爬虫Day2 正则表达式
爬虫Day2 正则表达式
一、正则表达式
1. 正则的作用
正则表达式是一种可以让复杂的字符串变得简单的工具。
写正则表达式就是用正则符号来描述字符串规则
# 案例1:判断一个字符串是否是一个合法的手机号码
tel = '23297293329'# 方法1:不用正则
if len(tel) == 11:if tel[0] == '1':if tel[1] in '3456789':if tel[2:].isdigit():print('合法')else:print('不合法')else:print('不合法')else:print('不合法')
else:print('不合法')print('--------------------------------华丽的分割线-------------------------------------')
import re
from re import *result = re.fullmatch(r'1[3-9]\d{9}', tel)
if result:print('合法')
else:print('不合法')
# 案例2:提取字符串中所有的数字子串,并且求和
str1 = '睡觉89jss=3.45-换手23=抗生素820=8'
result = re.findall(r'\d+\.?\d*', str1)
print(sum([float(x) for x in result]))
二、正则语法
from re import fullmatch, findall, search, match, finditer, split, sub
1. re模块 - 提供了python中所有和正则相关的函数
fullmatch(正则表达式, 字符串) - 判断整个字符串是否满足正则表达式所描述的规则
findall(正则表达式, 字符串) - 提取字符串中所有满足正则表达式的子串
search(正则表达式, 字符串) - 匹配字符串中第一个满足正则表达式的字串
注意:Python中表达式一个正则表达式一般使用r字符串
2.正则符号
第一类符号:匹配类符号
# 1)普通符号 - 在正则表达式中表符号本身的符号
result = fullmatch(r'abc', 'abc')
print(result)
# 2). - 匹配任意一个字符
result = fullmatch(r'.bc', '*bc')
print(result)result = fullmatch(r'.bc.', '1bcu')
print(result)
# 3)\d - 匹配任意一个数字字符
result = fullmatch(r'\d\dabc', '08abc')
print(result)
# 4)\s - 匹配任意一个空白字符
# 空白字符:空格(' ')、换行('\n')、水平制表符('\t')
result = fullmatch(r'123\sabc', '123\tabc')
print(result)result = fullmatch(r'\d\d\s\d', '89 2')
print(result)
# 5)\w - 匹配任意一个字母、数字、下划线或者中文
result = fullmatch(r'abc\w123', 'abc和123')
print(result)
# 6)\D、\S、\W - 分别和\d、\s、\w的功能相反
result = fullmatch(r'abc\D123', 'abc8123')
print(result) # None
# 7)[字符集] - 匹配在字符集中的任意一个字符
"""
[abc] - 匹配a或者b或者c
[abc\d] - 匹配a或者b或者c或者任意数字: [abc0123456789]
[1-5] - 匹配字符1到字符5中的任意一个字符
[a-z] - 匹配任意一个小写字母
[A-Z] - 匹配任意一个大写字母
[a-zA-Z] - 匹配任意一个字母
[a-zA-Z\d] - 匹配任意一个字母或者数字
[a-z=%] - 匹配任意一个小写字母或者=或者%
[\u4e00-\u9fa5] - 匹配任意一个中文
"""
result = fullmatch(r'abc[M9你]123', 'abc你123')
print(result)result = fullmatch(r'abc[M9你\d]123', 'abc0123')
print(result)result = fullmatch(r'abc[\u4e00-\u9fa5]123', 'abc和123')
print(result)
# 8)[^字符集] - 匹配不在字符集中的任意一个字符
result = fullmatch(r'abc[^MN]123', 'abc)123')
print(result)result = fullmatch(r'abc[^a-z]123', 'abc$123')
print(result)result = fullmatch(r'abc[M^N]123', 'abcM123')
print(result)
第二类符号:匹配次数符号
# 1)* - 任意次数(0次或者1次或者次数)
"""
a* - a出现任意多次
\d* - 任意多个任意数字
[abc]*
"""
result = fullmatch(r'1a*2', '1aaaaaaaa2')
print(result)result = fullmatch(r'M\d*N', 'M13599N')
print(result)result = fullmatch(r'M[3-9]*N', 'M3489N')
print(result)
# 2)+ - 一次或者多次(至少1次)
result = fullmatch(r'1a+2', '1aaa2')
print(result)
# 3) ? - 0次或者1次
result = fullmatch(r'1a?2', '1aa2')
print(result) # None
# 4){}
"""
{N} - N次
{M,N} - M到N次
{M,} - 至少M次
{,N} - 最多N次
"""
result = fullmatch(r'1a{3}2', '1aaa2')
print(result)result = fullmatch(r'1a{3,6}2', '1aaaa2')
print(result)
# 练习:写一个正则表达式,可以匹配任意一个除了0的整数。
# 合法:233、+234、-7283、100、-2000
# 不合法:0、0002、2.23、+-200
result = fullmatch(r'[+-]?[1-9]\d*', '2000')
print(result)
# 5)贪婪和非贪婪模式
"""
在匹配次数不确定的时候,如果有多种次数都可以匹配成功,贪婪取最多的那个次数,非贪婪取最少的那个次数。(默认是贪婪模式)
贪婪模式:+、?、*、{M,N}、{M,}、{,N}
非贪婪模式:+?、??、*?、{M,N}?、{M,}?、{,N}?
"""
# 'ahkmb'、'ahkmb收拾b'、'ahkmb收拾b收b'
result = search(r'a.+b', '收拾收拾收ahkmb收拾b收b3]er2')
print(result) # <re.Match object; span=(5, 15), match='ahkmb收拾b收b'>result = search(r'a.+?b', '收拾收拾收ahkmb收拾b收b3]er2')
print(result) # <re.Match object; span=(5, 10), match='ahkmb'># 'ahkmb'
result = search(r'a.+b', '收拾收拾收ahkmb3]er2')
print(result) # <re.Match object; span=(5, 10), match='ahkmb'>result = search(r'a.+?b', '收拾收拾收ahkmb3]er2')
print(result) # <re.Match object; span=(5, 10), match='ahkmb'>
第三类符号:分组和分支
# 1)分组 - ()
"""
