Elasticsearch讲解
1.Elasticsearch基本知识
1.基本认识和安装
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
-
Elasticsearch:用于数据存储、计算和搜索
-
Logstash/Beats:用于数据收集
-
Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等;
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
-
对Elasticsearch数据的搜索、展示
-
对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
-
对Elasticsearch的集群状态监控
-
它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
安装elasticsearch
执行如下代码,并访问9200端口
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network hm-net \-p 9200:9200 \-p 9300:9300 \elasticsearch:7.12.1安装Kibana
执行如下代码,并访问5601端口
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.12.倒排索引
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
缺点:
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引
优点:
-
根据词条搜索、模糊搜索时,速度非常快
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
3.IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
需要将中文分词器挂载到es的数据卷上
官方默认方式
POST /_analyze
{"analyzer": "standard","text": "世界人民大团结万岁"
}IK分词器包含两种模式:
-
ik_smart:智能语义切分 -
ik_max_word:最细粒度切分
POST /_analyze
{"analyzer": "ik_smart","text": "世界人民大团结万岁"
}POST /_analyze
{"analyzer": "ik_max_word","text": "世界人民大团结万岁"
}有些词语字典里面没有,需要自己手动添加,还可以对某些字或词语不进行分词
在config目录下如图三个文件
添加自己的词语和不希望分词的词语即可


