Python精选200Tips:181-182
针对图像的经典卷积网络结构进化史及可视化
- 针对图像的经典卷积网络结构进化史及可视化(续)
- P181--MobileNet【2017】
- 模型结构及创新性说明
- 模型结构代码
- MobileNet V1版本
- MobileNet V2版本
- MobileNet V3 版本
- Small版本
- Large版本
- P182--EfficientNet【2019】
- 模型结构及创新性说明
- 模型结构代码
- B1--B7版本
运行系统:macOS Sequoia 15.0
Python编译器:PyCharm 2024.1.4 (Community Edition)
Python版本:3.12
TensorFlow版本:2.17.0
Pytorch版本:2.4.1
往期链接:
| 1-5 | 6-10 | 11-20 | 21-30 | 31-40 | 41-50 |
|---|
| 51-60:函数 | 61-70:类 | 71-80:编程范式及设计模式 |
|---|
| 81-90:Python编码规范 | 91-100:Python自带常用模块-1 |
|---|
| 101-105:Python自带模块-2 | 106-110:Python自带模块-3 |
|---|
| 111-115:Python常用第三方包-频繁使用 | 116-120:Python常用第三方包-深度学习 |
|---|
| 121-125:Python常用第三方包-爬取数据 | 126-130:Python常用第三方包-为了乐趣 |
|---|
| 131-135:Python常用第三方包-拓展工具1 | 136-140:Python常用第三方包-拓展工具2 |
|---|
Python项目实战
| 141-145 | 146-150 | 151-155 | 156-160 | 161-165 | 166-170 | 171-175 | 176-180 |
|---|
针对图像的经典卷积网络结构进化史及可视化(续)
P181–MobileNet【2017】
模型结构及创新性说明
MobileNet是一系列为移动和嵌入式视觉应用设计的轻量级卷积神经网络。以下是MobileNet各个版本的的主要特点:
(1)MobileNetV1版本
主要特点
- 引入深度可分离卷积(Depthwise Separable Convolution)
- 使用宽度乘子(Width Multiplier)和分辨率乘子(Resolution Multiplier)调整模型大小和复杂度
创新点
- 深度可分离卷积将标准卷积分解为深度卷积和逐点卷积,大大减少了计算量
- 使用ReLU6作为激活函数,有利于低精度计算
(2)MobileNetV2版本
主要特点
- 引入倒置残差结构(Inverted Residual Structure)
- 设计线性瓶颈(Linear Bottleneck)
创新点
- 倒置残差结构先扩展通道数,再做深度卷积,最后压缩回原来的通道数
- 去掉了最后一个ReLU,使用线性激活,有助于保留低维特征
(3)MobileNetV3
主要特点
- 网络结构搜索(NAS)优化的网络架构
- 引入新的激活函数:h-swish
- 集成Squeeze-and-Excitation (SE) 模块
- 提供Small和Large两个版本
创新点
- 使用NAS自动搜索最优网络结构
- h-swish激活函数提高了精度,同时计算效率高
- SE模块增强了特征的表达能力
- 优化了网络的首尾层,进一步提高效率
模型结构代码
MobileNet V1版本
import tensorflow as tf
from tensorflow.keras import layers, modelsdef depthwise_conv_block(inputs, pointwise_conv_filters, alpha,depth_multiplier=1, strides=(1, 1), block_id=1):"""Adds a depthwise convolution block.A depthwise convolution block consists of a depthwise conv,batch normalization, ReLU6, pointwise convolution,batch normalization and ReLU6 activation."""channel_axis = -1pointwise_conv_filters = int(pointwise_conv_filters * alpha)x = layers.DepthwiseConv2D((3, 3),padding='same',depth_multiplier=depth_multiplier,strides=strides,use_bias=False,name='conv_dw_%d' % block_id)(inputs)x = layers.BatchNormalization(axis=channel_axis, name='conv_dw_%d_bn' % block_id)(x)x = layers.ReLU(6., name='conv_dw_%d_relu' % block_id)(x)x = layers.Conv2D(pointwise_conv_filters, (1, 1),padding='same',use_bias=False,strides=(1, 1),name='conv_pw_%d' % block_id)(x)x = layers.BatchNormalization(axis=channel_axis, name='conv_pw_%d_bn' % block_id)(x)return layers.ReLU(6., name='conv_pw_%d_relu' % block_id)(x)def MobileNetV1(input_shape=(224, 224, 3),alpha=1.0,depth_multiplier=1,dropout=1e-3,classes=1000):"""Instantiates the MobileNet architecture.Arguments:input_shape: Optional shape tuple, to be specified if you wouldlike to use a model with an input img resolution that is not(224, 224, 3).alpha: Controls the width of the network. This is known as thewidth multiplier in the MobileNet paper.- If `alpha` < 1.0, proportionally decreases the numberof filters in each layer.- If `alpha` > 1.0, proportionally increases the numberof filters in each layer.- If `alpha` = 1, default number of filters from the paperare used at each layer.depth_multiplier: Depth multiplier for depthwise convolution.This is called the resolution multiplier in the MobileNet paper.dropout: Dropout rate.classes: Optional number of classes to classify images into.Returns:A Keras model instance."""img_input = layers.Input(shape=input_shape)x = layers.Conv2D(int(32 * alpha), (3, 3),strides=(2, 2),padding='same',use_bias=False,name='conv1')(img_input)x = layers.BatchNormalization(axis=-1, name='conv1_bn')(x)x = layers.ReLU(6., name='conv1_relu')(x)x = depthwise_conv_block(x, 64, alpha, depth_multiplier, block_id=1)x = depthwise_conv_block(x, 128, alpha, depth_multiplier, strides=(2, 2), block_id=2)x = depthwise_conv_block(x, 128, alpha, depth_multiplier, block_id=3)x = depthwise_conv_block(x, 256, alpha, depth_multiplier, strides=(2, 2), block_id=4)x = depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=5)x = depthwise_conv_block(x, 512, alpha, depth_multiplier, strides=(2, 2), block_id=6)x = depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=7)x = depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=8)x = depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=9)x = depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=10)x = depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=11)x = depthwise_conv_block(x, 1024, alpha, depth_multiplier, strides=(2, 2), block_id=12)x = depthwise_conv_block(x, 1024, alpha, depth_multiplier, block_id=13)x = layers.GlobalAveragePooling2D()(x)x = layers.Reshape((1, 1, int(1024 * alpha)))(x)x = layers.Dropout(dropout, name='dropout')(x)x = layers.Conv2D(classes, (1, 1),padding='same',name='conv_preds')(x)x = layers.Reshape((classes,), name='reshape_2')(x)x = layers.Activation('softmax', name='act_softmax')(x)model = models.Model(img_input, x, name='mobilenet_v1')return model# 创建MobileNet V1模型
model = MobileNetV1(input_shape=(224, 224, 3), classes=1000)# 打印模型摘要
model.summary()
可以通过调整alpha参数来创建不同大小的MobileNetV1模型:
custom_model = MobileNetV1(input_shape=(224, 224, 3), classes=10, alpha=0.75)
custom_model.summary()
这将创建一个稍微窄一些(alpha=0.75)的MobileNet模型,用于10类分类任务。
MobileNet V2版本
import tensorflow as tf
from tensorflow.keras import layers, modelsdef inverted_residual_block(inputs, filters, stride, expand_ratio, alpha):input_channels = inputs.shape[-1]pointwise_filters = int(filters * alpha)# Expansion phasex = layers.Conv2D(int(input_channels * expand_ratio), kernel_size=1, padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = layers.ReLU(6.)(x)# Depthwise Convolutionx = layers.DepthwiseConv2D(kernel_size=3, strides=stride, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = layers.ReLU(6.)(x)# Projectionx = layers.Conv2D(pointwise_filters, kernel_size=1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)# Residual connection if possibleif stride == 1 and input_channels == pointwise_filters:return layers.Add()([inputs, x])return xdef MobileNetV2(input_shape=(224, 224, 3), num_classes=1000, alpha=1.0, include_top=True):inputs = layers.Input(shape=input_shape)# First Convolution Layerx = layers.Conv2D(int(32 * alpha), kernel_size=3, strides=(2, 2), padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = layers.ReLU(6.)(x)# Inverted Residual Blocksx = inverted_residual_block(x, filters=16, stride=1, expand_ratio=1, alpha=alpha)x = inverted_residual_block(x, filters=24, stride=2, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=24, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=32, stride=2, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=32, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=32, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=64, stride=2, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=64, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=64, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=64, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=96, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=96, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=96, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=160, stride=2, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=160, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=160, stride=1, expand_ratio=6, alpha=alpha)x = inverted_residual_block(x, filters=320, stride=1, expand_ratio=6, alpha=alpha)# Last Convolution Layerx = layers.Conv2D(int(1280 * alpha), kernel_size=1, use_bias=False)(x)x = layers.BatchNormalization()(x)x = layers.ReLU(6.)(x)if include_top:x = layers.GlobalAveragePooling2D()(x)x = layers.Dense(num_classes, activation='softmax')(x)model = models.Model(inputs, x, name='MobileNetV2')return model# 创建MobileNet V2模型
model = MobileNetV2(input_shape=(224, 224, 3), num_classes=1000)# 打印模型摘要
model.summary()
MobileNet V3 版本
Small版本
import tensorflow as tf
