优化 Go 语言数据打包:性能基准测试与分析
场景:在局域网内,需要将多个机器网卡上抓到的数据包同步到一个机器上。
原有方案:tcpdump -w 写入文件,然后定时调用 rsync 进行同步。
改造方案:使用 Go 重写这个抓包逻辑及同步逻辑,直接将抓到的包通过网络发送至服务端,由服务端写入,这样就减少了一次落盘的操作。
构造一个 pcap 文件很简单,需要写入一个 pcap文件头,后面每一条数据增加一个元数据进行描述。使用 pcapgo 即可实现这个功能,p.buffer[:ci.CaptureLength] 为抓包的数据。
ci := gopacket.CaptureInfo{CaptureLength: int(n),Length: int(n),Timestamp: time.Now(),
}
if ci.CaptureLength > len(p.buffer) {ci.CaptureLength = len(p.buffer)
}
w.WritePacket(ci, p.buffer[:ci.CaptureLength])为了通过区分是哪个机器过来的数据包需要增加一个 Id,算上元数据和原始数据包,表达结构如下
// from github.com/google/gopacket
type CaptureInfo struct {// Timestamp is the time the packet was captured, if that is known.Timestamp time.Time `json:"ts" msgpack:"ts"`// CaptureLength is the total number of bytes read off of the wire.CaptureLength int `json:"cap_len" msgpack:"cap_len"`// Length is the size of the original packet. Should always be >=// CaptureLength.Length int `json:"len" msgpack:"len"`// InterfaceIndexInterfaceIndex int `json:"iface_idx" msgpack:"iface_idx"`
}type CapturePacket struct {CaptureInfoId uint32 `json:"id" msgpack:"id"`Data []byte `json:"data" msgpack:"data"`
}有一个细节待敲定,抓到的包使用什么结构发送至服务端?json/msgpack/自定义格式?
json/msgpack 都有对应的规范,通用性强,不容易出 BUG,性能会差一点。自定义格式相比 json/msgpack 而言,可以去掉不必要的字段,连 key 都可以不用在序列化中出现,并且可以通过一些优化减少内存的分配,缓解gc压力。
自定义二进制协议优化思路如下
-
CaptureInfo/Id 字段直接固定N个字节表示,对于 CaptureLength/Length 可以直接使用 2 个字节来表达,Id 如果数量很少使用 1 个字节来表达都可以
-
内存复用Encode 逻辑内部不分配内存,这样直接写入外部的 buffer,如果外部 buffer 是同步操作的话,整个逻辑 0 内存分配Decode 内部不分配内存,只解析元数据和复制 Data 切片,如果外部是同步操作,同样整个过程 0 内存分配如果是异步操作,那么在调用 Encode/Decode 的地方对 Data 进行复制,这里可以使用 sync.Pool 进行优化,使用四个 sync.Pool 分别分配 128/1024/8192/65536 中数据
sync.Pool 的优化点有两个
-
异步操作下每个 Packet.Data 都需要有自己的空间,不能进行复用,使用 sync.Pool 来构造属于 Packet 的空间
-
元数据序列化固定字节长度的 buffer,使用 make 或者数组都会触发 gc
func acquirePacketBuf(n int) ([]byte, func()) {var (buf []byteputfn func())if n <= CapturePacketMetaLen+128 {smallBuf := smallBufPool.Get().(*[CapturePacketMetaLen + 128]byte)buf = smallBuf[:0]putfn = func() { smallBufPool.Put(smallBuf) }} else if n <= CapturePacketMetaLen+1024 {midBuf := midBufPool.Get().(*[CapturePacketMetaLen + 1024]byte)buf = midBuf[:0]putfn = func() { midBufPool.Put(midBuf) }} else if n <= CapturePacketMetaLen+8192 {largeBuf := largeBufPool.Get().(*[CapturePacketMetaLen + 8192]byte)buf = largeBuf[:0]putfn = func() { largeBufPool.Put(largeBuf) }} else {xlargeBuf := xlargeBufPool.Get().(*[CapturePacketMetaLen + 65536]byte)buf = xlargeBuf[:0]putfn = func() { xlargeBufPool.Put(xlargeBuf) }}return buf, putfn
