多目标跟踪之ByteTrack论文(翻译+精读)
ByteTrack:通过关联每个检测框进行多对象跟踪
摘要
翻译
多对象跟踪(MOT)旨在估计视频中对象的边界框和身份。大多数方法通过关联分数高于阈值的检测框来获取身份。检测分数低的物体,例如被遮挡的物体被简单地丢弃,这带来了不可忽略的真实物体丢失和碎片轨迹。为了解决这个问题,我们提出了一种简单、有效和通用的关联方法,通过关联几乎每个检测框而不是仅关联高分检测框来进行跟踪。对于低分检测框,我们利用它们与轨迹的相似性来恢复真实对象并过滤掉背景检测。当应用于 9 个不同的最先进的跟踪器时,我们的方法在 IDF1 分数上实现了从 1 到 10 分的持续改进。为了发挥 MOT 的最先进性能,我们设计了一个简单而强大的跟踪器,名为 ByteTrack。我们首次在单 V100 GPU 上以 30 FPS 的运行速度在 MOT17 测试集上实现了 80.3 MOTA、77.3 IDF1 和 63.1 HOTA。 ByteTrack 还在 MOT20、HiEve 和 BDD100K 跟踪基准测试中实现了最先进的性能。源代码、带有部署版本的预训练模型以及应用于其他跟踪器的教程已在 https://github.com/ifzhang/ByteTrack 发布。

图 1. MOT17 测试集上不同跟踪器的 MOTA-IDF1-FPS 比较。横轴为FPS(运行速度),纵轴为MOTA,圆的半径为IDF1。我们的 ByteTrack 在 MOT17 测试集上以 30 FPS 的运行速度实现了 80.3 MOTA、77.3 IDF1,优于之前所有的跟踪器。详细信息如表 4 所示。
精读
**现有问题:**检测分数低的物体(如被遮挡)被简单丢弃,带来了物体丢失和碎片化的轨迹。
**我们的方法:**通过关联几乎每个检测框而不是仅关联高分检测框来进行跟踪。对于低分检测框,我们利用它们与轨迹的相似性来恢复真实对象并过滤掉检测到的背景。
**效果:**很好
1.引言
翻译
检测跟踪是当前多目标跟踪(MOT)最有效的范例。由于视频中的场景复杂,检测器很容易做出不完美的预测。最先进的 MOT 方法 [1–3, 6, 12, 18, 45, 59, 70, 72, 85] 需要处理检测框中的真阳性和假阳性权衡,以消除低置信度检测框[4, 40]。然而,这是消除所有低置信度检测框的正确方法吗?我们的答案是否定的:正如黑格尔所说,“合理的才是真实的;合理的才是真实的;合理的才是真实的”。真实的就是合理的。”低置信度检测框有时表明物体的存在,例如被遮挡的物体。过滤掉这些物体会给 MOT 带来不可逆的错误,并带来不可忽略的缺失检测和碎片化轨迹。
图 2 (a) 和 (b) 显示了这个问题。在帧 t1 中,我们初始化了三个不同的 tracklet,因为它们的分数都高于 0.5。然而,在t2帧和t3帧中,当发生遮挡时,红色轨迹的相应检测分数变低,即0.8到0.4,然后0.4到0.1。这些检测框被阈值机制消除,红色轨迹相应消失。然而,如果我们考虑每个检测框,就会立即引入更多误报,例如图 2 (a) 的帧 t3 中最右边的框。据我们所知,MOT 中很少有方法 [30, 63] 能够处理这种检测困境。