正则表达式中可以用()将部分内容括起来表示一个整体;括号括起来的部分就是一个分组。
a. 整体操作的时候需要分组
b. 重复匹配 - 正则中可以通过\M来重复它前面第M个分组匹配的结果
c. 捕获 - 提取分组匹配到的结果(捕获分为自动捕获(findall)和手动捕获)
"""
# '23M'、'89K10L'、'09H23P90Q33W'、...
result = fullmatch(r'(\d\d[A-Z])+', '09H23P90Q33W')
print(result)# '23M23'、'90K90'、'78N78'、'10U10'
result = fullmatch(r'(\d\d)[A-Z]\1', '90K90')
print(result)result = fullmatch(r'(\d{3})([a-z]{2})=\2\1{2}', '234km=km234234')
print(result)# findall在正则表达式中有分组的时候,会自动提取正则匹配结果中分组匹配到的内容
message = '技术上234,jsskf8992==技术njk==9223-ssjs233结束时间453'
result = findall(r'[\u4e00-\u9fa5](\d+)', message)
print(result)# 匹配对象.group(N) - 获取匹配结果中指定分组匹配到的内容
# 提取身高
message = '我是小明,今年23岁,身高180厘米,体重70kg'
result = search(r'身高(\d+)厘米,体重(\d+)kg', message)
print(result) # <re.Match object; span=(11, 25), match='身高180厘米,体重70kg'>
print(result.group()) # '身高180厘米,体重70kg'
print(result.group(1), result.group(2)) # 180 70
# 2)分支 - |
"""
正则1|正则2|正则3|... - 先用正则1进行匹配,匹配成功直接成功;匹配失败用正则2进行匹配,....
"""
result = fullmatch(r'\d{3}|[a-z]{2}', 'mn')
print(result)# 'abc34'、'abcKJ'、'abc78'、'abcOP'
result = fullmatch(r'abc\d\d|abc[A-Z]{2}', 'abc23')
print(result)result = fullmatch(r'abc(\d\d|[A-Z]{2})', 'abcKS')
print(result)
转义符号
在本身具有特殊功能或者特殊意义的符号前加 \ ,让特殊符号变成普通
# 匹整数部分和小数部分都是两位数的小数
result = fullmatch(r'\d\d\.\d\d', '23.45')
print(result)result = fullmatch(r'\d\+\d', '3+4')
print(result)
# '(amd)'
result = fullmatch(r'\([a-z]{3}\)', '(jsk)')
print(result)
# 注意:单独存在有特殊意义的符号,在[]中它的功能会自动消失
result = fullmatch(r'\d[+.?*()\]]\d', '3]4')
print(result)
应用
# 使用正则表达式提取top250的电影名称
import requests
from re import findall
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
response = requests.get('https://movie.douban.com/top250?start=0&filter=', headers=headers)
# print(response.text)
result = findall(r'<img width="100" alt="(.+?)"', response.text)
print(result)
# 使用正则表达式提取top250的电影详情页
import requests
from re import findall
headers={'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
response = requests.get('https://movie.douban.com/top250',headers=headers)
# print(response.text)
# result1 = findall(r'<a href="(.+?)" class="">',response.text)
result2 = findall(r'https://movie.douban.com/subject/\d+/',response.text)
print(result2)
四、re模块
from re import fullmatch, findall, search, split, sub, finditer, match
"""
1)fullmatch(正则, 字符串) - 用整个字符串和正则,匹配成功返回匹配对象,匹配失败返回None
2)findall(正则, 字符串) - 获取字符串中所有满足正则的子串,默认返回一个列表,列表中的元素是所有匹配到的子串(存在自动捕获现象)
3)search(正则, 字符串) - 匹配第一个满足正则的子串,匹配成功返回匹配对象,匹配失败返回None
4)split(正则, 字符串) - 将字符串中所有满足正则的子串作为切割点进行切割
5)split(正则, 字符串, N) - 将字符串中前N个满足正则的子串作为切割点进行切割
6)sub(正则, 字符串1, 字符串2) - 将字符串2中所有满足正则的子串都替换成字符串1
7)sub(正则, 字符串1, 字符串2, N)
8)finditer(正则, 字符串) - 获取字符串中所有满足正则的子串,返回一个迭代器,迭代器中的元素是匹配对象
9)match(正则, 字符串) - 匹配字符串开头
"""
str1 = '技术7晋级赛7jsks7就开始看'
print(str1.split('7', 2))str1 = '技术22晋级赛709jsks511就开始80看'
print(split(r'\d+', str1, 2))str1 = '技术22晋级赛709jsks511就开始80看'
print(sub(r'\d', '+', str1))message = '妈的,SB,都打起来了你还在打野!草!F u c k'
print(sub(r'(?i)妈的|sb|草|操|艹|f\s*u\s*c\s*k', '*', message))str1 = '技术22晋级赛709jsks511就开始80看'
result = finditer(r'\d+', str1)
print(list(result))print(fullmatch(r'\d{3}', '234'))
print(match(r'\d{3}', '234卡咖啡'))
1)忽略大小写: (?i)
print(fullmatch(r'(?i)abc', 'abc'))
print(fullmatch(r'(?i)abc', 'Abc'))
print(fullmatch(r'(?i)abc', 'ABc'))
print(fullmatch(r'(?i)abc', 'aBc'))
2)单行匹配:(?s)
# 多行匹配(默认):. 不能和换行符进行匹配
# 单行匹配:. 可以和换行符进行匹配
print(fullmatch(r'abc.123', 'abc\n123')) # None
print(fullmatch(r'(?s)abc.123', 'abc\n123')) # <re.Match object; span=(0, 7), match='abc\n123'>msg = """
'name:"jshf2-
2ss技术"'
"""
result = findall(r'(?s)name:"(.+)"', msg)
print(result)
相关文章:

爬虫Day2 正则表达式
爬虫Day2 正则表达式 一、正则表达式 1. 正则的作用 正则表达式是一种可以让复杂的字符串变得简单的工具。 写正则表达式就是用正则符号来描述字符串规则 # 案例1:判断一个字符串是否是一个合法的手机号码 tel 23297293329# 方法1:不用正则 if len…...

LeetCode-0324~28
leetCode1032 思路:想的是维护一个后缀数组,然后用Set去判断一下,结果超时了,去看题解,好家伙AC自动机,没办法,开始学。 正确题解: class ACNode{public ACNode[] children;publi…...
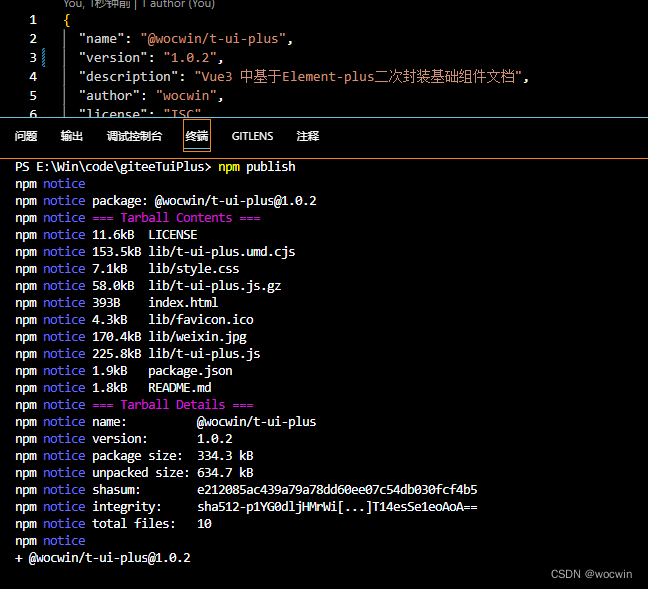
Vue2自己封装的基础组件库或基于Element-ui再次封装的基础组件库,如何发布到npm并使用(支持全局或按需引入使用),超详细
最终效果如下 一、先创建vue2项目 1、 可以用vue-cli自己来创建;也可以直接使用我开源常规的vue2后台管理系统模板 以下我以 wocwin-admin-vue2 项目为例 修改目录结构,最终如下 2、修改vue.config.js文件 module.exports { // 修改 src 目录 为 exam…...

