消息中间件 Kafka 快速入门与实战
1、概述
最近感觉上班实在是太无聊,打算给大家分享一下Kafka的使用,本篇文章首先给大家分享三种方式搭建Kafka环境,接着给大家介绍kafka核心的基础概念以及Java API的使用,最后分享一个SpringBoot的集成案例,希望对大家有所帮助
2、环境搭建
2.1、安装包安装
关于环境搭建这块我们先来通过手动下载安装包的方式来完成,首先下载安装包,这是我使用的环境是CentOS7。
下载的地址 :
https://archive.apache.org/dist/kafka/3.7.0/kafka_2.13-3.7.0.tgz可以使用wget 工具下载

下载完成后我们解压,这里我是用的路径是 /usr/local 解压后如下图所示:

来到bin路径下,我们需要先启动zookeeper 然后再启动kafka,相关命令如下
# 启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties &# 启动 kafka
./kafka-server-start.sh ../config/server.properties &启动后 我们可以查看进程

kafka 已经启动成功了
2.2、Kraft 方式启动 kafka
上面我们使用zookeeper的方式运行了Kafka,kafka从2.8的版本就引入了KRaft模式,主要是用来取代zookeeper来管理元数据,下面我们来试试使用KRaft的方式来启动kafka
# 停掉kafka
./kafka-server-stop.sh ../config/server.properties# 停掉zookeeper
./zookeeper-server-stop.sh ../config/zookeeper.properties# 生成Cluster UUID
./kafka-storage.sh random-uuid
这里我们能需要记录下 生成的这个uuid值
# 格式化日志目录
./kafka-storage.sh format -t y__hXaR2QVKaehk5FiNLfQ -c ../config/kraft/server.properties
接着启动kafka
# 启动Kafka
./kafka-server-start.sh ../config/kraft/server.properties &
2.3、 Docker 安装
相信大家一定喜欢这种方式,直接使用 Docker 一把梭哈
# 拉取Kafka镜像
docker pull apache/kafka:3.7.0# 启动Kafka容器
docker run -p 9092:9092 apache/kafka:3.7.0# 复制出来一份配置文件
docker cp 7434ce960297:/etc/kafka/docker/server.properties /opt/docker/kafka
然后我们需要修改配置文件

修改完成后我们使用以下命令启动kafka
docker run -d \
-v /opt/docker/kafka:/mnt/shared/config \
-v /opt/data/kafka-data:/mnt/kafka-data \
-p 9092:9092 \
--name kafka-container \
apache/kafka:3.7.0完成之后我们可以使用客户端工具连接试试

至此我们的环境搭建完成了。
3、基础概念
3.1、Topic & event 简述
在kafka中 消息(event) 被组织并持久地存储在Topic中。非常简单地说,Topic 类似于文件系统中的一个文件夹,而事件就是该文件夹中的文件。这既是官方给出的Topic和event的定义
https://kafka.apache.org/37/documentation.html#introduction接下来我们来创建一个主题,首先我们来到 kafka 安装目录的 bin 目录下

# 创建一个名为 tianlongbabu的主题
./kafka-topics.sh --create --topic tianlongbabu --bootstrap-server 192.168.200.100:9092# 列出所有的主题(在主机上操作可以使用 localhost)
./kafka-topics.sh --list --bootstrap-server localhost:9092创建好了之后 我们可以回到客户端工具查看

同样的 我们可以直接在这个客户端上删除这个 topic

3.2、生产消息和消费消息
我们接下来看看 怎么往主题中写入事件(消息)
# 在主机上 指定topic 连接到kafka服务端
./kafka-console-producer.sh --topic tianlongbabu \
--bootstrap-server 192.168.200.100:9092连接上之后 就可以发送事件了

同样的我们新开一个终端 使用 kafka-console-consumer.sh 这个脚本 就可以消费topic中的数据了
## 主机上操作 可以使用localhost
## --from-beginning 表示从kafka最早的消息开始消费./kafka-console-consumer.sh --topic tianlongbabu \
--from-beginning --bootstrap-server localhost:9092
我们连接上之后 就会打印出刚刚发送的事件(消息)了。
3.3、关于事件的组成
看到这里 相信大家对事件有了一定的了解,关于事件这里给出一段官方文档上的原文

