SpringCloud入门
SpringCloud
原版笔记:狂神说笔记——SpringCloud快速入门23 - subeiLY - 博客园 (cnblogs.com)
一.前言



常见面试题
-
什么是微服务?
-
微服务之间是如何独立通讯的?
-
SpringCloud 和 Dubbo有哪些区别?
-
SpringBoot和SpringCloud,请你谈谈对他们的理解
-
什么是服务熔断?什么是服务降级
-
微服务的优缺点是分别是什么?说下你在项目开发中遇到的坑
-
你所知道的微服务技术栈有哪些?请列举一二
-
eureka和zookeeper都可以提供服务注册与发现的功能,请说说两个的区别?
二.SpringCloud入门
1.微服务技术栈有哪些?
| 微服务条目 | 落地技术 |
|---|---|
| 服务开发 | SpringBoot,Spring,SpringMVC |
| 服务配置与管理 | Netflix公司的Archaius、阿里的Diamond等 |
| 服务注册与发现 | Eureka、Consul、Zookeeper等 |
| 服务调用 | Rest、RPC、gRPC |
| 服务熔断器 | Hystrix、Envoy等 |
| 负载均衡 | Ribbon、Nginx等 |
| 服务接口调用(客户端调用服务的简化工具) | Feign等 |
| 消息队列 | Kafka、RabbitMQ、ActiveMQ等 |
| 服务配置中心管理 | SpringCloudConfig、Chef等 |
| 服务路由(API网关) | 服务监控 |
| 服务监控 | Zabbix、Nagios、Metrics、Specatator等 |
| 全链路追踪 | Zipkin、Brave、Dapper等 |
| 服务部署 | Docker、OpenStack、Kubernetes等 |
| 数据流操作开发包 | SpringCloud Stream(封装与Redis,Rabbit,Kafka等发 送接收消息) |
| 事件消息总线 | SpringCloud Bus |
2.SpringCloud和SpringBoot关系
- SpringBoot专注于快速方便的开发单个个体微服务。
- SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,为各个微服务之间提供:配置管理,服务发现,断路器,路由,微代理,事件总线,全局锁,决策竞选,分布式会话等等集成服务。
- SpringBoot可以离开SpringClooud独立使用,开发项目,但是SpringCloud离不开SpringBoot,属于依赖关系。
- SpringBoot专注于快速、方便的开发单个个体微服务,SpringCloud关注全局的服务治理框架。
3.自学参考:
- SpringCloud Netflix 中文文档:Spring Cloud Netflix 中文文档 参考手册 中文版
- SpringCloud 中文API文档(官方文档翻译版):Spring Cloud Dalston 中文文档 参考手册 中文版
- SpringCloud中国社区:http://docs.springcloud.cn/
- SpringCloud中文网:https://springcloud.cc
三.Rest微服务构建
1.SpringCloud版本选择
| SpringBoot | SpringCloud | 关系 |
|---|---|---|
| 1.2.x | Angel版本(天使) | 兼容SpringBoot1.2x |
| 1.3.x | Brixton版本(布里克斯顿) | 兼容SpringBoot1.3x,也兼容SpringBoot1.4x |
| 1.4.x | Camden版本(卡姆登) | 兼容SpringBoot1.4x,也兼容SpringBoot1.5x |
| 1.5.x | Dalston版本(多尔斯顿) | 兼容SpringBoot1.5x,不兼容SpringBoot2.0x |
| 1.5.x | Edgware版本(埃奇韦尔) | 兼容SpringBoot1.5x,不兼容SpringBoot2.0x |
| 2.0.x | Finchley版本(芬奇利) | 兼容SpringBoot2.0x,不兼容SpringBoot1.5x |
| 2.1.x | Greenwich版本(格林威治) |
- 实际开发版本关系
| spring-boot-starter-parent | spring-cloud-dependencles | ||
|---|---|---|---|
| 版本号 | 发布日期 | 版本号 | 发布日期 |
| 1.5.2.RELEASE | 2017-03 | Dalston.RC1 | 2017-x |
| 1.5.9.RELEASE | 2017-11 | Edgware.RELEASE | 2017-11 |
| 1.5.16.RELEASE | 2018-04 | Edgware.SR5 | 2018-10 |
| 1.5.20.RELEASE | 2018-09 | Edgware.SR5 | 2018-10 |
| 2.0.2.RELEASE | 2018-05 | Fomchiey.BULD-SNAPSHOT | 2018-x |
| 2.0.6.RELEASE | 2018-10 | Fomchiey-SR2 | 2018-10 |
| 2.1.4.RELEASE | 2019-04 | Greenwich.SR1 | 2019-03 |
2.项目搭建
父项目maven项目
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.base.cloud</groupId><artifactId>spingcloud</artifactId><packaging>pom</packaging><modules><module>springcloud-api</module><module>springcloud-provider-dept-8001</module></modules><version>1.0-SNAPSHOT</version><name>spingcloud Maven Webapp</name><url>http://maven.apache.org</url><dependencyManagement><dependencies><!--springCloud的依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>Hoxton.SR8</version><type>pom</type><scope>import</scope></dependency><!--springboot的依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>2.3.3.RELEASE</version><type>pom</type><scope>import</scope></dependency><!--数据库--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.10</version></dependency><!--SpringBoot 启动器--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>1.3.2</version></dependency><!--日志测试~--><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-core</artifactId><version>1.2.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><!--lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version><scope>provided</scope></dependency></dependencies></dependencyManagement><build><finalName>spingcloud</finalName></build>
</project>
创建api公共模块 springcloud-api
创建部门数据库脚本
create database db01;use db01;CREATE TABLE dept ( deptno BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT, dname VARCHAR ( 60 ), db_source VARCHAR ( 60 ) );mysql> insert into dept values(1,'a','db01');mysql> insert into dept values(2,'b','db01');mysql> insert into dept values(3,'c','db01');mysql> insert into dept values(4,'d','db01');mysql> select * from dept;
+--------+-------+-----------+
| deptno | dname | db_source |
+--------+-------+-----------+
| 1 | a | db01 |
| 2 | b | db01 |
| 3 | c | db01 |
| 4 | d | db01 |
+--------+-------+-----------+
4 rows in set (0.00 sec)<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>com.base.cloud</groupId><artifactId>spingcloud</artifactId><version>1.0-SNAPSHOT</version></parent><artifactId>springcloud-api</artifactId><packaging>war</packaging><name>springcloud-api Maven Webapp</name><url>http://maven.apache.org</url><dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies><build><finalName>springcloud-api</finalName></build>
</project>
编写实体类,注意:实体类都序列化
package com.base.pojo;import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;import java.io.Serializable;@Data
@NoArgsConstructor
@Accessors(chain = true) // 链式写法
public class Dept implements Serializable {// Dept(实体类) orm mysql->Dept(表) 类表关系映射private Long deptno; // 主键private String dname; // 部门名称// 来自哪个数据库,因为微服务架构可以一个服务对应一个数据库,同一个信息被存到多个不同的数据库private String db_source;public Dept(String dname) {this.dname = dname;}
}
创建provider模块 springcloud-provider-dept-8001
编辑pom.xml
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-core</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jetty</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-test</artifactId></dependency><!-- spring-boot-devtools热部署 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId></dependency><dependency><groupId>com.base.cloud</groupId><artifactId>springcloud-api</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency></dependencies>编辑 application.yml
server:port: 8001
# mybatis的配置
mybatis:
# config-location: classpath:mybatis/mybatis-config.xmltype-aliases-package: com.base.cloud.pojomapper-locations: classpath:mybatis/mapper/*.xml# spring的相关配置
spring:application:name: springcloud-provider-deptdatasource:type: com.alibaba.druid.pool.DruidDataSource # 数据源driver-class-name: com.mysql.jdbc.Driver # mysql驱动url: jdbc:mysql://localhost:3306/db01?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8 #数据库名称username: rootpassword: 123456dbcp2:min-idle: 5 #数据库连接池的最小维持连接数initial-size: 5 #初始化连接数max-total: 5 #最大连接数max-wait-millis: 200 #等待连接获取的最大超时时间根据配置新建mybatis-config.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><settings><!--开启二级缓存--><setting name="cacheEnabled" value="true"/></settings></configuration>
编写部门的dao接口
@Mapper
@Repository
public interface DeptDao {public boolean addDept(Dept dept); // 添加一个部门public Dept queryById(Long id); // 根据id查询部门public List<Dept> queryAll(); // 查询所有部门
}
接口对应的DeptMapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.base.cloud.dao.DeptDao"><insert id="addDept" parameterType="Dept">insert into dept (dname,db_source) values (#{dname},DATABASE());</insert><select id="queryById" resultType="Dept" parameterType="Long">select deptno,dname,db_source from dept where deptno = #{deptno};</select><select id="queryAll" resultType="Dept">select deptno,dname,db_source from dept;</select>
</mapper>
创建Service服务层接口
public interface DeptService {public boolean addDept(Dept dept); // 添加一个部门public Dept queryById(Long id); // 根据id查询部门public List<Dept> queryAll(); // 查询所有部门
}
ServiceImpl实现类
@Service
public class DeptServiceImpl implements DeptService {// 自动注入@Autowiredprivate DeptDao deptDao;@Overridepublic boolean addDept(Dept dept) {return deptDao.addDept(dept);}@Overridepublic Dept queryById(Long id) {return deptDao.queryById(id);}@Overridepublic List<Dept> queryAll() {return deptDao.queryAll();}
}
Controller
@RestController
public class DeptController {@Autowiredprivate DeptService service;// @RequestBody// 如果参数是放在请求体中,传入后台的话,那么后台要用@RequestBody才能接收到@PostMapping("/add")public boolean addDept(Dept dept) {return service.addDept(dept);}@GetMapping("/get/{id}")public Dept get(@PathVariable("id") Long id) {return service.queryById(id);}@GetMapping("/list")public List<Dept> queryAll() {return service.queryAll();}
}编写DeptProvider的主启动类
@SpringBootApplication
public class DeptProvider8001 {public static void main(String[] args) {SpringApplication.run(DeptProvider8001.class,args);}
}启动测试,注意编写细节:

