OceanBase技术解析: 执行器中的自适应技术
在《OceanBase 数据库源码解析》这本书中,对于执行器的探讨还不够深入,它更多地聚焦于执行器的并行处理机制。因此,通过本文与大家分享OceanBase执行器中几种典型的自适应技术,作为对书中执行器部分的一个补充。
提升数据库分析性能面临的挑战
数据库如果想要提升分析性能(AP),主要面临着三个方面的问题:
- 首先就是优化器的估算往往无法保证百分之百的精确度,这背后隐藏着诸多复杂因素。例如统计信息在某些情况下可能不够精确,再者,估算时采用的代价模型与实际情况之间也可能存在偏差。无论何种原因,这些因素最终都会影响到优化器生成的执行计划的质量,导致计划可能并非最优。
- 除此之外,在生产业务中,我们也经常会碰到数据倾斜的场景,这对执行效率尤其是并行执行有着非常大的影响。
- 最后,就是 NULL 的特殊语义。这是非常容易被忽视的一点,由于 NULL 值的广泛存在,且在 join 等行为下表露出和普通值不尽相同的特点。执行器必须对其做各种特殊处理,否则就会遇到各种各样的 bad case。
自适应技术是指:执行引擎根据不同的数据情况,动态调整执行策略,从而达到提升执行性能的目的。简而言之,就是为了更好地解决上述几种问题。下面我们就来根据这几类问题,介绍下 OceanBase 执行器种几种典型的自适应技术。
自适应 Join Filter
这里简单介绍一下 join filter 的背景。这里有一个两表hash join 的示例,采用的 shuffle 方式是 hash 重分区, 也就是左右表的每一行都要根据其 hash 值做网络的重分区。

鉴于 hash join 的右表往往是很大的, 这个 shuffle 代价也很大。Join filter 就是在对左表做 build 时,提取左表的数据特征,发送给右表。在右表做 shuffle 之前提前过滤掉一部分数据,如果 join filter 过滤性比较好,这一步可以显著减少网络开销。

OB 早在 3.x 版本就实现了 join filter,并一直在做这方便工作的优化。这里展示了 2021 年 tpch 打榜拿到世界第一的成绩时,我们统计的 join filter 对 tpch 整体的性能影响。

Join filter 在一些大表 join 上 (如 Q9), 带来了巨大的性能提升。
但我们也能看到,join filter 并不是在所有场景都能带来正向收益 (如 Q18)。Join filter 开销主要有三部分:
- Create join filter(hash join 对左表做 build 时,提取左表的数据特征)
- Send join filter(把左表的数据特征发送给右表)
- Apply join filter(右表应用左表的数据特征进行过滤)
如果 join filter 选择率不够理想,在网络开销上的收益不足以弥补上述开销,就会带来性能的回退 。
计划中是否分配 Join filter 是优化器基于代价决定的。优化器可以根据 NDV, MIN/MAX 等统计信息粗略估算出join filter 的选择率,但对于执行器的中间计算结果,很难进行特别准确的估计。
为此,我们在 4.1 版本实现了基于滑动窗口的自适应 join filter,这个算法主要是为了弥补错误的 join filter 在 apply 这一步骤上的性能损失。
我们将数据拆分为一个个滑动窗口,对每个窗口的 apply 过程做统计信息收集。如果检查到此窗口的过滤效果不达标,则后面的一个窗口不做 apply, 直接 pass 掉, 如果连续窗口不达标,pass 窗口数量也会线性上升,从而达到减少 apply 代价的目的。

这里展示了一个 join filter bad case 下, 使用不同策略的性能测试,可以看出自适应 join filter 找回了一半左右的性能损失。但也能看到,自适应 join filter 在这个场景下, 距离不分配还有一定的差距。

这个方案的局限在于虽然弥补了右表应用 join filter 的性能损失,但创建和发送 join filter 的代价没能被弥补。我们将在后面的版本支持 join filter 创建过程中的自适应能力,以达到釜底抽薪的效果。
自适应 Hash Group By
下面为大家介绍一下 OceanBase 对 hash group by 的自适应算法。
这里展示了一个简单的 hash group by 在并行场景下的执行计划。
这是两阶段 hash group by 的计划:


这是一阶段 hash group by 的计划:

可以看到其主要区别在于,两阶段 group by 的数据在走网络 shuffle 之前,额外地做了一次 partial 的 group by。跟 join filter 一样,一阶段和两阶段的 hash group by 也各有优劣:
- 两阶段 group by 适用于数据聚合率比较高的场景,通过预聚合减少 shuffle 的数据量。