from tensorflow.keras import layers, modelsclass HSwish(layers.Layer):def call(self, x):return x * tf.nn.relu6(x + 3) / 6class HSigmoid(layers.Layer):def call(self, x):return tf.nn.relu6(x + 3) / 6def squeeze_excite_block(inputs, se_ratio=0.25):x = layers.GlobalAveragePooling2D()(inputs)filters = inputs.shape[-1]x = layers.Dense(max(1, int(filters * se_ratio)), activation='relu')(x)x = layers.Dense(filters, activation=HSigmoid())(x)x = layers.Reshape((1, 1, filters))(x)return layers.multiply([inputs, x])def bneck(inputs, out_channels, exp_channels, kernel_size, stride, se_ratio, activation, alpha=1.0):x = layers.Conv2D(int(exp_channels * alpha), 1, padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = activation(x)x = layers.DepthwiseConv2D(kernel_size, stride, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = activation(x)if se_ratio:x = squeeze_excite_block(x, se_ratio)x = layers.Conv2D(int(out_channels * alpha), 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)if stride == 1 and inputs.shape[-1] == int(out_channels * alpha):return layers.Add()([inputs, x])return xdef MobileNetV3Small(input_shape=(224, 224, 3), num_classes=1000, alpha=1.0, include_top=True):inputs = layers.Input(shape=input_shape)x = layers.Conv2D(16, 3, strides=2, padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = HSwish()(x)x = bneck(x, 16, 16, 3, 2, 0.25, layers.ReLU(), alpha)x = bneck(x, 24, 72, 3, 2, None, layers.ReLU(), alpha)x = bneck(x, 24, 88, 3, 1, None, layers.ReLU(), alpha)x = bneck(x, 40, 96, 5, 2, 0.25, HSwish(), alpha)x = bneck(x, 40, 240, 5, 1, 0.25, HSwish(), alpha)x = bneck(x, 40, 240, 5, 1, 0.25, HSwish(), alpha)x = bneck(x, 48, 120, 5, 1, 0.25, HSwish(), alpha)x = bneck(x, 48, 144, 5, 1, 0.25, HSwish(), alpha)x = bneck(x, 96, 288, 5, 2, 0.25, HSwish(), alpha)x = bneck(x, 96, 576, 5, 1, 0.25, HSwish(), alpha)x = bneck(x, 96, 576, 5, 1, 0.25, HSwish(), alpha)x = layers.Conv2D(int(576 * alpha), 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = HSwish()(x)x = layers.GlobalAveragePooling2D()(x)x = layers.Reshape((1, 1, int(576 * alpha)))(x)x = layers.Conv2D(int(1024 * alpha), 1, padding='same')(x)x = HSwish()(x)if include_top:x = layers.Conv2D(num_classes, 1, padding='same', activation='softmax')(x)x = layers.Reshape((num_classes,))(x)model = models.Model(inputs, x, name='MobileNetV3Small')return model# 创建MobileNet V3 Small模型
model = MobileNetV3Small(input_shape=(224, 224, 3), num_classes=1000)# 打印模型摘要
model.summary()
Large版本
import tensorflow as tf
from tensorflow.keras import layers, modelsclass HSwish(layers.Layer):def call(self, x):return x * tf.nn.relu6(x + 3) / 6class HSigmoid(layers.Layer):def call(self, x):return tf.nn.relu6(x + 3) / 6def squeeze_excite_block(inputs, se_ratio=0.25):x = layers.GlobalAveragePooling2D()(inputs)filters = inputs.shape[-1]x = layers.Dense(max(1, int(filters * se_ratio)), activation='relu')(x)x = layers.Dense(filters, activation=HSigmoid())(x)x = layers.Reshape((1, 1, filters))(x)return layers.multiply([inputs, x])def bneck(inputs, out_channels, exp_channels, kernel_size, stride, se_ratio, activation, alpha=1.0):x = layers.Conv2D(int(exp_channels * alpha), 1, padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = activation(x)x = layers.DepthwiseConv2D(kernel_size, stride, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = activation(x)if se_ratio:x = squeeze_excite_block(x, se_ratio)x = layers.Conv2D(int(out_channels * alpha), 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)if stride == 1 and inputs.shape[-1] == int(out_channels * alpha):return layers.Add()([inputs, x])return xdef MobileNetV3Large(input_shape=(224, 224, 3), num_classes=1000, alpha=1.0, include_top=True):inputs = layers.Input(shape=input_shape)x = layers.Conv2D(16, 3, strides=2, padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = HSwish()(x)x = bneck(x, 16, 16, 3, 1, None, layers.ReLU(), alpha)x = bneck(x, 24, 64, 3, 2, None, layers.ReLU(), alpha)x = bneck(x, 24, 72, 3, 1, None, layers.ReLU(), alpha)x = bneck(x, 40, 72, 5, 2, 0.25, layers.ReLU(), alpha)x = bneck(x, 40, 120, 5, 1, 0.25, layers.ReLU(), alpha)x = bneck(x, 40, 120, 5, 1, 0.25, layers.ReLU(), alpha)x = bneck(x, 80, 240, 3, 2, None, HSwish(), alpha)x = bneck(x, 80, 200, 3, 1, None, HSwish(), alpha)x = bneck(x, 80, 184, 3, 1, None, HSwish(), alpha)x = bneck(x, 80, 184, 3, 1, None, HSwish(), alpha)x = bneck(x, 112, 480, 3, 1, 0.25, HSwish(), alpha)x = bneck(x, 112, 672, 3, 1, 0.25, HSwish(), alpha)x = bneck(x, 160, 672, 5, 2, 0.25, HSwish(), alpha)x = bneck(x, 160, 960, 5, 1, 0.25, HSwish(), alpha)x = bneck(x, 160, 960, 5, 1, 0.25, HSwish(), alpha)x = layers.Conv2D(int(960 * alpha), 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = HSwish()(x)x = layers.GlobalAveragePooling2D()(x)x = layers.Reshape((1, 1, int(960 * alpha)))(x)x = layers.Conv2D(int(1280 * alpha), 1, padding='same')(x)x = HSwish()(x)if include_top:x = layers.Conv2D(num_classes, 1, padding='same', activation='softmax')(x)x = layers.Reshape((num_classes,))(x)model = models.Model(inputs, x, name='MobileNetV3Large')return model# 创建MobileNet V3 Large模型
