17、CPU缓存架构详解高性能内存队列Disruptor实战
1.CPU缓存架构详解
1.1 CPU高速缓存概念
CPU缓存即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。CPU高速缓存可以分为一级缓存,二级缓存,部分高端CPU还具有三级缓存,每一级缓存中所储存的全部数据都是下一级缓存的一部分,这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。

由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,减少CPU的等待时间,提高了系统的效率。
在CPU访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就是局部性原理。
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
比如循环、递归、方法的反复调用等。
空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
比如顺序执行的代码、连续创建的两个对象、数组等。
1.2 CPU多核缓存架构
现代CPU为了提升执行效率,减少CPU与内存的交互,一般在CPU上集成了多级缓存架构,常见的为三级缓存结构。如下图:
CPU寄存器是位于CPU内部的存储器,数据的读写速度非常快,比缓存和主存更快。CPU会把常用的数据放到寄存器中进行处理,而不是直接从主存中读取,这样可以加速数据的访问和处理。但是寄存器的容量非常有限,一般只有几十个或者几百个字节,因此只能存储少量的数据
当CPU读取一个地址中的数据时,会先在 L1 Cache 中查找。如果数据在 L1 Cache 中找到,CPU 会直接从 L1 Cache 中读取数据。如果没有找到,则会将这个请求发送给 L2 Cache,然后在 L2 Cache 中查找,如果 L2 Cache 中也没有找到,则会继续将请求发送到 L3 Cache 中。如果在 L3 Cache 中还是没有找到数据,则最后会从主内存中读取数据并将其存储到 CPU 的缓存中。
当CPU写入一个地址中的数据时,同样会先将数据写入 L1 Cache 中,然后再根据缓存一致性协议将数据写入 L2 Cache、L3 Cache 以及主内存中。具体写入过程与缓存一致性协议相关,有可能只写入 L1 Cache 中,也有可能需要将数据写入 L2 Cache、L3 Cache 以及主内存中。写入过程中也可能会使用缓存行失效、写回等技术来提高效率。
思考:这种缓存架构在多线程访问的时候存在什么问题?
CPU多核缓存架构缓存一致性问题分析
在CPU多核缓存架构中,每个处理器都有一个单独的缓存,共享数据可能有多个副本:一个副本在主内存中,一个副本在请求它的每个处理器的本地缓存中。当数据的一个副本发生更改时,其他副本必须反映该更改。也就是说,CPU多核缓存架构要保证缓存一致性。
1.3 CPU缓存架构缓存一致性的解决方案
《64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf》中有如下描述:
The 32-bit IA-32 processors support locked atomic operations on locations in system memory. These operations are typically used to manage shared data structures (such as semaphores, segment descriptors, system segments, or page tables) in which two or more processors may try simultaneously to modify the same field or flag. The processor uses three interdependent mechanisms for carrying out locked atomic operations:
• Guaranteed atomic operations
• Bus locking, using the LOCK# signal and the LOCK instruction prefix
• Cache coherency protocols that ensure that atomic operations can be carried out on cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon, and P6 family processors
32位的IA-32处理器支持对系统内存中的位置进行锁定的原子操作。这些操作通常用于管理共享的数据结构(如信号量、段描述符、系统段或页表),在这些结构中,两个或多个处理器可能同时试图修改相同的字段或标志。处理器使用三种相互依赖的机制来执行锁定的原子操作:
- 有保证的原子操作
处理器提供一些特殊的指令或者机制,可以保证在多个处理器同时执行原子操作时,它们不会相互干扰,从而保证原子性。这些指令或者机制的实现通常需要硬件支持。例如x86架构中提供了一系列的原子操作指令,如XADD、XCHG、CMPXCHG等,可以保证在多个处理器同时执行这些指令时,它们不会相互干扰,从而保证原子性。 - 总线锁定,使用LOCK#信号和LOCK指令前缀
总线锁定是一种用于确保原子操作的机制,通常会在LOCK指令前缀和一些特殊指令中使用。在执行LOCK指令前缀时,处理器会将LOCK#信号拉低,这个信号会通知其他处理器当前总线上的数据已经被锁定,从而确保原子性。 - 缓存一致性协议,确保原子操作可以在缓存的数据结构上执行(缓存锁定);这种机制出现在Pentium 4、Intel Xeon和P6系列处理器中
