【git】一文详解: git rebase到底有啥问题
引子
我反复看到这样的评论:“git rebase 像屎一样”。人们似乎对此有很强烈的感受,我真的很惊讶,因为我没有遇到太多使用 rebase 的问题,而且我一直在使用它。
使用 rebase 的成本有多大?在实际使用中它给你带来了什么问题?我这里只对你遇到的具体糟糕经历感兴趣。
我收到了大量感觉差异的问题,在这里总结它们。如果我知道怎么解决这些问题,也会提到这些问题的解决方案或解决方法。以下是大家的问题列表:
1)反复解决同一冲突很烦人
2)对大量提交进行 rebase 非常困难
3)撤销 rebase 操作很困难
4)强制推送到共享分支可能会导致工作丢失
5)强制推送让代码review更加困难
6)会丢失提交元数据
7)让恢复更困难
8)重新定基可能会破坏中间提交
9)意外地运行了 git commit –amend 而不是 git rebase –continue
10)在交互式 rebase 中拆分提交很困难
11)复杂的 rebase 很难
12)重新定位长期存在的分支可能会很烦人
13)重新定基并提交规则
14)“挤压和合并”工作流程
15)杂项问题
我的目的不是要说服任何人说 rebase 不好,你不应该使用它(我肯定会继续使用 rebase!)。但是看到所有这些问题能让rebase使用的时候更谨慎,而不解释如何安全地使用它。这也让我想知道是否有更简单的工作流程来清理你的提交历史, 而不产生很多的麻烦。
我的 git 工作流程假设
首先,我知道人们使用很多不同的 Git 工作流程。我先说下我在团队中工作时习惯的工作流程,即:
1)团队使用中央 Github/Gitlab 仓库来协调
2)只有一个main分支。它受到保护,不会受到强制推送。
3)人们在功能分支中编写代码并发出拉取main分支请求
4)main每次合并拉取请求时都会部署 Web 服务。
5)进行更改的唯一方法main是在 Github/Gitlab 上发出拉取请求并合并它
这不是唯一“正确的” git 工作流程(它是一种非常典型的“运行 Web 服务”的工作流,而开源项目或发布版的桌面软件通常使用略有不同的工作流程)。但这是我所知道的,所以我将讨论这一点。
两种 rebase
在我们开始之前:我注意到的一件大事是,有两种不同的 rebase 不断出现,其中只有一种需要您处理合并冲突。
1)在历史分支上重新rebase, 例如 `git rebase -i HEAD^^^^^^^`将许多小提交压缩为一个。只要你只是压缩提交,就永远不必在执行此操作时解决合并冲突。2)重新rebase到已经分叉的分支,如`git rebase main`。这可能会导致合并冲突。
我认为做出这种区分很有用,因为有时我正在考虑rebase 到type-1(这不太可能导致问题),但那些为此苦苦挣扎的人正在考虑rebase 到 type-2。
下面让我们把这些烦人的问题一一解决。
反复解决同一冲突很烦人
如果进行多次小提交,有时会陷入地狱般的循环,不得不修复相同的合并冲突 10 次。您还可能完全不必要去修复合并冲突(例如处理未来提交删除的代码中的合并冲突)。
有几种方法可以改善这种情况:
1)首先执行 agit rebase -i HEAD^^^^^^^^^^^ 将所有小提交压缩为1个大提交,然后git rebase main执行 a 重新定位到另一个分支。这样,您只需修复一次冲突。2)用git rerere自动重复解决相同的合并冲突(“rerere” 代表“重用记录的解决方案”,它将记录你以前的合并冲突解决方案并一次执行它们)。我从未尝试过这个,但我认为你可以设置git config rerere.enabled true 然后让它给你提供帮助。
此外,如果我发现自己在重新rebase过程中多次解决合并冲突,我通常会运行git rebase --abort以停止它,然后将我的提交压缩为一个并再试一次。
对大量提交进行 rebase 非常困难
通常,当我对不同的分支进行 rebase 时,我会 rebase 1-2 个提交。有时可能是 5 个!通常不会有冲突,而且运行良好。
有些人描述了将许多不同人的数百个提交重新定位到不同的分支的过程。这听起来确实很困难,这个场景解决不了,很可能有问题。
撤销 rebase 操作很困难
我听几个人说,当他们刚开始接触 rebase 时失败了, 弄丢了一周的代码。
这里的问题是,撤销出错的 rebase比撤销出错的合并要复杂得多(你可以使用类似 的命令撤销错误的合并)git reset --hard HEAD^。许多 rebase 菜鸟没有意识到撤销 rebase 是可能的,我认为这很容易理解。
尽管如此,还是可以撤销出错的 rebase。下面是使用 撤销 rebase 的示例git reflog。
step 1:执行错误的rebase(例如运行git rebase -I HEAD^^^^^ 并删除 3 个提交)
step 2:运行git reflog。会看到类似这样的内容:
ee244c4 (HEAD -> main) HEAD@{0}: rebase (finish): returning to refs/heads/main
ee244c4 (HEAD -> main) HEAD@{1}: rebase (pick): test
fdb8d73 HEAD@{2}: rebase (start): checkout HEAD^^^^^^^
ca7fe25 HEAD@{3}: commit: 16 bits by default
073bc72 HEAD@{4}: commit: only show tooltips on desktop
