使用 Llama-index 实现的 Agentic RAG-Router Query Engine
前言
你是否也厌倦了我在博文中经常提到的老式 RAG(Retrieval Augmented Generation | 检索增强生成) 系统?反正我是对此感到厌倦了。但我们可以做一些有趣的事情,让它更上一层楼。接下来就跟我一起将 agents 概念引入传统的 RAG 工作流,重新构建自己的 Agentic RAG 系统吧。
去年大模型领域最流行的关键词就是 RAG 了,而今年,一代新人换旧人,agents 已经取代 RAG 成为大模型领域的新宠。你大可不必为错过 RAG 的风口而沮丧,因为将 agents 引入 RAG 系统后会有更好的效果,所以现在开始学习也不晚。
在本文中,我会介绍如何使用 Llama-index 实现基本的 Agentic RAG 应用。我将在接下来的几周发布一系列(共四篇)有关 Agentic RAG 架构的文章,本文是这个系列的第一篇。
RAG 基础工作流
在开始新篇章前,让我们快速回顾一下传统的 RAG 架构的组织形式和工作原理。这部分知识在后续过程也会用到,那些对 RAG 没有任何经验的初学者务必仔细学习。
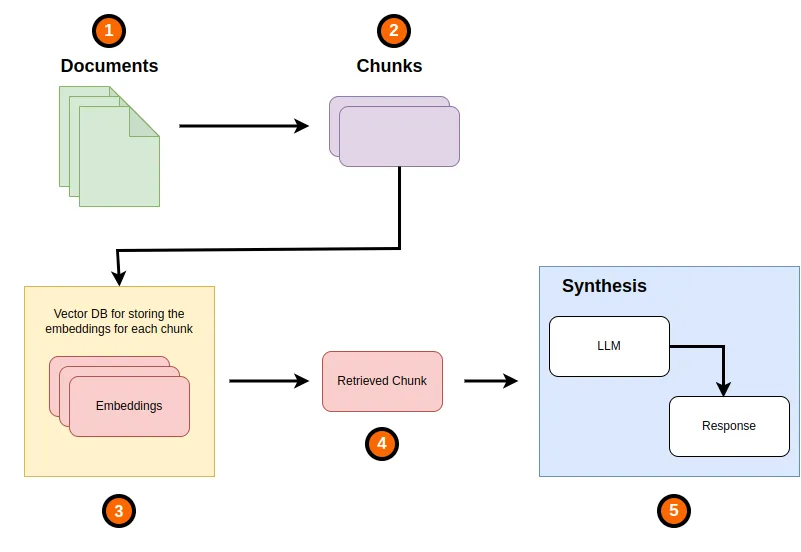
传统的 RAG 架构的组织形式和工作原理
在上面简单的 RAG 架构图中,我们至少需要理解以下概念:
- 文档(Documents):用于增强 LLM 理解特定领域的上下文。可以是 PDF 或者任何文本文档,对于多模态的 LLM 来说甚至可以是图片;
- 块(Chunks)/ 节点(nodes):将较大的文档通过合适的算法分割成尺寸合适的块(或节点);
- 特征映射(Embedings):在将文档分割成块后,我们需要为每个块创建与之对应的特征映射(一般以向量的形式存储)。当系统收到来自用户的查询时,RAG 系统会通过相似性搜索找到与查询内容相关性最高的文档块。这些被检索出来的文档块会与用户查询内容一起发送给 LLM,检索出来的文档块会充当此次 LLM 调用的上下文。最终,LLM 会根据以上内容生成响应。
以上就是典型的传统 RAG 系统的组织形式和工作原理。
为什么要创建 Agentic RAG
通过上一章节我们了解了传统 RAG 的实现,这种实现方案适用于少量文档的简单 QA 任务,不适合复杂的 QA 任务和对较大文档集的总结。
而这恰好是 agents 的强势领域,将 agents 与 RAG 结合能够将传统 RAG 系统提升到一个全新的水平。通过 Agentic RAG 系统,可以轻松地执行更复杂的任务,例如文档集摘要、复杂 QA 以及其他复杂任务。Agentic RAG 还能使 RAG 系统具有工具调用的能力,并且这些工具可以是自定义函数。