【开发】中间件——MongoDB
MongoDB是一个基于分布式(海量数据存储)文件存储的数据库。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的,它支持的数据结构非常松散,是类似json…...
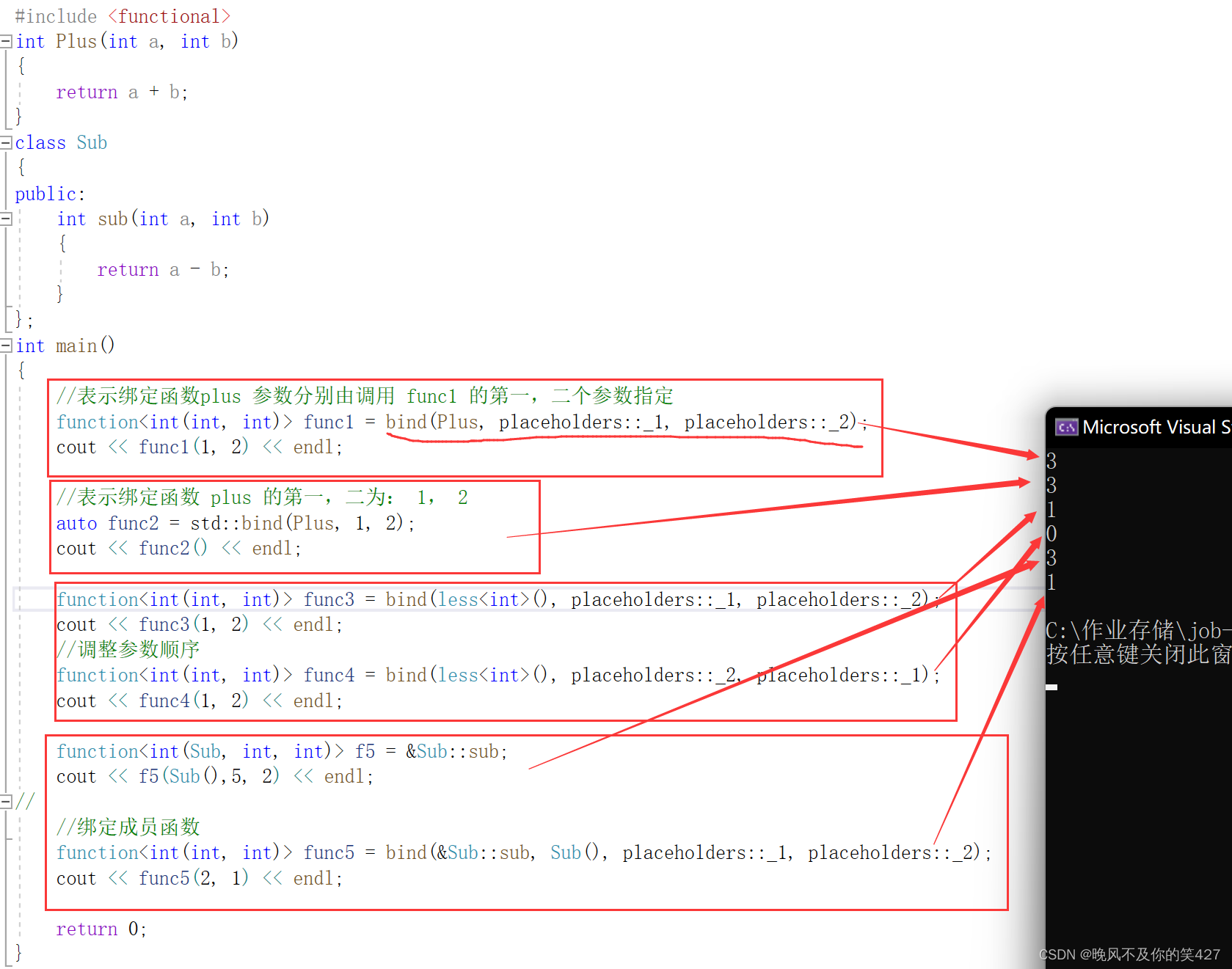
C++进阶 — 【C++11】
目录 一、 C11简介 二、 统一的列表初始化 1.{}初始化 2. initializer_list 三、声明 1. auto 2. decltype 3. nullptr 四、范围for循环 五、STL中一些变化 1. 提供了一些新容器 2.容器中增加了一些新方法 六、右值引用和移动语义 1. 左值引用和右…...

