OCR之论文笔记TrOCR
文章目录
- TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
- 一. 简介
- 二. TrOCR
- 2.1. Encoder
- 2.2 Decoder
- 2.3 Model Initialiaztion
- 2.4 Task Pipeline
- 2.5 Pre-training
- 2.6 Fine-tuning
- 2.7 Data Augmentation
- 三. 实验
- 3.1 Data
- 3.2 Settings
- 3.2 Results
- 3.2.1 Architecture Comparison
- 3.2.2 Ablation Experiment
- 3.2.3 SROIE Task 2
- 3.2.4 IAM Handwriting Database
- 3.2.5 Scene Text Recognition
- 3.2.6 Inference Speed
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
一. 简介
发表:CVPR2022
机构:微软
代码:https://github.com/microsoft/unilm/tree/master/trocr
摘要:
Text recognition is a long standing-research problem for document digitalization. Existing approaches are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post- processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on the printed, handwritten and scene text recognition tasks. The TrOCR models and code are publicly available at https://aka.ms/trocr.
Motivation:
现有的OCR方法往往基于 CNN + RNN的范式来进行建模,前者进行图像理解,后者用于字符级别的文本生成。除此之外,往往额外用一个语言模型来后处理,提高识别的准确率。本文,提出一种基于transformer的文本识别框架,将文本和图像都用transformer来建模,并且可以先在大规模人造数据上预训练,,再在人工标注的数据集上finetune。实验表明,TrOCR可以在印刷,手写和场景文本识别任务中,取得SOTA的结果。
二. TrOCR