在本系列文章中我将讨论以下内容:
- 路由式查询引擎(Router Query Engines):这是最简单的 Agentic RAG 实现方式,它提供了添加逻辑声明的能力。这种能力可以帮助 LLM 根据需要执行的任务以及提供的工具确定通过何种路径能够达到最终目的;
- 工具调用(Tool Calling):在这篇文章中,我将介绍如何将自己定义的工具(方法)添加到 Agentic RAG 架构中。我会为 agents 实现一些接口,以便从我们提供的工具中选择合适的工具并通过 LLM 生成调用这些工具(这里我们默认工具是自定义的 Python 函数)所需要的参数;
- 具有多步推理能力的 Agentic RAG;
- 在文档集中具有多步推理能力的 Agentic RAG。
路由式查询引擎 | Router Query Engine
这是 Llama-index 中最简单的 Agentic RAG 实现方案。在这种方案中,我们只需要创建一个路由式查询引擎。它能够在 LLM 帮助下,(从提供的工具和查询引擎列表中)确定具体使用什么工具或查询引擎来解决用户查询的。
下图是本文要实现的路由式查询引擎的基本结构:
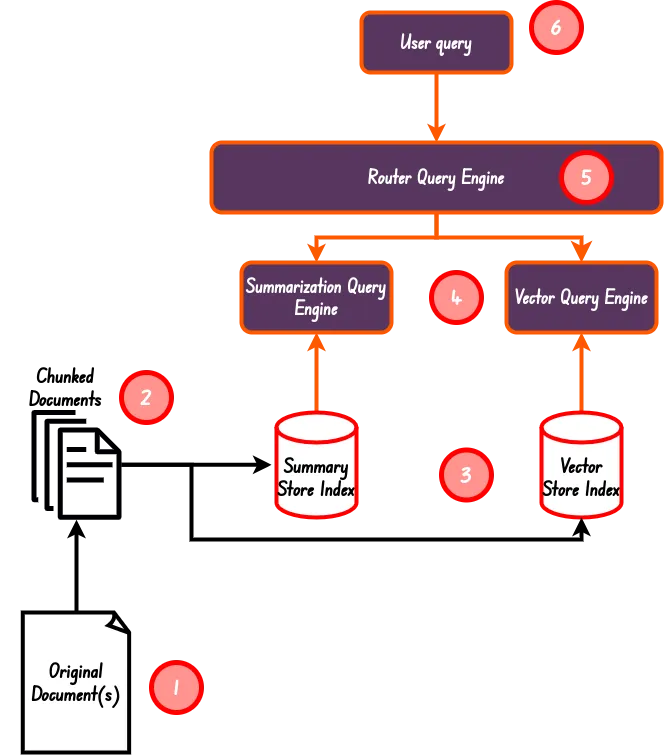
本文要实现的路由式查询引擎的基本结构
项目环境初始化
创建一个名为 agentic_rag 的目录作为本系列文章的项目目录,再在 agentic_rag 内部创建一个名为 basics 的目录作为本文代码实践的工作目录。创建完成后进入 basics 目录中进行环境初始化:
代码语言:javascript
复制
# /root/to/agentic_rag/basics
poetry init在正式开始前,你需要先准备好你的 OpenAI API 密钥,如果你还没有密钥,可以从 此处 获取。准备好密钥后,将其添加到你的 .env 文件中:
代码语言:javascript
复制
# /root/to/agentic_rag/basics/.env
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx译者注:也可以使用其他平台的 LLM 接口,你可以在 此链接 下确认 Llama-index 是否支持你期望的平台。
译者注:如果没有能力购买平台提供的 LLM 能力,也可以使用 Ollama 在本地运行指定模型,并参考 文档 在 Llama-index 中调用模型能力。
译者注:如果使用了不同平台的接口需要将后文中提到的 OpenAI 相关的接口替换成你所使用的平台的接口。

