大数据技术架构(组件)26——Spark:Shuffle
2.1.6、Shuffle
2.1.6.0 Shuffle Read And Write
MR框架中涉及到一个重要的流程就是shuffle,由于shuffle涉及到磁盘IO和网络IO,所以shuffle的性能直接影响着整个作业的性能。Spark其本质也是一种MR框架,所以也有自己的shuffle实现。但是和MR中的shuffle流程稍微有些不同(Spark相当于Mr来说其中一些环节是可以省略的),比如MR中的Shuffle过程是必须要有排序的,且不能省略掉,但Spark中的Shuffle是可以省略的;另对于MR的Shuffle中间结果是要落盘的,而对于Spark Shuffle来说,可以根据存储策略存储在内存或者磁盘中。
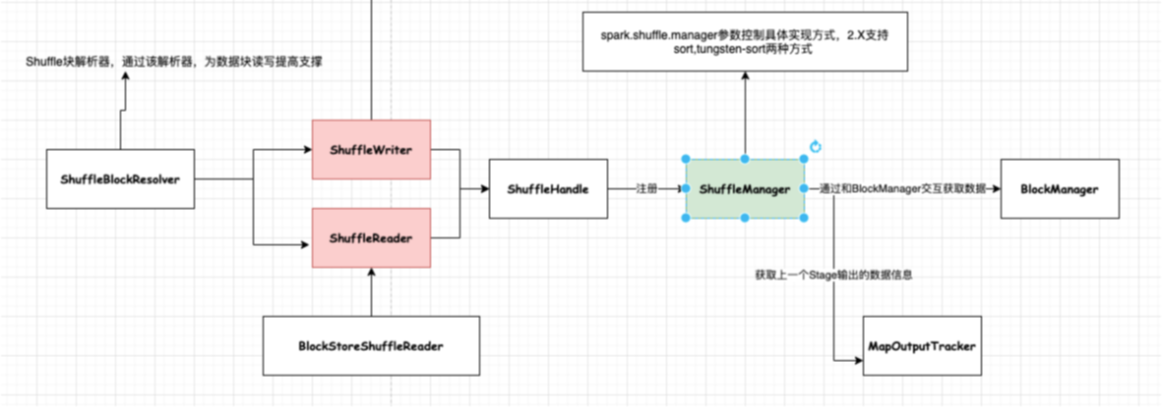
Shuffle阶段中涉及到一个很重要的插拔式接口ShuffleManager,该接口可以作为一个入口,可以获取用于数据读写处理句柄ShuffleHandle,然后通过ShuffleHandle获取特定的读写接口即ShuffleWriter和ShuffleReader,以及获取块数据信息解析接口ShuffleBlockResolver。
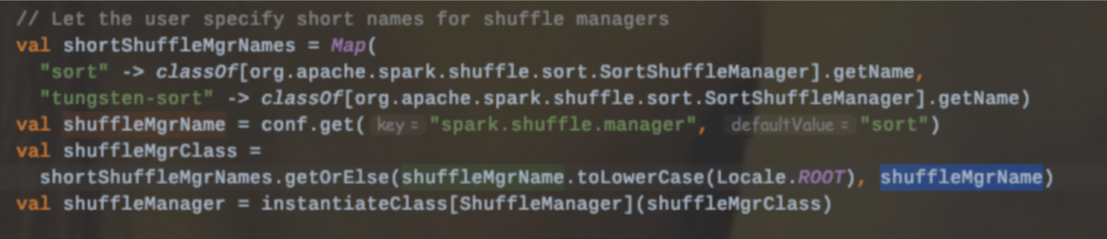
目前Spark提供了两种ShuffleManager:sort和tungsten-sort
2.1.6.0.1、Shuffle Writer
Shuffle写数据的时候,在内存中是有一个Buffer缓冲区,同时本地磁盘也有对应的文件(具体位置可以通过spark.local.dir配置);因此该部分内存中主要被两部分内容所占用:1、存储Buffer数据;2、管理文件句柄。