空指针异常:
1.解决方法一:在pom.xml文件中加入
<build><!--扫描到java和resources下的xml等资源文件--><resources><resource><directory>src/main/java</directory><!-- include说明:打包时只保留include标签下的文件exclude说明: exclude规定路径下的文件不被打包 --><includes><include>**/*.xml</include><include>**/*.tld</include></includes><!--不启用过滤--><filtering>false</filtering></resource><resource><directory>src/main/resources</directory><includes><include>**/*.xml</include><include>**/*.yaml</include><include>**/*.properties</include></includes><!--不启用过滤--><filtering>false</filtering></resource></resources></build> 

启动成功
创建consumer模块springcloud-consumer-dept-80
<dependencies><dependency><groupId>com.base.cloud</groupId><artifactId>springcloud-api</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency></dependencies>application.yml配置文件
server:port: 80
新建一个ConfigBean包注入 RestTemplate!
@Configuration
public class ConfigBean {@Beanpublic RestTemplate getRestTemplate(){return new RestTemplate();}
}
创建Controller包,编写DeptConsumerController类
解RestTemplate:
- RestTemplate提供了多种便捷访问远程Http服务的方法,是一种简单便捷的访问restful服务模板类,是Spring提供的用于访问Rest服务的客户端模板工具集。
- 使用RestTemplate访问restful接口非常的简单粗暴且无脑 (url,requsetMap,ResponseBean.class)这三个参数分别代表REST请求地址,请求参数,Http响应转换被转换成的对象类型。
@RestController
public class DeptConsumerController {// 理解:消费者,不应该有service层// 使用RestTemplate访问restful接口非常的简单粗暴且无脑// (url,requestMap,ResponseBean.class) 这三个参数分别代表// REST请求地址,请求参数,Http响应转换被转换成的对象类型@Autowiredprivate RestTemplate restTemplate;private static final String REST_URL_PREFIX = "http://localhost:8001";@PostMapping("/consumer/add")public boolean addDept(Dept dept) {return restTemplate.postForObject(REST_URL_PREFIX+"/add",dept,Boolean.class);}@GetMapping("/consumer/get/{id}")public Dept get(@PathVariable("id") Long id) {return restTemplate.getForObject(REST_URL_PREFIX+"/get/"+id,Dept.class);}@GetMapping("/consumer/list")public List<Dept> queryAll() {return restTemplate.getForObject(REST_URL_PREFIX+"/list",List.class);}
}
主启动类
@SpringBootApplication
public class DeptConsumer80 {public static void main(String[] args) {SpringApplication.run(DeptConsumer80.class,args);}
}- 测试访问,
先启动服务方:DeptProvider8001,再启动消费方:DeptConsumer80:

四.Eureka服务注册与发现
1.什么是Eureka
- Eureka(服务发现框架)
- Netflix 在设计Eureka时,遵循的就是API原则!
- CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
- Eureka是Netflix的一个子模块,也是核心模块之一。Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故障转移,服务注册与发现对于微服务来说是非常重要的,有了服务发现 与注册,只需要使用服务的标识符,就可以访问到服务,而不需要修改服务调用的配置文件了,功能类 似于Dubbo的注册中心,比如Zookeeper。
2.Eureka的基本架构
- Springcloud 封装了Netflix公司开发的Eureka模块来实现服务注册与发现 (对比Zookeeper)。
- SpringCloud将它集成在其子项目spring-cloud-netflix中,以实现SpringCloud的服务发现功能。
- Eureka采用了C-S的架构设计,EurekaServer作为服务注册功能的服务器,他是服务注册中心。
- 而系统中的其他微服务,使用Eureka的客户端连接到EurekaServer并维持心跳连接。这样系统的维护人员就可以通过EurekaServer来监控系统中各个微服务是否正常运行,Springcloud 的一些其他模块 (比如Zuul) 就可以通过EurekaServer来发现系统中的其他微服务,并执行相关的逻辑。

和Dubbo架构对比:
- Eureka包含两个组件:Eureka Server和Eureka Client。
- Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
- Eureka Client是一个java客户端,用于简化与Eureka Server的交互,客户端同时也就是一个内置的、使用轮询(round-robin)负载算法的负载均衡器。
- 在应用启动后,将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)
3.三大角色
- Eureka Server:提供服务的注册与发现。
- Service Provider:将自身服务注册到Eureka中,从而使消费方能够找到。
- Service Consumer:服务消费方从Eureka中获取注册服务列表,从而找到消费服务。
4.服务构建
建立springcloud-eureka-7001模块
编辑pom.xml
<dependencies><!-- eureka-server服务端 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka-server</artifactId><version>1.4.6.RELEASE</version></dependency></dependencies>application.yaml
server:port: 7001# Eureka配置
eureka:instance:hostname: localhost #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url: defaultzone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultzone地址
编写主启动类
@SpringBootApplication
@EnableEurekaServer // EurekaServer服务端启动类,接受其他微服务注册进来
public class EurekaServer7001 {public static void main(String[] args){SpringApplication.run(EurekaServer7001.class,args);}
}

- System Status:系统信息;
- DS Replicas:服务器副本;
- Instances currently registered with Eureka:已注册的微服务列表;
- General Info:一般信息;
- Instance Info:实例信息
5.Service Provider
将 8001 的服务入驻到 7001 的eureka中!
修改8001服务的pom文件,增加eureka的支持!
<!--将服务的provider注册到eureka中--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId><version>1.4.6.RELEASE</version></dependency>yaml 中配置 eureka 的支持
# Eureka配置:配置服务注册中心地址
eureka:client:service-url:defaultZone: http://localhost:7001/eureka/
8001 的主启动类注解支持
@SpringBootApplication
@EnableEurekaClient // 本服务启动之后会自动注册进Eureka中!
public class DeptProvider8001 {public static void main(String[] args) {SpringApplication.run(DeptProvider8001.class,args);}
}
截止目前:服务端也有了,客户端也有了,启动7001,再启动8001,测试访问:
actuator与注册微服务信息完善
主机名称:服务名称修改
在8001的yaml中修改一下配置。
# Eureka配置:配置服务注册中心地址
eureka:client:service-url:defaultZone: http://localhost:7001/eureka/instance:instance-id: springcloud-provider-dept8001 # 与client平级prefer-ip-address: true # true表示访问路径可以显示IP地址

现在点击info,出现ERROR页面:
修改8001的pom文件,新增依赖!
<!--actuator监控信息完善-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
然后回到8001的yaml配置文件中修改增加信息:
# info配置
info:app.name: s-springcloud # 项目的名称company.name: www.subeily.top # 公司的名称
重启项目测试:7001、8001
这里没出来的可以将spring boot版本降级即可!
如果还没出来,可以添加如下配置:
management:endpoints:web:exposure:include: "*"
Eureka的自我保护机制:好死不如赖活着
之前出现的这些红色情况,没出现的,修改一个服务名,故意制造错误!
-
一句话总结就是:某时刻某一个微服务不可用,eureka不会立即清理,依旧会对该微服务的信息进行保存!
-
默认情况下,当eureka server在一定时间内没有收到实例的心跳,便会把该实例从注册表中删除(默认是90秒),但是,如果短时间内丢失大量的实例心跳,便会触发eureka server的自我保护机制,比如在开发测试时,需要频繁地重启微服务实例,但是我们很少会把eureka server一起重启(因为在开发过程中不会修改eureka注册中心),当一分钟内收到的心跳数大量减少时,会触发该保护机制。可以在eureka管理界面看到Renews threshold和Renews(last min),当后者(最后一分钟收到的心跳数)小于前者(心跳阈值)的时候,触发保护机制,会出现红色的警告:
EMERGENCY!EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT.RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEGING EXPIRED JUST TO BE SAFE. -
从警告中可以看到,eureka认为虽然收不到实例的心跳,但它认为实例还是健康的,eureka会保护这些实例,不会把它们从注册表中删掉。
-
该保护机制的目的是避免网络连接故障,在发生网络故障时,微服务和注册中心之间无法正常通信,但服务本身是健康的,不应该注销该服务,如果eureka因网络故障而把微服务误删了,那即使网络恢复了,该微服务也不会重新注册到eureka server了,因为只有在微服务启动的时候才会发起注册请求,后面只会发送心跳和服务列表请求,这样的话,该实例虽然是运行着,但永远不会被其它服务所感知。所以,eureka server在短时间内丢失过多的客户端心跳时,会进入自我保护模式,该模式下,eureka会保护注册表中的信息,不在注销任何微服务,当网络故障恢复后,eureka会自动退出保护模式。自我保护模式可以让集群更加健壮。
-
但是我们在开发测试阶段,需要频繁地重启发布,如果触发了保护机制,则旧的服务实例没有被删除,这时请求有可能跑到旧的实例中,而该实例已经关闭了,这就导致请求错误,影响开发测试。
-
所以,在开发测试阶段,可以把自我保护模式关闭,只需在eureka server配置文件中加上如下配置即可:
eureka.server.enable-self-preservation=false【不推荐关闭自我保护机制】 -
详细可以参考:博客
8001服务发现Discovery
对于注册进eureka里面的微服务,可以通过服务发现来获得该服务的信息。【对外暴露服务】
修改springcloud-provider-dept-8001工程中的DeptController,并新增一个方法。
@RestController
@EnableEurekaClient
public class DeptController {@Autowiredprivate DeptService service;@Autowiredprivate DiscoveryClient client; // @RequestBody// 如果参数是放在请求体中,传入后台的话,那么后台要用@RequestBody才能接收到@PostMapping("/add")public boolean addDept(Dept dept) {return service.addDept(dept);}@GetMapping("/get/{id}")public Dept get(@PathVariable("id") Long id) {return service.queryById(id);}@GetMapping("/list")public List<Dept> queryAll() {return service.queryAll();}@GetMapping("/discovery")public Object discovery() {// 获取微服务列表的清单List<String> services = client.getServices();System.out.println("discovery=>services:" + services);// 得到一个具体的微服务信息,通过具体的微服务id,applicaioinName;List<ServiceInstance> instances = client.getInstances("SPRINGCLOUD-PROVIDER-DEPT");for (ServiceInstance instance : instances) {System.out.println(instance.getHost() + "\t" + // 主机名称instance.getPort() + "\t" + // 端口号instance.getUri() + "\t" + // uriinstance.getServiceId() // 服务id);}return this.client;
}主启动类增加一个注解:
@SpringBootApplication
@EnableEurekaClient
@EnableDiscoveryClient
public class DeptProvider8001 {public static void main(String[] args) {SpringApplication.run(DeptProvider8001.class,args);}
}启动Eureka服务,启动8001提供者,访问测试 http://localhost:8001/discovery

