【读写分离?聊聊Mysql多数据源实现读写分离的几种方案】
文章目录
- 一.什么是MySQL 读写分离
- 二.读写分离的几种实现方式(手动控制)
- 1.基于Spring下的AbstractRoutingDataSource
- 1.yml
- 2.Controller
- 3.Service实现
- 4.Mapper层
- 5.定义多数据源
- 6.继承Spring的抽象路由数据源抽象类,重写相关逻辑
- 7. 自定义注解@WR,用于指定当前操作使用哪个库
- 8. 切面逻辑
- 9.源码简单分析
- 10. 开始测试
- 2.基于Mybatis的SqlSessionFactory
- 1.yml
- 2.Controller
- 3.Service实现
- 4.Mapper层
- 5.配置类
- 1. 指定哪些Mapper接口使用读数据源:
- 2. 指定哪些Mapper接口使用写数据源
- 6. 开始测试
- 3.基于baomidou动态数据源实现读写分离(最简单)
- 1. maven依赖
- 2.yml
- 3.Controller
- 4.Service
- 5.Mapper层
- 6.开始测试
- 三.小结
一.什么是MySQL 读写分离
我记得实习的第一家公司做个一个项目就用过mysql多数据源的读写分离方案(4年前了…依稀记得也是在mapper层面来分离的),但那时候是我同事弄的,完全不懂怎么实现的,觉得他好厉害。从此成了心里的一道坎,很久之前就了解了,一直想着要写篇博客记录下,ok,那赶紧开始吧~
先了解下概念什么是读写分离、优势、实现方式、注意事项、和使用场景。如果项目里面有用到数据库集群,开始有性能方面问题,结合业务场景及综合衡量下去考虑是否适用数据库读写分离方案。
以下解释来自chatgpt,我觉得说的挺好的。
MySQL 读写分离是一种数据库优化策略,通过将数据库的读操作和写操作分开,分别交由不同的数据库实例处理,以提高系统的性能和扩展性。具体来说,读写分离通常涉及一个主数据库(Master)和一个或多个从数据库(Slave),它们通过复制机制保持数据的一致性。
以下是读写分离的核心概念:
- 主从复制(Master-Slave Replication)
- 主库(Master):负责处理所有的写操作(INSERT、UPDATE、DELETE 等),也可以处理读操作。
- 从库(Slave):主要用于处理读操作(SELECT),不会直接接收写操作。从库通过复制机制从主库同步数据,确保数据一致性。
- 读写分离的优势
- 提高读性能:由于从库处理读操作,可以通过增加从库实例来扩展系统的读性能,减轻主库的负担。
减少主库压力:写操作集中在主库,从库处理大部分的读操作,主库的压力减少,有助于提高写操作的响应速度。
容错性:在某些情况下,从库可以用作备份,如果主库出现故障,可以临时将从库提升为主库以保持服务的可用性。
- 实现方式
读写分离可以通过多种方式实现,包括:
- 手动分离:应用程序通过逻辑代码,手动决定读请求发送到从库,写请求发送到主库。
- 代理层(中间件):使用数据库中间件(如 MySQL Proxy、MaxScale、MyCat等),在应用和数据库之间自动实现读写分离和负载均衡。
- 连接池支持:某些数据库连接池(如 Druid、HikariCP)可以自动支持主从库的读写分离。
- 注意事项
- 数据一致性问题:由于复制存在延迟,从库上的数据可能会比主库滞后。如果应用程序对实时数据一致性要求较高,需谨慎处理。
- 负载均衡:要合理分配读请求到不同的从库,避免单个从库成为瓶颈。
- 主库故障恢复:需要设计可靠的故障转移机制,确保主库出现问题时,从库能够及时接管。
- 使用场景
读写分离适用于读操作远多于写操作的场景,例如电商平台、社交媒体网站等。在这些场景中,读请求往往占大多数,通过读写分离可以有效提升系统的扩展性和性能。
二.读写分离的几种实现方式(手动控制)
这里只介绍手动分离读写库:应用程序通过逻辑代码,手动决定读请求发送到从库,写请求发送到主库的几种实现方式。
1.基于Spring下的AbstractRoutingDataSource
根据大家平常开发习惯,我还是从controller层开始吧。
1.yml
我的yml配置如下:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedatasource1:url: jdbc:mysql://127.0.0.1:3306/tl_mall_master?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverdatasource2:url: jdbc:mysql://127.0.0.1:3306/tl_mall_slave?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver
2.Controller
@RestController
@RequestMapping("friend")
@Slf4j
public class FriendController {@Autowiredprivate FriendService friendService;@GetMapping(value = "select")public List<Friend> select(){return friendService.list();}@GetMapping(value = "insert")public String in(){Friend friend = new Friend();friend.setName("jinbiao666");friendService.save(friend);return "主库插入成功";}