model = MobileNetV3Large(input_shape=(224, 224, 3), num_classes=1000)# 打印模型摘要
model.summary()
P182–EfficientNet【2019】
模型结构及创新性说明
EfficientNet是由Google研究人员在2019年提出的一系列卷积神经网络模型,旨在提高模型效率和准确性。以下是EfficientNet的主要特点:
模型结构
- 基于MobileNetV2的倒置残差结构
- 使用Squeeze-and-Excitation (SE) 块
- 采用复合缩放方法
创新性:
- 提出了复合缩放方法,同时缩放网络的宽度、深度和分辨率
- 通过神经架构搜索(NAS)优化基础网络结构
- 在同等计算资源下,实现了更高的准确率
模型结构代码
B0版本
import matplotlib.pyplot as plt
import tensorflow as tf
from keras.utils import plot_model
from tensorflow.keras import layers, models# macos系统显示中文
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']def swish(x):return x * tf.nn.sigmoid(x)def se_block(inputs, se_ratio):channels = inputs.shape[-1]x = layers.GlobalAveragePooling2D()(inputs)x = layers.Dense(max(1, int(channels * se_ratio)), activation=swish)(x)x = layers.Dense(channels, activation='sigmoid')(x)return layers.Multiply()([inputs, x])def mbconv_block(inputs, out_channels, expand_ratio, stride, kernel_size, se_ratio):channels = inputs.shape[-1]x = inputs# Expansion phaseif expand_ratio != 1:expand_channels = channels * expand_ratiox = layers.Conv2D(expand_channels, 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = layers.Activation(swish)(x)# Depthwise Convx = layers.DepthwiseConv2D(kernel_size, stride, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = layers.Activation(swish)(x)# Squeeze and Excitationif se_ratio:x = se_block(x, se_ratio)# Output phasex = layers.Conv2D(out_channels, 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)if stride == 1 and channels == out_channels:x = layers.Add()([inputs, x])return xdef efficientnet(width_coefficient, depth_coefficient, resolution, dropout_rate):base_architecture = [# expansion, channels, repeats, stride, kernel_size[1, 16, 1, 1, 3],[6, 24, 2, 2, 3],[6, 40, 2, 2, 5],[6, 80, 3, 2, 3],[6, 112, 3, 1, 5],[6, 192, 4, 2, 5],[6, 320, 1, 1, 3]]inputs = layers.Input(shape=(resolution, resolution, 3))x = layers.Conv2D(32, 3, strides=2, padding='same', use_bias=False)(inputs)x = layers.BatchNormalization()(x)x = layers.Activation(swish)(x)for i, (expansion, channels, repeats, stride, kernel_size) in enumerate(base_architecture):channels = int(channels * width_coefficient)repeats = int(repeats * depth_coefficient)for j in range(repeats):x = mbconv_block(x, channels, expansion, stride if j == 0 else 1, kernel_size, se_ratio=0.25)x = layers.Conv2D(1280, 1, padding='same', use_bias=False)(x)x = layers.BatchNormalization()(x)x = layers.Activation(swish)(x)x = layers.GlobalAveragePooling2D()(x)if dropout_rate > 0:x = layers.Dropout(dropout_rate)(x)outputs = layers.Dense(1000, activation='softmax')(x)model = tf.keras.Model(inputs, outputs)return model# EfficientNet-B0 configuration
def efficientnet_b0():return efficientnet(width_coefficient=1.0,depth_coefficient=1.0,resolution=224,dropout_rate=0.2)# Create the model
model_b0 = efficientnet_b0()# Print model summary
model_b0.summary()# 将模型结构输出到pdf
plot_model(model_b0, to_file='model_b0.pdf', show_shapes=True,show_layer_names=True)
B1–B7版本
def efficientnet_b1():return efficientnet(width_coefficient=1.0, depth_coefficient=1.1, resolution=240, dropout_rate=0.2)def efficientnet_b2():return efficientnet(width_coefficient=1.1, depth_coefficient=1.2, resolution=260, dropout_rate=0.3)def efficientnet_b3():return efficientnet(width_coefficient=1.2, depth_coefficient=1.4, resolution=300, dropout_rate=0.3)def efficientnet_b4():return efficientnet(width_coefficient=1.4, depth_coefficient=1.8, resolution=380, dropout_rate=0.4)def efficientnet_b5():return efficientnet(width_coefficient=1.6, depth_coefficient=2.2, resolution=456, dropout_rate=0.4)def efficientnet_b6():return efficientnet(width_coefficient=1.8, depth_coefficient=2.6, resolution=528, dropout_rate=0.5)def efficientnet_b7():return efficientnet(width_coefficient=2.0, depth_coefficient=3.1, resolution=600, dropout_rate=0.5)
相关文章:

Python精选200Tips:181-182
针对图像的经典卷积网络结构进化史及可视化 针对图像的经典卷积网络结构进化史及可视化(续)P181--MobileNet【2017】模型结构及创新性说明模型结构代码MobileNet V1版本MobileNet V2版本MobileNet V3 版本Small版本Large版本 P182--EfficientNet【2019】…...

SpringCloud 配置 feign.hystrix.enabled: true 不生效
SpringCloud 配置 feign.hystrix.enabled: true 不生效的原因 feign 启用 hystrix feign 默认没有启用 hystrix,添加配置,启用 hystrix feign.hystrix.enabledtrue application.yml 添加配置 feign:hystrix:enabled: true启用 hystrix 后,访…...

9.24-k8s服务发布
Ingress 使用域名发布 K8S 服务 部署项目 一、先部署mariadb [rootk8s-master ~]# mkdir aaa [rootk8s-master ~]# cd aaa/ [rootk8s-master aaa]# # 先部署mariadb [rootk8s-master aaa]# # configmap [rootk8s-master aaa]# vim mariadb-configmap.yaml apiVersion: v1 ki…...

UI设计师面试整理-作品集展示
在UI设计师的面试中,作品集展示是非常关键的一环。它不仅展示了你的设计技能和风格,也让面试官了解你的设计思维和解决问题的能力。下面是如何有效地准备和展示你的作品集的建议: 1. 选择合适的项目 ● 多样性:选择能展示你在不同领域或平台上的设计能力的项目。确保作品集…...
)
CMU 10423 Generative AI:lec10(few-shot、提示工程、上下文学习)
文章目录 1 概述2 摘录2.1 zero-shot 和 few-shot一、Zero-shot Learning(零样本学习)特点:工作原理:优点:缺点: 二、Few-shot Learning(少样本学习)特点:工作原理&#…...