Encoder: ViT-style models
Decoder: BERT-style models
2.1. Encoder
Encoder的输入是固定尺寸(论文中是384 * 384),并且将其分解为 N 个patches,N=HW/P2N = HW / P ^2N=HW/P2,每个patch的尺寸是P∗PP * PP∗P,论文中N = 24 * 24,即每个patch的尺寸是16∗1616 * 1616∗16。然后将patch展平,过全连接,映射到D维。D就是transformer里面所有层的hidden size,默认是768。
与ViT和DeIT一样,保留了【CLS】这个特殊的token,用于图像分类任务。可以视作图像的全局特征。文中,还提到保留一种特殊的token,叫做distilation token,能够允许模型向教师模型学习。这两个特殊的token以及patches,会根据绝对位置被分配一个可以学习的位置编码(position embedding)。
Unlike the features extracted by the CNN-like network, the Transformer models have no image-specific inductive biases and process the image as a sequence of patches, which makes the model easier to pay different attention to either the whole image or the independent patches.
如何理解上面所说的归纳偏差:
CNN和Transformer是两种用于图像处理和计算机视觉任务的神经网络架构,它们在图像特定归纳偏差方面存在一些不同。
对于CNN来说,它的图像特定归纳偏差主要是基于卷积和池化操作。CNN中的卷积层通过局部感受野的方式捕捉图像的空间特征,并通过权值共享来减少参数数量。池化层则通过对特征图进行下采样来降低维度,从而提高网络的鲁棒性和计算效率。此外,CNN中的网络结构通常是层叠的,且特征图的通道数会随着网络的深度增加而增加,这些设计都是为了更好地适应图像数据的特征和结构。
相比之下,Transformer的图像特定归纳偏差主要是基于注意力机制。在Transformer中,注意力机制被用于在不同位置之间建立关联,从而能够处理不同尺度和分辨率的图像。通过自注意力机制,Transformer可以在不丢失空间信息的情况下,将图像编码成全局的特征向量。此外,Transformer的网络结构是基于自注意力层和全连接层的堆叠,这种结构可以处理变长的序列数据,因此在文本和语言等任务中也被广泛应用。
2.2 Decoder
decoder和encoder一样,也是标准的stack of identical layers的结构,有一点不同之处在于,decoder在multi-head self attetion和feed forward network之间插入了“ encoder-decoder attention",用于对encoder的输出分配不同的注意力。
在这个encoder-decoder attention中,K和V都来自encoder的输出,Q来自decoder的输入。除此之外,decoder在self attention中利用了attention masking,来防止它在训练过程中看到更多的信息,即,decoder的输出相较于decoder的输入员,往往会right shift一个位置,所以attention mask需要保证第i个位置的输出只能pay attention到之前的输出,即<i的这些位置。
decoder的hidden states然后会映射到V这个维度,其中V是词表的大小,然后用softmax来归一化,得到该hidden state输出各个字符的概率,并且用beam search来得到最终的输出。
2.3 Model Initialiaztion
- encoder initialiaztion
用DeiT和BeiT来初始化encoder。DeiT用ImageNet来训练,原始论文作者尝试不同的超参数和数据增强的方式,来使得数据更有效,除此之外,它们从一个非常强的图像分类器中提取知识到distilled token。而BeiT,借鉴MLM预训练任务,提出Mask Image Model任务来预训练image transformer。具体而言,每张图像,可以被视作两种view,image patches和visual tokens。用discreate VAE来将原始的图像转化为visual tokens,并且随机mask掉图像的patches,然后让模型进行复原原始的visual tokens。BeiT的图像transformer结果和DeiT一致,只不过是少了distilled token。 - decoder initialiaztion
用RoBERTa以及MiniLM来初始化decoder,前者是在bert的基础上,探索了许多关键超参数和训练数据规模的影响,并且去除了next sentence prediction任务,而且动态改变了MLM里面的masking pattern。MiniLM是大预训练模型的压缩版,然而保留了99%的模型能力,除了在MLM中用到soft target probs和蒸馏学习之外,来引入一个教师助教,来辅助蒸馏。
但是直接加载上面两个模型到decoder有一些问题,因为encoder-decoder attention layers在原始模型中是没有的,因此采用的策略是,decoder相应的参数用RoBERTa和MiniLM来初始化,缺失的参数,随机初始化。
2.4 Task Pipeline
在trocr中,文本识别任务被定义为这样的pipeline,对于输入的文本行图像,模型提出视觉特征,并且基于图像和之前产生的上下文来预测wordpiece的tokens。gt往往用【EOS】token来标识一个句子的结束。在训练的时候往往会在开头添加一个【BOS】的token来标识生成的开始,并达到shift one placed的效果。这个shifted的gt sequence会被输入decoder,它对应位置的输出被与gt sequence的交叉墒来监督。在inference的时候,decoder从【BOS】开始迭代预测,并且将产生的输出作为下一步的输入。
2.5 Pre-training
基于文本识别任务来进行预训练,分为两个阶段
- 第一阶段:构造了上亿(hundreds of million)的印刷体文本行图像,并且用trocr在这上面预训练。
- 第二阶段:构造了两个相对小一点的印刷体和手写体数据集,规模是百万级别,并且在场景文本识别任务上,用了现有的广泛使用的synthetic数据集。
疑问?
是分别预训练图像encoder以及文本decoder吗?
2.6 Fine-tuning
除了场景文本识别之外,预训练的trocr的模型,在其他下游文本识别任务中finetune。trocr的输出是基于Byte Pair Encoding (BPE)以及SentencePiece,而且不依赖于其他任何与任务无关的词表。