step 3:找到紧接在之前的条目rebase (start)。在我的例子中,它是ca7fe25
step 4:运行git reset --hard ca7fe25
撤消 rebase 的其他几种方法:
1) 显然@总是指的是 git 中的当前分支,因此您可以运行 git reset --hard @{1}将分支重置到其先前的位置。2) 大家提到的另一个避免使用 reflog 的解决方案是git switch -c backup 在重新rebase之前创建一个“备份分支”,这样就可以轻松返回老的提交。
强制推送到共享分支可能会导致代码丢失
包含如下提到了以下情况:
1)你正在与某人在某个分支上进行协作
2)你推动了一些改变
3)他们重新设置分支并运行git push --force(可能是意外)
4)现在当你运行 git pull,你得到了一个fatal: Need to specify how to reconcile divergent branches错误
5)在尝试处理后果时,你可能会丢失一些提交,特别是如果一些参与的人对 git 不太熟悉
这种情况比“撤消 rebase 失败”的情况更糟糕,因为丢失的提交可能会分散在许多不同的人手中,而比必须搜索 reflog 更糟糕的事情是多个不同的人都去搜索 reflog。
我从来没有遇到过这种情况,因为我曾经合作过的唯一分支是main,并且main一直受到保护,不会强制推送(根据我的经验,唯一可以将某些内容放入的方法main是通过拉取请求)。所以我从来没有真正遇到过这种情况。但我绝对可以理解这会 带来什么问题。
我知道的避免这种情况的主要工具是:
1)不要在共享分支上进行 rebase2)强制推送时使用--force-with-lease,以确保自上次获取后没有其他人推送到该分支
显然,since your last fetch 在这里很重要——如果你在git fetch 之前立即执行 git push --force-with-lease,那么 --force-with-lease 无法保护你。
我很好奇为什么有人会在共享分支上执行 git push --force 。他们给出的一些理由如下:
1)他们正在协作开发一个功能分支,并且该功能分支需要重新rebase到main分支。这里的想法是,你只需非常小心地同步rebase,以免丢失任何内容。2)作为开源维护者,有时他们需要重新rebase贡献者的分支以修复合并冲突3)他们是 git 菜鸟,在网上读到了一些建议`git rebase`和`git push --force`解决方案,并在没有理解后果的情况下就照做了4)他们习惯`git push --force`在个人分支上做,却意外地在共享分支上运行强制推送使代码review更加困难
这里的情况是:
1)你在 GitHub 上发出拉取请求2)人们留下一些评论3)你更新代码以解决注释问题,重新设置基准以清理提交,然后强制推送4)现在,当审阅者回来时,他们很难分辨出自上次看到以来你做了哪些更改——所有的提交都显示为“新的”。
避免这种情况的一种方法是推送解决审核意见的新提交,然后在 PR 获得批准后进行重新rebase以重新组织所有内容。
我认为有些审阅者比其他人更讨厌这个问题,这是一种个人偏好。此外,这可能是 Github 特有的问题,其他代码审查工具可能有更好的工具来解决这个问题。
丢失提交元数据
如果你通过 rebase 来压缩提交,你可能会丢失重要的提交元数据,例如Co-Authored-By。此外,如果你使用 GPG 签名提交,rebase 会丢失签名。
我还没有遇到过这种情况,所以我不知道如何避免。个人认为 GPG 签名提交不像以前那么流行了。
让回复变得更困难
有人提到,对于他们来说,能够轻松地撤销合并任何分支非常重要(以防分支出现问题),并且如果分支包含多个提交并与 rebase 合并,那么你需要执行多次撤销才能撤消提交。
在merge 流程中,我认为只需恢复merge提交即可恢复任何分支的合并。
重新rebase可能会破坏中间提交
如果你尝试拥有一个非常干净的提交历史记录,其中每次提交的测试都通过(非常令人钦佩!),那么即使最终提交通过了测试,重新rebase也可能会导致一些中间提交被破坏并且无法通过测试。
可以通过git rebase -x在 rebase 的每个步骤中运行测试套件并确保测试仍然通过来避免这种情况。但我从未这样做过。
意外地运行git commit --amend而不是git rebase --continue
有人提到了用 git commit --amend而不是git rebase --continue解决合并冲突时的问题。
之所以令人困惑,是因为你可能出于两个原因想要在rebase期间编辑文件:
1)编辑提交(使用editin ),完成时git rebase -i需要写入git commit --amend
2)git rebase --continue合并冲突,完成后需要运行
这两种情况很容易混淆,因为它们感觉非常相似。我认为这里的问题在于你:
1)开始重新定基
2)遇到合并冲突
3)解决合并冲突并运行git add file.txt
4)run :git commit因为这是你跑步后习惯做的事git add
5)你应该运行`git rebase --continue`!现在你有一个奇怪的提交,它可能提交信息和/或作者是错误的。
在交互式 rebase 中拆分提交很困难