}
3.Service实现
@Service
public class FriendImplService implements FriendService {@AutowiredFriendMapper friendMapper;@Override@WR("R") // 库2public List<Friend> list() {return friendMapper.list();}@Override@WR("W") // 库1public void save(Friend friend) {friendMapper.save(friend);}
}
4.Mapper层
public interface FriendMapper {@Select("SELECT * FROM friend")List<Friend> list();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void save(Friend friend);
}
5.定义多数据源
@Configuration
public class DataSourceConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource1")public DataSource dataSource1() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource2")public DataSource dataSource2() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}
}
6.继承Spring的抽象路由数据源抽象类,重写相关逻辑
- 继承 org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource抽象类。
- 重写determineCurrentLookupKey方法,设置当前db操作应使用的数据源key
- 重写afterPropertiesSet方法,设置多数据源和默认数据源。
@Component
@Primary
public class DynamicDataSource extends AbstractRoutingDataSource {/*** 通过ThreadLocal设置当前线程所使用的数据源key*/public static ThreadLocal<String> name = new ThreadLocal<>();// 写@AutowiredDataSource dataSource1;// 读@AutowiredDataSource dataSource2;// 返回当前数据源标识,根据返回的key决定最终使用的数据源@Overrideprotected Object determineCurrentLookupKey() {return name.get();}/*** InitializingBean 是 Spring 框架中的一个接口,用于在 Bean 初始化完成后执行特定的操作。它定义了一个方法 afterPropertiesSet(),当 Bean 的属性设置完成后会被调用。* Spring 容器会在实例化该 Bean 并设置完属性后,自动调用 afterPropertiesSet() 方法来执行一些初始化操作*/@Overridepublic void afterPropertiesSet() {// 为targetDataSources初始化所有数据源Map<Object, Object> targetDataSources=new HashMap<>();targetDataSources.put("W",dataSource1);targetDataSources.put("R",dataSource2);super.setTargetDataSources(targetDataSources);// 为defaultTargetDataSource 设置默认的数据源super.setDefaultTargetDataSource(dataSource1);super.afterPropertiesSet();}
}
7. 自定义注解@WR,用于指定当前操作使用哪个库
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface WR {String value() default "W";
}
8. 切面逻辑
@Component
@Aspect
public class DynamicDataSourceAspect implements Ordered {// 前置@Before("within(com.tuling.dynamic.datasource.service.impl.*) && @annotation(wr)")public void before(JoinPoint point, WR wr){// 设置数据源key为注解值(determineCurrentLookupKey()方法里面会去取这个key)DynamicDataSource.name.set(wr.value());}@Overridepublic int getOrder() {return 0;}
}
9.源码简单分析
简单看下AbstractRoutingDataSource里面的determineTargetDataSource决定目标数据源方法。