- 而一阶段 group by 则适用于数据聚合率比较低的场景。

如果数据聚合率低,走两阶段的计划会消耗额外的 CPU 去进行一次 hash 探测,而且网络开销依然很大,可能导致性能比一阶段更差。
这里展示了几个 clickbench 查询选择两阶段和一阶段的性能对比,可以看出有的 SQL 更适合两阶段执行,有的则适合一阶段。一般优化器会更加倾向于选择两阶段计划,避免严重的性能回退。

在 4.x 版本以前,优化器会根据统计信息 NDV 来决策计划是两阶段还是一阶段。用户还可以通过调整 session 变量 _GROUPBY_NOPUSHDOWN_CUT_RATIO 来选择让计划偏向选择两阶段还是一阶段的策略,如果输入的数据量与聚合之后结果的数据量的比值大于指定的这个 ratio,就生成两阶段的计划,否则生成一阶段的计划。实际上,这个变量是很难用的,由于 gby 输入输出数据量也是优化器根据统计信息估计出来的,一般运维同学很难通过把这个参数调整到合适的范围来让优化器选择更好的 gby 计划。

在 4.x 版本,我们让优化器强制选择两阶段计划,并废弃通过 _GROUPBY_NOPUSHDOWN_CUT_RATIO 参数控制一阶段/二阶段的计划选择。我们强制生成两阶段计划之后,两阶段中的第一阶段一定是一个自适应 Group By。

自适应 gby 的核心思想就是通过实时 NDV 信息的收集,来自己判断是进行去重,还是直接进行数据发送。我们将数据拆分为多轮,并统计每一轮的聚合率,如果本轮的去重率不够好,自适应 gby 会将 hash 表清空,一阶段的数据直接全部 flush 给网络,到二阶段再做最终的聚合。
轮次的划分是根据 CPU 三级缓存的大小来划分的,这是因为当 hash 表可以容纳在 L2 cache 内的时候,性能会比大 hash 表有 30% 以上的提升。我们在这里有一个 Cache Aware,会根据去重率把轮次的划分规则从 L2 cahce 扩张到 L3 cache
如果连续多个轮次的 hash 去重效果都很差,接下来我们就会选择 bypass 的策略,也就是不再做 hash 去重,而是直接向上吐行,在外界看起来就相当于一阶段的计划。

使用这种方法,我们获得了很好的性能提升,但这个方案也有一些 bad case,往往是数据量很大,但整体去重率又比较好的时候。因为这个时候如果我们只拿一小部分数据判断整体的去重率,很有可能是估不准的,为此我们最近在 4.2 上又做了对多轮数据 NDV 做合并的工作来让估算更加准确。
这里展示了刚才 clickbench query 的性能数据,增加了自适应 gby 的测试数据。

可以看到,自适应 gby 在几乎所有场景都能选到合适的执行策略。通过自适应 gby, 我们做到了一个计划适用于不同的数据模型情况,这就是我们希望达到的自适应的目的。在下一个版本 4.3,我们会支持一种全局 NDV 估算的策略,让自适应决策更加准确。
自适应 Hybrid Hash Shuffling
接下来介绍一下我们基于数据倾斜做的一些自适应技术。对于一个简单的分布式 hash join, 这里列举了两个常见的计划:
一个是 broadcast,就是将左表广播给右表的每个线程,右表数据原地对左表数据进行探测。


另一个是 hash 重分区,上面提到过,就是将左右表数据根据 hash 值打散到不同线程,每个线程各自做 join。


这两种方法同样各有优劣。一般 broadcast 计划适用于大小表 Join 的场景,对小表做广播,这样广播代价不会特别大。如果两张表都比较大,且不能根据 Join key 做重分区时,Hash-Hash 基本就是是唯一的选择了。但数据倾斜时,Hash-Hash 在数据倾斜场景下也会面临 bad case。比如下面这个图中有一个高频值,由于 hash 重分区,数据根据其 hash 值被发往不同线程,所有高频值都被发往了同一个 hash join 的线程里,最终导致 hash join 出现长尾的现象。

下面通过 SQL plan monitor 就能更加一目了然地看到在业务中遇到的类似场景:

为了解决这个问题, 我们在 4.x 实现了 Hybrid hash shuffling 的算法,这个算法在计划上显示是下图这样的,计划长得很像 hash 重分区的计划,只是在 exchange 算子里多了一个 Hybrid 的关键字。

