Kafka源码分析之Producer(一)
总览
根据kafka的3.1.0的源码example模块进行分析,如下图所示,一般实例代码就是我们分析源码的入口。
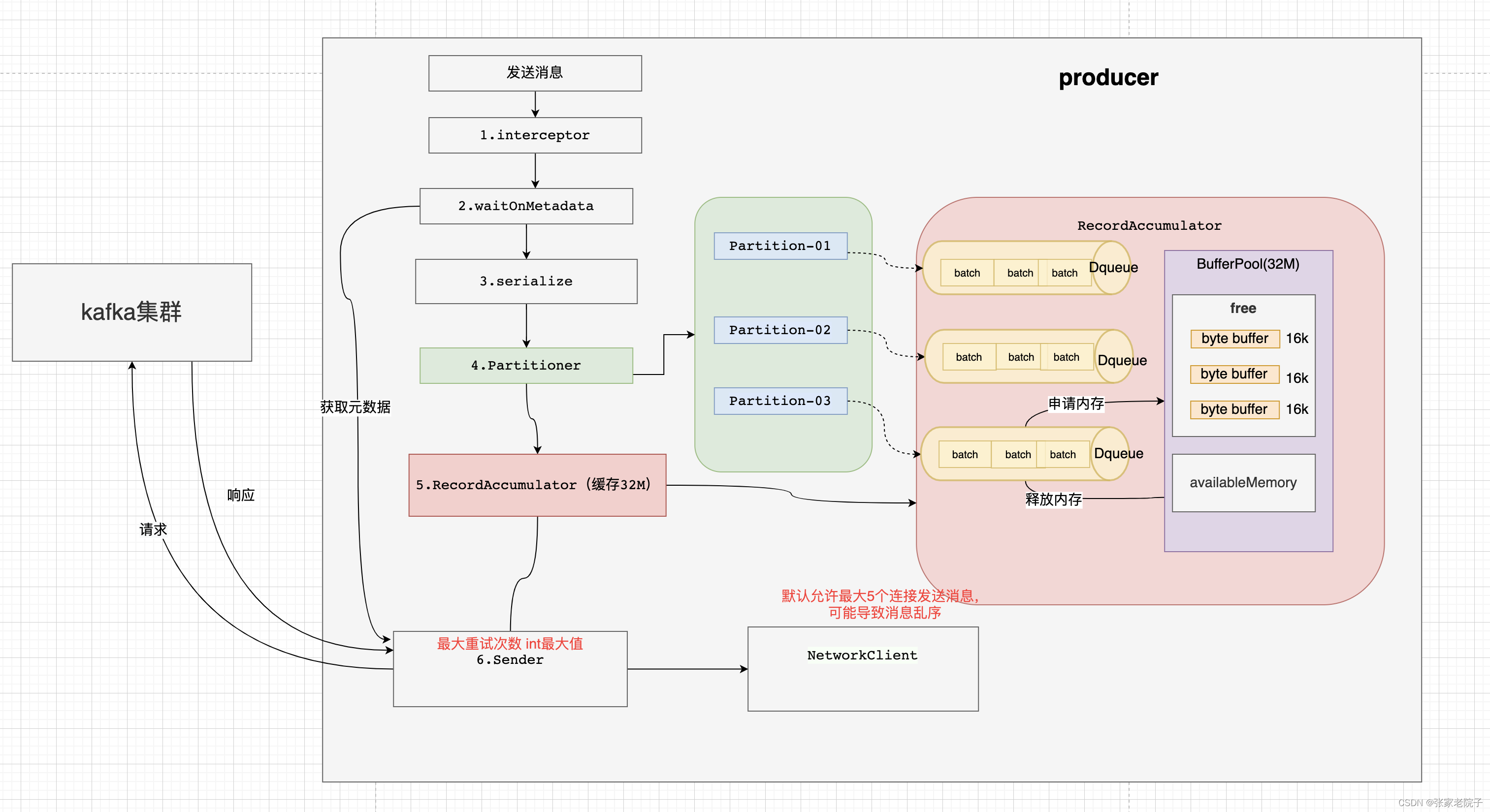
可以将produce的发送主要流程概述如下:
-
拦截器对发送的消息拦截处理;
-
获取元数据信息;
-
序列化处理;
-
分区处理;
-
批次添加处理;
-
发送消息。
总的大概是上面六个步骤,下面将结合源码对每个步骤进行分析。
1. 拦截器
消息拦截器在消息发送开始阶段进行拦截,this method does not throw exceptions注释加上代码可以看出即使拦截器抛出异常也不会中止我们的消息发送。
使用场景:发送消息的统一处理类似spring的拦截器动态切入功能,自定义拦截器打印日志、统计时间、持久化到本地数据库等。
@Overridepublic Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {// intercept the record, which can be potentially modified; this method does not throw exceptions//1.拦截器对发送的消息拦截处理;ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);return doSend(interceptedRecord, callback);}public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {ProducerRecord<K, V> interceptRecord = record;for (ProducerInterceptor<K, V> interceptor : this.interceptors) {try {interceptRecord = interceptor.onSend(interceptRecord);} catch (Exception e) {// do not propagate interceptor exception, log and continue calling other interceptors// be careful not to throw exception from hereif (record != null)log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);elselog.warn("Error executing interceptor onSend callback", e);}}return interceptRecord;}2. 获取元数据信息
下图是发送消息主线程和发送网络请求sender线程配合获取元数据的流程:
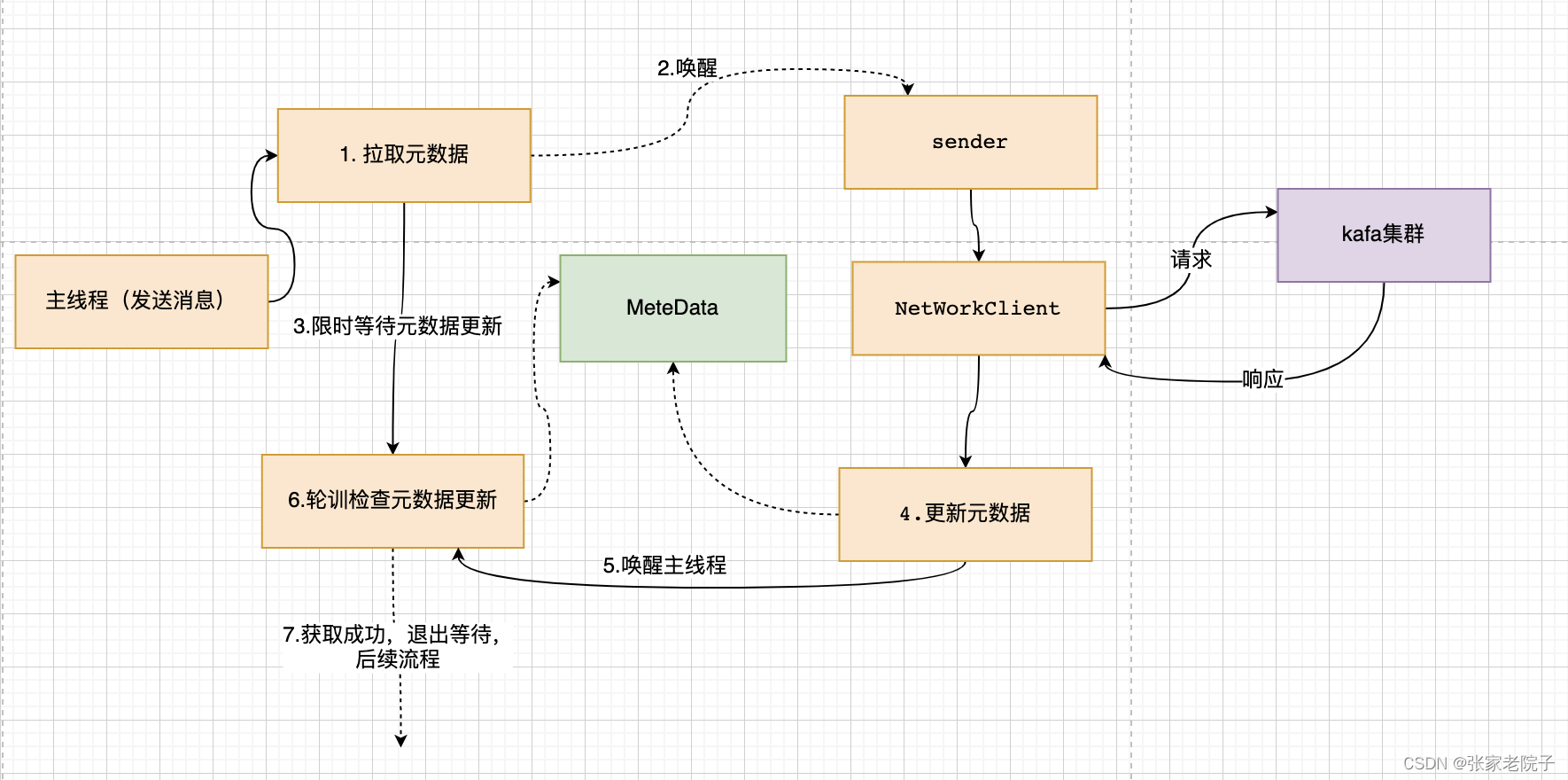
首先找到获取kafka的元数据信息的入口,maxBlockTimeMs最大的等待时间是60s:
try {//2.获取元数据信息;clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);} catch (KafkaException e) {if (metadata.isClosed())throw new KafkaException("Producer closed while send in progress", e);throw e;}.define(MAX_BLOCK_MS_CONFIG,Type.LONG,60 * 1000,atLeast(0),Importance.MEDIUM,MAX_BLOCK_MS_DOC)这里唤醒sender线程,然后阻塞等待元数据信息;
metadata.add(topic, nowMs + elapsed);int version = metadata.requestUpdateForTopic(topic);//唤醒线程更新元数据sender.wakeup();try {//阻塞等待metadata.awaitUpdate(version, remainingWaitMs);} catch (TimeoutException ex) {// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMsthrow new TimeoutException(String.format("Topic %s not present in metadata after %d ms.",topic, maxWaitMs));}这里可以看一下 sender线程的初始化参数:
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC) 初始化内存池的大小为32M;
.define(MAX_REQUEST_SIZE_CONFIG,Type.INT,1024 * 1024,atLeast(0),Importance.MEDIUM,MAX_REQUEST_SIZE_DOC) 默认单条消息最大为1M;
构造函数中初始化了sender,并作为守护线程在后台运行:
this.sender = newSender(logContext, kafkaClient, this.metadata);String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;this.ioThread = new KafkaThread(ioThreadName, this.sender, true);this.ioThread.start(); KafkaProducer(ProducerConfig config,Serializer<K> keySerializer,Serializer<V> valueSerializer,ProducerMetadata metadata,KafkaClient kafkaClient,ProducerInterceptors<K, V> interceptors,Time time) {try {...this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);int deliveryTimeoutMs = configureDeliveryTimeout(config, log);this.apiVersions = new ApiVersions();this.transactionManager = configureTransactionState(config, logContext);this.accumulator = new RecordAccumulator(logContext,config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),this.compressionType,lingerMs(config),retryBackoffMs,deliveryTimeoutMs,metrics,PRODUCER_METRIC_GROUP_NAME,time,apiVersions,transactionManager,new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));...this.errors = this.metrics.sensor("errors");this.sender = newSender(logContext, kafkaClient, this.metadata);String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;this.ioThread = new KafkaThread(ioThreadName, this.sender, true);this.ioThread.start();config.logUnused();AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());log.debug("Kafka producer started");} catch (Throwable t) {// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121close(Duration.ofMillis(0), true);// now propagate the exceptionthrow new KafkaException("Failed to construct kafka producer", t);}}.define(ACKS_CONFIG,Type.STRING,"all",in("all", "-1", "0", "1"),Importance.LOW,ACKS_DOC) 默认所有broker同步消息才算发送成功;
.define(MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,Type.INT,5,atLeast(1),Importance.LOW,MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC) 默认允许最多5个连接来发送消息;如果需要保证顺序消息需要将其设置为1.
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {int maxInflightRequests = configureInflightRequests(producerConfig);int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time, logContext);ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),this.metrics, time, "producer", channelBuilder, logContext),metadata,clientId,maxInflightRequests,producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),requestTimeoutMs,producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),time,true,apiVersions,throttleTimeSensor,logContext);short acks = configureAcks(producerConfig, log);return new Sender(logContext,client,metadata,this.accumulator,maxInflightRequests == 1,producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),acks,producerConfig.getInt(ProducerConfig.RETRIES_CONFIG),metricsRegistry.senderMetrics,time,requestTimeoutMs,producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),this.transactionManager,apiVersions);}等待元数据的版本更新,挂起当前线程直到超时或者唤醒:
public synchronized void awaitUpdate(final int lastVersion, final long timeoutMs) throws InterruptedException {long currentTimeMs = time.milliseconds();long deadlineMs = currentTimeMs + timeoutMs < 0 ? Long.MAX_VALUE : currentTimeMs + timeoutMs;time.waitObject(this, () -> {// Throw fatal exceptions, if there are any. Recoverable topic errors will be handled by the caller.maybeThrowFatalException();return updateVersion() > lastVersion || isClosed();}, deadlineMs);if (isClosed())throw new KafkaException("Requested metadata update after close");}public void waitObject(Object obj, Supplier<Boolean> condition, long deadlineMs) throws InterruptedException {synchronized (obj) {while (true) {if (condition.get())return;long currentTimeMs = milliseconds();if (currentTimeMs >= deadlineMs)throw new TimeoutException("Condition not satisfied before deadline");obj.wait(deadlineMs - currentTimeMs);}}}Sende通过NetWorkClient向kafak集群拉取元数据信息:
Sendervoid runOnce() {
client.poll(pollTimeout, currentTimeMs);
}NetWorkClient:public List<ClientResponse> poll(long timeout, long now) {ensureActive();if (!abortedSends.isEmpty()) {// If there are aborted sends because of unsupported version exceptions or disconnects,// handle them immediately without waiting for Selector#poll.List<ClientResponse> responses = new ArrayList<>();handleAbortedSends(responses);completeResponses(responses);return responses;}long metadataTimeout = metadataUpdater.maybeUpdate(now);try {this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));} catch (IOException e) {log.error("Unexpected error during I/O", e);}// process completed actionslong updatedNow = this.time.milliseconds();List<ClientResponse> responses = new ArrayList<>();handleCompletedSends(responses, updatedNow);handleCompletedReceives(responses, updatedNow);handleDisconnections(responses, updatedNow);handleConnections();handleInitiateApiVersionRequests(updatedNow);handleTimedOutConnections(responses, updatedNow);handleTimedOutRequests(responses, updatedNow);completeResponses(responses);return responses;}如下代码 handleCompletedReceives处理返回元数据的响应,然后调用handleSuccessfulResponse处理成功的响应,最后调用ProducerMetadata更新本地元数据信息并唤醒了主线程。主线程获取到元数据后进行下面流程。
//NetWorkClient private void handleCompletedReceives(List<ClientResponse> responses, long now) {...if (req.isInternalRequest && response instanceof MetadataResponse)metadataUpdater.handleSuccessfulResponse(req.header, now, (MetadataResponse) response);}public void handleSuccessfulResponse(RequestHeader requestHeader, long now, MetadataResponse response) {...this.metadata.update(inProgress.requestVersion, response, inProgress.isPartialUpdate, now);}//ProducerMetadata public synchronized void update(int requestVersion, MetadataResponse response, boolean isPartialUpdate, long nowMs) {super.update(requestVersion, response, isPartialUpdate, nowMs);// Remove all topics in the response that are in the new topic set. Note that if an error was encountered for a// new topic's metadata, then any work to resolve the error will include the topic in a full metadata update.if (!newTopics.isEmpty()) {for (MetadataResponse.TopicMetadata metadata : response.topicMetadata()) {newTopics.remove(metadata.topic());}}notifyAll();}3. 序列化处理
根据初始化的序列化器将消息的key和value进行序列化,以便后续发送网络请求:
byte[] serializedKey;try {serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());System.out.println("serializedKey:" + Arrays.toString(serializedKey));} catch (ClassCastException cce) {throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +" specified in key.serializer", cce);}byte[] serializedValue;try {serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());} catch (ClassCastException cce) {throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +" specified in value.serializer", cce);}4.分区处理