rebase 的全部目的是清理历史提交,使用 rebase合并提交非常简单。但是如果你想将一个提交拆分成两个较小的提交怎么办?这并不容易,特别是如果你想拆分的提交是前几个提交!虽然我对 rebase 非常熟悉,但实际上我真的不知道该怎么做。我可能会做点什么,git reset HEAD^^^ 然后git add -p从头开始重做我的所有提交。
复杂的 rebase 很难
如果你尝试在一次操作中做太多事情git rebase -i(重新排序提交、合并提交和修改提交),那么可能会让git操纵变得非常混乱。
为了避免这种情况,我个人倾向于每次 rebase 只做 1 件事,如果我想做 2 件不同的事情,我会做 2 次 rebase,千万别图省事,这样的结果可能会更麻烦
rebase长期存在的分支可能会很烦人
如果你的分支存在时间较长(例如 1 个月),那么反复进行 rebase 会很麻烦。最后只进行 1 次合并并仅解决一次冲突可能更简单。
理想情况是通过不留那些长期的分支来避免这个问题,但在实践中并不总是能实现这一点。
其他问题
还有一些我认为不太常见的问题:
1)错误地停止 rebase: 如果你尝试使用 `git reset --hard`而不是 git rebase --abort 来中止一个运行不正常的rebase ,那么事情会变得很奇怪,直到你正确地停止它。建议用 git rebase --abort 2)与合并提交的奇怪交互:关于此的几句话:“如果你重新rebase工作副本以保持分支的干净历史记录,但底层项目使用merges,结果可能会很糟糕。如果执行 rebase -i HEAD~4 并且第四次提交是合并,你可以在交互式编辑器中看到数十个提交。",我已经吸取了惨痛的教训,如果我合并了另一个分支中的任何内容,永远不要重新rebase"
重新定基并提交规则
我看到很多人在争论 rebase。我一直在思考这是为什么,并且我注意到人们实践着几个不同级别的“提交原则”:
1) 几乎什么都可以,“wip”,“fix”,“idk”,“添加东西”2)当你发出拉取请求(在 github/gitlab 上)时,将所有糟糕的提交压缩为一个带有合理消息(通常是 PR 标题)的提交3)原子精美提交 - 每个更改都被拆分为适当数量的提交,每个提交都有一个很好的提交消息,并且它们都讲述了你所做的更改的故事
我经常认为同一家公司内的不同人有不同级别的提交纪原则,我也经常看到人们为此争论不休。就我个人而言,我大多是 2 级的人。我认为 3 级可能就是人们所说的“清除提交历史”的意思。
我认为级别 1 和级别 2 无需 rebase 就很容易实现 - 对于级别 1,您无需执行任何操作,而对于级别 2,您可以在 github 上 按 squash and merge 或在命令行上运行git switch main; git merge --squash mybranch。
但是对于第 3 级,您要么需要 rebase 要么需要其他工具(例如 GitUp)来帮助你组织提交以完善它。
我一直在想,当人们争论是否“应该”使用 rebase 时,他们实际上是在争论应该要求哪种最低级别的提交原则。
我认为结果如何还取决于人们所做的更改有多大 —— 如果人们通常都会提出很小的拉取请求,那么将它们压缩成 1 次提交并不是什么大问题,但如果正在进行 6000 行的更改,可能需要将其拆分为多次提交。
“squash and merge”工作流
有几个人提到使用这个不使用rebase的工作流程:
1)做出提交2)定期运行git merge main将主要内容合并到分支中(如有必要,修复冲突)3)完成后,使用 GitHub 的“压缩和合并”功能(相当于运行git checkout main; git merge --squash mybranch)将所有更改压缩为 1 个提交。这样可以摆脱所有“丑陋的”合并提交。
我原本以为这会让我的分支上的提交日志太难看,但显然 git log main..mybranch 只会向你显示分支上的更改,如下所示:
$ git log main..mybranch
756d4af (HEAD -> mybranch) Merge branch 'main' into mybranch
20106fd Merge branch 'main' into mybranch
d7da423 some commit on my branch
85a5d7d some other commit on my branch
当然,这里的目标不是强迫那些做出了漂亮原子提交的人压缩他们的提交 - 它只是为人们提供一个简单的选项来清理混乱的提交历史(“添加新功能;wip;wip;fix;fix;fix;“)而不必使用rebase。
我很好奇想听听其他人使用这种工作流的情况以及它是否运行良好。
问题比我想象的要多
我当时真的觉得“rebase 没问题,还能出什么问题?”但实际上,很多这些问题过去都发生在我身上,只是这些年来我已经学会了如何避免或修复所有这些问题。
除了“永远不要强制推送到共享分支”之外,我从未真正看到过任何人分享 rebase 的最佳实践。老实说,所有这些都让我更不愿意推荐使用 rebase。
总结一下,我认为这些是我遵循的个人 rebase 规则:
1)如果情况不好,请停止 rebase,而不是让它完成(使用git rebase --abort)
2)知道如何git reflog撤消错误的 rebase
3)不要重新设置一百万个微小的提交(而是分两步进行:git rebase -i HEAD^^^^然后git rebase main)
4)不要一次性做多件事git rebase -i。保持简单。
5)永远不要强制推送到共享分支
6)永远不要重新定位已经推送的提交main
相关文章:

【git】一文详解: git rebase到底有啥问题
引子 我反复看到这样的评论:“git rebase 像屎一样”。人们似乎对此有很强烈的感受,我真的很惊讶,因为我没有遇到太多使用 rebase 的问题,而且我一直在使用它。 使用 rebase 的成本有多大?在实际使用中它给你带来了什…...
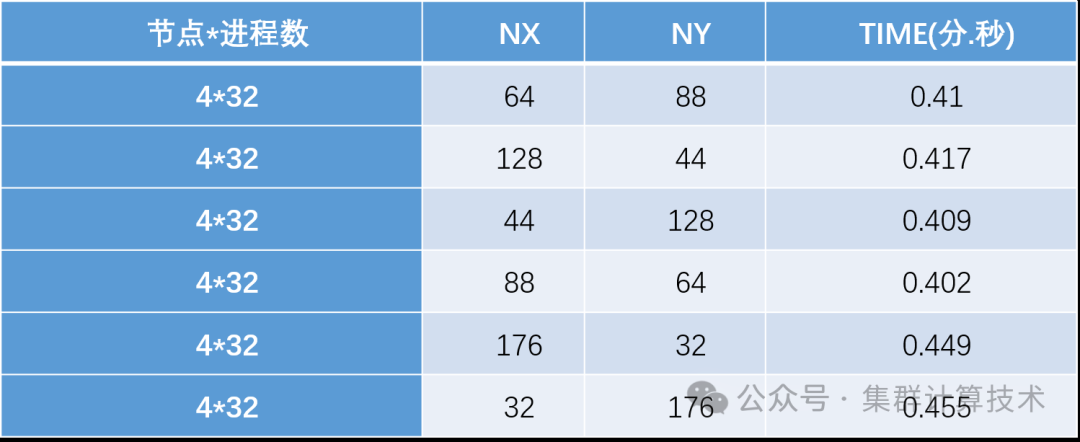
高性能计算应用优化实践之WRF
WRF(Weather Research Forecast)模式是由美国国家大气研究中心(NCAR)、国家环境预报中心(NCEP)等机构自1997年起联合开发的新一代高分辨率中尺度天气研究预报模式,重点解决分辨率为1~…...