代码截图-1
代码截图-2
安装依赖
我们会在本项目中使用到 Llama-index 以及一些其他的依赖库,你可以通过如下命令进行安装:
代码语言:javascript
复制
# /root/to/agentic_rag/basics
poetry add python-dotenv ipykernel llama-index nest_asyncio下载数据集
我们需要一个 PDF 文件用于后续代码实践,你可以点击 此链接 下载我所使用的 PDF。当然你也可以使用你手中的任何一个 PDF 文件(译者注:对于初学者来说最好是一个纯文本的 PDF 文件)。将它保存到 /path/to/agentic_rag/basic/datasets 目录下。
代码截图-3
加载文档并将其处理成块
译者注:原文作者是使用 .ipynb 格式来编写并运行代码的,如果你不熟悉这个文件格式可以使用正常的 .py 文件。
现在我们已经将代码运行的基础环境准备好了,然我们先通过 python-dotenv 库加载环境变量:
代码语言:javascript
复制
import dotenv
%load_ext dotenv
%dotenv随后我们需要引入 nest_asyncio 库,因为 Llama-index 在后台使用大量 asyncio 功能:
代码语言:javascript
复制
import nest_asyncio
nest_asyncio.apply()现在,然我们加载准备好的 PDF 文档:
代码语言:javascript
复制
from llama_index.core import SimpleDirectoryReader # load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=["./datasets/lora_paper.pdf"]).load_data()创建文档块
成功加载文档后,我们需要将其分解成合适大小的块:
代码语言:javascript
复制
from llama_index.core.node_parser import SentenceSplitter # chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)可以使用以下方法获取有关每个块的详细信息:
代码语言:javascript
复制
node_metadata = nodes[1].get_content(metadata_mode=True)
print(node_metadata)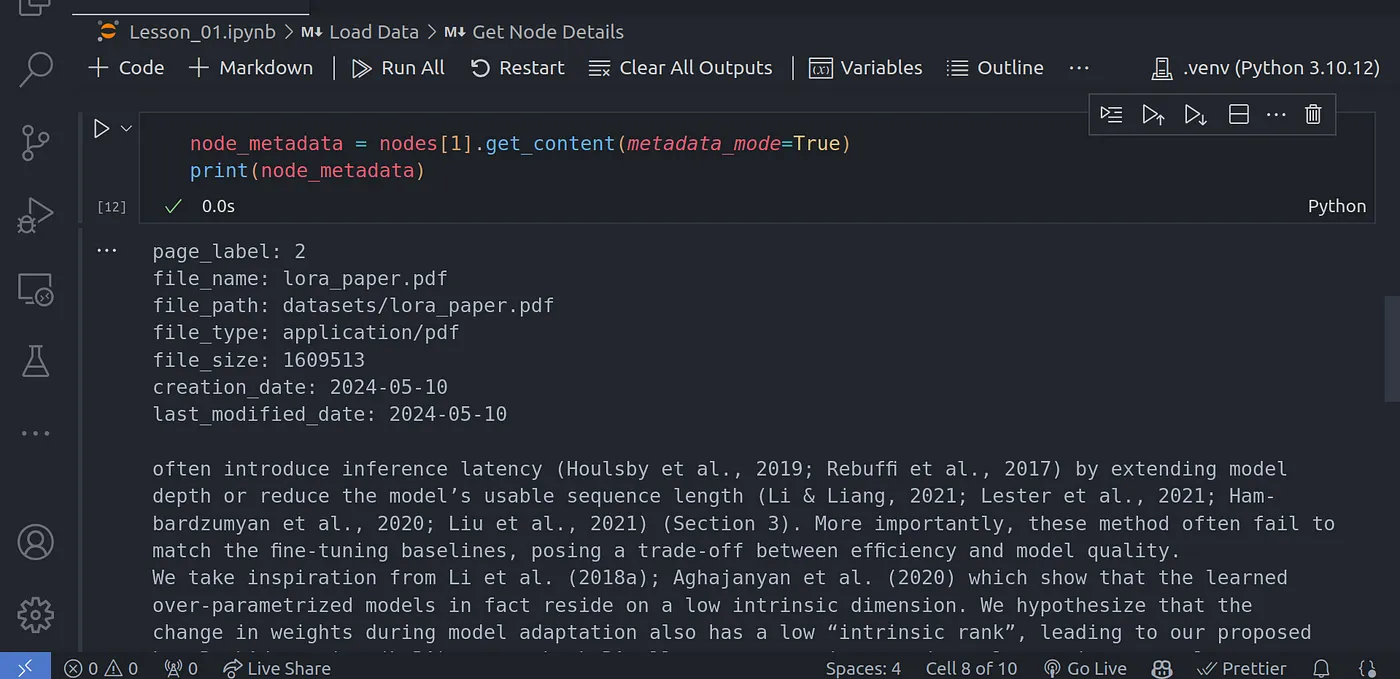
代码截图-4
创建所需的 LLM 和 Embedding 模型对象
译者注:这里你需要将用到的模型类替换为你所使用的平台所对应的类,有些类需要添加额外的第三方依赖,详情请查看 Llama-index 文档。
在本次代码实践中,我将使用 OpenAI 的 gpt-3.5-turbo 模型作为 LLM 模型,使用 OpenAI 的 text-embedding-ada-002 模型作为 Embedding 模型。
代码语言:javascript
复制
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding # LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")创建索引
正如前文基本结构图片所示,在本次代码实践中,我们将使用两个主要的索引:
- 摘要索引(Summary Index):根据 Llama-index 对应文档 所示,摘要索引是一种简单的数据结构,其中节点按顺序存储。在索引构建过程中,文档文本被分块、转换为节点并存储在列表中。在查询期间,摘要索引使用一些可选的过滤器参数迭代节点,并综合所有节点的答案。
- 向量索引(Vector Index):一个通过 Embedding 创建的常规索引存储,可以执行相似性搜索,以获得与搜索条件最相似的
n个的索引。
可以使用下面的代码来创建这两个索引:
代码语言:javascript
复制
from llama_index.core import SummaryIndex, VectorStoreIndex # summary index
summary_index = SummaryIndex(nodes)
