如何合理设置PostgreSQL的`max_connections`参数
合理设置PostgreSQL的max_connections参数对于数据库的稳定性和性能至关重要。这个设置值决定了允许同时连接到数据库的最大客户端数量。如果设置不当,可能导致资源浪费或系统过载。以下是设置max_connections时需要考虑的几个关键因素:
1. 评估系统硬件资源
max_connections值与系统的硬件资源密切相关,特别是内存和CPU资源。
-
内存(RAM): 每个连接都会占用一定量的内存。内存不足会导致系统交换频繁,从而降低性能。
- Shared Buffers: 推荐设置为总内存的25%-40%。
- Work Mem: 每个连接的工作内存,通常设置为2MB-64MB。
- Maintenance Work Mem: 用于维护任务(如
VACUUM、CREATE INDEX),通常设置为64MB-512MB。
-
CPU: 如果并发连接过多,CPU可能成为瓶颈。需要确保CPU能够处理所有连接的负载。
-
CPU Cores: 系统的CPU核心数量是决定能够同时处理多少并发连接的重要因素。
2. 计算每个连接的内存需求
在设置max_connections之前,计算每个连接的内存开销是非常重要的。每个连接的内存需求可以通过以下公式估算:
每一个连接消耗内存 = work_mem * 并行操作数 + 连接开销
- work_mem: 每个连接的工作内存
- 并行操作数: 通常假设一个连接会执行2-4个并行操作
- 连接开销: 通常为2-4MB
假设:
work_mem = 4MB- 每个连接假设 3 个并行操作(如排序、哈希)
- 每个连接开销为 2MB
根据公式,我们可以计算得出每一个连接所消耗的内存大小为:
4MB * 3 + 2MB = 14MB
3. 估算总内存需求
根据连接数和每个连接的内存需求,估算数据库的总内存需求。确保总内存需求小于可用内存的合理比例(通常不超过总内存的80%),以避免系统因内存不足而发生交换或崩溃。
总消耗内存 = 最大连接数 * 每一个连接消耗的内存 + Shared_Buffers + maintenance_work_mem + 主机总内存 * (Shared_Buffers / 主机总内存)
假设:
work_mem = 4MB- 每个连接假设 3 个并行操作(如排序、哈希)
- 每个连接开销为 2MB
max_connections = 200- 总系统内存为 64GB
Shared Buffers设置为 16GB(25%)maintenance_work_mem设置为 512MB
根据公式,我们可以计算得出每一个连接所消耗的内存大小为:
- 每一个连接消耗内存:
4MB * 3 + 2MB = 14MB- 总消耗内存:
200 × 14MB + 16GB + 512MB + 64GB × 0.25 = 2.8GB + 16GB + 512MB + 16GB = 35.3GB
每一个连接消耗内存 = 4MB × 3 + 2MB = 14MB
总消耗内存 = 200 × 14MB + 16GB + 512MB + 64GB × 0.25 = 2.8GB + 16GB + 512MB + 16GB = 35.3GB
通过这种方式,确保数据库的总内存需求在可用内存的合理范围内,以保证系统的稳定性和高效性。
4. 考虑应用程序需求
应用程序的连接需求是设置max_connections的关键因素,以下几点需要重点考虑:
-
连接池管理: 如果应用程序使用连接池(如PgBouncer),可以适当降低
max_connections的设置值。连接池通过复用现有连接来管理数据库连接,减少了对数据库的直接连接需求,从而可以有效降低所需的最大连接数。 -