后台输出:
6.consumer访问服务
进入springcloud-consumer-dept-80,修改DeptConsumerController增加一个方法
@GetMapping("/consumer/dept/discovery")
public Object discovery(){return restTemplate.getForObject(REST_URL_PREFIX+"/dept/discovery",Object.class);
}
启动 80 项目进行测试!先启动8001服务,再启动80
7.Eureka:集群环境配置
集群配置分析
新建工程springcloud-eureka-7002、springcloud-eureka-7003;
<dependencies><!-- eureka-server服务端 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka-server</artifactId><version>1.4.6.RELEASE</version></dependency><!--热部署--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId></dependency>
</dependencies>
server:port: 7003# Eureka配置
eureka:instance:hostname: localhost #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url:defaultzone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultzone地址
@SpringBootApplication
@EnableEurekaServer // EurekaServer服务端启动类,接受其他微服务注册进来
public class EurekaServer7003 {public static void main(String[] args){SpringApplication.run(EurekaServer7003.class,args);}
}
集群成员相互关联,修改映射配置 , windows域名映射。
配置一些自定义本机名字,找到本机hosts文件并打开:
在hosts文件最后加上,要访问的本机名称,默认是localhost
修改application.yml的配置,如图为springcloud-eureka-7001配置,springcloud-eureka-7002/springcloud-eureka-7003同样分别修改为其对应的名称即可。
在集群中使springcloud-eureka-7001关联springcloud-eureka-7002、springcloud-eureka-7003
server:port: 7001# Eureka配置
eureka:instance:hostname: eureka7001.com #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url:# 单机 defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultZone地址defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
server:port: 7002# Eureka配置
eureka:instance:hostname: eureka7002.com #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url:# 单机 defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultZone地址defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7003.com:7003/eureka/
server:port: 7003# Eureka配置
eureka:instance:hostname: eureka7003.com #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url:# 单机 defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultZone地址defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/
将8001微服务发布到1台eureka集群配置中,发现在集群中的其余注册中心也可以看到,但是平时我们保险起见,都发布!即通过springcloud-provider-dept-8001下的yml配置文件,修改Eureka配置:配置服务注册中心地址
# Eureka配置:配置服务注册中心地址
eureka:client:service-url:# 注册中心地址7001-7003defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/instance:instance-id: springcloud-provider-dept-8001 # 与client平级# prefer-ip-address: true # true表示访问路径可以显示IP地址
启动集群测试!7001、7002、7003、8001都要启动哦 
8.对比Zookeeper
回顾CAP原则
-
RDBMS (MySQL、Oracle、sqlServer) ===> ACID
-
NoSQL (Redis、MongoDB) ===> CAP
ACID是什么?
- A (Atomicity) 原子性
- C (Consistency) 一致性
- I (Isolation) 隔离性
- D (Durability) 持久性
ACID是数据库事务处理中的四个重要属性,分别是:原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成,不会结束在中间某个点。这保证了数据库状态的一致性。一致性(Consistency):事务必须保证数据库从一个一致的状态转移到另一个一致的状态。一致性通常意味着数据库的完整性约束在事务执行前后都保持有效。隔离性(Isolation):并发执行的事务之间不会互相影响。每个事务都像是在独立运行,其修改在最终提交前对其他事务是不可见的。持久性(Durability):一旦事务提交,则其所做的修改将永久保存在数据库中,即使系统发生故障也不会丢失。例子:假设你在一个在线商店进行购物,你选择了一些商品并进行结账。这个结账过程可以被视为一个事务,它具有以下ACID属性:原子性:当你点击结账后,系统会尝试更新库存、扣款、记录交易等。如果其中任何一个步骤失败(比如库存不足),整个结账过程会回滚,就像你从未尝试过结账一样。一致性:系统确保结账前后,数据库的状态是一致的。例如,你的账户余额和商品的库存数量在结账前后都是正确的。隔离性:当你在结账时,其他用户可能也在结账,但他们的交易不会影响你的。即使两个用户同时购买最后一件商品,系统也会确保他们不会互相干扰。持久性:一旦你成功结账,这笔交易就会被永久记录在数据库中,即使系统突然崩溃,你的交易记录也不会丢失。CAP是什么?
- C (Consistency) 强一致性
- A (Availability) 可用性
- P (Partition tolerance) 分区容错性
- CAP的三进二:CA、AP、CP
- CAP理论的核心
CAP定理是分布式系统设计中的一个基本理论,它指出在一个分布式系统中,以下三个关键要素不可能同时得到满足:一致性(Consistency):在分布式系统中,当数据更新后,所有节点在同一时间看到的数据应该是一致的,即所有节点看到的数据都是最新的。可用性(Availability):系统提供的服务必须处于100%可用的状态,对于用户的每一个操作请求,系统总能够在有限的时间内返回结果。分区容错性(Partition tolerance):由于分布式系统通过网络进行通信,网络是不可靠的,系统在出现网络分区(即部分节点之间失去连接)的情况下,仍然需要继续对外提供服务。根据CAP定理,一个分布式系统最多只能同时满足其中的两个要素。例如:CP系统:选择一致性和分区容错性,牺牲可用性。例如,ZooKeeper在进行Leader选举时,可能无法对外提供服务,但保证了数据的一致性。AP系统:选择可用性和分区容错性,牺牲一致性。例如,Eureka在设计时优先保证可用性,即使部分节点挂掉,服务仍然可用,但数据可能不是最新的。CA系统:在没有网络分区的情况下,可以选择一致性和可用性,但一旦发生网络分区,就必须在两者之间做出选择。一个简单的例子是在线购物平台的库存系统。如果系统设计为CP(一致性和分区容错性),当一个用户购买商品后,系统需要确保所有节点的库存数据都更新为最新的数量,即使这可能导致在数据同步期间服务不可用。而如果系统设计为AP(可用性和分区容错性),则在用户购买商品时,系统可能会立即响应,但库存数据可能不是最新的,因为网络分区导致数据同步延迟- 一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求;
- 根据CAP原理,将NoSQL数据库分成了满足CA原则,满足CP原则和满足AP原则三大类;
- CA:单点集群,满足一致性,可用性的系统,通常可扩展性较差;
- CP:满足一致性,分区容错的系统,通常性能不是特别高;
- AP:满足可用性,分区容错的系统,通常可能对一致性要求低一些;
作为服务注册中心,Eureka比Zookeeper好在哪里?
-
著名的CAP理论指出,一个分布式系统不可能同时满足C (一致性) 、A (可用性) 、P (容错性),由于分区容错性P再分布式系统中是必须要保证的,因此我们只能再A和C之间进行权衡。
- Zookeeper 保证的是 CP —> 满足一致性,分区容错的系统,通常性能不是特别高;
- Eureka 保证的是 AP —> 满足可用性,分区容错的系统,通常可能对一致性要求低一些;
-
Zookeeper保证的是CP- 当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接收服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但zookeeper会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30-120s,且选举期间整个zookeeper集群是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zookeeper集群失去master节点是较大概率发生的事件,虽然服务最终能够恢复,但是,漫长的选举时间导致注册长期不可用,是不可容忍的。
-
Eureka保证的是AP- Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保住注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有之中自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不在从注册列表中移除因为长时间没收到心跳而应该过期的服务;
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上 (即保证当前节点依然可用);
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中。
- Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保住注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有之中自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
-
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
五.Ribbon:负载均衡(基于客户端)
1.Ribbon是什么?
-
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
-
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将NetFlix的中间层服务连接在一起。Ribbon的客户端组件提供一系列完整的配置项如:连接超时、重试等等。简单的说,就是在配置文件中列出LoadBalancer(简称LB:负载均衡)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法!
2.Ribbon能干嘛?

- LB,即负载均衡 (LoadBalancer) ,在微服务或分布式集群中经常用的一种应用。
- 负载均衡简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA (高用)。
- 常见的负载均衡软件有 Nginx、Lvs等等。
- Dubbo、SpringCloud 中均给我们提供了负载均衡,SpringCloud 的负载均衡算法可以自定义。
- 负载均衡简单分类:
- 集中式LB
- 即在服务的提供方和消费方之间使用独立的LB设施,如Nginx(反向代理服务器),由该设施负责把访问请求通过某种策略转发至服务的提供方!
- 进程式 LB
- 将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选出一个合适的服务器。
Ribbon 就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址!
- 集中式LB
- Ribbon的github地址:GitHub - Netflix/ribbon: Ribbon is a Inter Process Communication (remote procedure calls) library with built in software load balancers. The primary usage model involves REST calls with various serialization scheme support.
3.集成Ribbon
springcloud-consumer-dept-80向pom.xml中添加Ribbon和Eureka依赖
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-ribbon -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-ribbon</artifactId><version>1.4.7.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId><version>1.4.7.RELEASE</version>
</dependency>
在application.yml文件中配置Eureka
server:port: 80# Eureka配置
eureka:client:register-with-eureka: false # false表示不向注册中心注册自己service-url:defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
主启动类加上@EnableEurekaClient注解,开启Eureka
// Ribbon 和 Eureka 整合以后,客户端可以直接调用,不用关心IP地址和端口号
@SpringBootApplication
@EnableEurekaClient // 开启Eureka 客户端
public class DeptConsumer80 {public static void main(String[] args) {SpringApplication.run(DeptConsumer80.class,args);}
}
自定义Spring配置类:ConfigBean.java 配置负载均衡实现RestTemplate
@Bean
@LoadBalanced // Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具
public RestTemplate getRestTemplate(){return new RestTemplate();
}
修改conroller:DeptConsumerController.java

/*** 服务提供方地址前缀* <p>* Ribbon:我们这里的地址,应该是一个变量,通过服务名来访问*/
// private static final String REST_URL_PREFIX = "http://localhost:8001";
private static final String REST_URL_PREFIX = "http://SPRINGCLOUD-PROVIDER-DEPT";
在这里插入图片描述
- 先启动3个Eureka集群后,再启动springcloud-provider-dept-8001并注册进eureka;
- 启动 DeptConsumerRibbon80;

- Ribbon和Eureka整合后Consumer可以直接调用服务而不用再关心地址和端口号!
4.Ribbon负载均衡
架构说明:
-
Ribbon在工作时分成两步:
- 第一步先选择EurekaServer,它优先选择在同一个区域内负载均衡较少的Server。
- 第二步在根据用户指定的策略,在从server去到的服务注册列表中选择一个地址。
- 其中Ribbon提供了多种策略,比如轮询(默认),随机和根据响应时间加权重,,,等等
-
测试:
- 参考springcloud-provider-dept-8001,新建两份,分别为8002,8003!
- 参照springcloud-provider-dept-8001,依次为另外两个Moudle添加pom.xml依赖 、resourece下的mybatis和application.yml配置,Java代码;
- 全部复制完毕,修改启动类名称,修改端口号名称!