如果shuffle过程中写入大量的文件,那么内存消耗也是一种压力,很容易产生OOM,频繁GC。
扩展:关于GC引发的shuffle fetch不到文件
有那么一种现象:即Reduce端的Stage去拉取上一个Stage的产生结果,但是因为找不到文件而抛出异常,其实并不是不存在,而是可能由于正在进行GC操作而未回应。
Spark2.X提供了三种Shuffle Writer模式:
2.1.6.0.1.1 BypassMergeSortShuffleWriter
该种模式是带了Hash风格的基于Sort的Shuffle机制,为每个reduce端生成一个文件。
适用场景:该种模式适用于分区数比较少的场景下,可以作为一种优化方案。
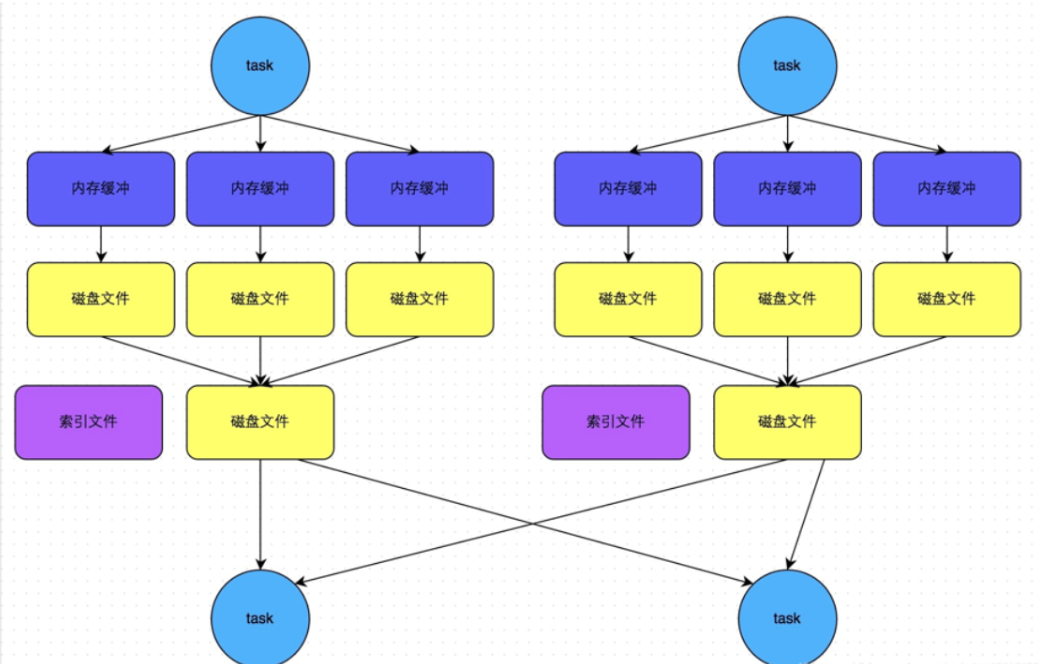
上图的合并机制即就是BypassMergeSortShuffleWriter的部分流程。
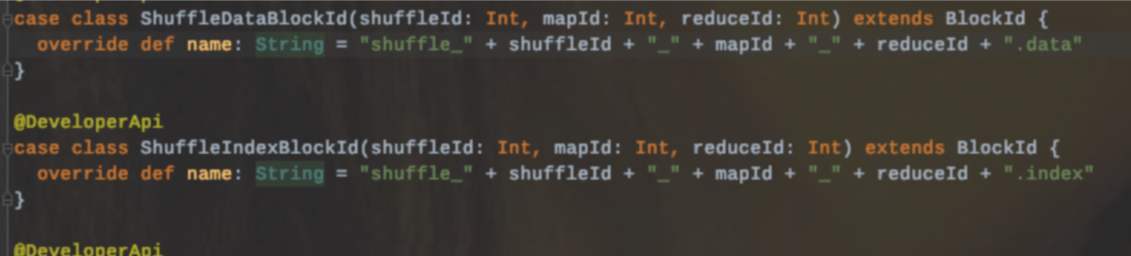
写入文件命名:
该种模式的缺点:
1、不能使用aggregator,以32条记录批次直接写入的(通过spark.shuffle.file.buffer参数配置),所以会造成后续的网络IO开销比较大。
2、每个分区都会生成一个对应的磁盘写入器DiskBlockObjectWriter,先对每个reduce产生的数据写入临时文件中,最后合并输出一个文件。所以分区数不能设置过大,避免同时打开过多实例加大内存开销
3、不能指定Ordering,也就是说该种模式的排序是采用分区Id进行的,分区内的数据是不保证有序的。
2.1.6.0.1.2 SortShuffleWriter
流程:
1、Sort Shuffle Writer模式首先会实例化一个ExternalSorter,根据是否在map端聚合来决定是否在实例化的时候传入aggregator和Ordering变量。
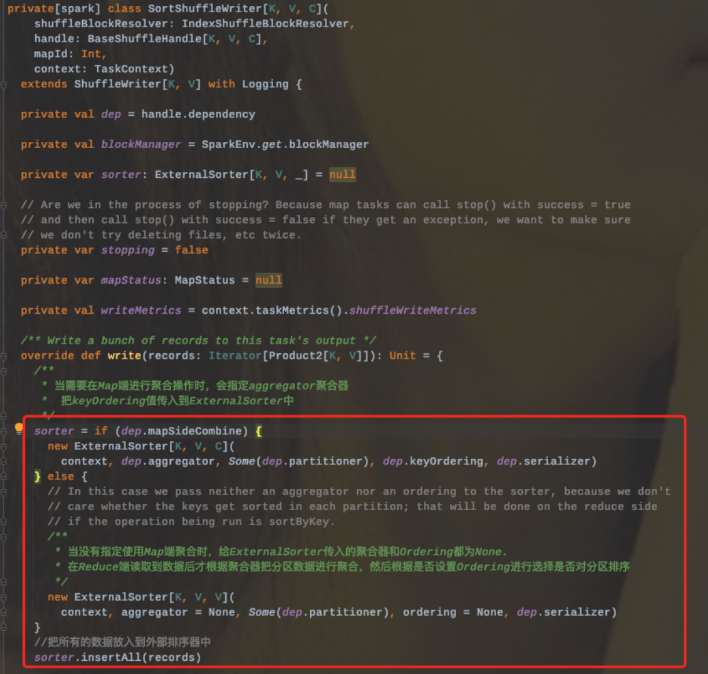
2、把所有的记录放到外部排序器中ExternalSorter(会调用Sorter.insertAll和writePartitionedFile两个方法)
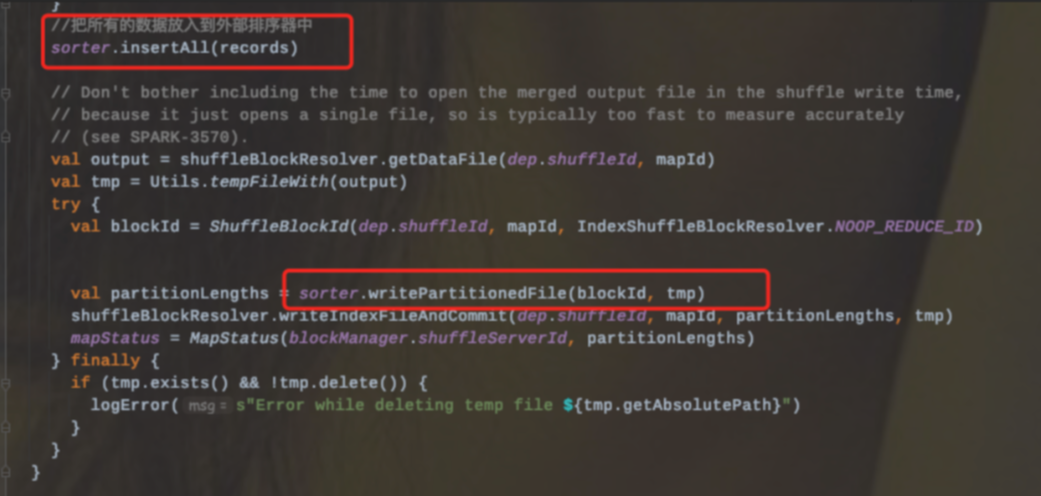
3、Sorter.insertAll内部会根据是否进行合并采用不同的存储。如果需要进行合并,那么就会使用AppendOnlyMap在内存中进行合并;如果不需要进行合并,那么就会存放到Buffer中。
3.1、无论是否进行合并,都会进行的是否溢写检查(即调用maybeSpillCollection检查是否溢写到磁盘),其底层内部调用的是maybeSpill方法。
4.其溢写策略:
4.1、首先检查是否需要spill;判断依据为:
4.1.1、当前记录数是否是32的倍数--即对小批量的数据集进行spill
4.1.2、检查当前需要的内存大小是否达到或者超过了当前分配的内存阈值spark.shuffle.spill.initialMemoryThreshold=510241025
4.2、如果以上条件都满足的话,那么会向Shuffle内存池申请当前2倍内存,然后再次判断是否需要spill。
4.3、再次判断的依据是:
4.3.1、当前判断结果为true|从上次spill之后读取的记录数是否超过了配置的阈值spark.shuffle.spill.numElementsForceSpillThreshold