消息有设置key根据hash值分区,没有key采用粘性分区的方式,详情可以看下面博客Kafka生产者的粘性分区算法_张家老院子的博客-CSDN博客
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {if (keyBytes == null) {return stickyPartitionCache.partition(topic, cluster);}// hash the keyBytes to choose a partitionreturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}5.批次添加处理
如果第一次添加会为分区初始化一个双端队列,然后获取批次为空会
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs)创建一个新的批次放到队列中dq.addLast(batch);
public RecordAppendResult append(TopicPartition tp,long timestamp,byte[] key,byte[] value,Header[] headers,Callback callback,long maxTimeToBlock,boolean abortOnNewBatch,long nowMs) throws InterruptedException {// We keep track of the number of appending thread to make sure we do not miss batches in// abortIncompleteBatches().appendsInProgress.incrementAndGet();ByteBuffer buffer = null;if (headers == null) headers = Record.EMPTY_HEADERS;try {// check if we have an in-progress batchDeque<ProducerBatch> dq = getOrCreateDeque(tp);synchronized (dq) {if (closed)throw new KafkaException("Producer closed while send in progress");RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);if (appendResult != null)return appendResult;}// we don't have an in-progress record batch try to allocate a new batchif (abortOnNewBatch) {// Return a result that will cause another call to append.return new RecordAppendResult(null, false, false, true);}byte maxUsableMagic = apiVersions.maxUsableProduceMagic();int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, tp.topic(), tp.partition(), maxTimeToBlock);// 内存池中分配内存buffer = free.allocate(size, maxTimeToBlock);// Update the current time in case the buffer allocation blocked above.nowMs = time.milliseconds();synchronized (dq) {// Need to check if producer is closed again after grabbing the dequeue lock.if (closed)throw new KafkaException("Producer closed while send in progress");RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);if (appendResult != null) {// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...return appendResult;}MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,callback, nowMs));dq.addLast(batch);incomplete.add(batch);// Don't deallocate this buffer in the finally block as it's being used in the record batchbuffer = null;return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);}} finally {if (buffer != null)free.deallocate(buffer);appendsInProgress.decrementAndGet();}}然后主流程中会再次调用添加,此时有了批次将能够添加成功:
result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);6.发送消息
批次满了或者创建了新的批次将唤醒消息发送线程:
if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);this.sender.wakeup();}后续将更加深入分析kafka的NIO源码,探究它怎么多到高性能的。
相关文章:
Kafka源码分析之Producer(一)
总览 根据kafka的3.1.0的源码example模块进行分析,如下图所示,一般实例代码就是我们分析源码的入口。 可以将produce的发送主要流程概述如下: 拦截器对发送的消息拦截处理; 获取元数据信息; 序列化处理;…...