# vector store index
vector_index = VectorStoreIndex(nodes)将向量索引转换为查询引擎
在创建并存储向量索引后,我们需要继续创建查询引擎,后续会将它们转换为 agnets 使用的工具(又名查询工具)。
代码语言:javascript
复制
# summary query engine
summary_query_engine = summary_index.as_query_engine( response_mode="tree_summarize", use_async=True,
) # vector query engine
vector_query_engine = vector_index.as_query_engine()在上面的例子中,我们创建了两个不同的查询引擎。后续我们会将它们都挂载到路由式查询引擎下,然后路由式查询引擎会根据用户的查询内容决定具体使用哪个查询引擎。
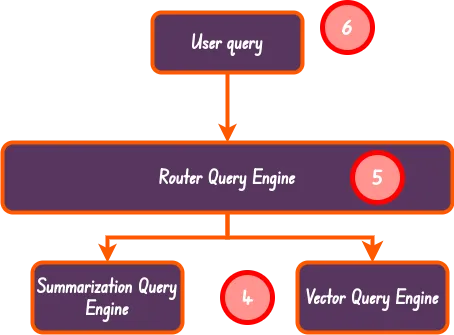
路由式查询引擎功能示意
在上面的代码中,我们指定了 use_async 参数以加快查询速度,这是我们必须使用 nest_asyncio 库的原因之一。
译者注:我刚去看 nest_asyncio 的代码库,发现被 archive 了,我还以为是 Python 官方支持了,后面在阅读 相关 issue 的时候才发现原来是代码库的作者年初去世了,RIP.
创建查询工具
查询工具是一个带有元数据(例如存储当前查询工具可以用来做什么)的查询引擎。这有助于路由式查询引擎能够根据传入的用户查询来决定具体使用哪个查询引擎。
代码语言:javascript
复制
from llama_index.core.tools import QueryEngineTool summary_tool = QueryEngineTool.from_defaults( query_engine=summary_query_engine, description=( "Useful for summarization questions related to the Lora paper." ),
) vector_tool = QueryEngineTool.from_defaults( query_engine=vector_query_engine, description=( "Useful for retrieving specific context from the the Lora paper." ),
)创建路由式查询引擎
最后,我们需要创建最终用于查询的路由式查询引擎。它能够帮我们聚合上文所创建的所有查询工具,即 summary_tool 和 vector_tool。
代码语言:javascript
复制
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector query_engine = RouterQueryEngine( selector=LLMSingleSelector.from_defaults(), query_engine_tools=[ summary_tool, vector_tool, ], verbose=True
)LLMSingleSelector:是一个使用 LLM 从选项列表中选择出单个选项的选择器。你可以在 这个链接 中查看更多信息。
测试路由式查询引擎
译者注:在执行如下代码是记得把问题换成与你使用的 PDF 相关的问题。
可以通过如下代码测试我们创建的路由式查询引擎:
代码语言:javascript
复制
response = query_engine.query("What is the summary of the document?")
print(str(response))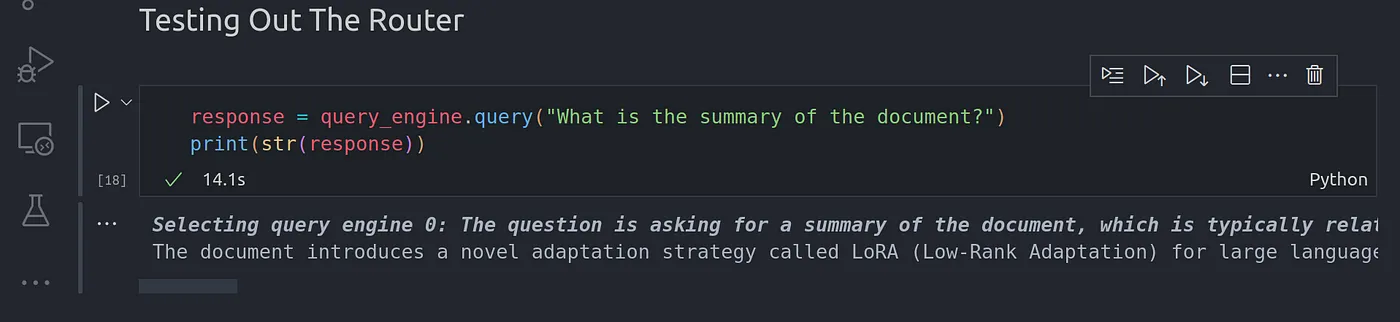
代码截图-5
以上是论文的摘要,总结了我们传递给查询引擎的 Lora 论文的所有上下文。
由于我们使用的摘要索引是将所有块存储在顺序列表中,因此在生成摘要时会访问所有块并从中生成一个总摘要,然后再以此生成最终摘要。
可以通过检查响应中 source_nodes 列表的长度来确认这一点,source_nodes 属性是这次响应中用到的所有块的列表。

