LLM之基于llama-index部署本地embedding与GLM-4模型并初步搭建RAG(其他大模型也可,附上ollma方式运行)
前言
日常没空,留着以后写
llama-index简介
官网:https://docs.llamaindex.ai/en/stable/
简介也没空,以后再写
注:先说明,随着官方的变动,代码也可能变动,大家运行不起来,可以进官网查查资料
加载本地embedding模型
如果没有找到 llama_index.embeddings.huggingface
那么:pip install llama_index-embeddings-huggingface
还不行进入官网,输入huggingface进行搜索
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import SettingsSettings.embed_model = HuggingFaceEmbedding(model_name=f"{embed_model_path}",device='cuda')加载本地LLM模型
还是那句话,如果以下代码不行,进官网搜索Custom LLM Model
from llama_index.core.llms import (CustomLLM,CompletionResponse,CompletionResponseGen,LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from transformers import AutoTokenizer, AutoModelForCausalLMclass GLMCustomLLM(CustomLLM):context_window: int = 8192 # 上下文窗口大小num_output: int = 8000 # 输出的token数量model_name: str = "glm-4-9b-chat" # 模型名称tokenizer: object = None # 分词器model: object = None # 模型dummy_response: str = "My response"def __init__(self, pretrained_model_name_or_path):super().__init__()# GPU方式加载模型self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True).eval()# CPU方式加载模型# self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)# self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)self.model = self.model.float()@propertydef metadata(self) -> LLMMetadata:"""Get LLM metadata."""# 得到LLM的元数据return LLMMetadata(context_window=self.context_window,num_output=self.num_output,model_name=self.model_name,)# @llm_completion_callback()# def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# return CompletionResponse(text=self.dummy_response)## @llm_completion_callback()# def stream_complete(# self, prompt: str, **kwargs: Any# ) -> CompletionResponseGen:# response = ""# for token in self.dummy_response:# response += token# yield CompletionResponse(text=response, delta=token)@llm_completion_callback() # 回调函数def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# 完成函数print("完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])return CompletionResponse(text=response)@llm_completion_callback()def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:# 流式完成函数print("流式完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])for token in response:yield CompletionResponse(text=token, delta=token)基于本地模型搭建简易RAG
from typing import Anyfrom llama_index.core.llms import (CustomLLM,CompletionResponse,CompletionResponseGen,LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from transformers import AutoTokenizer, AutoModelForCausalLM
from llama_index.core import Settings,VectorStoreIndex,SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbeddingclass GLMCustomLLM(CustomLLM):context_window: int = 8192 # 上下文窗口大小num_output: int = 8000 # 输出的token数量model_name: str = "glm-4-9b-chat" # 模型名称tokenizer: object = None # 分词器model: object = None # 模型dummy_response: str = "My response"def __init__(self, pretrained_model_name_or_path):super().__init__()# GPU方式加载模型self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True).eval()# CPU方式加载模型# self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)# self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)self.model = self.model.float()@propertydef metadata(self) -> LLMMetadata:"""Get LLM metadata."""# 得到LLM的元数据return LLMMetadata(context_window=self.context_window,num_output=self.num_output,model_name=self.model_name,)# @llm_completion_callback()# def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# return CompletionResponse(text=self.dummy_response)## @llm_completion_callback()# def stream_complete(# self, prompt: str, **kwargs: Any# ) -> CompletionResponseGen:# response = ""# for token in self.dummy_response:# response += token# yield CompletionResponse(text=response, delta=token)@llm_completion_callback() # 回调函数def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# 完成函数print("完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])return CompletionResponse(text=response)@llm_completion_callback()def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:# 流式完成函数print("流式完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])for token in response:yield CompletionResponse(text=token, delta=token)if __name__ == "__main__":# 定义你的LLMpretrained_model_name_or_path = r'/home/nlp/model/LLM/THUDM/glm-4-9b-chat'embed_model_path = '/home/nlp/model/Embedding/BAAI/bge-m3'Settings.embed_model = HuggingFaceEmbedding(model_name=f"{embed_model_path}",device='cuda')Settings.llm = GLMCustomLLM(pretrained_model_name_or_path)documents = SimpleDirectoryReader(input_dir="home/xxxx/input").load_data()index = VectorStoreIndex.from_documents(documents,)# 查询和打印结果query_engine = index.as_query_engine()response = query_engine.query("萧炎的表妹是谁?")print(response)
ollama
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollamadocuments = SimpleDirectoryReader("data").load_data()# bge-base embedding model
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")# ollama
Settings.llm = Ollama(model="llama3", request_timeout=360.0)index = VectorStoreIndex.from_documents(documents,
)欢迎大家点赞或收藏
大家的点赞或收藏可以鼓励作者加快更新哟~
参加链接:
LlamaIndex中的CustomLLM(本地加载模型)
llamaIndex 基于GPU加载本地embedding模型
官网文档
官网_starter_example_loca
官网_usage_custom
相关文章:
)
LLM之基于llama-index部署本地embedding与GLM-4模型并初步搭建RAG(其他大模型也可,附上ollma方式运行)
前言 日常没空,留着以后写 llama-index简介 官网:https://docs.llamaindex.ai/en/stable/ 简介也没空,以后再写 注:先说明,随着官方的变动,代码也可能变动,大家运行不起来,可以进…...