springboot校友社交系统
050-springboot校友社交系统演示录像开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:e…...

python flask项目部署
flask上传服务器pyhon安装下载Anacondasudo wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh可根据需要安装对应的版本https://repo.anaconda.com/archive/解压anaconda压缩包bash Anaconda3-5.3.1-Linux-x86_64.sh解压过程中会…...
常见排序算法(C语言实现)
文章目录排序介绍插入排序直接插入排序希尔排序选择排序选择排序堆排序交换排序冒泡排序快速排序递归实现Hoare版本挖坑法前后指针版本非递归实现Hoare版本挖坑法前后指针版本快排的优化三值取中小区间优化归并排序递归实现非递归实现计数排序排序算法复杂度及稳定性分析不同算…...

基于jsp+ssm+springboot的小区物业管理系统【设计+论文+源码】
摘 要随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于小区物业管理系统当然也不能排除在外,随着网络技术的不断成熟,带动了小区物业管理系统,它彻底改变了过去…...

Elasticsearch 学习+SpringBoot实战教程(三)
需要学习基础的可参照这两文章 Elasticsearch 学习SpringBoot实战教程(一) Elasticsearch 学习SpringBoot实战教程(一)_桂亭亭的博客-CSDN博客 Elasticsearch 学习SpringBoot实战教程(二) Elasticsearch …...

try-with-resource
try-with-resource是Java 7中引入的新特性,它可以方便地管理资源,自动关闭资源,从而避免了资源泄漏的问题。 作用 使用try-with-resource语句可以简化代码,避免了手动关闭资源的繁琐操作,同时还可以保证资源的正确关闭…...

leetcode148_排序链表的3种解法
1. 题目2. 解答 2.1. 解法12.2. 解法22.3. 解法3 1. 题目 给你链表的头结点head,请将其按升序排列并返回排序后的链表。 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullp…...
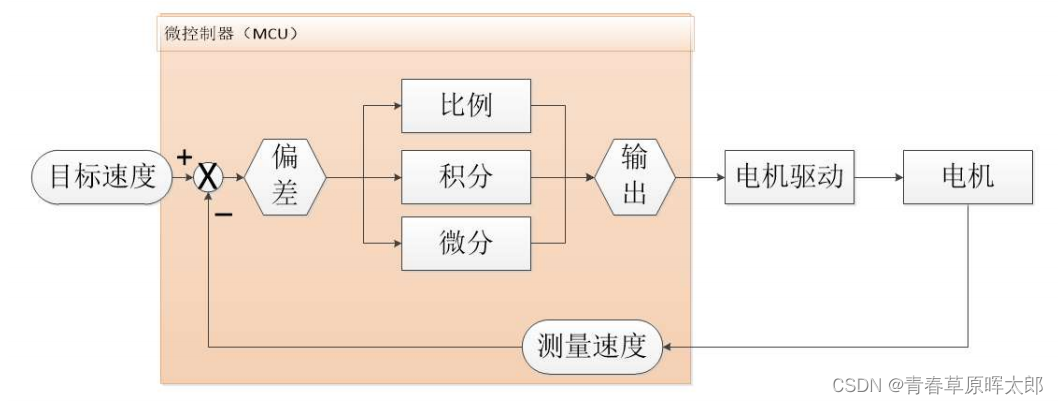
使用stm32实现电机的PID控制
使用stm32实现电机的PID控制 PID控制应该算是非常古老而且应用非常广泛的控制算法了,小到热水壶温度控制,大到控制无人机的飞行姿态和飞行速度等等。在电机控制中,PID算法用的尤为常见。 文章目录使用stm32实现电机的PID控制一、位置式PID1.计…...

数学原理—嵌入矩阵
目录 1.嵌入矩阵的基本作用 2.嵌入矩阵的数学解释 3.嵌入矩阵在联合分布适应中的数学推导主要包括以下几个步骤 4.在JDA中,怎么得到嵌入矩阵 5.联合分布自适应中如何得到嵌入矩阵 (另一种解释) 1.嵌入矩阵的基本作用 在机器学习中&a…...