做数据抓取工作要如何选择ip池
选择合适的IP池对于数据抓取工作至关重要。一个优质的IP池可以提高抓取的效率和成功率,同时减少被目标网站封禁的风险。以下是选择IP池时需要考虑的一些关键因素: 1. IP类型 住宅IP:住宅IP通常来自真实用户,难以被识别为代理。它…...

防止电脑电池老化,禁止usb或者ac接口调试时充电
控制android系统,开发者模式,开启和禁止充电 连接 Android 手机到电脑的 USB 端口。 下载并安装 Android Debug Bridge (ADB) 工具[1]。 USB: 在命令行中输入 adb shell dumpsys battery set usb 0,以禁止 USB 充电。 在命令…...

智权半导体/SmartDV力助高速发展的中国RISC-V CPU IP厂商走上高质量发展之道
作者:Karthik Gopal SmartDV Technologies亚洲区总经理 智权半导体科技(厦门)有限公司总经理 进入2024年,全球RISC-V社群在技术和应用两个方向上都在加快发展,中国国内的RISC-V CPU IP提供商也在内核性能和应用扩展…...

利用vue-capper封装一个可以函数式调用图片裁剪组件
1. 效果 const cropData await wqCrop({prop:{img,autoCrop: true, // 是否开启截图框maxImgSize: 600,autoCropWidth: 30,canMove: true, // 图片是否可移动canMoveBox: true, // 截图框是否可移动fixedBox: false, // 截图框是否固定}});console.log(cropData);使用wqCrop会…...

在系统开发中提升 Excel 数据导出一致性与可维护性的统一规范与最佳实践
背景: 在系统开发过程中,数据导出为 Excel 格式是一个常见的需求。然而,由于各个开发人员的编码习惯和实现方式不同,导致导出代码风格不一。有的人使用第三方库,有的人则自定义实现。这种多样化不仅影响了代码的一致性…...

SpringAOP学习
面向切面编程,指导开发者如何组织程序结构 增强原始设计的功能 oop:面向对象编程 1.导入aop相关坐标,创建 <!--spring依赖--><dependencies><dependency><groupId>org.springframework</groupId><artifactId>spri…...

智能网联汽车飞速发展,安全危机竟如影随形,如何破局?
随着人工智能、5G通信、大数据等技术的飞速发展,智能网联汽车正在成为全球汽车行业的焦点。特别是我国智能网联汽车市场规模近年来呈现快速增长态势,彰显了行业蓬勃发展的活力与潜力。然而,车联网技术的广泛应用也带来了一系列网络安全问题&a…...

Android常用C++特性之std::function
声明:本文内容生成自ChatGPT,目的是为方便大家了解学习作为引用到作者的其他文章中。 std::function 是 C 标准库中的一个 函数包装器,用于存储、复制、调用任何可以调用的目标(如普通函数、lambda 表达式、函数对象、成员函数等&…...

人工智能与机器学习原理精解【27】
文章目录 集成学习集成学习概述集成学习的定义集成学习的性质集成学习的算法过程集成学习的算法描述集成学习的例子和例题Julia实现集成学习 集成学习数学原理一、基学习器的生成Bagging(装袋法)Boosting(提升法) 二、基学习器的结…...

XXL-JOB在SpringBoot中的集成
在SpringBoot中,XXL-JOB作为一个轻量级的分布式任务调度平台,提供了灵活的任务分片处理功能,这对于处理大规模、复杂的任务场景尤为重要。以下将详细探讨如何在SpringBoot中利用XXL-JOB实现灵活控制的分片处理方案,涵盖配置、代码…...

前端工程规范-3:CSS规范(Stylelint)
样式规范工具(StyleLint) Stylelint 是一个灵活且强大的工具,适用于保持 CSS 代码的质量和一致性。结合其他工具(如 Prettier 和 ESLint),可以更全面地保障前端代码的整洁性和可维护性。 目录 样式规范工具…...