Byte Pair Encoding (BPE)是一种基于统计的无损数据压缩算法,它也被广泛用于自然语言处理领域中的文本编码和词汇表示。
BPE的基本思想是将文本编码成一个固定大小的词汇表。它通过迭代地合并词汇表中出现频率最高的相邻字符或字符对,来不断增加词汇表的大小,直到达到预设的大小或满足停止条件为止。在每次迭代中,BPE会计算所有相邻字符或字符对的出现频率,然后将出现频率最高的字符或字符对合并成一个新的字符,并将其添加到词汇表中。这个过程会不断重复,直到词汇表达到预设大小或者满足停止条件。
通过这种方式,BPE可以生成一个小而紧凑的词汇表,并将文本编码为由词汇表中的字符或字符对组成的符号串。在自然语言处理中,BPE常用于生成单词分段(subword segmentation),即将单词分成更小的子单元,以便于语言模型处理生僻单词、未登录词和低频词等情况。在神经机器翻译和文本生成等任务中,使用BPE编码的文本能够更好地适应不同语言的语言特点,从而提高模型的性能。
Byte Pair Encoding(BPE)和SentencePiece都是常用于文本编码和词汇表示的算法,它们的主要区别在于以下几个方面:
算法原理:BPE是一种基于贪心算法的数据压缩算法,它通过反复合并出现频率最高的字符或字符对来构建词汇表。而SentencePiece则是基于Unigram语言模型的,它使用马尔可夫模型来学习词汇表中每个子词的概率,然后根据概率来进行分割。
应用场景:BPE主要应用于分词和子词划分等任务,而SentencePiece除了分词和子词划分外,还可以用于语音识别、OCR等领域。SentencePiece还支持多种分词算法,包括BPE、Unigram语言模型、WordPiece等。
实现方式:BPE和SentencePiece都有多种不同的实现方式,包括基于C++、Python、Java等语言的实现。其中,SentencePiece在Google的开源机器翻译框架TensorFlow和PyTorch中都有支持。
总体而言,BPE和SentencePiece都是用于文本编码和词汇表示的常用算法,具体使用哪种算法取决于具体的任务需求和数据特点。
2.7 Data Augmentation
六种数据增强策略被用到预训练和finetune的数据当中,随机旋转 (-10,10)度,高斯模糊,图像膨胀,图像腐蚀,下采样,下划线。对于每一个样本而言,各个增强方式以一种相同的概率被随机选择。对于场景文本识别数据集,用了之前文献的RandAug方法,其中的数据增强方式包括:inversion,扭曲,模糊,噪声,distoration,旋转等。
三. 实验
3.1 Data
预训练数据集
将publily available的pdf转化为图像,并获得印刷体文本行的小图,总计684M。
通过TRDG开源库,来将5,427种手写体字体来构造手写数据集,其中语料是随机抓去自wiki,所以第二阶段的手写体预训练数据集的最终规模是17.9M,并且包括IIIT-HWS数据集。除此之外,收集了53K的真实票据数据,并用商用的OCR识别软件进行识别。也用TRDG构造了1M印刷体票据数据,对于场景文本识别而言,第二阶段预训练用到的数据集是MJSynth (MJ)和SynthText (ST),总计16M文本图像。
字体:
https://fonts.google.com/?category=Handwriting
https:// www.1001fonts.com/handwritten- fonts.html
渲染工程:
https://github.com/Belval/TextRecognitionDataGenerator
Benchmarks
票据识别:SROIE (Scanned Receipts OCR and In- formation Extraction) dataset (Task 2) focuses on text recognition in receipt images. There are 626 receipt images and 361 receipt images in the training and test sets of SROIE.
手写识别:The IAM Handwriting Database is composed of hand- written English text, which is the most popular dataset for handwritten text recognition. We use the Aachen’s partition of the dataset3: 6,161 lines from 747 forms in the train set, 966 lines from 115 forms in the validation set and 2,915 lines from 336 forms in the test set.
场景文本识别:IIIT5K-3000, SVT-647, IC13-857, IC13-1015 , IC15-1811, IC15-2077, SVTP-645 , and CT80-288。
3.2 Settings
TrOCR是基于Fairseq工具来写的,对于model初始化这一块,DeiT来自timm库,而BEiT和MiniLM来自微软的UniLM库,RoBERTa来自fairseq库。32张V100(32GBs)预训练,8张V100来finetune。
batch_size: 2048
learning rate: 5e-5
384 * 384输入,16 * 16 patches。
The DeiTSMALL has 12 layers with 384 hidden sizes and 6 heads. Both the DeiTBASE and the BEiTBASE have 12 layers with 768 hidden sizes and 12 heads while the BEiTLARGE has 24 layers with 1024 hidden sizes and 16 heads. We use 6 layers, 256 hidden sizes and 8 attention heads for the small decoders, 512 hidden sizes for the base decoders and 12 layers, 1,024 hidden sizes and 16 heads for the large decoders.
beam size : 10
CRNN作为baseline对比:https://github.com/meijieru/crnn.pytorch
评价指标:
word-level pre- cision, recall and f1 score.
Character Error Rate (CER)
Word Accuracy
3.2 Results
3.2.1 Architecture Comparison