English Learning - L2 语音作业打卡 辅音翘舌音 [ʃ] [ʒ] 空气摩擦音 [h] Day31 2023.3.23 周四
English Learning - L2 语音作业打卡 辅音翘舌音 [ʃ] [ʒ] 空气摩擦音 [h] Day31 2023.3.23 周四💌发音小贴士:💌当日目标音发音规则/技巧:翘舌音 [ʃ] [ʒ]空气摩擦音 [h]🍭 Part 1【热身练习】🍭 Part2【练习内容】…...
记录springboot+vue+fastdfs实现简易的文件(上传、下载、删除、预览)操作
前言说明:springboot vue FastDFS实现文件上传(支持预览)升级版 FASTDFS部分 FASTDFS安装过程:基于centos 7安装FastDFS文件服务器 SpringBoot部分 springboot源码实现 package com.core.doc.controller;import com.baomid…...
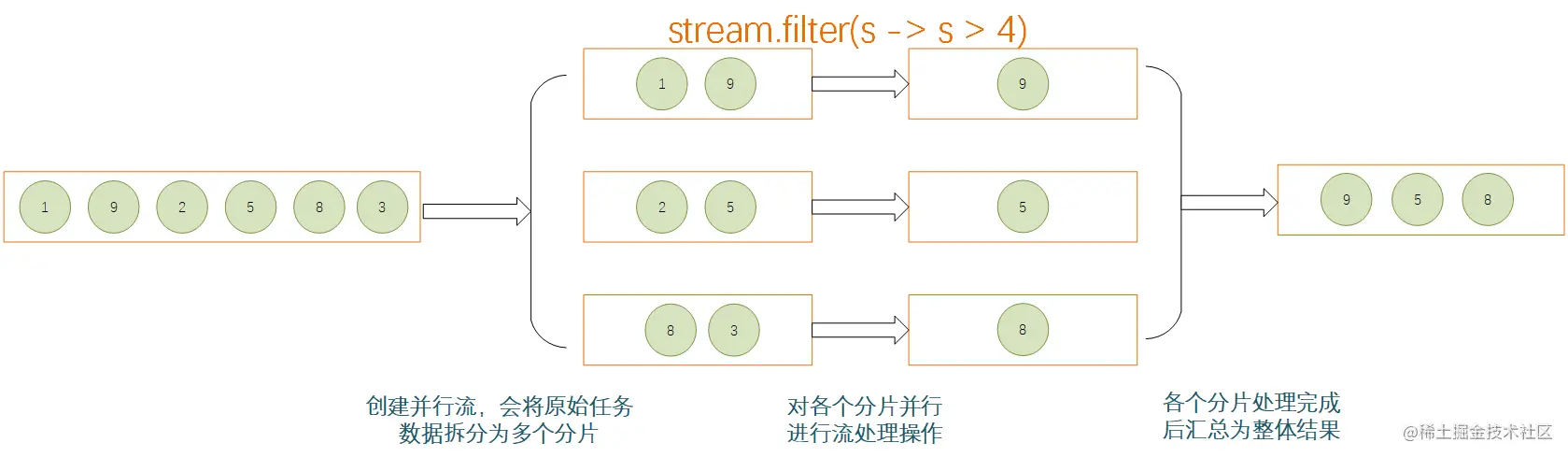
Java中循环使用Stream应用场景
在JAVA中,涉及到对数组、Collection等集合类中的元素进行操作的时候,通常会通过循环的方式进行逐个处理,或者使用Stream的方式进行处理。例如,现在有这么一个需求:从给定句子中返回单词长度大于5的单词列表,…...
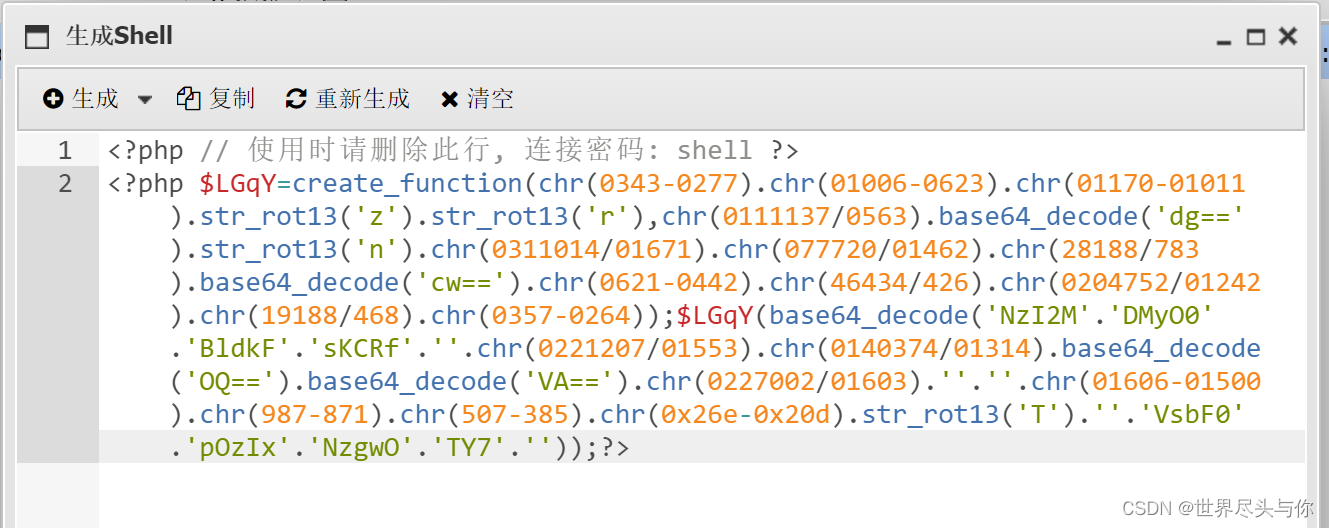
中国蚁剑AntSword实战
中国蚁剑AntSword实战1.基本使用方法2.绕过安全狗连接3.请求包修改UA特征伪造RSA流量加密4.插件使用1.基本使用方法 打开蚂蚁宝剑,右键添加数据: 输入已经上传马的路径和连接密码: 测试连接,连接成功! GetShell了&…...

