【LeetCode HOT 100】详细题解之链表篇
LeetCode HOT 100题解之链表篇
- 160 相交链表
- 题目分析
- 代码
- 206 反转链表
- 方法一:迭代
- 234 回文链表
- 方法一:将值复制到数组中
- 方法二:快慢指针
- 141 环形链表
- 方法一:哈希表
- 方法二:快慢指针
- 142 环形链表II
- 方法一:哈希表
- 方法二:快慢指针
- 21 合并两个有序链表
- 方法一:递归
- 方法二:迭代
- 2 两数相加
- 方法一:模拟
- 19 删除链表的倒数第N个结点
- 方法一:计算链表长度
- 方法二:栈
- 方法三:快慢指针
- 24 两两交换链表中的节点
- 方法一:迭代
- 方法二:递归
- 25 K个一组反转链表
- 方法一:模拟
- 138 随机链表的复制
- 方法一:哈希表
- 148 排序列表
- 方法一:归并排序(递归法)
- 23 合并K个升序链表
- 方法一:分治法
- 146 LRU缓存
- 方法一:哈希表+双向链表
160 相交链表
160. 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
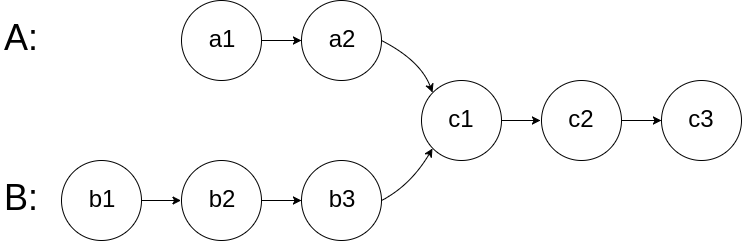
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:

输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:

输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA中节点数目为mlistB中节点数目为n1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA] == listB[skipB]
**进阶:**你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
题目分析
//只能说题目思想nb!//现在假设有A,B两个链表,A长度为5,B长度为3//那么,假如我用一个指针pa先遍历A,再遍历B,另一个指针pb先遍历B,再遍历A//这样pa和pb遍历的长度最终都会是5+3 = 3 + 5 = 8//那么,最终pa和pb一定会在A和B相交的节点相遇 //可以简单证明一下,假设A,B相交的节点数为c,A的总结点数为m+c,B的为n+c//那么当A,B通过这样的方式相遇时,pa走过来m+c+n,pb走过了n+c+m,此时正好pa和pb会在相交点相遇(对于A,B而言剩下c)
代码
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {//只能说题目思想nb!//现在假设有A,B两个链表,A长度为5,B长度为3//那么,假如我用一个指针pa先遍历A,再遍历B,另一个指针pb先遍历B,再遍历A//这样pa和pb遍历的长度最终都会是5+3 = 3 + 5 = 8//那么,最终pa和pb一定会在A和B相交的节点相遇 //可以简单证明一下,假设A,B相交的节点数为c,A的总结点数为m+c,B的为n+c//那么当A,B通过这样的方式相遇时,pa走过来m+c+n,pb走过了n+c+m,此时正好pa和pb会在相交点相遇(对于A,B而言剩下c)ListNode pA = headA,pB = headB;if(pA == null || pB == null){return null;}while(pA != pB){pA = pA == null? headB : pA.next;pB = pB == null? headA : pB.next;}return pA;}
}
206 反转链表
206. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:

输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
方法一:迭代
假设链表为 1→2→3→∅,我们想要把它改成 ∅←1←2←3。
在遍历链表时,将当前节点的 next 指针改为指向前一个节点。由于节点没有引用其前一个节点,因此必须事先存储其前一个节点。在更改引用之前,还需要存储后一个节点。最后返回新的头引用。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode reverseList(ListNode head) {//迭代的话需要将链表节点的指针反向//在这里我们考虑三个节点,prev,curr,next 分别代表上一个,当前和下一个节点//需要将curr.next指向prev,所以next需要记录原本的curr下一个节点//并且由于节点没有引用前一个节点,因此需要事先存储前一个节点。在更改引用之前,还需要存储后一个节点//比较巧妙的是另prev = null,这样可以直接从头开始遍历,不用考虑头节点的特殊情况ListNode prev = null;ListNode curr = head;while(curr != null){ListNode next = curr.next;//更改引用之前需要存储后一个节点curr.next = prev;//更改引用prev = curr;//更新前一个节点curr = next;//更新当前节点}return prev;//因为curr此时会指向null}
}
234 回文链表
234. 回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

输入:head = [1,2,2,1]
输出:true
示例 2:

输入:head = [1,2]
输出:false
提示:
- 链表中节点数目在范围
[1, 105]内 0 <= Node.val <= 9
**进阶:**你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
方法一:将值复制到数组中
很直观,判断一个数组是否是回文很简单,但是判断链表存在难度。想要判断数组是否回文可以直接使用双指针的方法。因此方法一是简单的将链表中的值复制到数组中。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public boolean isPalindrome(ListNode head) {/**方法一:将值复制到数组中后用双指针法 */List<Integer> list = new ArrayList<Integer> ();ListNode temp=head;while(temp!=null){list.add(temp.val);temp = temp.next;}int front = 0,end = list.size()-1;while(front <= end){if(list.get(front)!=list.get(end)){return false;}front++;end--;}return true;}
}
方法二:快慢指针
避免O(n)额外空间的方法就是改变输入。
可以考虑反转链表的后半部分,之后判断后半部分反转后的链表与前半部分是否相同。最后恢复链表,返回结果1.找到前半部分链表的尾节点 (使用快慢指针)2.反转后半部分链表3.判断是否回文4.恢复链表5.返回结果
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public boolean isPalindrome(ListNode head) {/**方法三:快慢指针可以考虑反转链表的后半部分,之后判断后半部分反转后的链表与前半部分是否相同。最后恢复链表,返回结果1.找到前半部分链表的尾节点 (使用快慢指针)2.反转后半部分链表3.判断是否回文4.恢复链表5.返回结果*/ListNode firstHalfEnd = endOfFirstHalf(head);ListNode secondHalfStart = reverseList(firstHalfEnd.next);//反转后半部分的链表ListNode p1 = head;ListNode p2 = secondHalfStart;boolean flag = true;while(flag && p2!=null){if(p1.val != p2.val){flag = false;}p1 = p1.next;p2 = p2.next;}firstHalfEnd.next = reverseList(secondHalfStart);return flag;}private ListNode reverseList(ListNode head){ListNode curr = head;ListNode prev = null;while(curr != null){ListNode next = curr.next;curr.next = prev;prev = curr; //更新前一个节点curr = next; //更新后一个节点}return prev; //注意,到最后curr是null,因此要返回prev}//使用快慢指针找到前面链表的最后一个节点,当链表长度为奇数时,将中间的奇数节点认为是前半部分。举个例子//1,2,3,4,5 ://fast:1,3,5//slow:1,2,3//1,2,3,4//fast:1,3,//slow:1,2,private ListNode endOfFirstHalf(ListNode head){ListNode slow = head;ListNode fast = head;while(fast.next != null && fast.next.next !=null){slow = slow.next;fast = fast.next.next;}return slow;}
}
141 环形链表
141. 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
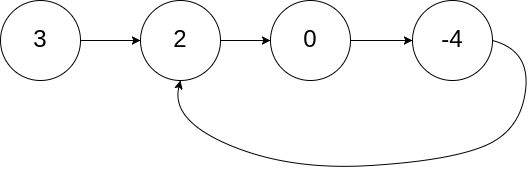
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
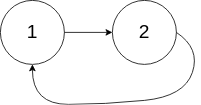
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
提示:
- 链表中节点的数目范围是
[0, 104] -105 <= Node.val <= 105pos为-1或者链表中的一个 有效索引 。
**进阶:**你能用 O(1)(即,常量)内存解决此问题吗?
方法一:哈希表
判断是否存在环,就是遍历所有节点,每次遍历到一个节点,就判断该节点此前是否被访问过。
用哈希表存储所有已经访问过的节点,每次到达一个界定啊,如果该节点已经存在于哈希表中,则说明该链表是环形链表,否则就将该节点加入哈希表中。重复,直至遍历完所有链表。
- 复杂度分析
- 时间复杂度:O(N),其中 N 是链表中的节点数。最坏情况下我们需要遍历每个节点一次。
- 空间复杂度:O(N),其中 N 是链表中的节点数。主要为哈希表的开销,最坏情况下我们需要将每个节点插入到哈希表中一次。
/*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public boolean hasCycle(ListNode head) {//最简单的hash表Set<ListNode> set = new HashSet<ListNode>();ListNode temp = head;while(temp != null){if(!set.add(temp)){return true;}temp = temp.next;}return false;}
}
方法二:快慢指针
方法二:快慢指针Floyd判圈算法(龟兔赛跑算法)假设乌龟和兔子在链表上移动,假如链表中没有环,那么兔子会一直在乌龟的前方。但是如果存在环,那么兔子会先于乌龟进入环,之后一直在环中移动。等乌龟进入环后,由于兔子速度快,兔子一定会在某一时刻与乌龟相遇。若不存在环,那么直接当兔子跑到终点的时候结束实现起来也是,一个while循环判断slow是否等于fast如果能跳出while循环,说明slot == fast,存在环同时在while内部还要设置终止条件,即fast.next == null或者fast.next.next == null
/*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public boolean hasCycle(ListNode head) {/**方法二:快慢指针Floyd判圈算法(龟兔赛跑算法)假设乌龟和兔子在链表上移动,假如链表中没有环,那么兔子会一直在乌龟的前方。但是如果存在环,那么兔子会先于乌龟进入环,之后一直在环中移动。等乌龟进入环后,由于兔子速度快,兔子一定会在某一时刻与乌龟相遇。若不存在环,那么直接当兔子跑到终点的时候结束实现起来也是,一个while循环判断slow是否等于fast如果能跳出while循环,说明slot == fast,存在环同时在while内部还要设置终止条件,即fast.next == null或者fast.next.next == null*/if(head == null || head.next == null){return false;} ListNode slow = head;ListNode fast = head.next;while(slow != fast ){ //能跳出循环,说明slow == fast,所以if(fast.next==null || fast.next.next == null){return false;}slow = slow.next;fast = fast.next.next;}return true;}
}
142 环形链表II
142. 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
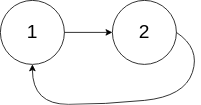
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -105 <= Node.val <= 105pos的值为-1或者链表中的一个有效索引
**进阶:**你是否可以使用 O(1) 空间解决此题?
方法一:哈希表
哈希表的实现思路同上题,此处不再过多赘述
/*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public ListNode detectCycle(ListNode head) {Set<ListNode> set = new HashSet<ListNode>();ListNode temp = head;while(temp != null){if(!set.add(temp)){return temp;}temp = temp.next;}return null;}
}
方法二:快慢指针
重画链表如下所示,线上有若干个节点。记蓝色慢指针为 slow,红色快指针为 fast。初始时 slow 和 fast 均在头节点处。 使 slow 和 fast 同时前进,fast 的速度是 slow 的两倍。当 slow 抵达环的入口处时,fast 一定在环上,如下所示。
使 slow 和 fast 同时前进,fast 的速度是 slow 的两倍。当 slow 抵达环的入口处时,fast 一定在环上,如下所示。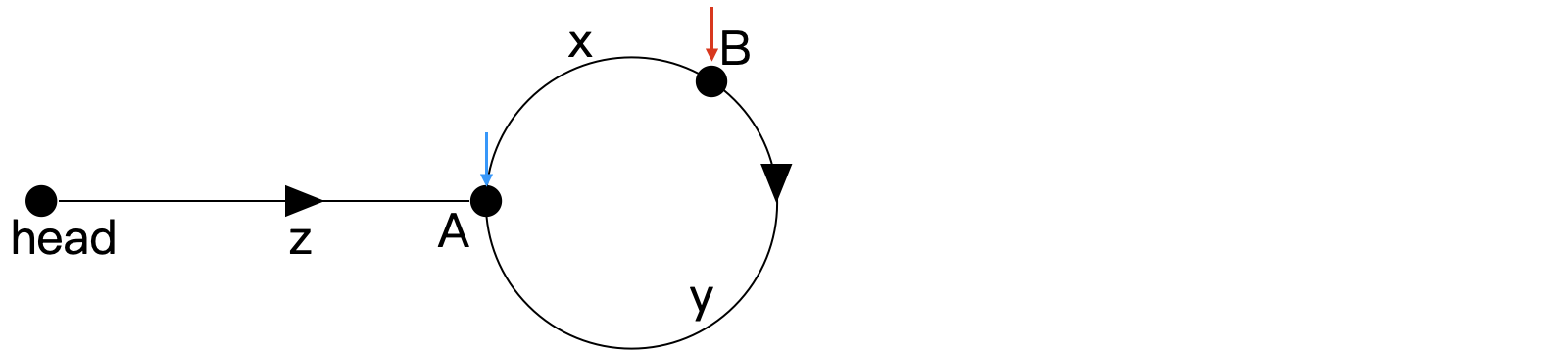 其中:
其中:
- head 和 A 的距离为 z
- 弧 AB (沿箭头方向) 的长度为 x
- 同理,弧 BA 的长度为 y
可得:
- slow 走过的步数为 z
- 设 fast 已经走过了 k 个环,k≥0,对应的步数为 z+k(x+y)+x
以上两个步数中,后者为前者的两倍,即 2z=z+k(x+y)+x 化简可得 z=x+k(x+y),替换如下所示。
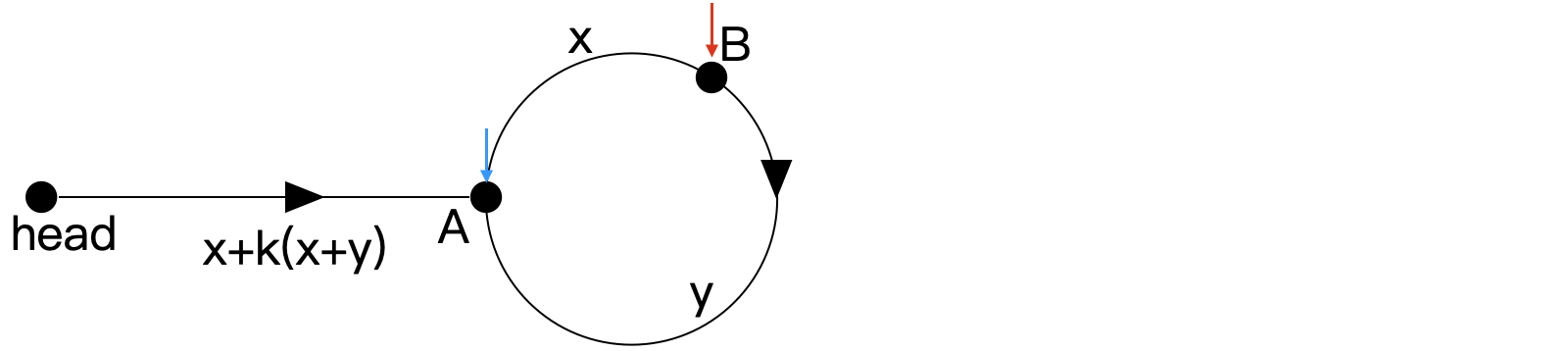 此时因为 fast 比 slow 快 1 个单位的速度,且y 为整数,所以再经过 y 个单位的时间即可追上 slow。
此时因为 fast 比 slow 快 1 个单位的速度,且y 为整数,所以再经过 y 个单位的时间即可追上 slow。
即 slow 再走 y 步,fast 再走 2y 步。设相遇在 C 点,位置如下所示,可得弧 AC 长度为 y。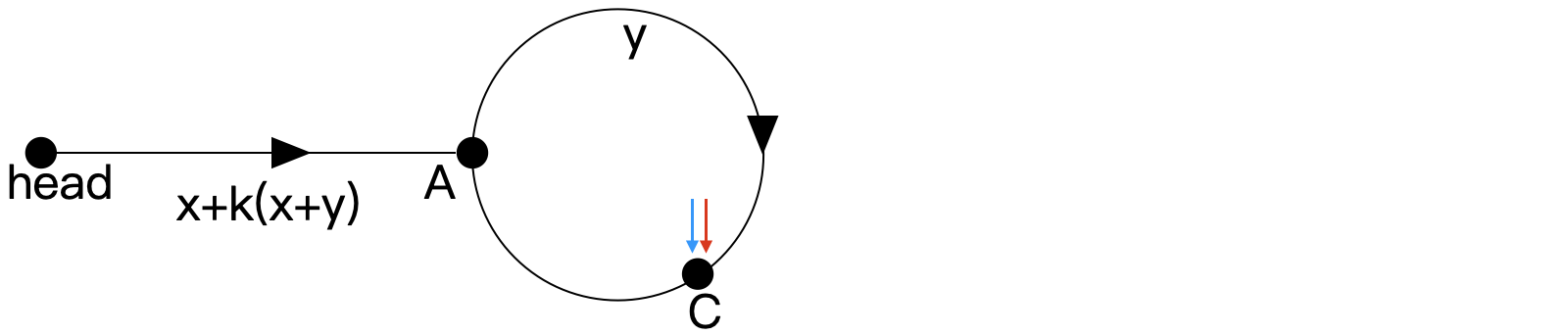 因为此前x+y 为环长,所以弧 CA 的长度为 x。 此时我们另用一橙色指针 ptr (pointer) 指向 head,如下所示。并使 ptr 和 slow 保持 1 个单位的速度前进,在经过 z=x+k(x+y) 步后,可在 A 处相遇。