4.mysql和es的对比
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |

2.索引库的操作
1.Mapping映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
-
type:字段数据类型,常见的简单类型有:-
字符串:
text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址) -
数值:
long、integer、short、byte、double、float、 -
布尔:
boolean -
日期:
date -
对象:
object
-
-
index:是否创建索引,默认为true -
analyzer:使用哪种分词器 -
properties:该字段的子字段
2.索引库的CRUD
创建索引库
基本语法:
-
请求方式:
PUT -
请求路径:
/索引库名,可以自定义 -
请求参数:
mapping映射
代码如下:
#新增
PUT /pxy
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"age":{"type": "byte"},"email":{"type": "keyword","index": false},"name":{"type": "object","properties": {"firstname":{"type": "keyword"},"lastname":{"type": "keyword","index":false}}}}}
}查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
代码如下:
#查询
GET /pxy修改索引库
无法修改索引库,但是可以添加新的字段
#es不支持修改,但可以添加
PUT /pxy/_mapping
{"properties":{"age":{"type":"byte"}}
}
删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
#删除
DELETE /pxy3.文档的操作
1.文档的CRUD
增加数据
#新增数据
POST /pxy/_doc/1
{"info":"我是大帅哥","age":18,"email":"123456@qq.com","name":{"firstname":"潘","lastname":"xy"}
}查询数据
#查询数据
GET /pxy/_doc/1删除数据
#删除数据
DELETE /pxy/_doc/1修改数据
分为全量修改和局部修改。全量修改是删除原来的数据在新增数据,局部修改只是把原来的数据修改掉。
#修改数据#全量修改
Put /pxy/_doc/1
{"info":"我是大帅哥","age":17,"email":"123456@qq.com","name":{"firstname":"p","lastname":"xy"}
}#局部修改
POST /pxy/_update/1
{"doc": {"info":"无敌是多么寂寞","name":{"firstname":"wd","lastname":"jm"}}
}
2.批量处理
一次处理多个请求
批处理采用POST请求,基本语法如下:
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }其中:
-
index代表新增操作-
_index:指定索引库名 -
_id指定要操作的文档id -
{ "field1" : "value1" }:则是要新增的文档内容
-
-
delete代表删除操作-
_index:指定索引库名 -
_id指定要操作的文档id
-
-
update代表更新操作-
_index:指定索引库名 -
_id指定要操作的文档id -
{ "doc" : {"field2" : "value2"} }:要更新的文档字段
-
批量新增操作
POST /_bulk{"index":{"_index":"pxy","_id":"2"}}{"info":"我是大帅哥","age":17,"email":"123456@qq.com", "name":{"firstname":"p","lastname":"xy"}}{"index":{"_index":"pxy","_id":"3"}}{"info":"我是大帅哥","age":17,"email":"123456@qq.com", "name":{"firstnam:"p","lastname":"xy"}}批量删除操作
POST /_bulk{"delete":{"_index":"pxy","_id":"2"}}{"delete":{"_index":"pxy","_id":"3"}}4.用java程序操作es
1.注册RestHighLevelClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
导入依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1<version>
</dependency>初始化代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.145.129:9200")
));2.对索引进行操作
创建索引
@Testpublic void createindex() throws IOException {//准备request对象CreateIndexRequest request = new CreateIndexRequest("pxy");//准备请求参数request.source(MAPPING_TEMPLATE, XContentType.JSON);//发送请求体client.indices().create(request, RequestOptions.DEFAULT);}private final static String MAPPING_TEMPLATE="{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"stock\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"image\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"category\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"sold\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"commentCount\":{\n" +" \"type\": \"integer\",\n" +" \"index\": false\n" +" },\n" +" \"isAD\":{\n" +" \"type\": \"boolean\"\n" +" },\n" +" \"updateTime\":{\n" +" \"type\": \"date\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
查询索引
@Testpublic void getindex() throws IOException {//准备request对象GetIndexRequest request = new GetIndexRequest("pxy");//发送请求体
// GetIndexResponse response = client.indices().get(request, RequestOptions.DEFAULT);
// System.out.println("返回参数"+response);//判断请求参数是否存在Boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println("exists="+exists);}删除索引
@Testpublic void deleteindex() throws IOException {//准备request对象DeleteIndexRequest request = new DeleteIndexRequest("pxy");//发送请求体client.indices().delete(request, RequestOptions.DEFAULT);}3.对文档进行操作
新增文档
@Test
void testAddDocument() throws IOException {// 1.准备Request对象IndexRequest request = new IndexRequest("pxy").id("1");// 2.准备Json文档request.source({}, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}查询文档
@Test
void testGetDocumentById() throws IOException {// 1.准备Request对象GetRequest request = new GetRequest("pxy").id("1");// 2.发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.获取响应结果中的sourceString json = response.getSourceAsString();System.out.println("json= " + json);
}删除文档
@Test
void testDeleteDocument() throws IOException {// 1.准备Request,两个参数,第一个是索引库名,第二个是文档idDeleteRequest request = new DeleteRequest("pxy", "1");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}修改文档
修改一共两种方式:
-
全量修改:本质是先根据id删除,再新增
-
局部修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
-
如果新增时,ID已经存在,则修改
-
如果新增时,ID不存在,则新增
这里不再赘述,我们主要关注局部修改的API即可。
@Test
void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("pxy", "1");// 2.准备请求参数request.doc("price", 58800,"commentCount", 1);// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}批量处理文档
@Test
void testBulk() throws IOException {// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备请求参数//新增文档request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));//删除文档request.add(new DeleteRequest("items").id("2"));// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}5.DSL查询
1.叶子查询
全文检索查询
全文检索中的match,语法如下:
GET /{索引库名}/_search
{"query": {"match": {"字段名": "搜索条件"}}
}与match类似的还有multi_match,区别在于可以同时对多个字段搜索,而且多个字段都要满足,语法示例:
GET /{索引库名}/_search
{"query": {"multi_match": {"query": "搜索条件","fields": ["字段1", "字段2"]}}
}精确查询
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。因此推荐查找keyword、数值、日期、boolean类型的字段。
term查询其语法如下:
GET /{索引库名}/_search
{"query": {"term": {"字段名": {"value": "搜索条件"}}}
}range查询语法如下:
GET /{索引库名}/_search
{"query": {"range": {"字段名": {"gte": {最小值},"lte": {最大值}}}}
}range是范围查询,对于范围筛选的关键字有:
-
gte:大于等于 -
gt:大于 -
lte:小于等于 -
lt:小于
2.复合查询
复合查询大致可以分为两类:
-
第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
-
bool
-
-
第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
-
function_score
-
dis_max
-
bool查询讲解
