《C++并发编程实战》笔记(五)
五、内存模型和原子操作
5.1 C++中的标准原子类型
原子操作是不可分割的操作,它或者完全做好,或者完全没做。
标准原子类型的定义在头文件<atomic>中,类模板std::atomic<T>接受各种类型的模板实参,从而创建该类型对应的原子类型。
C++为内建类型定义了特例化的标准原子类型,并使用atomic_T作为对T类型特例化的别名:
std::atomic<bool>→std::atomic_boolstd::atomic<char>→std::atomic_char
对于一些内建的typedef类型,C++也提供了它们的特例化原子类型及别名,如:
std::atomic<std::size_t>→std::atomic_size_t
标准原子类型是基于std::atomic<>模板类定义的,该模板类支持初始化、值的存储与获取、比较交换操作等。std::atomic<bool>完全基于该主模板类定义,所以std::atomic<bool>支持的操作就是所有标准原子类型支持的操作,包含如下五种。
1. 初始化
原子对象的初始化是非原子的,不同初始化方法的执行流程为:
- 默认初始化。C++20前,只为静态变量和全局变量执行值初始化。C++20后,使用值初始化底层对象。
{// 未初始化的原子对象std::atomic_bool abool; } - 使用内置类型初始化
std::atomic_bool abool1 = false; std::atomic<bool> abool2{true};
因为原子类型上的操作全是原子化的,在拷贝赋值的过程中,需要从源对象读取值,再写入目标对象。这是两个对象上的独立操作,其组合不可能是原子化的,所以原子对象禁止拷贝赋值和拷贝构造。
2. 值的存储与获取
有两种原子操作方法可以重新指定原子变量保存的值:
T operator=(T desired),如abool = true。为了避免多个线程修改造成获取的返回结果不可预测,该赋值运算按值返回非原子类型的实参。void store(T desired),如abool.store(true)
同样有两种原子操作方法可以获取原子变量保存的值:
operator T(),如(bool)abool。通过重载的类型转换运算符以非原子类型方式获取保存的值T load(),如abool.load()。
可以原子性地执行读-修改-写操作,即获取原子变量的原值,并指定新值:
T exchange(T desired),如abool.exchange(true)。返回非原子类型的原子变量底层值,并设置原子变量的值为desired
std::atomic<int> a = 3;
std::atomic<int> b{3};
std::cout << "[init] a: " << a.load() << "; b: " << (int)b << std::endl;
// [init] a: 3; b: 3// 保存新的值
a = 5;
b.store(5);
std::cout << "[set] a: " << a.load() << "; b: " << (int)b << std::endl;
// [set] a: 5; b: 5// 获取新的值
int old_a = a.exchange(7);
int old_b = b.exchange(7);
std::cout << "[exchange] old_a: " << old_a << "; old_b: " << old_b << std::endl;
// [exchange] old_a: 5; old_b: 5
std::cout << "[exchange] a: " << a.load() << "; b: " << (int)b << std::endl;
// [exchange] a: 7; b: 7
因为原子类型定义了类型转换运算符,所以当使用std::cout可以直接输出std::atomic<int>等类型的变量,这是因为隐式调用了类型转换运算符,实际输出的是普通类型的变量:
std::atomic<int> i = 0;
std::atomic<double> d = 1.2;std::cout << "i: " << i << "; d: " << d << std::endl;
// i: 0; d: 1.2
// 实际隐式调用了 cout.operator<<((int)i)
3. 比较-交换(Compare and Swap, CAS)
比较交换操作是原子类型的编程基石,有两个成员函数可以完成:
bool compare_exchange_weak(T& expected, T desired)bool compare_exchange_strong(T& expected, T desired)
它们原子地逐字节比较原子对象与**expected**的值:
- 如果相等,将**
desired保存到原子对象 **,返回true - 如果不等,将原子对象的值保存到**
expected**,返回false
compare_exchange_weak可能会发生假性失败,即当*this = expected时,也执行将原子对象的值保存到expected并返回false,但是性能更好。如果**compare_exchange_weak用在循环**中,就可以通过多次循环避免假性失败的问题。(因为一些处理器不支持原子比较交换指令,使用循环+weak会更高效)
compare_exchange_strong不会发生假性失败,一定会严格的按照上述逻辑执行。如果对性能要求并不极致,通常使用该版本会更简单。
两者的区别可以参考文章——c++并发编程3. CAS原语
从以上逻辑可以看出,如果在while循环中执行以上两种函数,由于失败时会设置expected等于原子对象的值,那么最多在第二次循环时一定会将desired写入原子对象。即:
std::atomic<int> a_int = 5;
int exp = 6, des = 7;
int loop_num = 1;
while(!a_int.compare_exchange_weak(exp, des)) {std::cout << "[" << loop_num << "] exp: " << exp << std::endl;std::cout << "[" << loop_num << "] a_int: " << a_int.load() << std::endl;
}
std::cout << "[end] a_int: " << a_int.load() << std::endl;
/*
[1] exp: 5
[1] a_int: 5
[end] a_int: 7
*/
4. C++20的新操作
C++20起,还添加了以下操作:
void wait(T old):阻塞线程,每次调用notify_xxx时去检查原子值,若值已经与old不同,退出阻塞;否则继续阻塞。不调用notify_xxx时,即使值改变了,也不会影响wait。该函数可能会被虚假解锁,即没有任何线程调用notify_xxx时,可能会去执行原子值与old的对比而退出阻塞。void notify_one()和void notify_all():如果有正在阻塞的线程,提醒一个或多个线程去检测原子值是否改变,判断是否可以退出阻塞。
std::atomic<int> a_int = 5;void Worker() {std::chrono::time_point beg = std::chrono::steady_clock::now();a_int.wait(5);std::chrono::time_point end = std::chrono::steady_clock::now();std::cout << "wait time: "<< std::chrono::duration_cast<std::chrono::milliseconds>(end - beg)<< std::endl;
}int main(int argc, char const *argv[]) {std::thread t(Worker);// 多次调用 notify_all 提醒原子变量去检测原子值std::this_thread::sleep_for(std::chrono::seconds(2));a_int.notify_all();std::this_thread::sleep_for(std::chrono::seconds(2));a_int.store(6);std::this_thread::sleep_for(std::chrono::seconds(2));a_int.notify_all();t.join();return 0;
}
/*
wait time: 6001ms
*/
5. 无锁类型的判断
对于原子类型的原子操作,一般是由原子指令直接实现的,但是对于部分类型的原子操作,仅仅靠原子指令可能无法实现,这时原子操作会借助编译器和程序库的内部锁实现。为了判断某一原子类型的操作是基于什么实现的,C++提供了运行时判断方法和编译时判断方法。
运行时判断:几乎全部原子类型都包含成员函数t.is_lock_free(),如果此类型对象上的所有原子操作都是无锁的返回true,否则返回false。
编译时判断:C++提供了多种方法在编译时判断原子类型是否无锁
- 使用宏
ATOMIC_xxx_LOCK_FREE,该宏中的xxx与要判断的标准原子类型相对应,其值包含三种:0:原子类型一定有锁1:部分机器上该类型无锁2:原子类型一定无锁
- 使用静态成员常量
std::atomic<type>::is_always_lock_free,原子类型始终为无锁则为true,若它一定或有时为无锁则为false - 使用非成员函数
std::atomic_is_lock_free( std::atomic<T>*),原子类型始终为无锁则为true,若它决不或有时为无锁则为false
std::atomic_llong allong{2};
std::cout << "is_lock_free: " << allong.is_lock_free() << std::endl;