缓存一致性协议是一种用于确保处理器缓存中的数据和主存中的数据一致的机制。缓存一致性协议会通过处理器之间的通信,确保在一个处理器修改了某个数据后,其他处理器缓存中的该数据会被更新或者失效,从而保证在多个处理器同时对同一个数据进行操作时,它们所看到的数据始终是一致的。
缓存锁定则是在缓存一致性协议的基础上实现原子操作的机制,它会利用缓存一致性协议来确保在多个处理器同时修改同一个缓存行中的数据时,只有一个处理器能够获得锁定,从而保证原子性。缓存锁定的实现也需要硬件的支持,而且不同的处理器架构可能会有不同的实现方式。
缓存一致性协议不能使用的特殊情况:
- 当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行时,则处理器会调用总线锁定。
不能被缓存在处理器内部的数据通常指的是不可缓存的设备内存(如显存、网络接口卡的缓存等),这些设备内存一般不受缓存一致性协议的管辖,处理器无法将其缓存到自己的缓存行中。 - 有些处理器不支持缓存锁定。早期的Pentium系列处理器并不支持缓存锁定机制。在这些处理器上,只能使用总线锁定来实现原子操作。
但现代的处理器通常都支持缓存锁定机制,因此应该尽量使用缓存锁定来实现原子操作,以获得更好的性能。
1.4 缓存一致性协议实现原理
总线窥探
总线窥探(Bus snooping)是缓存中的一致性控制器(snoopy cache)监视或窥探总线事务的一种方案,其目标是在分布式共享内存系统中维护缓存一致性。包含一致性控制器(snooper)的缓存称为snoopy缓存。该方案由Ravishankar和Goodman于1983年提出。
在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(Bus Transaction)
工作原理
当特定数据被多个缓存共享时,处理器修改了共享数据的值,更改必须传播到所有其他具有该数据副本的缓存中。这种更改传播可以防止系统违反缓存一致性。数据变更的通知可以通过总线窥探来完成。所有的窥探者都在监视总线上的每一个事务。如果一个修改共享缓存块的事务出现在总线上,所有的窥探者都会检查他们的缓存是否有共享块的相同副本。如果缓存中有共享块的副本,则相应的窥探者执行一个动作以确保缓存一致性。这个动作可以是刷新缓存块或使缓存块失效。它还涉及到缓存块状态的改变,这取决于缓存一致性协议(cache coherence protocol)。
窥探协议类型
根据管理写操作的本地副本的方式,有两种窥探协议:
写失效(Write-invalidate)
当处理器写入一个共享缓存块时,其他缓存中的所有共享副本都会通过总线窥探失效。这种方法确保处理器只能读写一个数据的一个副本。其他缓存中的所有其他副本都无效。这是最常用的窥探协议。MSI、MESI、MOSI、MOESI和MESIF协议属于该类型。
写更新(Write-update)
缓存一致性协议在多处理器系统中应用于高速缓存一致性。为了保持一致性,人们设计了各种模型和协议,如MSI、MESI(又名Illinois)、MOSI、MOESI、MERSI、MESIF、write-once、Synapse、Berkeley、Firefly和Dragon协议。
MESI协议
MESI协议是一个基于写失效的缓存一致性协议,是支持回写(write-back)缓存的最常用协议。也称作伊利诺伊协议 (Illinois protocol,因为是在伊利诺伊大学厄巴纳-香槟分校被发明的)。
缓存行有4种不同的状态:
- 已修改Modified (M)
缓存行是脏的(dirty),与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S). - 独占Exclusive (E)
缓存行只在当前缓存中,但是干净的——缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。 - 共享Shared (S)
缓存行也存在于其它缓存中且是未修改的。缓存行可以在任意时刻抛弃。 - 无效Invalid (I)
缓存行是无效的
MESI协议用于确保多个处理器之间共享的内存数据的一致性。当一个处理器需要访问某个内存数据时,它首先会检查自己的缓存中是否有该数据的副本。如果缓存中没有该数据的副本,则会发出一个缓存不命中(miss)请求,从主内存中获取该数据的副本,并将该数据的副本存储到自己的缓存中。
当一个处理器发出一个缓存不命中请求时,如果该数据的副本已经存在于另一个处理器或核心的缓存中(即处于共享状态),则该处理器可以从另一个处理器的缓存中复制该数据的副本。这个过程称为缓存到缓存复制(cache-to-cache transfer)。
缓存到缓存复制可以减少对主内存的访问,从而提高系统的性能。但是,需要确保数据的一致性,否则会出现数据错误或不一致的情况。因此,在进行缓存到缓存复制时,需要使用MESI协议中的其他状态转换来确保数据的一致性。例如,如果两个缓存都处于修改状态,那么必须先将其中一个缓存的数据写回到主内存,然后才能进行缓存到缓存复制。
1.5 伪共享的问题
如果多个核上的线程在操作同一个缓存行中的不同变量数据,那么就会出现频繁的缓存失效,即使在代码层面看这两个线程操作的数据之间完全没有关系。这种不合理的资源竞争情况就是伪共享(False Sharing)。
ArrayBlockingQueue有三个成员变量:
- takeIndex:需要被取走的元素下标
- putIndex:可被元素插入的位置的下标
- count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。
如上图所示,当生产者线程put一个元素到ArrayBlockingQueue时,putIndex会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。
linux下查看Cache Line大小
Cache Line大小是64Byte

