Pytorch 学习手册
零 相关资料
官方网址
官方网址下的API搜索网站
一 定义
深度学习框架是用于设计、训练和部署深度学习模型的软件工具包。这些框架提供了一系列预定义的组件,如神经网络层(卷积层、全连接层等)、损失函数、优化器以及数据处理工具,使得开发者可以更加高效地构建复杂的机器学习模型。此外,它们还通常包含自动微分功能,这极大地简化了梯度计算过程,这是训练神经网络时反向传播算法的核心部分。
一些流行的深度学习框架包括:
TensorFlow - 由Google开发,支持多种语言接口,如Python、C++等,并且拥有一个活跃的社区和丰富的资源库。TensorFlow提供了Keras作为其高级API,方便用户快速搭建模型。
PyTorch - 由Facebook的人工智能研究实验室(FAIR)开发,以动态计算图著称,特别适合于需要灵活实验的研究者。它也使用Python作为主要编程语言,并且因其直观易用而受到广泛欢迎。
二 基础知识
1. .cuda()作用
将计算由CPU转移至GPU;
可以将变量转移,也可以对函数转移
import torch
# 创建一个张量
x = torch.tensor([1.0, 2.0, 3.0])
# 将张量移动到 GPU
x = x.cuda()
# 或者对于模型
model = MyModel()
model = model.cuda()
如果机器上有多个 GPU,可以在 .cuda() 中指定 GPU 的索引,例如 x.cuda(0) 将张量移动到第一个 GPU。
2 tensor打印属性介绍
# requires_grad,grad_fn,grad的含义及使用
requires_grad: 如果需要为张量计算梯度,则为True,否则为False。我们使用pytorch创建tensor时,可以指定requires_grad为True(默认为False),
grad_fn: grad_fn用来记录变量是怎么来的,方便计算梯度,y = x*3,grad_fn记录了y由x计算的过程。
grad:当执行完了backward()之后,通过x.grad查看x的梯度值。
创建一个Tensor并设置requires_grad=True,requires_grad=True说明该变量需要计算梯度。
>>x = torch.ones(2, 2, requires_grad=True)
tensor([[1., 1.], [1., 1.]], requires_grad=True)
>>print(x.grad_fn) # None
3 张量
玩转Pytorch张量(Tensor)
一、什么是张量(Tensor)?
Tensor是Pytorch中最底层的核心的数据结构。Pytorch中的所有操作都是在张量的基础上进行的。