std::cout << "ATOMIC_LLONG_LOCK_FREE: " << ATOMIC_LLONG_LOCK_FREE << std::endl;
std::cout << "is_always_lock_free: " << allong.is_always_lock_free << std::endl;
std::cout << "atomic_is_lock_free: " << std::atomic_is_lock_free(&allong) << std::endl;
/**
is_lock_free: 1
ATOMIC_LLONG_LOCK_FREE: 2
is_always_lock_free: 1
atomic_is_lock_free: 1
*/
5.2 特定的原子类型及操作
1. std::atomic_flag
std::atomic_flag并非是std::atomic<T>的特例化,它是原子布尔类型,且保证一定是无锁的。该类型的对象有两种状态:
truefalse
特点:
- 与
std::atomic<T>类似,std::atomic_flag也不支持拷贝构造和拷贝赋值 - 因为
std::atomic_flag一定是无锁的,所以它也不提供is_lock_free()成员函数
创建对象:
std::atomic_flag flag;,默认初始化。C++20之前,其状态是未指定的;C++20起,状态被初始化为falsestd::atomic_flag flag = ATOMIC_FLAG_INIT;,对于C++20前,可以使用该宏将状态初始化为false
操作:
flag.clear():将状态原子地改为falseflag.test_and_set():将状态原子地改为true,并返回之前的状态
C++20起,还添加了获取状态的函数和**与std::atomic<T>**相同的阻塞唤醒函数:
flag.test():原子地返回值flag.wait(old)、falg.notify_one()、flag.notify_all()
自旋锁:在获取锁时不阻塞线程,通过循环不断尝试获取锁,直至成功。利用std::atomic_flag可以简单完美的实现自旋锁。
class Spinlock {public:Spinlock() : flag_(ATOMIC_FLAG_INIT) {}void Lock() {while (flag_.test_and_set());}void UnLock() {flag_.clear();}private:std::atomic_flag flag_;
};Spinlock sp;
int cnt = 0;void AddCnt() {for (int i = 0; i < 1000000; ++i) {// 利用 atomic_flag 实现的自旋锁实现互斥sp.Lock();++cnt;sp.UnLock();}
}- 自旋锁可以充分利用CPU,但是会造成性能的浪费。如果线程只是短时间阻塞,自旋锁非常高效。通常会将自旋锁与互斥量结合使用,需要阻塞等待时先在短时间内利用自旋锁等待;当超过一定时间后,转换为利用互斥量休眠等待。
std::atomic<bool>是标准的bool原子类型,相比于std::atomic_flag,它可以通过赋值和store设置目标值,可以通过load和类型转换运算符读取值,exchange和std::atomic_flag::test_and_set()也非常类似。std::atomic<bool>相比于std::atomic_flag更加的灵活,其缺点是并不保证所有实现都是无锁的。
2. 原子指针和原子整数
std::atomic<T*>是原子化的指针,std::atomic<int>、std::atomic<long>等是原子化的整数,它们除了支持主模板定义的操作外,还特例化提供了原子化的算术运算操作。包含:
- 原子自增/自减运算符
operator++、operator--等 - 原子加减函数,返回加减前的值:
fetch_add(n):原子化的加nfetch_sub(n):原子化的减n
- 原子复合赋值运算符,返回运算后的值(不是左侧对象的引用):
operator+=operator-=
此外,原子整数还定义了原子位运算操作:
- 原子位运算函数,返回运算前的值:
fetch_and、fetch_or、fetch_xor - 复合位运算,以值返回运算后的结果:
operator&=、operator|=、operator^=
std::atomic_int acnt{0};
int cnt{0};std::vector<std::thread> pool;for (int i = 0; i < 10; ++i) {pool.push_back(std::thread([&]() {for (int i = 0; i < 100000; ++i) {++acnt;++cnt;}}));
}
for (int i = 0; i < 10; ++i) {pool[i].join();
}
std::cout << "acnt: " << acnt << std::endl;
std::cout << "cnt: " << cnt << std::endl;
/**
acnt: 1000000
cnt: 752130
*/
3. std::atomic<>的泛化
可以给std::atomic<>传入自定义类型作为模板实参,从而创建一个原子化的自定义类型。只有自定义类型是可平凡复制时,才能创建该类型的原子类型。
可平凡复制:可以将对象按字节复制到char数组或其他对象中,并保有其原值。
对于原子化的自定义类型,支持主模板定义的初始化、值的存储与获取、比较交换操作等。
与所有的原子类型相同,即使自定义类型重载了比较运算符,原子化的自定义类型在执行比较交换操作时也是通过逐字节比较对象。
4. 原子化的智能指针
C++20开始,在头文件<memory>中通过部分特例化std::atomic<>定义了原子化的shared_ptr<T>和weak_ptr<T>:
std::atomic<std::shared_ptr<T>>std::atomic<std::weak_ptr<T>>
它们支持主模板定义的各种初始化、值的存储与获取、比较交换操作等。
5. 非成员函数实现的原子操作
以上各种原子操作都以成员函数的方式使用,为了更广的兼容性,C++还定义了对应于这些成员函数操作的非成员函数。一般情况下,这些操作以atomic_作为成员函数名的前缀,构成非成员函数版本的名字。
这些成员函数第一个参数是原子类型的指针,指向要操作的原子类型。
5.3 内存次序
在单线程中,编译器可能会对一段代码的执行顺序进行重排列,即代码的实际执行顺序可能与代码顺序不同。如下所示的代码:
int x = 0, y = 0;
{++x;++y;
}
- 实际执行时可能会先执行
++y,后执行++x
C++的优化会保证同样的代码在单一线程下的执行一定会得到相同的结果。但是在多线程环境下可能会因为指令重排造成问题。比如,多线程环境下在上面的代码中,在没有对指令的重排进行限制时,当前线程首先执行了++y,此时如果在另外一个线程中先获取y的值,再获取x的值,会出现y=1, x=0的状态,这与代码的实际顺序不符。
为了保证代码可以按照我们想要的顺序执行,可以限制编译器及CPU对一个线程中指令的重新排列,从而避免因重排执行顺序导致代码执行结果与预期不符。如,限制++y一定在++x后执行,这样就保证了在多线程环境下也能获取到和代码顺序相符的结果。
对于原子类型的每种操作,都可以在所有参数后提供一个额外的std::memory_order类型的内存序参数,用于限制编译器在当前线程中将该操作重排到某些位置。
注意:所有的内存序都只作用于指定内存序的操作所运行的线程,不会跨线程交换指令执行的顺序,之所以能够利用内存序保证多个线程中原子操作的执行顺序,是因为利用了如while循环等的手段,等待另一个线程中的某个操作A执行完成,如果在那个线程中限制了A操作前的指令不能重排到A后,那么在当前线程while循环结束后表示A执行完成,则当前线程一定能正确获得A之前指令的操作结果。
std::memory_order包含六种,按照对指令重排的限制程度从强到弱可以分为四类:
- 顺序一致次序(Sequentially-consistent ordering):
std::memory_order_seq_cst
- 释放-获取次序(Release-Acquire ordering)
std::memory_order_releasestd::memory_order_acquirestd::memory_order_acq_rel
- 释放-消费次序(Release-Consume ordering)
std::memory_order_consume
- 宽松次序(Relaxed ordering)
std::memory_order_relaxed
1. 顺序一致次序
顺序一致次序是原子操作的默认内存序。即,当调用某个原子操作,且没有指定任何内存序参数时,默认使用的就是std::memory_order_seq_cst。
顺序一致性规定:
- 同一线程内的多个顺序一致的操作会按照代码顺序执行
- 一个顺序一致的操作结束后,操作结果会对后续代码和其他线程立即可见(操作执行结束后,会从缓存立即同步到所有使用它的地方,避免像
relaxed序一样可能会延迟同步结果)
顺序一致次序是最强的约束,它可以保证程序的运行严格按照代码顺序执行,但是在部分机器上为了实现该约束可能会造成较大的性能损失。
// 虽然原子操作内存序的默认参数就是 std::memory_order_seq_cst,
// 但是以下代码仍然显式指定了 std::memory_order_seq_cst 以突出显式
#include <atomic>
#include <cassert>
#include <iostream>
#include <thread>/** @brief 先修改 x,再修改 y */