10. 开始测试
-
给master写库的friend表清空,写入写库

-
写库写入成功

-
给slave读库的friend表插入一条数据rise,仅查询到读库的内容,成功实现读写分离。

2.基于Mybatis的SqlSessionFactory
一样还是从yml开始吧,目录结果清晰些。
1.yml
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedatasource1:url: jdbc:mysql://127.0.0.1:3306/tl_mall_master?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverdatasource2:url: jdbc:mysql://127.0.0.1:3306/tl_mall_slave?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver
server:port: 8080
2.Controller
@RestController
@RequestMapping("friend")
@Slf4j
public class FriendController {@Autowiredprivate FriendService friendService;@GetMapping(value = "select")public List<Friend> select(){return friendService.select();}@GetMapping(value = "insert")public void insert(){Friend friend = new Friend();friend.setName("jinbiao666");friendService.insert(friend);}
}
3.Service实现
/**** 读数据源配置:* 1. 指定扫描的mapper接口包(从库)* 2. 指定使用sqlSessionFactory是哪个(从库)*/
@Service
public class FriendImplService implements FriendService {@Autowiredprivate RFriendMapper rFriendMapper;@Autowiredprivate WFriendMapper wFriendMapper;// 读-- 读库@Overridepublic List<Friend> select() {return rFriendMapper.select();}// 保存-- 写库@Overridepublic void insert(Friend friend) {wFriendMapper.insert(friend);}}
4.Mapper层
在mapper层做的读写区分。
public interface RFriendMapper {@Select("SELECT * FROM friend")List<Friend> select();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void save(Friend friend);
}
public interface WFriendMapper {@Select("SELECT * FROM friend")List<Friend> list();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void insert(Friend friend);
}
5.配置类
1. 指定哪些Mapper接口使用读数据源:
- 通过@MapperScan注解扫对应的mapper接口,然后设置数据源为从数据源构造一个SqlSessionFactory 对象。
- 事务管理器用作事务回滚,暂不测试事务回滚了,都是可成功的.
/**** 写数据源配置:* 1. 指定扫描的mapper接口包(主库)* 2. 指定使用sqlSessionFactory是哪个(主库)*/
@Configuration
@MapperScan(basePackages = "com.tuling.datasource.dynamic.mybatis.mapper.r", sqlSessionFactoryRef="rSqlSessionFactory")
public class RMyBatisConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource2")public DataSource dataSource2() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}@Bean@Primarypublic SqlSessionFactory rSqlSessionFactory() throws Exception {final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();// 指定主库sessionFactory.setDataSource(dataSource2());// 指定主库对应的mapper.xml文件/*sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/r/*.xml"));*/return sessionFactory.getObject();}@Beanpublic DataSourceTransactionManager rTransactionManager(){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource2());return dataSourceTransactionManager;}@Beanpublic TransactionTemplate rTransactionTemplate(){return new TransactionTemplate(rTransactionManager());}
}
2. 指定哪些Mapper接口使用写数据源
@Configuration
@MapperScan(basePackages = "com.tuling.datasource.dynamic.mybatis.mapper.w", sqlSessionFactoryRef="wSqlSessionFactory")
public class WMyBatisConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource1")public DataSource dataSource1() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}@Bean@Primarypublic SqlSessionFactory wSqlSessionFactory() throws Exception {final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();// 指定主库sessionFactory.setDataSource(dataSource1());// 指定主库对应的mapper.xml文件/*sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/order/*.xml"));*/return sessionFactory.getObject();}@Bean@Primarypublic DataSourceTransactionManager wTransactionManager(){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource1());return dataSourceTransactionManager;}@Beanpublic TransactionTemplate wTransactionTemplate(){return new TransactionTemplate(wTransactionManager());}
}
6. 开始测试
1.写写库,成功,之前只有1条现在2条。ok,基于Mybatis在mapper层面的读写分离也成功了