代码截图-6
可以看到最终的结果 38 与我们前面创建的块的数量相同,这意味着所有的块都用于本次摘要生成。
再提问一个不涉及总结的问题:
代码语言:javascript
复制
response = query_engine.query("What is the long from of Lora?")
print(str(response))
代码截图-7
这次回答使用了向量索引,尽管响应内容不是很准确。
将代码合并
现在你已经大致理解了这套 Agentic RAG 工作流,让我们将其抽象成函数方便后续调用:
代码语言:javascript
复制
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SummaryIndex, VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReaderasync def create_router_query_engine( document_fp: str, verbose: bool = True,
) -> RouterQueryEngine: # load lora_paper.pdf documents documents = SimpleDirectoryReader(input_files=[document_fp]).load_data() # chunk_size of 1024 is a good default value splitter = SentenceSplitter(chunk_size=1024) # Create nodes from documents nodes = splitter.get_nodes_from_documents(documents) # LLM model Settings.llm = OpenAI(model="gpt-3.5-turbo") # embedding model Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002") # summary index summary_index = SummaryIndex(nodes) # vector store index vector_index = VectorStoreIndex(nodes) # summary query engine summary_query_engine = summary_index.as_query_engine( response_mode="tree_summarize", use_async=True, ) # vector query engine vector_query_engine = vector_index.as_query_engine() summary_tool = QueryEngineTool.from_defaults( query_engine=summary_query_engine, description=( "Useful for summarization questions related to the Lora paper." ), ) vector_tool = QueryEngineTool.from_defaults( query_engine=vector_query_engine, description=( "Useful for retrieving specific context from the the Lora paper." ), ) query_engine = RouterQueryEngine( selector=LLMSingleSelector.from_defaults(), query_engine_tools=[ summary_tool, vector_tool, ], verbose=verbose ) return query_engine然后我们就可以通过如下方法便捷的调用次函数:
代码语言:javascript
复制
query_engine = await create_router_query_engine("./datasets/lora_paper.pdf")
response = query_engine.query("What is the summary of the document?")
print(str(response))
代码截图-7
我们可以在当前目录下创建一个 utils.py 文件,用于存放刚刚抽象出来的函数:
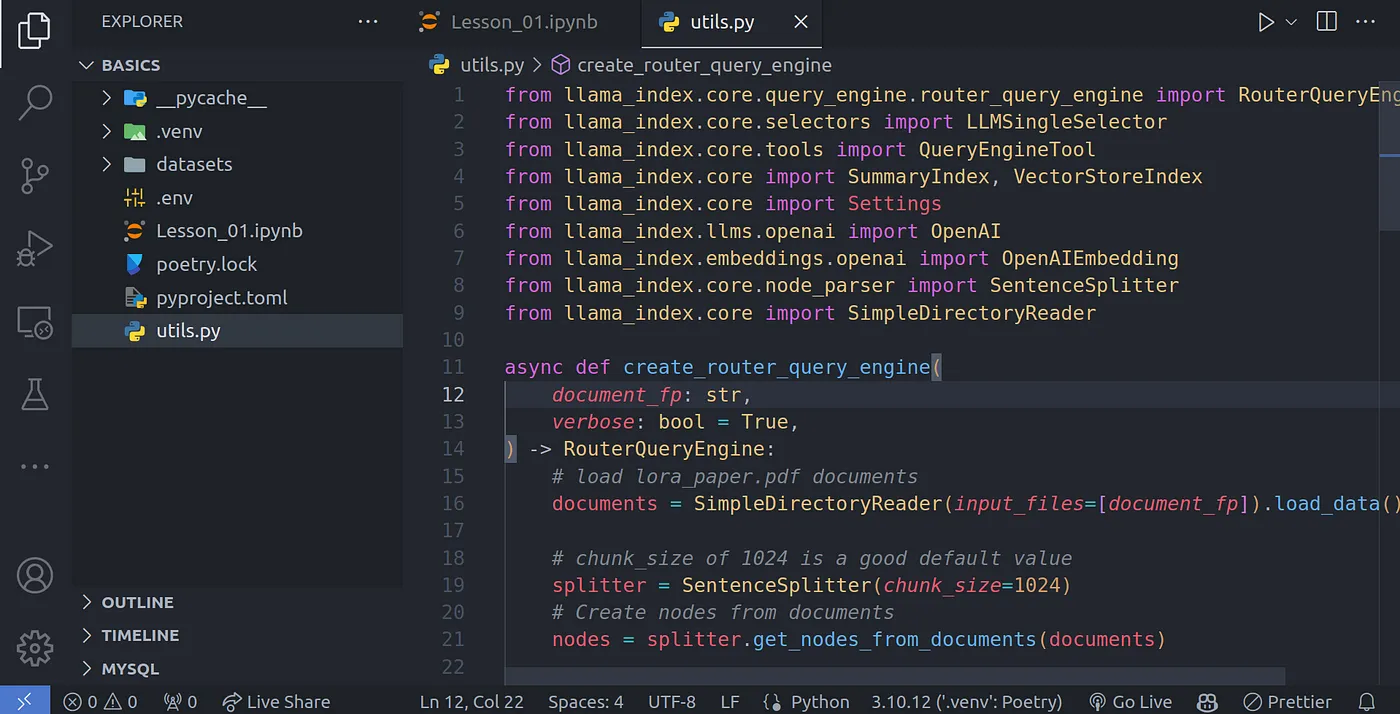
代码截图-8
之后我们就可以通过如下代码便捷的调用此函数:
代码语言:javascript
复制
from utils import create_router_query_engine query_engine = await create_router_query_engine("./datasets/lora_paper.pdf")
response = query_engine.query("What is the summary of the document?")
print(str(response))
代码截图-9
结语
恭喜你走到这一步。以上就是本文的全部内容了,在下一篇文章中,我将介绍如何使用工具调用(也称函数调用)来进一步加强我们的 RAG 系统。
相关文章:
使用 Llama-index 实现的 Agentic RAG-Router Query Engine
前言 你是否也厌倦了我在博文中经常提到的老式 RAG(Retrieval Augmented Generation | 检索增强生成) 系统?反正我是对此感到厌倦了。但我们可以做一些有趣的事情,让它更上一层楼。接下来就跟我一起将 agents 概念引入传统的 RAG 工作流,重新…...