Hybrid Hash Shuffling 会从优化器获得高频值的相关信息。在执行过程中,对于常规低频值,使用普通的 Hash Shuffling,依旧做 hash 重分区。对于高频值,如果它出现在左侧(hash join build 侧),这个数据需要被广播到所有线程去构建 hash 表;如果出现在右侧(hash join probe 侧),我们就将其 random 打散保证均匀性。通过这种方法,我们就可以很好地解决 hash 重分区在倾斜场景下的性能问题。

自适应 NULL Aware Hash Join
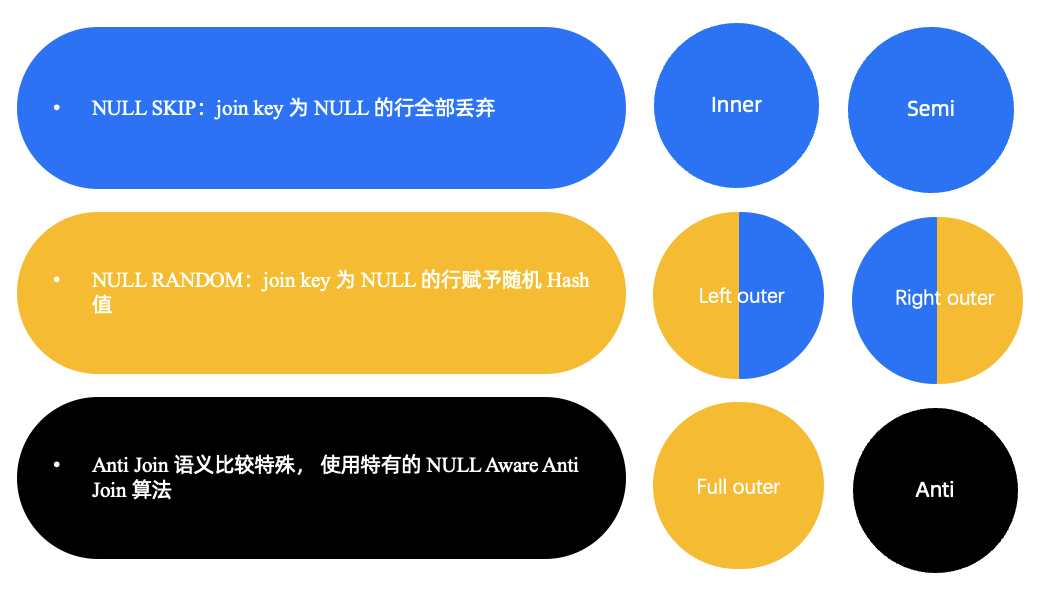
最后简单介绍一下,我们对 NULL 值做的一些优化处理。对于 Join, NULL 的特殊性在于其在 equal condition 中返回的结果永远为 NULL,而 NULL 在不同的连接方式中语义又不相同。
在 inner/semi join 中,join key 为 NULL 的值可以忽略。

但在 left outer join中, 左边的 NULL 也是需要输出的。

按照处理正常值的方式处理 NULL,可以得到正确的结果, 但可能会出现 NULL 的数据倾斜,或者出现大量 NULL 做无用网络 shuffle 的情况。 我们在 hash join 内部以及 hash join shuffle 的过程中,对 NULL 做了一些特殊的处理,主要分为三类:
- 第一类是 NULL skip,我们会在 join key 里忽略或者丢弃 NULL 值。这个一般发生在 Inner join 或 semi join 中,因为他们不会将任何 join key 为 NULL 的值进行输出的。
- 第二类是将 NULL random 打散,这是为了防止 NULL 出现倾斜采用的做法。一般在 outer join 中(left outer join 的左边、right outer join 的右边、full outer join 的两边),有一侧或者两侧的 NULL 都需要输出,这种 NULL 不会和任何值匹配成功,所以我们会为其赋一个随机的 hash 值,并将其随机打散到不同的线程。如果有不需要输出的 NULL 值,我们依然会对其做 skip。
- 第三类是 not in 相关的 anti join。它的语义最为特殊,我们用 NULL aware anti join 算法来处理,这篇博客暂时不对此做详尽的介绍。
还有更多
这篇博客给大家介绍了执行器中几个比较具有代表性的自适应技术,但是已经假设大家对 hash gby 的两阶段下压技术有所了解。如果大家对执行器的多阶段下压技术还不是特别了解,可以参考另一篇博客《OceanBase 分布式下压技术》。
相关文章:
OceanBase技术解析: 执行器中的自适应技术
在《OceanBase 数据库源码解析》这本书中,对于执行器的探讨还不够深入,它更多地聚焦于执行器的并行处理机制。因此,通过本文与大家分享OceanBase执行器中几种典型的自适应技术,作为对书中执行器部分的一个补充。 提升数据库分析性…...
Spring Cloud Gateway接入WebSocket:实现实时通信
在现代的微服务架构中,实时通信变得越来越重要。Spring Cloud Gateway作为Spring Cloud生态中的API网关,提供了动态路由、监控、弹性、安全等功能。本文将介绍如何通过Spring Cloud Gateway接入WebSocket,实现服务之间的实时通信。 为什么需…...

