Spring Boot 应用Kafka讲解和案例示范
Kafka 是一款高吞吐量、低延迟的分布式消息系统。本文将详细介绍如何在 Spring Boot 项目中使用 Kafka 进行消息接收与消费,并结合幂等和重试机制,确保消息消费的可靠性和系统的扩展性。我们将以电商交易系统为案例进行深入解析。
1. 系统架构概览
在电商系统中,Kafka 常用于订单状态变更、库存变化等事件的异步处理。
+----------------+ Kafka +----------------+
| 订单服务 | ---> Produce ---> | 消费服务 |
| (Order Service)| Topic | (Consumer Service)|
+----------------+ +----------------+| |MySQL MySQL
主要流程:
- 订单服务:接收用户订单请求后,异步将订单信息发送到 Kafka。
- 消费服务:从 Kafka 中消费订单信息,更新库存、生成发货信息等操作。
- 数据库:使用 MySQL 存储订单和库存数据,并通过 MyBatis 实现持久化操作。
2. Kafka 的基础介绍
Kafka 是一种基于发布-订阅模式的消息系统,支持高吞吐、分区与复制等机制,具备容错和可扩展的特点。它的主要组成部分有:
- Producer(生产者):向 Kafka 的 Topic 发送消息。
- Consumer(消费者):从 Kafka 的 Topic 读取消息。
- Broker(代理):Kafka 的服务器集群。
- Topic(主题):消息的分类单位。
- Partition(分区):用于分布式处理消息。
3. 项目环境搭建
3.1 Maven 依赖
在 Spring Boot 项目中,我们通过 spring-kafka 提供对 Kafka 的集成。还需要引入 MyBatis 和 MySQL 相关依赖。
<dependencies><!-- Spring Boot Kafka --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><!-- MySQL Driver --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!-- MyBatis --><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.0</version></dependency><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Lombok (可选,用于简化代码) --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency>
</dependencies>
3.2 数据库表结构设计
为实现电商系统的消息接收与消费,以下是两个主要数据库表:订单表和消费记录表。
- 订单表(
orders):存储订单的基础信息。 - 消费记录表(
message_consume_record):记录消费过的消息,用于幂等校验。
CREATE TABLE orders (id BIGINT AUTO_INCREMENT PRIMARY KEY,order_no VARCHAR(64) NOT NULL,user_id BIGINT NOT NULL,total_price DECIMAL(10, 2) NOT NULL,status INT NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);CREATE TABLE message_consume_record (id BIGINT AUTO_INCREMENT PRIMARY KEY,message_key VARCHAR(64) NOT NULL UNIQUE,consumed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
4. Kafka 消息生产与接收实现
4.1 生产者配置
在 Spring Boot 中,我们可以通过 KafkaTemplate 发送消息。首先,在 application.yml 中配置 Kafka 的基础信息:
spring:kafka:bootstrap-servers: localhost:9092producer:retries: 3key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
bootstrap-servers: 这是 Kafka 服务的地址,Kafka 集群通常由多个 Broker 组成,每个 Broker 提供消息的存储与转发功能。这里指定了本地的 Kafka 服务器(localhost:9092),如果有多个 Broker,可以用逗号分隔(例如:localhost:9092,localhost:9093)。
retries: 当消息发送失败时,生产者将重试发送的次数。这里配置了 3 次重试。这在网络不稳定或 Kafka 节点暂时不可用时非常有用,可以有效提高消息发送成功率。
key-serializer: 生产者发送的消息可以有一个键值对。key-serializer 用于将消息的键序列化为字节数组。这里使用了 StringSerializer,表示消息的键是字符串形式,序列化为字节后发送。
value-serializer: 类似于键,value-serializer 用于将消息的值序列化为字节数组。配置 StringSerializer 表示消息内容是字符串。
4.2 消息生产示例
@Service
public class OrderProducer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendOrderMessage(String orderId) {kafkaTemplate.send("order-topic", orderId);}
}
在 OrderService 中,用户提交订单后,可以将订单 ID 发送至 Kafka:
@Service
public class OrderService {@Autowiredprivate OrderProducer orderProducer;public void createOrder(OrderDTO order) {// 保存订单逻辑...orderProducer.sendOrderMessage(order.getOrderId());}
}
5. 消息消费实现
5.1 消费者配置
在消费者中,我们需要定义 @KafkaListener 注解监听 Kafka 主题,并从中接收消息。
spring:kafka:consumer:group-id: order-groupauto-offset-reset: earliestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
