Pytorch :从零搭建一个神经网络
文章目录
- 安装
- 依赖
- 从源码编译pytorch
- CXX_ABI问题
- 数据集
- 归一化
- Transforms
- 搭建神经网络
- Components of a neural network
- nn.Flatten
- nn.Linear
- nn.Sequential
- nn.Softmax
- Model Parameters
- 优化模型参数
- 设置超参数
- 添加优化循环
- 添加 loss function
- 优化过程
- 完整实现
- 模型的保存和加载
安装
依赖
下载cudnn压缩包
#Unzip the cuDNN package.
$ tar -xvf cudnn-linux-x86_64-8.x.x.x_cudaX.Y-archive.tar.xz
#Copy the following files into the CUDA toolkit directory.
$ sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
$ sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
从源码编译pytorch
git clone https://github.com/pytorch/pytorch.git
cd pytorch
git checkout branchname # 切换分支
git submodule sync
git submodule update --init --recursive
conda install cmake ninja
# Run this command from the PyTorch directory after cloning the source code using the “Get the PyTorch Source“ section below
pip install -r requirements.txt
conda install mkl mkl-include
# CUDA only: Add LAPACK support for the GPU if needed
conda install -c pytorch magma-cuda110 # or the magma-cuda* that matches your CUDA version from https://anaconda.org/pytorch/repo
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
python setup.py build --cmake-only
ccmake build # or cmake-gui build
make -j${nproc}
CXX_ABI问题
查看pytorch编译使用的CXXABI
torch._C._GLIBCXX_USE_CXX11_ABI
数据集
torch.utils.data.Dataset是代表这一数据的抽象类,你可以自己定义你的数据类继承和重写这个抽象类,只需定义__len__和__getitem__这两个函数:
__len__函数返回数据集样本的数量__getitem__函数从数据集中返回给定索引idx的样本
归一化
归一化是一种常用的数据预处理技术,用于缩放或转换数据,以确保每个特征都有相同的学习贡献。
Transforms
数据并不总是以训练机器学习算法所需的最终处理形式出现。我们使用transforms来对数据进行一些操作,并使其适合训练。所有TorchVision数据集都有两个参数(tansform来修改特征和target_transform来修改标签),它们接受包含转换逻辑的可调用对象。torchvision.transforms模块提供了几个开箱即用的常用转换。
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdads = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
ToTensor将PIL image 或 NumPy ndarray 转化为FloatTensor,并且将像素值缩放到[0.,1.]区间
搭建神经网络
神经网络是由一层一层连接起来的神经元的集合。每个神经元都是一个小型计算单元,执行简单的计算,解决一个问题。它们是分层组织的。有3种类型的层:输入层,隐藏层和输出层。除了输入层,每一层都包含一些神经元。神经网络模仿人类大脑处理信息的方式。

Components of a neural network
- Activation function激活函数
决定一个神经元是否应该被激活。在神经网络中发生的计算包括应用激活函数。如果一个神经元被激活,那就意味着输入很重要。这是不同种类的激活函数。选择使用哪个激活函数取决于您想要的输出是什么。激活函数的另一个重要作用是为模型添加非线性- Binary used to set an output node to 1 if function result is positive and 0 if the function result is negative. f(x)={0,if x<01,if x≥0f(x)= {\small \begin{cases} 0, & \text{if } x < 0\\ 1, & \text{if } x\geq 0\\ \end{cases}}f(x)={0,1,if x<0if x≥0
- Sigmod is used to predict the probability of an output node being between 0 and 1. f(x)=11+e−xf(x) = {\large \frac{1}{1+e^{-x}}}f(x)=1+e−x1
- Tanh is used to predict if an output node is between 1 and -1. Used in classification use cases. f(x)=ex−e−xex+e−xf(x) = {\large \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}}f(x)=ex+e−xex−e−x
- ReLU used to set the output node to 0 if fuction result is negative and keeps the result value if the result is a positive value. f(x)={0,if x<0x,if x≥0f(x)= {\small \begin{cases} 0, & \text{if } x < 0\\ x, & \text{if } x\geq 0\\ \end{cases}}f(x)={0,x,if x<0if x≥0
- Weights权值
一层中所有神经元的权重被组织成一个张量 - Bias偏置