linux信号| 学习信号三步走 | 学习信号需要打通哪些知识脉络?
前言: 本节内容主要讲解linux下信号的预备知识以及信号的概念, 信号部分我们将会分为几个阶段进行讲解:信号的概念, 信号的产生, 信号的保存。本节主要讲解信号 ps:本节内容适合学习了进程相关概念的友友们进行观看哦 目录 什么是…...

Java调用第三方接口、http请求详解,一文学会
Java 调用第三方接口的封装方法详解 在开发企业级应用时,调用第三方接口是非常常见的场景。我们可能需要与外部服务集成,如支付接口、短信接口、天气服务接口等。为了提高代码的可维护性、复用性和易扩展性,封装第三方接口调用的方法非常重要…...
windows10使用bat脚本安装前后端环境之redis注册服务
首先需要搞清楚redis在本地是怎么安装配置、然后在根据如下步骤编写bat脚本: 思路 1.下载zip格式redis 2.查看windows server服务是否已安装redis 3.启动查看服务是否正常 bat脚本 echo off echo windows10 x64 server redis init REM 请求管理员权限并隐藏窗口 …...

fastapp-微信开发GPT项目第一课
0. 开发说明 在学习开发本项目之前,必须保证有以下知识储备和环境工具。 技术栈说明python>3.9、pydantic>2.7.1python基础,http协议fastapi>0.111.0web协程异步框架,有web开发基础,异步编程,类型标注[pyth…...

在双十一必买的好物有哪些?2024年双十一好物清单分享
一年一度的双十一购物狂欢节再次悄然临近,它不仅是一场购物的盛宴,更是我们提前规划生活、享受优惠的绝佳时机,在这个全民狂欢的日子里,各大品牌纷纷亮出杀手锏,推出年度最给力的优惠和新品,让人目不暇接&a…...
避免glibc版本而报错,CentOS等Linux安装node.js完美方法
概述 对于Node.js v18.x或更高,Node.js官方默认是在Ubuntu 20.04, Debian 10, RHEL 8,CentOS 8等高版操作系统上编译得到的,高版本操作系统的glibc版本≥2.28。所以,下载Node.js后,也需要glibc版本≥2.28才能使用。 而CentOS 7.x等…...

elasticsearch实战应用
Elasticsearch是一个基于Lucene的分布式、实时全文搜索引擎,广泛应用于日志收集和可视化、数据分析以及大规模数据检索等领域。其强大的搜索和分析能力,使得Elasticsearch成为许多企业和开发者在处理大规模数据时的首选工具。以下将从Elasticsearch的实战…...
STM32精确控制步进电机
目的:学习使用STM32电机驱动器步进电机,进行电机运动精确控制。 测试环境: MCU主控芯片STM32F103RCT6 ;A4988步进电机驱动器模块; 微型2相4线步…...

Qemu开发ARM篇-5、buildroot制作根文件系统并挂载启动
文章目录 1、 buildroot源码获取2、buildroot配置3、buildroot编译4、挂载根文件系统 在上一篇 Qemu开发ARM篇-4、kernel交叉编译运行演示中,我们编译了kernel,并在qemu上进行了运行,但到最后,在挂载根文件系统时候,挂…...

光控资本:10转10送10股有多少股?转股与送股又什么区别?
10转10送10股是投资者每10股转增10股并送10股,即每10股添加20股,变为30股。 例如,某投资者有1000股,上市公司10转10送10后,投资者将添加2000股,手中持有股票变为3000股。 上市公司进行10转10送10股之后&a…...