或者执行 cat /proc/cpuinfo 命令

避免伪共享方案
方案1:缓存行填充
class Pointer {volatile long x;//避免伪共享: 缓存行填充long p1, p2, p3, p4, p5, p6, p7;volatile long y;
}
方案2:使用 @sun.misc.Contended 注解(java8)
注意需要配置jvm参数:-XX:-RestrictContended
public class FalseSharingTest {public static void main(String[] args) throws InterruptedException {testPointer(new Pointer());}private static void testPointer(Pointer pointer) throws InterruptedException {long start = System.currentTimeMillis();Thread t1 = new Thread(() -> {for (int i = 0; i < 100000000; i++) {pointer.x++;}});Thread t2 = new Thread(() -> {for (int i = 0; i < 100000000; i++) {pointer.y++;}});t1.start();t2.start();t1.join();t2.join();System.out.println(pointer.x+","+pointer.y);System.out.println(System.currentTimeMillis() - start);}
}class Pointer {// 避免伪共享: @Contended + jvm参数:-XX:-RestrictContended jdk8支持//@Contendedvolatile long x;//避免伪共享: 缓存行填充//long p1, p2, p3, p4, p5, p6, p7;volatile long y;
}
方案3: 使用线程的本地内存,比如ThreadLocal
2.高性能内存队列Disruptor详解
2.1 juc包下阻塞队列的缺陷
1) juc下的队列大部分采用加ReentrantLock锁方式保证线程安全。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列。
2)加锁的方式通常会严重影响性能。线程会因为竞争不到锁而被挂起,等待其他线程释放锁而唤醒,这个过程存在很大的开销,而且存在死锁的隐患。
3) 有界队列通常采用数组实现。但是采用数组实现又会引发另外一个问题false sharing(伪共享)。
2.2 Disruptor介绍
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
目前,包括Apache Storm、Camel、Log4j2在内的很多知名项目都应用了Disruptor以获取高性能。
Github:https://github.com/LMAX-Exchange/disruptor
Disruptor实现了队列的功能并且是一个有界队列,可以用于生产者-消费者模型。
2.3 Disruptor的高性能设计方案
Disruptor通过以下设计来解决队列速度慢的问题:
- 环形数组结构
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好(空间局部性原理)。 - 元素位置定位
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。 - 无锁设计
每个生产者或者消费者线程,会通过先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。整个过程通过原子变量CAS,保证操作的线程安全。 - 利用缓存行填充解决了伪共享的问题
- 实现了基于事件驱动的生产者消费者模型(观察者模式)
消费者时刻关注着队列里有没有消息,一旦有新消息产生,消费者线程就会立刻把它消费
RingBuffer数据结构
使用RingBuffer来作为队列的数据结构,RingBuffer就是一个可自定义大小的环形数组。除数组外还有一个序列号(sequence),用以指向下一个可用的元素,供生产者与消费者使用。原理图如下所示:
- Disruptor要求设置数组长度为2的n次幂。在知道索引(index)下标的情况下,存与取数组上的元素时间复杂度只有O(1),而这个index我们可以通过序列号与数组的长度取模来计算得出,index=sequence % entries.length。也可以用位运算来计算效率更高,此时array.length必须是2的幂次方,index=sequece&(entries.length-1)
- 当所有位置都放满了,再放下一个时,就会把0号位置覆盖掉
思考:覆盖数据是否会导致数据丢失呢?
等待策略
| 名称 | 措施 | 适用场景 |
|---|---|---|
| BlockingWaitStrategy | 加锁 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| BusySpinWaitStrategy | 自旋 | 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定义策略 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| SleepingWaitStrategy | 自旋 + yield + sleep | 性能和CPU资源之间有很好的折中。延迟不均匀 |
| TimeoutBlockingWaitStrategy | 加锁,有超时限制 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| YieldingWaitStrategy | 自旋 + yield + 自旋 | 性能和CPU资源之间有很好的折中。延迟比较均匀 |
Disruptor在日志框架中的应用
Log4j 2相对于Log4j 1最大的优势在于多线程并发场景下性能更优。该特性源自于Log4j 2的异步模式采用了Disruptor来处理。 在Log4j 2的配置文件中可以配置WaitStrategy,默认是Timeout策略。