Mac安装Homebrew
1.前往Homebrew官网,复制官网的安装命令 https://brew.sh/ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"安装结束后,记得仔细看脚本执行最后的提示,需要我们复制两行命令执…...
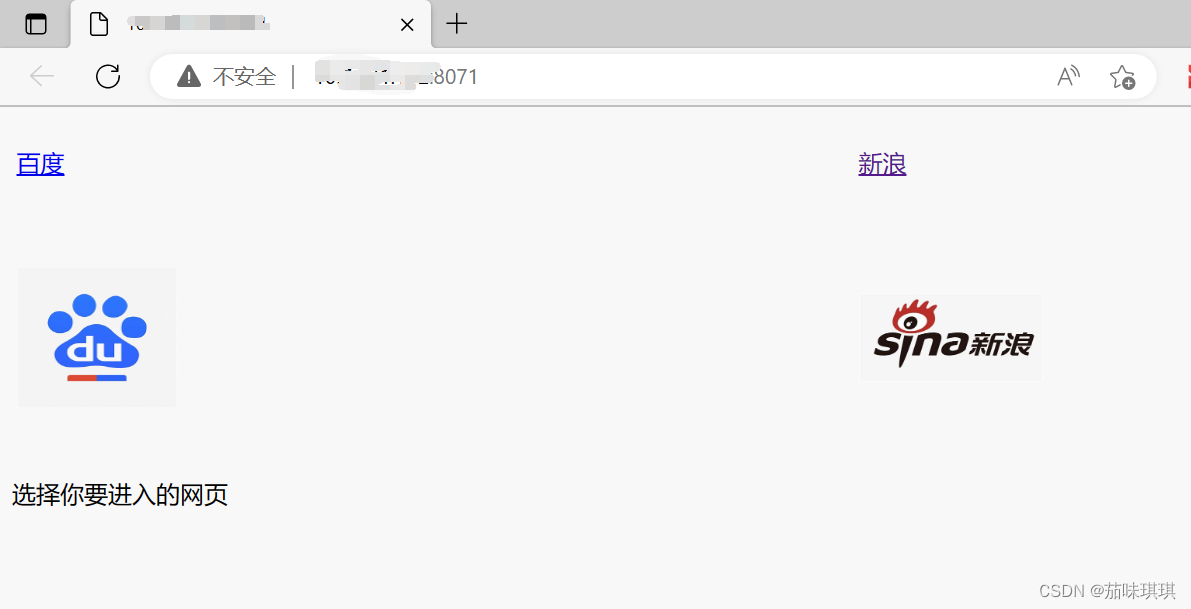
【详细】利用VS2019创建Web项目,并发送到IIS,以及IIS与ASP.NET配置
一、打开VS2019选择创建新项目【最好以管理员身份运行VS2019,后面发布网站时需要以管理员身份,避免后面还要重启,可以一开始就以管理员身份运行】 二、选择语言为C#,然后选择“ASP.NET Web应用程序(.NET Framework&…...