也就是说,一个Tensor是一个包含单一数据类型的多维矩阵。通常,其多维特性用三维及以上的矩阵来描述,例如下图所示:单个元素为标量(scalar),一个序列为向量(vector),多个序列组成的平面为矩阵(matrix),多个平面组成的立方体为张量(tensor)。
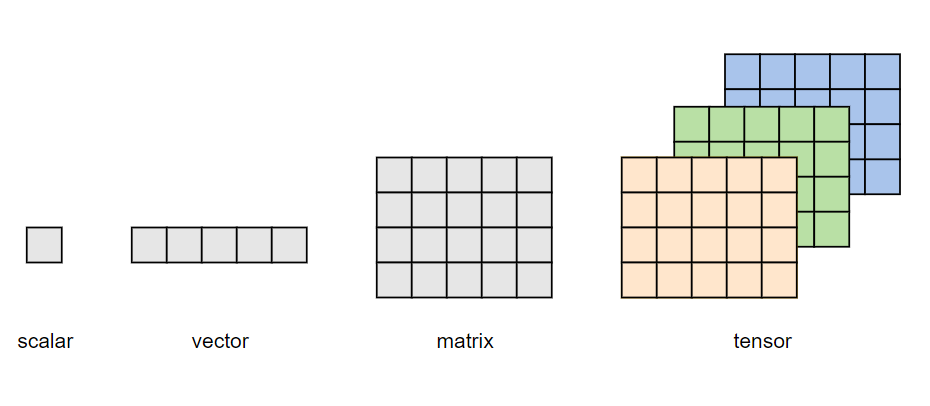
当然,张量也无需严格限制在三维及以上才叫张量,就像矩阵也有一维、二维矩阵乃至多维矩阵之分一样。
「在深度学习的范畴内,标量、向量和矩阵也可分为称为零维张量、一维张量、二维张量。」
二、为什么深度学习要搞出Tensor?
熟悉机器学习的小伙伴们应该都知道,有监督机器学习模型的输入X通常是多个特征列组成的二维矩阵,输出y是单个特征列组成的标签向量或多个特征列组成的二维矩阵。那么深度学习中,为何要定义多维矩阵Tensor呢?
深度学习当前最成熟的两大应用方向莫过于CV和NLP,其中CV面向图像和视频,NLP面向语音和文本,二者分别以卷积神经网络和循环神经网络作为核心基础模块,且标准输入数据集都是至少三维以上。其中,
- 图像数据集:至少包含三个维度(样本数Nx图像高度Hx图像宽度W);如果是彩色图像,则还需增加一个通道C,包含四个维度(NxHxWxC);如果是视频帧,可能还需要增加一个维度T,表示将视频划分为T个等时长的片段。
- 文本数据集:包含三个维度(样本数N×序列长度L×特征数H)。
因此,输入学习模型的输入数据结构通常都要三维以上,这也就促使了Tensor的诞生。
三、Tensor创建
1.使用torch.tensor()函数直接创建
在PyTorch中,torch.tensor()函数用于直接从Python的数据结构(如列表、元组或NumPy数组)中创建一个新的张量。
"""
data:数据,可以是list,numpy
dtype:数据类型,默认与data对应
device:张量所在的设备(cuda或cpu)
requires_grad:是否需要梯度
pin_memory:是否存于锁存内存
"""
torch.tensor(data,dtype=None,device=None,requires_grad=False,pin_memory=False)
pin_memor用于实现锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
如需创建一个放在GPU的数据,则可做如下修改,运行结果同上。
import numpy as np
import torch
device= torch.device("cuda" if torch.cuda.is_available() else 'cpu')
arr = np.ones((3, 3))
print("ndarray的数据类型:", arr.dtype)
t = torch.tensor(arr, device=device)
print(t)
2.根据数值创建张量
'''
size:张量的形状
out:输出的张量,如果指定了out,torch.zeros()返回的张量则会和out共享同一个内存地址
layout:内存中的布局方式,有strided,sparse_coo等。如果是稀疏矩阵,则可以设置为sparse_coo以减少内存占用
device:张量所在的设备(cuda或cpu)
requires_grad:是否需要梯度
'''
torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
四、Tensor属性
1.Tensor形状
张量具有如下形状属性:
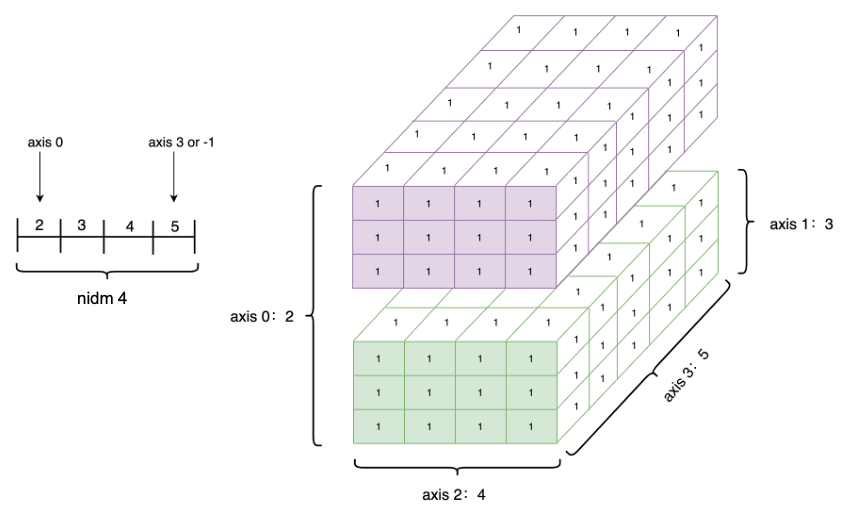
- Tensor.ndim:张量的维度,例如向量的维度为1,矩阵的维度为2。
- Tensor.shape:张量每个维度上元素的数量。
- Tensor.shape[n]:张量第n维的大小。第n维也称为轴(axis)。
- Tensor.numel:张量中全部元素的个数。
import torch
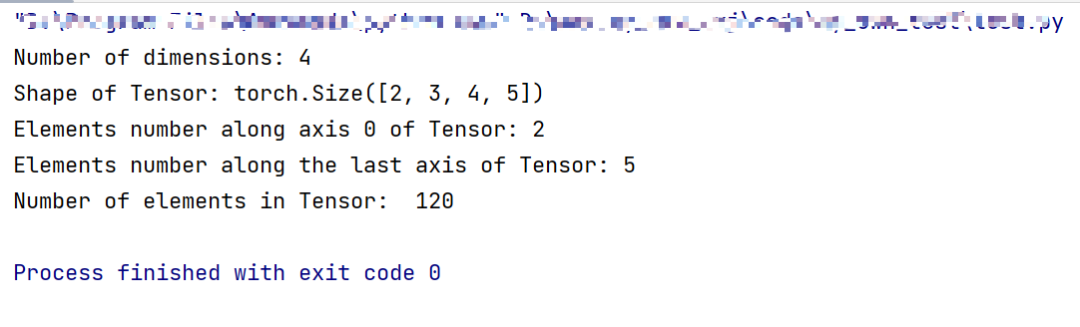
Tensor=torch.ones([2,3,4,5])
print("Number of dimensions:", Tensor.ndim)
print("Shape of Tensor:", Tensor.shape)
print("Elements number along axis 0 of Tensor:", Tensor.shape[0])
print("Elements number along the last axis of Tensor:", Tensor.shape[-1])
print('Number of elements in Tensor: ', Tensor.numel()) #用.numel表示元素个数
如下是创建一个四维Tensor,并通过图形直观表达以上几个概念的关系。
Tensor的axis、shape、dimension、ndim之间的关系如下图所示。
五、Tensor操作
1.形状重置
Tensor的shape可通过torch.reshape接口来改变。例如:
import torch
Tensor =torch.tensor([[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]],[[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]],[[21, 22, 23, 24, 25],[26, 27, 28, 29, 30]]])
print("the shape of Tensor:", Tensor.shape)
#利用reshape改变形状
reshape_Tensor = torch.reshape(Tensor, [2, 5, 3])
print("After reshape:\n", reshape_Tensor)

