强化学习-python案例
强化学习是一种机器学习方法,旨在通过与环境的交互来学习最优策略。它的核心概念是智能体(agent)在环境中采取动作,从而获得奖励或惩罚。智能体的目标是最大化长期奖励,通过试错的方式不断改进其决策策略。
在强化学习中,智能体观察当前状态,选择动作,并根据环境反馈(奖励和下一个状态)调整其策略。常见的强化学习算法包括Q-learning、策略梯度方法和深度强化学习等。强化学习广泛应用于游戏、机器人控制、推荐系统等领域。
-
奖励(Reward):
r t = R ( s t , a t ) r_t = R(s_t, a_t) rt=R(st,at)
其中 r t r_t rt 是在时间步 t t t 时,智能体在状态 s t s_t st 下采取动作 a t a_t at 所获得的奖励。 -
状态价值函数(State Value Function):
V ( s ) = E [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s ] V(s) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t r_t \mid s_0 = s \right] V(s)=E[t=0∑∞γtrt∣s0=s]
其中 V ( s ) V(s) V(s) 是状态 s s s 的价值, γ \gamma γ 是折扣因子 ( 0 ≤ γ < 1 ( 0 \leq \gamma < 1 (0≤γ<1),表示未来奖励的重要性。 -
动作价值函数(Action Value Function):
Q ( s , a ) = E [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s , a 0 = a ] Q(s, a) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t r_t \mid s_0 = s, a_0 = a \right] Q(s,a)=E[t=0∑∞γtrt∣s0=s,a0=a]
其中 Q ( s , a ) Q(s, a) Q(s,a) 是在状态 s s s 下采取动作 a a a 的价值。 -
贝尔曼方程(Bellman Equation):
- 状态价值函数的贝尔曼方程:
V ( s ) = ∑ a π ( a ∣ s ) ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V ( s ′ ) ] V(s) = \sum_{a} \pi(a \mid s) \sum_{s', r} P(s', r \mid s, a) \left[ r + \gamma V(s') \right] V(s)=a∑π(a∣s)s′,r∑P(s′,r∣s,a)[r+γV(s′)] - 动作价值函数的贝尔曼方程:
Q ( s , a ) = ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ max a ′ Q ( s ′ , a ′ ) ] Q(s, a) = \sum_{s', r} P(s', r \mid s, a) \left[ r + \gamma \max_{a'} Q(s', a') \right] Q(s,a)=s′,r∑P(s′,r∣s,a)[r+γa′maxQ(s′,a′)]
- 状态价值函数的贝尔曼方程:
-
策略(Policy):
π ( a ∣ s ) = P ( a ∣ s ) \pi(a \mid s) = P(a \mid s) π(a∣s)=P(a∣s)
其中 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 是在状态 s s s 下选择动作 a a a 的概率。
目标函数
- 策略梯度目标函数:
J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T r t ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T} r_t \right] J(θ)=Eτ∼πθ[t=0∑Trt]- 说明: J ( θ ) J(\theta) J(θ) 是关于策略参数 θ \theta θ 的目标函数,表示在策略 π θ \pi_\theta πθ 下,执行轨迹 τ \tau τ 的预期总奖励。目标是最大化该期望值,通常通过梯度上升方法进行优化。
损失函数
-
策略损失函数(使用REINFORCE算法):
L ( θ ) = − E τ ∼ π θ [ ∑ t = 0 T r t log π θ ( a t ∣ s t ) ] L(\theta) = -\mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T} r_t \log \pi_\theta(a_t \mid s_t) \right] L(θ)=−Eτ∼πθ[t=0∑Trtlogπθ(at∣st)]- 说明:这个损失函数的目的是最小化负的期望总奖励。通过优化该损失函数,可以最大化目标函数 J ( θ ) J(\theta) J(θ)。这里的 log π θ ( a t ∣ s t ) \log \pi_\theta(a_t \mid s_t) logπθ(at∣st) 是对策略的对数概率,表示在状态 s t s_t st 下采取动作 a t a_t at 的可能性。
-
价值函数损失(对于Q-learning):
L ( θ ) = E [ ( r t + γ max a ′ Q ( s ′ , a ′ ; θ ) − Q ( s , a ; θ ) ) 2 ] L(\theta) = \mathbb{E} \left[ \left( r_t + \gamma \max_{a'} Q(s', a'; \theta) - Q(s, a; \theta) \right)^2 \right] L(θ)=E[(rt+γa′maxQ(s′,a′;θ)−Q(s,a;θ))2]- 说明:该损失函数用于最小化当前动作价值函数 Q ( s , a ; θ ) Q(s, a; \theta) Q(s,a;θ) 和目标价值 r t + γ max a ′ Q ( s ′ , a ′ ; θ ) r_t + \gamma \max_{a'} Q(s', a'; \theta) rt+γmaxa′Q(s′,a′;θ) 之间的均方误差。通过最小化该损失,更新网络参数 θ \theta θ 以更准确地预测价值。
细节总结
- 目标函数:用于衡量当前策略的性能,指导优化过程。强化学习的目标是通过更新策略来最大化期望奖励。
- 损失函数:是优化过程中实际最小化的函数,直接反映模型的学习效果。损失函数的设计直接影响学习的效率和效果。
这些公式是强化学习中策略优化和价值评估的核心,理解它们有助于深入掌握强化学习的理论基础和应用。
代码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 环境假设
class SimpleEnv:def reset(self):return np.random.rand(4) # 随机状态def step(self, action):next_state = np.random.rand(4)reward = np.random.rand() # 随机奖励done = np.random.rand() > 0.9 # 随机结束return next_state, reward, done# 策略网络