一行命令将Cmder添加到系统右键菜单中----配置环境
第一步,去官网下载一个简版的文件 ** 第二步,将下载的文件解压后如图,找到Cmder.exe右键以管理员身份运行 第三步,在窗口输入cmder /register all然后回车 第四步,OK!不管在哪里都可以使用了,直接右键即可...

【系统架构设计师】专题:基于构件的软件工程考点
更多内容请见: 备考系统架构设计师-核心总结目录 文章目录 一、构件概述二、构件模型三、CBSE的特征四、CBSE的过程五、构件组装一、构件概述 基于构件的软件工程(Component-Based Software Engineering,CBSE) 是一种基于分布对象技术、 强调通过可复用构件设计与构造软件系…...

目前最好用的爬虫软件是那个?
作为一名数据工程师,三天两头要采集数据,用过十几种爬虫软件,也用过Python爬虫库,还是建议新手使用现成的软件比较方便。 这里推荐3款不错的自动化爬虫工具,八爪鱼、亮数据、Web Scraper 1. 八爪鱼爬虫 八爪鱼爬虫是一…...

运营计划管理——电商运营(案例分享)
运营计划,作为运营管理的重要组成部分,通过科学规划与有效执行,对确保企业目标实现起着至关重要的作用。 运营计划是指通过制定、执行、监控和调整运营计划,以确保企业资源得到合理配置,业务活动有序进行,最…...