void WriteXAndY() {x.store(true, std::memory_order_seq_cst);y.store(true, std::memory_order_seq_cst);
}/** @brief 先读取 x,再读取 y */
void ReadXThenY() {while (!x.load(std::memory_order_seq_cst));if (y.load(std::memory_order_seq_cst)) {std::cout << "111" << std::endl;++z;}
}
/** @brief 先读取 y,再读取 x */
void ReadYThenX() {while (!y.load(std::memory_order_seq_cst));if (x.load(std::memory_order_seq_cst)) {++z;std::cout << "222" << std::endl;}
}std::atomic<bool> x, y;
std::atomic<int> z;int main() {x = false;y = false;z = 0;std::thread c(ReadXThenY);std::thread d(ReadYThenX);std::thread e(WriteXAndY);e.join();c.join();d.join();return 0;
}- 以上代码中,无论编译器或CPU对指令怎么重排,按照内存序的约束,
ReadYThenX一定会执行。即,当y被修改为true时,x一定也已经被修改为true了。但是ReadXThenY不一定执行,因为按照代码顺序,执行完x.store(true, std::memory_order_seq_cst)后,可能会发生进程的调度,造成不能进入ReadXThenY的if判断内。
2. 宽松次序
宽松次序规定在一个线程内:
- 对同一原子变量的操作,按照代码顺序执行,操作结果对其他线程可能会延迟可见(最终一定会可见)
- 对不同原子变量的操作可以重排顺序
宽松次序是最松的约束,指定宽松次序后,允许编译器根据需要重排指令的顺序以代码提高运行效率。
#include <atomic>
#include <iostream>
#include <thread>std::atomic<int> x(0), y(1);
int r1 = 2, r2 = 3;
void WriteX() {r1 = y.load(std::memory_order_relaxed);x.store(r1, std::memory_order_relaxed);
}void WriteY() {r2 = x.load(std::memory_order_relaxed);y.store(42, std::memory_order_relaxed);
}int main(int argc, char const *argv[]) {std::thread a(WriteX);std::thread b(WriteY);a.join();b.join();return 0;
}
- 以上原子操作都指定了
std::memory_order_relaxed,编译器如果对执行指令重排,再叠加进程调度,最终的执行结果可能会出现r1 = 42, r2 = 42的情况。即重排后先执行y.store(指令重排)、再执行r1 = y.load(进程调度)、再执行x.store(r1)、最后执行r2 = x.load(进程调度+指令重排)
宽松次序最常见的应用是计数器自增:
#include <iostream>
#include <thread>
#include <atomic>
#include <vector>std::atomic<int> cnt(0);/** @brief 对 cnt 递增 100 次 */
void Work() {for (int i = 0; i < 100; ++i) {cnt.fetch_add(1, std::memory_order_relaxed);}
}int main() {std::vector<std::thread> ts;for (int i = 0; i < 10; ++i) {ts.emplace_back(Work);}for (int i = 0; i < 10; ++i) {ts[i].join();}std::cout << "cnt: " << cnt.load() << std::endl;
}
/*
cnt: 1000
*/- 因为计数器自增只要求原子性,对执行的顺序并不敏感,且不会影响与其他线程的同步,即使编译器为了优化性能发生了指令的重排,对最终的结果也不会造成影响
3. 释放-获取次序
释放获取次序主要包含两个,它们都是只影响操作所在的线程:
std::memory_order_release:用来修饰一个写操作(如store),限制在该写操作前的所有操作(包含非原子、原子及宽松原子的读写)不能重排到该写操作之后;且如果有操作发生了内存写入,写入的结果会在运行完该写操作后,在其他线程立即可见std::memory_order_acquire:用来修饰一个读操作(如load),限制在该读操作后的所有操作(包含非原子、原子及宽松原子的读写)不能重排到该读操作前
此外,还有一个同时作用获取释放的次序:
std::memory_order_acq_rel:修饰一个读-改-写操作(如exchange),同时包含上面两个修饰符的作用
从定义可以看出,写操作的释放保证一个线程中该写操作之前的代码一定执行完成,读操作的获取保证一个线程中该读操作后的所有代码都在读操作后执行。因此,可以利用该特性,实现内存操作的同步。
#include <atomic>
#include <iostream>
#include <thread>std::atomic<bool> x = false, y = false;
int data = 0;void Producer() {x.store(true, std::memory_order_relaxed);data = 42;// memory_order_release 声明之前的所有代码不能重排到后面y.store(true, std::memory_order_release);
}void Consumer() {while (!y.load(std::memory_order_acquire));// memory_order_acquire 声明之后的代码不能重排到前面if (x.load() == true && data == 42) {std::cout << "Yep\n";}
}int main(int argc, char const *argv[]) {std::thread a(Producer);std::thread b(Consumer);a.join();b.join();return 0;
}
- 在
Consumer中由于循环等待y.load返回true,当退出while循环时,说明Producer中y.store(true, std::memory_order_release)一定执行完成,因为有参数memory_order_release,所以y.store前的所有代码也一定执行完成(即使x.store指定了memory_order_relaxed)。此时,在Consumer的while循环后的代码一定能够看到Producer的y.store前的修改,所以会输出Yep
实际上,顺序一致次序等价于同时指定了释放-获取次序,即:
- 对写操作的
std::memory_order_seq_cst,就是执行std::memory_order_release内存序 - 对读操作的
std::memory_order_seq_cst,就是执行std::memory_order_acquire内存序
4. 释放-消费操作
释放-消费操作与释放获取操作类似,区别在于使用时将std::memory_order_acquire替换为std::memory_order_consume:
std::memory_order_consume:作用于某个原子变量的读操作(如load),限制当前线程中该原子变量及依赖该原子变量的所有操作不能重排到该读操作之前
代码:
std::atomic<int *> global_addr{nullptr};
void Func(int *data) {int *addr = global_addr.load(std::memory_order_consume);int d = *data;int f = *(data + 1);if (addr) {int x = *addr;}
}
- 由于
global_addr的读操作指定了std::memory_order_consume,所以依赖于global_addr的addr和x的相关操作不能重排到global_addr.load前。d和f的相关代码不依赖global_addr,所以编译器可以将这些代码重排到合适的位置。
将std::memory_order_release和std::memory_order_consume结合,可以实现不同线程中只同步相互依赖的变量。如:
#include <atomic>
#include <iostream>
#include <thread>
#include <string>std::atomic<bool> abool = false;
int data;void Producer() {data = 42;abool.store(true, std::memory_order_release);// 保证 abool.store 之前的所有操作都执行完成
}
void Consumer() {// 只保证与 abool 相关的操作不会重排到前面while (!abool.load(std::memory_order_consume));if (abool.load() == true) {std::cout << "abool: Yep\n";}// data 可以被重排到 while 前,可能会输出 date: Noif (data == 42) {std::cout << "data: Yep\n";} else {std::cout << "date: No\n";}
