【数据结构初阶】排序算法(中)快速排序专题
文章目录
- 1. 快排主框架
- 2. 快排的不同实现
- 2. 1 hoare版本
- 2. 2 挖坑法
- 2. 3 lomuto前后指针法
- 2. 4 快排的非递归版本
- 3. 快排优化
- 3. 1 快排性能的关键点分析:
- 3. 1 三路划分
- 3. 2 introsort自省排序
1. 快排主框架
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。
其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
简单地说,就是将数组分成左右两个部分,左部分都大于(或小于)中间的基准值,右部分都小于(或大于)中间的基准值,然后不断重复上述过程,直到数组完全有序。
//快排主框架
void QuickSort(int* a, int left, int right)
{if (left >= right)return;int mid = PartSort(a, left, right);QuickSort(a, left, mid - 1);QuickSort(a, mid + 1, right);
}
那么显然快排最关键的就是PartSort这个函数怎么实现了,这个函数要实现:找到基准值并将数据按照大小划分到基准值的两侧。
- 时间复杂度:
O(nlogn) - 空间复杂度:
O(logn)
2. 快排的不同实现
这里的PartSort函数的实现有很多种,这里介绍3种。
2. 1 hoare版本
算法思路
- 创建左右指针,确定基准值
- 从右向左找出比基准值小的数据,从左向右找出比基准值大的数据,左右指针数据交换,进入下次循环
- 跳出循环后,交换
right和key
提问1:为什么跳出循环后right位置的值一定不大于key?
当 left > right 时,即right走到left的左侧,而left扫描过的数据均不大于key,因此right此时指向的数据一定不大于key
提问2:当left==right时要不要跳出循环?
不能,因为此时不知道left和right同时指向的这个值的大小,必须让right或者left额外多走一步。