【音乐格式转换攻略】6个好用的音乐转换成mp3格式技巧!
现如今,不少用户在将手机下载的歌曲转移到其他设备,如MP3播放器、车载音响或智能音箱时,却遭遇了兼容性难题。尤其是面对一些特殊音频格式,只能在各自的平台播放器上正常播放,一旦尝试在其他设备上打开,往往…...
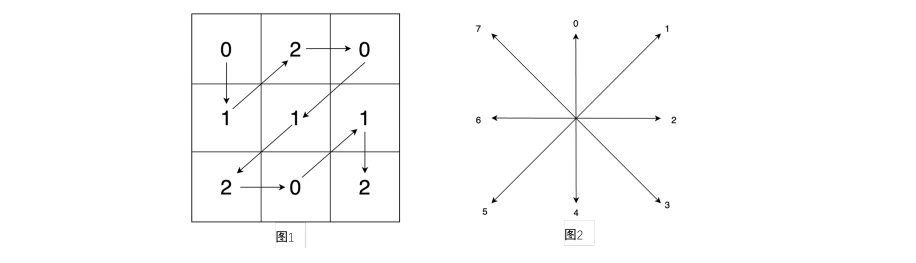
蓝桥杯15届C/C++B组省赛题目
问题描述 小蓝组织了一场算法交流会议,总共有 5050 人参加了本次会议。在会议上,大家进行了握手交流。按照惯例他们每个人都要与除自己以外的其他所有人进行一次握手 (且仅有一次)。但有 77 个人,这 77 人彼此之间没有进行握手 (但这 77 人与…...

感悟:糟糠之妻不下堂和现在女性觉醒的关系
古人说“糟糠之妻不下堂”真是害惨了中国女性,古代之所以有这一说法,大概是因为男子可以三妻四妾,妻子永远是正妻,也不需要讲究什么从一而终,更不会讲什么男德,只会要求女性学习女德、女训之类,…...

Linux网络之UDP与TCP协议详解
文章目录 UDP协议UDP协议数据报报头 TCP协议确认应答缓冲区 超时重传三次握手其他问题 四次挥手滑动窗口流量控制拥塞控制 UDP协议 前面我们只是说了UDP协议的用法,但是并没有涉及到UDP协议的原理 毕竟知道冰箱的用法和知道冰箱的原理是两个层级的事情 我们首先知道计算机网…...
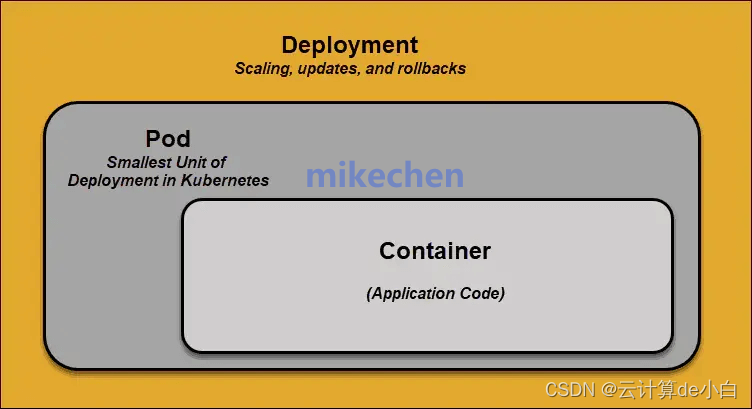
K8S:开源容器编排平台,助力高效稳定的容器化应用管理
云计算de小白 Kubernetes(简称K8s)是一个开源容器编排平台,用于自动化部署、扩展和管理容器化应用程序。 K8S诞生于Google,基于其多年在生产环境运行容器的经验,目前已成为现代微服务架构和云原生应用的核心技术。 图…...

STM32嵌入式编程学习到提高:【4】UART串口打印
------------------------------------------------------------------------------------------------------------------------- 工程文件:放在百度云盘里,需要的自行下载!!! 链接: https://pan.baidu.com/s/14gRne…...

C 标准库 - <ctype.h>
C 标准库 - <ctype.h> 概述 <ctype.h> 是 C 语言标准库中的一个头文件,它提供了一系列用于测试和操作字符的函数。这些函数主要用于检查字符是否属于特定的字符类别,如字母、数字、标点符号等,以及进行字符的大小写转换。<ctype.h> 中的函数通常在处理文…...

linux:chown用法详解
文章目录 1. 描述2. 语法3. 参数4. 例子 1. 描述 chown 是 Linux 中用于更改文件或目录的所有者和所有者组的命令。 2. 语法 chown [选项] 所有者[:组] 文件名详细用法: Usage: chown [OPTION]... [OWNER][:[GROUP]] FILE...or: chown [OPTION]... --reference…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...