nsight-compute使用教程
一 安装 有的时候在linux上安装上了nsight-compute,可以生成报告,但是却因为缺少qt组件而无法打开,我选择的方法是在linux上生成报告,在window上的nsight compute的图形界面打开,需要注意的是,nsight compute图形界面的版本一定要更高,不然无法打开 二 使用 2.1 生成…...

【深度学习】03-神经网络01-4 神经网络的pytorch搭建和参数计算
# 计算模型参数,查看模型结构,我们要查看有多少参数,需要先安装包 pip install torchsummary import torch import torch.nn as nn from torchsummary import summary # 导入 summary 函数,用于计算模型参数和查看模型结构# 创建神经网络模型类 class Mo…...

我与Linux的爱恋:命令行参数|环境变量
🔥个人主页:guoguoqiang. 🔥专栏:Linux的学习 文章目录 一.命令行参数二.环境变量1.环境变量的基本概念2.查看环境变量的方法3.环境变量相关命令4.环境变量的组织方式以及获取环境变量的三种方法 环境变量具有全局属性 一…...

django drf 统一Response格式
场景 需要将响应体按照格式规范返回给前端。 例如: 响应体中包含以下字段: {"result": true,"data": {},"code": 200,"message": "ok","request_id": "20cadfe4-51cd-42f6-af81-0…...

SM2协同签名算法中随机数K的随机性对算法安全的影响
前面介绍过若持有私钥d的用户两次SM2签名过程中随机数k相同,在对手获得两次签名结果Sig1和Sig2的情况下,可破解私钥d。 具体见SM2签名算法中随机数K的随机性对算法安全的影响_sm2关闭随机数-CSDN博客 另关于SM2协同签名过程,具体见SM2协同签…...

解决setMouseTracking(true)后还是无法触发mouseMoveEvent的问题
如图,在给整体界面设置鼠标追踪且给ui界面的子控件也设置了鼠标追踪后,运行后的界面仍然有些地方移动鼠标无法触发 mouseMoveEvent函数,这就令人头痛。。。 我的解决方法是:重载event函数: 完美解决。。。...

基于深度学习的花卉智能分类识别系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 传统的花卉分类方法通常依赖于专家的知识和经验,这种方法不仅耗时耗力,而且容易受到主观因素的影响。本系统利用 TensorFlow、Keras 等深度学习框架构建卷积神经网络&#…...

Springboot集成MongoDb快速入门
1. 什么是MongoDB 1.1. 基本概念 MongoDB是一个基于分布式文件存储 [1] 的数据库。由C语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数…...

DERT目标检测—End-to-End Object Detection with Transformers
DERT:使用Transformer的端到端目标检测 论文题目:End-to-End Object Detection with Transformers 官方代码:https://github.com/facebookresearch/detr 论文题目中包括的一个创新点End to End(端到端的方法)简单的理解就是没有使…...

软件后端开发速度慢的科技公司老板有没有思考如何破局
最近接到两个科技公司咨询,说是他们公司后端开发速度太慢,前端程序员老等着,后端程序员拖了项目进度。 这种问题不只他们公司,在软件外包公司中,有一部分项目甲方客户要得急,以至于要求软件开发要快&#…...

开放原子超级链内核XuperCore可搭建区块链
区块链是一种分布式数据库技术,它以块的形式存储数据,并使用密码学方法保证数据的安全性和完整性。 每个块包含一定数量的交易信息,并通过加密链接到前一个块,形成一个不断增长的链条。 这种设计使得数据在网络中无法被篡改,因为任何尝试修改一个块的数据都会破坏整个链的…...

【Qualcomm】高通SNPE框架的使用 | 原始模型转换为量化的DLC文件 | 在Android的CPU端运行模型
目录 ① 激活snpe环境 ② 设置环境变量 ③ 模型转换 ④ run on Android 首先,默认SNPE工具已经下载并且Setup相关工作均已完成。同时,拥有原始模型文件,本文使用的模型文件为SNPE 框架示例的inception_v3_2016_08_28_frozen.pb文件。imag…...