因为此前x+y 为环长,所以弧 CA 的长度为 x。 此时我们另用一橙色指针 ptr (pointer) 指向 head,如下所示。并使 ptr 和 slow 保持 1 个单位的速度前进,在经过 z=x+k(x+y) 步后,可在 A 处相遇。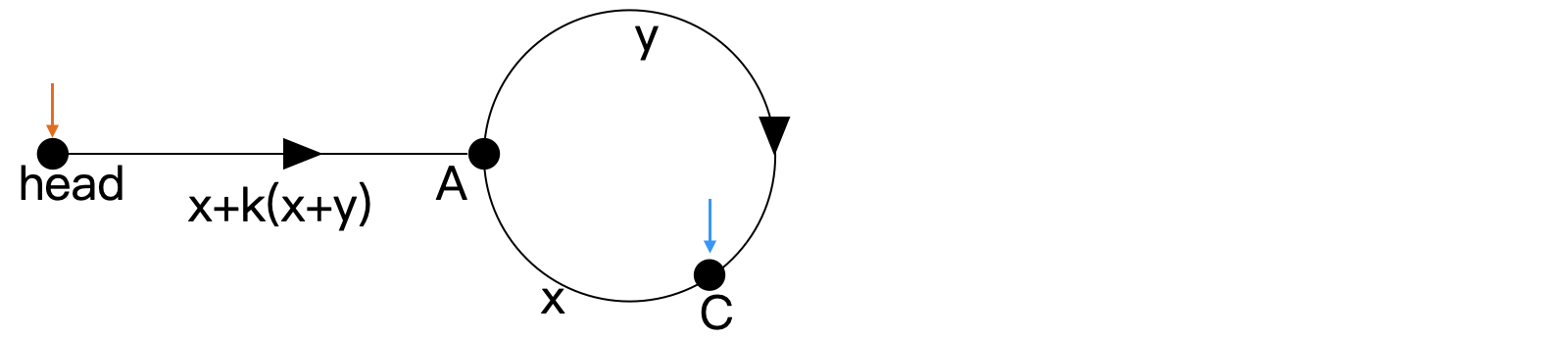 再考虑链表无环的情况,fast 在追到 slow 之前就会指向空节点,退出循环即可。
再考虑链表无环的情况,fast 在追到 slow 之前就会指向空节点,退出循环即可。
/*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public ListNode detectCycle(ListNode head) {/**方法二:快慢指针。这里需要具体原理需要参考题解。在这里就简单说一下做法。同样设置快慢指针fast和slow,均位于list的头部。我们设链表中环外的长度为z,当slow指针位于环的入口时,fast指针距离环的入口长度为x,圆的总周长为x+y那么此时slow走的长度为z,fast走的长度为z+k(x+y)+x2z = z+k(x+y)+x,解出可得,z = k(x+y)+x此时,若slow想与fast相遇,假如slow静止,fast相对于slow的速度为1,此时fast还需要经过y步才能与slow相遇。即,slow与fast相遇时,slow距离环的入口长度为y,若slow需要再回到入口,需要走x+y-y =x 步这时假如我们另一个额外指针ptr从head处开始遍历,那么ptr会和slow在环的入口处相遇。因为ptr需要走z = k(x+y)+x 到达入口,slow 会走x+k(x+y)到达入口*/if(head == null || head.next == null){return null;}ListNode slow = head;ListNode fast = head;do{if(fast.next == null || fast.next.next == null){return null;}slow = slow.next;fast = fast.next.next;}while(slow != fast);ListNode ptr = head;while(ptr != slow){ptr = ptr.next;slow = slow.next;}return ptr;}
}
21 合并两个有序链表
21. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
方法一:递归
本来以为递归解法会很难,后面发现只要写出了递归表达式,并且清楚边界条件,递归解法会比其他解法更加容易。
在这里我们已知有两个链表l1,l2。可以给出如下的递归定义。两个链表头部值较小的一个节点与剩下元素的merge操作结果合并。
{ l i s t 1 [ 0 ] + m e r g e ( l i s t 1 [ 1 : ] , l i s t 2 ) l i s t 1 [ 0 ] < l i s t 2 [ 0 ] l i s t 2 [ 0 ] + m e r g e ( l i s t 1 , l i s t 2 [ 1 : ] ) o t h e r w i s e \left.\left\{\begin{array}{ll}list1[0]+merge(list1[1:],list2)&list1[0]<list2[0]\\list2[0]+merge(list1,list2[1:])&otherwise\end{array}\right.\right. {list1[0]+merge(list1[1:],list2)list2[0]+merge(list1,list2[1:])list1[0]<list2[0]otherwise
所以思路就是,如果l1或者l2为空,不需要合并,直接返回非空链表即可。若l1.val<l2.val那么l1需要被添加到结果里,然后继续合并l1.next = merge(l1.next,l2). 如果两个链表钟有一个为空,递归结束。
其实核心思想都是需要将较小值添加到结果中,之后再去决定下一个要添加到结果里的节点。
代码如下
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {/**方法一:递归递归定义两个链表中的merge操作list1[0]<list2[0],list1[0]+merge(list[1:],list2)otherwise,list2[0]+merge(list1,list2[1:])*/if(list1 == null){return list2;}else if(list2 == null){return list1;}else if(list1.val < list2.val){list1.next = mergeTwoLists(list1.next,list2);return list1;}else{list2.next = mergeTwoLists(list1,list2.next);return list2;}}
}
方法二:迭代
当l1,l2都不是空链表的时候,判断l1和l2哪一个链表的头节点值更小,将较小值的节点添加到结果中,当一个节点被添加到结果里后,将对应链表里的节点后移一位
一开始没想到的是,对结果链表最好初始化一个头节点和遍历的节点,不然直接在list1和list2上操作会有点乱
想到需要结果链表之后就容易了。
定义一个prevHead作为结果链表的哨兵节点,维护curr指针指向当前遍历的元素。
需要不停的修改curr的next,直到l1或者l2为null:
如果当前l1.val<l2.val,那么curr.next = l1,l1 = l1.next;
否则curr.next = l2,l2=l2.next;
不管哪个元素接在了结果链表的后面,都需要将curr指针后移
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {/**方法二:迭代当l1,l2都不是空链表的时候,判断l1和l2哪一个链表的头节点值更小,将较小值的节点添加到结果中,当一个节点被添加到结果里后,将对应链表里的节点后移一位一开始没想到的是,对结果链表最好初始化一个头节点和遍历的节点,不然直接在list1和list2上操作会有点乱想到需要结果链表之后就容易了。定义一个prevHead作为结果链表的哨兵节点,维护curr指针指向当前遍历的元素。需要不停的修改curr的next,直到l1或者l2为null:如果当前l1.val<l2.val,那么curr.next = l1,l1 = l1.next;否则curr.next = l2,l2=l2.next;不管哪个元素接在了结果链表的后面,都需要将curr指针后移。*/ListNode prevHead = new ListNode();ListNode curr = prevHead;while(list1 != null && list2 != null){ListNode temp;if(list1.val < list2.val){//将list1的当前节点添加到结果中temp = list1.next;curr.next = list1;list1 = list1.next;}else{temp = list2.next;curr.next = list2;list2 = list2.next;}curr = curr.next;//移动结果指针}curr.next = list1==null?list2 : list1;return prevHead.next;}
}
2 两数相加
2. 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
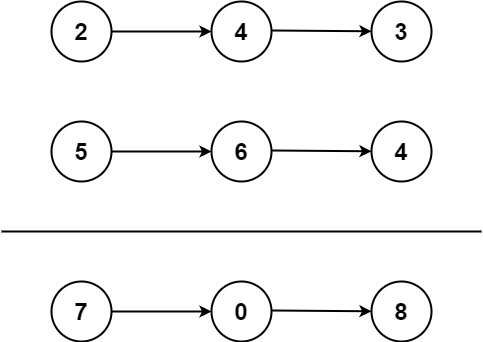
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
提示:
- 每个链表中的节点数在范围
[1, 100]内 0 <= Node.val <= 9- 题目数据保证列表表示的数字不含前导零
方法一:模拟
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode addTwoNumbers(ListNode l1, ListNode l2) {ListNode dummpy = new ListNode();//定义哑节点ListNode curr = dummpy;int carry = 0;while(l1!=null || l2!=null ){int a = l1!=null ?l1.val :0;int b = l2!=null ?l2.val : 0;int sum = a+b+carry;curr.next = new ListNode(sum%10);curr = curr.next;carry = sum /10;if(l1 != null) l1 = l1.next;if(l2 != null ) l2 = l2.next;}if(carry >0){curr.next = new ListNode(carry);}return dummpy.next;}
}
19 删除链表的倒数第N个结点
19. 删除链表的倒数第 N 个结点
提示
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
**进阶:**你能尝试使用一趟扫描实现吗?
方法一:计算链表长度
关于这种删除第几个节点的题,我总是有点不明白应该如何写循环才能遍历到第n个节点。需要手动模拟
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode removeNthFromEnd(ListNode head, int n) {//思路很直接,先遍历一遍链表,获得链表长度L,之后再从头节点开始对链表进行一次遍历,当遍历到第L-n+1个节点时,它就是我们需要删除的节点。(链表长度为5时,要删除倒数第2个节点等价于要删除第4个节点)//为了方便删除,引入一个dummpyNode,此时,遍历到的第L-n+1个节点时,下一个节点就是我们要是删除的节点。int L = getLength(head);//引入dummpyNodeListNode dummpy = new ListNode(0,head);//遍历到第L-n+1个节点//现在length=5,n=2,我们想要删除的是第L-n+1 = 4个节点//因此,需要循环执行3次,让指针指向想要删除的节点的前一个节点,//所以另i=1ListNode curr = dummpy;for(int i = 1;i<L-n+1;i++){curr =curr.next;}//删除节点curr.next = curr.next.next;return dummpy.next;}public int getLength(ListNode head){int n = 0;while(head != null){head = head.next;n++;}return n;}