FasterRcnn,Yolov2,Yolov3中的Label Assignment机制 和 ATSS
一般把anchor到gt之间如何匹配的方法称为label assignment,也就是给预设的anchor打上正负样本等标签,方便我们后续进一步回归。 其实RPN和Yolo有各自的label assignment方法, 在Faster rcnn,yolo,RetinaNet中…...

使用Java技术WebSocket创建聊天、群聊,实现好友列表,添加好友,好友分组,聊天记录查询功能。
文章目录 引入依赖主要代码配置WebSocket创建通讯完整后台项目代码下载WebSocket的由来: 之前只有一个http协议,http协议是请求响应,存在缺陷,就是请求只能由客户端发起,然后请求到服务器,服务器做响应,但是如果服务器状态做了改变,客户端并不能即使的更新,之前的是按照…...

【Redis07】Redis基础:Bitmap 与 HyperLogLog 相关操作
Redis基础学习:Bitmap 与 HyperLogLog 相关操作继续进行 Redis 基础部分的学习,今天我们学习的是两种另外的数据类型。说是数据类型,但其实它们实际上使用的都是 String 类型做为底层基础,只不过是在存储的时候进行了一些特殊的操…...

华为路由器 VRRP主备配置
组网需求 如下图所示,PC1通过SW1双归属到R1和R2。为保证用户的各种业务在网络传输中不中断,需在R1和R2上配置VRRP主备备份功能。 正常情况下,主机以R1为默认网关接入Internet,当R1故障时,R2接替R1作为网关继续进行工作…...

docker容器安装ES
1.拉取镜像 docker pull elasticsearch:6.5.42.修改别名 docker tag [容器ID] es65:6.5.42.启动应用 docker run -it -d -p 9200:9200 -p 9300:9300 --name es -e ES_JAVA_OPTS"-Xms128m -Xmx128m" es65:6.5.43.拷贝配置文件到宿主机 docker cp es:/usr/share/ela…...

Python Module — prompt_toolkit CLI 库
目录 文章目录目录prompt_toolkit示例化历史记录热键自动补全多行输入Python 代码高亮自定义样式prompt_toolkit prompt_toolkit 是一个用于构建 CLI 应用程序的 Python 库,可以让我们轻松地构建强大的交互式命令行应用程序。 自动补全:当用户输入命令…...

springboot mybatis-plus 调用 sqlserver 的 存储过程 返回值问题
问题: 在使用 mybatis-plus 调用sqlserver 存储过程 没有返回值 经过资料查找 注意点 此处使用Map传参,原因在于存储过程的返回值,通常在参数定义中实现,如In 入参、out 出参。 这样当执行后有结果返回时,则可以将结…...
)
【0180】PG内核读取pg_hba.conf并创建HbaLine记录(1)
文章目录 1. pg_hba.conf文件是什么?2. postmaster何时读取pg_hba.conf?2.1 pg内核使用pg_hba.conf完成客户端认证的原理2.2 读取pg_hba.conf的几个模块3. pg内核读取pg_hba.conf过程3.1 VFD机制获取文件描述符3.2 根据fd读取文件内容相关阅读: 【0178】DBeaver、pgAdmin I…...