- 修改8002/8003各自的YML文件
- 端口
- 数据库连接
- 实例名也需要修改
instance:instance-id: springcloud-provider-dept-8003 # 与client平级
- 对外暴露的统一的服务实例名【三个服务名字必须一致!】
application:name: springcloud-provider-dept
新建8002/8003数据库,各自微服务分别连接各自的数据库
- 启动3个Eureka集群配置区
-
启动3个Dept微服务并都测试通过
- http://localhost:8001//list
- http://localhost:8002//list
- http://localhost:8003//list


-
启动springcloud-consumer-dept-80
-
客户端通过Ribbon完成负载均衡并访问上一步的Dept微服务
- http://localhost/consumer/list
- 多刷新几次注意观察结果

-
总结:
- Ribbon其实就是一个软负载均衡的客户端组件,他可以和其他所需请求的客户端结合使用,和Eureka结合只是其中的一个实例。
5.自定义负载均衡算法
官方文档明确给出了警告:
这个自定义配置类不能放在@ComponentScan所扫描的当前包以及子包下,否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,也就是说达不到特殊化定制的目的了!
由于有以上配置细节原因,我们建立一个包:com.base.myrul,在这里新建一个自定义规则的Rubbion类。
@Configuration
public class MySelfRule {/*** IRule:* RoundRobinRule 轮询策略* RandomRule 随机策略* AvailabilityFilteringRule : 会先过滤掉,跳闸,访问故障的服务~,对剩下的进行轮询~* RetryRule : 会先按照轮询获取服务~,如果服务获取失败,则会在指定的时间内进行,重试*/@Beanpublic IRule myRule() {return new RandomRule();//使用随机策略// return new RoundRobinRule();//使用轮询策略// return new AvailabilityFilteringRule();//使用轮询策略// return new RetryRule();//使用轮询策略}
}
Ribbon核心组件IRule
- 修改springcloud-consumer-dept-ribbon-80
- 主启动类添加@RibbonClient注解;
- 在启动该微服务的时候就能去加载我们自定义的Ribbon配置类,从而使配置类生效,例如:
@RibbonClient(name="SPRINGCLOUD-PROVIDER-DEPT",configuration=MySelfRule.class)
启动所有项目,访问测试,查看编写的随机算法,现在是否生效!
问题:依旧轮询策略,但是加上新需求,每个服务器要求被调用5次,就是以前每一个机器一次,现在每个机器5次;
解析源码:RandomRule.java , IDEA直接点击进去,复制出来,变成我们自己的类 MyRondomRule
public class MyRondomRule extends AbstractLoadBalancerRule {public MyRondomRule() {}// total = 0 当total数等于5以后,我们指针才能往下走// index = 0 当前对外提供服务的服务器地址// 如果total等于5,则index+1,将total重置为0即可!// 问题:我们只有3台机器,所有total>3 则将total置为0;private int total = 0; //总共被调用的次数private int currentIndex = 0; //当前提供服务的机器序号!// ILoadBalancer选择的随机算法public Server choose(ILoadBalancer lb, Object key) {if (lb == null) {return null;} else {Server server = null;while(server == null) {// 查看线程是否中断了if (Thread.interrupted()) {return null;}// Reachable: 可及;可到达;够得到List<Server> upList = lb.getReachableServers(); // 活着的服务List<Server> allList = lb.getAllServers(); // 获取所有的服务int serverCount = allList.size();if (serverCount == 0) {return null;}// 生成区间随机数!
// int index = this.chooseRandomInt(serverCount);// 从活着的服务中,随机取出一个
// server = (Server)upList.get(index);// =====================================if (total<5){server = upList.get(currentIndex);total++;}else {total = 0;currentIndex++;if (currentIndex>=upList.size()){currentIndex = 0;}server = upList.get(currentIndex);}// =====================================if (server == null) {Thread.yield();} else {if (server.isAlive()) {return server;}server = null;Thread.yield();}}return server;}}// 随机protected int chooseRandomInt(int serverCount) {return ThreadLocalRandom.current().nextInt(serverCount);}@Overridepublic Server choose(Object key) {return this.choose(this.getLoadBalancer(), key);}@Overridepublic void initWithNiwsConfig(IClientConfig clientConfig) {}
}注册
public class MySelfRule {@Beanpublic IRule myRule() {return new MyRondomRule(); }
} 测试实现,会连续五次之后才会切换轮询http://localhost/consumer/list
六.Feign:负载均衡(基于服务端)
1.简介
-
Feign是声明式Web Service客户端,它让微服务之间的调用变得更简单,类似controller调用service。SpringCloud集成了Ribbon和Eureka,可以使用Feigin提供负载均衡的http客户端。
-
只需要创建一个接口,然后添加注解即可!
Feign,主要是社区版,大家都习惯面向接口编程。这个是很多开发人员的规范。调用微服务访问两种方法:
- 微服务名字 【ribbon】
- 接口和注解 【feign】
2.Feign能干什么
- Feign旨在使编写Java Http客户端变得更容易
- 前面在使用Ribbon + RestTemplate时,利用RestTemplate对Http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一个客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步的封装,由他来帮助我们定义和实现依赖服务接口的定义,在Feign的实现下,我们只需要创建一个接口并使用注解的方式来配置它 (类似以前Dao接口上标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解),即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon 时,自动封装服务调用客户端的开发量。
Feign默认集成了Ribbon
- 利用Ribbon维护了MicroServiceCloud-Dept的服务列表信息,并且通过轮询实现了客户端的负载均衡,而与Ribbon不同的是,通过Feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。
3.Feign的使用步骤
参考springcloud-consumer-dept-ribbon-80
新建springcloud-consumer-dept-feign-80
- 修改主启动类名称;
- 将springcloud-consumer-dept-80的内容都拷贝到feign项目中;
- 删除myrule文件夹;
- 修改主启动类的名称为 FeignDeptConsumer80;

springcloud-consumer-dept-feign-80修改pom.xml,添加对Feign的支持。
<!--Feign的依赖-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-feign</artifactId><version>1.4.6.RELEASE</version>
</dependency>
修改springcloud-api工程
- pom.xml添加feign的支持
- 新建一个Service包
编写接口 DeptClientService,并增加新的注解@FeignClient。
@Service
@FeignClient(value = "SPRINGCLOUD-PROVIDER-DEPT")
public interface DeptClientService {@GetMapping("/get/{id}")public Dept queryById(@PathVariable("id") Long id); //根据id查询部门@GetMapping("/list")public List<Dept> queryAll(); //查询所有部门@PostMapping(value = "/add")public boolean addDept(Dept dept); //添加一个部门}
springcloud-consumer-dept-feign-80工程修改Controller,添加上一步新建的DeptClientService。
@RestController
public class DeptConsumerController {@Autowiredprivate DeptClientService service;@PostMapping("/consumer/add")public boolean addDept(Dept dept) {return service.addDept(dept);}@GetMapping("/consumer/get/{id}")public Dept get(@PathVariable("id") Long id) {return service.queryById(id);}@GetMapping("/consumer/list")public List<Dept> queryAll() {return service.queryAll();}
}
microservicecloud-consumer-dept-feign工程修改主启动类,开启Feign使用!
@SpringBootApplication
@EnableEurekaClient
// feign客户端注解,并指定要扫描的包以及配置接口DeptClientService
@EnableFeignClients(basePackages = {"com.base.cloud.service"})
public class FeignDeptConsumer80 {public static void main(String[] args) {SpringApplication.run(FeignDeptConsumer80.class,args);}
}
测试!
- 启动eureka集群;
- 启动8001,8002,8003
- 启动feign客户端
- 测试: http://localhost/consumer/list

七.Hystrix
1.分布式系统面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败!