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}} #必须是手机],"should": [ #或者小米或者vivo{"term": {"brand": { "value": "vivo" }}},{"term": {"brand": { "value": "小米" }}}],"must_not": [ #不是大于等于2500块的{"range": {"price": {"gte": 2500}}}],"filter": [ #必须是小于等于1000块的{"range": {"price": {"lte": 1000}}}]}}
}3.排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。不过分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"排序字段": {"order": "排序方式asc和desc"}}]
}示例,我们按照商品价格排序:
GET /items/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}}]
}4.分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
基础分页
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
-
from:从第几个文档开始 -
size:总共查询几个文档
类似于mysql中的limit ?, ?
GET /items/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页文档数量,默认10"sort": [{"price": {"order": "desc"}}]
}深度分页
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
针对深度分页,elasticsearch提供了两种解决方案:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。 -
scroll:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
5.高亮
实现高亮的思路就是:
-
用户输入搜索关键字搜索数据
-
服务端根据搜索关键字到elasticsearch搜索,并给搜索结果中的关键字词条添加
html标签 -
前端提前给约定好的
html标签添加CSS样式
GET /{索引库名}/_search
{"query": {"match": {"搜索字段": "搜索关键字"}},"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}}}
}注意:
-
搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match -
参与高亮的字段必须是
text类型的字段 -
默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match=false
6.用java代码实现DSL查询
文档的查询依然使用昨天学习的 RestHighLevelClient对象,查询的基本步骤如下:
-
1)创建
request对象,这次是搜索,所以是SearchRequest -
2)准备请求参数,也就是查询DSL对应的JSON参数
-
3)发起请求
-
4)解析响应,响应结果相对复杂,需要逐层解析
handleResponse函数实现解析返回结果
private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化并打印ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);System.out.println(item);}
}1.叶子查询
match查询:
@Test
void testMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}multi_match查询:
@Test
void testMultiMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}range查询:
@Test
void testRange() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.rangeQuery("price").gte(10000).lte(30000));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}term查询:
@Test
void testTerm() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.termQuery("brand", "华为"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}2.复合查询
复合查询也是由QueryBuilders来构建,以下是bool查询实例
@Test
void testBool() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.准备bool查询BoolQueryBuilder bool = QueryBuilders.boolQuery();// 2.2.关键字搜索bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.3.品牌过滤bool.filter(QueryBuilders.termQuery("brand", "德亚"));// 2.4.价格过滤bool.filter(QueryBuilders.rangeQuery("price").lte(30000));request.source().query(bool);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}3.排序和分页
代码如下:
@Test
void testPageAndSort() throws IOException {int pageNo = 1, pageSize = 5;// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.搜索条件参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.排序参数request.source().sort("price", SortOrder.ASC);// 2.3.分页参数request.source().from((pageNo - 1) * pageSize).size(pageSize);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}4.高亮
高亮查询与前面的查询有两点不同:
-
条件同样是在
request.source()中指定,只不过高亮条件要基于HighlightBuilder来构造 -
高亮响应结果与搜索的文档结果不在一起,需要单独解析
@Test
void testHighlight() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.query条件request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.高亮条件request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);// 5.获取高亮结果Map<String, HighlightField> hfs = hit.getHighlightFields();if (CollUtils.isNotEmpty(hfs)) {// 5.1.有高亮结果,获取name的高亮结果HighlightField hf = hfs.get("name");if (hf != null) {// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值String hfName = hf.getFragments()[0].string();item.setName(hfName);}}System.out.println(item);}
}7.数据聚合
聚合常见的有三类:
-
桶(
Bucket)聚合:用来对文档做分组-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组 -
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(
Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等-
Avg:求平均值 -
Max:求最大值 -
Min:求最小值 -
Stats:同时求max、min、avg、sum等
-
-
管道(
pipeline)聚合:其它聚合的结果为基础做进一步运算
1.DSL实现聚合
Bucket聚合
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
GET /items/_search
{"size": 0, "aggs": {"category_agg": {"terms": {"field": "category","size": 20}}}
}语法说明:
-
size:设置size为0,就是每页查0条,则结果中就不包含文档,只包含聚合 -
aggs:定义聚合-
category_agg:聚合名称,自定义,但不能重复-
terms:聚合的类型,按分类聚合,所以用term-
field:参与聚合的字段名称 -
size:希望返回的聚合结果的最大数量
-
-
-
Metric聚合
Metric聚合,例如stat聚合,就可以同时获取min、max、avg等结果。
GET /items/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}},{"range": {"price": {"gte": 300000}}}]}}, "size": 0, "aggs": {"brand_agg": {"terms": {"field": "brand","size": 20},"aggs": {"stats_meric": {"stats": {"field": "price"}}}}}
}可以看到我们在brand_agg聚合的内部,我们新加了一个aggs参数。这个聚合就是brand_agg的子聚合,会对brand_agg形成的每个桶中的文档分别统计。
-
stats_meric:聚合名称-
stats:聚合类型,stats是metric聚合的一种-
field:聚合字段,这里选择price,统计价格
-
-
由于stats是对brand_agg形成的每个品牌桶内文档分别做统计,因此每个品牌都会统计出自己的价格最小、最大、平均值。
2.用java实现聚合
@Test
void testAgg() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.准备请求参数BoolQueryBuilder bool = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("category", "手机")).filter(QueryBuilders.rangeQuery("price").gte(300000));request.source().query(bool).size(0);// 3.聚合参数request.source().aggregation(AggregationBuilders.terms("brand_agg").field("brand").size(5));// 4.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析聚合结果Aggregations aggregations = response.getAggregations();// 5.1.获取品牌聚合Terms brandTerms = aggregations.get("brand_agg");// 5.2.获取聚合中的桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 5.3.遍历桶内数据for (Terms.Bucket bucket : buckets) {// 5.4.获取桶内keyString brand = bucket.getKeyAsString();System.out.print("brand = " + brand);long count = bucket.getDocCount();System.out.println("; count = " + count);}
}相关文章:
Elasticsearch讲解
1.Elasticsearch基本知识 1.基本认识和安装 Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括: Elasticsearch:用于数据存储、计算和搜索 Logstash/Beats:用于数据收集 Kib…...