【原型设计工具】上海道宁为您提供Justinmind,助力您在几分钟内形成原型,并现场测试,无需编写任何代码
Justinmind是用于 Web和应用程序的原型制作工具 在几分钟内形成原型 并在现场进行测试 无需编写任何代码 单击一下即可轻松在线获取您的设计 并与整个团队共享 享受高效的沟通和快速反馈 以实现持续改进和利益相关者的支持 开发商介绍 JustinMind是由西班牙JustinMind公…...

计算机网络中---HDLP协议和PPP协议
目录 HDLC协议PPP协议HDLC协议和PPP协议HDLC协议 HDLC协议【高级数据链路控制协议】是一种数据链路层协议,用于在两个节点之间传输数据。以下是HDLC协议的重点知识: HDLC协议定义了一种标准的帧格式,包括起始标志、地址字段、控制字段、信息字段、校验字段和结束标志。HDLC…...

k8s之节点kubelet预留资源配置
k8s之kubelet预留资源配置1 前言2 预留资源Kube-reservedSystem-reservedEviction Thresholds实施节点可分配约束3 Pod优先级4 生产应用配置文件重启kubelet服务查看节点资源1 前言 最近k8s在使用过程中遇到这样一个问题 由于Pod没有对内存及CPU进行限制,导致Pod在…...
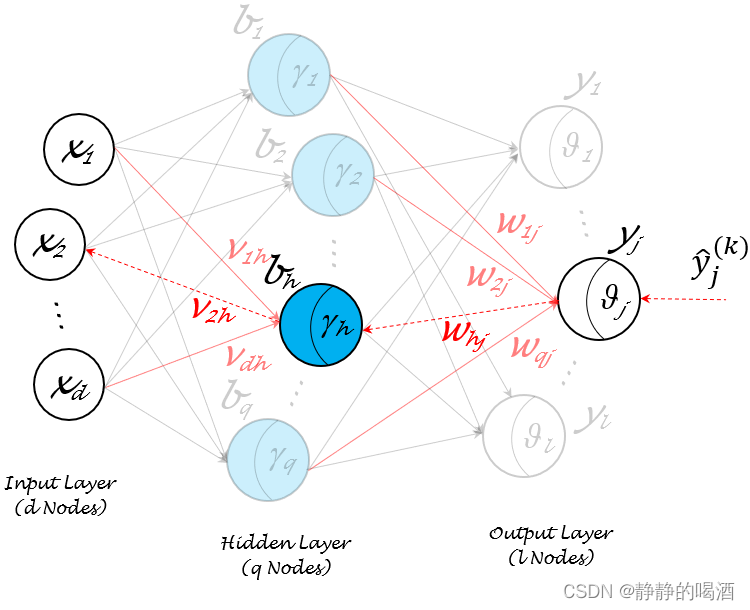
机器学习笔记之前馈神经网络(四)反向传播算法[数学推导过程]
机器学习笔记之前馈神经网络——反向传播算法[数学推导过程]引言回顾:感知机算法非线性问题与多层感知机反向传播算法(BackPropagation,BP\text{BackPropagation,BP}BackPropagation,BP)场景构建求解各权重更新量图示描述反向传播过程总结引言 上一节介绍了M-P\tex…...

vscode+elementui校园跑腿系统 nodejs+vue
本系统从用户的角度出发,结合当前的校园环境而开发的,在开发语言上是使用的Java语言,在框架上我们是使用的Vue框架,数据库方面使用的是MySQL数据库,开发工具为IDEA。 基于Vue的校园跑腿管理系统中的管理员配送用户都可…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...