loggers all async采用的是Disruptor,而Async Appender采用的是ArrayBlockingQueue队列。
由图可见,单线程情况下,loggers all async与Async Appender吞吐量相差不大,但是在64个线程的时候,loggers all async的吞吐量比Async Appender增加了12倍,是Sync模式的68倍。
2.4 Disruptor实战
引入依赖
<!-- disruptor -->
<dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.3.4</version>
</dependency>
Disruptor构造器
public Disruptor(final EventFactory<T> eventFactory,final int ringBufferSize,final ThreadFactory threadFactory,final ProducerType producerType,final WaitStrategy waitStrategy)
- EventFactory:创建事件(任务)的工厂类。
- ringBufferSize:容器的长度。
- ThreadFactory :用于创建执行任务的线程。
- ProductType:生产者类型:单生产者、多生产者。
- WaitStrategy:等待策略。
使用流程:
1)构建消息载体(事件)
2) 构建生产者
3)构建消费者
4) 生产消息,消费消息的测试
单生产者单消费者模式
1)创建Event(消息载体/事件)和EventFactory(事件工厂)
创建 OrderEvent 类,这个类将会被放入环形队列中作为消息内容。创建OrderEventFactory类,用于创建OrderEvent事件
@Data
public class OrderEvent {private long value;private String name;
}public class OrderEventFactory implements EventFactory<OrderEvent> {@Overridepublic OrderEvent newInstance() {return new OrderEvent();}
}
2) 创建消息(事件)生产者
创建 OrderEventProducer 类,它将作为生产者使用
public class OrderEventProducer {//事件队列private RingBuffer<OrderEvent> ringBuffer;public OrderEventProducer(RingBuffer<OrderEvent> ringBuffer) {this.ringBuffer = ringBuffer;}public void onData(long value,String name) {// 获取事件队列 的下一个槽long sequence = ringBuffer.next();try {//获取消息(事件)OrderEvent orderEvent = ringBuffer.get(sequence);// 写入消息数据orderEvent.setValue(value);orderEvent.setName(name);} catch (Exception e) {// TODO 异常处理e.printStackTrace();} finally {System.out.println("生产者发送数据value:"+value+",name:"+name);//发布事件ringBuffer.publish(sequence);}}
}
3)创建消费者
创建 OrderEventHandler 类,并实现 EventHandler ,作为消费者。
public class OrderEventHandler implements EventHandler<OrderEvent> {@Overridepublic void onEvent(OrderEvent event, long sequence, boolean endOfBatch) throws Exception {// TODO 消费逻辑System.out.println("消费者获取数据value:"+ event.getValue()+",name:"+event.getName());}
}
4) 测试
public class DisruptorDemo {public static void main(String[] args) throws Exception {//创建disruptorDisruptor<OrderEvent> disruptor = new Disruptor<>(new OrderEventFactory(),1024 * 1024,Executors.defaultThreadFactory(),ProducerType.SINGLE, //单生产者new YieldingWaitStrategy() //等待策略);//设置消费者用于处理RingBuffer的事件disruptor.handleEventsWith(new OrderEventHandler());disruptor.start();//创建ringbuffer容器RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();//创建生产者OrderEventProducer eventProducer = new OrderEventProducer(ringBuffer);//发送消息for(int i=0;i<100;i++){eventProducer.onData(i,"Fox"+i);}disruptor.shutdown();}