应用程序的并发量: 评估应用程序的峰值并发连接数是设置
max_connections的重要步骤。了解应用程序在高峰时刻的并发连接需求,以确保max_connections能够满足业务的最大并发需求,同时避免设置过高而导致资源浪费。 -
连接释放策略: 确保应用程序在完成数据库操作后及时释放连接,以避免不必要的连接占用。合理的连接释放策略可以降低连接数的长期占用,提高数据库资源的利用率,进而允许
max_connections值的设置更加优化。
通过充分考虑这些应用程序的需求,可以更加精准地设置max_connections,确保数据库既能满足业务需求,又不会因为连接数设置不当而导致性能问题。
5. 设置合理的max_connections值
根据硬件资源和应用需求,合理设置max_connections值。
推荐的最大连接数 = 可用于连接的内存 / 每个连接消耗的内存
其中,可用于连接的内存是扣除Shared Buffers、Maintenance Memory和启动系统占用的内存后的可用内存。
假设:
- 总内存: 64GB
- Shared Buffers: 16GB
- maintenance_work_mem: 512MB
- 其他系统内存消耗: 64GB × 0.2 = 12.8GB
- 每个连接的内存消耗: 14MB
根据公式,我们可以计算得出:
- 可用于连接的内存: = 64GB - 16GB - 512MB - 12.8GB = 34.688GB
- 推荐的最大连接数: = 34.688GB / 14MB ≈ 2480
根据计算,推荐的最大连接数为约2480个。这个值可以根据实际业务需求和负载测试进一步调整。
6. 调整其他相关参数
设置max_connections后,还需要调整其他与连接管理相关的参数:
shared_buffers: 一般设置为总内存的25%-40%。work_mem: 根据每个连接的工作内存需求调整。maintenance_work_mem: 为维护任务预留足够的内存,通常为64MB-512MB。effective_cache_size: 设置为系统可用内存的50%-75%,用于查询规划器估算缓存使用情况。
7. 监控和优化
设置完max_connections后,持续监控系统的实际表现,尤其是在高负载时。
- 监控工具: 使用PostgreSQL自带的
pg_stat_activity、pg_stat_statements和第三方监控工具(如Prometheus、Grafana)监控连接使用情况。- 性能调优: 如果监控显示系统资源紧张或连接数经常达到上限,考虑进一步优化查询、调整参数,或者增加硬件资源。
结语
合理设置max_connections需要综合考虑系统的硬件资源、应用程序的需求以及数据库的实际负载。通过精确的计算和参数调整,可以确保数据库在高并发情况下依然稳定、高效地运行。此外,持续监控和优化是确保max_connections设置合理的关键步骤。在实际操作中,应结合具体业务需求和负载测试结果,灵活调整max_connections,以更好地管理数据库资源,优化整体性能。
扩展阅读
为了更深入地了解如何合理设置PostgreSQL的max_connections参数,以及如何优化数据库性能,你可以参考以下资源:
- Managing Kernel Resources: 这部分文档讨论了如何配置操作系统以支持较大的
max_connections值。 - Resource Consumption: 本章节介绍了PostgreSQL资源使用的相关参数,包括
max_connections、work_mem、shared_buffers等。 - PgBouncer: 了解如何通过PgBouncer优化PostgreSQL连接管理。
相关文章:

如何合理设置PostgreSQL的`max_connections`参数
合理设置PostgreSQL的max_connections参数对于数据库的稳定性和性能至关重要。这个设置值决定了允许同时连接到数据库的最大客户端数量。如果设置不当,可能导致资源浪费或系统过载。以下是设置max_connections时需要考虑的几个关键因素: 1. 评估系统硬件…...

Kubectl 常用命令汇总大全
kubectl 是 Kubernetes 自带的客户端,可以用它来直接操作 Kubernetes 集群。 从用户角度来说,kubectl 就是控制 Kubernetes 的驾驶舱,它允许你执行所有可能的 Kubernetes 操作;从技术角度来看,kubectl 就是 Kubernetes…...

【Linux】Linux环境基础开发工具使用之Linux调试器-gdb使用
目录 一、程序发布模式1.1 debug模式1.2 release模式 二、默认发布模式三、gdb的使用结尾 一、程序发布模式 程序的发布方式有两种,debug模式和release模式 1.1 debug模式 目的:主要用于开发和测试阶段,目的是让开发者能够更容易地调试和跟…...

clickhouse_driver
一、简介 clickhouse_driver是一个Python库,用于与ClickHouse数据库进行交互。ClickHouse是一个高性能的列式数据库管理系统(DBMS),它适用于实时分析(OLAP)场景。clickhouse_driver模块提供了与ClickHouse…...
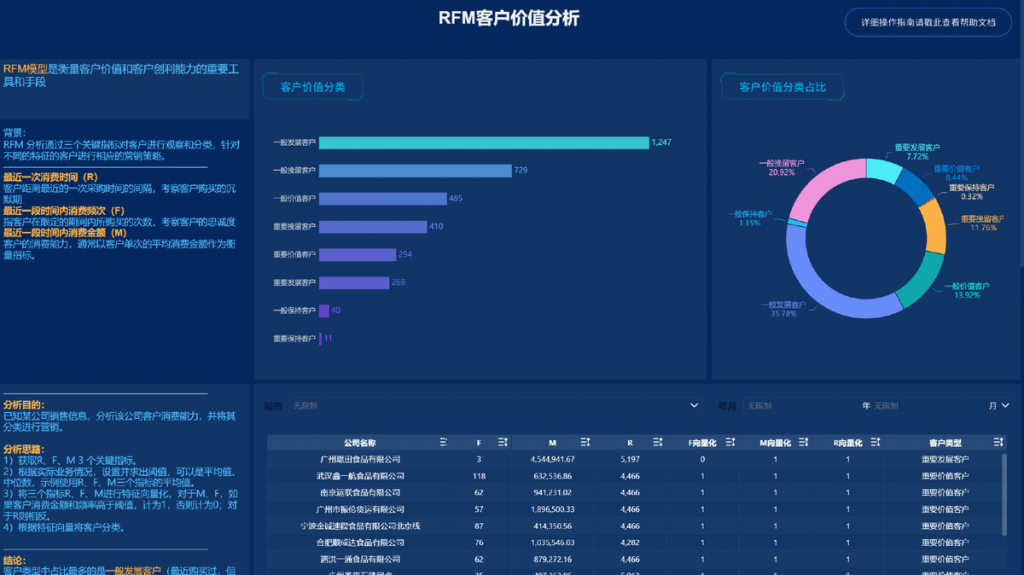
BI分析实操案例分享:零售企业如何利用BI工具对销售数据进行分析?
在当下这个竞争激烈的零售市场,企业如何在波诡云谲的商场中站稳脚跟,实现销售目标的翻倍增长? 答案可能就藏在那些看似杂乱无章的数字里。 是的,你没有看错,答案正是那些我们日常接触的销售数据。它们就像是宝藏&…...

python : Requests请求库入门使用指南 + 简单爬取豆瓣影评
Requests 是一个用于发送 HTTP 请求的简单易用的 Python 库。它能够处理多种 HTTP 请求方法,如 GET、POST、PUT、DELETE 等,并简化了 HTTP 请求流程。对于想要进行网络爬虫或 API 调用的开发者来说,Requests 是一个非常有用的工具。在今天的博…...

宋红康JVM调优思维导图
文章目录 1. 概述2. JVM监控及诊断命令-命令行篇3. JVM监控及诊断工具-GUI篇4. JVM运行时参数5. 分析GC日志 课程地址 1. 概述 2. JVM监控及诊断命令-命令行篇 3. JVM监控及诊断工具-GUI篇 4. JVM运行时参数 5. 分析GC日志...

linux 网卡配置
linux网卡可以通过命令和配置文件配置,如果是桌面环境还可以通过图形化界面配置. 1.ifconfig(interfaces config)命令方式 通常需要以root身份登录或使用sudo以便在Linux机器上使用ifconfig工具。依赖于ifconfig命令中使用一些选项属性,ifconfig工具不仅可以被用来…...

IEEE |第五届机器学习与计算机应用国际学术会议(ICMLCA 2024)
第五届机器学习与计算机应用国际学术会议(ICMLCA 2024)定于2024年10月18-20日在中国杭州隆重举行。本届会议将主要关注机器学习和计算机应用面临的新的挑战问题和研究方向,着力反映国际机器学习和计算机应用相关技术研究的最新进展。 IEEE |第五届机器学习与计算机应…...