class PolicyNetwork(nn.Module):def __init__(self):super(PolicyNetwork, self).__init__()self.fc = nn.Sequential(nn.Linear(4, 128),nn.ReLU(),nn.Linear(128, 2), # 假设有两个动作)def forward(self, x):return torch.softmax(self.fc(x), dim=-1)# 计算折扣奖励
def compute_discounted_rewards(rewards, discount_factor=0.99):discounted_rewards = []cumulative_reward = 0for r in reversed(rewards):cumulative_reward = r + cumulative_reward * discount_factordiscounted_rewards.insert(0, cumulative_reward)return discounted_rewards# 训练函数
def train(env, policy_net, optimizer, episodes=1000):for episode in range(episodes):state = env.reset()rewards = []log_probs = []while True:state_tensor = torch.FloatTensor(state)probs = policy_net(state_tensor)action = np.random.choice(len(probs), p=probs.detach().numpy())log_prob = torch.log(probs[action])next_state, reward, done = env.step(action)log_probs.append(log_prob)rewards.append(reward)state = next_stateif done:break# 计算折扣奖励discounted_rewards = compute_discounted_rewards(rewards)# 更新策略optimizer.zero_grad()loss = -sum(log_prob * reward for log_prob, reward in zip(log_probs, discounted_rewards))loss.backward()optimizer.step()# 输出每个回合的总奖励total_reward = sum(rewards)print(f"Episode {episode + 1}, Total Reward: {total_reward:.2f}")# 测试函数
def test(env, policy_net, episodes=10):for episode in range(episodes):state = env.reset()total_reward = 0while True:state_tensor = torch.FloatTensor(state)with torch.no_grad():probs = policy_net(state_tensor)action = torch.argmax(probs).item()next_state, reward, done = env.step(action)total_reward += rewardstate = next_stateif done:breakprint(f"Test Episode {episode + 1}, Total Reward: {total_reward:.2f}")# 主程序
env = SimpleEnv()
policy_net = PolicyNetwork()
optimizer = optim.Adam(policy_net.parameters(), lr=0.01)train(env, policy_net, optimizer)
test(env, policy_net)
训练奖励图:显示每个训练回合的总奖励变化,帮助评估模型在训练过程中的学习效果。
测试奖励图:展示在测试回合中模型的总奖励,反映训练后的表现。
代码结构
-
环境(Environment)
SimpleEnv类:模拟一个简单的环境,包含reset和step方法。reset():初始化并返回一个随机状态。step(action):根据所采取的动作返回下一个状态、奖励和是否结束标志。- 奖励和结束状态是随机生成的,模拟了一个非常简化的环境。
-
策略网络(Policy Network)
PolicyNetwork类:定义一个神经网络,用于近似策略。- 使用全连接层,输入状态维度为 4(环境状态的维度),输出动作概率的维度为 2(假设有两个可能的动作)。
forward方法通过 softmax 函数输出每个动作的概率。
-
折扣奖励计算
compute_discounted_rewards(rewards, discount_factor=0.99):计算每个时间步的折扣奖励。- 从后往前遍历奖励列表,使用折扣因子更新累计奖励,生成折扣奖励列表。
-
训练函数(Training Function)
train(env, policy_net, optimizer, episodes=1000):进行训练的主函数。- 循环执行指定的回合数:
- 重置环境,初始化奖励和日志概率列表。
- 在回合中循环,使用当前状态选择动作并记录日志概率和奖励。
- 计算并更新策略网络的损失,使用反向传播更新参数。
- 每个回合结束后打印总奖励,帮助监控训练进度。
- 循环执行指定的回合数:
-
测试函数(Testing Function)
test(env, policy_net, episodes=10):用于评估训练后模型表现的函数。- 重置环境并执行多个测试回合,选择最大概率的动作。
- 累计并打印每个测试回合的总奖励,评估训练的效果。
-
主程序
- 创建环境和策略网络实例,定义优化器(Adam)。
- 调用训练函数进行训练,然后调用测试函数进行评估。
整体逻辑
-
环境设置:定义了一个非常简单的环境,主要用于演示如何应用策略梯度方法。实际应用中,可以替换为更复杂的环境,比如OpenAI的Gym库中的环境。
-
策略学习:使用神经网络近似策略,通过与环境的交互收集状态、动作、奖励,并更新网络参数,以优化策略。
-
输出和评估:通过在训练过程中的总奖励输出和测试过程中的评估,可以观察到模型的学习进展。
小结
这段代码是一个简单的强化学习示例,展示了如何使用策略梯度方法和PyTorch进行训练和测试。虽然环境和任务是简化的,但它提供了一个良好的基础,便于理解强化学习的核心概念和实现。
相关文章:
强化学习-python案例
强化学习是一种机器学习方法,旨在通过与环境的交互来学习最优策略。它的核心概念是智能体(agent)在环境中采取动作,从而获得奖励或惩罚。智能体的目标是最大化长期奖励,通过试错的方式不断改进其决策策略。 在强化学习…...