服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的 “扇出”、如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。

- 对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几十秒内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示需要对故障和延迟进行隔离和管理,以达到单个依赖关系的失败而不影响整个应用程序或系统运行。
- 此时,我们需要弃车保帅!
2.Hystrix
1.什么是Hystrix

-
Hystrix是一个应用于处理分布式系统的延迟和容错的开源库,在分布式环境中,许多服务依赖项中的一些不可避免地会失败。Hystrix 是一个库,它通过添加延迟容错和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix 通过隔离服务之间的访问点、停止它们之间的级联故障并提供回退选项来做到这一点,所有这些都可以提高系统的整体弹性。
-
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控 (类似熔断保险丝) ,向调用方返回一个服务预期的,可处理的备选响应 (FallBack) ,而不是长时间的等待或者抛出调用方法无法处理的异常,这样就可以保证了服务调用方的线程不会被长时间,不必要的占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。

2.Hystrix的历史
Hystrix 源于 Netflix API 团队于 2011 年开始的弹性工程工作。2012 年,Hystrix 不断发展和成熟,Netflix 内部的许多团队都采用了它。如今,Netflix 每天通过 Hystrix 执行数百亿个线程隔离和数千亿个信号量隔离调用。这极大地提高了正常运行时间和恢复能力。
3.Hystrix 有什么用?
Hystrix 旨在执行以下操作:
- 通过第三方客户端库访问(通常通过网络)依赖关系,保护和控制延迟和故障。
- 停止复杂分布式系统中的级联故障。
- 快速失败并迅速恢复。
- 尽可能回退并优雅降级。
- 实现近乎实时的监控、警报和操作控制。
4.Hystrix 解决了什么问题?
-
复杂分布式架构中的应用程序有几十个依赖项,每个依赖项都不可避免地会在某个时候失败。如果主机应用程序没有与这些外部故障隔离开来,它就有被它们一起关闭的风险。
-
例如,对于依赖于 30 个服务且每个服务的正常运行时间为 99.99% 的应用程序,您可以期待以下内容:
99.99 30 = 99.7% 的正常运行时间
10 亿次请求的 0.3% = 3,000,000 次故障 2
小时以上的停机时间/月,即使所有依赖项都具有出色的正常运行时间。
-
现实通常更糟。
-
即使所有依赖项都表现良好,如果您不对整个系统进行弹性设计,即使对数十项服务中的每项服务造成 0.01% 的停机时间的总影响也相当于可能每月停机数小时。
- 当一切正常时,请求流程可能如下所示:

- 当许多后端系统之一变得潜在时,它可以阻止整个用户请求:

-
在大流量的情况下,单个后端依赖变得潜在可能会导致所有服务器上的所有资源在几秒钟内变得饱和。
-
应用程序中通过网络或客户端库中可能导致网络请求的每个点都是潜在故障的根源。比故障更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,这会备份队列、线程和其他系统资源,从而导致整个系统出现更多的级联故障。

-
当通过第三方客户端执行网络访问时,这些问题会更加严重——一个“黑匣子”,其中实现细节被隐藏并且可以随时更改,并且每个客户端库的网络或资源配置都不同,并且通常难以监控和改变。
-
更糟糕的是传递依赖,它执行潜在的昂贵或容易出错的网络调用,而没有被应用程序显式调用。
-
网络连接失败或降级。服务和服务器出现故障或变慢。新的库或服务部署会改变行为或性能特征。客户端库有错误。
-
所有这些都代表了需要隔离和管理的故障和延迟,以便单个故障依赖项无法关闭整个应用程序或系统。
5.Hystrix 的设计原则是什么?
Hystrix 通过以下方式工作:
- 防止任何单个依赖项用完所有容器(例如 Tomcat)用户线程。
- 减轻负载并快速失败,而不是排队。
- 在可行的情况下提供回退,以保护用户免于失败。
- 使用隔离技术(例如隔板、泳道和断路器模式)来限制任何一种依赖项的影响。
- 通过近乎实时的指标、监控和警报优化发现时间
- 通过配置更改的低延迟传播和对 Hystrix 大部分方面的动态属性更改的支持来优化恢复时间,这允许您使用低延迟反馈循环进行实时操作修改。
- 防止整个依赖客户端执行中的故障,而不仅仅是网络流量中的故障。
6.Hystrix 如何实现其目标?
- Hystrix 通过以下方式做到这一点:
- 将所有对外部系统(或“依赖项”)的调用包装在一个
HystrixCommand或HystrixObservableCommand对象中,该对象通常在单独的线程中执行(这是命令模式的一个示例)。 - 超时调用时间超过您定义的阈值。有一个默认值,但是对于大多数依赖项,您可以通过“属性”自定义设置这些超时,以便它们略高于每个依赖项测量的 99.5 %性能。
- 为每个依赖项维护一个小型线程池(或信号量);如果它已满,发往该依赖项的请求将立即被拒绝而不是排队。
- 测量成功、失败(客户端抛出的异常)、超时和线程拒绝。
- 如果服务的错误百分比超过阈值,则手动或自动触发断路器以在一段时间内停止对特定服务的所有请求。
- 当请求失败、被拒绝、超时或短路时执行回退逻辑。
- 近乎实时地监控指标和配置更改。
- 将所有对外部系统(或“依赖项”)的调用包装在一个
- 当您使用 Hystrix 包装每个底层依赖项时,如上图所示的架构将更改为类似于下图。每个依赖项相互隔离,限制在发生延迟时它可以饱和的资源,并包含在回退逻辑中,该逻辑决定当依赖项中发生任何类型的故障时做出什么响应:

-
详细了解它的工作原理和使用方法。
-
以上概念参考于官方资料:https://github.com/Netflix/Hystrix/wiki。
3.服务熔断(服务端)
1.什么是服务熔断?
-
熔断机制是赌赢雪崩效应的一种微服务链路保护机制。
-
当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。检测到该节点微服务调用响应正常后恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阀值缺省是5秒内20次调用失败,就会启动熔断机制。
-
熔断机制的注解是:
@HystrixCommand。
2.服务熔断解决如下问题:
- 当所依赖的对象不稳定时,能够起到快速失败的目的;
- 快速失败后,能够根据一定的算法动态试探所依赖对象是否恢复。
3.入门案例:
参考springcloud-provider-dept-8001,新建springcloud-provider-dept-hystrix-8001,将之前8001的所有东西拷贝一份。

server:port: 8001
# mybatis的配置
mybatis:
# config-location: classpath:mybatis/mybatis-config.xmltype-aliases-package: com.base.cloud.pojomapper-locations: classpath:mybatis/mapper/*.xml# spring的相关配置
spring:application:name: springcloud-provider-dept-hystrixdatasource:type: com.alibaba.druid.pool.DruidDataSource # 数据源driver-class-name: com.mysql.jdbc.Driver # mysql驱动url: jdbc:mysql://localhost:3306/db01?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8 #数据库名称username: rootpassword: 123456dbcp2:min-idle: 5 #数据库连接池的最小维持连接数initial-size: 5 #初始化连接数max-total: 5 #最大连接数max-wait-millis: 200 #等待连接获取的最大超时时间# Eureka配置:配置服务注册中心地址
eureka:client:service-url:# 注册中心地址7001-7003defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/instance:instance-id: springcloud-provider-dept-hystrix-8001 # 与client平级# prefer-ip-address: true # true表示访问路径可以显示IP地址# info配置
info:app.name: s-springcloud # 项目的名称company.name: www.subeily.top # 公司的名称修改pom,添加Hystrix的依赖。
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-hystrix -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-hystrix</artifactId><version>1.4.7.RELEASE</version>
</dependency>
使用
@RestController
public class DeptController {@Autowiredprivate DeptService service;@GetMapping("/get/{id}")@HystrixCommand(fallbackMethod = "hystrixGet")// 备用方案public Dept get(@PathVariable("id") long id) {Dept dept = service.queryById(id);// id 为空时抛出异常,并启动备用方案if (dept == null) {throw new RuntimeException("该id:\"+id+\"没有对应的的信息");}return dept;}// 备用方案public Dept hystrixGet(@PathVariable("id") long id) {return new Dept().setDeptno(id).setDname("这个id=>"+id+",没有对应的信息,null---@Hystrix~").setDb_source("在MySQL中没有这个数据库");}}开启
@SpringBootApplication
@EnableEurekaClient
@EnableDiscoveryClient
@EnableCircuitBreaker // 对hystrix 断机制的支持
public class DeptProviderHystrix8001 {public static void main(String[] args) {SpringApplication.run(DeptProviderHystrix8001.class,args);}
}测试
- 启动Eureka集群;
- 启动主启动类 DeptProviderHystrix8001;
- 启动客户端 springcloud-consumer-dept-80;
- 访问 http://localhost/consumer/get/111


4.服务降级 (客户端)
1.什么是服务降级?
-
服务降级是指当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理,或换种简单的方式处理,从而释放服务器资源以保证核心业务正常运作或高效运作。说白了,就是尽可能的把系统资源让给优先级高的服务。
-
资源有限,而请求是无限的。如果在并发高峰期,不做服务降级处理,一方面肯定会影响整体服务的性能,严重的话可能会导致宕机某些重要的服务不可用。所以,一般在高峰期,为了保证核心功能服务的可用性,都要对某些服务降级处理。比如当双11活动时,把交易无关的服务统统降级,如查看蚂蚁深林,查看历史订单等等。
2.服务降级主要用于什么场景呢
-
当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,可以将一些不重要或不紧急的服务或任务进行服务的 延迟使用或暂停使用。
-
降级的方式可以根据业务来,可以延迟服务,比如延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行;或者在粒度范围内关闭服务,比如关闭相关文章的推荐。

由上图可得,当某一时间内服务A的访问量暴增,而B和C的访问量较少,为了缓解A服务的压力,这时候需要B和C暂时关闭一些服务功能,去承担A的部分服务,从而为A分担压力,叫做服务降级。
3.服务降级需要考虑的问题
- 1)那些服务是核心服务,哪些服务是非核心服务
- 2)那些服务可以支持降级,那些服务不能支持降级,降级策略是什么
- 3)除服务降级之外是否存在更复杂的业务放通场景,策略是什么?
4.自动降级分类
-
超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况。
-
失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况。
-
故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)。
-
限流降级:秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
5.入门案例
修改springcloud-api工程,根据已经有的DeptClientService接口新建一个实现了FallbackFactory接口的类DeptClientServiceFallbackFactory。
【注意:这个类上需要@Component注解!!!】
@Component
public class DeptClientServiceFallbackFactory implements FallbackFactory {public Object create(Throwable throwable) {return new DeptClientService() {public Dept queryById(Long id) {return new Dept().setDeptno(id).setDname("该ID:" + id + "没有对应的信息,Consumer客户端提供的降级信息,此刻服务Provider已经关闭!").setDb_source("No this database in MySQL.");}public List<Dept> queryAll() {return null;}public boolean addDept(Dept dept) {return false;}};}
}
修改springcloud-api工程,DeptClientService接口在注解@FeignClient中添加fallbackFactory属性值。
@Component
@FeignClient(value = "SPRINGCLOUD-PROVIDER-DEPT",fallbackFactory = DeptClientServiceFallbackFactory.class)
public interface DeptClientService {@GetMapping("/get/{id}")public Dept queryById(@PathVariable("id") Long id); //根据id查询部门@GetMapping("/list")public List<Dept> queryAll(); //查询所有部门@PostMapping(value = "/add")public boolean addDept(Dept dept); //添加一个部门}springcloud-api工程mvn clean install;
springcloud-consumer-dept-feign-80工程修改YML;