group-id: 消费者组 ID。Kafka 允许多个消费者组监听同一个 Topic,每个消费者组可以独立消费消息。此处配置 order-group,意味着该消费者属于订单消费逻辑的消费者组。
auto-offset-reset: 指定消费者在没有初始偏移量(offset)或当前偏移量无效的情况下,从哪里开始读取消息。earliest 表示从最早的可用消息开始消费,这对于新启动的消费者非常有用,能够确保读取历史数据。
key-deserializer: 将接收到的消息键从字节数组反序列化为 Java 对象。这里配置 StringDeserializer,表示键是字符串。
value-deserializer: 类似于键的反序列化,value-deserializer 用于将消息内容反序列化为 Java 对象。配置 StringDeserializer,表示消息内容是字符串。
5.2 消息消费示例
@Service
public class OrderConsumer {@Autowiredprivate OrderService orderService;@KafkaListener(topics = "order-topic", groupId = "order-group")public void consumeOrder(String orderId) {orderService.processOrder(orderId);}
}
在 OrderService 中,处理接收到的订单消息:
@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;@Transactionalpublic void processOrder(String orderId) {// 根据订单 ID 更新订单状态、库存等操作Order order = orderMapper.findById(orderId);// 更新订单逻辑...}
}
6. 幂等性保证
Kafka 的消息消费可能会因为网络问题或其他故障导致重复消费,因此在消费消息时需要考虑幂等性。我们可以通过在数据库中存储每个消息的唯一标识来实现幂等。
6.1 幂等校验实现
在消费消息时,首先检查该消息是否已经被消费过:
@Service
public class OrderConsumer {@Autowiredprivate MessageConsumeRecordMapper consumeRecordMapper;@KafkaListener(topics = "order-topic", groupId = "order-group")public void consumeOrder(String orderId) {if (consumeRecordMapper.existsByMessageKey(orderId)) {// 如果已经处理过该消息,直接返回return;}// 处理订单orderService.processOrder(orderId);// 记录已处理消息consumeRecordMapper.insertConsumeRecord(orderId);}
}
MessageConsumeRecordMapper 接口用于操作消费记录表:
@Mapper
public interface MessageConsumeRecordMapper {boolean existsByMessageKey(String messageKey);void insertConsumeRecord(String messageKey);
}
通过这种方式,我们确保了每条消息只被消费一次,避免重复处理订单数据。
7. 重试机制实现
为了保证消息的可靠消费,可能会需要对消费失败的消息进行重试。Kafka 提供了自动重试机制,但在多次重试失败后,仍然可能需要手动处理。因此,我们可以通过将消费失败的消息保存至数据库,并定期进行重试的方式,实现可靠的消息处理。
7.1 消费失败记录表设计
CREATE TABLE failed_message (id BIGINT AUTO_INCREMENT PRIMARY KEY,message_key VARCHAR(64) NOT NULL,payload TEXT NOT NULL,failed_reason TEXT,retry_count INT DEFAULT 0,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
7.2 重试机制实现
在消费消息失败时,将消息记录到失败表中,并定期进行重试。
@Service
public class OrderConsumer {@Autowiredprivate FailedMessageMapper failedMessageMapper;@KafkaListener(topics = "order-topic", groupId = "order-group")public void consumeOrder(String orderId) {try {orderService.processOrder(orderId);} catch (Exception e) {failedMessageMapper.insertFailedMessage(orderId, e.getMessage());}}
}
通过定时任务或手动触发,定期查询失败的消息并重新消费:
@Service
public class FailedMessageRetryService {@Autowiredprivate FailedMessageMapper failedMessageMapper;@Scheduled(fixedDelay = 60000) // 每分钟重试一次public void retryFailedMessages() {List<FailedMessage> failedMessages = failedMessageMapper.findAll();for (FailedMessage message : failedMessages) {try {orderService.processOrder(message.getPayload());failedMessageMapper.deleteById(message.getId());} catch (Exception e) {failedMessageMapper.incrementRetryCount(message.getId());}}}
}
8. 扩展性设计
为了使系统具备良好的扩展性,我们需要考虑以下几个方面:
8.1 支持多种消息格式
除了支持 Kafka 消息,我们可以通过设计合理的接口结构,扩展系统支持其他消息队列或 HTTP 请求的接入。例如,通过创建统一的 MessageConsumer 接口,任何类型的消息都可以实现消费逻辑。