从输出结果看,将张量从[3, 2, 5]的形状reshape为[2, 5, 3]的形状时,张量内的数据不会发生改变,元素顺序也没有发生改变,只有数据形状发生了改变。
在指定新的shape时存在一些技巧:
-1 表示这个维度的值是从Tensor的元素总数和剩余维度自动推断出来的。因此,有且只有一个维度可以被设置为-1。
0 表示该维度的元素数量与原值相同,因此shape中0的索引值必须小于Tensor的维度(索引值从 0 开始计,如第 1 维的索引值是 0,第二维的索引值是 1)。
# 直接指定目标 shape
origin:[3, 2, 5] reshape:[3, 10] actual: [3, 10]
# 转换为 1 维,维度根据元素总数推断出来是 3*2*5=30
origin:[3, 2, 5] reshape:[-1] actual: [30]
# 转换为 2 维,固定一个维度 5,另一个维度根据元素总数推断出来是 30÷5=6
origin:[3, 2, 5] reshape:[-1, 5] actual: [6, 5]
# reshape:[0, -1]中 0 的索引值为 0,按照规则
# 转换后第 0 维的元素数量与原始 Tensor 第 0 维的元素数量相同,为3
# 第 1 维的元素数量根据元素总值计算得出为 30÷3=10。
origin:[3, 2, 5] reshape:[0, -1] actual: [3, 10]
# reshape:[3, 1, 0]中 0 的索引值为 2
# 但原 Tensor 只有 2 维,无法找到与第 3 维对应的元素数量,因此出错。
origin:[3, 2] reshape:[3, 1, 0] error:
4 nn.Embedding
详见nn.Embedding解析
nn.Embedding 是它的主要作用是将输入的整数序列映射为连续的向量表示
nn.Embedding 的输入通常是一个整数索引(代表词汇或符号),输出是对应的向量表示。该模块可以看作是一个查找表,其中每个词汇都有一个与之对应的向量。具体来说,它有两个关键参数:
num_embeddings: 词汇表的大小,即可以嵌入的词汇数量。embedding_dim: 每个词汇对应的向量维度。
注:embeddings中的值是正态分布N(0,1)中随机取值。
如何使用
在NLP任务中,首先要对文本进行处理,将文本进行编码转换,形成向量表达,embedding处理文本的流程如下:
(1)输入一段文本,中文会先分词(如jieba分词),英文会按照空格提取词
(2)首先将单词转成字典的形式,由于英语中以空格为词的分割,所以可以直接建立词典索引结构。类似于:word2id = {‘i’ : 1, ‘like’ : 2, ‘you’ : 3, ‘want’ : 4, ‘an’ : 5, ‘apple’ : 6} 这样的形式。如果是中文的话,首先进行分词操作。
(3)然后再以句子为list,为每个句子建立索引结构,list [ [ sentence1 ] , [ sentence2 ] ] 。以上面字典的索引来说,最终建立的就是 [ [ 1 , 2 , 3 ] , [ 1 , 4 , 5 , 6 ] ] 。这样长短不一的句子
(4)接下来要进行padding的操作。由于tensor结构中都是等长的,所以要对上面那样的句子做padding操作后再利用 nn.Embedding 来进行词的初始化。padding后的可能是这样的结构
[ [ 1 , 2 , 3, 0 ] , [ 1 , 4 , 5 , 6 ] ] 。其中0作为填充。(注意:由于在NMT任务中肯定存在着填充问题,所以在embedding时一定存在着第三个参数,让某些索引下的值为0,代表无实际意义的填充)
比如有两个句子:
I want a plane
I want to travel to Beijing
将两个句子转化为ID映射:
{I:1,want:2,a:3,plane:4,to:5,travel:6,Beijing:7}
转化成ID表示的两个句子如下:
1,2,3,4
1,2,5,6,5,7
import torch
from torch import nn# 创建最大词个数为10,每个词用维度为4表示
embedding = nn.Embedding(10, 4)# 将第一个句子填充0,与第二个句子长度对齐
in_vector = torch.LongTensor([[1, 2, 3, 4, 0, 0], [1, 2, 5, 6, 5, 7]])
out_emb = embedding(in_vector)
print(in_vector.shape)
print((out_emb.shape))
print(out_emb)
print(embedding.weight)
torch.Size([2, 6]) # 2行6列
torch.Size([2, 6, 4]) #2个6行4列