}
单生产者多消费者模式
如果消费者是多个,只需要在调用 handleEventsWith 方法时将多个消费者传递进去。
//设置多消费者,消息会被重复消费
disruptor.handleEventsWith(new OrderEventHandler(), new OrderEventHandler());
上面传入的两个消费者会重复消费每一条消息,如果想实现一条消息在有多个消费者的情况下,只会被一个消费者消费,那么需要调用 handleEventsWithWorkerPool 方法。
//设置多消费者,消费者要实现WorkHandler接口,一条消息只会被一个消费者消费
disruptor.handleEventsWithWorkerPool(new OrderEventHandler(), new OrderEventHandler());
注意:消费者要实现WorkHandler接口
public class OrderEventHandler implements EventHandler<OrderEvent>, WorkHandler<OrderEvent> {@Overridepublic void onEvent(OrderEvent event, long sequence, boolean endOfBatch) throws Exception {// TODO 消费逻辑System.out.println("消费者"+ Thread.currentThread().getName()+"获取数据value:"+ event.getValue()+",name:"+event.getName());}@Overridepublic void onEvent(OrderEvent event) throws Exception {// TODO 消费逻辑System.out.println("消费者"+ Thread.currentThread().getName()+"获取数据value:"+ event.getValue()+",name:"+event.getName());}
}
多生产者多消费者模式
在实际开发中,多个生产者发送消息,多个消费者处理消息才是常态。
public class DisruptorDemo2 {public static void main(String[] args) throws Exception {//创建disruptorDisruptor<OrderEvent> disruptor = new Disruptor<>(new OrderEventFactory(),1024 * 1024,Executors.defaultThreadFactory(),ProducerType.MULTI, //多生产者new YieldingWaitStrategy() //等待策略);//设置消费者用于处理RingBuffer的事件//disruptor.handleEventsWith(new OrderEventHandler());//设置多消费者,消息会被重复消费//disruptor.handleEventsWith(new OrderEventHandler(),new OrderEventHandler());//设置多消费者,消费者要实现WorkHandler接口,一条消息只会被一个消费者消费disruptor.handleEventsWithWorkerPool(new OrderEventHandler(), new OrderEventHandler());//启动disruptordisruptor.start();//创建ringbuffer容器RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();new Thread(()->{//创建生产者OrderEventProducer eventProducer = new OrderEventProducer(ringBuffer);// 发送消息for(int i=0;i<100;i++){eventProducer.onData(i,"Fox"+i);}},"producer1").start();new Thread(()->{//创建生产者OrderEventProducer eventProducer = new OrderEventProducer(ringBuffer);// 发送消息for(int i=0;i<100;i++){eventProducer.onData(i,"monkey"+i);}},"producer2").start();//disruptor.shutdown();}
}
相关文章:
17、CPU缓存架构详解高性能内存队列Disruptor实战
1.CPU缓存架构详解 1.1 CPU高速缓存概念 CPU缓存即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。CPU高速缓存可以分为一级缓存,二级缓存,部分高端CPU还具有三级缓存,每一级缓存中所储存的全部数据都是…...