}int main(int argc, char const *argv[]) {std::thread a(Producer);std::thread b(Consumer);a.join();b.join();return 0;
}
- 只有
abool的值会在两个线程间同步,在Consumer中如果重排data的判断语句到abool.load前,会输出date: No
5.4 栅栏
以上的内存序都局限于某个原子操作,C++11还定义了可以独立于原子操作使用的内存栅栏,相比于原子操作的内存序,使用栅栏可以强制施加内存次序,实现更强的同步效果。
内存栅栏主要通过全局函数设置:
void atomic_thread_fence(std::memory_order order)
当线程运行到栅栏函数处时,栅栏会对线程中其他原子操作的重排施加限制,从而使得这些操作满足特定的执行顺序。
1. 内存栅栏的逻辑
当六种不同的内存序做参数时,可以将栅栏类型分为三种:
release fence:用于阻止当前线程中**fence前的内存操作重排到fence后的任意store之后 **(store可以是任意内存序)。原子操作的release只限制了之前的操作不能重排到release后;release fence则限制不能排到release后的任意store后(添加了store条件),包括:std::atomic_thread_fence(std::memory_order_release)
根据以上原则,以下两种代码有相同的效果:
// 代码 1 std::string* p = new std::string("Hello"); ptr.store(p, std::memory_order_release);// 代码 2 std::string* p = new std::string("Hello"); std::atomic_thread_fence(memory_order_release); // 由于release fence的限制,即使ptr.store是releaxed的,也会在p的初始化后执行 ptr.store(p, std::memory_order_relaxed);acquire fence:用于阻止当前线程中**fence**后的内存操作重排到**fence前的任意load之前**(load可以是任意内存序)。原子操作的acquire只限制了之后的操作不能重排到acquire前;acquire fence则限制不能排到release前的任意load前(添加了load条件),包括:std::atomic_thread_fence(std::memory_order_acquire)std::atomic_thread_fence(std::memory_order_consume)
根据以上原则,以下两种代码有相同的效果:
// 代码 1 std::string* p; while(p = ptr.load(std::memory_order_acquire)); assert(*p == "hello")// 代码 2 std::string* p; // 由于acquire fence的限制,即使ptr.load是relaxed的,也会在*p前执行 while(p = ptr.load(std::memory_order_relaxed)); std::atomic_thread_fence(memory_order_acquire); assert(*p == "hello")full fence:release fence和acquire fence的组合,可以同时实现以上两者的功能std::atomic_thread_fence(std::memory_order_acq_rel):release fence和acquire fence的组合std::atomic_thread_fence(std::memory_order_seq_cst):额外保证有完全顺序一致性的full fence,具有最强的约束
std::atomic_thread_fence(std::memory_order_relaxed)类型的栅栏不限制任何重排
2. 内存栅栏的使用
根据以上栅栏内存序,通过和原子内存次序的组合,可以形成三种同步。
1. release fence-acquire atomic同步
如下在两个线程运行的代码:
std::atomic<bool> atm;// Thread A
void WorkA() {// ops1std::atomic_thread_fence(std::memory_order_release);atm.store(true, std::memory_order_relaxed);
}// Thread B
void WorkB() {while (!atm.load(std::memory_order_acquire));// ops2
}
可以构成如下执行流程:
| Thread A | Thread B |
|---|---|
ops1 | |
F:release fence | Y:while(!atm.load(acquire)) |
X:atm.store(any_order) | ops2 |
- 由于
release fence操作限制ops1重排到X后面,atomic acquire限制ops2重排到Y前面,所以当Y执行完毕时,表示F前的所有操作一定执行完成了。因此该release fence与acquire atomic使得两个线程中的ops1部分的代码一定早于ops2部分的代码执行 - 根据上面的规则,X的操作只要是
store操作即可,内存序可以任意
2. release atomic-acquire fence同步
如下在两个线程运行的代码:
std::atomic<bool> atm;// Thread A
void WorkA() {// ops1atm.store(true, std::memory_order_release);
}// Thread B
void WorkB() {while (!atm.load(std::memory_order_relaxed));std::atomic_thread_fence(std::memory_order_acquire);// ops2
}
可以构成如下执行流程:
| Thread A | Thread B |
|---|---|
ops1 | Y:while(!atm.load(any_order)) |
X:atm.store(release) | F:acquire fence |
ops2 |
- 由于
acquire fence限制ops2重排到Y之前,atomic release限制ops1重排到X后面,当Y执行完毕时,X一定执行完成。因此,release atomic与acquire fence使得ops1的代码一定比ops2的代码先执行 - 根据上面的规则,Y的操作只要是
load操作即可,内存序可以任意
3. release fence-acquire fence同步
如下两个线程运行的代码:
std::atomic<bool> atm;// Thread A
void WorkA() {// ops1std::atomic_thread_fence(std::memory_order_release);atm.store(true, std::memory_order_relaxed);
}
// Thread B
void WorkB() {while (!atm.load(std::memory_order_relaxed));std::atomic_thread_fence(std::memory_order_acquire);// ops2
}
可以构成如下执行流程:
| Thread A | Thread B |
|---|---|
ops1 | Y:while(!``var.load(any_order)``) |
FA:release fence | FB:acquire fence |
X:var.store(any_order) | ops2 |
- 由于
release fence限制ops1必须在X之前执行,acquire fence限制ops2必须在Y之后执行。当Y执行完成后,表示X一定执行过了。因此,release fence与acquire fence使得ops1的代码一定早于ops2执行
参考资料:
- C++11中的内存模型上篇 - 内存模型基础
- 如何理解 C++11 的六种 memory order?
- c++并发编程1.内存序
- C++11中的内存模型下篇 - C++11支持的几种内存模型
- C++ memory order循序渐进(四)—— 在std::atomic_thread_fence 上应用std::memory_order实现不同的内存序
- 内存模型与c++中的memory order
相关文章:
)
《C++并发编程实战》笔记(五)
五、内存模型和原子操作 5.1 C中的标准原子类型 原子操作是不可分割的操作,它或者完全做好,或者完全没做。 标准原子类型的定义在头文件<atomic>中,类模板std::atomic<T>接受各种类型的模板实参,从而创建该类型对应…...
)
在Python中实现多目标优化问题(5)
在Python中实现多目标优化问题 在Python中实现多目标优化,除了传统的进化算法(如NSGA-II、MOEA/D)和机器学习辅助的方法之外,还有一些新的方法和技术。以下是一些较新的或较少被提及的方法: 1. 基于梯度的多目标优化…...
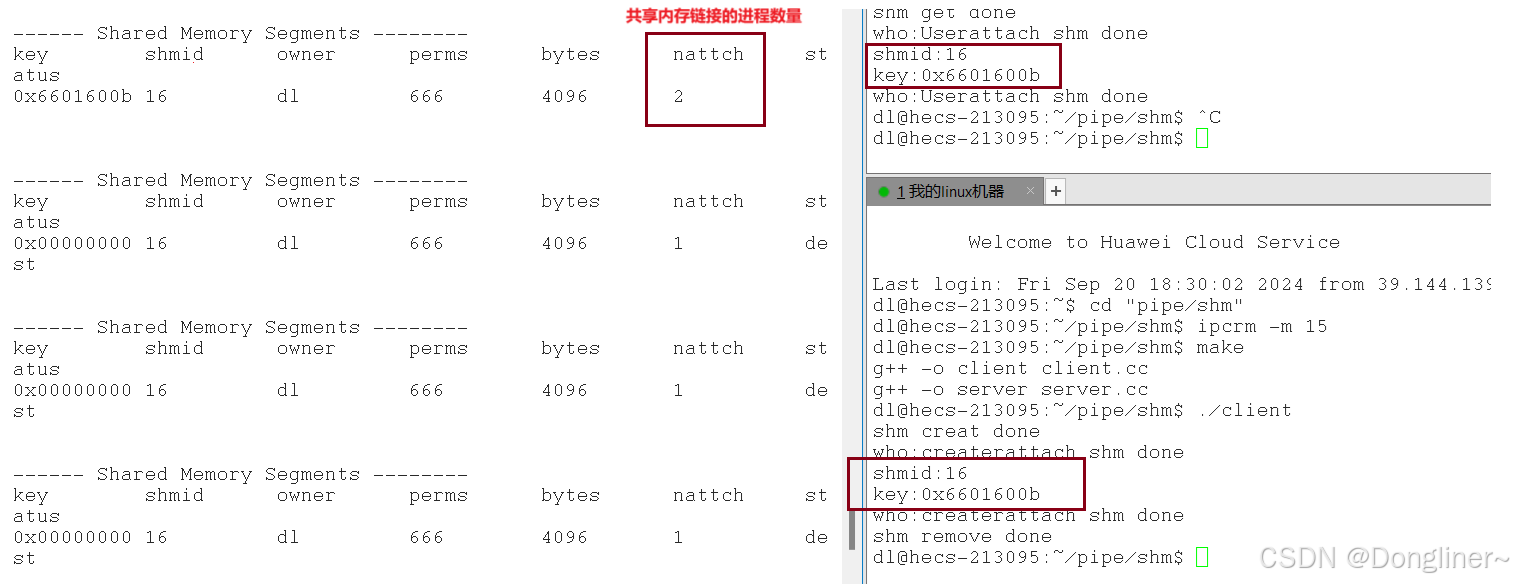
【Linux:共享内存】
共享内存的概念: 操作系统通过页表将共享内存的起始虚拟地址映射到当前进程的地址空间中共享内存是由需要通信的双方进程之一来创建但该资源并不属于创建它的进程,而属于操作系统 共享内存可以在系统中存在多份,供不同个数,不同进…...