我们通过这三个场景来分析提问1并详细解释hoare版本的思路:
首先我们选定第一个元素为基准值(实际上选择基准值还有其他更好地方式,但这里先简化),然后将left=1,right=numsSize-1,也就是除了第一个元素外,数组的头和尾。
注:以升序为例。
场景一:
left<key,left++;right > key,right不动。
left++,left++,left指向7。
left和right交换数据,数组变为:
int a[]={6,1,2,3,9,7};
left++,right++,left==right,right指向9。
此时right大于key,肯定不能直接交换,必须再进行一次交换,让left > right,而因为此时right已经走到了left的左边,left的左边一定小于key。
将right与key交换,第一次快排结束,此时数组为:
int a[]={3,1,2,6,9,7};
并将right返回,right就是基准值。
这里调用时,PartSort的返回值就是mid,left和right依然是传入的left和right,
QuickSort(a, left, mid - 1);
QuickSort(a, mid + 1, right);
接下来就是继续递归,left和right(在递归传参时改变)最终会在循环之前就left >= right,递归停止。
场景二:
第一次快排在交换right与key之前的结果是这样的:
int a[]={6,1,2,3,6,7};
left与right相遇在6。
且此时left == right,right指向3。right位置的值不大于key。
场景三:
第一次快排在交换right与key之前的结果是这样的:
left与right相遇在4。
int a[]={6,1,2,3,4,7}; //实际上的步骤和场景二是一样的,只是right位置的值不一样
且此时left == right,right指向3。right位置的值不大于key。
为什么不用left与right交换?
我们来看这个数组:
int a[]={6,1,2,3,7};
left和right在7相遇,left++,right--之后,left指向的位置就已经越界了。
但是right就不会有这个问题,因为我们选中的基准值在最左边,即使在第二个数字相遇,right--之后也不会越界。
代码:
// 快速排序Hoare版本
int PartSort1(int* a, int left, int right)
{int keyi = left; //设定key为最左边的值left++;while (left <= right){while (left <= right && a[left] < a[keyi])left++;while (left <= right && a[right] > a[keyi])right--;if(left <= right) //注意这里要加这个判断,因为上面的两个循环可能是因为left>right结束的Swap(&a[left++], &a[right--]);}Swap(&a[right], &a[keyi]); //将right的值与keyi交换return right;
}
2. 2 挖坑法
思路:
创建左右指针。首先从右向左找出比基准小的数据,找到后立即放入左边坑中,当前位置变为新的"坑",然后从左向右找出比基准大的数据,找到后立即放入右边坑中,当前位置变为新的"坑",结束循环后将最开始存储的分界值放入当前的"坑"中,返回当前"坑"下标(即分界值下标)。
int a[]={6,1,2,7,9,3,4,5,10,8};
我们以这个数组为例,分析挖坑法的步骤:
首先将6挖成坑,并将6存成key。
int hole = left;
int key = a[left];
先从右边开始遍历,到5时a[right] > key,停下遍历,将right的值放到坑中,并将right的位置挖成坑:
a[hole] = a[right]; //把right的值放进坑中
hole = right; //把right挖成新的坑
再从左边遍历,到7时,停下遍历,将left的值放到坑中,并将left的位置挖成坑。
重复上述过程,直到left > right,把最开始的key放进现在的坑中。
挖坑法实际上和hoare版本的原理差不多,只不过是挖坑填坑这个动作代替了交换,并没有本质的变化。
代码:
// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{int hole = left;int key = a[left];while (left < right){//右边找while (left < right && a[right] >= key)right--;a[hole] = a[right]; //赋值与挖坑hole = right;while (left < right && a[left] <= key)left++;a[hole] = a[left];hole = left;}a[hole] = key; //把key放进坑里return hole; //最后的坑就是基准值的位置
}
2. 3 lomuto前后指针法
创建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。
前指针prev在开始的时候指向left+1,后指针cur指向left也就是基准值。
prev开始遍历,如果发现cur的值小于key,就把prev++,再cur和prev指向的值交换,当遍历完成后,把prev和left指向的值交换。这样结果就是比基准值小的值都会在prev的左边,那么比基准值大的值就会都在prev右边,划分就完成了。
我们以这个数组为例,简单说明一下前后指针法的步骤:
int a[]={6,1,2,7,9,3,4,5,10,8};
一开始,prev指向6,cur指向1,key为6。
cur向后遍历,发现2比6小,prev++,并与cur交换,但这是我们会发现prev和cur其实是一样的,那么交换就没有意义了,还会浪费性能,可以在这里添加一个判断。此时prev和cur都指向1。
然后cur继续遍历到2,和1一样。此时prev和cur都指向2。
接着cur继续遍历,直到cur指向3,prev++,然后与3进行交换,因为prev++之后指向的值是cur遍历过的,所以一定是大于key的。此时数组为:
int a[]={6,1,2,3,9,7,4,5,10,8};
prev指向3,cur指向7。
…………
可以发现,在这个过程中比基准值小的值不断地被交换到prev及prev的左边,那么最终把基准值与prev交换,就可以实现划分了。
// 快速排序前后指针法
int PartSort3(int* a, int left, int right)
{int prev = left;int cur = left + 1;int key = a[left];while (cur <= right){if (a[cur] < key && ++prev != cur) //先++,再比较Swap(&a[cur], &a[prev]); //Swap函数自行实现即可cur++;}Swap(&a[left], &a[prev]); //把基准值放到prev的位置return prev;
}
2. 4 快排的非递归版本
上面的三种方法都是通过递归实现的,那么有没有办法不使用递归实现快速排序呢?
当然有,只不过需要借助数据结构——栈。
用left和right进行基准值的计算并划分,然后把本应递归的区间的新的left和right入栈,在入栈或出栈时判断left和right的大小是否合适,一直运行到栈为空,快速排序就完成了。
void QuickSortNonR(int* a, int left, int right)