我们可以说,具有权重WWW和偏差bbb的神经网络层的输出y=f(x)y=f(x)y=f(x)被计算为输入的总和乘以权重加上偏差x=∑(weights∗inputs)+biasx = \sum{(weights * inputs) + bias}x=∑(weights∗inputs)+bias,其中f(x)f(x)f(x)是激活函数
nn.Flatten
nn.Flatten 将高维数据展平为一维数据
nn.Linear
线性层是一个模块,该模块使用其存储的权重和偏置在输入上应用线性转换。
nn.Sequential
nn.Sequential 是一个有顺序的模块容器
nn.Softmax
Softmax激活函数计算神经网络输出的概率。它只用于神经网络的输出层。结果被缩放为值[0,1],表示模型对每个类的预测概率。dim 参数表示结果值之和必须为维度1。

torch.nn.functional.binary_cross_entropy_with_logits二元交叉熵
loss=−(target∗log(sigmoid(input))+(1−target)∗log(1−sigmoid(input)))\rm loss = -(target * \log(sigmoid(input)) + (1 - target) * log(1 - sigmoid(input))) loss=−(target∗log(sigmoid(input))+(1−target)∗log(1−sigmoid(input)))
sigmoid()函数将输入映射到0到1之间的概率
Model Parameters
神经网络中的许多层都被参数化,即具有在训练过程中优化的相关权重和偏置。nn.module的派生类自动跟踪模型对象中定义的所有字段,并使用模型的parameter()或named_parameters()方法访问所有参数。
优化模型参数
现在我们有了模型和数据,是时候通过优化数据上的参数来训练、验证和测试我们的模型了。训练一个模型是一个迭代的过程,在每个迭代中(称为epoch)。该模型对输出进行预测,计算预测的误差(损失),收集误差对其参数的导数(正如我们在上一模块中看到的那样),并使用梯度下降优化这些参数。
设置超参数
超参数是可调整的参数,让您控制模型优化过程。不同的超参数值可能会影响模型的训练和准确性水平。
我们为训练定义了以下超参数:
- Epoch number - 整个训练数据集通过网络的次数。
- Batch size - 每个 epoch 模型看到的数据样本数量。迭代次数是完成一个 epoch 所需的批次数。
- 学习率 - 模型匹配时所采用的步长大小,以寻找能够产生更高模型准确度的最佳权重。较小的值意味着模型需要更长时间来寻找最佳权重,而较大的值可能会导致模型跳过并错过最佳权重,从而在训练期间产生不可预测的行为。
添加优化循环
一旦我们设置了超参数,我们就可以用优化循环来训练和优化我们的模型。优化循环的每个迭代称为一个epoch。
每个epoch包含两个部分:
- The Train Loop - iterate over the training dataset and try to converge to optimal parameters.
- The Validation/Test Loop - iterate over the test dataset to check if model performance is improving.
添加 loss function
当给出一些训练数据时,我们未经训练的网络可能不会给出正确的预测。
Loss function衡量预测结果与期望值的差异度,我们希望在训练阶段最小化loss function。为了计算损失,我们使用给定数据样本的输入进行预测,并将其与真实的数据标签值进行比较。
Common loss functions include:
nn.MSELoss(Mean Square Error) used for regression tasksnn.NLLLoss(Negative Log Likelihood) used for classificationnn.CrossEntropyLosscombinesnn.LogSoftmaxandnn.NLLLoss
We pass our model’s output logits to nn.CrossEntropyLoss, which will normalize the logits and compute the prediction error.
优化过程
所有优化的逻辑都被封装在optimizer对象中。提供了很多不同的优化算法,如ADAM 和 RMSProp
我们通过注册需要训练的模型参数来初始化优化器,并传入学习率超参数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
在训练循环,优化分为三步:
- 调用
optimizer.zero_grad()来初始化模型参数的梯度。梯度默认情况下是累加起来的,为了避免这种情况,我们在每次迭代显式调用归零。 - 通过调用
loss.backward()反向传播预测损失。PyTorch保存损失函数相对于每个参数的梯度 - 一旦有了梯度,调用