tensor([[[-0.6642, -0.6263, 1.2333, -0.6055],[ 0.9950, -0.2912, 1.0008, 0.1202],[ 1.2501, 0.1923, 0.5791, -1.4586],[-0.6935, 2.1906, 1.0595, 0.2089],[ 0.7359, -0.1194, -0.2195, 0.9161],[ 0.7359, -0.1194, -0.2195, 0.9161]],[[-0.6642, -0.6263, 1.2333, -0.6055],[ 0.9950, -0.2912, 1.0008, 0.1202],[-0.3216, 1.2407, 0.2542, 0.8630],[ 0.6886, -0.6119, 1.5270, 0.1228],[-0.3216, 1.2407, 0.2542, 0.8630],[ 0.0048, 1.8500, 1.4381, 0.3675]]], grad_fn=<EmbeddingBackward0>)
Parameter containing:
tensor([[ 0.7359, -0.1194, -0.2195, 0.9161],[-0.6642, -0.6263, 1.2333, -0.6055],[ 0.9950, -0.2912, 1.0008, 0.1202],[ 1.2501, 0.1923, 0.5791, -1.4586],[-0.6935, 2.1906, 1.0595, 0.2089],[-0.3216, 1.2407, 0.2542, 0.8630],[ 0.6886, -0.6119, 1.5270, 0.1228],[ 0.0048, 1.8500, 1.4381, 0.3675],[ 0.3810, -0.7594, -0.1821, 0.5859],[-1.4029, 1.2243, 0.0374, -1.0549]], requires_grad=True)例如,如果你有一个大小为 1000 的词汇表,并希望每个词汇用一个 300 维的向量来表示,你可以这样定义 nn.Embedding:
import torch.nn as nn
# 词汇表大小为 1000,每个词汇的嵌入维度为 300
embedding = nn.Embedding(num_embeddings=1000, embedding_dim=300)
# 输入一个词汇索引
input = torch.tensor([1, 2, 3, 4])
# 获取对应的嵌入向量
output = embedding(input)
print("output_size:",output.size(),"\n.output:",output)
------------------------------------
output_size: torch.Size([4, 300])
.output: tensor([[ 2.3543, 1.1523, -1.6173, ..., -0.5308, -0.8865, 0.1191],[ 0.9140, 0.1824, -0.6363, ..., 0.9007, -0.3558, 2.0714],[ 1.0525, 0.0092, 0.8510, ..., 0.7767, -1.3282, 0.1715],[ 0.8045, 1.3735, 0.7389, ..., -1.2809, -0.4609, 0.4125]],grad_fn=<EmbeddingBackward0>)
参考
https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html
3 nn.Dropout用法与作用
nn.Dropout 是 PyTorch 中的一个模块,用于防止神经网络过拟合的一种正则化技术。它的主要作用是在训练期间随机将一部分神经元的输出设为零(即“丢弃”),从而减少模型对特定神经元的依赖,增强模型的泛化能力。
用法
在使用 nn.Dropout 时,你可以指定一个 p 参数,该参数表示在每次前向传播时,以多大的概率将神经元的输出置零。p 的取值范围在 0 到 1 之间,通常设为 0.5 左右。
import torch
import torch.nn as nn# 创建一个 Dropout 层,丢弃率为 0.5
dropout = nn.Dropout(p=0.5)# 输入数据
input_data = torch.randn(5, 10)# 应用 Dropout 层
output_data = dropout(input_data)
print("input_size:",input_data.size(),"\n.input:",input_data)
print("output_size:",output_data.size(),"\n.output:",output_data)
-----------------------------
input_size: torch.Size([5, 10])