今年Java回暖了吗
今年回暖了吗 仅结合师兄和同学的情况 BG 大多双非本 少部分211本 985硕 去年十月一之前 基本转正都失败 十月一之前0 offer 只有很少的人拿到美团 今年十月一之前 有HC的基本都转正了(美团、字节等),目前没有HC的说也有机会(…...

a = Sw,其中a和w是向量,S是矩阵,求w等于什么?w可以写成关于a和S的什么样子的公式
给定公式: a S w a S w aSw 其中: a a a 是已知向量, S S S 是已知矩阵, w w w 是未知向量。 我们的目标是求解 w w w,即将 w w w 表示为 a a a 和 S S S 的函数。 情况 1:矩阵 S S S 可逆 如果矩…...

多线程事务管理:Spring Boot 实现全局事务回滚
多线程事务管理:Spring Boot 实现全局事务回滚 在日常开发中,我们常常会遇到需要在多线程环境下进行数据库操作的场景。这类操作的挑战在于如何保证多个线程中的数据库操作要么一起成功,要么一起失败,即 事务的原子性。尤其是在多个线程并发执行的情况下,确保事务的一致性…...
Vue3 中集成海康 H5 监控视频播放功能
🌈个人主页:前端青山 🔥系列专栏:Vue篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来Vuet篇专栏内容:Vue-集成海康 H5 监控视频播放功能 目录 一、引言 二、环境搭建 三、代码解析 子组件部分 1.…...