}
方法二:栈
我们也可以在遍历链表的同时将所有节点依次入栈。根据栈「先进后出」的原则,我们弹出栈的第 n 个节点就是需要删除的节点,并且目前栈顶的节点就是待删除节点的前驱节点。这样一来,删除操作就变得十分方便了。
复杂度分析
- 时间复杂度:O(L),其中 L 是链表的长度。
- 空间复杂度:O(L),其中 L 是链表的长度。主要为栈的开销。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode removeNthFromEnd(ListNode head, int n) {//方法二:栈/**先把List中的结点都push到栈中。之后再往外弹,弹n次后,第n次出栈的就是要删除的第n个结点,栈顶元素即为要删除的结点的前一个结点.在之前先加一个哑结点,不然需要额外处理要删除头结点的情况熟悉一下Java中栈的定义和使用Deque<> = LinkedListpush(),pop(),peek()*/Deque<ListNode> stack = new LinkedList<ListNode> ();ListNode dummpy = new ListNode(0,head);ListNode cur = dummpy;while(cur != null){stack.push(cur);cur=cur.next;}for(int i = 0;i<n;i++){stack.pop();}cur = stack.peek();cur.next = cur.next.next;return dummpy.next;}}
方法三:快慢指针
由于我们需要找到倒数第 n 个节点,因此我们可以使用两个指针 first 和 second 同时对链表进行遍历,并且 first 比 second 超前 n 个节点。当 first 遍历到链表的末尾时,second 就恰好处于倒数第 n 个节点。
具体地,初始时 first 和 second 均指向头节点。我们首先使用 first 对链表进行遍历,遍历的次数为 n。此时,first 和 second 之间间隔了 n−1 个节点,即 first 比 second 超前了 n 个节点。
在这之后,我们同时使用 first 和 second 对链表进行遍历。当 first 遍历到链表的末尾(即 first 为空指针)时,second 恰好指向倒数第 n 个节点。
根据方法一和方法二,如果我们能够得到的是倒数第 n 个节点的前驱节点而不是倒数第 n 个节点的话,删除操作会更加方便。因此我们可以考虑在初始时将 second 指向哑节点,其余的操作步骤不变。这样一来,当 first 遍历到链表的末尾时,second 的下一个节点就是我们需要删除的节点。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode removeNthFromEnd(ListNode head, int n) {//方法二:先后指针/**当一个指针遍历到末尾空指针时,需要另一个指针刚好指在倒数第n个的结点的位置。fast,slowfast比slow要先走n步,之后同时前进就可以满足这个条件为什么要先走n步呢,假设现在有5个节点,1,2,3,4,5,需要删除倒数第2个节点,也就是4fast先走2步,走到3,之后slow和fast开始同时遍历slow :2 fast :4slow:3 fast 5slow:4 fast null 停止遍历但是我们先走想要指针能指向要删除结点的前一个结点,因此这里先引入dummpyNode*/ListNode dummpy = new ListNode(0,head);ListNode fast = head;ListNode slow = dummpy;//先走n步for(int i = 0;i<n;i++){fast = fast.next;}//同时遍历while(fast != null){fast = fast.next;slow = slow.next;}slow.next = slow.next.next;return dummpy.next;}}
24 两两交换链表中的节点
24. 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
方法一:迭代
创建哑结点dummpyHead,另dummpyHead.next = head另curr代表当前到达的节点
算法思路
- 初始化:创建一个哑节点
dummy,它的next指向头节点head。哑节点用于简化对头节点交换的处理。 - 遍历链表:使用两个指针
prev和curr分别指向当前正在处理的节点的前一个节点和当前节点。初始时,prev指向哑节点,curr指向头节点。 - 交换节点:
- 检查
curr和curr.next是否为null,如果任一为null,则表示没有更多的节点可以交换,算法结束。 - 保存
curr.next.next,即下一对需要交换的节点的起始节点。 - 执行交换:(prev->curr->curr.next->next)
- 将
prev.next指向curr.next,即把第二节点(b)设置为新的前一个节点的下一个节点。 - 将
curr.next.next指向curr,即把第二节点(b)的下一个节点指向第一节点(a)。 - 将
curr.next指向next,即把第一节点(a)的下一个节点指向下一对节点的起始节点。
- 将
- 检查
- 更新指针:更新
prev和curr以指向下一对需要交换的节点。 - 返回结果:返回哑节点的下一个节点,即交换后的链表的头节点。
代码实现
class Solution {public ListNode swapPairs(ListNode head) {if (head == null) {return null;}ListNode dummy = new ListNode(-1, head);ListNode prev = dummy;ListNode curr = dummy.next;while (curr != null && curr.next != null) {ListNode next = curr.next.next;prev.next = curr.next; // 第一步:将前一个节点指向当前节点的下一个节点curr.next.next = curr; // 第二步:将当前节点的下一个节点的下一个节点指向当前节点curr.next = next; // 第三步:将当前节点的下一个节点指向下一对节点的起始节点prev = curr; // 更新 prev 为当前节点curr = next; // 更新 curr 为下一对节点的起始节点}return dummy.next;}
}
- 确保在断开节点连接之前正确设置所有指针,以避免丢失节点。
- 使用哑节点可以简化对头节点交换的处理,避免特殊情况的判断。
这个算法的时间复杂度是 O(n),其中 n 是链表的长度,因为我们需要遍历整个链表一次。空间复杂度是 O(1),除了输入的链表外,我们只使用了有限的额外空间。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode swapPairs(ListNode head) {if(head == null){return null;}ListNode dummpy = new ListNode(-1,head);ListNode prev = dummpy;ListNode curr = dummpy.next;//现在有List a,b,c,d,e//我们需要两两一组进行交换,先引入一个哑节点dummpy//假设需要对a,b交换,此时需要记录ab前的指针以及ab后的节点c//prev = dummpy,curr = a ,next = curr.next.next (c)//开始交换//重点是第一步一定要在第三步之前。就是在断掉a->b的指针,需要将a指向c时,一定要先将prev.next = b,不然会找不到b//当然也可以再声明一个Node指向b,不用全在curr上操作。//第一步应该是将prev.next = curr.next (头节点的下一个是b)//第二步 curr.next.next = curr (b的指针指向a)//第三步 curr.next = next (a的指针指向c) //最后开始更新prev和curr//prev = curr (curr始终指的是a),现在a已经被我们交换到后面去变成b,a了,所以prev = curr//curr = next; (curr现在应当指向下一组需要被两两交换的节点,也就是c)while(curr != null && curr.next != null){ListNode next = curr.next.next;prev.next = curr.next; // 第一步:将前一个节点指向当前节点的下一个节点curr.next.next = curr; // 第二步:将当前节点的下一个节点的下一个节点指向当前节点curr.next = next;// 第三步:将当前节点的下一个节点指向下一对节点的起始节点prev = curr;// 更新 prev 为当前节点curr = next;// 更新 curr 为下一对节点的起始节点}return dummpy.next;}
}
方法二:递归
思路与算法
可以通过递归的方式实现两两交换链表中的节点。
递归的终止条件是链表中没有节点,或者链表中只有一个节点,此时无法进行交换。
如果链表中至少有两个节点,则在两两交换链表中的节点之后,原始链表的头节点变成新的链表的第二个节点,原始链表的第二个节点变成新的链表的头节点。链表中的其余节点的两两交换可以递归地实现。在对链表中的其余节点递归地两两交换之后,更新节点之间的指针关系,即可完成整个链表的两两交换。
用 head 表示原始链表的头节点,新的链表的第二个节点,用 newHead 表示新的链表的头节点,原始链表的第二个节点,则原始链表中的其余节点的头节点是 newHead.next。令 head.next = swapPairs(newHead.next),表示将其余节点进行两两交换,交换后的新的头节点为 head 的下一个节点。然后令 newHead.next = head,即完成了所有节点的交换。最后返回新的链表的头节点 newHead。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode swapPairs(ListNode head) {/**方法二:递归*///1.判断递归结束的条件,当当前节点为空,或者当前节点只有一个时,无需交换,递归结束if(head == null || head.next == null){return head;}//2.开始递归,现在链表为head,head.next,...ListNode newHead = head.next;head.next = swapPairs(newHead.next);newHead.next = head;return newHead;}
}
25 K个一组反转链表
25. K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:

输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
**进阶:**你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
方法一:模拟
我们需要将链表节点按照k个一组进行分组。对于每个分组,要判断长度是否大于k,是则翻转这部分链表,否则则不需要翻转。
1.如何按k个一组进行分组:用head指向每组的头结点,指针向前移动k次到达尾结点。
2.翻转之后,子链表的头部需要与上一个子链表相连接,子链表的尾部也要连接下一个子链表。因此在翻转时,需要子链表的头结点head以及head的上一个结点pre,
3.如何翻转子链表。这里参考206 翻转链表题目的解法。
复杂度分析
时间复杂度:O(n),其中 n 为链表的长度。head 指针会在 O(⌊n/k ⌋) 个节点上停留,每次停留需要进行一次 O(k) 的翻转操作。
空间复杂度:O(1),我们只需要建立常数个变量。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode reverseKGroup(ListNode head, int k) {ListNode dummpy = new ListNode(-1,head);ListNode pre = dummpy; //记录该小组前的最后一个节点while(head != null){ListNode tail = pre;//for(int i = 0;i<k;i++){tail = tail.next;if(tail == null){ //如果该组节点小于k,返回return dummpy.next;}}ListNode nex = tail.next; //记录该小组后的第一个节点ListNode[] reverse = myReverse(head,tail);pre.next = reverse[0]; //reverse[0]是反转后的head,reverse[1]是反转链表后的的tailreverse[1].next = nex; //将反转链表后的节点连上反转的链表pre = reverse[1];//更新prehead = pre.next;//更新head}return dummpy.next;}public ListNode[] myReverse(ListNode head, ListNode tail) {//反转head ->tail之间的链表// ListNode dummpy = new ListNode(-1,head);ListNode prev = null;ListNode curr = head;tail.next = null;while(curr != null){ListNode next = curr.next;curr.next = prev;prev = curr;curr = next;}return new ListNode[] {tail,head};}
}
138 随机链表的复制
138. 随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
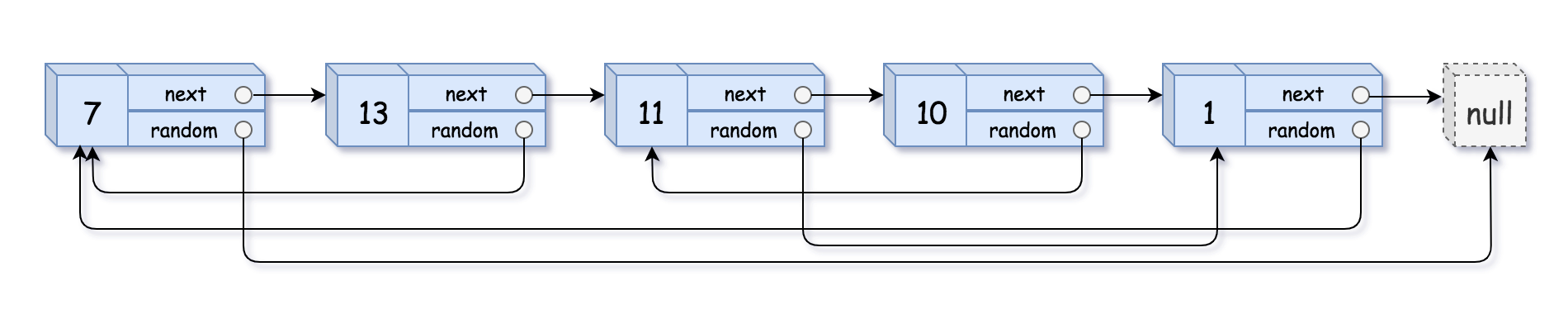
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
方法一:哈希表
直接复制。用hashmap存储oldnode和newnode,<oldnode,newnode>,之后遍历原先的链表,为新链表的next和random赋值。
map.get(cur).next = map.get(cur.next); //新节点的next = 原先节点next的 复制节点
map.get(cur).random = map.get(cur.random); //新节点的random = 原先节点random的复制节点
/*
// Definition for a Node.
class Node {int val;Node next;Node random;public Node(int val) {this.val = val;this.next = null;this.random = null;}
}
*/class Solution {public Node copyRandomList(Node head) {Map<Node,Node> map = new HashMap<>();Node cur = head;while(cur != null){map.put(cur,new Node(cur.val));cur = cur.next;}cur = head;while(cur != null){map.get(cur).next = map.get(cur.next); //新节点的next = 原先节点next的 复制节点map.get(cur).random = map.get(cur.random);cur = cur.next;}return map.get(head);}
}
148 排序列表
148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:

输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目在范围
[0, 5 * 104]内 -105 <= Node.val <= 105
**进阶:**你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
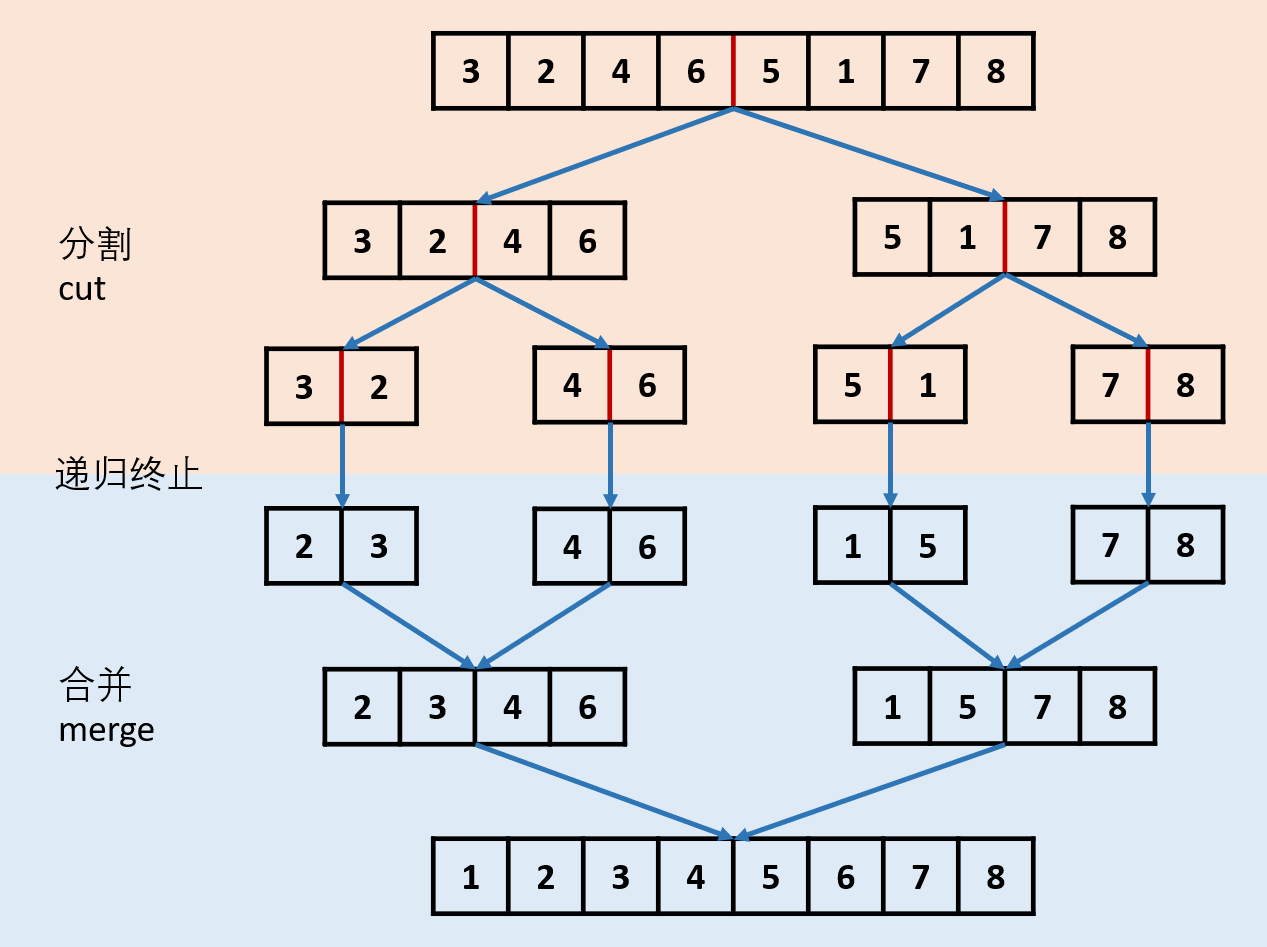
方法一:归并排序(递归法)
其实没有想到归并排序。这里就相当于重新复习一遍。归并排序是一种分而治之的算法。将大问题分解成小问题,再解决小问题,将小问题的解合并成大问题的解。
具体到这个题目中就是,将链表一分为二,之后再排序,合并。
数组额外空间:链表可以通过修改引用来更改节点顺序,无需像数组一样开辟额外空间;
递归额外空间:递归调用函数将带来 O(logn) 的空间复杂度,因此若希望达到 O(1) 空间复杂度,则不能使用递归。
通过递归实现链表归并排序,有以下两个环节:
-
分割 cut 环节: 找到当前链表 中点,并从 中点 将链表断开(以便在下次递归 cut 时,链表片段拥有正确边界);
-
我们使用 fast,slow 快慢双指针法,奇数个节点找到中点,偶数个节点找到中心左边的节点。
-
找到中点 slow 后,执行 slow.next = None 将链表切断。
-
递归分割时,输入当前链表左端点 head 和中心节点 slow 的下一个节点 tmp(因为链表是从 slow 切断的)。
-
cut 递归终止条件: 当 head.next == None 时,说明只有一个节点了,直接返回此节点。
-
-
合并 merge 环节: 将两个排序链表合并,转化为一个排序链表。
- 双指针法合并,建立辅助 ListNode h 作为头部。
- 设置两指针 left, right 分别指向两链表头部,比较两指针处节点值大小,由小到大加入合并链表头部,指针交替前进,直至添加完两个链表。
- 返回辅助ListNode h 作为头部的下个节点 h.next。
时间复杂度 O(l + r),l, r 分别代表两个链表长度。
当题目输入的 head == None 时,直接返回 None。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode sortList(ListNode head) {//归并排序,对单链表进行排序。//归并排序:分治算法,将大问题分解成小问题递归解决,之后将小问题的解合并为大问题的解。//本题中:将链表分成两半,对每段进行排序,之后将排序后的链表合成一个。//1.递归结束条件,当前为空或者当前只有1个元素if(head == null || head.next == null){return head;}//2.通过快慢指针找到中点ListNode fast = head;ListNode slow = head;while(fast.next!=null && fast.next.next != null){fast = fast.next.next;slow = slow.next;}//找到第二段list的起点,并将第一段链表的终点设为nullListNode mid = slow.next;slow.next = null;//递归ListNode list1 = sortList(head);ListNode list2 = sortList(mid);//合并排序ListNode sorted = merge(list1,list2);return sorted;}public ListNode merge(ListNode head1,ListNode head2){ListNode dummpy = new ListNode(0);ListNode temp = dummpy,temp1 = head1,temp2 = head2;while(temp1 != null && temp2 != null){if(temp1.val < temp2.val){temp.next = temp1;temp1 = temp1.next;}else{temp.next = temp2;temp2 = temp2.next;}temp = temp.next;//一定要更新}if(temp1!=null){temp.next = temp1;}else if(temp2!=null){temp.next = temp2;}return dummpy.next;}
}
23 合并K个升序链表
23. 合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[1->4->5,1->3->4,2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
方法一:分治法
分治法:
1.将k个链表两两配对并将同一对中的链表合并。
2.第一轮合并后,k个链表被合并为k/2个链表
3.重复1,2 就能得到最终的有序链表
写递归的话注意写递归结束的条件,当递归中只有一个链表要处理时,直接返回该链表,否则递归合并。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeKLists(ListNode[] lists) {//分治法,K个一组合并return merge(lists,0,lists.length-1);}public ListNode merge(ListNode[] lists,int start,int end){if(start == end){ //当前递归中只有1个链表要处理,所以直接返回return lists[start];//说明排序完毕}if(start > end){return null;}int mid = (start + end) >> 1;return mergeTwoLists(merge(lists,start,mid),merge(lists,mid+1,end));}public ListNode mergeTwoLists(ListNode head1,ListNode head2){ListNode dumpy = new ListNode(0);ListNode temp = dumpy,temp1 = head1,temp2 = head2;while(temp1!=null && temp2 !=null){if(temp1.val < temp2.val){temp.next = temp1;temp1 = temp1.next;}else{temp.next = temp2;temp2 = temp2.next;}temp = temp.next;}if(temp1 != null){temp.next = temp1;}else{temp.next = temp2;}return dumpy.next;}
}
146 LRU缓存
146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 105- 最多调用
2 * 105次get和put
方法一:哈希表+双向链表
这个题目以前没有做过,是个比较新颖有趣的题。用自定义的双向链表结构实现这一点。
哈希表存储key,DLinkedNode(value)键值对,通过key来映射到DLinkedNode的位置。
之后就可以判断最近使用了,只要使用过就将该值动DLinkedNode中移动到头部。
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的key映射到其在双向链表中的位置。因此为<key,DLinkedNode>
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
-
对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 −1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
-
对于 put 操作,首先判断 key 是否存在:
-
如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
-
如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
-
上述各项操作中,访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。
小贴士
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
class LRUCache {/**使用一个哈希表+双向链表实现这个操作。因为get和put要以O(1)的复杂度,说明get需要用hashmap,put的话需要逐出最久未使用的关键字,删除操作平均时间复杂度也是O(1),因此需要用双向链表来实现。HashMap<key,DLinkNode(value)>,通过这种方式来实现LRU*///定义一个双向节点class DLinkedNode{int key;int value;DLinkedNode prev;DLinkedNode next;public DLinkedNode(){}public DLinkedNode(int _key,int _value){ key = _key;value = _value;}}//定义cache 的map结构,当前容量size和最大容量capacityprivate Map<Integer,DLinkedNode> map = new HashMap<>();private int size ;private int capacity;private DLinkedNode head,tail; //定义伪头结点和伪尾结点//LRUCache初始化public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;//初始化伪头结点和伪尾结点head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}//get操作,先判断key是否存在,不存在则返回-1//存在,key应当是最近被使用的结点,将key移动到双向链表的头部,返回该结点的值public int get(int key) {DLinkedNode node = map.get(key);if(node!=null){//将该结点移动到双向链表的头部moveToHead(node);return node.value;}else{return -1;}}//先判断key是否存在,不存在则创建新节点,在双链表的头部添加该结点后,往map中插入//并且判断双向链表中的节点数是否超出容量//超出容量则删除双向链表的尾部结点,删除map中对应的项//存在则通过哈希表定位,值更新为value,并将该结点移动到双向链表的头部public void put(int key, int value) {DLinkedNode node = map.get(key);if(node!=null){//存在,需要更新值,移动头部node.value = value;moveToHead(node);}else{DLinkedNode newnode = new DLinkedNode(key,value);//添加进hashmapmap.put(key,newnode);//向双向链表头部插入结点addToHead(newnode);++size; //大小++//判断当前是否超过最大容量if(size>capacity){ DLinkedNode tail = removeTail();//删除hashmap中的对应项map.remove(tail.key); --size;}}}//从中可以抽象出,将结点添加到头部private void addToHead(DLinkedNode node){node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}//从双向链表中移除结点private void removeNode(DLinkedNode node){node.prev.next = node.next; //前一个结点的next应当指向后一个node.next.prev = node.prev; //后一个结点的prev应当指向前一个结点}//移动到头部private void moveToHead(DLinkedNode node){removeNode(node);addToHead(node);}//尾部元素删除private DLinkedNode removeTail(){DLinkedNode res = tail.prev;removeNode(res);return res;}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/
相关文章:
【LeetCode HOT 100】详细题解之链表篇
LeetCode HOT 100题解之链表篇 160 相交链表题目分析代码 206 反转链表方法一:迭代 234 回文链表方法一:将值复制到数组中方法二:快慢指针 141 环形链表方法一:哈希表方法二:快慢指针 142 环形链表II方法一:…...