我们 从这段话中至少可以知道
1、event 在文档中也被称为记录(record)或消息(message)
2、 当你向Kafka读写数据时,采用的是事件形式
3、概念上,一个事件包含键(key)、值(value)、时间戳(timestamp),以及可选的元数据(metadata)。
所以一个事件可以设置一个key, 那么你可能会问key 是干什么用的呢,作用是什么呢?这个会在后面的编码的章节中给出解释,大家先知道有这个概念就行了
3.4、关于 Partition (分区)
先来给出一张图,出自官方文档的主要术语解释的章节

从这张图中我们可以看到,topic 中存在多个 partition(分区),也就是说事件其实都是被保存在topic中的分区里,并且一个topic 可以创建多个分区。
消息在分区中以追加的方式存储,每条消息都有一个唯一的偏移量(offset),表示它在分区中的位置。
那么分区的作用是什么呢,我自己根据文档上描述主要总结了4点
1、分区允许多个消费者并行消费同一主题中的消息,不同的消费者可以消费不同的分区,从而提高系统的吞吐量
2、Kafka会根据配置将消息均匀地分布到各个分区,确保负载在多个消费者之间均匀分配
3、在同一分区内,消息的顺序是有保障的。这意味着对于同一键的所有消息都会被发送到同一分区,从而保持顺序
4、通过增加分区数,可以扩展主题的并发能力和存储能力。Kafka支持动态增加分区,但请注意,这可能影响到现有数据的顺序。
这几点大家先了解即可。
4、入门程序开发
4.1、新建项目引入依赖
新建项目,添加 kafka 客户端依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.7.0</version></dependency>4.2、编写生产者
我们先来创建消息生产者的代码
public class KafkaProducerTest {public static void main(String[] args) {// Kafka配置Properties props = new Properties();props.put("bootstrap.servers", "192.168.200.100:9092"); // Kafka服务器地址props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 创建Kafka生产者KafkaProducer<String, String> producer = new KafkaProducer<>(props);String topic = "tianlongbabu"; // 主题名称String key = "gaibang"; // 消息键String value = "乔峰"; // 消息值// 发送消息ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);producer.send(record, (RecordMetadata metadata, Exception e) -> {if (e != null) {e.printStackTrace();} else {System.out.println("Sent message with key: " + key + ", value: " + value + ", to partition: " + metadata.partition() + ", offset: " + metadata.offset());}});// 关闭生产者producer.close();}
}
上述代码的写法 在org.apache.kafka.clients.producer.KafkaProducer 类的注释中有详细的说明

这个简单的入门案例中用到了前面给大家介绍的key(事件键)了,看了这个案例大家应该能够明白是什么意思了吧。这个时候 我们运行main方法 就能把测试数据写入到 topic 中了
4.3、编写消费者
相关代码如下:
public static void main(String[] args) {// Kafka配置Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.100:9092"); // Kafka服务器地址props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group"); // 消费者组IDprops.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 创建Kafka消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);String topic = "tianlongbabu"; // 主题名称// 订阅主题consumer.subscribe(Collections.singletonList(topic));// 不断消费消息while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Consumed message with key: %s, value: %s, from partition: %d, offset: %d%n",record.key(), record.value(), record.partition(), record.offset());}}// 关闭消费者(通常不会到达这里)// consumer.close();}消费者的代码里我们需要指定一个消费组 id ,当存在多个消费者服务的时候 需要为他们各自的消费组id。
我们运行main方法即可收到刚才发送的消息了。