【网络安全】漏洞挖掘:IDOR实例
未经许可,不得转载。 文章目录 正文 正文 某提交系统,可以选择打印或下载passport。 点击Documents > Download后,应用程序将执行 HTTP GET 请求: /production/api/v1/attachment?id4550381&enamemId123888id为文件id&am…...

vue项目执行 cnpm install 报错证书过期的解决方案
拉下源码后执行依赖安装过程,报错 error Error: Certificate has expired,可以通过一下方发解决:npm config set strict-ssl false 再执行 cnpm 命令即可正常拉依赖...

XGboost的安装与使用
安装xgboost: conda install py-xgboost下载demo的数据: https://github.com/dmlc/xgboost 安装graphviz conda install python-graphviz数据 在demo/data里面: 训练集是:agaricus.txt.train、测试集是:agaricus…...

【AI趋势9】开源普惠
关于开源的问题,可以参考我之前的文章: 再说开源软件-CSDN博客 【AI】马斯克说大模型要开源,我们缺的是源代码?(附一图看懂6大开源协议)_分开源和闭源,我们要的当然是开源,马斯克开源。-CSDN博客 一、开…...

【Spark集群部署系列一】Spark local模式介绍和搭建以及使用(内含Linux安装Anaconda)
简介 注意: 在部署spark集群前,请部署好Hadoop集群,jdk8【当然Hadoop集群需要运行在jdk上】,需要注意hadoop,spark的版本,考虑兼容问题。比如hadoop3.0以上的才兼容spark3.0以上的。 下面是Hadoop集群部署…...

泛微OA 常用数据库表
HrmDepartment 人力资源部门 HrmSubCompany 人力资源分部 HrmResource 员工信息表 HrmRoles 角色信息表 T_Condition 报表条件 T_ConditionDetail 报表条件详细值 T_DatacenterUser 基层用户信息 T_FadeBespeak 调查退订表 T_fieldItem 调查项目表输入项信息 T_fieldItemDetail…...
宜佰丰超市进销存管理系统
你好呀,我是计算机学姐码农小野!如果有相关需求,可以私信联系我。 开发语言: Java 数据库: MySQL 技术: JavaMysql 工具: IDEA/Eclipse、Navicat、Maven 系统展示 首页 管理员功能模块…...

生成Vue脚手架报错:npm error code ETIMEDOUT
遇到 ETIMEDOUT 错误通常表示你的 npm 请求在尝试连接到 npm 仓库(如 https://registry.npmjs.org)时超时了。这个问题通常与网络连接、代理设置或网络配置有关。以下是一些解决这个问题的步骤: 检查网络连接: 确保你的设备可以正…...

Readiness Probe可以解决应用启动慢造成访问异常的问题。
Readiness Probe可以解决应用启动慢造成访问异常的问题。 正确 错误 这句话是正确的。 Readiness Probe确实可以解决应用启动慢造成的访问异常问题。 Readiness Probe,也称为就绪性探针,是Kubernetes中用于监控容器应用状态稳定性的重要机制之一。…...

第一批AI原住民开始变现:9岁小学生,用大模型写书赚1个w
前言 当人们正在观望,AI什么时候抢走自己的饭碗时,北京一名9岁的小学生在AI的帮助下写了一本小说,并赚到了2万元的版税。 这件看似不可思议的事,他是如何做到的?此外,他还带来一个启发:面对AI时…...