{Stack st;StackInit(&st);Stack* tmp = &st; //以上均为创建栈StackPush(tmp, right); //将初始的left和right入栈,可以方便StackPush(tmp, left);while (!StackEmpty(tmp)){//出栈得到本次循环的left和rightint lefti = StackTop(tmp);StackPop(tmp);int righti = StackTop(tmp);StackPop(tmp);//采用前后指针法得到基准值并划分,也可以使用其他的办法int keyi = lefti;int prev = lefti;int cur = lefti + 1;while (cur <= righti){if (a[cur] < a[keyi] && prev++ != cur)Swap(&a[cur], &a[prev]);cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;//入栈前判断if (keyi - 1 > lefti){StackPush(tmp, keyi - 1);StackPush(tmp, lefti);}if (keyi + 1 < righti){StackPush(tmp, righti);StackPush(tmp, keyi + 1);}}//销毁栈StackDestroy(tmp);
}
3. 快排优化
3. 1 快排性能的关键点分析:
决定快排性能的关键点是每次单趟排序后,key对数组的分割,如果每次选key基本二分居中,那么快排的递归树就是颗均匀的满二叉树,性能最佳。但是实践中虽然不可能每次都是二分居中,但是性能也还是可控的。但是如果出现每次选到最小值/最大值,划分为0个和N-1的子问题时,时间复杂度为O(N^2),数组序列有序时就会出现这样的问题,我们可以用三数取中(选取3个数,把大小在中间那个作为基准值)或者随机选key(使用随机数选基准值,这两种办法实际的效率提升不是很高,不单独介绍了)解决这个问题,但是现在还是有一些场景没解决,比如数组中有大量重复数据时,比如以下代码:
// 数组中有多个跟key相等的值
int a[] = { 6,1,7,6,6,6,4,9 };
int a[] = { 3,2,3,3,3,3,2,3 };
// 数组中全是相同的值
int a[] = { 2,2,2,2,2,2,2,2 };
这种时候快排的效率就会急剧下降,完全不如其他的较快的排序算法(如堆排序)。
3. 1 三路划分
当面对有大量跟key相同的值时,三路划分的核心思想有点类似hoare的左右指针和lomuto的前后指针的结合。核心思想是把数组中的数据分为三段【比key小的值】【跟key相等的值】【比key大的值】,所以叫做三路划分算法。结合步骤,理解一下实现思想:
key默认取left位置的值。left指向区间最左边,right指向区间最后边,cur指向left+1位置。cur遇到比key小的值后跟left位置交换,换到左边,left++,cur++。cur遇到比key大的值后跟right位置交换,换到右边,right--。cur遇到跟key相等的值后,cur++。- 直到
cur > right结束
int a[]={6,1,7,6,6,6,4,9}; //前
int a[]={1,4,6,6,6,6,9,7}; //后int b[]={6,6,6,6,6,6,6,6}; //前
int b[]={6,6,6,6,6,6,6,6}; //后
代码:
void QuickSortTreeWay(int* a, int left, int right)
{if (left >= right)return;int begin = left;int cur = left + 1;int end = right;int key = a[left];while (cur <= right){if (a[cur] > key){//把大于key的数放到右边Swap(&a[cur], &a[end--]); //注意由于不确定被换过来的值的大小,cur不能直接++}else if (a[cur] == key){cur++; //等于key的先不管}else{Swap(&a[cur++], &a[begin++]); //小于key的放到begin的左边}}//递归时,begin-end的数不需要再调整QuickSortTreeWay(a, left, begin - 1);QuickSortTreeWay(a, end + 1, right);
}
3. 2 introsort自省排序
introsort是由David Musser在1997年设计的排序算法,C++ sgi STLsort中就是用的introspectivesort(内省排序)思想实现的。
内省排序可以认为不受数据分布的影响,无论什么原因划分不均匀导致递归深度太深,它都会转换为堆排painkiller,而堆排不受数据分布影响,具体可以看下面代码。
三路划分针对有大量重复数据时效率很好,其他场景就一般,而自省排序在任何场景都有优异的性能。
introsort是introspective sort采用了缩写,他的名字其实表达了它的实现思路,也就是进行自我侦测和反省,快排递归深度太深(sgi stl中使用的是深度为2倍排序元素数量的对数值)那就说明在这种数据序列下,选key出现了问题,性能在快速退化,那么就不要再进行快排分割递归了,改换为堆排序进行排序。
代码:(堆排序与插入排序不再赘述)
void IntroSort(int* a, int left, int right, int depth, int defaultDepth)
{if (left >= right)return;// 数组⻓度小于16的小数组,换为插入排序,简单递归次数if (right - left + 1 < 16){InsertSort(a + left, right - left + 1);return;}// 当深度超过2*logN时改⽤堆排序if (depth > defaultDepth){HeapSort(a + left, right - left + 1);return;}depth++; //深度++,方便判断int begin = left;int end = right;// 随机选key,相较于直接将第一个元素作为key,有一定的优势int randi = left + (rand() % (right - left + 1));Swap(&a[left], &a[randi]); //把选中的key放到left上,和之前的快排尽可能保持相似//前后指针法int prev = left;int cur = prev + 1;int keyi = left;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev],&a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;// [begin, keyi-1] keyi [keyi+1, end]IntroSort(a, begin, keyi - 1, depth, defaultDepth);IntroSort(a, keyi + 1, end, depth, defaultDepth);
}
void QuickSort(int* a, int left, int right)
{int depth = 0;int logn = 0;int N = right - left + 1;//计算lognfor (int i = 1; i < N; i *= 2){logn++;}// introspective sort -- 自省排序IntroSort(a, left, right, depth, logn * 2);
}int* sortArray(int* nums, int numsSize, int* returnSize) {srand(time(0));QuickSort(nums, 0, numsSize - 1);*returnSize = numsSize;return nums;
}
谢谢你的阅读,喜欢的话来个点赞收藏评论关注吧!
我会持续更新更多优质文章
相关文章:
【数据结构初阶】排序算法(中)快速排序专题
文章目录 1. 快排主框架2. 快排的不同实现2. 1 hoare版本2. 2 挖坑法2. 3 lomuto前后指针法2. 4 快排的非递归版本 3. 快排优化3. 1 快排性能的关键点分析:3. 1 三路划分3. 2 introsort自省排序 1. 快排主框架 快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。 其…...