缺点:
1、内存中的数据是以反序列化的形式存储的,这样会增加内存的开销,同时也意味着增加GC负载。
2、存储到磁盘的时候会对数据进行序列化,而反序列化和序列化操作会增加CPU的开销。
2.1.6.0.1.3 UnsafeShuffleWriter
和Sort Shuffle Writer基本一致,主要不同在于使用的是序列化排序模式。
上述中说到在spark.shuffle.manager设置为sort时,内部会自动选择具体的实现机制。
Tungsten-Sort Shuffle内部的写入器是使用的UnsafeShuffleWriter,该类在构建的时候会传入一个context.taskMemoryManager(),构建一个TaskMemoryManager实例,主要负责管理分配task内存。
该写入器有以下三个关键步骤:
1、通过循环遍历将记录写入到外部排序器中
2、closeAndWriteOutput方法写数据文件和索引文件,在写的过程中会先合并外部排序器在插入过程中生成的中间文件。该方法主要有三个步骤:
2.1、触发外部排序器,获取spill信息
2.2、合并Spill中间文件,生成数据文件,并返回各个分区对应的数据量信息。
2.3、根据各个分区的数据量信息生成数据文件对应的索引文件。
3、sorter.cleanupresources最后释放外部排序器的资源。
2.1.6.0.2、Shuffle Read
2.1.6.1、Hash Shuffle(Spark2.X abandoned)
早期引入Hash Shuffle主要是为了避免不必要的排序(MR中的Shuffle过程sort是必经的一个过程)。
在Spark1.1之前,每个Mapper阶段的Task都会为每个Reduce阶段的Task生成一个文件,那么也就会生成M*R个中间文件(M表示Mapper阶段的Task个数,R表示Reduce阶段的Task个数)。
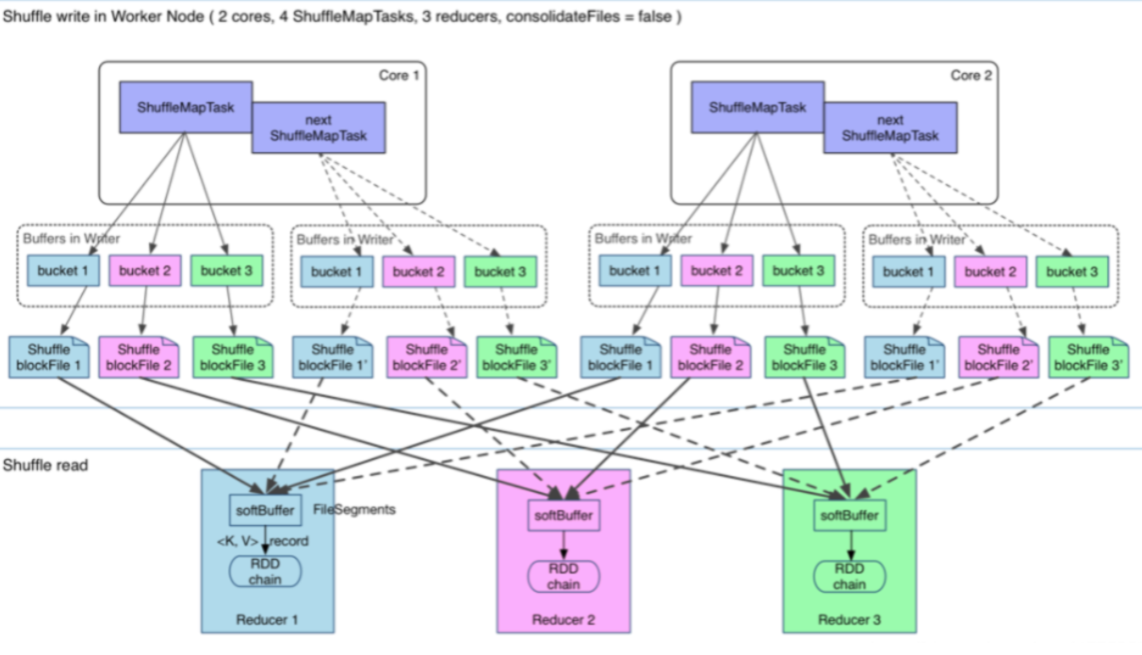
后来为了缓解这种大量文件产生的问题,基于Hash Shuffle实现又引入了Shuffle Consolidate机制,也就是将中间文件进行合并。通过配置spark.shuffle.consolidateFiles=true减少中间文件生成的个数。该种机制把中间文件生成方式调整为每个执行单元(类似于Slot)为每个Reduce阶段的Task生成一个文件,那么最后生成的文件个数为E(C/T)R;
E:表示Executors个数
C:表示Mapper阶段可用Cores个数
T:表示Mapper阶段Task分配的Cores个数。
从抽象的角度来说,Consolidate Shuffle是通过ShuffleFileGroup的概念,即每个ShuffleFileGroup对应一批Shuffle文件,文件数量和Reducer端的Task个数一样。同个Core上执行的MapTask任务会往这一批Shuffle文件里写,这样可以进行复用,在一定程度上对多个task进行了合并。
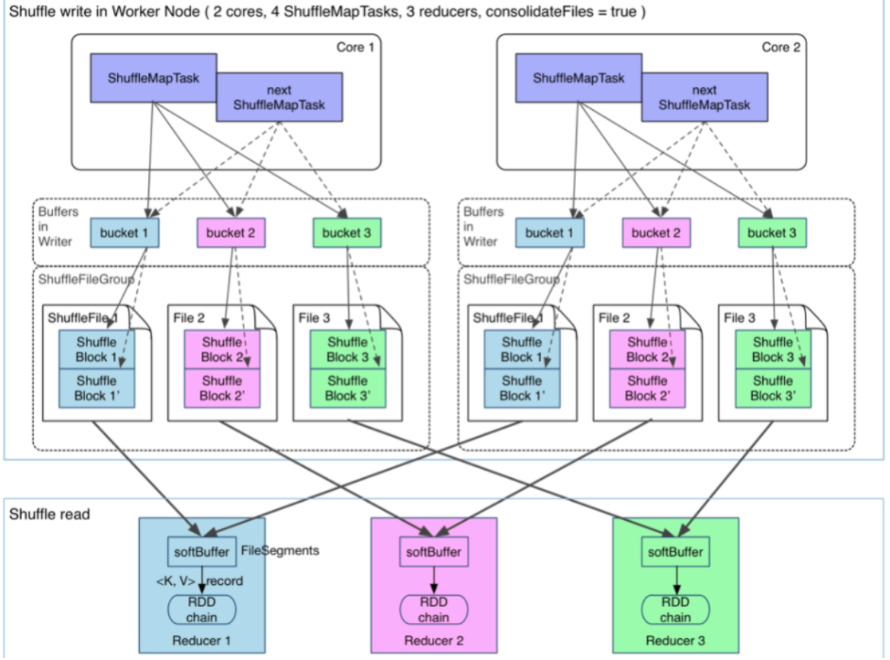
2.1.6.2、Sort Shuffle
2.1.6.2.1、引入背景
基于Hash的Shuffle实现方式,生成的中间结果文件个数取决于Reduce阶段的Task个数,即Reduce端的并行度。虽然引入了consolidate机制,但是仍然解决不了大量文件生成的问题。
因此在Spark1.1中又引入了基于Sort的Shuffle方式,在2.X中废弃掉了hash shuffle。也就是说现在1.1之后所有的版本中默认都是Sort Shuffle(早期版本其实可以调整ShuffleManager为hash方式)。