.input: tensor([[ 0.4757, 1.0549, 0.4897, -0.3439, 0.9176, 0.2441, 0.4073, 0.0852,-0.3969, -0.7151],[-0.4394, 0.7188, 0.7403, -0.1388, 0.9963, 0.0678, 1.1171, 0.4086,-0.1567, -0.4750],[-0.0219, -0.2155, -0.2252, -0.7611, 1.4713, -0.5379, 0.4363, -1.5307,-0.9243, -0.5168],[-0.3247, 0.9712, -0.4859, 0.2869, -0.9935, -0.8477, 2.1244, -0.0360,0.3316, -1.1796],[-2.4401, -0.3394, -0.4239, -0.1039, -1.7476, 0.5174, -1.0108, -0.2301,-0.1675, -0.1827]])
output_size: torch.Size([5, 10])
.output: tensor([[ 0.0000, 0.0000, 0.0000, -0.0000, 0.0000, 0.4881, 0.0000, 0.1704,-0.7937, -0.0000],[-0.8789, 0.0000, 0.0000, -0.0000, 1.9926, 0.0000, 0.0000, 0.8172,-0.3134, -0.0000],[-0.0439, -0.0000, -0.4504, -0.0000, 0.0000, -0.0000, 0.8727, -3.0614,-1.8487, -0.0000],[-0.6495, 1.9424, -0.9717, 0.5739, -0.0000, -1.6955, 4.2488, -0.0000,0.0000, -0.0000],[-4.8802, -0.6788, -0.0000, -0.0000, -0.0000, 1.0348, -0.0000, -0.0000,-0.3349, -0.3654]])
另外还可以通过如下方式改变shape:
torch.squeeze:可实现Tensor的降维操作,即把Tensor中尺寸为1的维度删除。
torch.unsqueeze:可实现Tensor的升维操作,即向Tensor中某个位置插入尺寸为1的维度。
torch.flatten,将Tensor的数据在指定的连续维度上展平。
torch.transpose,对Tensor的数据进行重排。
4 维度变换
1. pe
pe 是一个二维张量,表示位置编码矩阵。它的形状是 [max_len, d_model],其中 max_len 是序列的最大长度,d_model 是每个位置的嵌入维度。每一行对应一个位置的编码。
2. pe.unsqueeze(0)
unsqueeze 函数会在指定位置添加一个新的维度。在这里,pe.unsqueeze(0) 会在第 0 维添加一个新的维度,使 pe 的形状从 [max_len, d_model] 变成 [1, max_len, d_model]。添加这个新维度是为了方便后续的批处理操作,这个维度通常表示批次(batch)。
3. pe.transpose(0, 1)
transpose 函数用于交换张量的两个维度。在这里,pe.transpose(0, 1) 将第 0 维和第 1 维交换,即将形状从 [1, max_len, d_model] 变成 [max_len, 1, d_model]。这样操作的目的是将位置维度放到第一维,这样可以很方便地对序列中的每个位置进行操作。
总结
经过这两个操作后,位置编码张量 pe 的形状变为 [max_len, 1, d_model]。这样做的目的是为了在前向传播时能够将位置编码添加到输入序列的每个位置上。具体来说,当有一个输入张量 x,其形状为 [seq_len, batch_size, d_model] 时,通过 x = x + self.pe[:x.size(0), :] 将位置编码加到 x 上。由于 self.pe[:x.size(0), :] 的形状为 [seq_len, 1, d_model],它可以自动广播(broadcast)以匹配 x 的形状。
参考
- # Transformer 的 Pytorch 代码实现讲解
- # Pytorch中nn.Module和nn.Sequencial的简单学习
三 类相关
1 多继承
类的继承与重载
# Pytorch构建网络模型时super(class, self).init()的作用
# Python多继承与super使用详解
# python多继承及其super的用法
相关文章:
Pytorch 学习手册
零 相关资料 官方网址 官方网址下的API搜索网站 一 定义 深度学习框架是用于设计、训练和部署深度学习模型的软件工具包。这些框架提供了一系列预定义的组件,如神经网络层(卷积层、全连接层等)、损失函数、优化器以及数据处理工具…...
——Vite 环境变量)
第十一章 【前端】调用接口(11.1)——Vite 环境变量
第十一章 【前端】调用接口 11.1 Vite 环境变量 参考:https://cn.vitejs.dev/guide/env-and-mode.html Vite 在一个特殊的 import.meta.env 对象上暴露环境变量。为了防止意外地将一些环境变量泄漏到客户端,只有以 VITE_ 为前缀的变量才会暴露给经过 …...