Redis缓存双写一致性笔记(上)
Redis缓存双写一致性是指在将数据同时写入缓存(如Redis)和数据库(如MySQL)时,确保两者中的数据保持一致性。在分布式系统中,缓存通常用于提高数据读取的速度和减轻数据库的压力。然而,当数据更新…...

PCB基础
一、简介 PCB:printed circuit board,印刷电路板 主要作用:传输信号、物理支撑、提供电源、散热 二、分类 2.1 按基材分类 陶瓷基板:包括氧化铝、氮化铝、碳化硅基板等,具有优异的导热性,适用于高温和高…...

PostgreSQL 17:新特性与性能优化深度解析
目录 引言核心新特性 块级别增量备份与恢复逻辑复制槽同步参数SQL/JSON的JSON_TABLE命令PL/pgSQL支持数组%TYPE和%ROWTYPE 性能优化 IO合并读取性能参数真空处理过程的内存管理改进写前日志(WAL)锁的改进 升级建议结语 引言 PostgreSQL 17版本于2024年…...
[Linux#58][HTTP] 自己构建服务器 | 实现网页分离 | 设计思路
目录 一. 最简单的HTTP服务器 二.服务器 2.0 Protocol.hpp httpServer.hpp 子进程的创建和退出 子进程退出的意义 父进程关闭连接套接字 httpServer.cc argc (argument count) argv (argument vector) 三.服务器和网页分离 思考与补充: 一. 最简单的HTT…...

7.MySQL内置函数
目录 日期函数时间函数字符串函数数学函数其他函数 日期函数 函数名称描述current_date()当前日期current_time()当前时间current_timesamp()当前时间戳date(datetime)返回datetime参数的日期部分date_add(date, interval d_value_tyep)在date中添加日期函数或时间。interval后…...

