookie 的模拟登录二、基于 JWT 模拟登入三、账号池四、基于 Cookie 模拟登录爬取实战五、基于JWT 的模拟登录爬取实战六、构建账号池 很多情况下,网站的一些数据需要登录才能查看,如果需要爬取这部分的数据,就需要实现模拟…...

SQL 调优最佳实践笔记
定义与重要性 SQL 调优:提高SQL性能,减少查询时间和资源消耗。目标:减少查询时间和扫描的数据行数。 基本原则 减少扫描行数:只扫描所需数据。使用合适索引:确保WHERE条件命中最优索引。合适的Join类型:…...
Eclipse的使用配置教程:必要设置、创建工程及可能遇到的问题(很详细,很全面,能解决90%的问题)
Eclipse的使用配置: Ⅰ、Eclipse 的必要配置:1、Eclipse 的安装:其一、将 Eclipse 解压或安装到没有中文且没有空格的路径下。其二、拿到 eclipse.exe 文件,傻瓜式安装即可; 2、设置工作空间(workspace):其一、首次启动…...

遗传算法与深度学习实战(4)——遗传算法详解与实现
遗传算法与深度学习实战(4)——遗传算法详解与实现 0. 前言1. 遗传算法简介1.1 遗传学和减数分裂1.2 类比达尔文进化论 2. 遗传算法的基本流程2.1 创建初始种群2.2 计算适应度2.3 选择、交叉和变异2.4算法终止条件 3. 使用 Python 实现遗传算法3.1 构建种…...

Nginx+Tomcat实现负载均衡、动静分离集群部署
文章目录 一、Nginx实现负载均衡原理1.正向代理和反向代理2.负载均衡模式1. 轮询(Round Robin):2. 最少连接数(Least Connections):3. IP 哈希(IP Hash):4. 加权轮询…...

英语学习8月19日
词根前缀后缀 accomplishment 成就 acid n.酸的,adj.酸的 acidity n.酸性 ace adj.顶尖的 acute adj.敏锐的;急性的;严重的 acuity n.敏锐 obtuse adj.迟钝的;钝角的 acuity n.敏锐,严重 1.前缀ac: 尖&#x…...
关于windows环境使用nginx的一些性能问题
遇到的问题 最近在一个windows环境中部署nginx,遇到了以下问题: 1. nginx启动了九个线程(1master8woekr),但是所有链接都被1个woker接收,其余worker不工作 2. 用户端访问web很慢,登录服务器使…...
“解决Windows电脑无法投影到其他屏幕的问题:尝试更新驱动程序或更换视频卡“
背景: 今天在日常的工作中, 我想将笔记本分屏到另一个显示屏,我这电脑Windows10,当我按下Windows键P键,提示我"你的电脑不能投影到其他屏幕,请尝试从新安装驱动程序或使用"遇到这种问题。 解决方法1: 1.快…...

第10章 无持久存储的文件系统 (2)
目录 10.1 proc文件系统 10.1.2 数据结构 10.1.3 初始化 10.1.4 装载 proc 文件系统 10.1.5 管理 /proc 数据项 10.1.6 读取和写入信息 10.1.7 进程相关信息 10.1.8 系统控制机制 本专栏文章将有70篇左右,欢迎关注,查看后续文章。 10.1 proc文件…...
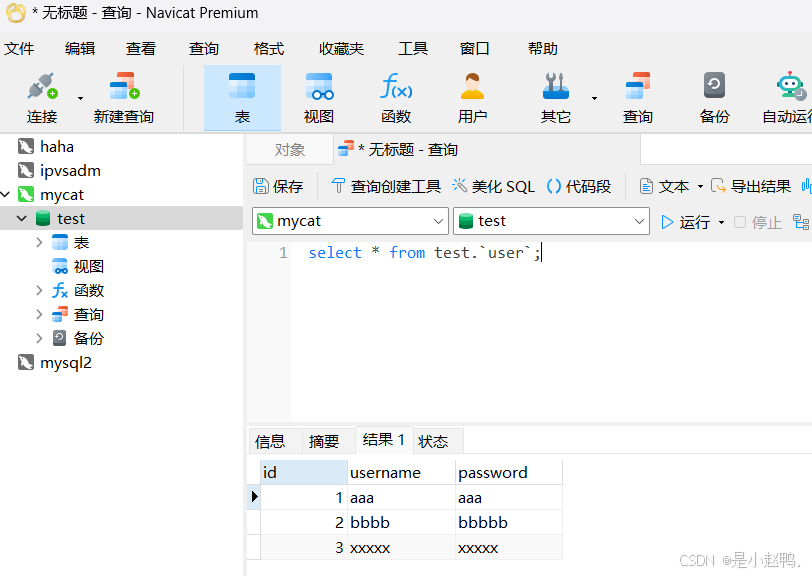
云计算实训29——mysql主从复制同步、mysql5.7版本安装配置、python操作mysql数据库、mycat读写分离实现
一、mysql主从复制及同步 1、mysql主从自动开机同步 2、配置mysql5.7版本 mysql-5.7.44-linux-glibc2.12-x86_64.tar 启动服务、登录 对数据库进行基本操作 3、使用python操纵mysql数据库 4、编辑python脚本自动化操纵mysql数据库 二、mycat读写分离实现 1.上传jdk和mycat安装…...
AI搜索引擎Perplexica的本地部署(之二)Perplexica的非docker安装
Perplex 是一个开源的AI 驱动的搜索引擎,可以使用 Grok 和 Open AI 等模型在计算机上本地安装和运行。它为学术研究、写作、YouTube 和 Reddit 提供了一系列搜索功能。用户可以通过选择不同的模型、设置本地嵌入模型和探索各种搜索选项来定制他们的体验。该工具演示…...