optimizer.step()来通过反向传播中收集的梯度来调整参数
完整实现
我们定义了根据训练数据集优化模型参数的train_loop,以及根据测试数据评估模型性能的test_loop
def train_loop(dataloader, model, loss_fn, optimizer):model.train() # sets the module in training modesize = len(dataloader.dataset)for batch, (X, y) in enumerate(dataloader): # Compute prediction and losspred = model(X)loss = loss_fn(pred, y)# Backpropagationoptimizer.zero_grad()loss.backward()optimizer.step()if batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test_loop(dataloader, model, loss_fn):model.eval() # sets the module in evaluation modesize = len(dataloader.dataset)test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= sizecorrect /= sizeprint(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
我们初始化损失函数和优化器,并将其传递给“训练循环”和“测试循环”。您可以随意增加epoch的数量,以跟踪模型不断改进的性能
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)epochs = 10
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(train_dataloader, model, loss_fn, optimizer)test_loop(test_dataloader, model, loss_fn)
print("Done!")
模型的保存和加载
参考链接
在PyTorch里面使用torch.save来保存模型的结构和参数,有两种保存方式
- 保存整个模型的结构信息和参数信息,保存的对象是模型
model - 保存模型的参数,保存的对象是模型的状态
model.state_dict()
可以这样保存,save的第一个参数是保存对象,第二个参数是保存路径及名称:
torch.save(model, './model.pth')
torch.save(model.state_dict(), './model_state.pth')
加载模型有两种方式对应于保存模型的方式:
- 加载完整的模型结构和参数信息,使用
load_model = torch.load('model.pth'),在网络较大时加载时间比较长,同时存储空间也比较大; - 加载模型的参数信息,需要先导入模型的结构,然后通过
model.load(torch.load('model_state.pth'))来导入。
model = NeuralNetwork()
model.load_state_dict(torch.load('data/model.pth'))
model.eval()
Note: Be sure to call
model.eval()method before inferencing to set the dropout and batch normalization layers to evaluation mode. Failing to do this will yield inconsistent inference results.
相关文章:
Pytorch :从零搭建一个神经网络
文章目录安装依赖从源码编译pytorchCXX_ABI问题数据集归一化Transforms搭建神经网络Components of a neural networknn.Flattennn.Linearnn.Sequentialnn.SoftmaxModel Parameters优化模型参数设置超参数添加优化循环添加 loss function优化过程完整实现模型的保存和加载安装 …...
)
【华为OD机试 2023最新 】 区块链文件转储系统(C++ 100%)
题目描述 区块链底层存储是一个链式文件系统,由顺序的N个文件组成,每个文件的大小不一,依次为F1,F2,…,Fn。随着时间的推移,所占存储会越来越大。 云平台考虑将区块链按文件转储到廉价的SATA盘,只有连续的区块链文件才能转储到SATA盘上,且转储的文件之和不能超过SATA盘…...

基于springcloud实现分布式架构网上商城演示【项目源码】分享
基于springcloud实现分布式架构网上商城演示摘要 首先,论文一开始便是清楚的论述了系统的研究内容。其次,剖析系统需求分析,弄明白“做什么”,分析包括业务分析和业务流程的分析以及用例分析,更进一步明确系统的需求。然后在明白了系统的需求基础上需要进一步地设计系统,主要包…...