public interface MessageConsumer {void consume(String payload);
}@Service
public class KafkaOrderConsumer implements MessageConsumer {@Overridepublic void consume(String payload) {// Kafka 消息消费逻辑}
}
通过这种设计,可以轻松添加新的消息类型或处理逻辑,而不需要修改现有代码。
8.2 动态配置
为了增强系统的灵活性,系统可以支持通过数据库或配置文件动态调整消息消费逻辑。例如,可以在配置文件中定义不同业务的消费逻辑:
message-consumers:order:type: kafkatopic: order-topicuser:type: httpurl: http://example.com/user/message
通过读取这些配置,系统可以动态选择不同的消费逻辑,从而增强扩展性。
9. 性能优化
9.1 异步消费
为了提高消费速度,可以将消息的处理逻辑放入线程池中异步执行,从而避免阻塞 Kafka 消费的主线程。
@Async
public void processOrderAsync(String orderId) {orderService.processOrder(orderId);
}
9.2 批量消费
Kafka 支持批量消费消息,这样可以减少 Kafka 客户端与 Broker 之间的交互次数,提升性能。在 Spring Boot 中,可以通过配置 max.poll.records 参数控制每次批量消费的消息数量。
spring:kafka:consumer:max-poll-records: 500
9.3 分区与并行消费
通过为 Kafka 的 Topic 配置多个分区,并为消费者组中的消费者分配不同的分区,可以实现并行消费,从而提升系统的消费能力。
spring:kafka:consumer:concurrency: 3
10. Kafka 防止 MQ 队列堆积太多导致内存溢出问题
在实际的生产环境中,当消费速度低于消息的生产速度时,Kafka 消费者端的消息队列可能会出现堆积。如果消息堆积时间过长,会导致 Kafka 中的分区文件过大,甚至在消费者端可能造成内存溢出。因此,我们需要在架构设计中考虑如何有效防止消息堆积的问题。
以下是一些常见的应对策略:
10.1 提高消费速度
当 Kafka 的消费速度低于生产速度时,最直接的应对措施就是提升消费的速度:
- 并行消费:通过配置 Kafka 消费者的
concurrency参数来增加消费者实例的数量。Kafka 使用分区来进行负载均衡,分区的数量决定了并发消费的能力。因此,增加分区数可以提升消费者的并发处理能力。
spring:kafka:consumer:concurrency: 3 # 配置多个消费者进行并行处理
- 批量消费:通过
max.poll.records参数配置每次拉取的消息数量。增加批量消费可以减少 Kafka 消费者与 Broker 之间的交互,从而提升性能。
spring:kafka:consumer:max-poll-records: 500 # 每次批量拉取 500 条消息
10.2 优化消息处理逻辑
在消费端,消息的处理速度是决定 Kafka 消费效率的关键。因此,需要对消费逻辑进行优化:
- 异步处理:在消息处理完成后再返回响应,可能导致整个消费过程变慢。可以通过使用异步任务处理消息内容,从而避免阻塞 Kafka 消费的主线程。可以结合 Spring 的
@Async注解实现异步处理。
@Async
public void processOrderAsync(String orderId) {// 异步处理订单消息orderService.processOrder(orderId);
}
- 缩短消息处理时间:简化业务逻辑,避免冗长的处理流程。使用缓存等方式减少对数据库的频繁访问,降低 I/O 操作带来的性能开销。
10.3 调整 Kafka 生产者端的速率
生产者端的消息发送速率直接影响消息的堆积情况。当消费端无法跟上生产端的速度时,适当限制生产者的消息发送速率是一个有效的策略:
- 限流机制:在生产者端通过限流策略,控制每秒钟向 Kafka 发送的消息数量,确保消费者有足够的时间处理消息。例如,可以使用
RateLimiter实现限流。
RateLimiter rateLimiter = RateLimiter.create(1000); // 每秒最多发送 1000 条消息public void sendMessage(String topic, String message) {rateLimiter.acquire(); // 获取许可kafkaTemplate.send(topic, message);
}
- 分布式限流:如果消息的生产端部署在多个节点上,可以使用 Redis 等工具实现分布式限流。
10.4 设置合适的消费位移提交策略
Kafka 消费者有两种提交消费位移的方式:自动提交和手动提交。默认情况下,Kafka 会每隔一段时间自动提交消费位移。如果消费端发生异常,未能处理的消息在下次重新拉取时会再次被消费。为了避免消息重复消费,我们可以将消费位移的提交改为手动提交,确保消息处理完后再提交位移。
spring:kafka:consumer:enable-auto-commit: false # 关闭自动提交位移
手动提交消费位移:
try {// 消费处理消息processMessage(record);// 手动提交位移acknowledgment.acknowledge();
} catch (Exception e) {// 处理异常
}
10.5 配置 Kafka 消息保留策略
如果消息堆积严重,可以通过 Kafka 的 retention.ms 参数设置消息的存储时间,确保超过存储时间的消息自动删除,防止 Kafka 分区文件无限制增长。
log.retention.ms=604800000 # 配置 Kafka 日志文件的保留时间,单位为毫秒,这里设置为 7 天
此外,可以通过配置 log.retention.bytes 来限制 Kafka 每个分区的日志文件大小,确保超出大小限制后自动删除最早的消息。
log.retention.bytes=1073741824 # 配置 Kafka 分区日志文件的最大大小,单位为字节,这里设置为 1 GB
10.6 使用 Kafka 消息压缩
对于大数据量的消息,可以启用 Kafka 消息压缩功能,减少消息的占用空间,从而提升生产和消费的效率。Kafka 支持多种压缩算法,包括 GZIP、LZ4 和 SNAPPY。
spring:kafka:producer:compression-type: gzip # 启用 GZIP 压缩
压缩不仅可以减少网络传输的数据量,还可以降低 Kafka Broker 和消费端的存储压力,从而减少消息堆积的可能性。
相关文章:

Spring Boot 应用Kafka讲解和案例示范
Kafka 是一款高吞吐量、低延迟的分布式消息系统。本文将详细介绍如何在 Spring Boot 项目中使用 Kafka 进行消息接收与消费,并结合幂等和重试机制,确保消息消费的可靠性和系统的扩展性。我们将以电商交易系统为案例进行深入解析。 1. 系统架构概览 在电…...

以到手价为核心的品牌电商价格监测
在当今竞争激烈的电商时代,品牌的价格监测至关重要。传统的页面价监测已无法满足品牌对渠道管控的需求,而到手价监测则成为品牌控价的关键所在。 力维网络,作为深耕数据监测服务多年的专业机构,拥有自主开发的数据监测系统&#…...

Android中使用RecyclerView制作横向轮播列表及索引点
在Android开发中,RecyclerView是一个非常强大的组件,用于展示列表数据。它不仅支持垂直滚动,还能通过配置不同的LayoutManager实现横向滚动,非常适合用于制作轮播图或横向列表。本文将详细介绍如何使用RecyclerView在Android应用中…...

Llama 3.1 技术研究报告-2
3.3 基础设施、扩展性和效率 我们描述了⽀持Llama 3 405B⼤规模预训练的硬件和基础设施,并讨论了⼏项优化措施,这些措施提⾼了训练效率。 3.3.1 训练基础设施 Llama 1和2模型在Meta的AI研究超级集群(Lee和Sengupta,2022&#x…...
【深度学习】05-RNN循环神经网络-02- RNN循环神经网络的发展历史与演化趋势/LSTM/GRU/Transformer
RNN网络的发展历史与演化趋势 RNN(Recurrent Neural Network,循环神经网络)是一类用于处理序列数据的神经网络,特别擅长捕捉数据的时间或上下文依赖性。在其发展的过程中,不断出现各种改进和变体,以解决不…...

C++学习9.27
1、顺序表、栈、队列都更改成模板类 (1)顺序表 #include <iostream> #include <cstring>using namespace std;template <typename T1,typename T2,typename T3> class My_string { private:T1 *ptr; //指向字符数组的指针T2…...

【STM32开发环境搭建】-1-Keil(MDK) 5.27软件安装和注册教程
目录 1 安装前装备工作 2 安装KEIL(MDK-ARM) 5.27软件 3 注册KEIL(MDK-ARM) 5.27软件,获取License许可证 4 手动安装STM32F0,STM32F1,STM32F4,STM32F7,STM32H7的支持包 4.1 下载STM32的支持包 4.2 安装STM32的支…...