如何快速自定义一个Spring Boot Starter!!
目录 引言: 一. 我们先创建一个starter模块 二. 创建一个自动配置类 三. 测试启动 引言: 在我们项目中,可能经常用到别人的第三方依赖,又是引入依赖,又要自定义配置,非常繁琐,当我们另一个项…...
)
【音视频】ffmpeg其他常用过滤器filter实现(6-4)
最近一直在研究ffmpeg的过滤器使用,发现挺有意思的,这里列举几个个人感觉比较有用的过滤器filter,如下是代码实现,同样适用于命令行操作: 1、视频模糊:通过boxblur可以将画面进行模糊处理,第1个…...

云栖3天,云原生+ AI 多场联动,新产品、新体验、新探索
云栖3天,云原生 AI 20场主题分享,三展互动,为开发者带来全新视听盛宴 2024.9.19-9.21 云栖大会 即将上演“云原生AI”的全球盛会 展现最新的云计算技术发展与 AI技术融合之下的 “新探索” 一起来云栖小镇 见证3天的云原生AI 前沿探索…...

jackson对于对象序列化的时候默认空值和手动传入的null的不同处理
Jackson 在序列化对象时如何处理默认的空值和手动传入的 null,其实归结于它的序列化机制和注解配置。默认情况下,Jackson 不区分 手动设置的 null 和 对象中字段的默认空值,但可以通过配置来改变其行为。具体细节如下: 1. 默认行为…...

L8打卡学习笔记
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 SVM与集成学习 SVMSVM线性模型SVM非线性模型SVM常用参数 集成学习随机森林导入数据查看数据信息数据分析随机森林模型预测结果结果分析 个人总结 SVM 超平面&…...

VBA解除Excel工作表保护
Excel工作表保护解除 工作表保护后无法编辑内容,可能是密码忘记,不可暴力破解隐私 1 打开需的Excel 2 Alt F11 打开代码编辑,点击任意代码编辑项,将如下代码复制,并运行。 Public Sub GetWorkbookPassword()Dim w1 A…...

bash: unzip: 未找到命令,sudo: nano:找不到命令
在 Ubuntu/Debian 系统上 打开终端并运行以下命令: sudo apt update sudo apt install unzip在 CentOS/RHEL 系统上 打开终端并运行以下命令: sudo yum install unzip在 macOS 上 如果您使用的是 macOS,可以使用 Homebrew 安装 unzip&#…...

tauri开发配置文件和文件夹访问路径问题
文件夹没权限:Unhandled Promise Rejection: path not allowed on the configured scope: /Users/song/Library/Application Support/com.pakeplus.app/assets/default.png 没有文件夹,需要先创建:Unhandled Promise Rejection: path: /Users…...
【web安全】——信息收集
一、收集域名信息 1.1域名注册信息 工具:站长之家 whois查询 SEO综合查询 1.2子域名收集 原理:字典爆破,通过字典中的各种字符串与主域名拼接,尝试访问。 站长之家 直接查询子域名 ip138.com https://phpinfo.me/domain/ …...

赵长鹏今日获释,下一步会做什么?币安透露2024年加密货币牛市的投资策略!
中国时间2024年9月28日,加密货币行业的风云人物赵长鹏(Changpeng Zhao,简称CZ)终于从监狱获释。他因在担任币安首席执行官期间未能有效执行反洗钱(AML)计划而被判刑四个月。赵长鹏的获释引发了广泛关注,不仅因为他是全…...

SpringMVC之ContextHolder
员工不必为自己的弱点而太多的忧虑,而是要大大地发挥自己的优点,使自己充满自信,以此来解决自己的压抑问题。我自己就有许多地方是弱项,常被家人取笑小学生水平,若我全力以赴去提升那些弱的方面,也许我就做…...

什么是SQL注入?
SQL注入是一种安全漏洞,攻击者通过在应用程序的输入字段中插入恶意SQL代码,从而操控数据库。此类攻击通常利用应用程序未对用户输入进行适当验证和清理的弱点。 工作原理: 输入字段:攻击者在登录表单或搜索框等输入区域插入恶意…...

混合密码系统——用对称密钥提高速度,用公钥密码保护会话密钥
混合密码系统(Hybrid Cryptosystem)是一种结合了多种密码学技术和算法的加密方案,旨在充分利用不同密码算法的优势,以提供更强大的安全性、更高的效率或更好的功能特性。以下是对混合密码系统的详细解释: 组成要素 对…...