【Qt】(自制类)适用于QTextCharFormat的字体选择对话框
先附上github链接:https://github.com/Ls-Jan/Qt_CharFormatDialog 主要是作为QFontDialog的平替/增强,毕竟Qt自带的字体选择器一言难尽(用过的都叹气)。 【运行界面】 【功能】 一目了然,可以选择字体,设置字号,设置…...
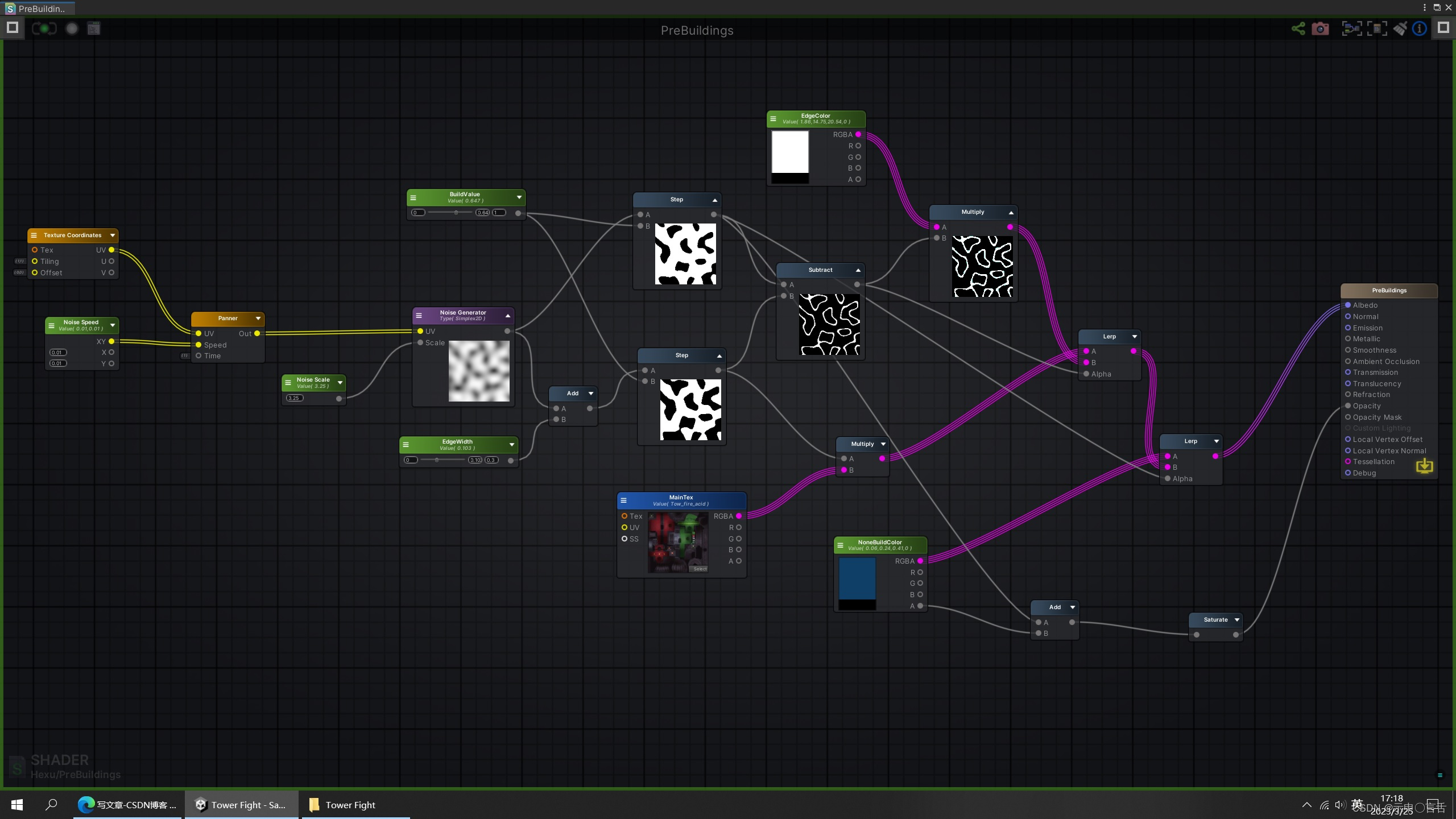
Unity即时战略/塔防项目实战(一)——构造网格建造系统
Unity即时战略/塔防项目实战(一)—— 构造网格建造系统 效果展示 Unity RTS游戏网格建造系统实现原理 地形和格子划分,建造系统BuildManager构建 地形最终需要划分成一个一个的小方格,首先定义一下小方格: private…...
)
【ZOJ 1095】Humble Numbers 题解(动态规划)
一个素数只有2,3,5或7的数被称为谦逊数。序列1、2、3、4、5、6、7、8、9、10、12、14、15、16、18、20、21、24、25、27。。。显示了前20个不起眼的数字。 编写一个程序来查找并打印此序列中的第n个元素。 输入规范 输入由一个或多个测试用例组成。每个…...