MySQL添加时间戳字段并且判断插入或更新时间
文章目录 步骤 1: 修改表结构步骤 2: 插入或更新数据步骤 3: 查询数据并判断时间完整示例 在MySQL中,可以在表中添加一个时间戳字段来记录每条数据的最后插入或更新时间。然后,在插入或更新数据时,自动更新这个时间戳字段。最后,在…...
)
SOA(面相服务架构)
目录 SOA的基本概念 SOA的关键特性 SOA的实现步骤 SOA的技术实现 SOA的应用场景 面向服务的架构(Service-Oriented Architecture, SOA)是一种软件设计理念和架构模式,旨在通过网络协议将不同的服务相互连接和集成,以构建灵活、可扩展和可重用的应用系统。SOA的…...
关联场景中,如何从模型(一)关联到模型(多)的某个字段)
One2many(一对多)关联场景中,如何从模型(一)关联到模型(多)的某个字段
好的,我们用一个更通俗的例子来解释不同模块之间的模型关联,场景是“学校和学生”的例子。 1. 场景介绍 假设我们有两个模块: 学校模块 (school):用于管理学校信息。学生模块 (student):用于管理学生信息。 每个学…...

LLaMA 3 和 OpenAI有哪些相同点和不同点?
LLaMA 3(Meta 的 LLaMA 系列)和 OpenAI 的模型(如 GPT 系列)都是先进的 大语言模型(LLMs),它们在训练、应用场景和能力上有很多相似之处,但也存在显著的不同点。以下是一些关键相同点…...