为什么说Sort Shuffle解决了Hash Shuffle生成大量文件的问题?那么最后又是会生成多少个文件呢?
解答:基于sort shuffle的模式是将所有的数据写入到一个数据文件里,同时会生成一个索引文件。那么最终文件生成的个数变成了2M;
M表示Mapper阶段的Task个数,每个Mapper阶段的Task分别生成两个文件(1个数据文件、1个索引文件)
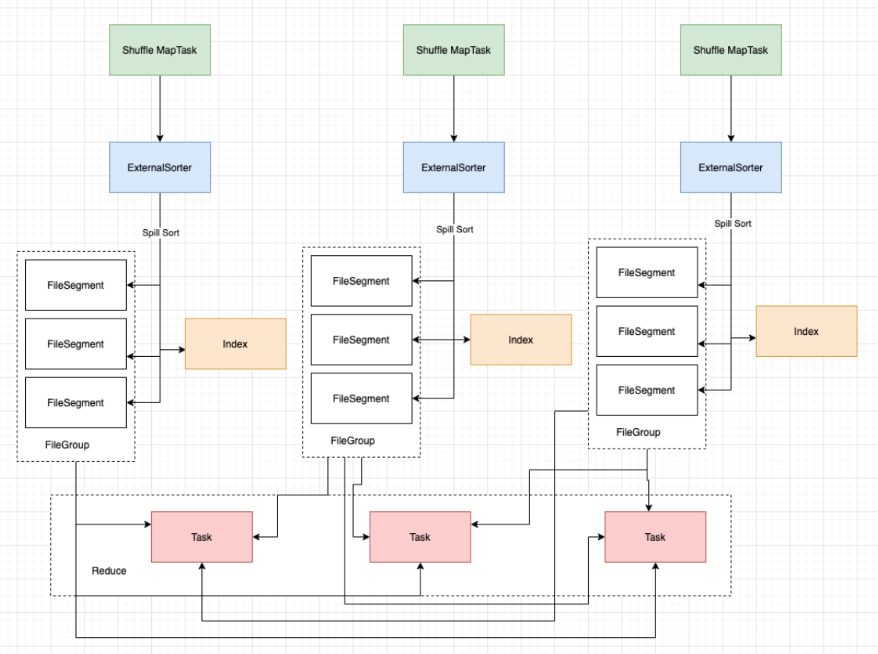
其中索引文件存储了数据文件通过Partitioner的分类的信息,所以下一个阶段Stage中的Task就是根据这个index文件获取自己所需要的上一个Stage中ShuffleMapTask产生的数据。而ShuffleMapTask产生数据写入是顺序写的(根据自身的Key写进去的,同时也是按照Partition写进去的)
2.1.6.2.2、原理
Sort Shuffle主要是在Mapper阶段,在Mapper阶段,会进行两次排序(第一次是根据PartitionId进行排序;第二次是根据数据本身的Key进行排序,当然第二次排序除非调用了带排序的方法,在方法里指定了Key值的Ordering实例,这个时候才会对分区内的数据进行排序)。
sort shuffle其核心借助于ExternalSorter首先会把每个ShuffleMapTask的输出排序内存中,当超过内存容纳的时候,会spill到一个文件中(FileSegmentGroup),同时还会写一个索引文件用来区分下一个阶段Reduce Task不同的内容来告诉下游Stage的并行任务哪些数据是属于自己的。
2.1.6.2.3、缺点
1、sort shuffle产生的文件数量为2M,那么这个文件数量的大小也是取决于M的个数,也就是Map端的TASK个数。如果task数过多,那么这个时候Reduce端需要大量记录并进行反序列化,同样会造成OOM,甚至full GC
2、Mapper端强制排序(和MR中的Shuffle是一样的)
3、如果分区内也需要进行排序,那么就都要在mapper端和reducer端进行排序。
4、sort shuffle是基于记录本身进行排序的,会有一定的性能消耗。
2.1.6.3、Tungsten Sort Shuffle
tungen-sort shuffle对排序算法进行了改造优化了排序的速度。其优化(从避免反序列化的数据量过大消耗内存方面考虑;借助于Tungsten内存管理模型,可以直接处理序列化的数据,同时也降低了CPU开销。
使用该模式需要具备以下几个条件:
1、shuffle依赖中不存在聚合操作或者没有对输出排序的要求
2、shuffle的序列化器支持序列化值的重定位(目前仅支持KryoSerializer以及SparkSQL子框架自定义的序列化器)
3、Shuffle过程重化工的输出分区个数少于16777216个。
所以使用基于Tungsten-sort的Shuffle实现机制条件还是比较苛刻的。
2.1.6.4、Shuffle & Storage (TODO)
相关文章:
大数据技术架构(组件)26——Spark:Shuffle
2.1.6、Shuffle2.1.6.0 Shuffle Read And WriteMR框架中涉及到一个重要的流程就是shuffle,由于shuffle涉及到磁盘IO和网络IO,所以shuffle的性能直接影响着整个作业的性能。Spark其本质也是一种MR框架,所以也有自己的shuffle实现。但是和MR中的shuffle流程…...