电路笔记(PCB):串扰的原理与减少串扰的几种方法
串扰 串扰(Crosstalk)是指在电路中,一条信号线上的电磁干扰不经意间耦合到另一条相邻的信号线上,从而影响其正常信号传输的现象。串扰会导致相邻信号线上的信号出现畸变或噪声,从而影响信号的完整性和电路的正常工作。…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...
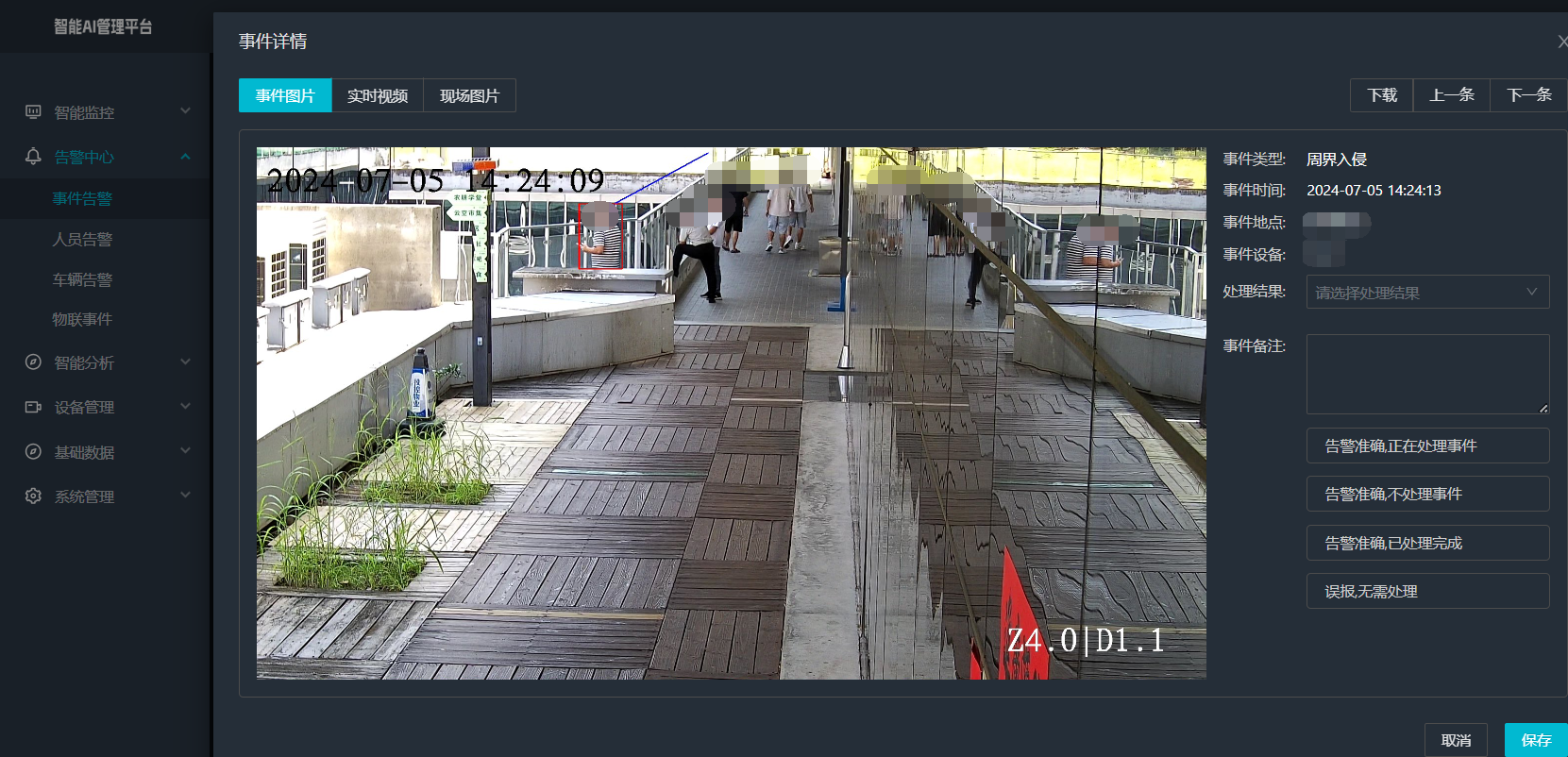
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...