C++map与set
文章目录 前言一、map和set基础知识二、set与map使用示例1.set去重操作2.map字典统计 总结 前言 本章主要介绍map和set的基本知识与用法。 一、map和set基础知识 map与set属于STL的一部分,他们底层都是是同红黑树来实现的。 ①set常见用途是去重 ,set不…...

随手记:前端一些定位bug的方法
有时候接到bug很烦躁,不管是任何环境的bug,看到都影响心情,随后记总结一下查看bug的思路,在摸不着头脑的时候或者焦虑的时候,可以静下心来顺着思路思考和排查bug可能产生的原因 1.接到bug,最重要的是&am…...

【深度学习】03-神经网络2-1损失函数
在神经网络中,不同任务类型(如多分类、二分类、回归)需要使用不同的损失函数来衡量模型预测和真实值之间的差异。选择合适的损失函数对于模型的性能至关重要。 这里的是API 的注意⚠️,但是在真实的公式中,目标值一定是…...

Python爬虫APP程序:构建智能化数据抓取工具
在信息爆炸的时代,数据的价值日益凸显。Python作为一种强大的编程语言,与其丰富的库一起,为爬虫程序的开发提供了得天独厚的优势。本文将探讨如何使用Python构建一个爬虫APP程序,以及其背后的思维逻辑。 什么是Python爬虫APP程序&…...