Spring 事务管理及失效总结
所谓事务管理,其实就是“按照给定的事务规则来执行提交或者回滚操作”。 Spring 并不直接管理事务,而是提供了多种事务管理器,他们将事务管理的职责委托给 Hibernate 或者 JTA 等持久化机制所提供的相关平台框架的事务来实现。 Spring 事务…...

全局思维下的联合创新:华为携手ISV伙伴助推银行核心平稳升级
文 | 螳螂观察 作者 | 李永华 随着数字金融快速发展,对核心系统提出了“海量、高效、弹性、扩展、敏捷”等新需求,区域性银行面临核心系统升级的迫切需要,对金融科技厂商而言也催生了庞大的机遇和空间。 只是,银行核心系统是金…...

深度估计任务中的有监督和无监督训练
在计算机视觉领域,深度估计任务一直是研究的热点之一。它旨在通过图像或视频数据来推断场景中物体与相机之间的距离,为许多应用提供关键信息,如自动驾驶、机器人导航、增强现实等。在深度估计任务中,有监督训练和无监督训练是两种…...

扩散模型DDPM代码实践
安装diffusers pip install diffusers 按照diffusers官方代码 from diffusers import DDPMPipelinepipe DDPMPipeline.from_pretrained("google/ddpm-cat-256")image pipe().images[0]image.save("/data/zhz/projects/diffusion/output/ddpm_generated_imag…...

关于GPIO输入模式的配置选择
GPIO(通用输入输出)口是嵌入式系统中的重要组成部分,输入模式使得微控制器能够与外部世界进行交互。本文将探讨GPIO输入模式中的浮空输入、上拉输入和下拉输入的配置、使用场景及注意事项,并提供一些决策指导,帮助读者…...

【Kubernetes】日志平台EFK+Logstash+Kafka【实战】
一,环境准备 (1)下载镜像包(共3个): elasticsearch-7-12-1.tar.gz fluentd-containerd.tar.gz kibana-7-12-1.tar.gz (2)在node节点导入镜像: ctr -nk8s.io images i…...

今天推荐一个文档管理系统 Dorisoy.Pan
Dorisoy.Pan 是一个基于 .NET 8 和 WebAPI 构建的文档管理系统,它集成了 Autofac、MediatR、JWT、EF Core、MySQL 8.0 和 SQL Server 等技术,以实现一个简单、高性能、稳定且安全的解决方案。 这个系统支持多种客户端,包括网站、Android、iO…...

【RocketMQ】消费失败重试与死信消息
🎯 导读:本文档详细介绍了RocketMQ中的重试机制与死信消息处理方法。对于生产者而言,文档提供了如何配置重试次数的具体示例;而对于消费者,它解释了默认情况下消息消费失败后的重试策略,并展示了如何通过代…...

注册安全分析报告:闪送
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

SpringCloud入门
SpringCloud 原版笔记:狂神说笔记——SpringCloud快速入门23 - subeiLY - 博客园 (cnblogs.com) 一.前言 常见面试题 什么是微服务? 微服务之间是如何独立通讯的? SpringCloud 和 Dubbo有哪些区别? SpringBoot和SpringCloud&…...

js替换css主题变量并切换iconfont文件
iconfont不止有单色、双色的图标,还有很多【多色】的图标,于是不能【去色】,只能手动替换primary 新建一个iconfont,替换过主题色的,然后与旧的iconfont配合切换使用 主要如下: reqiure之前必须【清除缓…...

UI设计师面试整理-设计趋势和行业理解
在UI设计师的面试中,了解当前的设计趋势和行业动态可以让你在面试中展示你的前瞻性思维和对设计领域的深刻理解。面试官希望看到你不仅具备扎实的设计技能,还能够洞察和应用最新的设计趋势和技术。以下是一些当前的设计趋势和如何在面试中展示你对这些趋势的理解和应用的建议…...