到这里一个简单的生产-消费的案例已经结束了,相信你对Kafka也有了一个初步的认知。
4.4、关于消费组ID
上述入门程序的消费者程序中有一个消费组id 。在 Kafka 中,消费组 ID(Consumer Group ID)是一个重要的概念,用于标识一组协同工作的消费者。
简单来说就是:
1、对于一个特定的主题,如果多个消费者属于同一个消费组,那么主题中的每条消息只会被该消费组内的一个消费者消费。
2、如果消费者属于不同的消费组,则它们可以独立消费同一主题的消息,并且不会互相影响
5、SpringBoot集成
5.1、相关依赖
SpringBoot版本:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.9</version><relativePath/> <!-- lookup parent from repository --></parent>项目相关依赖:
<dependencies><!-- Spring Boot Starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!-- Spring Kafka --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><!-- Spring Boot Starter Web (optional, if you want to create a REST API) --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Add other dependencies as needed -->
</dependencies>5.2、配置详解
我们在applicatio.properties 添加以下配置
spring.kafka.bootstrap-servers=192.168.200.100:9092
## 消费组
spring.kafka.consumer.group-id=my-group
## 从最早的消息开始消费
spring.kafka.consumer.auto-offset-reset=earliest5.3、编写生产者
@Service
public class KafkaProducer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);}
}5.4、编写消费者
@Service
public class KafkaConsumer {@KafkaListener(topics = "tianlongbabu", groupId = "my-group")public void listen(String message) {System.out.println("Received Message: " + message);}
}5.5、测试
@RestController
public class KafkaController {@Autowiredprivate KafkaProducer kafkaProducer;@PostMapping("/send")public void sendMessage(@RequestBody String message) {kafkaProducer.sendMessage("tianlongbabu", message);}
}启动类
@SpringBootApplication
public class BootKafkaApplication {public static void main(String[] args) {SpringApplication.run(BootKafkaApplication.class, args);}}启动服务,由于我们配置的是earliest所以会打印出 topic中之前的消息

我们可以继续使用postman发送消息 ,然后观察控制台的输出


好了一个简单的消息生产和消费的流程就是这样了
6、Kafka 的应用
今天这篇文章主要给大家介绍了Kafka的一些基础知识,并且实现了SpringBoot快速集成的案例,大家后续可以使用上述案例作为模板添加自己的业务代码。后续我也会分享一些 Kafka工程化落地的实战案例在我的微信公众号(代码洁癖症患者)上,感兴趣的小伙伴可以去查阅
最后我们聊聊Kafka的应用场景
首先 Kafka 可以作为高吞吐量的消息队列,支持异步通信。生产者将消息发送到主题,消费者从主题中读取消息,适合实现解耦的微服务架构。
其次 Kafka 可以收集各个服务或应用的日志信息,并将其集中存储,以便后续的分析和监控。
在大数据领域 使用 Kafka 结合流处理框架(如 Apache Flink、Apache Spark Streaming),可以实时处理和分析数据流,适用于实时监控、欺诈检测等场景。
在数据集成领域 Kafka 可以作为不同数据源之间的数据桥梁,实现数据的实时传输和整合,常用于 ETL(提取、转换、加载)流程。
这里仅仅列出几个比较常用的场景,还有很多领域都可以见到Kafka的身影。
好了,纸上得来终觉浅,大家赶紧动手试试吧
相关文章:
消息中间件 Kafka 快速入门与实战
1、概述 最近感觉上班实在是太无聊,打算给大家分享一下Kafka的使用,本篇文章首先给大家分享三种方式搭建Kafka环境,接着给大家介绍kafka核心的基础概念以及Java API的使用,最后分享一个SpringBoot的集成案例,希望对大…...

【Unity服务】如何使用Unity Version Control
Unity上的线上服务有很多,我们接触到的第一个一般就是Version Control,用于对项目资源的版本管理。 本文介绍如何为项目添加Version Control,并如何使用,以及如何将项目与Version Control断开链接。 其实如果仅仅是对项目资源进…...

C++ --- 静态多态和动态多态
静态多态和动态多态 静态多态动态多态总结 静态多态和动态多态是面向对象编程中多态性的两种主要形式,它们在实现方式、绑定时机以及应用场景上存在一些显著的区别。 静态多态 静态多态,也被称为编译时多态,是指在编译阶段就已经确定了对象调…...

华为vxlan
VXLAN是什么?VXLAN与VLAN之间有何不同? - 华为...