启动eureka集群;
启动 springcloud-provider-dept-hystrix-8001;
启动 springcloud-consumer-dept-feign-80;
正常访问测试:http://localhost/consumer/get/1;

故意关闭微服务 springcloud-provider-dept-hystrix-8001;
客户端自己调用提示:http://localhost/consumer/dept/get/1
- 此时服务端provider已经down了,但是我们做了服务降级处理,让客户端在服务端不可用时 也会获得提示信息而不会挂起耗死服务器。

5.服务熔断和降级的区别
- 服务熔断—>服务端:一般是某个服务故障或者异常引起,类似现实世界中的“保险丝”,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时!
- 服务降级—>客户端:从整体网站请求负载考虑,当某个服务熔断或者关闭之后,服务将不再被调用,此时在客户端,我们可以准备一个 FallBackFactory ,返回一个默认的值(缺省值)。会导致整体的服务下降,但是好歹能用,比直接挂掉强。
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)。
- 实现方式不太一样,服务降级具有代码侵入性(由控制器完成/或自动降级),熔断一般称为自我熔断。

熔断,降级,限流:
-
限流:限制并发的请求访问量,超过阈值则拒绝;
-
降级:服务分优先级,牺牲非核心服务(不可用),保证核心服务稳定;从整体负荷考虑;
-
熔断:依赖的下游服务故障触发熔断,避免引发本系统崩溃;系统自动执行和恢复
6.Dashboard 流监控
- 除了隔离依赖服务的调用以外,Hystrix还提供了准实时的调用监控(Hystrix Dashboard),Hystrix会持续地记录所有通过Hystrix发起的请求的执行信息,并以统计报表和图形的形式展示给用户,包括每秒执行多少请求,多少成功,多少失败等等。
- Netflix通过hystrix-metrics-event-stream项目实现了对以上指标的监控,SpringCloud也提供了Hystrix Dashboard的整合,对监控内容转化成可视化界面!

新建工程springcloud-consumer-hystrix-dashboard-9001
导入pom依赖
<dependencies><!--Hystrix依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-hystrix</artifactId><version>1.4.7.RELEASE</version></dependency><!--dashboard依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-hystrix-dashboard</artifactId><version>1.4.7.RELEASE</version></dependency><!--Ribbon--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-ribbon</artifactId><version>1.4.7.RELEASE</version></dependency><!--Eureka--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId><version>1.4.6.RELEASE</version></dependency><!--实体类+web--><dependency><groupId>com.base.cloud</groupId><artifactId>springcloud-api</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--热部署--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId></dependency></dependencies>添加主启动类
@SpringBootApplication
@EnableHystrixDashboard
public class DeptConsumerDashBoardApp9001 {public static void main(String[] args) {SpringApplication.run(DeptConsumerDashBoardApp9001.class,args);}
}
添加配置文件
server:port: 9001hystrix:dashboard:proxy-stream-allow-list: localhost
给springcloud-provider-dept-hystrix-8001模块下的主启动类添加如下代码,添加监控
@SpringBootApplication
@EnableEurekaClient // 本服务启动之后会自动注册进Eureka中!
@EnableDiscoveryClient // 开启服务发现客户端的注解,可以用来获取一些配置的信息,得到具体的微服务
@EnableCircuitBreaker //对hystrix 熔断机制的支持 【==========new=======】public class DeptProviderHystrix8001 {public static void main(String[] args) {SpringApplication.run(DeptProviderHystrix8001.class,args);}//增加一个 Servlet@Beanpublic ServletRegistrationBean hystrixMetricsStreamServlet(){ServletRegistrationBean registrationBean = new ServletRegistrationBean(new HystrixMetricsStreamServlet());//访问该页面就是监控页面registrationBean.addUrlMappings("/actuator/hystrix.stream");return registrationBean;}
}
测试一
-
启动springcloud-consumer-hystrix-dashboard-9001监控服务
-
访问:http://localhost:9001/hystrix

-
启动3个Eureka集群
-
启动springcloud-provider-dept-hystrix-8001
-
进入监控页面,访问:
- http://localhost:8001/get/1
- http://localhost:8001/actuator/hystrix.stream 【查看1秒一动的数据流】

监控测试
- 多次刷新 http://localhost:8001/dept/get/1
- 观察监控窗口,就是那个豪猪页面;
- 添加监控地址

- Delay: 该参数用来控制服务器上轮询监控信息的延迟时间,默认为2000毫秒,可以通过配置该属性来降低客户端的网络和CPU消耗
- Title:该参数对应了头部标题HystrixStream之后的内容,默认会使用具体监控实例URL,可以通过配置该信息来展示更合适的标题。
- 监控结果:

- 实心圆:公有两种含义,他通过颜色的变化代表了实例的健康程度。
- 它的健康程度从 绿色<黄色<橙色<红色 递减。
- 该实心圆除了颜色的变化之外,它的大小也会根据实例的请求流量发生变化,流量越大,该实心圆就越大,所以通过该实心圆的展示,就可以在大量的实例中快速发现故障实例和高压力实例。
八.Zull路由网关
1.概述
-
Zull包含了对请求的路由(用来跳转的)和过滤两个最主要功能:
-
其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础,而过滤器功能则负责对请求的处理过程进行干预,是实现请求校验,服务聚合等功能的基础。Zuul和Eureka进行整合,将Zuul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他服务的消息,也即以后的访问微服务都是通过Zuul跳转后获得

-
注意:Zuul 服务最终还是会注册进 Eureka
-
提供:代理 + 路由 + 过滤 三大功能!
2.Zuul 能干嘛?
- 路由
- 过滤
官方文档:GitHub - Netflix/zuul: Zuul is a gateway service that provides dynamic routing, monitoring, resiliency, security, and more.
3.入门案例
新建springcloud-zuul模块,并导入依赖
<dependencies><dependency><groupId>com.base.cloud</groupId><artifactId>springcloud-api</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-ribbon --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-ribbon</artifactId><version>1.4.7.RELEASE</version></dependency><!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId><version>1.4.7.RELEASE</version></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zuul</artifactId><version>1.4.7.RELEASE</version></dependency></dependencies>application.yml
server:port: 4399
spring:application:name: springcloud-zuul#Eureka的配置,服务注册到哪里
eureka:client:service-url:defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/instance:instance-id: zuul4399.comprefer-ip-address: true #改为true后默认显示的是ip地址而不再是localhost 方便团队不同人使用# info配置
info:app.name: fuck-springcloud # 项目的名称company.name: www.fuck.top # 公司的名称# zull 路由网关配置
zuul:# 路由相关配置 routes:mydept.serviceId: springcloud-provider-dept # eureka注册中心的服务提供方路由名称mydept.path: /mydept/** # 将eureka注册中心的服务提供方路由名称 改为自定义路由名称ignored-services: "*" # 不能再使用这个路径访问了,*: 忽略,隐藏全部的服务名称~prefix: /fuck # 设置公共的前缀
osts修改
hosts文件的位置在C:\Windows\System32\drivers\etc\hosts
127.0.0.1 cloud.com
主启动类
@SpringBootApplication
@EnableZuulProxy // 开启Zuul
public class SpringCloudZuulApp4399 {public static void main(String[] args) {SpringApplication.run(SpringCloudZuulApp4399.class,args);}
}
启动:
- 三个Eureka集群
- 服务提供者springcloud-provider-dept-8001
- zuul服务
- 访问:http://localhost:7001/

不用路由:http://localhost:8001/get/2 
使用路由:http://cloud.com:4399/springcloud-provider-dept/get/2

- 上图是没有经过Zull路由网关配置时,服务接口访问的路由,可以看出直接用微服务(服务提供方)名称去访问,这样不安全,不能将微服务名称暴露!
- 所以经过Zull路由网关配置后,访问封装好的url:http://cloud.com:4399/fuck/mydept/get/2

九.SpringCloud Config 分布式配置
1.分布式系统面临的–配置文件问题
- 微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务,由于每个服务都需要必要的配置信息才能运行,所以一套集中式的,动态的配置管理设施是必不可少的。spring cloud提供了configServer来解决这个问题,我们每一个微服务自己带着一个application.yml,那上百个的配置文件修改起来,令人头疼!
SpringCloud config分布式配置中心

- spring cloud config 为微服务架构中的微服务提供集中化的外部支持,配置服务器为各个不同微服务应用的所有环节提供了一个中心化的外部配置。
- spring cloud config 分为服务端和客户端两部分。
- 服务端也称为 分布式配置中心,它是一个独立的微服务应用,用来连接配置服务器并为客户端提供获取配置信息,加密,解密信息等访问接口。
- 客户端则是通过指定的配置中心来管理应用资源,以及与业务相关的配置内容,并在启动的时候从配置中心获取和加载配置信息。配置服务器默认采用git来存储配置信息,这样就有助于对环境配置进行版本管理。并且可用通过git客户端工具来方便的管理和访问配置内容。
2.spring cloud config 分布式配置中心能干嘛?
- 集中式管理配置文件
- 不同环境,不同配置,动态化的配置更新,分环境部署,比如 /dev /test /prod /beta /release
- 运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
- 当配置发生变动时,服务不需要重启,即可感知到配置的变化,并应用新的配置
- 将配置信息以REST接口的形式暴露
3.spring cloud config 分布式配置中心与GitHub整合
服务端
由于spring cloud config 默认使用git来存储配置文件 (也有其他方式,比如自持SVN 和本地文件),但是最推荐的还是git,而且使用的是 http/https 访问的形式。
- 在码云上新建仓库 springcloud-config,仓库要开源哦!!!
- 生成/添加SSH公钥
- 拉取到本地,编写application.yaml配置文件
spring:profiles:active: dev---
spring:profiles: devapplication:name: springcloud-config-dev---
spring:profiles: testapplication:name: springcloud-config-test