图 2.我们的方法示例,它将每个检测框关联起来。 (a) 显示了所有检测框及其分数。 (b) 显示了通过以前的方法获得的轨迹,该轨迹将分数高于阈值(即 0.5)的检测框关联起来。相同的盒子颜色代表相同的身份。 © 显示了通过我们的方法获得的轨迹。虚线框表示使用卡尔曼滤波器先前轨迹的预测框。两个低分检测框基于大 IoU 与之前的轨迹正确匹配。
精读
**观点:**现有的消除低置信度检测的方法不合理!
**原因:**低置信度检测框有时表明被遮挡的物体。过滤掉这些物体会给 MOT 带来不可逆的错误,并带来不可忽略的缺失检测和碎片化轨迹。
**我们提出的方法:**如图2的c所示,可以将被遮挡的物体也检测出来,并关联轨迹成功。
翻译
在本文中,我们发现与轨迹的相似性为区分低分检测框中的对象和背景提供了强有力的线索。如图2(c)所示,两个低分检测框通过运动模型的预测框与轨迹进行匹配,从而正确地恢复了对象。同时,背景框被删除,因为它没有匹配的轨迹。
为了在匹配过程中充分利用从高分到低分的检测框,我们提出了一种简单有效的关联方法 BYTE,命名为每个检测框是 tracklet 的基本单位,就像计算机程序中的字节一样,我们的跟踪方法重视每个详细的检测框。我们首先根据运动相似性或外观相似性将高分检测框与轨迹进行匹配。与[6]类似,我们采用卡尔曼滤波器[29]来预测新帧中轨迹的位置。相似度可以通过预测框和检测框的 IoU 或 Re-ID 特征距离来计算。图2(b)正是第一次匹配后的结果。然后,我们使用相同的运动相似度在未匹配的轨迹(即红色框中的轨迹)和低分检测框之间执行第二次匹配。图2©显示了第二次匹配后的结果。检测分数较低的被遮挡人与之前的轨迹正确匹配,并且背景(在图像的右侧部分)被移除。
作为目标检测和关联的集成主题,MOT 的理想解决方案绝不是检测器和以下关联;此外,其连接区域的精心设计也很重要。 BYTE的创新之处在于检测和关联的结合领域,其中低分检测框是促进两者的桥梁。受益于这种集成创新,当 BYTE 应用于 9 种不同的最先进的跟踪器时,包括基于 Re-ID 的跟踪器 [33,47,69,85]、基于运动的跟踪器 [71, 89]、链式跟踪器基于 [48] 和基于注意力的 [59, 80],几乎所有指标都取得了显着的改进,包括 MOTA、IDF1 分数和 ID 开关。例如,我们将 CenterTrack [89] 的 MOTA 从 66.1 增加到 67.4,IDF1 从 64.2 增加到 74.0,并将 MOT17 的半验证集上的 ID 从 528 减少到 144。
为了推动 MOT 的最先进性能,我们提出了一个简单而强大的跟踪器,名为 ByteTrack。我们采用最新的高性能检测器 YOLOX [24] 来获取检测框并将它们与我们提出的 BYTE 相关联。在 MOT 挑战上,ByteTrack 在 MOT17 [44] 和 MOT20 [17] 上均排名第一,在 MOT17 上的 V100 GPU 上以 30 FPS 的运行速度实现了 80.3 MOTA、77.3 IDF1 和 63.1 HOTA,在很多情况下达到了 77.8 MOTA、75.2 IDF1 和 61.3 HOTA。 MOT20 更拥挤。 ByteTrack 还在 HiEve [37] 和 BDD100K [79] 跟踪基准上实现了最先进的性能。我们希望 ByteTrack 的效率和简单性能够使其在社交计算等实际应用中具有吸引力。
精读
**我们的方法:**将“与轨迹的相似性”作为关联的区分标准之一。
BYTE:
- 我们首先根据运动相似性或外观相似性将高分检测框与轨迹进行匹配。
- 采用卡尔曼滤波器预测新帧中的轨迹位置。
- 第一次匹配:相似度关联通过预测框和检测框的 IoU 或 Re-ID 特征距离来计算。
- 第二次匹配:使用相同的运动相似度在未匹配的轨迹(即红色框中的轨迹)和低分检测框之间执行第二次匹配
**BYTE的优势:**BYTE的这个简单的将低分检测框作为关键桥梁的创新使得别的跟踪器也有了很好的长进。
**检测模型:**YOLOX
ByteTrack:效果最先进。
2.相关工作
2.1 MOT中的目标检测
翻译
目标检测是计算机视觉中最活跃的主题之一,是多目标跟踪的基础。 MOT17数据集[44]提供了DPM[22]、Faster R-CNN[50]和SDP[77]等流行检测器获得的检测结果。大量方法[3,9,12,14,28,74,91]专注于基于这些给定的检测结果来提高跟踪性能。
**通过检测进行跟踪。**随着目标检测的快速发展[10,23,26,35,49,50,58,60],越来越多的方法开始利用更强大的检测器来获得更高的跟踪性能。一级目标检测器 RetinaNet [35] 开始被 [39, 48] 等多种方法采用。 CenterNet [90] 因其简单性和高效性而成为大多数方法 [63、65、67、71、85、87、89] 采用的最流行的检测器。 YOLO系列检测器[8, 49]也因其精度和速度的出色平衡而被大量方法[15,33,34,69]采用。这些方法大多数直接使用单个图像上的检测框进行跟踪。
然而,正如视频对象检测方法[41, 62]所指出的那样,当视频序列中发生遮挡或运动模糊时,丢失检测和得分非常低的检测的数量开始增加。因此,通常利用前一帧的信息来增强视频检测性能。
**通过跟踪检测。**还可以采用跟踪来帮助获得更准确的检测框。一些方法[12-15,53,91]利用单目标跟踪(SOT)[5]或卡尔曼滤波器[29]来预测下一帧中轨迹的位置,并将预测框与检测框融合以增强检测结果。其他方法 [34, 86] 利用前一帧中的跟踪框来增强下一帧的特征表示。最近,基于 Transformer 的 [20, 38, 64, 66] 检测器 [11, 92] 因其在帧之间传播框的强大能力而被多种方法 [42, 59, 80] 采用。我们的方法还利用与轨迹的相似性来增强检测框的可靠性。
在通过各种检测器获得检测框后,大多数MOT方法[33,39,47,59,69,71,85]仅将高分检测框保留一个阈值,即0.5,并将这些框用作数据的输入。这是因为低分检测框包含许多背景,这会损害跟踪性能。然而,我们观察到许多被遮挡的物体可以被正确检测到,但得分较低。为了减少丢失检测并保持轨迹的持久性,我们保留所有检测框并在每个检测框之间进行关联。
精读
MOT中的目标检测相关研究:
- 通过检测进行跟踪:
- 例子:RetinaNet、YOLO系列
- 可改进的方向:利用前一帧的信息来增强视频这一帧的检测性能。
- 通过跟踪检测:
- 利用前一帧的来增强下一帧的:利用单目标跟踪(SOT)[5]或卡尔曼滤波器[29]来预测下一帧中轨迹的位置,并将预测框与检测框融合以增强检测结果。
- 基于 Transformer 的 [20, 38, 64, 66] 检测器 [11, 92] 因其在帧之间传播框的强大能力而被多种方法 [42, 59, 80] 采用。
- 我们的方法:
- 我们观察到:许多被遮挡的物体可以被正确检测到,但得分较低。
- 我们的方法原理:为了减少丢失检测并保持轨迹的持久性,我们保留所有检测框并在每个检测框之间进行关联。
2.2 数据关联
翻译
数据关联是多目标跟踪的核心,它首先计算轨迹和检测框之间的相似度,并根据相似度利用不同的策略来匹配它们。
**相似性度量。**位置、动作和外观是关联的有用线索。 SORT [6] 以一种非常简单的方式结合了位置和运动提示。它首先采用卡尔曼滤波器[29]来预测新帧中轨迹的位置,然后计算检测框和预测框之间的 IoU 作为相似度。最近的一些方法[59,71,89]设计网络来学习对象运动并在相机运动较大或帧速率较低的情况下获得更稳健的结果。短距离匹配中位置和运动相似度准确。外观相似度有助于远距离匹配。物体被遮挡很长一段时间后,可以利用外观相似度重新识别物体。外观相似度可以通过Re-ID特征的余弦相似度来衡量。 DeepSORT [70]采用独立的Re-ID模型从检测框中提取外观特征。最近,联合检测和 Re-ID 模型[33,39,47,69,84,85]由于其简单性和效率而变得越来越流行。
**匹配策略。**相似度计算后,匹配策略为对象分配身份。这可以通过匈牙利算法[31]或贪婪赋值[89]来完成。 SORT [6] 通过一次匹配将检测框与轨迹进行匹配。 DeepSORT [70]提出了一种级联匹配策略,该策略首先将检测框与最近的轨迹进行匹配,然后与丢失的轨迹进行匹配。 MOTDT [12]首先利用外观相似度进行匹配,然后利用 IoU 相似度来匹配未匹配的轨迹。 QDTrack[47]通过双向softmax运算将外观相似度转化为概率,并采用最近邻搜索来完成匹配。注意机制[64]可以直接在帧之间传播框并隐式地执行关联。最近的方法(例如[42, 80])提出了跟踪查询来查找后续帧中被跟踪对象的位置。匹配是在注意力交互过程中隐式执行的,不使用匈牙利算法。
所有这些方法都集中在如何设计更好的关联方法。然而,我们认为检测框的使用方式决定了数据关联的上限,我们关注的是如何在匹配过程中从高分到低分充分利用检测框。
精读
数据关联相关研究:
- 相似度关联:
- SORT采用卡尔曼滤波器来预测新帧中轨迹的位置,然后计算检测框和预测框之间的 IoU 作为相似度判断。
- DeepSORT 采用独立的Re-ID模型从检测框中提取外观特征,融合外观和运动进行相似度判断。
- 匹配策略(匹配可以通过匈牙利算法[31]或贪婪赋值[89]来完成):
- SORT [6] 通过一次匹配将检测框与轨迹进行匹配。
- DeepSORT [70]提出了一种级联匹配策略,该策略首先将检测框与最近的轨迹进行匹配,然后与丢失的轨迹进行匹配。
- MOTDT [12]首先利用外观相似度进行匹配,然后利用 IoU 相似度来匹配未匹配的轨迹。
- QDTrack[47]通过双向softmax运算将外观相似度转化为概率,并采用最近邻搜索来完成匹配。
- …
- 我们的研究:
- 我们认为:检测框的使用方式决定了数据关联的上限
- 我们关注:如何在匹配过程中从高分到低分充分利用检测框
3.BYTE
翻译
我们提出了一种简单、有效且通用的数据关联方法,BYTE。与之前的仅保留高分检测框的方法[33,47,69,85]不同,我们保留了几乎每个检测框并将它们分为高分检测框和低分检测框。我们首先将高分检测框与轨迹相关联。一些轨迹无法匹配,因为它们与适当的高分检测框不匹配,这通常在发生遮挡、运动模糊或大小变化时发生。然后,我们将低分检测框和这些不匹配的轨迹关联起来,以恢复低分检测框中的对象并同时过滤掉背景。 BYTE的伪代码如算法1所示。