Linux嵌入式有发展吗,以及对uboot,kernel,rootfs的领悟
工作多年后,对uboot,kernel,rootfs的领悟,总结 上大学时,51单片机,正点原子的stm32,linux arm开发。对uboot,kernel,rootfs的理解云里雾里,感觉自己很懂了 其…...

基于Springboot+Vue的公寓管理系统(含源码+数据库)
1.开发环境 开发系统:Windows10/11 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql5.7或8.0 数据库可视化工具: navicat 服务器: SpringBoot自带 apache tomcat 主要技术: Java,Springboot,mybatis,mysql,vue 2.视频演示地址 3.功能 该系统…...

多功能声学气膜馆:承载梦想与希望的舞台—轻空间
在9月29日上午,苏州大学应用技术学院的2024级新生开学典礼暨开学第一课在轻空间建造的多功能声学气膜馆内盛大举行。这一盛典不仅见证了2849名新生的入学,也展示了气膜馆的独特魅力与优越功能。 卓越的声学表现 声学气膜馆采用高性能材料,确保…...

【线程】线程池
线程池通过一个线程安全的阻塞任务队列加上一个或一个以上的线程实现,线程池中的线程可以从阻塞队列中获取任务进行任务处理,当线程都处于繁忙状态时可以将任务加入阻塞队列中,等到其它的线程空闲后进行处理。 线程池作用: 1.降…...

输出 / 目录下所有目录文件的大小并排序
使用 du -sh /* 输出 / 目录下所有的目录总大小,看下效果: [rootlocalhost ~]# du -sh /* 0 /bin 110M /boot 0 /dev 32M /etc 12K /home 0 /lib 0 /lib64 0 /media 0 /mnt 0 /opt du: cannot access ‘/proc/2731/task/2731/fd/4’: No such file or …...

【hot100-java】【编辑距离】
多维dp篇 class Solution {public int minDistance(String word1, String word2) {char [] sword1.toCharArray();char [] tword2.toCharArray();int ns.length;int mt.length;int [][] fnew int[n1][m1];for (int j1;j<m;j){f[0][j]j;}for(int i0;i<n;i){f[i1][0]i1;for…...

随手记:牛回速归
上周-国庆前:牛回速归 国庆:小心被套住 国庆后:一片迷茫 总结:要是上周到国庆前的基本都能捞到,后面情况不好说 后续持续更新...

UI设计师面试整理-设计过程和方法论
在UI设计师面试中,清晰地阐述你的设计过程和方法论是至关重要的。这不仅可以展示你的专业技能和设计思维,也能让面试官看到你是如何解决实际设计问题的。以下是一个全面的UI设计过程和常用方法论的概述,你可以根据你的经验进行相应调整。 1. 设计过程 a. 研究与发现阶段(Re…...

ACM 纳新每日一题 4329: 三进制
首先我们要学习的是数制转化 这里我找了一篇博客https://blog.csdn.net/weixin_53564801/article/details/123665194 一定要注意0需要单独特判一下,这个点尤其重要 然后关于这道题可以使用递归来实现,如下: 递归的代码比较简洁,但…...
WebGIS包括哪些技术栈?怎么学习?
WebGIS,其实是利用Web开发技术结合地理信息系统(GIS)的产物,它是一种通过Internet实现GIS交互操作和服务的最佳途径。 WebGIS通过图形化界面直观地呈现地理信息和特定数据,具有可扩展性和跨平台性。 它提供交互性&am…...