【WRF工具】WRF Domain Wizard第二期:服务器中下载及安装
【WRF工具】WRF Domain Wizard第二期:服务器下载及安装 准备WRF Domain Wizard下载及安装WRF Domain Wizard下载WRF Domain Wizard安装添加环境变量(为当前用户永久添加环境变量)Java环境安装报错-Exception in thread "main" java…...

信安 实验1 用Wireshark分析典型TCP/IP体系中的协议
我发现了有些人喜欢静静看博客不聊天呐, 但是ta会点赞。 这样的人呢帅气低调有内涵, 美丽大方很优雅。 说的就是你, 不用再怀疑哦 实验1 用Wireshark分析典型TCP/IP体系中的协议 实验目的 通过Wireshark软件分析典型网络协议数据包&a…...

Halcon内部和外部函数,区分明白
我们从保存位置,使用范围,跨程序使用,及修改时影响面来说 内部函数 只存在于当前的halcon程序, 是程序体的一部分,随程序一起保存, 只能在当前定义的程序内当做算子使用 其他程序想使用,需要通过…...
使用 pypdf 给 PDF 添加目录书签
""" dir.txt的形式 第1章 计算机系统基础知识 1 1.1 嵌入式计算机系统概述 1 1.2 数据表示 4 1.2.1 进位计数制及转换 4 1.2.2 数值型数据的表示 6 第2章 嵌入式系统硬件基础知识 56 2.1 数字电路基础 56 2.1.1 信号特征 56 2.1.2 组合逻辑电路和时序逻辑电路 5…...

2025郑州台球展,河南台球展会,智能台球桌展3月举办
壹肆柒台球展,整合全面优势资源,与业界一道倾力打造全国型台球贸易和交流盛会; 2025中国(郑州)国际台球产业博览会(壹肆柒台球展) The 2025 China (Zhengzhou) International Billiards Indust…...

Vue下载静态文件
1、需求:将静态文件放在本地,让用户进行下载。 2、文件位置: ① 原生js:直接将文件放在某个目录或者根目录下 ② Vue:将文件放在根目录的public文件夹下面 3、代码示例: const url "/模板.xlsx"…...

04 B-树
目录 常见的搜索结构B-树概念B-树的插入分析B-树的插入实现B树和B*树B-树的应用 1. 常见的搜索结构 种类数据格式时间复杂度顺序查找无要求O(N)二分查找有序O( l o g 2 N log_2N log2N)二分搜索树无要求O(N)二叉平衡树无要求O( l o g 2 N log_2N log2N)哈希无要求O(1) 以…...

计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-27
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-27 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-27目录1. VisScience: An Extensive Benchmark for Evaluating K12 Educational Multi-modal Scientific Reasoning VisScience:…...

恋爱辅助应用小程序app开发之广告策略
恋爱话术小程序带流量主广告开启,是一个有效的盈利模式,可以增加小程序的收入来源。以下是对此的详细分析 一、流量主广告的定义与优势 流量主广告是指在小程序中嵌入广告位,通过展示广告内容来获取广告主的付费。对于恋爱话术小程序而言&am…...

iTextPDF中,要实现表格中的内容在数据长度超过边框时自动换行
在iTextPDF中,要实现表格中的内容在数据长度超过边框时自动换行,你可以使用Phrase对象并设置其HyphenationEvent,或者使用Chunk对象并设置其setSplitCharacter方法。以下是一些方法来实现这一功能: 1. 使用Phrase对象:…...

Unreal Engine 5 C++: 插件编写03 | MessageDialog
在虚幻引擎编辑器中编写Warning弹窗 准备工作 FMessageDialog These functions open a message dialog and display the specified informations there. EAppReturnType::Type 是 Unreal Engine 中用于表示应用程序对话框(如消息对话框)返回结果的枚举…...