Qt系列-1.Qt安装
Qt安装 0 简介 1.安装步骤 1.1 下载 进入qt中文网站:https://www.qt.io/zh-cn/ Qt开源社区版本:https://www.qt.io/download-open-source#source 1.2 安装 chmod +x qt-online-installer-linux-x64-4.8.0.run ./qt-online-installer-linux-x64-4.8.0.run 外网不能下载…...

《自控原理》最小相位系统
在复平面右半平面既没有零点,也没有极点的系统,称为最小相位系统,其余均为非最小相位系统。 从知乎看了一篇答案: https://www.zhihu.com/question/24163919 证明过程大概率比较难,我翻了两本自控的教材,…...

SpringBoot3脚手架
MySpringBootAPI SpringBoot3脚手架,基于SpringBoot3DruidPgSQLMyBatisPlus13FastJSON2Lombok,启动web容器为Undertow(非默认tomcat),其他的请自行添加和配置。 <java.version>17</java.version> <springboot.version>3.3…...

【C语言软开面经】
C语言软开面经 malloc calloc realloc free动态分配内存malloccalloc函数:realloc 函数:free函数: 堆栈-内存分区栈区(Stack):堆区(Heap):全局(静态ÿ…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...
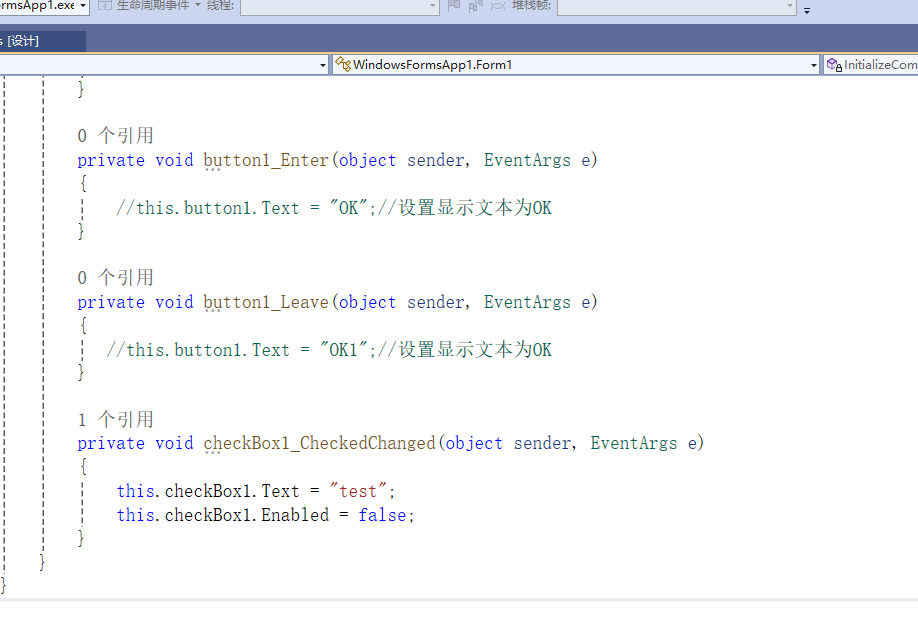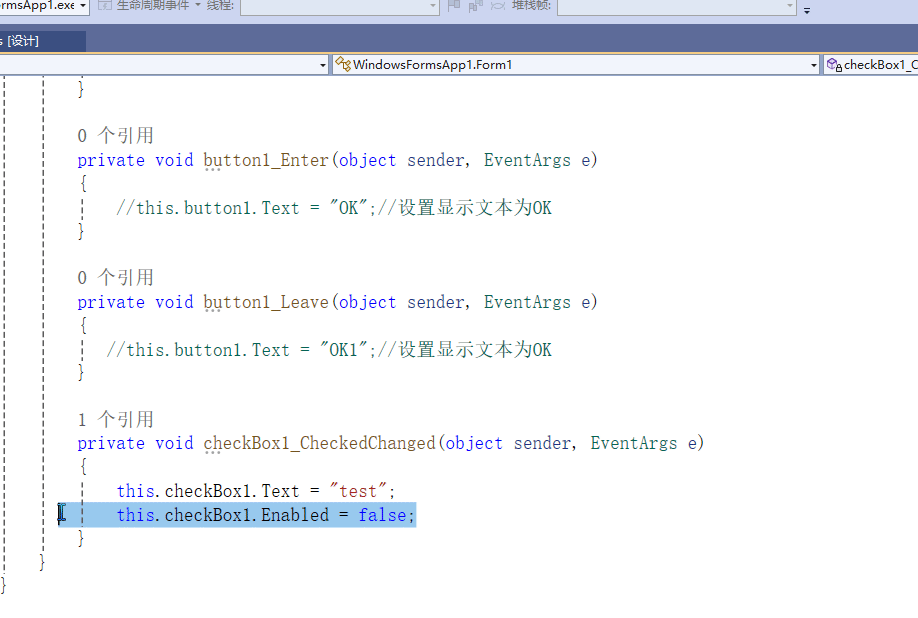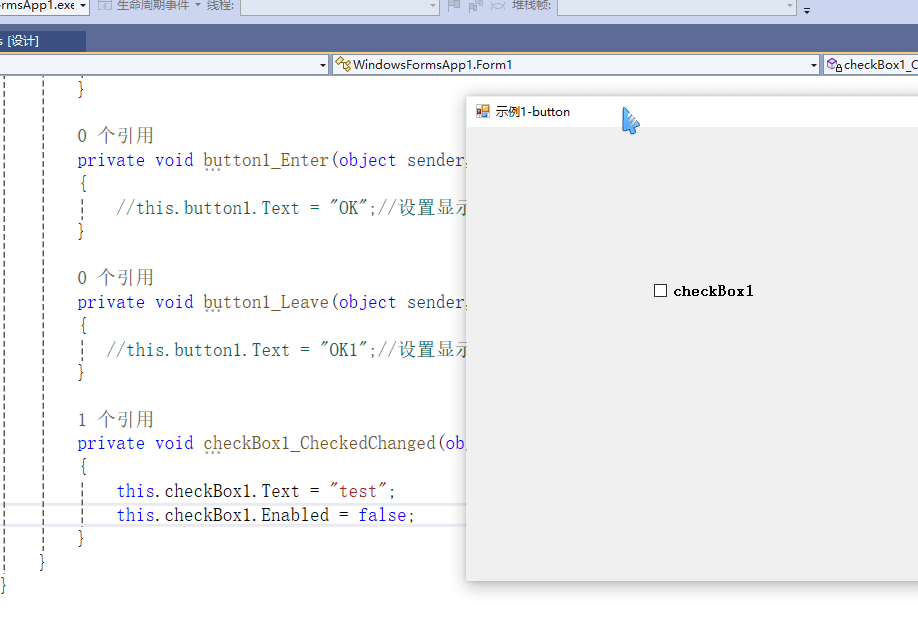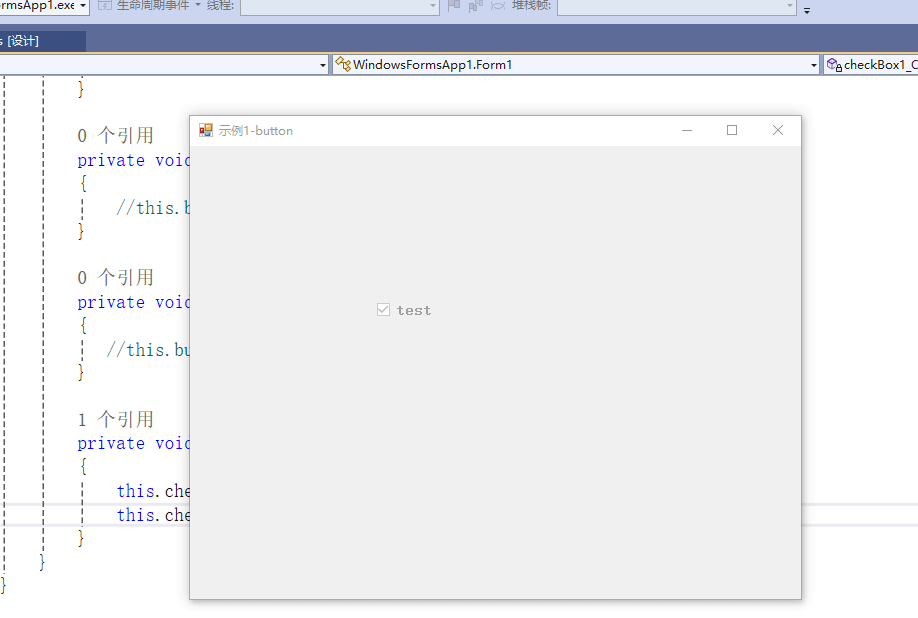
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...