无人机之集群控制及应用
一、无人机集群控制 无人机集群控制是指通过先进的通信、导航和控制算法,实现多架无人机之间的协同、协调和高效的任务执行。其关键技术包括: 通信技术:实现无人机之间的实时数据传输和共享,确保集群控制的准确性和稳定性。 路径…...

AV1 Bitstream Decoding Process Specification--[9]:语法结构语义-5
原文地址:https://aomediacodec.github.io/av1-spec/av1-spec.pdf 没有梯子的下载地址:AV1 Bitstream & Decoding Process Specification摘要:这份文档定义了开放媒体联盟(Alliance for Open Media)AV1视频编解码…...
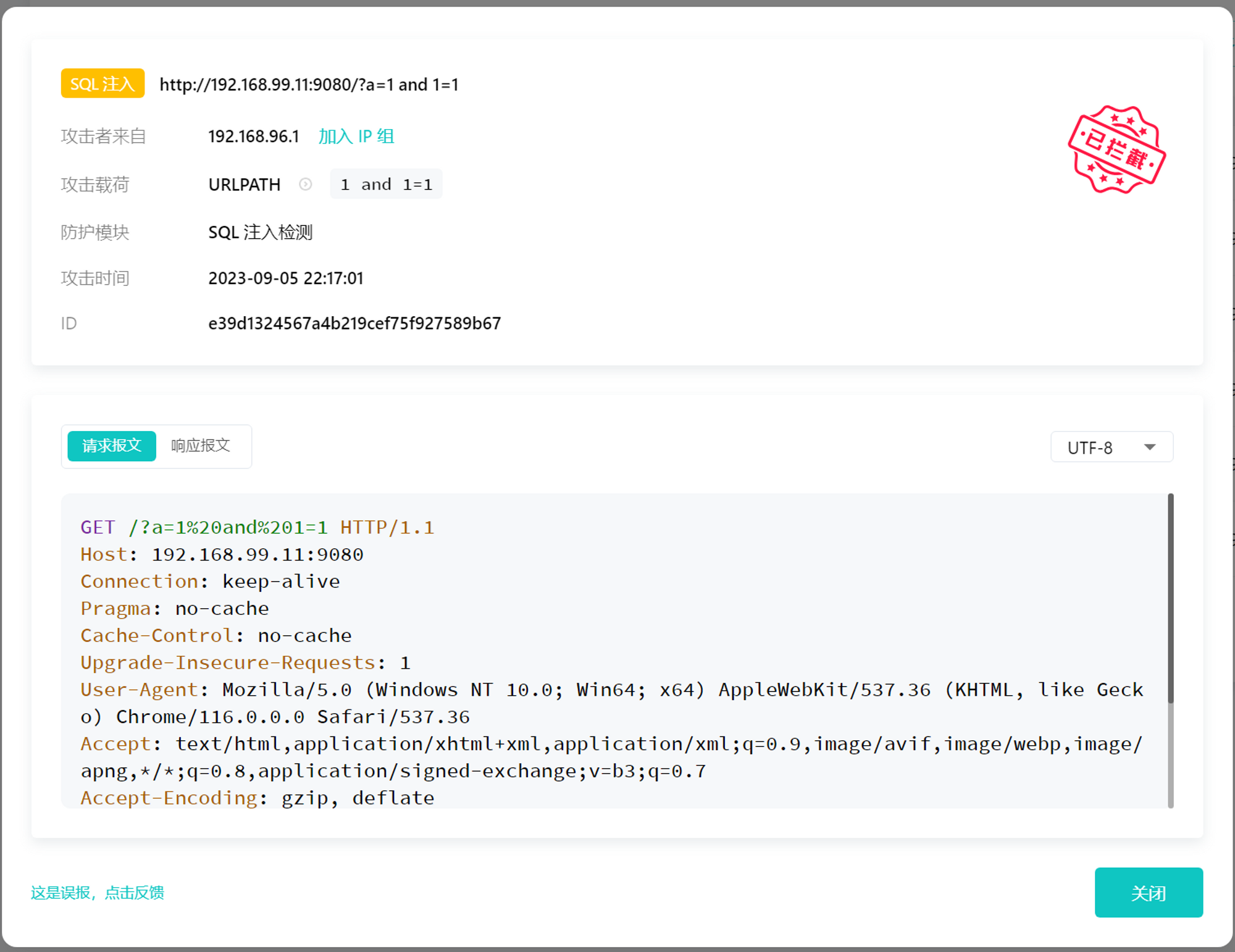
APISIX 联动雷池 WAF 实现 Web 安全防护
Apache APISIX 是一个动态、实时、高性能的云原生 API 网关,提供了负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。 雷池是由长亭科技开发的 WAF 系统,提供对 HTTP 请求的安全请求,提供完整的 API 管理和…...