2.读读库

其他场景比如写库失败回滚都是可以的,因为我们给DataSourceTransactionManager注入了写库的数据源。这里不展示了。
3.基于baomidou动态数据源实现读写分离(最简单)
1. maven依赖
<dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.0</version></dependency>
2.yml
一主两从
spring:datasource:dynamic:#设置默认的数据源或者数据源组,默认值即为masterprimary: master#严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源strict: falsedatasource:master:url: jdbc:mysql://127.0.0.1:3306/tl_mall_master?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverslave_1:url: jdbc:mysql://127.0.0.1:3306/tl_mall_slave?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverslave_2:url: jdbc:mysql://127.0.0.1:3306/tl_mall_user?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver
server:port: 8080
3.Controller
@RestController
@RequestMapping("frend")
@Slf4j
public class FriendController {@Autowiredprivate FriendService friendService;@GetMapping(value = "select")public List<Friend> select(){return friendService.select();}@GetMapping(value = "insert")public void insert(){Friend friend = new Friend();friend.setName("jinbiao666");friendService.insert(friend);}
}
4.Service
@Service
public class FriendImplService implements FriendService {@AutowiredFriendMapper friendMapper;@Override@DS("slave2") // 从库2public List<Friend> select() {return friendMapper.select();}@Override@DS("master") // 主库//@DS("#session.userID") 基于session里面的用户id取数据源,sass化,数据源动态根据用户选择。@DSTransactional //开启事务操作public void insert(Friend friend) {friendMapper.insert(friend);}
}
5.Mapper层
public interface FriendMapper {@Select("SELECT * FROM friend")List<Friend> select();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void insert(Friend friend);
}
6.开始测试
使用是不是超级简单,省去了很多自己注入的步骤,如使用@DS注解选择数据源、@DSTransactional注解回滚对应的数据源事务等等都由baomidou帮我们实现了。
- 写写库,成功,之前只有2条现在3条。ok,基于baomidou动态数据源实现读写分离也成功了

- 读slave_2(tl_mall_user),可以看到数据库3条数据:

接口测试:查询从库slave_2,没问题, 事务回滚暂不在这里做测试了,替大家测过了的,没问题~

三.小结
- 经过上面3种方式介绍,多数据源读写分离是不是很简单。
- 不过上面都是对单数据源写入操作的,可以使用@Transactional或者@DSTransactional帮我们回滚单数据源的事务。
- 如果涉及到多数据源的写入需要统一提交回滚怎么实现呢?小伙伴们不妨也思考一下这个问题,这其实就是相当于是分布式事务的回滚了。
相关文章:
【读写分离?聊聊Mysql多数据源实现读写分离的几种方案】
文章目录 一.什么是MySQL 读写分离二.读写分离的几种实现方式(手动控制)1.基于Spring下的AbstractRoutingDataSource1.yml2.Controller3.Service实现4.Mapper层5.定义多数据源6.继承Spring的抽象路由数据源抽象类,重写相关逻辑7. 自定义注解WR,用于指定当…...

C++游戏
宠粉福利! 目录 1.猜数字 2.五子棋 3.打怪 4.跑酷 5.打飞机 6.扫雷 1.猜数字 #include <iostream> #include <cstdlib> #include <ctime>int main() {std::srand(static_cast<unsigned int>(std::time(0))); // 设置随机数种子int …...

探索顶级低代码开发平台,实现创新
文章盘点ZohoCreator、OutSystems等10款顶尖低代码开发平台,各平台以快速开发、集成、数据安全等为主要特点,适用于不同企业需求,助力数字化转型。 一、Zoho Creator Zoho Creator 是一个低代码开发平台,它简化了应用开发中的复杂…...

Html--笔记01:使用软件vscode,简介Html5--基础骨架以及标题、段落、图片标签的使用
一.使用VSC--全称:Visual Studio Code vscode用来写html文件,打开文件夹与创建文件夹:①选择文件夹 ②拖拽文件 生成浏览器的html文件的快捷方式: !enter 运行代码到网页的方法: 普通方法:…...