二叉树的递归遍历
方法论 确定递归函数的参数和返回值 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。 确定终止条件 写完了递归算法, 运行的时候,经常会遇到栈溢…...

国内访问OpenAI API
最近在学习LLM。绕不过去的肯定要学习OpenAI。 国内想直接使用官方API十分麻烦。就到处查资料及网友的分享。发现了这个代理可以在国内很方便的使用OpenAI API。 代理的地址如下: https://referer.shadowai.xyz/r/1014150 经过一段实际体验下来,这个…...

深入 Spring RestTemplate 源码:掌握 HTTP 通信核心技术
在上一篇文章《Spring Boot 项目高效 HTTP 通信:常用客户端大比拼!》里,我们提到了RestTemplate,它是Spring框架提供的Http客户端,在springboot项目开发过程中,属于使用最为广泛的 HTTP 客户端之一了。今天…...

计算机网络:计算机网络概述 —— 初识计算机网络
文章目录 计算机网络组成部分网络架构协议与标准网络设备网络类型作用实际应用案例 计算机网络 计算机网络是指将多台计算机通过通信设备和通信链路连接起来,以实现数据和信息的交换和共享的技术和系统。它是现代信息社会的基础设施之一,也是互联网的基…...

set和map结构的使用
个人主页:敲上瘾-CSDN博客 个人专栏:游戏、数据结构、c语言基础、c学习、算法 目录 一、序列式容器和关联式容器 二、set和multiset 1.insert 2.erase 3.find 4.count 三、map和mapmulti 1.pair 2.insert 3.find 4.operator[ ] 5.erase 6.lo…...