【前端面试题】Vue 3 生命周期钩子的执行顺序详解
前言 在 Vue 3 中,生命周期钩子的执行顺序与 Vue 2 有所不同,特别是 setup 函数取代了传统的生命周期钩子 beforeCreate 和 created。本文将详细解析 Vue 3 的生命周期钩子执行顺序,帮助你更好地理解 Vue 3 的组件生命周期及其工作机制。 V…...
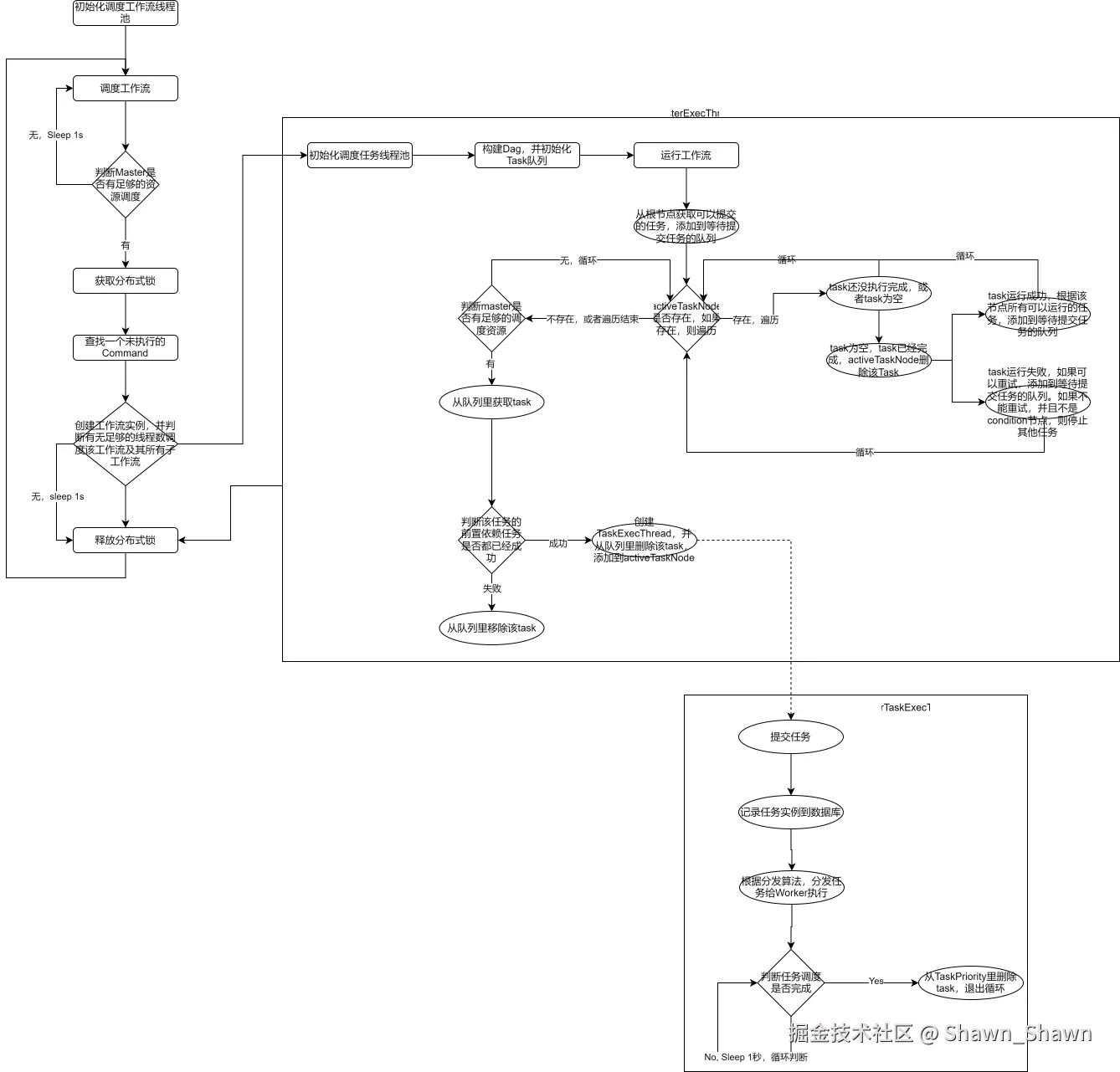
Apache DolphinScheduler-1.3.9源码分析(一)
引言 随着大数据的发展,任务调度系统成为了数据处理和管理中至关重要的部分。Apache DolphinScheduler 是一款优秀的开源分布式工作流调度平台,在大数据场景中得到广泛应用。 在本文中,我们将对 Apache DolphinScheduler 1.3.9 版本的源码进…...

高级java每日一道面试题-2024年9月29日-数据库篇-索引怎么定义,分哪几种?
如果有遗漏,评论区告诉我进行补充 面试官: 索引怎么定义,分哪几种? 我回答: 在Java高级面试中,尤其是涉及数据库和数据结构的部分,索引(Index)是一个核心概念。索引的目的是提高数据库表中数据的检索速度,从而加快…...
现代LLM基本技术整理
0 开始之前 作者:hadiii,北京大学 电子信息硕士在读 本文从Llama 3报告出发,基本整理一些现代LLM的技术。基本,是说对一些具体细节不会过于详尽,而是希望得到一篇相对全面,包括预训练,后训练&…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...