C++ 直接初始化和拷贝初始化
首先我们介绍直接初始化:编译器使用普通的函数匹配来选择与我们提供的参数最匹配的构造函数。文字描述可能会让你们云里雾里,那我们直接看代码: //先设计这样的一个类 class A{ public:A(){ cout << "A()" << endl; }A…...
数据迁移工具
1.Kettle Kettle是一款国外开源的ETL工具,纯Java编写,绿色无需安装,数据抽取高效稳定 (数据迁移工具)。 Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。 Kettle 中文名称叫水壶,该项目的主程序…...
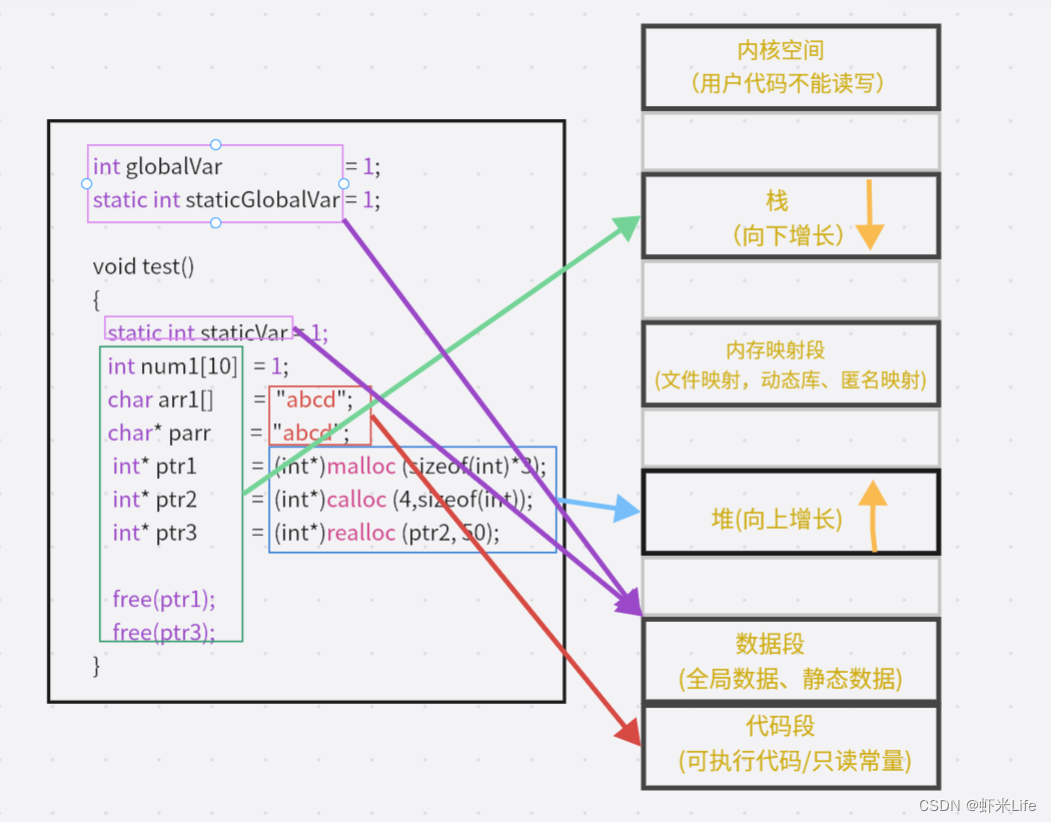
【C/C++】程序的内存开辟
在C/C语言中,不同的类型开辟的空间区域都是不一样的. 这节我们就简单了解下开辟不同的类型内存所存放的区域在哪里. 文章目录栈区(stack)堆区(heap)数据段(静态区)常量存储区内存开辟布局图栈区…...
全网最完整,接口测试总结彻底打通接口自动化大门,看这篇就够了......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 所谓接口࿰…...
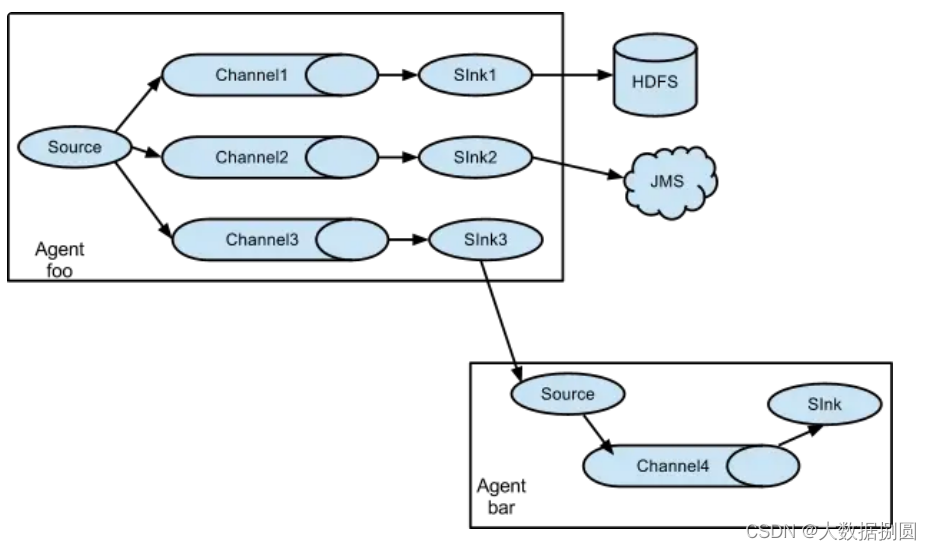
28-flume和kafka为什么要结合使用
一:flume和kafka为什么要结合使用 首先:Flume 和 Kafka 都是用于处理大量数据的工具,但它们的设计目的不同。Flume 是一个可靠地收集、聚合和移动大量日志和事件数据的工具,而Kafka则是一个高吞吐量的分布式消息队列,…...