音频剪辑还能在线做?以前的我真是OUT了,效果秒杀专业软件
以前,剪辑音频都得靠那些专业的音频师,用很贵的设备和复杂的软件才行。不过,现在有了互联网和云计算,在线音频剪辑变得简单多了。只要你有台能上网的电脑或者手机,就能轻松做出很棒的音频。这个变化让更多人都能玩音频…...

Library介绍(三)
环境描述 工作条件 一般lib文件里面包含了芯片的工作条件即operation conditions,其指定了工艺(process)、温度(temperature)和电压(voltage),见图1。 其中,process代表了…...

VMware搭建DVWA靶场
目录 1.安装phpstudy 2.搭建DVWA 本次搭建基于VMware16的win7系统 1.安装phpstudy 下载windows版本:小皮面板-好用、安全、稳定的Linux服务器面板! 安装后先开启mysql再开启apache,遇到mysql启动不了的情况,最后重装了phpstud…...
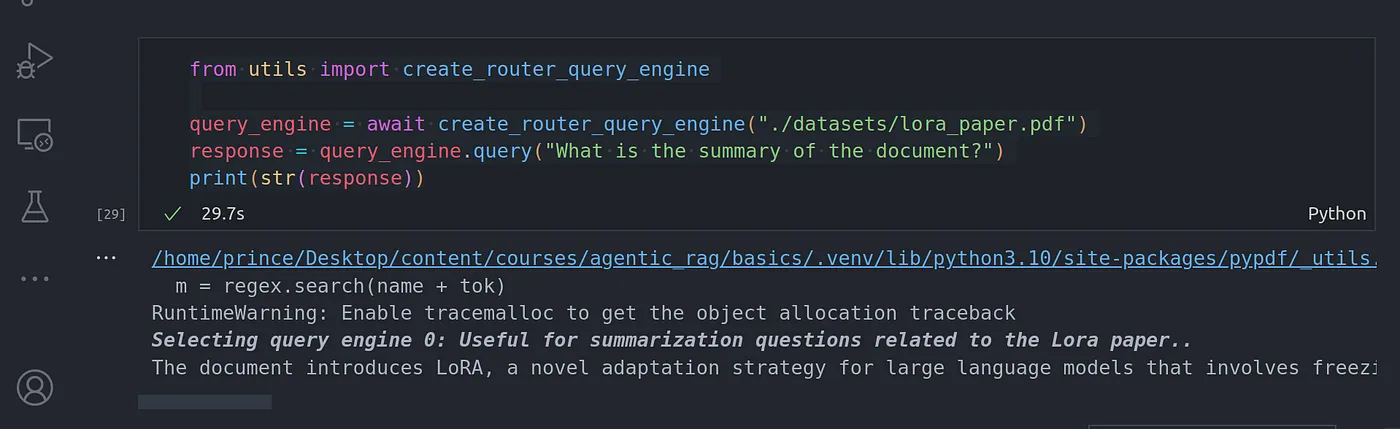
使用 Llama-index 实现的 Agentic RAG-Router Query Engine
前言 你是否也厌倦了我在博文中经常提到的老式 RAG(Retrieval Augmented Generation | 检索增强生成) 系统?反正我是对此感到厌倦了。但我们可以做一些有趣的事情,让它更上一层楼。接下来就跟我一起将 agents 概念引入传统的 RAG 工作流,重新…...

一行命令将Cmder添加到系统右键菜单中----配置环境
第一步,去官网下载一个简版的文件 ** 第二步,将下载的文件解压后如图,找到Cmder.exe右键以管理员身份运行 第三步,在窗口输入cmder /register all然后回车 第四步,OK!不管在哪里都可以使用了,直接右键即可...