算法训练营打卡Day18
目录 二叉搜索树的最小绝对差二叉搜索树中的众数二叉树的最近公共祖先额外练手题目 题目1、二叉搜索树的最小绝对差 力扣题目链接(opens new window) 给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。 示例: 思…...

【leetcode】169.多数元素
boyer-moore算法最简单理解方法: 假设你在投票选人 如果你和候选人(利益)相同,你就会给他投一票(count1),如果不同,你就会踩他一下(count-1)当候选人票数为0&…...

MyBatis<foreach>标签的用法与实践
foreach标签简介 实践 demo1 简单的一个批量更新,这里传入了一个List类型的集合作为参数,拼接到 in 的后面 ,来实现一个简单的批量更新 <update id"updateVislxble" parameterType"java.util.List">update model…...

R语言Shiny包新手教程
R语言Shiny包新手教程 1. 简介 Shiny 是一个 R 包,用于创建交互式网页应用。它非常适合展示数据分析结果和可视化效果。 2. 环境准备 安装R和RStudio 确保你的计算机上安装了 R 和 RStudio。你可以从 CRAN 下载 R,或从 RStudio 官网 下载 RStudio。…...

[大象快讯]:PostgreSQL 17 重磅发布!
家人们,数据库界的大新闻来了!📣 PostgreSQL 17 正式发布,全球开发者社区的心血结晶,带来了一系列令人兴奋的新特性和性能提升。 发版通告全文如下 PostgreSQL 全球开发小组今天(2024-09-26)宣布…...

CHI trans--Home节点发起的操作
总目录: CHI协议简读汇总-CSDN博客https://blog.csdn.net/zhangshangjie1/article/details/131877216 Home节点能够发起的操作,包含如下几类: Home to Subordinate Read transactionsHome to Subordinate Write transactionsHome to Subor…...

Rust和Go谁会更胜一筹
在国内,我认为Go语言会成为未来的主流,因为国内程序员号称码农,比较适合搬砖,而Rust对心智要求太高了,不适合搬砖。 就个人经验来看,Go语言简单,下限低,没有什么心智成本,…...

记HttpURLConnection下载图片
目录 一、示例代码1 二、示例代码2 一、示例代码1 import java.io.*; import java.net.HttpURLConnection; import java.net.URL;public class Test {/*** 下载图片*/public void getNetImg() {InputStream inStream null;FileOutputStream fOutStream null;try {// URL 统…...
物联网实训室建设的必要性
物联网实训室建设的必要性 一、物联网发展的背景 物联网(IoT)是指通过信息传感设备,按照约定的协议,将任何物品与互联网连接起来,进行信息交换和通信,以实现智能化识别、定位、跟踪、监控和管理的一种网络…...

初识C语言(四)
目录 前言 十一、常见关键字(补充) (1)register —寄存器 (2)typedef类型重命名 (3)static静态的 1、修饰局部变量 2、修饰全局变量 3、修饰函数 十二、#define定义常量和宏…...
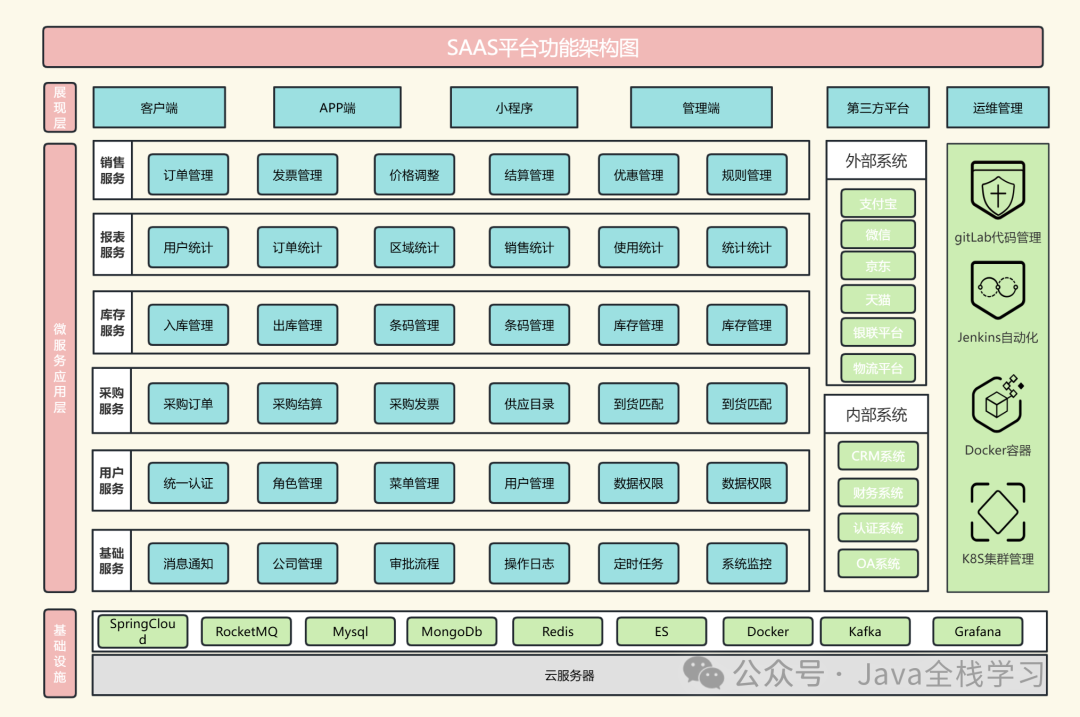
产品架构图:从概念到实践
在当今快速发展的科技时代,产品架构图已成为产品经理和设计师不可或缺的工具。它不仅帮助我们理解复杂的产品体系,还能指导我们进行有效的产品设计和开发。本文将深入探讨产品架构图的概念、重要性以及绘制方法。 整个内容框架分为三个部分,…...