Linux: eBPF: libbpf-bootstrap-master 编译
文章目录 简介编译运行展示输出展示:简介 这个是使用libbpf的一个例子; 编译 如果是一个可以联网的机器,这个libbpf-bootstrap的编译就方便了,完全是自动化的下载依赖文件;如果没有,就只能自己准备这些个软件。 需要:libbpf-static; [root@RH8-LCP c]# makeLIB …...
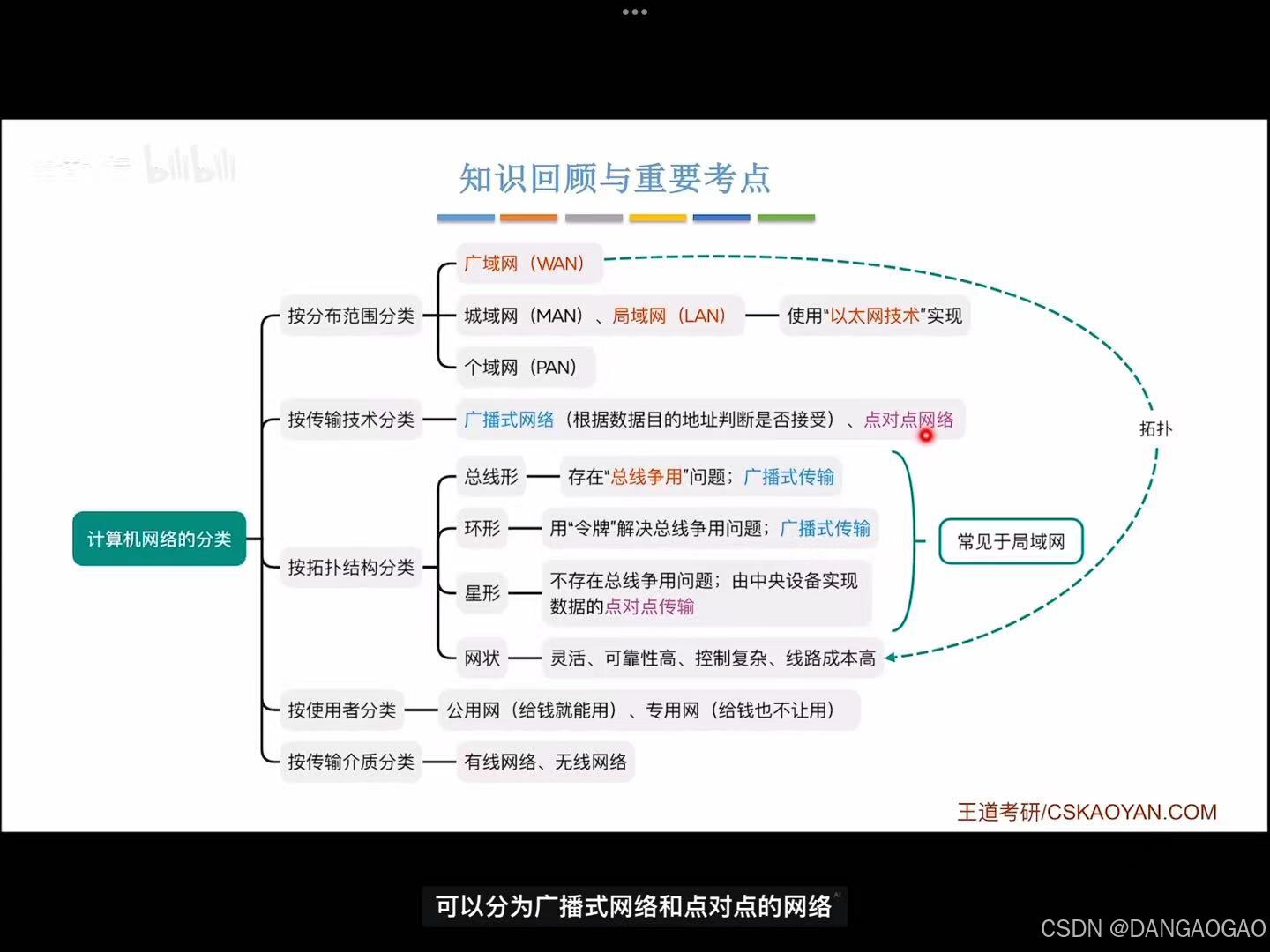
1.1.4 计算机网络的分类
按分布范围分类: 广域网(wan) 城域网(man) 局域网(lan) 个域网(pan) 注意:如今局域网几乎采用“以太网技术实现”,因此“以太网”几乎成了“局域…...