Python 异步爬虫:高效数据抓取的现代武器
标题:“Python 异步爬虫:高效数据抓取的现代武器” 在当今信息爆炸的时代,网络爬虫已成为数据采集的重要工具。然而,传统的同步爬虫在处理大规模数据时往往效率低下。本文将深入探讨如何使用 Python 实现异步爬虫,以提…...
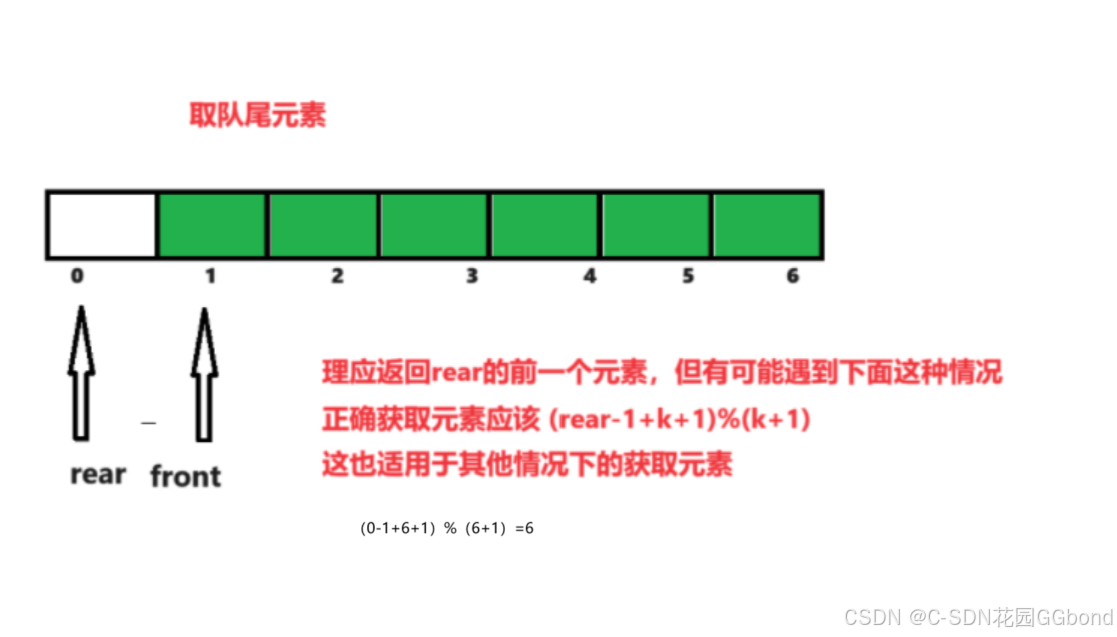
【数据结构算法经典题目刨析(c语言)】使用数组实现循环队列(图文详解)
💓 博客主页:C-SDN花园GGbond ⏩ 文章专栏:数据结构经典题目刨析(c语言) 目录 一.题目描述 二.解题思路 1.循环队列的结构定义 2.队列初始化 3.判空 4.判满 5.入队列 6.出队列 7.取队首元素 8.取队尾元素 三.完整代码实…...

PTA L1-005 考试座位号
L1-005 考试座位号(15分) 每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生…...
软件测试3333
禅道? 学习正则表达式 目标: 能说出软件测试缺陷判定标准 能说出项目中缺陷的管理系统 能使用Excel对于缺陷进行管理 能使用工具管理缺陷 一、用例执行 说明:用例执行不通过,执行结果与用例的期望结果不一致(含义&…...
))
JJJ:结构体定义中常加的后缀:attribute ((packed))
__attribute__ ((packed)): 的作用就是告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法。这个功能是跟操作系统没关系,跟编译器有关 在GCC下:struct my{ char ch; int a;} sizeof(int)4…...