STM32外设-定时器详解
0. 概述 本文针对STM32F1系列,主要讲解了其中的8个定时器的原理和功能 1. 定时器分类 STM32F1 系列中,除了互联型的产品,共有 8 个定时器,分为基本定时器,通用定时器和高级定时器基本定时器 TIM6 和 TIM7 是一个 16 位…...

TurboVNC终极指南:如何快速搭建高性能远程桌面系统
TurboVNC终极指南:如何快速搭建高性能远程桌面系统 【免费下载链接】turbovnc Main TurboVNC repository 项目地址: https://gitcode.com/gh_mirrors/tu/turbovnc TurboVNC是一个专为高性能图形应用优化的远程桌面解决方案,特别适合3D渲染、视频处…...

3分钟快速上手:Buzz音频转录软件完整使用指南
3分钟快速上手:Buzz音频转录软件完整使用指南 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Trending/buz/buzz 还在为音频转录烦恼…...

百度文库文档免费下载终极指南:三步获取PDF完整教程
百度文库文档免费下载终极指南:三步获取PDF完整教程 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到心仪的文档,却因为需要下载券或付费而无法保存…...

Windows 环境 OpenClaw 2.7.5 一键安装避坑指南
OpenClaw 一键安装包|可视化部署,简化环境配置流程✨适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)✨核心优势:全程可视化操作,不用命令行、不用手动配置 Python/Node.js&a…...

2026年最新解答:天学网的英语听力对孩子真的有用吗?
作为在英语听力教研领域深耕5年的从业者,今年Q1刚做完一轮主流AI英语听力工具的横评,刚好结合实测数据和一线教学反馈来客观回答这个问题,没有广告,全是干货。先聊聊当前英语听力训练的共性痛点我们团队最近1年调研了30多所公立校…...

如何将Scrapeless MCP服务器集成到ZeroClaw中:逐步指南
关键要点: 一个TOML块将云浏览器连接到本地Rust代理。 ZeroClaw是一个单一二进制AI代理运行时,它与LLM提供者通信,监听30多个频道,并通过工具进行操作。只需在~/.zeroclaw/config.toml中添加四行[mcp]块即可添加Scrapeless MCP服…...

XXMI启动器:二次元游戏模组管理的一站式解决方案,5分钟搞定复杂配置
XXMI启动器:二次元游戏模组管理的一站式解决方案,5分钟搞定复杂配置 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款革命性的开源游戏模…...

如何优化NovelReader性能:10个技巧降低内存使用率
如何优化NovelReader性能:10个技巧降低内存使用率 【免费下载链接】NovelReader 仿照"任阅"的追书、看书的小说阅读器。重写"任阅"的代码,优化代码逻辑和代码结构,降低内存使用率。重写小说阅读器,支持网络阅…...

AI赋能泳装设计——让科技与时尚共舞
AI赋能泳装设计——让科技与时尚共舞当AI遇见泳装:北京先智先行用智能技术重新定义夏日时尚夏日的脚步渐近,泳装市场即将迎来年度销售旺季。在这个看脸的时代,消费者对泳装的要求早已不止于"能穿",更追求个性化、时尚感…...

实战解析:如何用Qualcomm AI Engine Direct的OpPackage机制为你的AI模型添加自定义算子
深度实战:利用Qualcomm AI Engine Direct的OpPackage机制实现自定义算子全流程开发 在移动端AI模型部署的实践中,我们常常会遇到一个关键挑战:当模型包含特殊算子或自研算法时,如何在不修改底层框架的前提下实现高效执行ÿ…...