周家庄智慧旅游小程序
项目概述 周家庄智慧旅游小程序将通过数字化手段提升游客的旅游体验,依托周家庄的自然与文化资源,打造智慧旅游新模式。该小程序将结合虚拟现实(VR)、增强现实(AR)和人工智能等技术,提供丰富的…...

【在Linux世界中追寻伟大的One Piece】命名管道
目录 1 -> 命名管道 1.1 -> 创建一个命名管道 1.2 -> 匿名管道与命名管道的区别 1.3 -> 命名管道的打开规则 1.4 -> 例子 1 -> 命名管道 管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。如果我们想在不相关的进程之间交换数据&…...
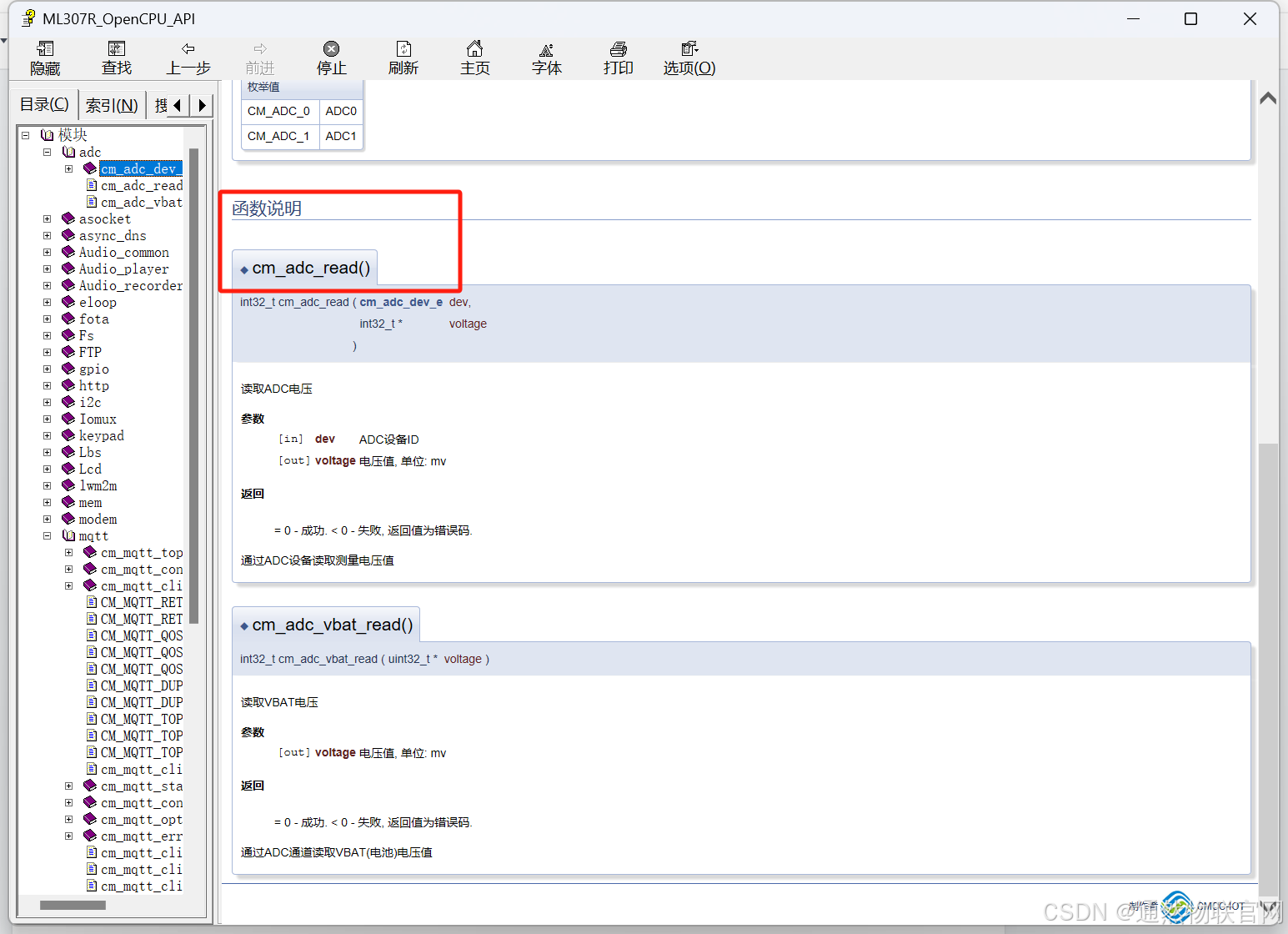
如意控物联网项目-ML307R模组软件及硬件调试环境搭建
软件及硬件调试环境搭建 1、 软件环境搭建及编译 a) 打开官方SDK,内涵APP-DEMO,通过vscode打开程序, 软件程序编写及编译参考下边说明文档链接 OneMO线上服务平台 编译需预安装python3.7以上版本,安装完python后,打开…...