【HTML】DOCTYPE作用
<!DOCTYPE html> DOCTYPE是document type(文档类型)的缩写。是HTML5中一种标准通用标记语言的文档类型声明,告诉浏览器文档的类型,便于解析文档。不同渲染模式会影响浏览器对CSS代码甚至JS脚本的解析。它必须声明在第一行。…...
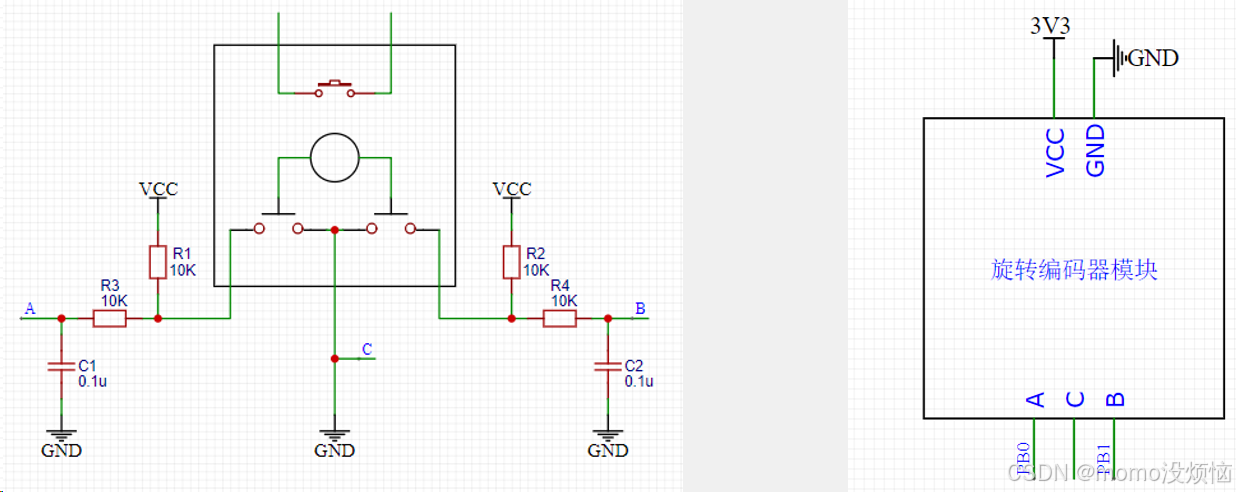
STM32学习记录-04-EXTI外部中断
1 中断系统 (1)中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续…...
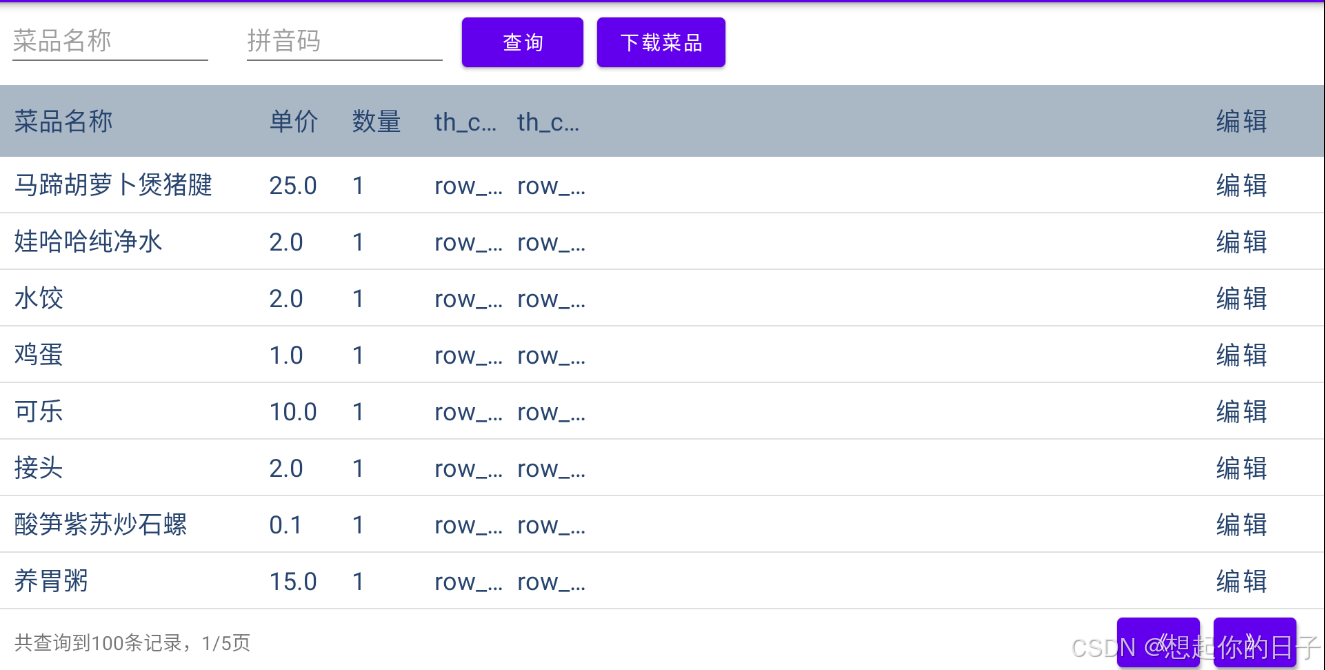
Android Studio 动态表格显示效果
最终效果 一、先定义明细的样式 table_row.xml <?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_h…...