BYTE 的输入是视频序列 V,以及对象检测器 Det。我们还设置了一个检测分数阈值 τ 。 BYTE 的输出是视频的轨迹 T,每个轨道包含每个帧中对象的边界框和标识。
对于视频中的每一帧,我们使用检测器 Det 预测检测框和分数。我们根据检测分数阈值 τ 将所有检测框分为两部分 Dhigh 和 Dlow 。对于得分高于τ的检测框,我们将它们放入高分检测框Dhigh中。对于分数低于 τ 的检测框,我们将它们放入低分检测框 Dlow(算法 1 中的第 3 至 13 行)。
在分离低分检测框和高分检测框后,我们采用卡尔曼滤波器来预测 T 中每个轨道的当前帧中的新位置(算法 1 中的第 14 到 16 行)。
在高分检测框Dhigh和所有轨道T(包括丢失轨道Tlost)之间执行第一次关联。相似度#1 可以通过检测框 Dhigh 和轨道 T 的预测框之间的 IoU 或 Re-ID 特征距离来计算。然后,我们采用匈牙利算法[31]来完成基于相似度的匹配。我们将不匹配的检测保留在 Dremain 中,将不匹配的轨迹保留在 Tremain 中(算法 1 中的第 17 到 19 行)。
BYTE具有高度的灵活性,可以兼容其他不同的关联方式。例如,当BYTE与FairMOT[85]结合时,算法1中的第一个关联中添加了Re-ID特征,其他相同。在实验中,我们将 BYTE 应用于 9 个不同的最先进的跟踪器,并在几乎所有指标上都取得了显着的改进。
在第一次关联之后,在低分检测框Dlow和剩余轨迹Tremain之间执行第二次关联。我们将不匹配的轨迹保留在 Tre−remain 中,并删除所有不匹配的低分检测框,因为我们将它们视为背景。 (算法 1 中的第 20 至 21 行)。我们发现在第二个关联中单独使用 IoU 作为相似度#2 很重要,因为低分检测框通常包含严重的遮挡或运动模糊,并且外观特征不可靠。因此,当将 BYTE 应用于其他基于 Re-ID 的跟踪器 [47,69,85] 时,我们在第二个关联中不采用外观相似性。
关联后,不匹配的轨迹将从轨迹中删除。为了简单起见,我们没有在算法1中列出轨道重生[12,70,89]的过程。实际上,远程关联有必要保留曲目的身份。对于第二次关联后仍保留的不匹配的轨迹Tre,我们将它们放入Tlost 中。对于 Tlost 中的每个轨道,只有当它存在超过一定数量的帧(即 30)时,我们才将其从轨道 T 中删除。否则,我们将丢失的轨迹 Tlost 保留在 T 中(算法 1 中的第 22 行)。最后,我们在第一次关联后从不匹配的高分检测框 Dremain 中初始化新轨迹。 (算法 1 中的第 23 至 27 行)。每个单独帧的输出是当前帧中轨道 T 的边界框和标识。请注意,我们不输出 Tlost 的框和身份。
为了展现 MOT 的最先进性能,我们通过为高性能检测器 YOLOX [24] 配备我们的关联方法 BYTE,设计了一个简单而强大的跟踪器,名为 ByteTrack。
精读
BYTE方法具体内容:
- 将检测到的检测框分为高分检测框和低分检测框,分别处理。
- 预测:对现有轨迹进行卡尔曼滤波
- 第一次关联:高分检测框和卡尔曼滤波预测T得到的所有框进行关联(IoU 或 Re-ID 特征距离),得到未匹配的高分检测(Dremain)和未匹配的轨迹(Tremain)
- 第二次关联:低分检测框和卡尔曼滤波预测Tremain得到的框进行关联(单独使用 IoU)(原因:因为低分检测框通常包含严重的遮挡或运动模糊,并且外观特征不可靠。),得到未匹配的低分检测(删除)和二次未匹配成功的轨迹(Tre-remain)
- 结束:将Tre-remain存到Tlost中(Tlost不会被输出作为轨迹,但下帧的匹配会用Tlost),用Dremain进行轨迹初始化。
**ByteTrack跟踪器:**应用YOLOX作为检测器,用BYTE作为关联方法的跟踪器。
总体感觉是在DeepSORT上进行的改进。
4.实验
4.1实验设置
翻译
**数据集。**我们在“私有检测”协议下在 MOT17 [44] 和 MOT20 [17] 数据集上评估 BYTE 和 ByteTrack。两个数据集都包含训练集和测试集,没有验证集。对于消融研究,我们使用 MOT17 训练集中每个视频的前半部分进行训练,后半部分进行验证[89]。我们结合 CrowdHuman 数据集 [55] 和 MOT17 半训练集 [59,71,80,89] 进行训练。当在 MOT17 的测试集上进行测试时,我们添加了 Cityperson [82] 和 ETHZ [21] 来按照 [33,69,85] 进行训练。我们还在 HiEve [37] 和 BDD100K [79] 数据集上测试 ByteTrack。 HiEve 是一个以人为中心的大规模数据集,专注于拥挤和复杂的事件。 BDD100K 是最大的驾驶视频数据集,MOT 任务的数据集分割为 1400 个用于训练的视频、200 个用于验证的视频和 400 个用于测试的视频。它需要跟踪 8 类物体,并包含大相机运动的情况。
**指标。**我们使用CLEAR指标[4],包括MOTA、FP、FN、ID等、IDF1[51]和HOTA[40]来评估跟踪性能的不同方面。 MOTA 是根据 FP、FN 和 ID 计算的。考虑到FP和FN的数量比ID大,MOTA更关注检测性能。 IDF1评估身份保存能力,更关注关联性能。 HOTA 是最近提出的一个指标,它明确平衡了执行准确检测、关联和定位的效果。对于BDD100K数据集,有一些多类指标,例如mMOTA和mIDF1。 mMOTA / mIDF1 是通过平均所有类别的 MOTA / IDF1 来计算的。
**实施细节。**对于 BYTE,除非另有说明,默认检测分数阈值 τ 为 0.6。对于MOT17、MOT20和HiEve的基准评估,我们仅使用IoU作为相似性度量。在线性分配步骤中,如果检测框和轨迹框之间的 IoU 小于 0.2,则匹配将被拒绝。对于丢失的轨迹,我们将其保留 30 帧,以防它再次出现。对于 BDD100K,我们使用 UniTrack [68] 作为 Re-ID 模型。在消融研究中,我们使用 FastReID [27] 来提取 MOT17 的 Re-ID 特征。
对于 ByteTrack,检测器是 YOLOX [24],以 YOLOX-X 作为主干,COCO 预训练模型 [36] 作为初始化权重。对于 MOT17,训练计划是 MOT17、CrowdHuman、Cityperson 和 ETHZ 组合的 80 个 epoch。对于 MOT20 和 HiEve,我们仅添加 CrowdHuman 作为附加训练数据。对于 BDD100K,我们不使用额外的训练数据,仅训练 50 个 epoch。多尺度训练时输入图像尺寸为1440×800,最短边范围为576到1024。数据增强包括Mosaic [8]和Mixup [81]。该模型在 8 个 NVIDIA Tesla V100 GPU 上进行训练,批量大小为 48。优化器为 SGD,权重衰减为 5 × 10−4,动量为 0.9。初始学习率为 10−3,具有 1 轮预热和余弦退火计划。总训练时间约为12小时。按照 [24],FPS 是在单个 GPU 上使用 FP16 精度 [43] 和批量大小 1 进行测量的。
精读