Three.js粒子系统与特效
目录 粒子系统基础常见粒子系统特效粒子系统基础 基础的粒子系统 使用THREE.ParticleSystem和THREE.ParticleBasicMaterial实现: // 导入Three.js库 import * as THREE from three...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...
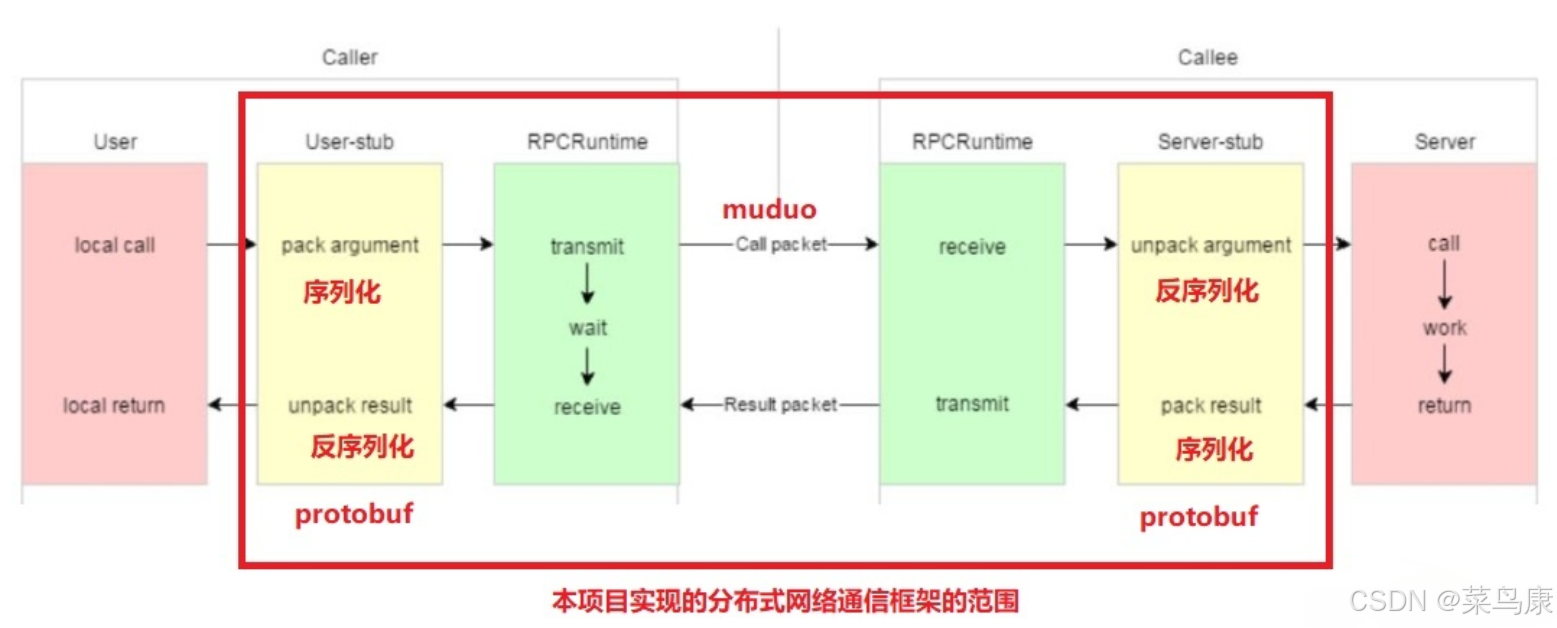
C++实现分布式网络通信框架RPC(2)——rpc发布端
有了上篇文章的项目的基本知识的了解,现在我们就开始构建项目。 目录 一、构建工程目录 二、本地服务发布成RPC服务 2.1理解RPC发布 2.2实现 三、Mprpc框架的基础类设计 3.1框架的初始化类 MprpcApplication 代码实现 3.2读取配置文件类 MprpcConfig 代码实现…...