关于Zebec生态的改进提案,即将上线的 Nautilus 链
概括 在最初作为 Solana 原生应用程序推出一年后,Zebec 团队已经能够通过在 BNB和NEAR区块链上成功部署来扩大其产品的范围。 凭借继续向尽可能多的公司/协议/基金提供薪资工具和基础设施的雄心勃勃的计划,我们决定采用最终将使 Zebec生态系统及其核心…...

Python数据可视化(三)(pyecharts)
分享一些python-pyecharts作图小技巧,用于展示汇报。 一、特点 任何元素皆可配置pyecharts只支持python原生的数据类型,包括int,float,str,bool,dict,list动态展示,炫酷的效果,给人视觉冲击力 # 安装 pip install pyecharts fr…...

【Redis面试指南】
Redis面试指南 Redis是一个开源的、基于内存的、高性能的键值对存储系统,它可以用于存储非常大量的数据,并且可以在短时间内获取数据。Redis的性能被广泛用于Web应用程序的缓存层,以提高应用程序的性能和可用性。Redis的面试是一个比较复杂的…...

大数据技术之Hadoop(生产调优手册)
第1章 HDFS—核心参数 1.1 NameNode内存生产配置 1)NameNode内存计算 每个文件块大概占用150byte,一台服务器128G内存为例,能存储多少文件块呢? 128 * 1024 * 1024 * 1024 / 150Byte ≈ 9.1亿 G MB KB Byte 2)Hadoop…...

「Vue源码学习」常见的 Vue 源码面试题,看完可以说 “精通Vue” 了吗?
Vue源码面试题一、行时(Runtime) 编译器(Compiler) vs. 只包含运行时(Runtime-only)webpackRollupBrowserify二、Vue 的初始化过程(面试关问:new Vue(options) 发生了什么࿱…...

FreeModbus RTU 移植指南
FreeModbus 简介 FreeModbus 是一个免费的软件协议栈,实现了 Modbus 从机功能: 纯 C 语言支持 Modbus RTU/ASCII支持 Modbus TCP 本文介绍 Modbus RTU 移植。 移植环境: 裸机Keil MDK 编译器Cortex-M3 内核芯片(LPC1778/88&…...
《唐诗三百首》数据源网络下载
2023年的 元宵之夜,这场以“长安”为主题的音乐会火了!在抖音,超过2300万人次观看了直播,在线同赏唐诗与交响乐的融合。许多网友惊呼,上学时那些害怕背诵的诗句,原来还可以有这么美的表达这场近80分钟的音乐…...

(深度学习快速入门)第五章第一节2:GAN经典案例之MNIST手写数字生成
获取pdf:密码7281 文章目录一:数据集介绍二:GAN简介(1)简介(2)损失函数三:代码编写(1)参数及数据预处理(2)生成器与判别器模型&#x…...
雁过留痕,竟是病毒的痕迹?
凌恩生物全新升级宏病毒组分析流程;聚焦DNA,RNA病毒组研究热点;高灵敏度检测vOTUs;多软件整合,精准鉴定病毒序列;直击地化循环关键环节,助力宏病毒组科研成功!期刊:Micro…...

Linux基本功系列之sort命令实战
文章目录前言一. sort命令介绍二. 语法格式及常用选项三. 参考案例3.1 按照文本默认排序3.2 忽略相同的行3.3 按数字大小进行排序3.4 检查文件是否已经按照顺序排序3.5 将第3列按照数字大小进行排序3.6 将排序结果输出到文件四. 探讨 -k的高级用法总结前言 大家好,…...
【笔记】移动端自动化:adb调试工具+appium+UIAutomatorViewer
学习源: https://www.bilibili.com/video/BV11p4y197HQ https://blog.csdn.net/weixin_47498728/category_11818905.html 一、移动端测试环境搭建 学习目标 1.能够搭建java 环境 2.能够搭建android 环境 (一)整体思路 我们的目标是Andr…...
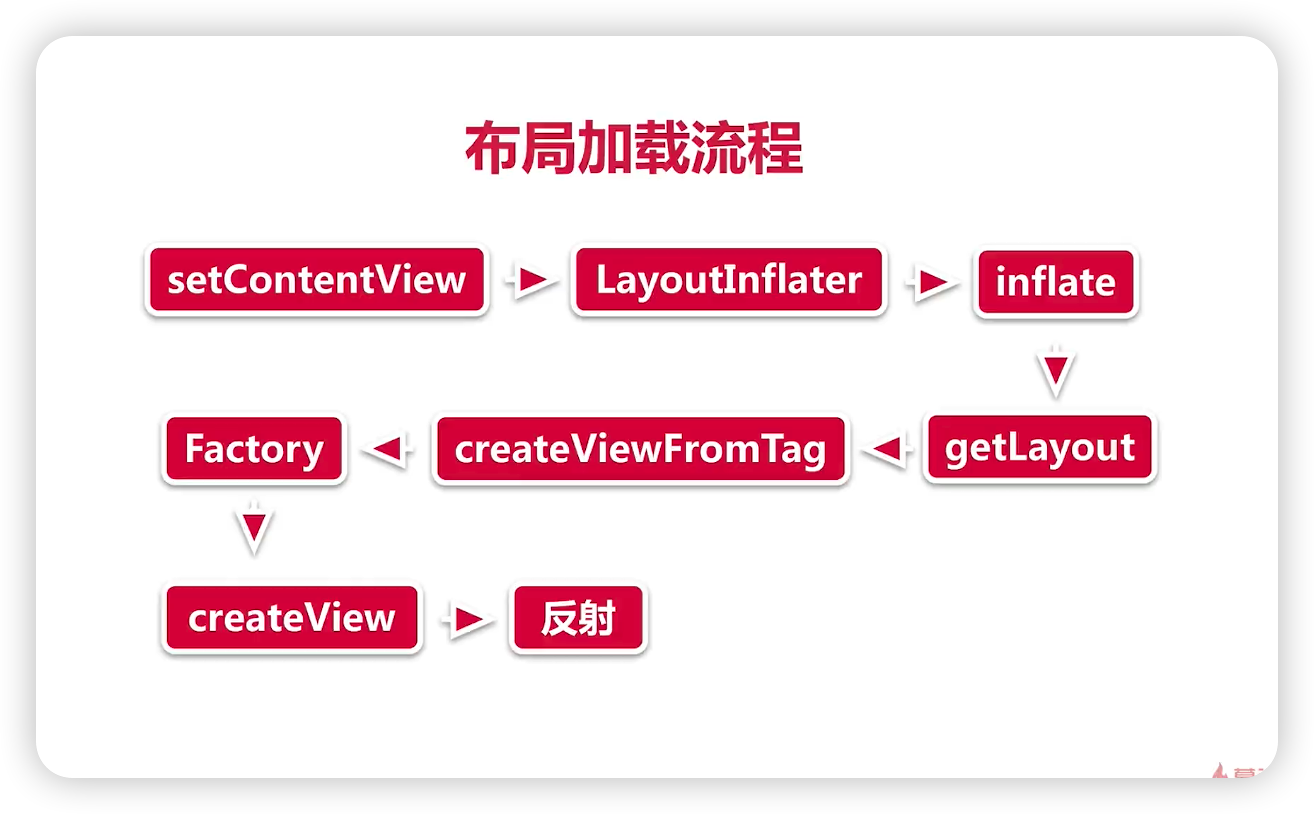
面试复习题--性能检测原理
1、布局性能检测 Systrace,内存优化工具中也用到了 Systrace,这里关注 Systrace 中的 Frames 页面,正常情况下圆点为绿色,当出现黄色或者红色的圆点时,表现出现了丢帧。 Layout Inspector,是 AndroidStudio 自带工具…...