武汉正向科技格雷母线公司,无人天车系统,采用格雷母线定位技术
正向科技-格雷母线高精确定位技术-实操视频 高精度格雷母线内胆采用刚性内胆,基板采用精密度数控加工工艺,穿线卡采用高精度模具制作,不采用泡沫板填充,提高了地址检测精度和线性度。 最新一代的格雷母线定位技术特点是全数字化检…...
【保姆级教程】批量下载Pexels视频Python脚本(以HumanVid数据集为例)
目录 方案一:转换链接为download模式 方案二:获取源链接后下载 附录:HumanVid链接 方案一:转换链接为download模式 将下载链接的后缀加入 /download 然后用下面的脚本下载: import argparse import json import o…...
Python画笔案例-067 绘制配乐七角星
1、绘制橙子 通过 python 的turtle 库绘制 配乐七角星,如下图: 2、实现代码 绘制 配乐七角星 ,以下为实现代码: """配乐七角星.py本程序需要coloradd模块支持,安装方法:pip install coloradd""" import turtle from coloradd import color…...

Spark Job 对象 详解
在 Apache Spark 中,Job 对象是执行逻辑的核心组件之一,它代表了对一系列数据操作(如 transformations 和 actions)的提交。理解 Job 的本质和它在 Spark 中的运行机制,有助于深入理解 Spark 的任务调度、执行模型和容…...

C#中NModbus4中常用的方法
NModbus4 是一个用于 Modbus 协议通信的 C# 库,它支持串行 ASCII、RTU、TCP 和 UDP 协议。以下是 NModbus4 中常用的一些方法: 创建连接: ModbusSerialMaster.CreateRtu(SerialPort serialPort): 创建一个 RTU 串行连接。ModbusSerialMaster.…...
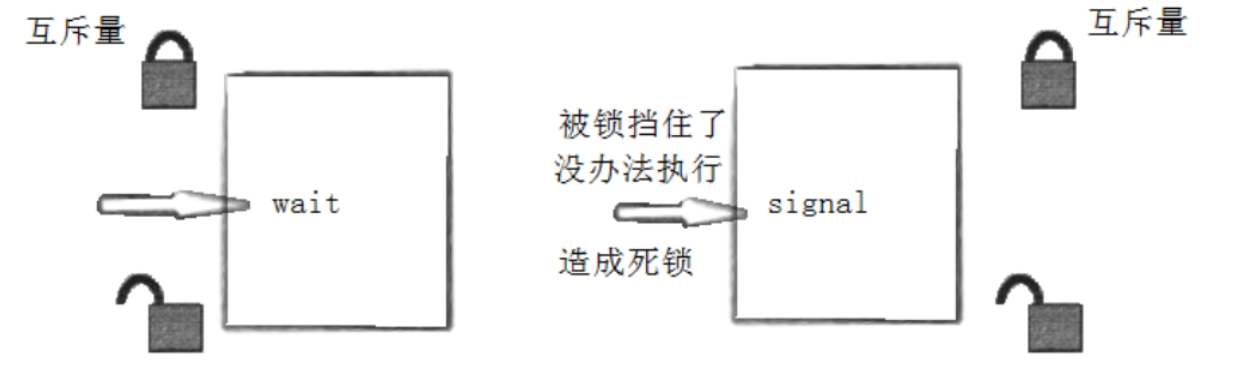
【Linux】线程同步与互斥
一、线程间互斥 1 .进程线程间的互斥相关概念 临界资源:多线程执行流共享的资源就叫做临界资源 临界区:每个线程内部,访问临界资源的代码,就叫做临界区 互斥:任何时刻,互斥保证有且只有一个执行流进入临界…...
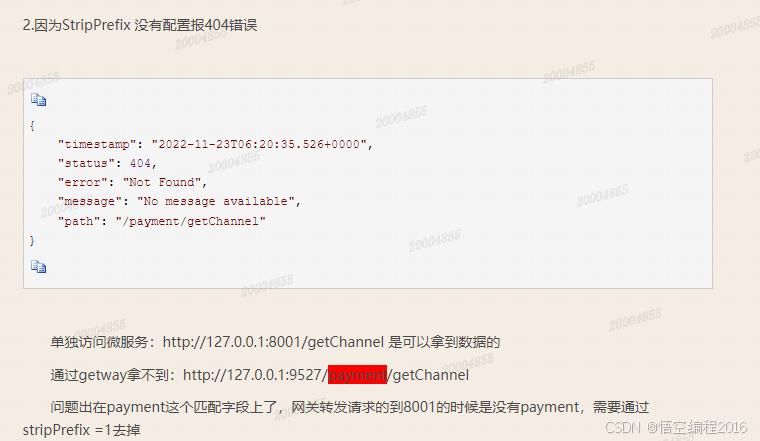
003、网关路由问题
1. nginx配置404跳转回默认路由 https://blog.csdn.net/masteryee/article/details/83689954 https://blog.csdn.net/IbcVue/article/details/133230460 https://www.jb51.net/server/317970ynk.htm https://blog.csdn.net/u014438244/article/details/120531287 https://blog…...