百科媒体背书,什么媒体的收录可以修改百科?
传媒如春雨,润物细无声,大家好 大家都知道百科在百度搜索引擎中有很高的权重,排名非常靠前,任何机构,个人,或者企业做网络宣传百科是必不可少的,虽然任何人都可以注册并编辑其内容。但是&#x…...
)
USB鼠标实现——HID 报告的返回(八)
文章目录HID 报告的返回仓库地址USB 鼠标阅读顺序报告返回HID 报告的返回 仓库地址 仓库地址 USB 鼠标阅读顺序 枚举过程USB鼠标实现——设备描述符(一)USB鼠标实现——设置地址(二)USB鼠标实现——配置描述符集合(…...

DOPE PEG Maleimide,DOPE-PEG-Mal,二油酰磷脂酰乙醇胺PEG马来酰亚胺
文章关键词:高分子PEG,DOPE,聚乙二醇化修饰试剂基团反应特点: DOPE PEG Maleimide是一种由 DOPE 和马来酰亚胺基团组成的 PEG 化合物。基础产品数据: CAS号:N/A 中文名:1,2-二油酰-SN-甘油-3-磷…...

python-课后作业-2
1.Python 3.x的range()函数返回一个:可迭代的序列对象 注意: Python 3.x的range()函数返回一个可迭代的序列对象,其中包含指定范围内的整数。range()函数的语法如下: range([start], stop[, step]) 其中,start表示序…...

redis 六. list应用场景及底层分析
List 类型一. 简单命令示例二. java 操作示例三. 使用场景四. 底层分析一. 简单命令示例 1.首先简单说明: List是一个双端链表的结构,内容是2的32次方减1个元素,大概40多亿,主要功能有push/pop等,一般用在栈,队列,消息队列等场景 2.简单命令 //1.向列表左边添加元素 LPUSH ke…...

成语填字接龙隐私政策
1. 适用范围 (a) 在您注册本应用帐号时,您根据本应用要求提供的个人注册信息; (b) 在您使用本应用网络服务,或访问本应用平台网页时,本应用自动接收并记录的您的浏览器和计算机上的信息,包括但不限于您的IP地址、浏览…...