探索反向传播:深度学习中优化神经网络的秘密武器
反向传播的概念: 反向传播(Backpropagation) 是深度学习中训练神经网络的核心算法。它通过有效计算损失函数相对于模型参数的梯度,使得模型能够通过梯度下降等优化方法逐步调整参数,从而最小化损失函数,提…...

K8S精进之路-控制器DaemonSet -(3)
介绍 DaemonSet就是让一个节点上只能运行一个Daemonset Pod应用,每个节点就只有一个。比如最常用的网络组件,存储插件,日志插件,监控插件就是这种类型的pod.如果集群中有新的节点加入,DaemonSet也会在新的节点创建出来…...
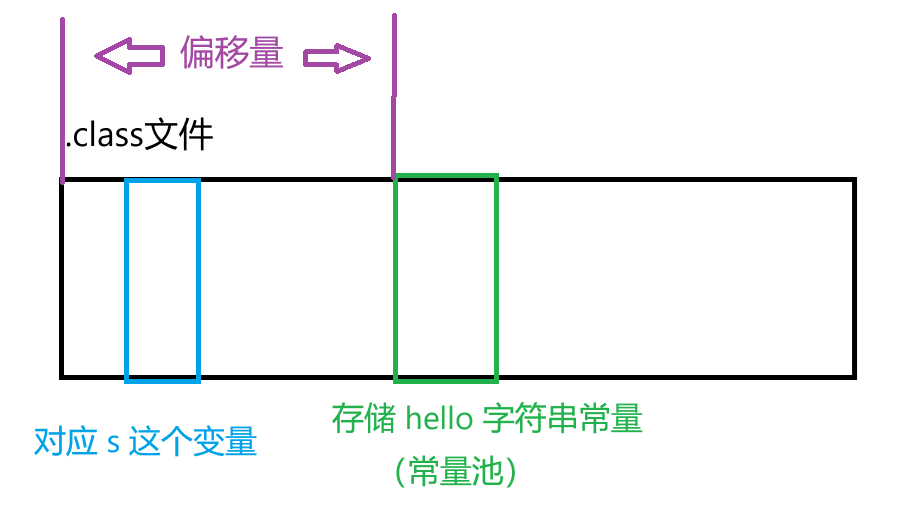
【JVM】类加载机制
文章目录 类加载机制类加载过程1. 加载2. 验证3. 准备4. 解析偏移量符号引用和直接引用 5. 初始化 类加载机制 类加载指的是,Java 进程运行的时候,需要把 .class 文件从硬盘读取到内存,并进行一些列的校验解析的过程(程序要想执行…...
)
ENV | 5步安装 npm node(homebrew 简洁版)
1. 操作步骤 1.1 安装 homebrew /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"1.2 安装 node # 安装最新版 brew install node # 安装指定版本,如18 brew install node181.3 安装 nvm(…...

EasyExcel全面实战:掌握多样化的Excel导出能力
1 概述 本文将通过实战案例全面介绍EasyExcel在Excel导出方面的多种功能。内容涵盖多表头写入、自定义格式、动态表头生成、单元格合并应用等。通过这些实例,读者可以掌握EasyExcel的各种高级功能,并在实际项目中灵活应用。 白日依山尽,黄河入海流。 欲穷千里目,更上一层楼…...