选择不同的encoder和decoder的组合,可以发现BeiT在encoder中表现最好,其次DeiT,再之后是resnet50
decoder的话,是roberta large表现最好。
TrOCRSMALL (total parameters=62M) consists of the encoder of DeiT SMALL and the decoder of MiniLM,
TrOCRBASE (total parameters=334M) consists of the en- coder of BEiT BASE and the decoder of RoBERTa LARGE
TrOCRLARGE (total parameters=558M) consists of the en- coder of BEiT LARGE and the decoder of RoBERTa LARGE.
3.2.2 Ablation Experiment

疑问?
from scratch 这么低是什么原因?
3.2.3 SROIE Task 2
https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=2
 与cnn + rnn的一些方法进行对比
与cnn + rnn的一些方法进行对比
3.2.4 IAM Handwriting Database

3.2.5 Scene Text Recognition

3.2.6 Inference Speed

相关文章:
OCR之论文笔记TrOCR
文章目录TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models一. 简介二. TrOCR2.1. Encoder2.2 Decoder2.3 Model Initialiaztion2.4 Task Pipeline2.5 Pre-training2.6 Fine-tuning2.7 Data Augmentation三. 实验3.1 Data3.2 Settings3.2 Resul…...
雷电4模拟器安装xposed框架(2022年)
别问我都2202年了为什么还在用雷电4安卓7。我特么哪知道Xposed的相关资料这么难找啊,只能搜到一些老旧的资料,尝试在老旧的平台上实现了。 最初的Xposed框架现在已经停止更新了,只支持到安卓8。如果要在更高版本的安卓系统上使用Xposed得看看…...
微信小程序支付完整流程(前端)
微信小程序中,常见付款给商家的场景,下面列出企业小程序中,从0起步完整微信支付流程。 一,注册微信支付商户号(由上级或法人注册) 接入微信支付 - 微信商户平台 此商户号,需要由主管及更上级领导…...
设置鼠标右键打开方式,添加IDEA的打开方式
一、问题描述 已下载IDEA,但是右键打开之前保存的项目文件,无法显示以IDEA方式打开。 二、解决步骤 1. 打开注册表 winR键输入regedit 2、查找路径为计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Classes\Directory\shell (我找了半天没看到Class…...
LAMP架构之zabbix监控(2):zabbix基础操作
目录 一、zabbix监控节点添加和删除 (1)手动添加 (2)自动添加 (3)按照条件批量添加 (4)使用api工具进行管理 二、针对应用的zabbix监控 一、zabbix监控节点添加和删除 实验说明&a…...
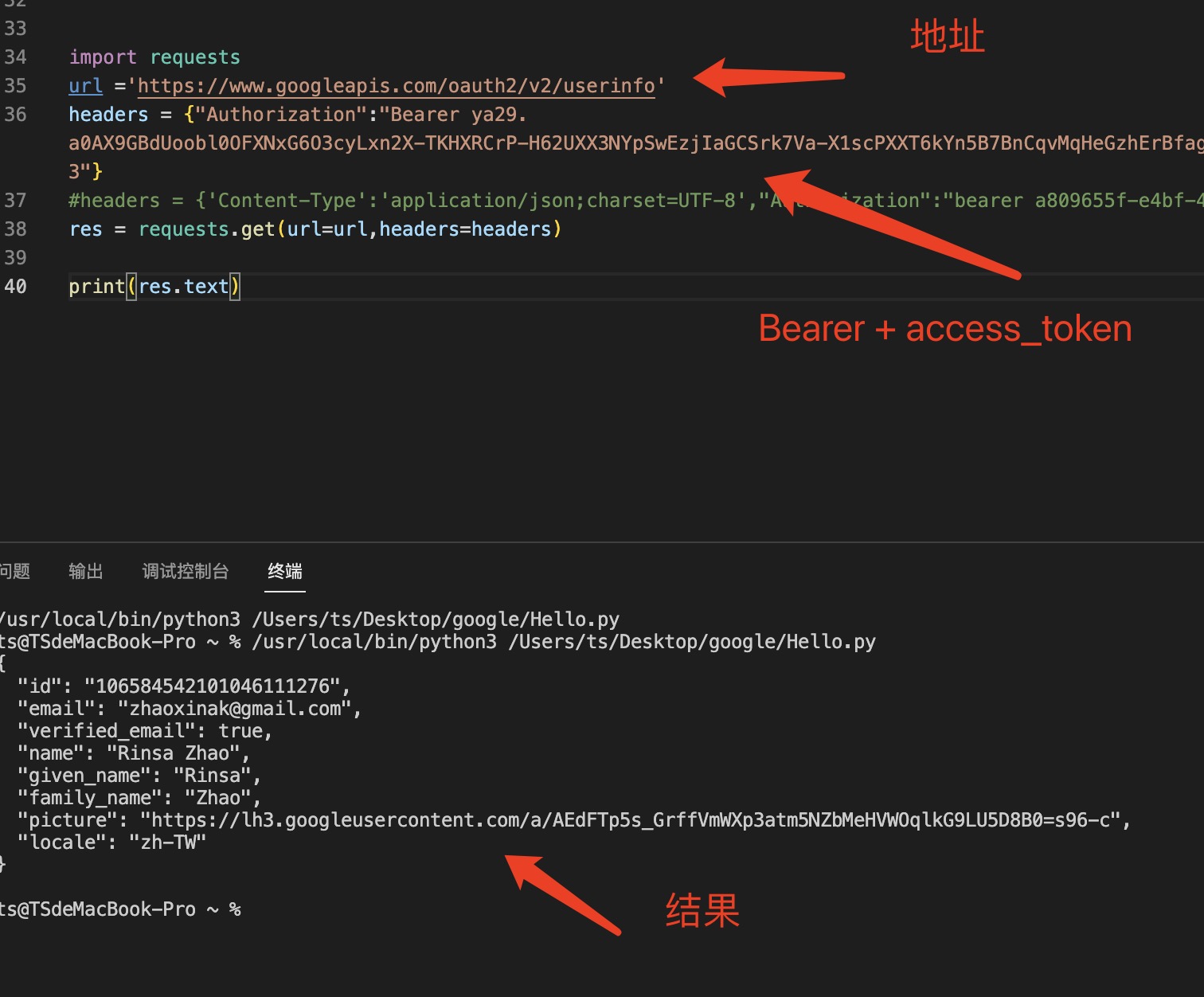
ShareSDK常见问题
QQ-分享报错901111,9001010等 由于QQ现在需要审核后才可以分享(之前分享不需要审核),所以此错误解决方法只需通过腾讯开放平台的审核即可,另外要检查注册好的应用的基本信息,包名、md5签名和Bundle id是不…...

[Spring]一文明白IOC容器和思想
✅作者简介:大家好,我是Philosophy7?让我们一起共同进步吧!🏆 📃个人主页:Philosophy7的csdn博客 🔥系列专栏: 数据结构与算法 👑哲学语录: 承认自己的无知,乃…...