}func (binaryPack) EncodeTo(p *CapturePacket, w io.Writer) (int, error) {buf := metaBufPool.Get().(*[CapturePacketMetaLen]byte)defer metaBufPool.Put(buf)binary.BigEndian.PutUint64(buf[0:], uint64(p.Timestamp.UnixMicro()))...return nm + nd, err
}数据包构造大小(By 通义千问)
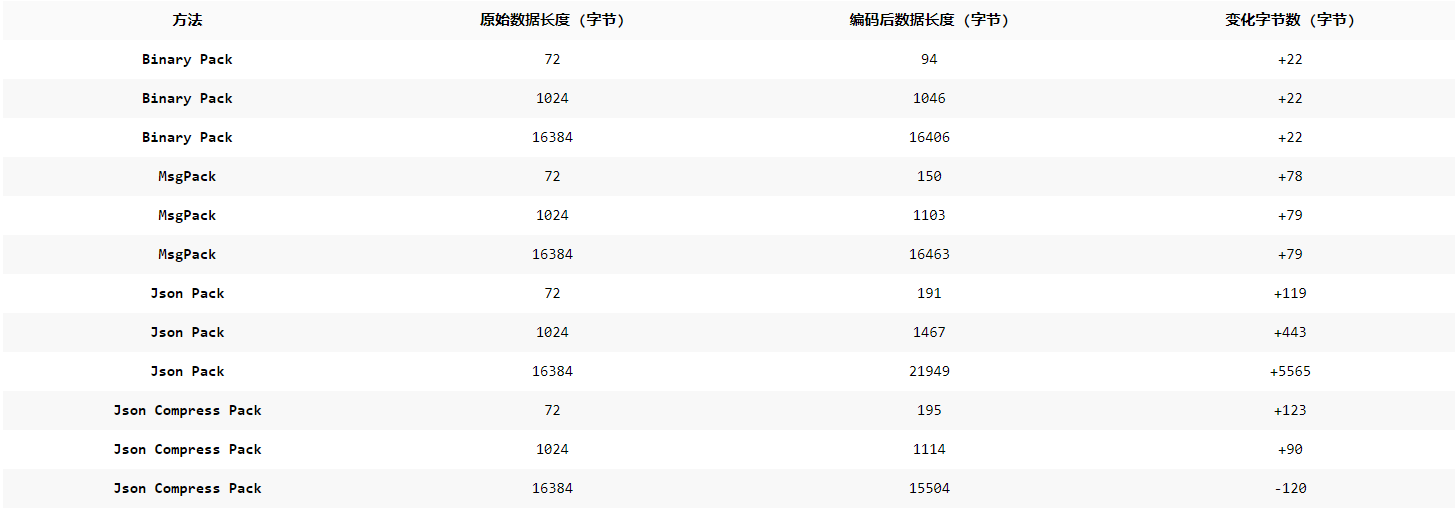
分析
-
Binary Pack:
对于较小的数据(72字节),编码后增加了22字节。
对于较大的数据(16384字节),编码后增加了22字节。
总体来看,Binary Pack的编码效率较高,增加的字节数相对较少。
-
MsgPack:
对于较小的数据(72字节),编码后增加了78字节。
对于较大的数据(16384字节),编码后增加了79字节。
MsgPack的编码效率在小数据量时不如Binary Pack,但在大数据量时仍然保持较高的效率。
-
Json Pack:
对于较小的数据(72字节),编码后增加了119字节。
对于较大的数据(16384字节),编码后增加了5565字节。
Json Pack的编码效率较低,特别是对于大数据量,增加的字节数较多。
-
Json Compress Pack:
对于较小的数据(72字节),编码后增加了123字节。
对于较大的数据(16384字节),编码后增加了120字节。
Json Compress Pack在小数据量时增加的字节数较多,但在大数据量时增加的字节数较少,表明压缩效果较好。
通过这个表格,你可以更直观地看到不同数据打包方法在不同数据量下的表现。希望这对你有帮助!
Benchmark
json
可以看到使用 buffer 进行复用提升比较明显,主要还是减少内存分配带来的提升。
BenchmarkJsonPack/encode#72-20 17315143 647.1 ns/op 320 B/op 3 allocs/op
BenchmarkJsonPack/encode#1024-20 4616841 2835 ns/op 1666 B/op 3 allocs/op
BenchmarkJsonPack/encode#16384-20 365313 34289 ns/op 24754 B/op 3 allocs/op
BenchmarkJsonPack/encode_with_buf#72-20 24820188 447.4 ns/op 128 B/op 2 allocs/op
BenchmarkJsonPack/encode_with_buf#1024-20 13139395 910.6 ns/op 128 B/op 2 allocs/op
BenchmarkJsonPack/encode_with_buf#16384-20 1414260 8472 ns/op 128 B/op 2 allocs/op
BenchmarkJsonPack/decode#72-20 8699952 1364 ns/op 304 B/op 8 allocs/op
BenchmarkJsonPack/decode#1024-20 2103712 5605 ns/op 1384 B/op 8 allocs/op
BenchmarkJsonPack/decode#16384-20 159140 73101 ns/op 18664 B/op 8 allocs/opmsgpack
同样看到使用 buffer 进行复用的提升,和 json 的分水岭大概在 1024 字节左右,超过这个大小 msgpack 速度快很多,并且在解析的时候内存占用不会随数据进行增长。
BenchmarkMsgPack/encode#72-20 10466427 1199 ns/op 688 B/op 8 allocs/op
BenchmarkMsgPack/encode#1024-20 6599528 2132 ns/op 1585 B/op 8 allocs/op
BenchmarkMsgPack/encode#16384-20 1478127 8806 ns/op 18879 B/op 8 allocs/op
BenchmarkMsgPack/encode_with_buf#72-20 26677507 388.2 ns/op 192 B/op 4 allocs/op
BenchmarkMsgPack/encode_with_buf#1024-20 31426809 400.2 ns/op 192 B/op 4 allocs/op
BenchmarkMsgPack/encode_with_buf#16384-20 22588560 494.5 ns/op 192 B/op 4 allocs/op
BenchmarkMsgPack/decode#72-20 19894509 654.2 ns/op 280 B/op 10 allocs/op
BenchmarkMsgPack/decode#1024-20 18211321 664.0 ns/op 280 B/op 10 allocs/op
BenchmarkMsgPack/decode#16384-20 13755824 769.1 ns/op 280 B/op 10 allocs/opjson压缩
在内网的情况下,带宽不是问题,这个压测结果直接被 Pass
BenchmarkJsonCompressPack/encode#72-20 19934 709224 ns/op 1208429 B/op 26 allocs/op
BenchmarkJsonCompressPack/encode#1024-20 17577 766349 ns/op 1212782 B/op 26 allocs/op
BenchmarkJsonCompressPack/encode#16384-20 11757 860371 ns/op 1253975 B/op 25 allocs/op
BenchmarkJsonCompressPack/decode#72-20 490164 28972 ns/op 42048 B/op 15 allocs/op