导出LKD3588开发板的根文件系统
序:将RK3588上的整个根文件系统的文件通过ssh拷贝到PC系统(虚拟机) 工具:RK3588上的ubuntu系统需要安装:ssh, rsync。 PC电脑(虚拟机)上安装:ssh, rsync。 安装ssh 和rsync不做介绍,百度里面全是,也很简单需要设置开发板root权限的密码,因为后面同步文件的时候会用到…...
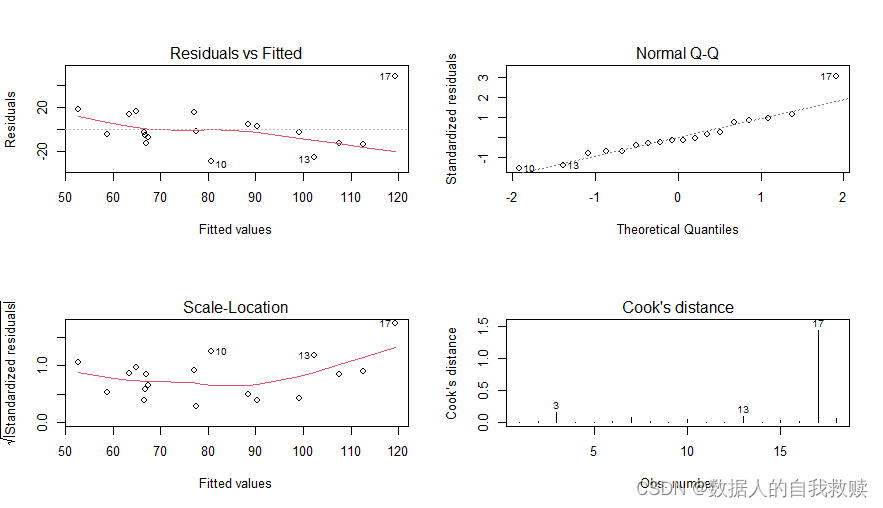
【统计模型】某地区土壤所含可给态磷回归分析
目录 某地区土壤所含可给态磷回归分析 一、研究目的 二、数据来源和相关说明 三、描述性分析 3.1 样本描述 3.2 数据可视化 四、数据建模 4.1 回归模型A 4.2 回归模型B 4.3 回归模型B模型诊断 4.4 回归模型C 五、结论及建议 5.1 结论 5.2 建议 六、代码 某地区土…...
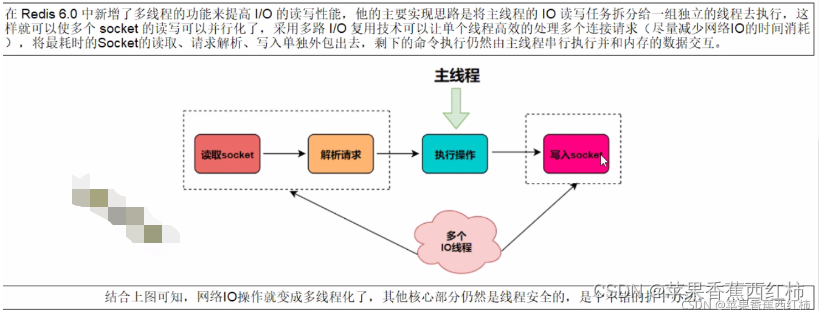
redis 十. 线程基础
目录一. redis 基础复习与了解redis6二. redis 线程问题总结一. redis 基础复习与了解redis6 redis官网, redis中文网站, redis命令参考网站此处以redis6.0.8或以上版本为例(查看自己redis版本命令"redis- server -v")按照redis6以上版本测试使用时,redis.conf下需要…...
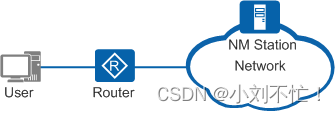
NQA简介
NQA简介定义目的NQA原理描述使用DHCP进行测试DNS测试NQA的联动机制NQA的应用场景定义 网络质量分析NQA(Network Quality Analysis)是一种实时的网络性能侦探和统计技术,可以对响应时间、网络抖动、丢包率等网络信息进行统计。NQA能够实时监视…...