Oracle环境下在相同参数和数据源的情况,mybatis-plus查询和sql查询结果不一致
场景: 在系统中某个对象执行修改的时候,查询对象为空,造成修改报错 分析: 在传参中有一个eq的参数需要传null,mybatis-plus在执行eq时可能是拼成" null",但是oracle中查null必须要用is null, null是查不出东西的 解决: 改成用sql查询修改,或者加判断如果这个参…...
springboot静态资源访问问题归纳
以下内容基于springboot 2.3.4.RELEASE 1、默认配置的springboot项目,有四个静态资源文件夹,它们是有优先级的,如下: "classpath:/META-INF/resources/", (优先级最高) "classpath:/reso…...
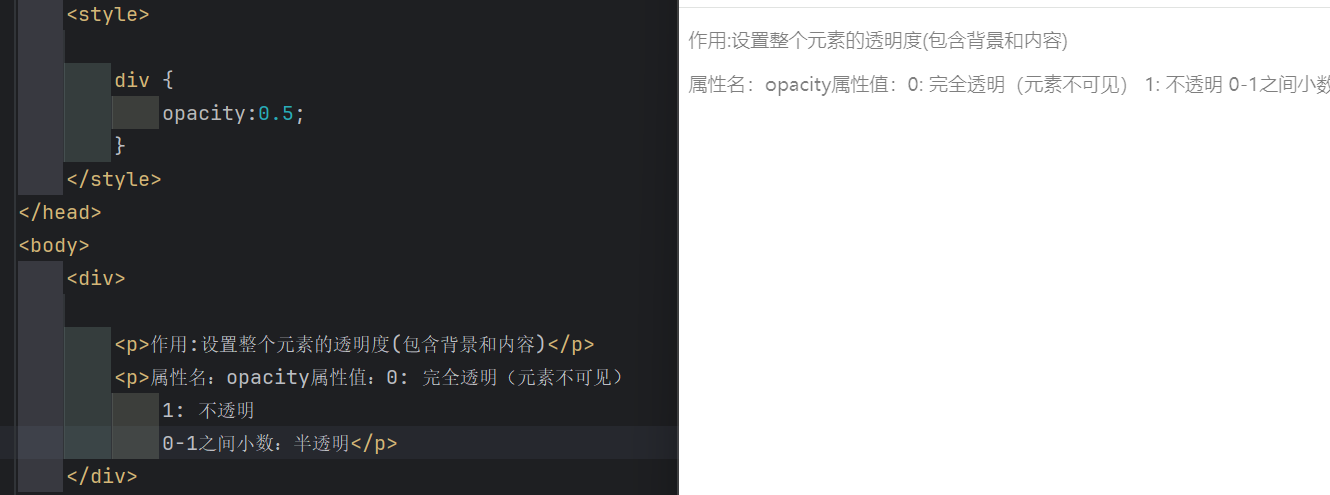
HTML与CSS学习Day01
文章目录 一 、CSS技巧1.1 CSS精灵(CSS Sprites)1.1.1 实现步骤1.1.2 例子 1.2 字体图标1.2.1如何使用字体图标1.2.2 字体图标使用总结 1.3 垂直对齐方式vertical-align1.3.1 值1.3.2 例子 1.4 过渡效果transition1.4.1 CSS过渡效果(transiti…...
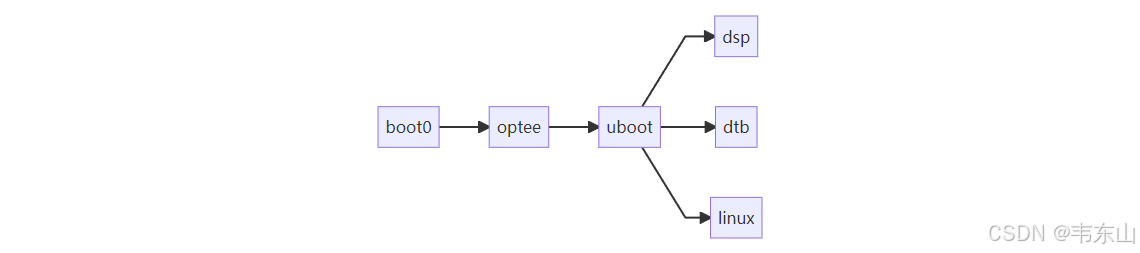
Tina-Linux Bootloaer简述
Tina-Linux Bootloaer简述 目录介绍 ubuntuubuntu1804:~/tina-v2.0-sdk/lichee/brandy-2.0$ tree -L 1 . ├── build.sh ├── opensbi ├── spl //boot0 ├── spl-pub //boot0 ├── tools └── u-boot-2018 /ubootTina-Linux 启动流程简述...