程序人生 | 与足球共舞的火柴人(致敬格拉利什,赋予足球更深的意义)
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,也会涉及到服务端 📃个人状态: 在校大学生一枚,已拿多个前端 offer(秋招) 🚀未…...
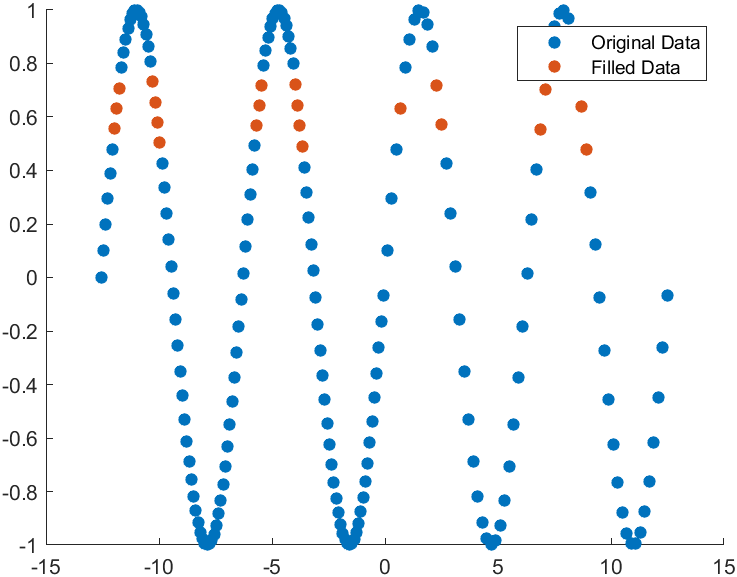
MATLAB | R2023a更新了哪些好玩的东西
R2023a来啦!!废话不多说看看新版本有啥有趣的玩意和好玩的特性叭!!把绘图放最前面叭,有图的内容看的人多。。 1 区域填充 可以使用xregion及yregion进行区域填充啦!! x -10:0.25:10; y x.^…...

Python Module — OpenAI ChatGPT API
目录 文章目录目录OpenAI Python SDKopenai.ChatCompletion 模块openai.ChatCompletion.create 函数OpenAI Python SDK 官方文档:https://platform.openai.com/docs/api-reference/introduction OpenAI Python SDK 用于开发与 OpenAI RESTful API 进行交互的客户端…...

Docker学习记录
阅读前请看一下:我是一个热衷于记录的人,每次写博客会反复研读,尽量不断提升博客质量。文章设置为仅粉丝可见,是因为写博客确实花了不少精力。希望互相进步谢谢!! 文章目录阅读前请看一下:我是一…...

Linux-VIM使用
文章目录前言VIM使用1、切换模式2、跳转(1) 跳转到指定行(2) 跳转到首行(3) 跳转到末行3、自动格式化程序4. 大括号对应5. 删除(1)删除一个单词(2)删除光标位置至行尾(3)删除光标位置至行首(4&a…...

Windows安全中心内存完整性无法打开问题的处理方法
Windows11安全中心内存完整性无法打开 今天电脑使用过程中突然看到系统桌面右下角任务栏中 windows安全中心图标出现了警告信息,如下图红框所示: 点击该图标进入windows安全中心的 安全性概览 界面,如下图: 在该界面可以看到出现安…...

在芯片设计行业,从项目的初期到交付,不同的岗位的工程师主要负责什么?
大家都知道在芯片设计行业,项目是至关重要的一环。从项目的初期到交付,不同的岗位的工程师在项目的各环节主要负责什么?他们是怎样配合的?下面看看资深工程师怎么说。 一个项目,从初期到交付的过程是比较漫长的。我们知道最早的时候&#…...