基于springcloud的药品销售系统
文未可获取一份本项目的java源码和数据库参考。 一、选题背景与意义 1. 选题背景 在日常医药管理中,面对众多的药品和众多不同需求的顾客,每天都会产生大量的数据信息。以传统的手工方式来处理这些信息,操作比较繁琐,且效率低下…...
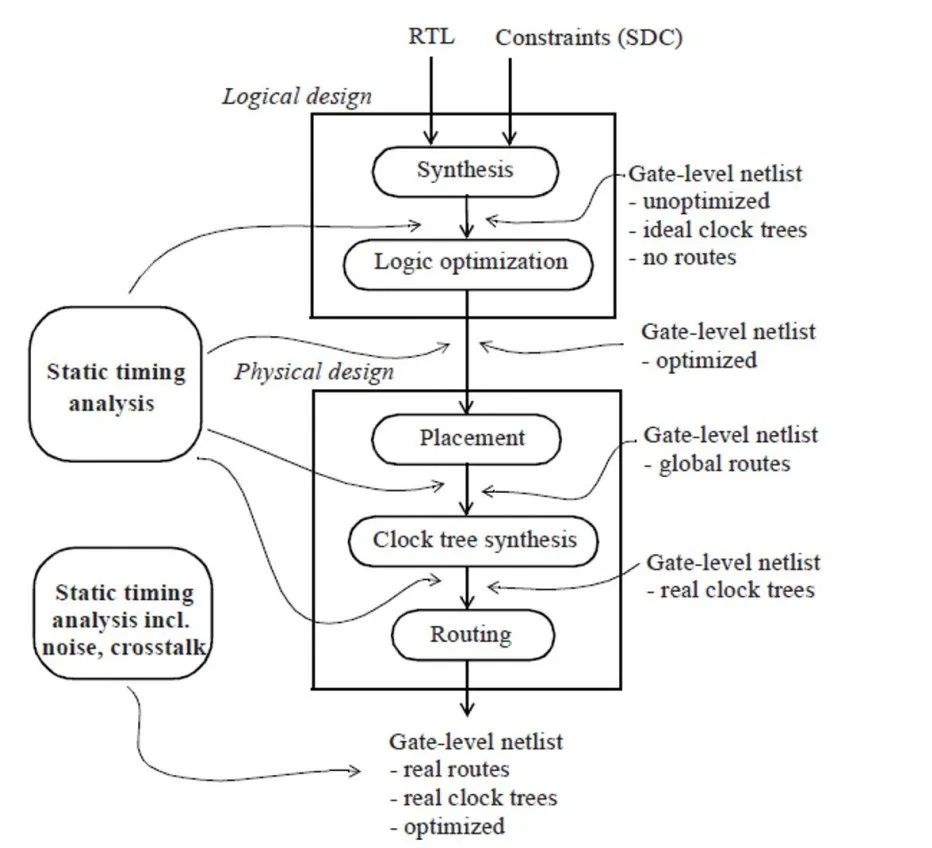
基于组网分割的超大规模设计 FPGA 原型验证解决方案
引言 如何快速便捷的完成巨型原型验证系统的组网,并监测系统的连通性及稳定性? 如何将用户设计快速布局映射到参与组网的原型验证系统的每一块 FPGA? 随着用户设计规模的日益增大,传统基于单片 FPGA 或单块电路板的原型验证系统…...

C# 面向对象基础,简单的银行存钱取钱程序
题目: 代码实现: BankAccount部分: using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace Bank {internal class BankAccount{private decimal balance 0;//账…...

【Rockchip系列】官方函数:drm_buf_alloc
drm_buf_alloc 函数 功能 分配一个DRM(Direct Rendering Manager)缓冲区。 语法 void* drm_buf_alloc(int width, int height, int bpp, int* fd, int* handle, size_t* size, int flags);参数 width: 缓冲区宽度(像素)heigh…...

深度学习--------------------------------门控循环单元GRU
目录 门候选隐状态隐状态门控循环单元GRU从零开始实现代码初始化模型参数定义隐藏状态的初始化函数定义门控循环单元模型训练该部分总代码简洁代码实现 做RNN的时候处理不了太长的序列,这是因为把整个序列信息全部放在隐藏状态里面,当时间很长的话&#…...

【实战】| X小程序任意用户登录
复现步骤 在登陆时,弹出这个页面时 抓包,观察数据包的内容 会发现有mobile值(密文)和iv值(随机数),拿到密文,肯定时想到解密,想要解密就必须知道密文,…...