【Python】 Scrapyd:Python Web Scraping 的强大分布式调度工具
我听见有人猜 你是敌人潜伏的内线 和你相知多年 我确信对你的了解 你舍命救我画面 一一在眼前浮现 司空见惯了鲜血 你忘记你本是娇娆的红颜 感觉你我彼此都那么依恋 🎵 许嵩《内线》 在网络爬虫项目中,Scrapy 是 Python 中最流行和…...
吴恩达机器学习课后题-01线性回归
线性回归 一.单变量线性回归题目损失函数(代价函数)梯度下降函数代价函数可视化整体代码 二.多变量线性回归特征归一化(特征缩放)不同学习率比较 正规方程正规方程与梯度下降比较 使用列表创建一维数组使用嵌套列表创建二维数组&a…...

白盒报告-jacoco
使用jacoco--执行nvn test 运行过程: 1、idea执行mvn test ,运行过程如下: a.maven-surefire-plugin:0.8.7执行目标动作:prepare-agent, 目的是:执行目标动作是为了在当前的项目名下生成jecoco.…...

【MySQL】SQL语句执行流程
目录 一、连接器 二、 查缓存 三、分析器 四、优化器 五、执行器 一、连接器 学习 MySQL 的过程中,除了安装,我们要做的第一步就是连接上 MySQL 在一开始我们都是先使用命令行连接 MySQL mysql -h localhost -u root -p 你的密码 使用这个命令…...
Selenium自动化防爬技巧:从入门到精通,保障爬虫稳定运行,通过多种方式和add_argument参数设置来达到破解防爬的目的