Element UI教程:如何将Radio单选框的圆框改为方框
大家好,今天给大家带来一篇关于Element UI的使用技巧。在项目中,我们经常会用到Radio单选框组件,默认情况下,Radio单选框的样式是圆框。但有时候,为了满足设计需求,我们需要将圆框改为方框,如下…...

vue3结合 vue-router和keepalive实现路由跳转保持滚动位置不改变(超级简易清晰)
1.首先我们在路由跳转页面设置keepalive(Seeall是我想实现结果的页面) 2. 想实现结果的页面中如果不是全屏实现滚动而是有单独的标签实现滚动效果...

PostgreSQL 字段使用pglz压缩测试
PostgreSQL 字段使用pglz压缩测试 测试一: 创建测试表 yewu1.test1,并插入1000w行数据 创建测试表 yewu1.test2,使用 pglz压缩字段,并插入1000w行数据–创建测试表1,并插入1000w行数据 white# create table yewu1.t…...

基于大数据的学生体质健康信息系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

【STM32】 TCP/IP通信协议(1)--LwIP介绍
一、前言 TCP/IP是干啥的?它跟SPI、IIC、CAN有什么区别?它如何实现stm32的通讯?如何去配置?为了搞懂这些问题,查询资料可解决如下疑问: 1.为什么要用以太网通信? 以太网(Ethernet) 是指遵守 IEEE 802.3 …...

828华为云征文|部署音乐流媒体服务器 mStream
828华为云征文|部署音乐流媒体服务器 mStream 一、Flexus云服务器X实例介绍二、Flexus云服务器X实例配置2.1 重置密码2.2 服务器连接2.3 安全组配置2.4 Docker 环境搭建 三、Flexus云服务器X实例部署 mStream3.1 mStream 介绍3.2 mStream 部署3.3 mStream 使用 四、…...
】力扣712. 两个字符串的最小ASCII删除和)
【动态规划-最长公共子序列(LCS)】力扣712. 两个字符串的最小ASCII删除和
给定两个字符串s1 和 s2,返回 使两个字符串相等所需删除字符的 ASCII 值的最小和 。 示例 1: 输入: s1 “sea”, s2 “eat” 输出: 231 解释: 在 “sea” 中删除 “s” 并将 “s” 的值(115)加入总和。 在 “eat” 中删除 “t” 并将 116 加入总和。 结束时&…...

override
override 是 C11 引入的一个关键字,override 的作用是在派生类中显式地声明某个函数是用于重写基类的虚函数。它不仅仅是一个语法标记,更重要的是提供了编译时的错误检查功能,确保程序员确实按照预期在派生类中重写了基类的函数。如果没有正确…...