数据集:
- MOT17 & MOT20:包含训练集和测试集,无验证集。使用MOT17训练集的前半部分进行训练,后半部分进行验证。
- CrowdHuman:作为附加训练数据,增加对拥挤场景的适应性。
- Cityperson & ETHZ:用于MOT17测试集训练时增加数据多样性。
- HiEve:以人为中心的大规模数据集,专注于拥挤和复杂事件。
- BDD100K:最大的驾驶视频数据集,包含大相机运动情况,需跟踪8类物体。
评估指标:
- CLEAR指标:包括MOTA(关注检测性能)、FP(误检)、FN(漏检)、ID(身份切换次数)。
- IDF1:评估身份保存能力,更关注关联性能。
- HOTA:平衡检测、关联和定位效果的指标。
- 多类指标(如mMOTA、mIDF1):针对BDD100K数据集,计算所有类别的平均MOTA和IDF1。
实施细节:
- BYTE:
- 检测分数阈值τ默认为0.6。
- 使用IoU作为相似性度量,IoU小于0.2的匹配被拒绝。
- 丢失轨迹保留30帧。
- 在MOT17消融研究中,使用FastReID提取Re-ID特征。
- ByteTrack:
- 检测器为YOLOX,以YOLOX-X为主干,使用COCO预训练模型初始化。
- 训练数据组合和训练周期根据数据集不同有所变化。
- 多尺度训练,输入图像尺寸及数据增强方法(Mosaic、Mixup)。
- 使用8个NVIDIA Tesla V100 GPU训练,批量大小为48。
- 优化器为SGD,带有余弦退火计划的学习率调整。
- 训练时间约12小时,FPS测量在单个GPU上进行。
4.2 BYTE 消融研究
翻译
相似性分析。我们为BYTE的第一关联和第二关联选择不同类型的相似性。结果如表1所示。我们可以看到,IoU或Re-ID对于MOT17上的Similarity#1来说都是不错的选择。 IoU 实现了更好的 MOTA 和 ID,而 Re-ID 实现了更高的 IDF1。在 BDD100K 上,Re-ID 在第一次关联中取得了比 IoU 更好的结果。这是因为BDD100K包含较大的相机运动并且注释处于低帧率,这导致运动提示失败。在两个数据集的第二个关联中使用 IoU 作为相似性#2 非常重要,因为低分检测框通常包含严重的遮挡或运动模糊,因此 Re-ID 特征不可靠。从表1中我们可以发现,使用IoU作为Similarity#2与Re-ID相比增加了约1.0 MOTA,这表明低分检测框的Re-ID特征并不可靠。
**与其他关联方法的比较。**我们在 MOT17 和 BDD100K 的验证集上将 BYTE 与其他流行的关联方法(包括 SORT [6]、DeepSORT [70] 和 MOTDT [12])进行比较。结果如表2所示。
SORT 可以看作是我们的基线方法,因为这两种方法都只采用卡尔曼滤波器来预测物体运动。我们可以发现,BYTE 将 SORT 的 MOTA 指标从 74.6 提高到 76.6,将 IDF1 从 76.9 提高到 79.3,并将 ID 从 291 减少到 159。这凸显了低分检测框的重要性,并证明了 BYTE 从低分检测框恢复目标框的能力。低分一。
DeepSORT 利用额外的 Re-ID 模型来增强远程关联。我们惊讶地发现,与 DeepSORT 相比,BYTE 还具有额外的增益。这表明,当检测框足够准确时,简单的卡尔曼滤波器可以执行远程关联并实现更好的 IDF1 和 ID。我们注意到,在严重遮挡的情况下,Re-ID 功能很脆弱,可能会导致身份切换,相反,运动模型表现得更可靠。
MOTDT 将运动引导框传播结果与检测结果集成在一起,将不可靠的检测结果与轨迹关联起来。尽管动机相似,但 MOTDT 远远落后于 BYTE。我们解释说,MODTT 使用传播框作为轨迹框,这可能会导致跟踪中的定位漂移。相反,BYTE 使用低分检测框来重新关联那些不匹配的轨迹,因此轨迹框更准确。
**检测分数阈值的鲁棒性。**检测分数阈值τhigh是一个敏感的超参数,在多目标跟踪任务中需要仔细调整。我们将其从 0.2 更改为 0.8,并比较 BYTE 和 SORT 的 MOTA 和 IDF1 分数。结果如图3所示。从结果我们可以看出,BYTE对于检测分数阈值比SORT更加稳健。这是因为 BYTE 中的第二个关联恢复了分数低于 τhigh 的对象,因此无论 τhigh 的变化如何,都会考虑几乎每个检测框。
**低分检测框分析。**为了证明BYTE的有效性,我们收集了BYTE获得的低分框中的TP和FP的数量。我们使用 MOT17 的半训练集和 CrowdHuman 在 MOT17 的半验证集上进行训练和评估。首先,我们保留所有得分范围从 τlow 到 τhigh 的低分检测框,并使用地面实况注释对 TP 和 FP 进行分类。然后,我们从低分检测框中选择BYTE获得的跟踪结果。每个序列的结果如图 4 所示。我们可以看到,尽管某些序列(即 MOT17-02)在所有检测框中具有更多的 FP,但 BYTE 从低分检测框中获得的 TP 明显多于 FP。所获得的 TP 显着地将 MOTA 从 74.6 增加到 76.6,如表 2 所示。
**其他跟踪器上的应用程序。**我们将 BYTE 应用于 9 种不同的最先进的跟踪器,包括 JDE [69]、CSTrack [33]、FairMOT [85]、TraDes [71]、QDTrack [47]、CenterTrack [89]、Chained-Tracker [ 48]、TransTrack [59] 和 MOTR [80]。在这些跟踪器中,JDE、CSTrack、FairMOT、TraDes 采用了运动和 ReID 相似性的组合。 QDTrack单独采用Re-ID相似度。 CenterTrack 和 TraDes 通过学习网络预测运动相似度。 Chained-Tracker采用链式结构,同时输出两个连续帧的结果,并通过IoU关联在同一帧中。 TransTrack 和 MOTR 采用注意力机制在帧之间传播框。他们的结果显示在表3中每个跟踪器的第一行中。为了评估BYTE的有效性,我们设计了两种不同的模式将BYTE应用于这些跟踪器。
- 第一种模式是在不同跟踪器的原始关联方法中插入BYTE,如表3中每个跟踪器结果的第二行所示。以FairMOT[85]为例,原始关联完成后,我们选择所有不匹配的轨迹,并将它们与算法 1 中第二个关联之后的低分检测框关联起来。请注意,对于低分对象,Re-ID 特征不可靠,因此我们仅采用检测框之间的 IoU并将运动预测后的轨迹框作为相似度。我们没有将BYTE的第一种模式应用到Chained-Tracker中,因为我们发现它很难在链式结构中实现。
- 第二种模式是直接使用这些跟踪器的检测框并使用算法1中的整个过程进行关联,如表3中每个跟踪器结果的第三行所示。
我们可以看到,在两种模式下,BYTE 都能对包括 MOTA、IDF1 和 ID 在内的几乎所有指标带来稳定的改进。例如,BYTE将CenterTrack增加1.3 MOTA和9.8 IDF1,Chained-Tracker增加1.9 MOTA和5.8 IDF1,TransTrack增加1.2 MOTA和4.1 IDF1。表3的结果表明BYTE具有很强的泛化能力,可以很容易地应用于现有的跟踪器以获得性能增益。