在Web自动化测试和爬虫开发中,Selenium作为一种强大的自动化工具,被广泛用于模拟用户行为、数据抓取等场景。然而,随着网站反爬虫技术的日益增强,直接使用Selenium很容易被目标网站识别并阻止。因此,掌握Selenium的防爬…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...
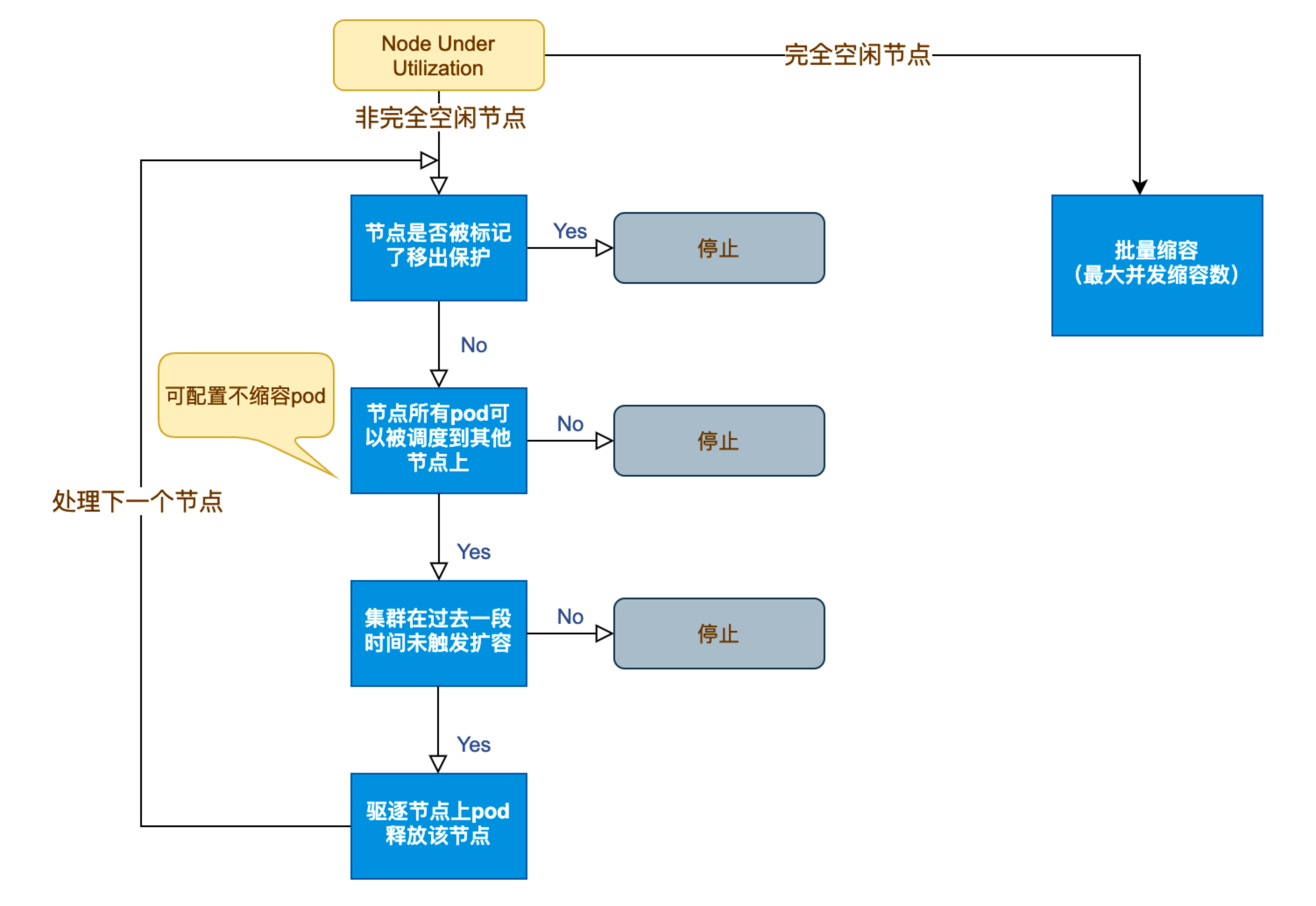
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...
Linux基础开发工具——vim工具
文章目录 vim工具什么是vimvim的多模式和使用vim的基础模式vim的三种基础模式三种模式的初步了解 常用模式的详细讲解插入模式命令模式模式转化光标的移动文本的编辑 底行模式替换模式视图模式总结 使用vim的小技巧vim的配置(了解) vim工具 本文章仍然是继续讲解Linux系统下的…...
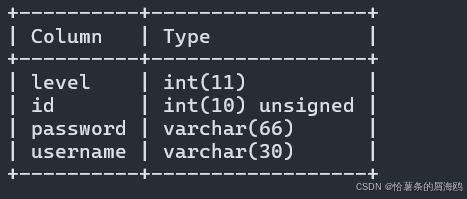
SQL注入篇-sqlmap的配置和使用
在之前的皮卡丘靶场第五期SQL注入的内容中我们谈到了sqlmap,但是由于很多朋友看不了解命令行格式,所以是纯手动获取数据库信息的 接下来我们就用sqlmap来进行皮卡丘靶场的sql注入学习,链接:https://wwhc.lanzoue.com/ifJY32ybh6vc…...