BenchmarkJsonCompressPack/decode#1024-20 187113 71612 ns/op 47640 B/op 23 allocs/op
BenchmarkJsonCompressPack/decode#16384-20 35790 346580 ns/op 173352 B/op 30 allocs/op自定义二进制协议
对于序列化和反序列化在复用内存后,速度的提升非常明显,在同步的操作下,能做到 0 字节分配。异步场景下,使用 sync.Pool 内存固定字节分配(两个返回值在堆上分配)
BenchmarkBinaryPack/encode#72-20 72744334 187.1 ns/op 144 B/op 2 allocs/op
BenchmarkBinaryPack/encode#1024-20 17048832 660.6 ns/op 1200 B/op 2 allocs/op
BenchmarkBinaryPack/encode#16384-20 2085050 6280 ns/op 18495 B/op 2 allocs/op
BenchmarkBinaryPack/encode_with_pool#72-20 34700313 109.2 ns/op 64 B/op 2 allocs/op
BenchmarkBinaryPack/encode_with_pool#1024-20 39370662 101.1 ns/op 64 B/op 2 allocs/op
BenchmarkBinaryPack/encode_with_pool#16384-20 18445262 177.2 ns/op 64 B/op 2 allocs/op
BenchmarkBinaryPack/encode_to#72-20 705428736 16.96 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/encode_to#1024-20 575312358 20.78 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/encode_to#16384-20 100000000 113.4 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode_meta#72-20 1000000000 2.887 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode_meta#1024-20 1000000000 2.882 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode_meta#16384-20 1000000000 2.876 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode#72-20 100000000 85.63 ns/op 80 B/op 1 allocs/op
BenchmarkBinaryPack/decode#1024-20 7252350 445.4 ns/op 1024 B/op 1 allocs/op
BenchmarkBinaryPack/decode#16384-20 554329 5499 ns/op 16384 B/op 1 allocs/op
BenchmarkBinaryPack/decode_with_pool#72-20 109352595 33.97 ns/op 16 B/op 1 allocs/op
BenchmarkBinaryPack/decode_with_pool#1024-20 85589674 36.27 ns/op 16 B/op 1 allocs/op
BenchmarkBinaryPack/decode_with_pool#16384-20 26163607 140.4 ns/op 16 B/op 1 allocs/op总结一下
通义千问的
Binary Pack:
- encode_to:性能最优,几乎没有内存分配,适用于高性能要求的场景。
- encode_with_pool:使用内存池优化,显著减少了时间和内存开销,适用于大多数场景。
- encode:标准方法,时间和内存开销较高。
MsgPack:
- encode_with_buf:使用预分配的缓冲区,显著减少了时间和内存开销,适用于大多数场景。
- encode:标准方法,时间和内存开销较高。
- decode:解码性能一般,内存开销较高。
Json Pack:
- encode_with_buf:使用预分配的缓冲区,显著减少了时间和内存开销,适用于大多数场景。
- encode:标准方法,时间和内存开销较高。
- decode:解码性能较差,内存开销较高。
Json Compress Pack:
- encode:标准方法,时间和内存开销非常高,不推荐用于高性能要求的场景。
- decode:解码性能较差,内存开销较高。
我总结的
在内网的环境进行传输,一般网络带宽不会成为瓶颈,所以可以不用考虑数据压缩,上面结果也看到压缩非常占用资源;如果对数据内容不关心且数据量非常多的情况下(比如传输 pcap 包),那么使用自定义协议可能更合适一些,固定长度的元数据解析起来优化空间巨大,二进制解析比 json/msgpack 快内存分配也非常少。
文章转载自:文一路挖坑侠
原文链接:https://www.cnblogs.com/shuqin/p/18427020
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
优化 Go 语言数据打包:性能基准测试与分析
场景:在局域网内,需要将多个机器网卡上抓到的数据包同步到一个机器上。 原有方案:tcpdump -w 写入文件,然后定时调用 rsync 进行同步。 改造方案:使用 Go 重写这个抓包逻辑及同步逻辑,直接将抓到的包通过网…...