Java零工市场小程序如何改变自由职业者生活
如今,自由职业者越来越多,他们需要找到合适的工作机会,Java零工市场小程序,为自由职业者提供了一个方便、快捷的寻找工作机会的方式,这样一来,改变了自由职业者找寻工作的方式,也提高了他们的收…...

android11 自动授权访问sdcard
目录 步骤1 步骤2 步骤1 frameworks/base/core/java/com/android/internal/os/ZygoteInit.java OsConstants.CAP_SYS_PTRACE,OsConstants.CAP_SYS_TIME,OsConstants.CAP_SYS_TTY_CONFIG,OsConstants.CAP_WAKE_ALARM,OsConstants.CAP_BLOCK_SUSPENDOsConstants.CAP_BLOCK_SUS…...

MATLAB小白也能懂的LTI系统时域分析:从零输入响应到阶跃响应全攻略
MATLAB零基础玩转LTI系统时域分析:从微分方程到响应曲线实战指南 刚接触信号与系统课程时,看到那些复杂的微分方程和响应曲线总让人望而生畏。但别担心,今天我们就用MATLAB这把"瑞士军刀",带你轻松拆解LTI(线…...

Z-Image-Turbo-辉夜巫女角色一致性生成:多角度角色设定图效果展示
Z-Image-Turbo-辉夜巫女角色一致性生成:多角度角色设定图效果展示 最近在尝试用AI做角色设计,最头疼的就是角色一致性。今天想画个正面,明天想画个侧面,结果生成的角色看起来像两个人,衣服细节也对不上,简…...

notepad--跨平台编辑器:重新定义文本处理的10个效率革命
notepad--跨平台编辑器:重新定义文本处理的10个效率革命 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- 在…...
)
华为交换机日常运维:5个必会的端口状态查询命令(含display interface brief详解)
华为交换机端口状态深度解析:从基础查询到实战排障 清晨7:30,机房告警灯突然闪烁——核心业务端口异常离线。作为网络运维工程师,如何在十分钟内定位问题?掌握端口状态查询命令不仅是基础技能,更是快速响应故障的第一道…...

普通Java开发如何转型大模型方向?
说真的,这两年看着身边一个个搞Java的哥们开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。 结果一个ChatGPT火了之后,整条后端线上的人都开始有点慌了,谁还不是在想…...

Prototype.js完全指南:革命性JavaScript框架入门与实战
Prototype.js完全指南:革命性JavaScript框架入门与实战 【免费下载链接】prototype 项目地址: https://gitcode.com/gh_mirrors/pro/prototype Prototype.js是JavaScript开发史上具有里程碑意义的革命性框架,它为Web开发者提供了强大的面向对象编…...

【CLion+Keil】无缝迁移:在CLion中高效开发与管理Keil工程
1. 为什么要在CLion中开发Keil工程? 作为一名嵌入式开发者,我经常遇到这样的困扰:团队其他成员使用Keil MDK开发STM32项目,而我想用CLion这个更现代的IDE。Keil虽然稳定可靠,但代码补全、重构、调试等功能确实不如CLio…...

Ralph与现有开发流程集成:10个关键策略实现CI/CD管道与质量保障
Ralph与现有开发流程集成:10个关键策略实现CI/CD管道与质量保障 【免费下载链接】ralph Ralph is an autonomous AI agent loop that runs Amp repeatedly until all PRD items are complete. 项目地址: https://gitcode.com/gh_mirrors/ralph1/ralph Ralph…...

Qwen3-0.6B-FP8效果对比:FP8量化对Qwen3-0.6B在AlpacaEval 2.0得分影响深度分析
Qwen3-0.6B-FP8效果对比:FP8量化对Qwen3-0.6B在AlpacaEval 2.0得分影响深度分析 最近,大模型部署和推理的效率问题越来越受到关注。模型越大,对显存和算力的要求就越高,这让很多想用大模型的朋友望而却步。有没有办法让模型“瘦身…...

Z-Image-Turbo孙珍妮LoRA实战:为摄影工作室生成AI艺术写真风格预览图
Z-Image-Turbo孙珍妮LoRA实战:为摄影工作室生成AI艺术写真风格预览图 1. 引言:当摄影工作室遇见AI写真 想象一下这个场景:一位客户走进你的摄影工作室,想拍一套艺术写真。她描述了自己想要的风格——可能是复古港风、清新日系&a…...