【系统架构设计师】专题:基于构件的软件工程考点
更多内容请见: 备考系统架构设计师-核心总结目录 文章目录 一、构件概述二、构件模型三、CBSE的特征四、CBSE的过程五、构件组装一、构件概述 基于构件的软件工程(Component-Based Software Engineering,CBSE) 是一种基于分布对象技术、 强调通过可复用构件设计与构造软件系…...

5个强力步骤实现旧Mac升级:开源工具OpenCore Legacy Patcher全攻略
5个强力步骤实现旧Mac升级:开源工具OpenCore Legacy Patcher全攻略 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当你的Mac提示"此Mac不支…...

别再只会‘永不在此停止’了!实战绕过网站JS混淆与内存爆破的三种硬核方法
实战突破:三种硬核方法破解JS混淆与内存爆破 打开开发者工具的那一刻,页面突然卡死,控制台不断弹出debugger断点——这可能是每个爬虫工程师都经历过的噩梦。当简单的"永不在此停止"失效时,我们需要更高级的技术手段来应…...

SDMatte算法原理浅析:从卷积神经网络看图像分割技术
SDMatte算法原理浅析:从卷积神经网络看图像分割技术 1. 效果展示:当AI学会"精准抠图" 先来看一组实际案例。左边是原始图片,右边是SDMatte算法的处理结果: 你会注意到,即便是复杂场景下的发丝、半透明物体…...

忍者像素绘卷基础教程:3步完成‘火之意志’提示词→像素绘卷生成
忍者像素绘卷基础教程:3步完成火之意志提示词→像素绘卷生成 1. 认识忍者像素绘卷 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工具,它将传统忍者文化与16-Bit复古游戏美学完美结合。不同于常见的暗色调像素艺术,这款工具采用了…...

机器学习周报三十九
文章目录摘要Abstract1.TurboDiffusion1.1 注意力改进1.2蒸馏模型1.3权重量化2 训练和推理2.1 训练阶段2.2 推理阶段3 Make It Count3.1数据集3.2损失函数总结摘要 本周阅读了清华大学的论文《TurboDiffusion: Accelerating Video Diffusion Models by 100–200 Times》&#…...

Phi-4-mini-reasoning应用场景:技术文档自动逻辑校验与漏洞推理辅助工具
Phi-4-mini-reasoning应用场景:技术文档自动逻辑校验与漏洞推理辅助工具 1. 模型概述 Phi-4-mini-reasoning是一款由微软开发的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。该模型以"小参数、强推理、长上下文、低…...
)
别再被网站当机器人了!手把手教你编译一个‘隐身版’Chromedriver(绕过Selenium检测)
从源码到隐身:深度定制Chromedriver绕过检测的工程实践 当你的Selenium脚本突然被目标网站拦截,熟悉的"Access Denied"页面赫然出现时,那种挫败感每个爬虫开发者都深有体会。网站的反爬系统越来越智能,常规的UserAgent轮…...

15K Star 爆火!用大厂 PUA 话术逼 AI 干活,Claude 效率翻倍的黑色幽默工具
用大厂 PUA 话术逼 AI 干活:一个 15K Star 的黑色幽默项目如何让 Claude 效率翻倍 最近 GitHub 上火了个名字叫"PUA"的开源项目,短短几周从 0 到 15K Stars,还被各大科技媒体争相报道。 看名字的时候我以为又是哪位网友的整活之作…...

SpringBoot + 本地事务表 + 定时扫描补偿:轻量级方案实现最终一致性,无中间件依赖
在分布式系统中,数据一致性是一个永恒的话题。传统的分布式事务解决方案如 Seata、XA 等往往需要引入重量级中间件,增加了系统复杂度和运维成本。 本文将介绍一种轻量级的最终一致性方案——本地事务表 + 定时扫描补偿,该方案: 零中间件依赖:不需要 MQ、Seata 等外部组件…...

OpenMMLab 环境配置实战:从 YOLO 项目报错到模块化开发的避坑指南
1. 从YOLO项目报错说起:OpenMMLab环境配置的典型痛点 最近在复现一个基于YOLOv5改进的OpenMMLab项目时,遇到了让人头疼的ModuleNotFoundError: No module named mmdet报错。这个场景太典型了——明明项目目录里清清楚楚躺着mmdet文件夹,Pytho…...