第五部分:2---中断与信号
目录 操作系统如何得知哪个外部资源就绪? 什么是中断机制? CPU引脚和中断号的关系: 中断向量表: 信号和中断的关系: 操作系统如何得知哪个外部资源就绪? 操作系统并不会主动轮询所有外设来查看哪些资源…...
:SQL Server Query Optimizer 简介)
梧桐数据库(WuTongDB):SQL Server Query Optimizer 简介
SQL Server Query Optimizer 是 SQL Server 数据库引擎的核心组件之一,负责生成查询执行计划,以优化 SQL 查询的执行性能。它的目标是根据查询的逻辑结构和底层数据的统计信息,选择出最优的查询执行方案。SQL Server Query Optimizer 采用基于…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...
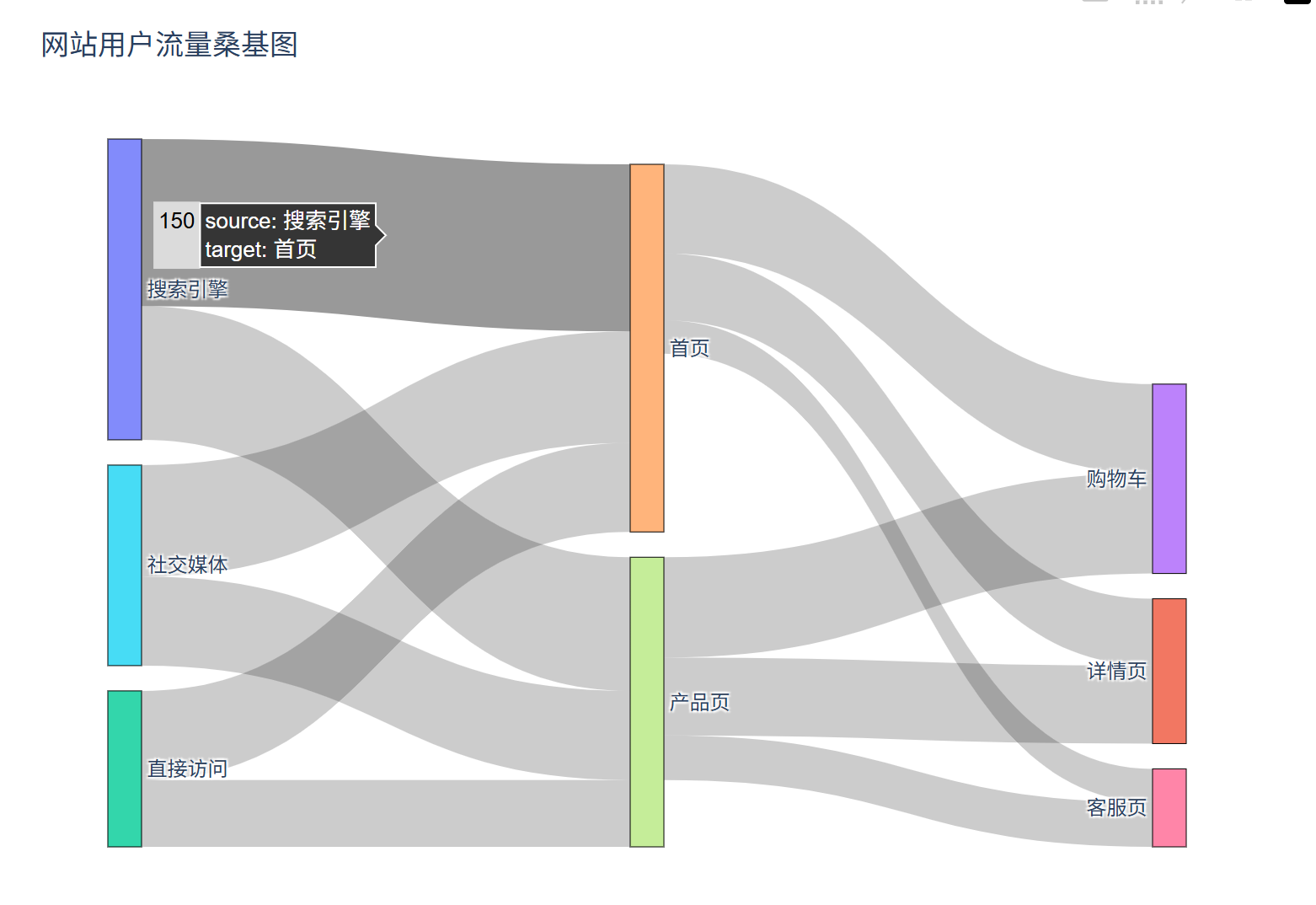
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...
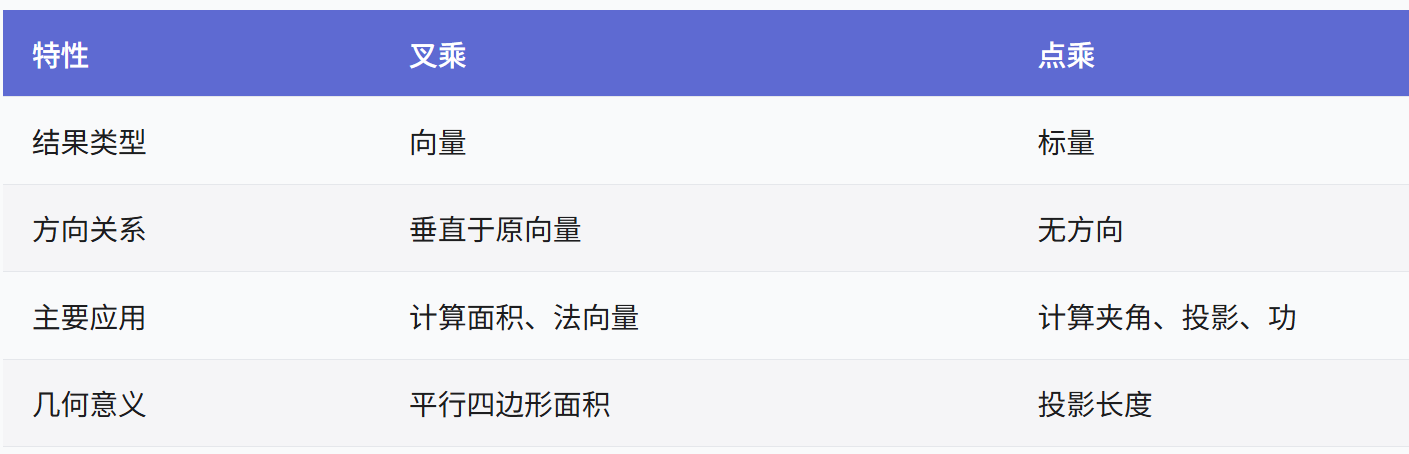
向量几何的二元性:叉乘模长与内积投影的深层联系
在数学与物理的空间世界中,向量运算构成了理解几何结构的基石。叉乘(外积)与点积(内积)作为向量代数的两大支柱,表面上呈现出截然不同的几何意义与代数形式,却在深层次上揭示了向量间相互作用的…...

MySQL体系架构解析(三):MySQL目录与启动配置全解析
MySQL中的目录和文件 bin目录 在 MySQL 的安装目录下有一个特别重要的 bin 目录,这个目录下存放着许多可执行文件。与其他系统的可执行文件类似,这些可执行文件都是与服务器和客户端程序相关的。 启动MySQL服务器程序 在 UNIX 系统中,用…...