Eclipse 快捷键:提高开发效率的利器
Eclipse 快捷键:提高开发效率的利器 Eclipse 是一款广泛使用的集成开发环境(IDE),它为Java、C、PHP等编程语言提供了强大的开发支持。对于开发者来说,熟练掌握Eclipse的快捷键不仅能提高编码效率,还能减少…...

Agent智能体
Agent(智能体)是一个能够感知环境并采取行动的自主实体,通常被设计用于在特定的环境中执行任务。智能体可以通过学习、推理等方式来决策,目标是最大化某种效用或实现某个预定的目标。它们广泛应用于自动化系统、游戏AI、机器人、自…...

用Promise实现前端并发请求
/** * 构造假请求 */ async function request(url) {return new Promise((resolve) > {setTimeout(() > {resolve(url);},// Math.random() * 500 800,1000,);}); }请求一次,查看耗时,预计应该是1s: async function requestOnce() {c…...
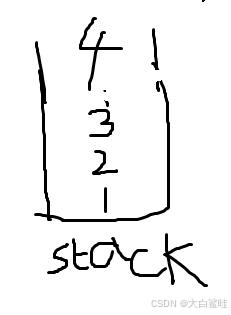
通过队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int to…...
Mac下可以平替paste的软件pastemate,在windows上也能用,还可以实现数据多端同步
Mac平台上非常经典的剪贴板管理工具:「Paste」。作为一款功能完善且易用的工具,「Paste」在实际使用中体现出了许多令人欣赏的特点。但是它是一个收费软件,一年至少要24美元. 现有一平替软件pastemate,功能更加丰富,使用更加方便。 下载地址…...
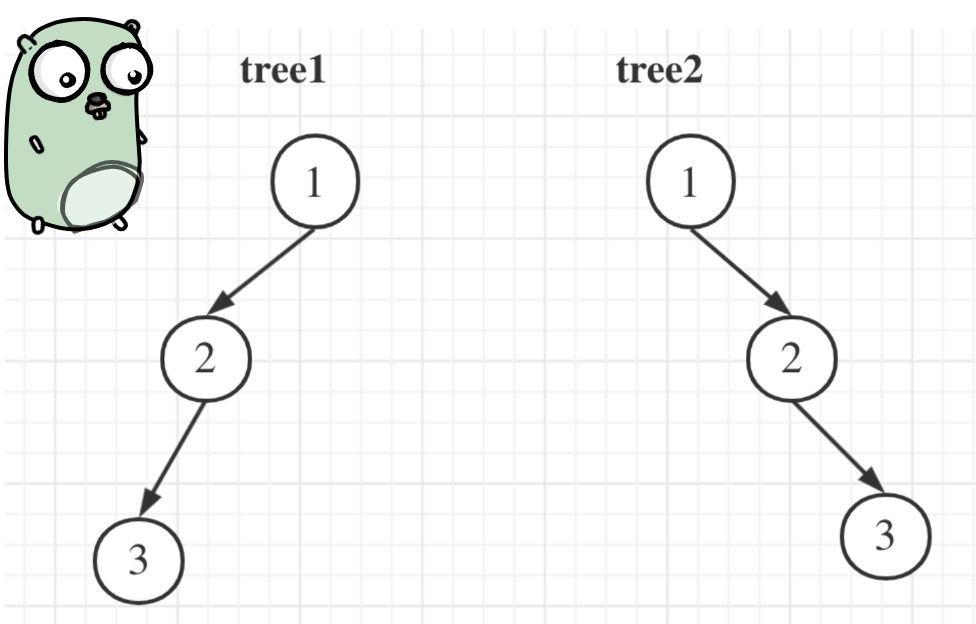
106. 从中序与后序遍历序列构造二叉树
文章目录 106. 从中序与后序遍历序列构造二叉树思路 105. 从前序与中序遍历序列构造二叉树思路 思考 106. 从中序与后序遍历序列构造二叉树 106. 从中序与后序遍历序列构造二叉树 给定两个整数数组 inorder 和postorder,其中 inorder 是二叉树的中序遍历ÿ…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...