大模型分布式训练并行技术(九)-总结
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。 而利用AI集群&a…...

uniapp view设置当前view之外的点击事件
推荐学习文档 golang应用级os框架,欢迎stargolang应用级os框架使用案例,欢迎star案例:基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总想学习更多golang知识,这里有免费的golang学习笔…...

【Mybatis篇】动态SQL的详细带练
🧸安清h:个人主页 🎥个人专栏:【计算机网络】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 文章目录 🎯一.动态SQL简单介绍 🚦动态S…...

【MyBatis-Plus】 学习记录 常用功能及代码生成器使用
文章目录 1. 环境准备2. 创建基础实体类3. 编写 Mapper 接口4. Service 层5. 控制器层6. 分页功能7. 条件构造器8. 配置乐观锁9. 常见问题10. 代码生成器1. 创建数据库表2. 引入依赖3. 配置数据库连接4. 编写代码生成器5. 运行代码生成器6. 查看生成的代码 MyBatis-Plus 是一个…...

HalconDotNet实现OCR详解
文章目录 一、基于字符分割的 OCR二、基于模板匹配的 OCR三、基于深度学习的 OCR四、基于特征提取的 OCR五、基于区域建议的 OCR 一、基于字符分割的 OCR 字符分割是 OCR 中的一个重要步骤。首先,对包含文本的图像进行预处理,如去噪、二值化等操作&#…...

手搓一个Agent#Datawhale 组队学习Task3
书接上回,首先回顾一下Task2的一些补充: Task2主要任务是从零预训练一个tiny-llama模型,熟悉一下Llama的模型架构和流程。然后测试一下模型的效果。总的来说,因为某些未知的原因,loss一直没有降下去,导致最…...

基于SpringBoot+Vue+MySQL的在线酷听音乐系统
系统展示 用户前台界面 管理员后台界面 系统背景 随着互联网技术的飞速发展,网络已成为人们日常生活中不可或缺的一部分。在线音乐服务因其便捷性和丰富性,逐渐成为用户获取音乐内容的主要渠道。然而,传统的音乐播放平台往往存在歌曲资源有限…...

大数据实时数仓Hologres(一):Hologres 简单介绍
文章目录 Hologres 简单介绍 一、什么是实时数仓 Hologres 二、产品优势 1、专注实时场景 2、亚秒级交互式分析 3、统一数据服务出口 4、开放生态 5、MaxCompute查询加速 6、计算存储分离架构 三、应用场景 搭建实时数仓 四、产品架构 1、Shared Disk/Storage &am…...

汽车ECU BootLoader开发:基于CAN总线与MPC57XX系列MCU
汽车ECU BootLoader开发基于CAN总线通信MPC57XX系列MCU bootloader开发 文档54页 在汽车电子领域,ECU(Electronic Control Unit)的重要性不言而喻,而BootLoader则是ECU中关键的一环。今天咱们就来聊聊基于CAN总线通信,…...

Seed-VC语音转换工具终极指南:零样本语音克隆技术完全解析
Seed-VC语音转换工具终极指南:零样本语音克隆技术完全解析 【免费下载链接】seed-vc zero-shot voice conversion & singing voice conversion, with real-time support 项目地址: https://gitcode.com/GitHub_Trending/se/seed-vc Seed-VC作为当前最先进…...

ms-swift框架实战:从零构建高效Embedding微调流水线
1. 为什么需要定制Embedding模型? 在智能客服问答匹配这类场景中,预训练的通用Embedding模型往往表现不佳。我去年做过一个电商客服项目,直接用开源Embedding模型处理"怎么退货"这类问题时,会把"如何退款"、&…...

低成本AI方案:OpenClaw对接本地Qwen3.5-9B替代ChatGPT API
低成本AI方案:OpenClaw对接本地Qwen3.5-9B替代ChatGPT API 1. 为什么选择本地部署Qwen3.5-9B? 作为一名长期使用OpenAI API的开发者,我最近开始尝试将OpenClaw与本地部署的Qwen3.5-9B模型对接。这个转变源于一个简单但痛苦的事实࿱…...

EfficientDet的‘复合缩放’到底强在哪?对比YOLOv5、RetinaNet的模型扩展策略
EfficientDet复合缩放策略的工程实践解析:从理论优势到部署优化 1. 目标检测模型扩展的技术演进脉络 计算机视觉领域对高效目标检测的需求从未如此迫切。随着应用场景从云端服务器向边缘设备、移动终端和嵌入式系统的扩展,算法工程师们面临着一个核心矛…...

告别绿幕!安卓免Root虚拟视频插件开发避坑指南:从Media3播放到Xposed Hook的完整流程
安卓虚拟视频插件开发实战:从Media3解码到系统Hook的避坑指南 在移动端开发领域,音视频处理与系统级功能结合一直是技术难点与创新点交汇处。许多开发者尝试过在安卓平台上实现摄像头替换功能,却往往在视频编解码、系统API拦截和性能优化等环…...
)
听说拍照的人会拿相似的鱼皮豆代替野生鹌鹑蛋拍照(防原创)
听说拍照的人会拿相似的鱼皮豆代替野生鹌鹑蛋拍照(防原创)大家都知道吃野生动物会得怪病,吃野生植物很容易中毒因为野生植物很多都有毒,获取野生鹌鹑蛋属于盗猎野生动植物破坏野生环境(在野外拍摄写生不破坏野生环境除…...

BG3ModManager全攻略:从基础配置到故障解决的模组管理大师之路
BG3ModManager全攻略:从基础配置到故障解决的模组管理大师之路 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 一、基础配置:搭建你的模组管理中心 让游戏与工具…...

3步解决Atlas OS中Xbox登录错误0x89235107的实用方案
3步解决Atlas OS中Xbox登录错误0x89235107的实用方案 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.com/GitHub_Trending/atlas1/Atlas …...

保姆级教程:在RHEL 8上彻底搞定X-Server远程连接,让xeyes不再报‘Error can‘t open display‘
深度解析RHEL 8远程X11连接:从原理到实战的全链路解决方案 当你在RHEL 8服务器上尝试通过SSH转发X11图形界面时,是否遇到过xeyes测试程序报出"Error: Cant open display"的困扰?这看似简单的错误背后,实际上隐藏着新版R…...