Python 全栈系列264 使用kafka进行并发处理
说明 暂时考虑的场景是单条数据处理特别复杂和耗时的场景。 场景如下: 要对一篇文档进行实体处理,然后再对实体进行匹配。在这个过程当中,涉及到了好几部分服务: 1 实体识别服务2 数据库查询服务3 es查询服务 整个处理包成了服…...

【安全靶场】-DC-7
❤️博客主页: iknow181 🔥系列专栏: 网络安全、 Python、JavaSE、JavaWeb、CCNP 🎉欢迎大家点赞👍收藏⭐评论✍ 一、收集信息 1.查看主机是否存活 nmap -T4 -sP 192.168.216.149 2.主动扫描 看开放了哪些端口和功能 n…...

0065__windows开发要看的经典书籍
windows开发要看的经典书籍_window编程书籍推荐-CSDN博客...

第133天:内网安全-横向移动域控提权NetLogonADCSPACKDC永恒之蓝
案例一:横向移动-系统漏洞-CVE-2017-0146 这个漏洞就是大家熟悉的ms17-010,这里主要学习cs发送到msf,并且msf正向连接后续 原因是cs只能支持漏洞检测,而msf上有很多exp可以利用 注意msf不能使用4.5版本的有bug 这里还是反弹权…...

【IoTDB 线上小课 06】列式写入=时序数据写入性能“利器”?
【IoTDB 视频小课】更新来啦!今天已经是第六期了~ 关于 IoTDB,关于物联网,关于时序数据库,关于开源... 一个问题重点,3-5 分钟,我们讲给你听: 列式写入到底是? 上一期我们详细了解了…...

【机器学习】小样本学习的实战技巧:如何在数据稀缺中取得突破
我的主页:2的n次方_ 在机器学习领域,充足的标注数据通常是构建高性能模型的基础。然而,在许多实际应用中,数据稀缺的问题普遍存在,如医疗影像分析、药物研发、少见语言处理等领域。小样本学习(Few-Shot Le…...

2024.08.14 校招 实习 内推 面经
地/球🌍 : neituijunsir 交* 流*裙 ,内推/实习/校招汇总表格 1、校招 | 理想汽车2025“理想”技术沙龙开启报名 校招 | 理想汽车2025“理想”技术沙龙开启报名 2、校招 | 紫光国芯2025校园招聘正式启动 校招 | 紫光国芯2025校园招聘正式…...

国产双通道集成电机一体化应用的电机驱动芯片-SS6951A
电机驱动芯片 - SS6951A为电机一体化应用提供一种双通道集成电机驱动方案。SS6951A有两路H桥驱动,每个H桥可提供较大峰值电流4.0A,可驱动两个刷式直流电机,或者一个双极步进电机,或者螺线管或者其它感性负载。双极步进电机可以以整…...

32 - II. 从上到下打印二叉树 II
comments: true difficulty: 简单 edit_url: https://github.com/doocs/leetcode/edit/main/lcof/%E9%9D%A2%E8%AF%95%E9%A2%9832%20-%20II.%20%E4%BB%8E%E4%B8%8A%E5%88%B0%E4%B8%8B%E6%89%93%E5%8D%B0%E4%BA%8C%E5%8F%89%E6%A0%91%20II/README.md 面试题 32 - II. 从上到下打…...

總結熱力學_3
參考: 陈曦<<热力学讲义>>http://ithatron.phys.tsinghua.edu.cn/downloads/thermodynamics.pdf 4 热力学量的测量 4.3 主温度计 常用的气体温度计有等体积气体温度计、声学气体温度计和介电常数气体温度计。很多气体在水的三相点附近都接近理想气体。但真正的理…...

TypeScript学习笔记1---认识ts与js的异同、ts的所有数据类型详解
前言:去年做过几个vue3js的项目,当时考虑到时间问题,js更加熟悉,学习成本低一点,所以只去了解了vue3。最近这段时间补了一下ts的知识点,现今终于有空来码文章了,做个学习总结,方便以…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...