队列及笔试题
队列 先进先出 使用单链表进行队尾插入 队头删除 其中带头结点直接尾插,不带头结点第一次操作要判断一下 但是带头结点需要malloc和free 函数传需要修改的参数方法 1、二级指针 2、带哨兵位的头结点 3、返回值 4、如果有多个值,用结构体封装起来…...

JAVA TCP协议初体验
文章目录 一、需求概述二、设计选择三、代码结构四、代码放送五、本地调试1. 服务端日志2. 客户端日志3. 断线重连日志 六、服务器部署运行1. 源码下载2. 打包镜像3. 运行容器 一、需求概述 最近开发某数据采集系统,系统整体的数据流程图如下: #mermaid…...

sqlserver迁移数据库文件存储位置
业务背景:由于C盘爆满,需要将数据库文件迁移到别处比如D盘 下面以某一个数据库转移为示例:(可以用SSMS工具,新建查询配合使用) 1.查询数据库文件存储路径 sql语句: -- 查询路径 USE QiangTes…...

配置项取值给静态类用
在 Java 中,如果要从 application.yml 文件中取值并供静态类使用,可以考虑以下几种方法: 一、使用 Spring 的 Environment 类 1. 首先确保你的项目是一个 Spring 项目,并且配置文件被正确加载。 2. 在需要获取配置值的类中注入…...

【vs code(cursor) ssh连不上服务器】但是 Terminal 可以连上,问题解决 ✅
问题描述 通过 vs code 的 ssh 原本方式无法连接,但是通过 Terminal 使用相同的 bash 却可以连接上服务器。 ssh -p 4xx username14.xxx.3 问题解决方法 在 vs code 的 config 里,将该服务器(14.xxx.3)的相关配置全部清空或注释…...

Go基础学习06-Golang标准库container/list(双向链表)深入讲解;延迟初始化技术;Element;List;Ring
基础介绍 单向链表中的每个节点包含数据和指向下一个节点的指针。其特点是每个节点只知道下一个节点的位置,使得数据只能单向遍历。 示意图如下: 双向链表中的每个节点都包含指向前一个节点和后一个节点的指针。这使得在双向链表中可以从前向后或从后…...

多层时间轮原理以及使用
文章目录 背景常用定时器实现 任务队列时间轮介绍基本结构指针移动定时任务插入循环任务插入代码示例 多层时间轮使用流程 代码 背景 在软件开发中,定时器是一个极为常用的组件,它发挥着至关重要的作用。通过定时器,开发者能够精确地控制程序…...

鸿蒙HarmonyOS开发生态
1、官网 华为开发者联盟-HarmonyOS开发者官网,共建鸿蒙生态 2、开发工具IDE下载及使用 https://developer.huawei.com/consumer/cn/ 3、使用帮助文档 4、发布到华为应用商店 文档中心...

vue中使用jsencrypt加密
vue中封装并使用jsencrypt加密 一般在项目搭建过程中用户注册、登录、修改密码、重置密码等功能都需要用到密码加密的功能,所以把jsencrypt进行封装使用,使代码更加简洁,流程如下: 1、安装jsencrypt npm install jsencrypt2、在…...

SpirngBoot核心思想之一AOP
简介: AOP(Aspect-Oriented Programming,面向切面编程) 是一种用于解决软件系统中横切关注点的编程范式。在企业级开发中,很多非业务功能(如日志、事务、权限、安全等)需要在多个模块中执行&am…...

足球预测推荐软件:百万数据阐述百年足球历史-大数据模型量化球员成就值
我开始创建这个模型是从梅西22世界杯夺冠第二天开始准备的,当时互联网上充斥了太多了个人情感的输出,有的人借题对C罗冷嘲热讽,有的人质疑梅西的阿根廷被安排夺冠不配超越马拉多纳做GOAT。作为一个从2002年开始看球的球迷,说实话有…...

AD中如何批量修改丝印的大小,节省layout时间
先选中一个元器件的丝印,然后右键,选择“查找相似项” 直接点击OK,这时会发现所有的丝印都会被选中 然后点击右上角的按键,修改其属性。...