表 1. BYTE 在 MOT17 和 BDD100K 验证集上的第一个关联和第二个关联中使用的不同类型相似性度量的比较。最佳结果以粗体显示。

表2. MOT17和BDD100K验证集上不同数据关联方法的比较。最佳结果以粗体显示。

图 3. BYTE 和 SORT 在不同检测分数阈值下的性能比较。结果来自MOT17的验证集。

图 4. 所有低分检测框的 TP 和 FP 数量以及 BYTE 获得的低分跟踪框的比较。结果来自MOT17的验证集。

表 3. 将 BYTE 应用于 MOT17 验证集上 9 个不同的最先进跟踪器的结果。 “K”是卡尔曼滤波器的缩写。绿色表示至少 +1.0 点的改进。
精读
相似性分析:
- Similarity#1(第一关联相似性):
- 对于MOT17数据集,IoU(交并比)和Re-ID(重识别)都是不错的选择,但IoU在MOTA和ID指标上表现更好,而Re-ID在IDF1上更高。
- 对于BDD100K数据集,由于相机运动大和注释帧率低,Re-ID在第一关联中表现优于IoU。
- Similarity#2(第二关联相似性):
- 在两个数据集的第二次关联中,使用IoU作为相似性非常重要,因为低分检测框通常包含遮挡或运动模糊,Re-ID特征不可靠。IoU作为Similarity#2相比Re-ID显著提高了MOTA分数。
与其他关联方法的比较:
- SORT:
- BYTE在MOTA、IDF1和ID指标上均优于SORT,证明了低分检测框的重要性以及BYTE恢复目标框的能力。
- DeepSORT:
- 尽管DeepSORT使用Re-ID模型增强远程关联,但BYTE在检测框准确时通过简单的卡尔曼滤波器实现了更好的IDF1和ID,说明在遮挡情况下Re-ID可能脆弱。
- MOTDT:
- MOTDT使用传播框可能导致定位漂移,而BYTE使用低分检测框重新关联不匹配轨迹,轨迹框更准确。
检测分数阈值的鲁棒性:
- BYTE对检测分数阈值(τ)的变化更加稳健,因为第二个关联机制会考虑几乎所有检测框,无论其分数如何。
低分检测框分析:
- 通过对低分检测框中TP(真正例)和FP(假正例)的分析,BYTE能够从低分检测框中恢复更多真正的目标,显著提升MOTA分数。
其他跟踪器上的应用:
-
BYTE被应用于9种不同的先进跟踪器,通过两种不同模式的应用,显著提升了这些跟踪器的性能,证明了BYTE的通用性和有效性。
-
第一种模式:
-
方法描述:在跟踪器完成其原始关联后,BYTE选择所有未匹配的轨迹,并将它们与通过算法1中“第二个关联”步骤处理后的低分检测框进行关联。此过程中,主要依赖检测框之间的IoU(交并比)以及运动预测后的轨迹框作为相似性度量,因为低分检测框的Re-ID(重识别)特征通常不可靠。
-
应用示例:以FairMOT为例,展示了如何在保持原跟踪器主要框架不变的情况下,通过BYTE增强未匹配轨迹的关联能力。
-
限制:该模式未应用于Chained-Tracker,因为其实现难度较高,难以在链式结构中有效集成。
-
-
第二种模式:
-
方法描述:直接使用跟踪器的检测框,并完全按照BYTE的算法1进行关联处理,包括两个关联步骤和相应的相似性度量。
-
优势:这种模式下,BYTE能够完全控制关联过程,从而最大化其性能增益。
-
应用效果:表3中的结果显示,几乎所有参与测试的跟踪器在采用这种模式后,MOTA、IDF1和ID等关键指标均得到了稳定的提升。
-
4.3 基准评估
翻译
我们分别在表 4、表 5 和表 6 中在私有检测协议下的 MOT17、MOT20 和 HiEve 测试集上将 ByteTrack 与最先进的跟踪器进行了比较。所有结果均直接从官方MOT Challenge评估服务器和Human in Events服务器获得。
MOT17。 ByteTrack 在 MOT17 排行榜上的所有追踪器中排名第一。它不仅达到了最好的精度(即80.3 MOTA、77.3 IDF1和63.1 HOTA),而且还以最高的运行速度(30 FPS)运行。它的性能大幅优于第二性能跟踪器[76](即+3.3 MOTA、+5.3 IDF1 和+3.4 HOTA)。此外,我们使用的训练数据比许多高性能方法要少,例如 [33,34,54,65,85](29K 图像与 73K 图像)。值得注意的是,与另外采用 Re-ID 相似度或注意力机制的其他方法[33,47,59,67,80,85]相比,我们在关联步骤中仅利用最简单的相似度计算方法卡尔曼滤波器。这些都表明ByteTrack是一个简单而强大的跟踪器。
**MOT20。**与MOT17相比,MOT20的拥挤场景和遮挡情况要多得多。在 MOT20 的测试集中,图像中的平均行人数量为 170。 ByteTrack 在 MOT20 排行榜上的所有跟踪器中排名第一,并且在几乎所有指标上都大幅领先其他跟踪器。例如,它将MOTA从68.6增加到77.8,IDF1从71.4增加到75.2,并将ID从4209减少到1223,减少71%。值得注意的是,ByteTrack实现了极低的身份切换,这进一步表明关联每个检测框是非常简单的。在遮挡情况下非常有效。
**Human in Events。**与MOT17和MOT20相比,HiEve包含更复杂的事件和更多样化的摄像机视图。我们在 CrowdHuman 数据集和 HiEve 的训练集上训练 ByteTrack。 ByteTrack 在 HiEve 排行榜上的所有追踪器中排名第一,并且大幅领先其他最先进的追踪器。例如,它将 MOTA 从 40.9 增加到 61.3,IDF1 从 45.1 增加到 62.9。优异的结果表明 ByteTrack 对复杂场景具有鲁棒性。
BDD100K。 BDD100K是自动驾驶场景中的多类别跟踪数据集。挑战包括低帧速率和大相机运动。我们利用 UniTrack [68] 中的简单 ResNet-50 ImageNet 分类模型来提取 Re-ID 特征并计算外观相似度。 ByteTrack在BDD100K排行榜上排名第一。验证集上的mMOTA从36.6提高到45.5,测试集上的mMOTA从35.5提高到40.1,这表明ByteTrack也可以应对自动驾驶场景中的挑战。

表 4. MOT17 测试集上“私人检测器”协议下最先进方法的比较。最佳结果以粗体显示。 MOT17包含丰富的场景,一半的序列是通过摄像机运动捕捉的。 ByteTrack 在 MOT17 排行榜上的所有跟踪器中排名第一,并且在几乎所有指标上都大幅领先第二名 ReMOT。它还具有所有追踪器中最高的运行速度。

表 5. MOT20 测试集上“私人检测器”协议下最先进方法的比较。最佳结果以粗体显示。 MOT20的场景比MOT17拥挤得多。 ByteTrack 在 MOT20 排行榜上的所有跟踪器中排名第一,并且在所有指标上都大幅领先第二名 SOTMOT。它还具有所有追踪器中最高的运行速度。