[python]上下文管理contextlib模块与with语句
文章目录with语句自定义对象支持withcontextlib模块closing自动关闭suppress回避错误ExitStack清理Python 中的 with 语句用于清理工作,封装了 try…except…finally编码范式,提高了易用性。with语句 with语句有助于简化资源管理: # 离开作…...
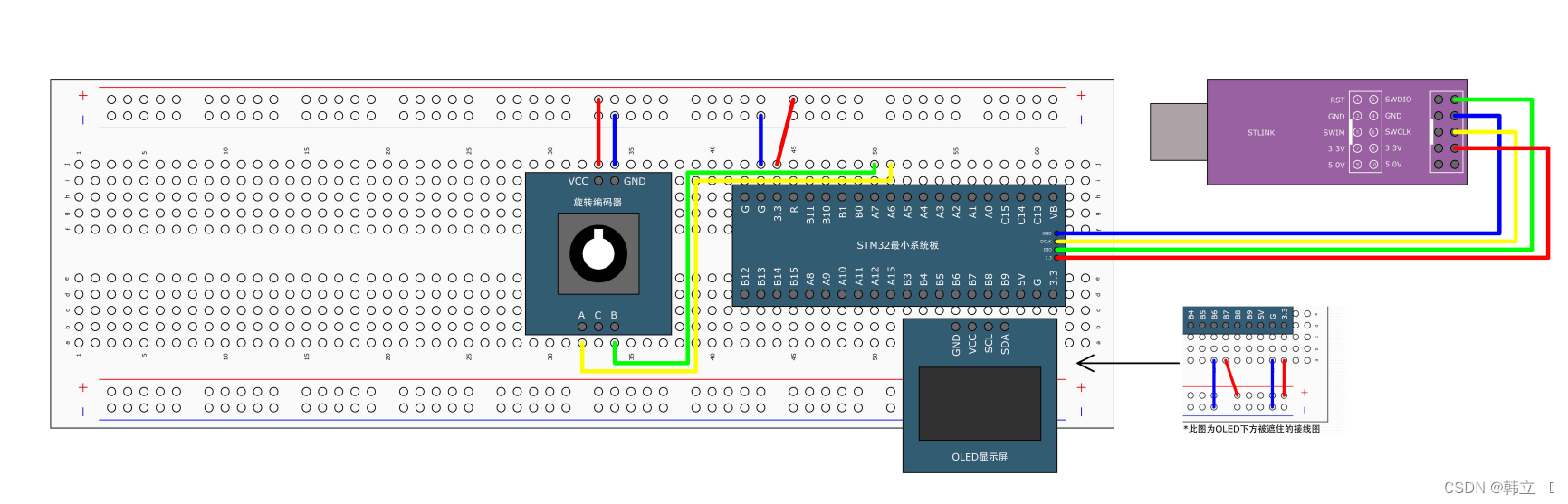
STM32之TIM编码器接口
编码器简介: 例子讲解:正交编码器有两个输出,一个A相,一个B相,AB接口输出正交信号。然后接入STM32的定时器的编码器接口,编码器接口自动控制定时器时基单元中的CNT计数器进行自增或自减,比如初始…...

b站第一,Python自动化测试实战详细教学,3天教你学会自动化测试
目录 简介 Python自动化测试概述 Python自动化测试目标 Python自动化测试流程 1. 测试计划和设计 2. 测试脚本开发 3. 测试执行和管理 4. 测试维护和优化 Python自动化测试最佳实践 Python自动化测试工具和框架 结论 简介 自动化测试是软件开发过程中一个必不可少的…...

刷题记录:P8804 [蓝桥杯 2022 国 B] 故障 条件概率
传送门:洛谷 题目描述: 题目较长,此处省略 输入: 3 5 30 20 50 0 50 33 25 0 30 0 35 0 0 0 0 0 25 60 1 3 输出: 2 56.89 1 43.11 3 0.00读完题目,我们会发现其实题目给了我们两个事件,并且这两个事件是相互关联的.因此不难想到使用条件概率 我们将故障原因看做事件AAA,结合…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...