【SQL】未订购的客户
目录 语法 需求 示例 分析 代码 语法 SELECT columns FROM table1 LEFT JOIN table2 ON table1.common_field table2.common_field; LEFT JOIN(或称为左外连接)是SQL中的一种连接类型,它用于从两个或多个表中基于连接条件返回左表…...

Qt(9.28)
widget.cpp #include "widget.h"Widget::Widget(QWidget *parent): QWidget(parent) {QPushButton *btn1 new QPushButton("登录",this);this->setFixedSize(640,480);btn1->resize(80,40);btn1->move(200,300);btn1->setIcon(QIcon("C:…...

javascript-冒泡排序
前言:好久没学习算法了,今天看了一个视频课,之前掌握很好的冒泡排序居然没写出来? <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport"…...

第九届蓝桥杯嵌入式省赛程序设计题解析(基于HAL库)
一.题目分析 (1).题目 (2).题目分析 按键功能分析----存储位置的切换键 a. B1按下切换存储位置,切换后定时时间设定为当前位置存储的时间 b. B2短按切换时分秒高亮,设置完成后,长按把设置的时…...

MATLAB云计算集成:在云端扩展计算能力
摘要 MATLAB云计算集成是指将MATLAB的计算能力与云平台的弹性资源相结合,以实现高性能计算、数据处理和算法开发。本文详细介绍了MATLAB云计算的基本概念、优势、配置要点以及编程实践。 1. 云计算概述 云计算是一种通过互联网提供计算资源(如服务器、…...