Ps:堆栈
将多张类似的图像图层堆叠在一起形成图像堆栈 Stack,通过应用不同的堆栈模式,可以从这些图像中提取有用的信息或达到特定的视觉效果。 Photoshop 中的堆栈技术被广泛应用于摄影后期处理、科学研究、环境监测与分析等领域。 例如,它常用于减少…...

獨立IP和共用IP有什麼區別?
什麼是獨立IP? 獨立IP指的是一個IP地址專屬於一個用戶或設備。無論是網站、伺服器還是其他線上服務,獨立IP都意味著該IP地址不會與其他用戶或設備共用。獨立IP通常用於需要高安全性和穩定性的場景,比如企業網站、電子商務平臺和需要SSL證書的…...

枢纽云EKP数字门户模板上线!轻松复刻胖东来官网,实现数字化逆袭
数字化转型的浪潮中,胖东来凭借着其独特的企业文化和对员工福利的重视,走进了大众视野。近期,胖东来推出了“不开心假”等员工关怀,又一次引发了大众的广泛关注。这种关怀不仅仅提升了员工的幸福感,也间接的改善了顾客…...
从自动化到智能化:AI如何推动业务流程自动化
引言:从自动化到智能化的必然趋势 在当今数字化时代,企业为了提升效率、降低成本,纷纷采用自动化技术来简化重复性任务。然而,传统自动化仅限于标准化操作,无法应对复杂的决策和多变的市场环境。随着人工智能ÿ…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...
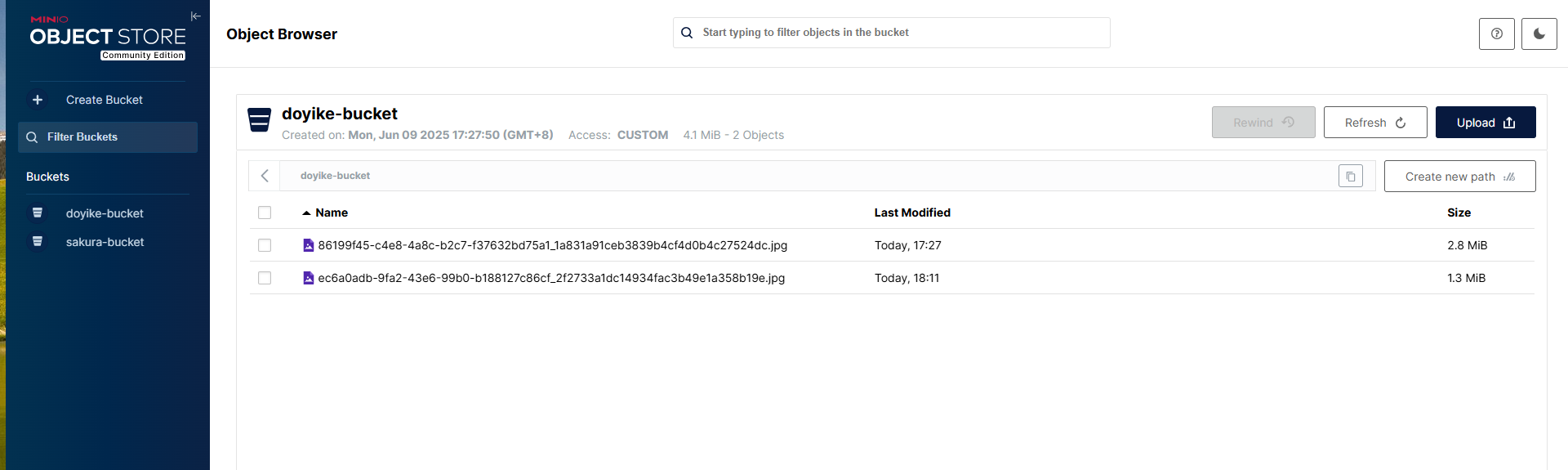
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...

TJCTF 2025
还以为是天津的。这个比较容易,虽然绕了点弯,可还是把CP AK了,不过我会的别人也会,还是没啥名次。记录一下吧。 Crypto bacon-bits with open(flag.txt) as f: flag f.read().strip() with open(text.txt) as t: text t.read…...