@LoadBalanced 和 @RefreshScope 同时使用,负载均衡失效分析
背景 最近引入了 Nacos Config 配置管理能力,说起来用法很简单,还是踩了三个坑。 Nacos Config 的 nacos 的帐号密码加密配置后,怎么解密而且在 NacosConfigBootstrapConfiguration 真正注入 Nacos Config 注入之前,而且不能触发…...

2023年个人计划
2023年个人计划 可能是最近太清闲,感觉生活很无聊,就胡乱做下新年的规划吧,扰乱下烦闷的心 1 二宝健健康康,活泼可爱 目前老婆已经怀孕5周左右了,二宝将在进行年中降生,希望老婆少受点罪,二宝…...

加拿大访问学者家属如何办理探亲签证?
由于大多数访问学者的访学期限都为一年,家人来访不仅可以缓解访学的寂寞生活,而且也是家人到加拿大体验国外风情的好机会。家属在国内申请赴加签证时,如果材料齐全,一般上午递交了申请,下午就可以拿到签证。以下是家人…...
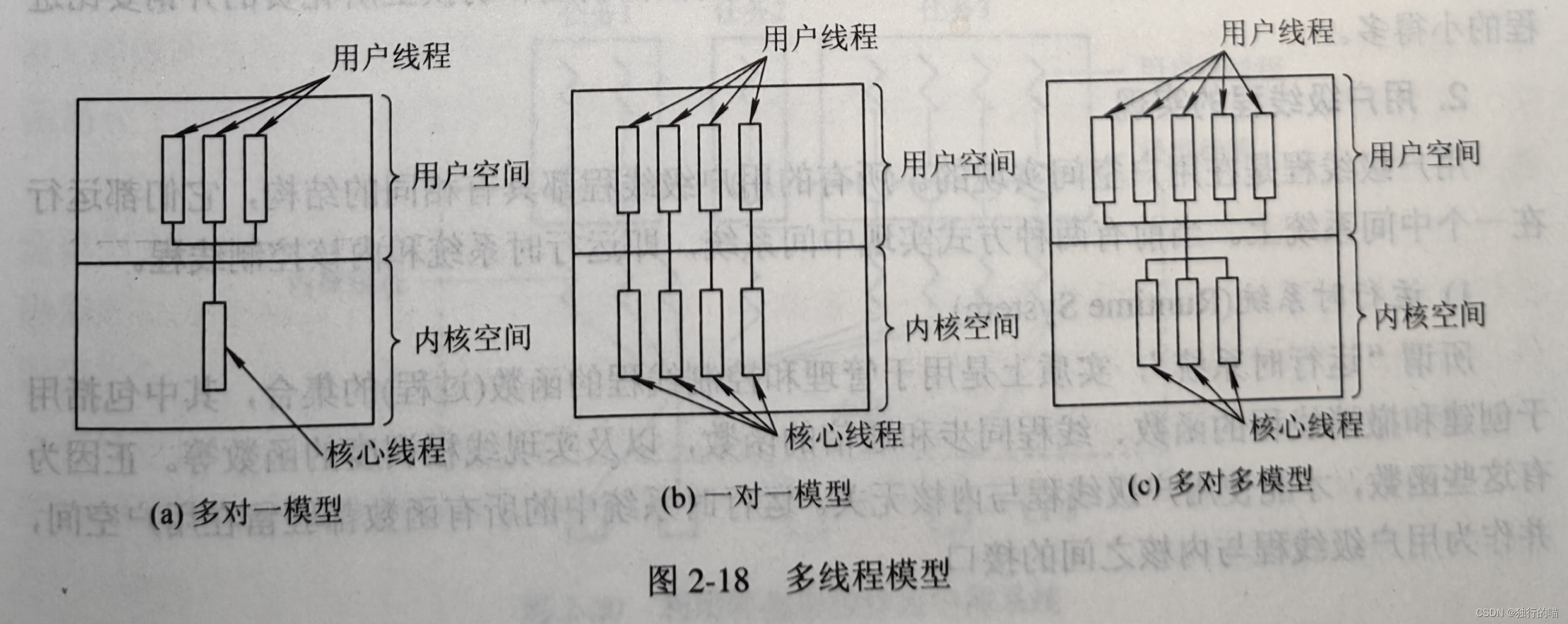
操作系统基础---多线程
文章目录操作系统基础---多线程1.为何引入线程程序并发的时空开销线程的设计思路线程的状态和线程控制块TCB2.线程与进程的比较3.线程的实现⭐1.内核支持线程KST2.用户级线程3.组合方式操作系统基础—多线程 1.为何引入线程 利用传统的进程概念和设计方法已经难以设计出适合于…...
等级考试试卷(六级)解析)
2022-12-10青少年软件编程(C语言)等级考试试卷(六级)解析
2022-12-10青少年软件编程(C语言)等级考试试卷(六级)解析T1、区间合并 给定 n 个闭区间 [ai; bi],其中i1,2,...,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3…...