smartctl 命令:查看硬盘健康状态
一、命令简介 smartctl 命令用于获取硬盘的 SMART 信息。 介绍硬盘SMART 硬盘的 SMART (Self-Monitoring, Analysis, and Reporting Technology) 技术用于监控硬盘的健康状态,并能提供一些潜在故障的预警信息。通过查看 SMART 数据,用户可以了解硬…...

BBR 为什么没有替代 CUBIC 成为 Linux 内核缺省算法
自 2017 年底 bbr 发布以来,随着媒体的宣讲,各大站点陆续部署 bbr,很多网友不禁问,bbr 这么好,为什么不替代 cubic 成为 linux 的缺省算法。仅仅因为它尚未标准化?这么好的算法又为什么没被标准化ÿ…...

Git忽略规则原理和.gitignore文件不生效的原因和解决办法
在使用Git进行版本控制时,.gitignore文件扮演着至关重要的角色。它允许我们指定哪些文件或目录应该被Git忽略,从而避免将不必要的文件(如日志文件、编译产物等)纳入版本控制中。然而,在实际使用过程中,有时…...

MySQL-数据库设计
1.范式 数据库的范式是⼀组规则。在设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数 据库,这些不同的规范要求被称为不同的范式。 关系数据库有六种范式:第⼀范式(1NF)、第⼆范式(…...

Unity开发绘画板——04.笔刷大小调节
笔刷大小调节 上面的代码中其实我们已经提供了笔刷大小的字段,即brushSize,现在只需要将该字段和界面中的Slider绑定即可,Slider值的范围我们设置为1~20 代码中只需要做如下改动: public Slider brushSizeSlider; //控制笔刷大…...

./mnt/container_run_medium.sh
#!/bin/bash# 清理旧的日志文件 rm -f *.log rm -f nohup.out rm -f cssd.dat# 启动 pwbox_simu 和 MediumBoxBase nohup /mnt/simutools/pwbox_simu /mnt/simutools/pw_box.conf > /dev/null 2>&1 & nohup /mnt/mediumSimu/MediumBoxBase /mnt/mediumSimu/hynn_…...

数学建模研赛总结
目录 前言进度问题四分析问题五分析数模论文经验分享总结 前言 本文为博主数学建模比赛第五天的内容记录,希望所写的一些内容能够对大家有所帮助,不足之处欢迎大家批评指正🤝🤝🤝 进度 今天已经是最后一天了…...

通信工程学习:什么是TCF技术控制设施
TCF(Technical Control Facility):技术控制设施 首先,需要明确的是,通信工程是一门涉及电子科学与技术、信息与通信工程和光学工程学科领域的基础理论、工程设计及系统实现技术的学科。它主要关注通信过程中的信息传输…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...
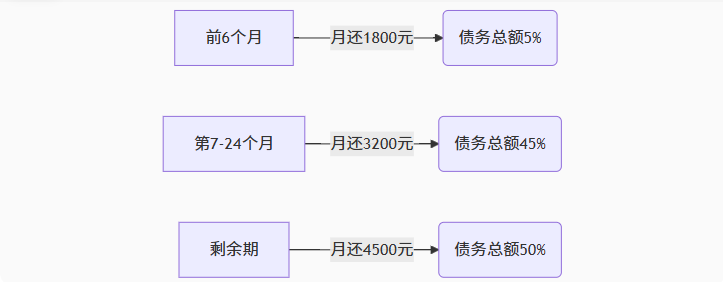
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...

flow_controllers
关键点: 流控制器类型: 同步(Sync):发布操作会阻塞,直到数据被确认发送。异步(Async):发布操作非阻塞,数据发送由后台线程处理。纯同步(PureSync…...