Spring Cloud Alibaba全家桶(七)——Sentinel控制台规则配置
前言 本文小新为大家带来 Sentinel控制台规则配置 相关知识,具体内容包括流控规则(包括:QPS流控规则,并发线程数流控规则),BlockException统一异常处理,流控模式(包括:直…...
mysql-installer安装教程(详细图文)
目录 1.安装 2.配置系统环境变量 3.配置初始化my.ini文件 4.MySQL彻底删除 5.Navicat 安装 1.安装 先去官网下载需要的msi,在这放出官网下载地址下载地址 这里我具体以8.0.28 为安装例子,除了最新版安装界面有些变动以往的都是差不多的。 过去的版本…...

微服务架构第一阶段(nacos,gateWay,RPC)
最近在学习完 springcloud 微服务架构之后,自己用了之前的一个项目计划拆分成微服务的项目,第一阶段要求整合 nacos,RPC以及gateWay,首先来看一下几个技术组件的概念 RPC RPC 框架 —— 远程过程调用协议RPC(Remote …...
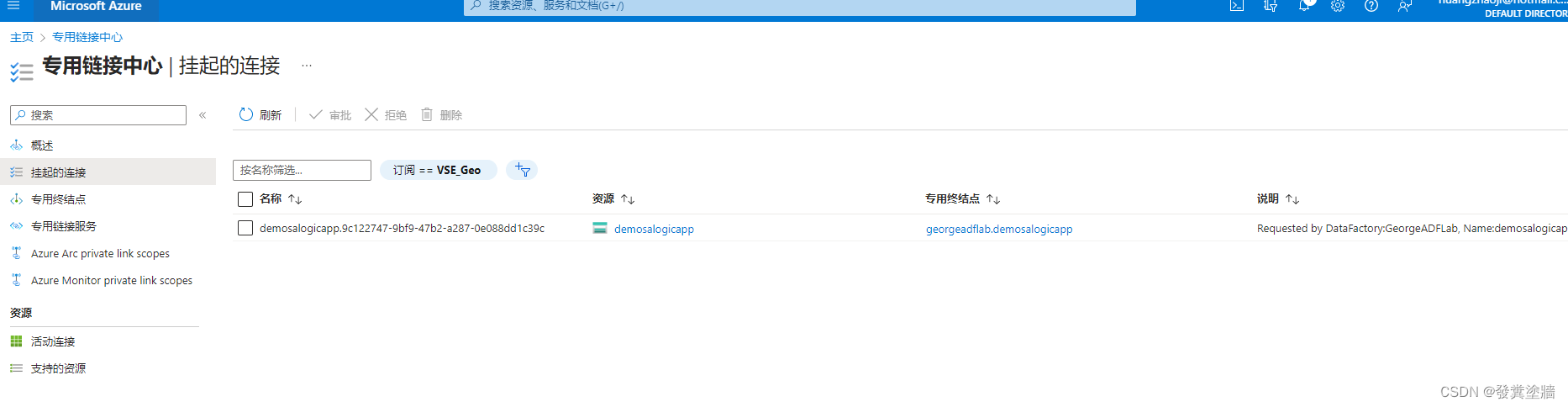
【Azure 架构师学习笔记】-Azure Data Factory (5)-Managed VNet
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Data Factory】系列。 接上文【Azure 架构师学习笔记】-Azure Data Factory (4)-触发器详解-事件触发器 前言 PaaS服务默认都经过公网传输, 这对很多企业而言并不安全,那么就需要对其进行安全改…...

ActiveMQ(三)
协议配置 ActiveMQ 支持的协议有 TCP 、 UDP、NIO、SSL、HTTP(S) 、VM 这是activemq 的activemq.xml 中配置文件设置协议的地方 <transportConnector name"openwire" uri"tcp://0.0.0.0:61616?maximumCon nections1000&wireFormat.maxFrameSiz…...

区块链多方计算 人工智能学习笔记
区块链:让数据不被篡改,但需要复制数据给每一块,造成数据泄露 多方计算 : 让数据用途可控。数控可用但不可见。 人工智能:数据更难造假 主讲人简介: 徐葳,宾夕法尼亚大学学士(在清华…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...