新建模块 springcloud-config-server-3344,导入依赖
<dependencies><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--config--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-config-server</artifactId><version>2.1.1.RELEASE</version></dependency><!--eureka--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId><version>1.4.6.RELEASE</version></dependency>
</dependencies>
编写配置文件
server:port: 3344spring:application:name: springcloud-config-server# 连接码云远程仓库cloud:config:server:git:# 注意是https的而不是sshuri: https://gitee.com/x15930311121/springcloud-cloud.git# 通过 config-server可以连接到git,访问其中的资源以及配置~# 不加这个配置会报Cannot execute request on any known server 这个错:连接Eureka服务端地址不对
# 或者直接注释掉eureka依赖 这里暂时用不到eureka
eureka:client:register-with-eureka: falsefetch-registry: false
主启动类
@EnableConfigServer // 开启spring cloud config server服务
@SpringBootApplication
public class ConfigServer3344 {public static void main(String[] args) {SpringApplication.run(ConfigServer3344.class,args);}
}
HTTP服务具有以下格式的资源:
/{application}/{profile}[/{label}]
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
测试
-
启动 ConfigServer3344 即可;
-
访问 http://localhost:3344/application-dev.yaml

访问 http://localhost:3344/application/test/master

访问 http://localhost:3344/master/application-dev.yaml

访问不存在的配置

客户端
在本地库编写一个配置文件config-client.yaml,并且上传到码云仓库 
spring:profiles:active: dev---
server:port: 8201
#spring配置
spring:profiles: devapplication:name: springcloud-config-client
#Eureka的配置,服务注册到哪里
eureka:client:service-url:defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/---
server:port: 8202
#spring配置
spring:profiles: testapplication:name: springcloud-config-client
#Eureka的配置,服务注册到哪里
eureka:client:service-url:defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
git提交与上面一样的命令
新建 springcloud-config-client-3355 模块,导入依赖
<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId><version>2.1.1.RELEASE</version></dependency><!--——web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--actuator完善监控信息--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
</dependencies>
resources下创建application.yml和bootstrap.yml配置文件
其中bootstrap.yml是系统级别的配置文件,application.yml是用户级别的配置文件,系统级别更高级。因为要访问远程库的配置文件,所以一些重要的配置编写在系统级别的配置文件中。
bootstrap.yaml
# 系统级别的配置
spring:cloud:config:name: config-client # 需要从git上读取的资源名称,不要后缀profile: devlabel: masteruri: http://localhost:3344
application.yml
# 用户级别的配置
spring:application:name: springcloud-config-client# 不加这个配置会报Cannot execute request on any known server 这个错:连接Eureka服务端地址不对
# 或者直接注释掉eureka依赖 这里暂时用不到eureka
eureka:client:register-with-eureka: falsefetch-registry: false
建controller包下的ConfigClientController.java 用于测试
@RestController
public class ConfigClientController {@Value("${spring.application.name}")private String applicationName; //获取微服务名称@Value("${eureka.client.service-url.defaultZone}")private String eurekaServer; //获取Eureka服务@Value("${server.port}")private String port; //获取服务端的端口号@RequestMapping("/config")public String getConfig(){return "applicationName:"+applicationName +"eurekaServer:"+eurekaServer +"port:"+port;}
}
编写主启动类
@SpringBootApplication
public class ConfigClient3355 {public static void main(String[] args) {SpringApplication.run(ConfigClient3355.class,args);}
}
测试一下,先启动3344,后启动客户端,然后访问 http://localhost:8201/config/

在bootstrap.yaml文件中,切换一下环境dev->test
# 系统级别的配置
spring:cloud:config:name: config-client # 需要从git上读取的资源名称,不要后缀profile: testlabel: masteruri: http://localhost:3344
重新测试,继续访问 http://localhost:8201/config 发现没用了。访问 http://localhost:8202/config

实战一下
需求:把之前的7001、8001配置文件修改成远程库读取配置文件,实现配置与编码解耦。

config-dept.yaml
- 其中为了测试dev和test唯一的不同是连接的数据库不同。
spring:profiles:active: dev---
server:port: 8001
# mybatis的配置
mybatis:
# config-location: classpath:mybatis/mybatis-config.xmltype-aliases-package: com.base.cloud.pojomapper-locations: classpath:mybatis/mapper/*.xml# spring的相关配置
spring:profiles: devapplication:name: springcloud-provider-deptdatasource:type: com.alibaba.druid.pool.DruidDataSource # 数据源driver-class-name: com.mysql.jdbc.Driver # mysql驱动url: jdbc:mysql://localhost:3306/db01?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8 #数据库名称username: rootpassword: 123456dbcp2:min-idle: 5 #数据库连接池的最小维持连接数initial-size: 5 #初始化连接数max-total: 5 #最大连接数max-wait-millis: 200 #等待连接获取的最大超时时间# Eureka配置:配置服务注册中心地址
eureka:client:service-url:# 注册中心地址7001-7003defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/instance:instance-id: springcloud-provider-dept-8001 # 与client平级# prefer-ip-address: true # true表示访问路径可以显示IP地址# info配置
info:app.name: s-springcloud # 项目的名称company.name: www.one.top # 公司的名称---
server:port: 8001
# mybatis的配置
mybatis:
# config-location: classpath:mybatis/mybatis-config.xmltype-aliases-package: com.base.cloud.pojomapper-locations: classpath:mybatis/mapper/*.xml# spring的相关配置
spring:profiles: testapplication:name: springcloud-provider-deptdatasource:type: com.alibaba.druid.pool.DruidDataSource # 数据源driver-class-name: com.mysql.jdbc.Driver # mysql驱动url: jdbc:mysql://localhost:3306/db02?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8 #数据库名称username: rootpassword: 123456dbcp2:min-idle: 5 #数据库连接池的最小维持连接数initial-size: 5 #初始化连接数max-total: 5 #最大连接数max-wait-millis: 200 #等待连接获取的最大超时时间# Eureka配置:配置服务注册中心地址
eureka:client:service-url:# 注册中心地址7001-7003defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/instance:instance-id: springcloud-provider-dept-8001 # 与client平级# prefer-ip-address: true # true表示访问路径可以显示IP地址# info配置
info:app.name: s-springcloud # 项目的名称company.name: www.one.top # 公司的名称
config-eureka.yaml
spring:profiles:active: dev---
server:port: 7001#spring配置
spring:profiles: devapplication:name: springcloud-config-eureka# Eureka配置
eureka:instance:hostname: eureka7001.com #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url:# 单机 defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultZone地址defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/---
server:port: 7001#spring配置
spring:profiles: testapplication:name: springcloud-config-eureka# Eureka配置
eureka:instance:hostname: eureka7001.com #eureka服务端的实例名称client:register-with-eureka: false #是否将自己注册到Eureka服务器中,本身是服务器,无需注册fetch-registry: false #false表示自己端就是注册中心,职责是维护服务实例,并不需要检索服务service-url:# 单机 defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/# 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个defaultZone地址defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
新建springcloud-config-eureka-7001模块,内容和之前的springcloud-eureka-7001一样
修改springcloud-config-eureka-7001的配置文件,换成远程库读取
添加bootstrap.yaml系统配置文件
# 系统级别的配置
spring:cloud:config:name: config-eureka # 需要从git上读取的资源名称,不要后缀profile: devlabel: masteruri: http://localhost:3344
修改application.yaml
spring:application:name: springcloud-config-eureka# 不加这个配置会报Cannot execute request on any known server 这个错:连接Eureka服务端地址不对
# 或者直接注释掉eureka依赖 这里暂时用不到eureka
eureka:client:register-with-eureka: falsefetch-registry: false
新建springcloud-config-provider-dept-8001模块,内容和之前的springcloud-provider-dept-8001一样
修改springcloud-config-provider-dept-8001的配置文件,换成远程库读取
添加bootstrap.yaml系统配置文件
# 系统级别的配置
spring:cloud:config:name: config-dept # 需要从git上读取的资源名称,不要后缀profile: devlabel: masteruri: http://localhost:3344
修改application.yaml
spring:application:name: springcloud-config-provider-dept# 不加这个配置会报Cannot execute request on any known server 这个错:连接Eureka服务端地址不对
# 或者直接注释掉eureka依赖 这里暂时用不到eureka
eureka:client:register-with-eureka: falsefetch-registry: false
在7001、8001的pom.xml中添加spring cloud config依赖
<!--config-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId><version>2.1.1.RELEASE</version>
</dependency>
测试
- 启动cofig3344服务端、客户端7001和8001
- 访问 http://localhost:3344/master/config-eureka-dev.yaml

说明config服务端没问题
- 访问 http://localhost:7001

说明远程配置读取成功
- 访问 http://localhost:8001/get/2
相关文章:
SpringCloud入门
SpringCloud 原版笔记:狂神说笔记——SpringCloud快速入门23 - subeiLY - 博客园 (cnblogs.com) 一.前言 常见面试题 什么是微服务? 微服务之间是如何独立通讯的? SpringCloud 和 Dubbo有哪些区别? SpringBoot和SpringCloud&…...

js替换css主题变量并切换iconfont文件
iconfont不止有单色、双色的图标,还有很多【多色】的图标,于是不能【去色】,只能手动替换primary 新建一个iconfont,替换过主题色的,然后与旧的iconfont配合切换使用 主要如下: reqiure之前必须【清除缓…...

UI设计师面试整理-设计趋势和行业理解
在UI设计师的面试中,了解当前的设计趋势和行业动态可以让你在面试中展示你的前瞻性思维和对设计领域的深刻理解。面试官希望看到你不仅具备扎实的设计技能,还能够洞察和应用最新的设计趋势和技术。以下是一些当前的设计趋势和如何在面试中展示你对这些趋势的理解和应用的建议…...