表 6. HiEve 测试集上“私人检测器”协议下最先进方法的比较。最佳结果以粗体显示。 HiEve 的事件比 MOT17 和 MOT20 更复杂。 ByteTrack 在 HiEve 排行榜上的所有跟踪器中排名第一,并且在所有指标上都大幅领先第二名 CenterTrack。
精读
ByteTrack 在多个权威的多目标跟踪(MOT)数据集上展示了其卓越的性能和鲁棒性,包括 MOT17、MOT20、HiEve 以及 BDD100K。
- MOT17:
- 在MOT17排行榜上,ByteTrack在所有追踪器中排名第一,实现了最高的精度(80.3 MOTA、77.3 IDF1、63.1 HOTA)和最高的运行速度(30 FPS)。
- 相比其他高性能方法,ByteTrack在精度上大幅提升,同时使用的训练数据量更少。
- 在关联步骤中,ByteTrack仅利用卡尔曼滤波器这一最简单的相似度计算方法,证明了其高效性和简洁性。
- MOT20:
- MOT20包含更多的拥挤场景和遮挡情况,ByteTrack在此数据集上同样排名第一,并在几乎所有指标上大幅领先其他跟踪器。
- ByteTrack在MOT20上实现了显著的MOTA(从68.6增加到77.8)和IDF1(从71.4增加到75.2)提升,并大幅减少了身份切换次数。
- Human in Events (HiEve):
- HiEve数据集包含更复杂的事件和更多样化的摄像机视图,ByteTrack在此数据集上也排名第一,并大幅领先其他最先进的追踪器。
- ByteTrack显著提高了MOTA(从40.9增加到61.3)和IDF1(从45.1增加到62.9),展示了其在复杂场景中的鲁棒性。
- BDD100K:
- BDD100K是自动驾驶场景中的多类别跟踪数据集,具有低帧速率和大相机运动的挑战。
- ByteTrack在BDD100K排行榜上同样排名第一,通过引入简单的ResNet-50 ImageNet分类模型来提取Re-ID特征,实现了mMOTA的显著提升(验证集从36.6提高到45.5,测试集从35.5提高到40.1)。
5.总结
翻译
我们提出了一种简单而有效的数据关联方法 BYTE 用于多目标跟踪。 BYTE 可以轻松应用于现有的跟踪器并实现一致的改进。我们还提出了一个强大的跟踪器ByteTrack,它在MOT17测试集上以30 FPS实现了80.3 MOTA、77.3 IDF1和63.1 HOTA,在排行榜上的所有跟踪器中排名第一。 ByteTrack 由于其准确的检测性能以及关联低分检测框的帮助而对遮挡非常稳健。它还揭示了如何充分利用检测结果来增强多目标跟踪。我们希望 ByteTrack 的高精度、快速性和简单性能够使其在实际应用中具有吸引力。
A.边界框注释
我们注意到 MOT17 [44] 需要覆盖整个身体的边界框 [89],即使对象被遮挡或部分位于图像之外。然而,YOLOX 的默认实现会剪辑图像区域内的检测框。为了避免图像边界周围的错误检测结果,我们在数据预处理和标签分配方面修改了YOLOX。在数据预处理和数据增强过程中,我们不会剪切图像内的边界框。我们只删除数据增强后完全位于图像之外的框。在SimOTA标签分配策略中,正样本需要位于物体中心周围,而全身框的中心可能位于图像之外,因此我们将物体的中心裁剪在图像内部。 MOT20 [17]、HiEve [37] 和 BDD100K 剪切图像内的边界框注释,因此我们只使用 YOLOX 的原始设置。
B. 光模型的跟踪性能
我们使用光检测模型比较 BYTE 和 DeepSORT [70]。我们使用具有不同主干网的 YOLOX [24] 作为我们的检测器。所有模型均在 CrowdHuman 和 MOT17 的半训练集上进行训练。多尺度训练时输入图像尺寸为1088×608,最短边范围为384到832。结果如表8所示。我们可以看到,与DeepSORT相比,BYTE在MOTA和IDF1上带来了稳定的改进,这表明BYTE对检测性能具有鲁棒性。值得注意的是,当使用YOLOX-Nano作为主干时,BYTE带来了比DeepSORT高3个点的MOTA,这使得它在实际应用中更具吸引力。
C. ByteTrack的消融研究
**速度与速度准确性。**我们在推理过程中使用不同大小的输入图像来评估 ByteTrack 的速度和准确性。所有实验都使用相同的多尺度训练。结果如表9所示。推理期间的输入大小范围为512×928至800×1440。检测器的运行时间范围为17.9 ms至30.0 ms,关联时间均在4.0 ms左右。 ByteTrack可以实现75.0 MOTA,45.7 FPS运行速度和76.6 MOTA,29.6 FPS运行速度,在实际应用中具有优势。
**训练数据。**我们使用不同的训练数据组合在 MOT17 的半验证集上评估 ByteTrack。结果如表10所示。当仅使用MOT17的一半训练集时,性能达到75.8 MOTA,这已经优于大多数方法。这是因为我们使用了强大的增强功能,例如 Mosaic [8] 和 Mixup [81]。当进一步添加 CrowdHu-man、Cityperson 和 ETHZ 进行训练时,我们可以达到 76.7 MOTA 和 79.7 IDF1。 IDF1 的巨大改进源于 CrowdHuman 数据集可以增强检测器识别被遮挡的人的能力,从而使卡尔曼滤波器产生更平滑的预测并增强跟踪器的关联能力。
训练数据的实验表明 ByteTrack 并不需要数据。与之前需要超过 7 个数据源 [19、21、44、55、73、82、88] 才能实现高性能的方法 [33、34、65、85] 相比,这对于实际应用来说是一个很大的优势。
D.轨迹插值
我们注意到MOT17中有一些完全遮挡的行人,其可见比率在地面实况注释中为0。由于几乎不可能通过视觉线索检测到它们,因此我们通过轨迹插值来获取这些对象。
假设我们有一个轨迹 T ,它的轨迹框由于从帧 t1 到 t2 的遮挡而丢失。 T 在帧 t1 处的轨迹框是 Bt1 ∈ R4,其中包含边界框的左上角和右下角坐标。令 Bt2 表示 T 在帧 t2 处的轨迹框。我们设置一个超参数 σ 代表我们执行轨迹插值的最大间隔,这意味着当 t2 − t1 ≤ σ 时执行轨迹插值。轨迹 T 在帧 t 处的插值框可以计算如下:

其中 t1 < t < t2。
如表 11 所示,当 σ 为 20 时,轨迹插值可以将 MOTA 从 76.6 提高到 78.3,IDF1 从 79.3 提高到 80.2。轨迹插值是一种有效的后处理方法,可以获取完全遮挡对象的框。我们在私有检测协议下的 MOT17 [44]、MOT20 [17] 和 HiEve [37] 的测试集中使用轨迹插值。
E. MOTChallenge上公开检测结果
我们在公共检测协议下的 MOT17 [44] 和 MOT20 [17] 测试集上评估 ByteTrack。遵循 Tracktor [3] 和 CenterTrack [89] 中的公共检测过滤策略,我们仅在与公共检测框的 IoU 大于 0.8 时初始化新轨迹。我们不使用公共检测协议下的轨迹插值。如表 12 所示,ByteTrack 在 MOT17 上大幅优于其他方法。例如,它在 MOTA 上优于 SiamMOT 1.5 分,在 IDF1 上优于 SiamMOT 6.7 分。表 13 显示了 MOT20 的结果。 ByteTrack 的性能也大幅优于现有结果。例如,它在 MOTA 上比 TMOH [57] 好 6.9 点,在 IDF1 上好 9.0 点,在 HOTA 上好 7.5 点,并将身份切换减少四分之三。公共检测协议下的结果进一步表明了我们的关联方法 BYTE 的有效性。
F. 可视化结果。
我们在图 5 中展示了 ByteTrack 能够处理的一些困难情况的可视化结果。困难情况包括遮挡(即 MOT17-02、MOT1704、MOT17-05、MOT17-09、MOT17-13)、运动模糊(即 MOT17- 10、MOT17-13)和小物体(即 MOT1713)。中间帧中带有红色三角形的行人检测得分较低,这是通过我们的关联方法 BYTE 获得的。低分框不仅减少了漏检的数量,而且在长程关联中发挥着重要作用。从所有这些困难案例中我们可以看到,ByteTrack 没有带来任何身份切换,并且有效地保留了身份。

表 7. BDD100K 测试集上最先进方法的比较。最佳结果以粗体显示。 ByteTrack 在 BDD100K 排行榜上的所有跟踪器中排名第一,并且在大多数指标上都大幅领先第二名 QDTrack。