万象奥科工业平板上线,邀您体验与众不同!
Vanxoak推出的全新品类——ARM工业平板电脑!该系列工业平板具有防护等级高、接口丰富、易开发等特点,专为工业HMI(人机界面)和工业控制领域设计。整机采用高性能工业级ARM处理器,适配全贴合电容触摸屏,可选…...

java将word转pdf
总结 建议使用aspose-words转pdf,poi的容易出问题还丑… poi的(多行的下边框就不对了) aspose-words的(基本和word一样) poi工具转换 <!-- 处理PDF --><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres…...

Golang | Leetcode Golang题解之第449题序列化和反序列化二叉搜索树
题目: 题解: type Codec struct{}func Constructor() (_ Codec) { return }func (Codec) serialize(root *TreeNode) string {arr : []string{}var postOrder func(*TreeNode)postOrder func(node *TreeNode) {if node nil {return}postOrder(node.Le…...

基于SpringBoot+Vue+MySQL的美食信息推荐系统
系统展示 用户前台界面 管理员后台界面 系统背景 在数字化时代,随着人们对美食文化的热爱与追求不断增长,美食信息推荐系统成为了连接食客与美食之间的重要桥梁。面对海量的美食信息,用户往往难以快速找到符合个人口味和需求的美食。因此&…...

spring boot jar 分离自动部署脚本
背景 远程部署时spring boot 包,比较大。可以采用依赖库和业务包分离的方式。提供一个脚本进行自动部署 maven 配置分离jar包 <build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springfra…...

PGMP-03战略一致性
1.概要 program strategy alignment:战略一致性 2.详细...

华为OD机试真题---智能成绩表
题目描述 小明来到某学校当老师,需要将学生按考试总分或单科分数进行排名。输入包括学生人数、科目数量、科目名称、每个学生的姓名和对应科目的成绩,最后输入一个用作排名的科目名称。如果输入的排名科目不存在,则按总分进行排序。输出一行…...

828华为云征文 | 华为云Flexus云服务器X实例搭建企业内部VPN私有隧道,以实现安全远程办公
VPN虚拟专用网络适用于企业内部人员流动频繁和远程办公的情况,出差员工或在家办公的员工利用当地ISP就可以和企业的VPN网关建立私有的隧道连接。 通过拨入当地的ISP进入Internet再连接企业的VPN网关,在用户和VPN网关之间建立一个安全的“隧道”ÿ…...
:NameNode和resourcemanager高可用的搭建)
Hadoop集群的高可用(HA):NameNode和resourcemanager高可用的搭建
文章目录 一、NameNode高可用的搭建1、免密配置2、三个节点都需要安装psmisc3、检查三个节点是否都安装jdk以及zk4、检查是否安装了hadoop集群5、修改hadoop-env.sh6、修改core-site.xml7、修改hdfs-site.xml8、检查workers 文件是否为三台服务9、分发给其他两个节点10、初始化…...

支付宝沙箱环境 支付
一 什么是沙箱: 沙箱环境是支付宝开放平台为开发者提供的安全低门槛的测试环境 支付宝正式和沙箱环境的区别 : AI: 从沙箱到正式环境: 当应用程序开发完成后,需要将应用程序从沙箱环境迁移到正式环境。 这通常涉及…...

获取unity中prefab的中文文本内容以及和prefab有关的问题
背景1:经常会在开发中遇到策划需要改某个界面,但是我们不知道那是什么界面,只看到一些关键字比如圣诞活动,那这样我就可以轻易找到这个预设了。另外还可以扩展就是收集项目中的所有中文文本然后归集到多语言表中,然后接…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
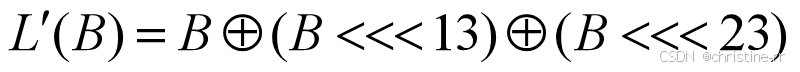
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...

基于开源AI智能名片链动2 + 1模式S2B2C商城小程序的沉浸式体验营销研究
摘要:在消费市场竞争日益激烈的当下,传统体验营销方式存在诸多局限。本文聚焦开源AI智能名片链动2 1模式S2B2C商城小程序,探讨其在沉浸式体验营销中的应用。通过对比传统品鉴、工厂参观等初级体验方式,分析沉浸式体验的优势与价值…...