基于BeagleBone Black的网页LED控制功能(flask+gpiod)
目录 项目介绍硬件介绍项目设计开发环境功能实现控制LED外设构建Webserver 功能展示项目总结 👉 【Funpack3-5】基于BeagleBone Black的网页LED控制功能 👉 Github: EmbeddedCamerata/BBB_led_flask_web_control 项目介绍 基于 BeagleBoard Black 开发板…...

【C语言】单片机map表详细解析
1、RO Size、RW Size、ROM Size分别是什么 首先将map文件翻到最下面,可以看到 1.1 RO Size:只读段 Code:程序的代码部分(也就是 .text 段),它存放了程序的指令和可执行代码。 RO Data:只读…...

Java中的继承和实现
Java中的继承和实现在面向对象编程中扮演着不同的角色,它们之间的主要区别可以从以下几个方面进行阐述: 1. 定义和用途 继承(Inheritance):继承是面向对象编程中的一个基本概念,它允许我们定义一个类&…...

uniapp云打包
ios打包 没有mac电脑,使用香蕉云编 先登录香蕉云编这个工具,新建csr文件——把csr文件下载到你电脑本地: 然后,登录苹果开发者中心 生成p12证书 1、点击+号创建证书 创建证书的时候一定要选择ios distribution app store and ad hoc类型的证书 2、上传刚才从本站生成的…...

端口安全技术原理与应用
目录 概述 端口安全原理 端口安全术语 二层安全地址配置 端口模式下配置 全局模式下配置 动态学习 二层数据包处理流程 三层安全地址配置 三层数据包处理流程 端口安全违例动作和安全地址老化时间 查看命令 端口安全的注意事项 小结 概述 园区网的接入安全关系着…...

数据集-目标检测系列-鲨鱼检测数据集 shark >> DataBall
数据集-目标检测系列-鲨鱼检测数据集 shark >> DataBall 数据集-目标检测系列-鲨鱼检测数据集 shark 数据量:6k 数据样例项目地址: gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview github: https://github.com/Te…...

数字乡村解决方案-3
1. 国家大数据战略与数字乡村 中国第十三个五年规划纲要强调实施国家大数据战略,加快建设数字中国,推进数据资源整合和开放共享,保障数据安全,以大数据助力产业转型升级和提高社会治理的精准性与有效性。 2. 大数据与数字经济 …...

WPF文本框无法输入小数点
问题描述 在WPF项目中,文本框BInding双向绑定了数据Text“{UpdateSourceTriggerPropertyChanged}”,但手套数据是double类型,手动输入数据时,小数点输入不进去 解决办法: 在App.xaml.cs文件中添加语句: …...

R开头的后缀:RE
RE表示方位上的向后,一种时空上的折返,和表示否定意味的不。 68.re- 空间顺序 ①表示"向后,相反,不" RE表示正向抵抗的力的词语,和情绪的词语,用来表示一种极力的反抗和拒绝,包括…...

Vue2配置环境变量的注意事项
在实际开发中时常会遇到需要开发环境与生产环境中一些参数的替换,为了方便线上线下环境变量切换可以利用node中的process进行环境变量管理 实现步骤如下: 1.在 根目录 新增环境文件 .env.development 和 .env.production 注意文件名称保持一致( 需要强调的是文件中的变量名切…...

机器学习:探索未知边界,解锁智能潜力
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 在这个日新月异的科技时代,机器学习作为人工智能领域的核心驱动力,正以前所未有的速度改变着我们的世界。从智能家居的个性化推荐到自动驾驶汽车的精准导航,从医疗诊断的辅助…...

万户OA-ezOFFICE fileUpload.controller 任意文件上传漏洞复现
0x01 产品描述: 万户OA(Office Automation)是一款企业级协同办公管理软件,旨在为企业提供全面的办公自动化解决方案。万户ezOFFICE存在任意文件上传漏洞。攻击者可以通过该远程下载任意文件到目标服务器,导致攻击者可获…...
Time-MoE : 时间序列领域的亿级规模混合专家基础模型
Time-MoE : 时间序列领域的亿级规模混合专家基础模型 时间序列预测一直是量化研究和工业应用中的重要课题。随着深度学习技术的发展,大规模预训练模型在自然语言处理和计算机视觉领域取得了显著进展,但在时间序列预测领域,这些模型的规模和运…...

Spring Boot入门指南
前言 Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。本文将详细介绍 Spring Boot 的基本概念、环境搭建、第一…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...