计算机毕业设计之:云中e百货微信小程序设计与实现(源码+文档+定制)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

CEX上币趋势分析:Infra赛道与Ton生态的未来
在当前的加密市场中,CEX(中心化交易所)上币的选择愈发重要,尤其是对项目方而言。根据 FMG 的整理,结合「杀破狼」的交易所上币信息,显然 Infra 赛道成为了交易所的热门选择,而 Ton 生态也展现出…...
)
数组基础(c++)
第1题 精挑细选 时限:1s 空间:256m 小王是公司的仓库管理员,一天,他接到了这样一个任务:从仓库中找出一根钢管。这听起来不算什么,但是这根钢管的要求可真是让他犯难了,要求如下&#x…...

第十三届蓝桥杯真题Python c组A.排列字母(持续更新)
博客主页:音符犹如代码系列专栏:蓝桥杯关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 【问题描述】 小蓝要把一个字符串中的字母按其在字母表中的顺序排列。 例如&a…...

IDEA自动清理类中未使用的import包
目录 1.建议清理包的理由 2.清理未使用包的方式 2.1 手动快捷键清理 2.2 设置自动清理 1.建议清理包的理由 有时候项目类文件中会有很多包被引入了,但是并没有被使用,这会增加项目的编译时间并且代码可读性也会变差。在开发过程中,建议设…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...
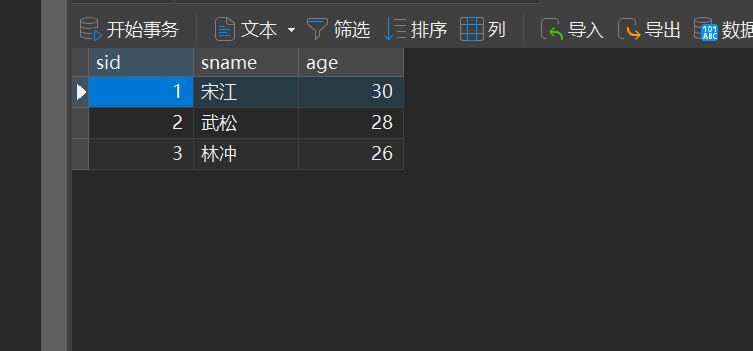
MySQL的pymysql操作
本章是MySQL的最后一章,MySQL到此完结,下一站Hadoop!!! 这章很简单,完整代码在最后,详细讲解之前python课程里面也有,感兴趣的可以往前找一下 一、查询操作 我们需要打开pycharm …...
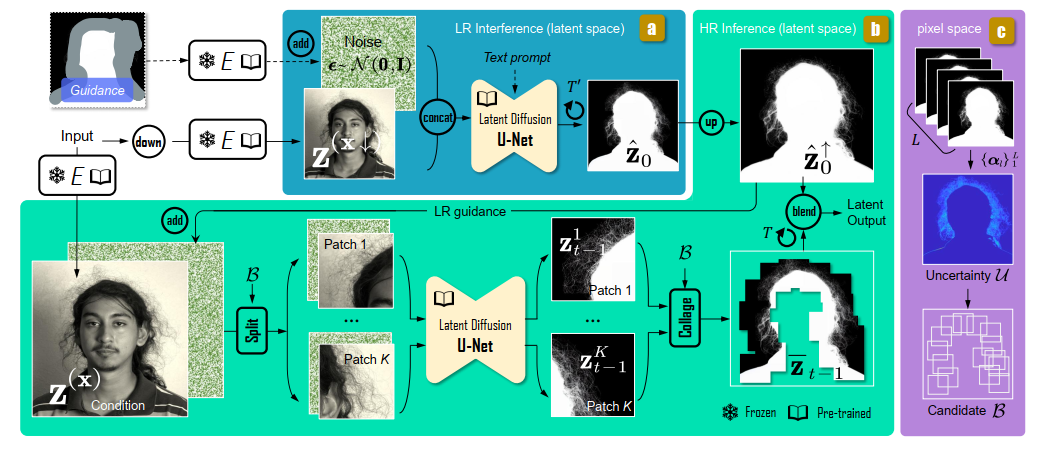
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...