表 8. 在 MOT17 验证集上使用光检测模型对 BYTE 和 DeepSORT 进行比较。

表 9. MOT17 验证集上不同输入大小的比较。总运行时间是检测时间和关联时间的组合。最佳结果以粗体显示。

表 10. MOT17 验证集上不同训练数据的比较。 “MOT17”是 MOT17 半训练集的缩写。 “CH”是 CrowdHuman 数据集的缩写。 “CE”是 Cityperson 和 ETHZ 数据集的缩写。最佳结果以粗体显示。

表 11. MOT17 验证集上不同插值间隔的比较。最佳结果以粗体显示。

表 12. MOT17 测试集上“公共检测器”协议下最先进方法的比较。最佳结果以粗体显示。

表 13. MOT20 测试集上“公共检测器”协议下最先进方法的比较。最佳结果以粗体显示。

图 5.ByteTrack 的可视化结果。我们从 MOT17 的验证集中选择了 6 个序列,并展示了 ByteTrack 处理遮挡和运动模糊等困难情况的有效性。黄色三角形代表高分框,红色三角形代表低分框。相同的盒子颜色代表相同的身份。
精读
我们提出了一种名为BYTE的数据关联方法,并设计了一个基于该方法的强大跟踪器ByteTrack,它在多目标跟踪领域展示了显著的性能提升。
-
BYTE数据关联方法:
- BYTE是一种简单而有效的数据关联技术,可以轻松集成到现有跟踪器中,带来一致的改进。
- ByteTrack通过结合BYTE方法和精确的检测器,实现了对遮挡情况的鲁棒性,并充分利用了检测结果来增强跟踪性能。
-
ByteTrack的性能:
- 在MOT17测试集上,ByteTrack以30 FPS的速度达到了80.3 MOTA、77.3 IDF1和63.1 HOTA,在所有跟踪器中排名第一。
- ByteTrack的高精度、快速性和简单性使其成为实际应用中的理想选择。
-
边界框注释处理:
- 针对MOT17等数据集,我们修改了YOLOX的检测器,以避免在图像边界周围的错误检测结果,确保边界框覆盖整个物体。
- 对于其他剪切图像内边界框注释的数据集(如MOT20、HiEve和BDD100K),我们则保持YOLOX的原始设置。
-
光检测模型下的跟踪性能:
- 使用不同主干网的YOLOX作为检测器,ByteTrack在MOTA和IDF1上均优于DeepSORT,表明其对检测性能的鲁棒性。
- 特别是在使用轻量级检测模型(如YOLOX-Nano)时,ByteTrack的优势更为明显,使其在实际应用中更具吸引力。
-
消融研究:
- 速度与准确性:通过调整输入图像大小,ByteTrack可以在保持高准确性的同时,实现不同的运行速度,满足不同应用场景的需求。
- 训练数据:ByteTrack在仅使用少量训练数据的情况下就能达到优异的性能,这表明其对数据的依赖性较低。进一步增加训练数据集(如CrowdHuman)可以显著提升其性能,特别是IDF1指标,这得益于增强的检测器对遮挡物体的识别能力。
-
轨迹插值:
-
ByteTrack采用了轨迹插值技术来处理MOT17等数据集中完全遮挡的行人。由于这些行人在遮挡期间几乎无法通过视觉线索被检测到,轨迹插值成为获取这些对象位置的有效手段。
-
通过在轨迹丢失的帧之间进行线性插值,ByteTrack能够估计并填充遮挡期间的轨迹框。这种方法显著提高了MOTA和IDF1等关键指标,证明了轨迹插值的有效性。
-
-
MOTChallenge上公开检测结果:
-
ByteTrack在MOTChallenge的MOT17和MOT20测试集上,按照公共检测协议进行了评估,并展示了卓越的性能。
-
在MOT17上,ByteTrack大幅优于其他方法,特别是在MOTA和IDF1等指标上。同样,在MOT20上,ByteTrack也表现出色,显著提高了MOTA、IDF1和HOTA等指标,并大幅减少了身份切换。
-
这些结果进一步验证了ByteTrack的关联方法BYTE的有效性和鲁棒性,尤其是在处理复杂场景和遮挡情况时。
-
-
可视化结果:
-
通过可视化结果,展示了ByteTrack在处理遮挡、运动模糊和小物体等困难情况时的优势。
-
即使在低分检测框的帮助下,ByteTrack也能有效地保留并关联行人身份,避免了身份切换的问题。
-
这些可视化结果直观地展示了ByteTrack在实际应用中的潜力和价值,为未来的多目标跟踪研究提供了新的思路和方法。
-
论文总结:
这篇论文主要讲了一个关联方法:BYTE,以及用该关联方法和YOLOX检测器组成的跟踪器ByteTrack。然后做了大量的实验将该关联方法应用到了很多跟踪器上,最终得出该关联方法很有效,可以显著提升别的跟踪器的效果。该跟踪器ByteTrack也是最先进的结果目前为止。
相关文章:
多目标跟踪之ByteTrack论文(翻译+精读)
ByteTrack:通过关联每个检测框进行多对象跟踪 摘要 翻译 多对象跟踪(MOT)旨在估计视频中对象的边界框和身份。大多数方法通过关联分数高于阈值的检测框来获取身份。检测分数低的物体,例如被遮挡的物体被简单地丢弃,…...

【实践】Java开发常用工具类或中间件
在Java开发中,有许多常用的工具类和中间件,它们可以显著提高开发效率,简化代码,并提供强大的功能。这些工具类和中间件广泛应用于各种类型的Java应用程序中,包括Web应用、企业级应用、微服务等。以下是一些在Java开发中…...

Vue2移动端(H5项目)项目封装车牌选择组件
一、最终效果 二、参数配置 1、代码示例: <t-keyword:isShow"isShow"ok"isShowfalse"cancel"isShowfalse"inputchange"inputchange":finalValue"trailerNo"/>2、配置参数(TKeyword Attribute…...

四川财谷通信息技术有限公司抖音小店的优势
在数字化浪潮的推动下,电商行业迎来了前所未有的发展机遇,而抖音小店作为新兴的电商平台,凭借其独特的社交属性和便捷的购物体验,迅速赢得了广大消费者的青睐。在众多抖音小店中,四川财谷通信息技术有限公司旗下的抖音…...

2025届八股文:计算机网络高频重点面试题
鉴于排版复杂且篇幅过长,本文仅列举出问题,而未给出答案,有需要答案的同学可后台私信。整理总结不易,请尊重劳动成果,转载请注明出处。 目录 网络基础 HTTP TCP UDP IP PING WebSocket DNS 网络安全 网络基础…...

嵌入式和单片机有什么区别?
目录 (1)什么是嵌入式? (2)什么是单片机? (3)嵌入式和单片机的共同点 (4)嵌入式和单片机的区别 (1)什么是嵌入式? 关…...

JSON.stringify 和 JSON.parse
JSON.stringify 是一个将 JavaScript 对象转换为 JSON 字符串的方法,它有三个参数: JSON.stringify(value, replacer, space) 参数详解 value (必需): 这是你想要转换为 JSON 字符串的 JavaScript 对象或数组。例如:…...

APP架构设计_2.用MVVM架构实现一个具体业务
2.MVVM架构图 3.MVVM 实现一个具体业务 3.1 界面层的实现 界面层实现时,需要遵循以下几点。 1)选择实现界面的元素 界面元素可以用 view 或 compose 来实现,这里用 view 实现。 2)提供一个状态容器 这里使用 ViewModel 作为状态容…...