太酷了,用Python实现一个动态条形图!
大家好,我是小F~说起动态条形图,小F之前推荐过两个Python库,比如「Bar Chart Race」、「Pandas_Alive」,都可以实现。今天就给大家再介绍一个新的Python库「pynimate」,一样可以制作动态条形图,…...
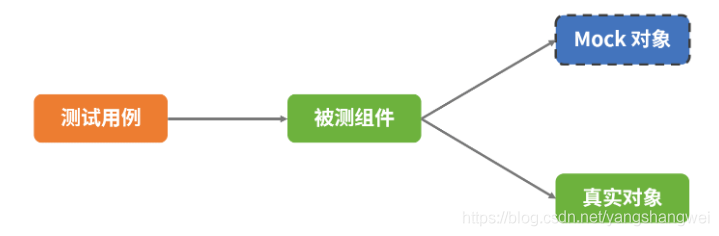
单元测试junit+mock
单元测试 是什么? 单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。至于“单元”的大小或范围,并没有一个明确的标准,“单元”可以是一个方法、类、功能模块或者子系统。 单元测试通…...

archfi开发者指南:如何贡献代码和测试脚本
archfi开发者指南:如何贡献代码和测试脚本 【免费下载链接】archfi Arch Linux Fast Installer : tutorial installer 项目地址: https://gitcode.com/gh_mirrors/ar/archfi Arch Linux Fast Installer(简称archfi)是一个简单高效的Ba…...

10.1软件工程概述-CMM-软件过程模型-逆向工程
一、软件工程基础知识 00:00 1. 软件工程概述 03:10 考试重要性:本章节每年考察12-15分,涉及选择题、案例和论文三种题型,重要性仅次于系统架构设计。内容特点:新版教材对概念定义改动较大,但…...

Scanpy进阶可视化--UMAP科研级图表定制
1. 从基础到进阶:UMAP科研级图表的核心要素 单细胞数据分析中,UMAP图是最常用的可视化工具之一。但很多研究者都会遇到这样的困扰:为什么我的UMAP图看起来总是差强人意?其实,科研级UMAP图与普通UMAP图的区别࿰…...

Shadow Robot 触觉传感器:摄像头隔着透明层,直接“看见”接触与形变
本文素材源于专利US12025525)一个触觉传感器包括以下组件:1. 第一层:由柔性材料形成,具有外部接触表面和相对的内部接口表面。2. 第二层:由基本透明的柔性材料形成,与第一层在接口表面处连续接触。3. 摄像头…...
TranslucentTB:轻量级Windows任务栏个性化解决方案
TranslucentTB:轻量级Windows任务栏个性化解决方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 项目价值:重新…...

GLM-4.1V-9B-Base从零开始:Docker容器内服务重启与持久化配置
GLM-4.1V-9B-Base从零开始:Docker容器内服务重启与持久化配置 1. 模型概述 GLM-4.1V-9B-Base是智谱开源的一款视觉多模态理解模型,专注于图像内容分析与中文视觉理解任务。这个9B参数规模的模型在图像识别、场景描述、目标问答等任务上表现出色&#x…...

RAG系统里最容易被低估的环节:深度解析检索优化策略,提升大模型应用效果!
本文深入剖析了RAG系统中检索环节的重要性,指出检索错误是导致大模型应用效果不佳的关键因素。文章从表达鸿沟、粒度鸿沟和意图鸿沟三重鸿沟出发,详细介绍了Query侧优化(如Query Rewriting、Multi-Query、HyDE)、索引侧优化&#…...

07-opencode 代码分析与重构
07-代码分析与重构 掌握 OpenCode 的代码分析和重构功能,实现批量编辑、智能分析和代码库问答。 一、代码分析概述 1.1 分析能力 OpenCode 可以分析整个代码库,提供: 结构分析:模块依赖、调用关系质量分析:代码规范…...

西门子1500博途医药系统程序案例:标准化编程实践
西门子1500博途医药系统程序案例。标准化编程! 具体为医药制品,及空调恒温恒湿,PID控制博图程序,带昆仑流程图,西门子1500PLC和昆仑通态触摸屏上位软件,博图版本V16及以上。 适合研究学习标准程序设计。在…...

嵌入式裸机开发中的轻量级上下文切换方案
1. 嵌入式编程中的上下文切换挑战在裸机嵌入式开发中,中断服务程序(ISR)的设计一直是个棘手的问题。传统教科书告诉我们:中断处理必须快进快出,绝对不能执行耗时操作。但在实际项目中,我们经常遇到这样的困境——某个传感器触发中…...