Java零工市场小程序如何改变自由职业者生活
如今,自由职业者越来越多,他们需要找到合适的工作机会,Java零工市场小程序,为自由职业者提供了一个方便、快捷的寻找工作机会的方式,这样一来,改变了自由职业者找寻工作的方式,也提高了他们的收…...

android11 自动授权访问sdcard
目录 步骤1 步骤2 步骤1 frameworks/base/core/java/com/android/internal/os/ZygoteInit.java OsConstants.CAP_SYS_PTRACE,OsConstants.CAP_SYS_TIME,OsConstants.CAP_SYS_TTY_CONFIG,OsConstants.CAP_WAKE_ALARM,OsConstants.CAP_BLOCK_SUSPENDOsConstants.CAP_BLOCK_SUS…...

优青博导团队/免费指导/数据分析//论文润色/组学技术服务 、表观组分析、互作组分析、遗传转化实验、生物医学
🌟 教授团队领衔,全方位科研服务 🚀 一站式科研解决方案 📈 加速科研进程,让成果不再等待 📝 专业分析 定制服务 科研成功 👨🔬 立即行动,让科研成果跃然纸上 业务领…...

Mybatis 学习之 分页实现
文章目录 1. Mybatis1.1. 代码实现 2. Mybatis Plus2.1. 代码实现2.2. 特别注意 3. PageHelper3.1. 代码实现3.2. 特别注意 参考资料 1. Mybatis 1.1. 代码实现 package com.example.demo;import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot…...

Spring Boot文件上传
配置文件上传属性: 在application.properties文件中配置文件上传的属性,包括上传目录的路径、文件大小限制等。 spring.servlet.multipart.max-file-size10MB spring.servlet.multipart.max-request-size10MB处理文件上传请求 上传的文件按照日期进行…...

基于Springboot+Vue的高校体育运动会比赛系统(含源码+数据库)
1.开发环境 开发系统:Windows10/11 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql5.7或8.0 数据库可视化工具: navicat 服务器: SpringBoot自带 apache tomcat 主要技术: Java,Springboot,mybatis,mysql,vue 2.视频演示地址 3.功能 该系统…...

【JavaEE】——内存可见性问题
阿华代码,不是逆风,就是我疯,你们的点赞收藏是我前进最大的动力!!希望本文内容能够帮助到你! 目录 一:内存可见性问题 1:代码解释 2:结果分析 (1…...

YOLO训练参数设置解析
笔者按照教程训练完YOLO后对train训练参数配置产生兴趣,因此下文参考官方文档进行总结 Train - Ultralytics YOLO Docs YOLO 模型的训练设置包括训练过程中使用的各种超参数和配置。 这些设置会影响模型的性能、速度和准确性。 关键的训练设置包括批量大小、学习率…...

基于OpenCV的实时年龄与性别识别(支持CPU和GPU)
关于深度实战社区 我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万粉丝,拥有2篇国家级人工智能发明专利。 社区特色…...

理解Js执行上下文
执行上下文 执行上下文(Context)又称上下文,在 JavaScript 中是一个重要的概念,它决定了变量和函数的可访问性及其行为。每个上下文都有一个关联的变量对象(Variable Object),所有在该上下文中定义的变量和…...

微信小程序 蓝牙通讯
客户的需求如下:通过微信小程序控制蓝牙ble设备(电子面膜),通过不同指令控制面膜的亮度和时间。 01.首先看下客户的ble设备服务文档:(本部分需要有点蓝牙基础,在调试过程中可以用安卓软件nRF Connect软件来执行测试命令) 0xFFF1灯控命令 命…...

java后端项目技术记录
后端使用技术记录 一、软件1. apifox,API管理软件问题 2. nginx前端服务器(1) 反向代理(2) 负载均衡 二、问题1. 使用spring全局异常处理器处理特定的异常2. 扩展springmvc的消息转换器(对象和json数据的转换)3. 路径参数的接收4. 实体构建器…...
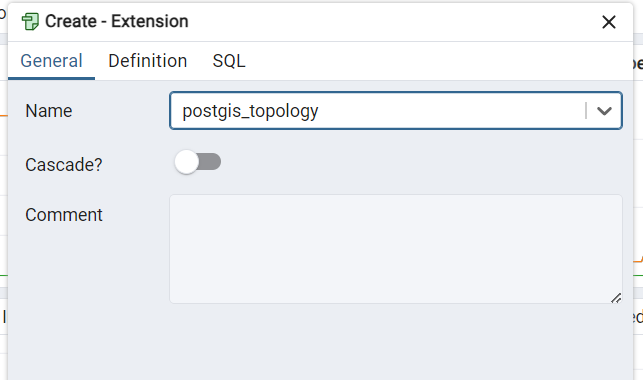
PostgreSQL数据库与PostGIS在Windows中的部署与运行
本文介绍在Windows电脑中,下载、安装、部署并运行PostgreSQL与PostGIS数据库服务的方法。 PostgreSQL是一种功能强大的开源关系型数据库管理系统(RDBMS),以其稳定性、可靠性和丰富的功能而闻名;其支持多种高级特性&…...

高级算法设计与分析 学习笔记10 平摊分析
动态表,可以变长。 一溢出就另起一个两倍大小的表。 可以轻易证明把n个数字放进去的时间复杂度是O(n),n n/2 n/4……也就2n,插入数字本身也就是n,加起来最多不超过3n. 这种复杂度究竟是怎么算的?毕竟每次插入复杂度…...

从“纸面算力”到“好用算力”,超聚变打通AI+“最后一公里”
如果要评选2024年的年度科技名词,AI当属最热门的候选项。 年初的《政府工作报告》中首次提出了“人工智能”行动,正在从顶层设计着手,加快形成以人工智能为引擎的新质生产力。 折射到市场层面,AI作为一种新的范式,不…...

【有啥问啥】具身智能(Embodied AI):人工智能的新前沿
具身智能(Embodied AI):人工智能的新前沿 引言 在人工智能(AI)的进程中,具身智能(Embodied AI)正逐渐成为研究与应用的焦点。具身智能不仅关注于机器的计算能力,更强调…...

11-pg内核之锁管理器(六)死锁检测
概念 每个事务都在等待集合中的另一事务,由于这个集合是一个有限集合,因此一旦在这个等待的链条上产生了环,就会产生死锁。自旋锁和轻量锁属于系统锁,他们目前没有死锁检测机制,只能靠内核开发人员在开发过程中谨慎的…...

M2LOrder模型Mathtype公式编辑器的趣味扩展:为数学证明添加情感注释
M2LOrder模型Mathtype公式编辑器的趣味扩展:为数学证明添加情感注释 你有没有过这样的经历?面对一篇复杂的数学论文或教材,读到某个证明步骤时,心里忍不住嘀咕:“这一步也太巧妙了,怎么想到的?…...

从ReVeal到实战:基于图神经网络的智能漏洞检测技术演进与落地思考
1. 图神经网络在漏洞检测中的崛起 第一次接触代码漏洞检测领域时,我被传统方法的繁琐流程震惊了。记得当时需要手动定义数百条规则来检测缓冲区溢出漏洞,每次遇到新漏洞类型就得加班加点补充规则。直到2018年遇到ReVeal论文,才发现图神经网络…...

特斯拉行车记录仪视频合并神器:告别碎片化,一键生成完整记录
特斯拉行车记录仪视频合并神器:告别碎片化,一键生成完整记录 【免费下载链接】tesla_dashcam Convert Tesla dash cam movie files into one movie 项目地址: https://gitcode.com/gh_mirrors/te/tesla_dashcam 还在为特斯拉行车记录仪生成的海量…...

FrankenPHP服务器性能监控终极指南:10个关键指标深度解析
FrankenPHP服务器性能监控终极指南:10个关键指标深度解析 【免费下载链接】frankenphp The modern PHP app server 项目地址: https://gitcode.com/GitHub_Trending/fr/frankenphp FrankenPHP作为现代化的PHP应用服务器,提供了强大的性能监控能力…...

从河南农村到泰国拳台:张家乐在Bangla Boxing Stadium加冕泰拳冠军的荣耀
2017年,泰国普吉岛Bangla Boxing Stadium的聚光灯下,来自中国河南的拳手张家乐高举冠军奖杯,在这片泰拳发源地的擂台上,书写了中国格斗选手的荣耀篇章。这场胜利,不仅是他个人职业生涯的高光时刻,更让世界看…...

Windows 11 LTSC系统如何安全添加微软商店:完整解决方案指南
Windows 11 LTSC系统如何安全添加微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 如果你正在使用Windows 11 24…...

PathOfBuilding:流放之路玩家的离线构建神器,打造最强角色规划方案
PathOfBuilding:流放之路玩家的离线构建神器,打造最强角色规划方案 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding 你是否曾经在《流放之路》中花…...

FPGA图像处理入门:OV7670+DVP接口数据采集的那些‘坑’与优化策略
FPGA图像处理实战:OV7670DVP接口数据采集的工程级优化指南 当你在实验室调试OV7670摄像头时,是否遇到过这些场景:VGA显示器上的图像突然撕裂、颜色通道错乱,或是帧率莫名其妙降到个位数?作为一款经典的VGA分辨率CMOS传…...

从合合技术揭秘到自建数据集:手把手训练你的文档矫正模型
从合合技术揭秘到自建数据集:手把手训练你的文档矫正模型 在数字化办公场景中,文档图像矫正技术正成为提升OCR识别精度的关键环节。当开发者面对弯曲、折叠或透视变形的文档时,传统参数化方法往往难以应对复杂形变,而基于深度学习…...
Qwen-Image-2512-Pixel-Art-LoRA 跨界创作:生成像素风音乐专辑封面与海报
Qwen-Image-2512-Pixel-Art-LoRA 跨界创作:生成像素风音乐专辑封面与海报 最近在玩一个挺有意思的AI工具,叫Qwen-Image-2512-Pixel-Art-LoRA。名字有点长,但功能很直接,就是专门生成像素艺术。我琢磨着,像素风这种复古…...