安恒信息总裁宋端智,辞职了!活捉一枚新鲜出炉的餐饮人!
吉祥知识星球http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247485367&idx1&sn837891059c360ad60db7e9ac980a3321&chksmc0e47eebf793f7fdb8fcd7eed8ce29160cf79ba303b59858ba3a6660c6dac536774afb2a6330#rd 《网安面试指南》http://mp.weixin.qq.com/s?…...

《javaEE篇》--定时器
定时器概念 当我们不需要某个线程立刻执行,而是在指定时间点或指定时间段之后执行,假如我们要定期清理数据库里的一些信息时,如果每次都手动清理的话就太麻烦,所以就可以使用定时器。定时器就可以比作一个闹钟,可以让…...

OpenLayers3, 缩放、平移、复位操作
文章目录 一、前言二、代码示例 一、前言 本文基于OpenLayers3实现地图缩放、平移和复位操作 二、代码示例 <!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><htm…...

进程与线程(7)
IPC通信方式: 一、共享内存 system v : 共享内存 是一块,内核预留的空间 最高效的通信方式 (避免了用户空间 到 内核空间的数据拷贝) 二、IPC对象操作通用框架: key值 > 申请 》读写 》关闭 》卸载 1.ftok函数:…...

传知代码-自动化细胞核分割与特征分析(论文复现)
代码以及视频讲解 本文所涉及所有资源均在传知代码平台可获取 引言 细胞核分割和分类在医学研究和临床诊断中具有重要意义。精准的细胞核分割能够帮助医生更好地识别和分析细胞核的形态学特征,从而辅助疾病诊断、癌症检测以及药物研发。HoverNet是一种基于深度学…...

Vue UI - 可视化的Vue项目管理器
概述 Vue CLI 3.0 更新后,提供了一套全新的可视化Vue项目管理器 —— Vue UI。所以要想使用它,你的 Vue CL I版本必须要在v3.0以上。 一、启动Vue UI 1.1 环境准备 1.1.1 安装node.js 访问官网(外网下载速度较慢)或 http://nod…...

团队管理之敏捷开发
一、敏捷实践 敏捷开发中一直秉承的理念和宣言是:我们正在通过亲身实践以及帮助他人实践,揭示更好的软件开发方法。通过这项工作,我们认为:个体和交互胜过过程和工具、可以工作的软件胜过面面俱到的文档、客户合作胜过合同谈判、…...

Hive3:表的常用修改语句
1、表重命名 ALTER TABLE old_table_name RENAME TO new_table_name;如: ALTER TABLE score4 RENAME TO score5;2、修改表属性值 ALTER TABLE table_name SET TBLPROPERTIES table_properties; table_properties:: (property_name property_value, property…...
MidJourney付费失败的原因以及失败后如何取消或续订(文末附MidJourney,GPT-4o教程)
MidJourney付费失败的原因 MidJourney付费失败的原因可能包括支付方式无效、支付信息错误、网络问题、账户设置问题等。 支付方式无效或信息错误:如果用户提供的支付方式(如信用卡)信息不正确,或者支付方式本身不支持该地区…...

PHP安全开发
安全开发 PHP 基础 增:insert into 表名(列名 1, 列名 2) value(‘列 1 值 1’, ‘列 2 值 2’); 删:delete from 表名 where 列名 ‘条件’; 改:update 表名 set 列名 数据 where 列名 ‘条件’; 查:select * from 表名 wher…...

【大模型从入门到精通32】开源库框架LangChain RAG 系统中的问答技术2
这里写目录标题 探索高级问答链类型MapReduce 和 Refine 技术 实用建议和最佳实践解决 RetrievalQA 限制结论进一步阅读和探索理论问题实践问题 探索高级问答链类型 MapReduce 和 Refine 技术 MapReduce 和 Refine 是设计用来规避由语言模型 (LM) 上下文窗口大小所导致的限制…...

MySQL 数据库管理
在 MySQL 中,数据库管理是非常基础但又至关重要的技能。无论是创建新的数据库、选择当前使用的数据库,还是查看数据库的相关信息,这些操作都是日常数据库管理中不可或缺的一部分。本文将详细介绍 MySQL 数据库管理的基本操作,包括…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...
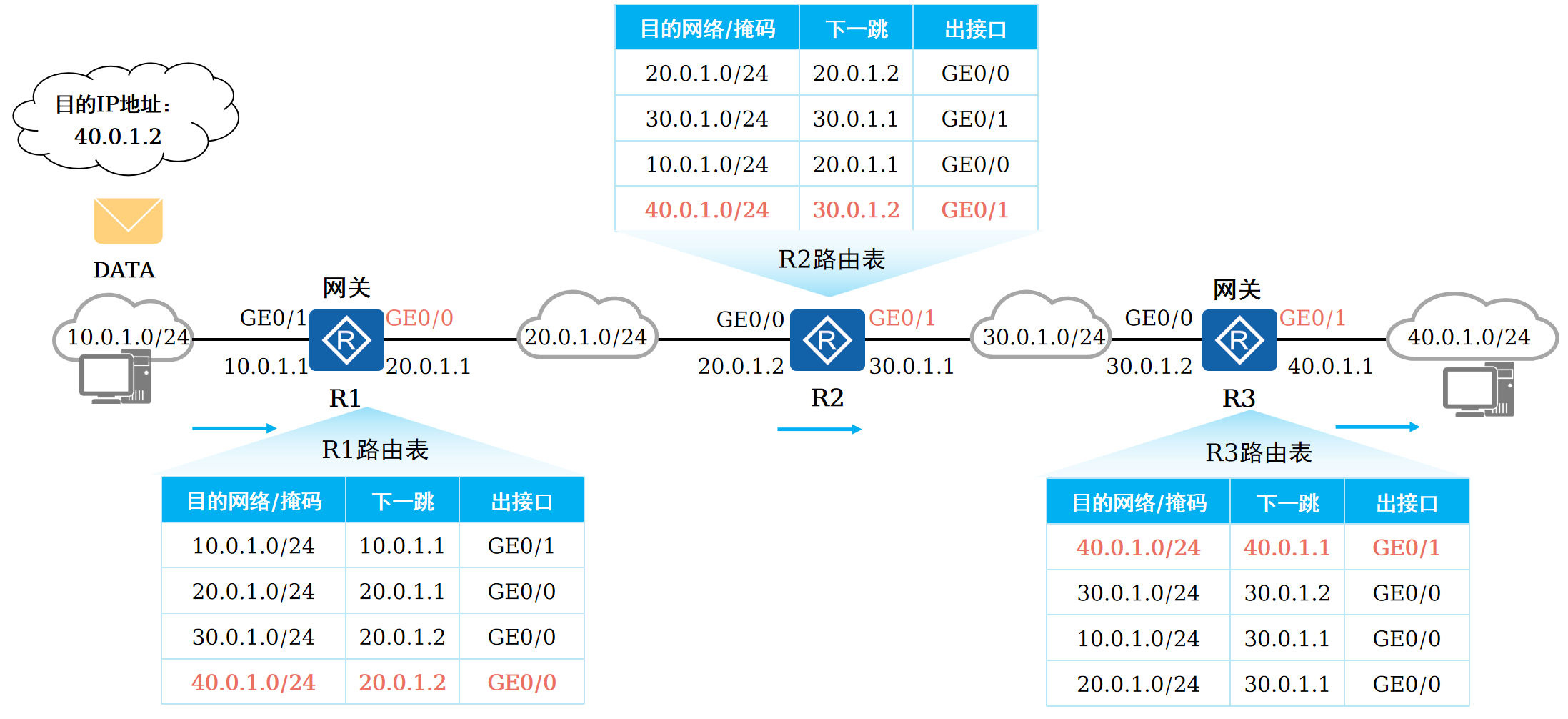
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...