2. qt_c++反射实例
目录 使用场景元对象相关类及宏常用功能获取类相关内容以及委托调用 使用场景 Qt基于强大的元对象系统实现反射机制; 在复杂的开发需求中,我们希望通过一些手段映射出我们的类(映射对象) 然后直接使用,通过࿰…...

卷积神经网络(CNN)的计算量和参数怎么准确估计?
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 1. 卷积层(Convolutional Layer) a) 计算量估计: 卷积层的 FLOPs 2 * H_out * W_out * C_in * C_out * K_h * K_w 详细解释: H_out, W_outÿ…...

Ruby基础语法
Ruby 是一种动态、反射和面向对象的编程语言,它以其简洁的语法和强大的功能而受到许多开发者的喜爱。以下是 Ruby 语言的一些基本语法: 1. 打印输出 puts "Hello, Ruby!" 变量赋值 x 10 name "John" 2. 数据类型 Ruby 有多种…...

插入排序C++
题目: 样例解释: 【样例解释 #1】 在修改操作之前,假设 H 老师进行了一次插入排序,则原序列的三个元素在排序结束后所处的位置分别是 3,2,1。 在修改操作之后,假设 H 老师进行了一次插入排序,则原序列的三个…...

修改ID不能用关键字作为ID校验器-elementPlus
1、校验器方法 - forbiddenCharValidator const idUpdateFormRef ref(null); const forbiddenCharValidator (rule, value, callback) > {const forbiddenCharacters [as,for,default,in,join,left,inner,right,where,when,case,select];for (let forbiddenCharacter o…...

一文详解WebRTC、RTSP、RTMP、SRT
背景 好多开发者,希望对WebRTC、RTSP、RTMP、SRT有个初步的了解,知道什么场景该做怎样的方案选择,本文就四者区别做个大概的介绍。 WebRTC 提到WebRTC,相信好多开发者第一件事想到的就是低延迟,WebRTC(W…...

全国职业院校技能大赛(大数据赛项)-平台搭建Zookeeper笔记
ZooKeeper是一个分布式的、开放源码的分布式应用程序协调服务,为分布式应用提供一致性服务。它的设计目标是简化分布式系统的管理,保证多个节点之间的数据一致性和协调工作。ZooKeeper提供了类似文件系统的层次化命名空间,用来存储和管理元数…...
)
不同领域神经网络一般选择什么模型作为baseline(基准模型)
在神经网络研究中,选择合适的baseline(基线模型)是评估新方法有效性的重要步骤。基线模型通常是领域内公认的、性能良好的参考模型,用于比较和验证新提出模型的优势。以下是一些在不同任务和领域中常见的基线模型选择:…...

华为-IPv6与IPv4网络互通的6to4自动隧道配置实验
IPv4向IPv6的过渡不是一次性的,而是逐步地分层次地。在过渡时期,为了保证IPv4和IPv6能够共存、互通,人们发明了一些IPv4/IPv6的互通技术。 本实验以6to4技术为例,阐述如何配置IPv6过渡技术。 配置参考 R1 # sysname R1 # ipv6# interface GigabitEthernet0/0/1ip address 200…...

【spring中event】事件简单使用
定义事件类 /* * 1. 定义事件类 * 首先,我们创建一个自定义事件 UserRegisteredEvent,用于表示用户注册事件。 * */ public class UserRegisteredEvent extends ApplicationEvent {private final String email;public UserRegisteredEvent(Object sourc…...

leetcode每日一题day19(24.9.29)——买票需要的时间
思路:在最开始的情况下每人需要买的票数减一是能保持相对位置不变的, 如果再想减一就有可能 有某些人只买一张票,而离开了队伍, 所有容易想到对于某个人如果比当前的人买的多就按当前的人数量算 因为在一次次减一的情况下…...

智源研究院推出全球首个中文大模型辩论平台FlagEval Debate
近日,智源研究院推出全球首个中文大模型辩论平台FlagEval Debate,旨在通过引入模型辩论这一竞争机制对大语言模型能力评估提供新的度量标尺。该平台是智源模型对战评测服务FlagEval大模型角斗场的延展,将有助于甄别大语言模型的能力差异。 F…...
:删除xml标签下的指定类别)
python实用脚本(二):删除xml标签下的指定类别
介绍 在目标检测中,有些时候会遇到标注好的类别不想要了的情况,这时我们可以运行下面的代码来批量删除不需要的类别节省时间。 代码实现: import argparseimport xml.etree.ElementTree as ET import osclasses [thin_smoke]def GetImgNam…...

vue3 父子组件调用
vue3 父子组件调用 父组件调用子组件方法 子组件使用defineExpose将方法抛出 父组件定义 function,子组件通过 defineExpose 暴露方法,父组件通过 ref 获取子组件实例,然后通过 ref 获取子组件方法。 // 父组件 <template><div>…...

【王阳明】《泛海》
王阳明《泛海》:证道诗与心学宣言原诗险夷原不滞胸中, 何异浮云过太空? 夜静海涛三万里, 月明飞锡下天风。一、创作背景:九死一生的逃亡 这首诗写于王阳明人生最险峻的时刻,背景远比字面所呈现的更为惊心动…...

AI驱动3D骨骼绑定:从3天到3分钟的自动化革命
AI驱动3D骨骼绑定:从3天到3分钟的自动化革命 【免费下载链接】UniRig One Model to Rig Them All: Diverse Skeleton Rigging with UniRig 项目地址: https://gitcode.com/gh_mirrors/un/UniRig 3D骨骼绑定是动画制作流程中的关键环节,传统手工绑…...

全能视频下载工具:Video-Downloader让在线视频轻松保存
全能视频下载工具:Video-Downloader让在线视频轻松保存 【免费下载链接】Video-Downloader 下载youku,letv,sohu,tudou,bilibili,acfun,iqiyi等网站分段视频文件,提供mac&win独立App。 项目地址: https://gitcode.com/gh_mirrors/vi/Video-Downloa…...

让老旧Mac焕发新生:OpenCore Legacy Patcher完整指南
让老旧Mac焕发新生:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 您的Mac是否被苹果官方"抛弃"&…...

超轻量级OpenClaw与LaTeX结合:学术文档自动化处理
超轻量级OpenClaw与LaTeX结合:学术文档自动化处理 科研工作者每天需要处理大量的文献整理、公式编辑和文档排版工作,传统手动方式耗时且容易出错。本文将展示如何用超轻量级OpenClaw实现学术文档的自动化处理,让LaTeX文档编写变得轻松高效。 …...
——从艾里斑到系统分辨率:衍射极限的实战解析)
Zemax光学设计(三)——从艾里斑到系统分辨率:衍射极限的实战解析
1. 艾里斑:光学的终极像素 当你用手机拍夜景时,为什么远处的路灯总变成模糊的光团?这背后隐藏着光学系统的基本限制——艾里斑。我在设计微型内窥镜镜头时,曾花了三周时间优化像差,最终却发现图像清晰度卡在一个无法突…...

内网渗透实战:利用SSH密钥实现Linux主机间横向移动
1. SSH密钥横向移动的核心原理 当你第一次接触内网渗透时,可能会被各种复杂的技术术语吓到。其实SSH密钥横向移动的原理非常简单:就像用钥匙开锁一样,只要拿到目标主机的SSH私钥,就能像合法用户一样登录系统。我在实际渗透测试中发…...

Qwen3-14B芯片设计辅助:Verilog注释生成、RTL代码解释、DFT建议
Qwen3-14B芯片设计辅助:Verilog注释生成、RTL代码解释、DFT建议 1. 镜像概述与硬件适配 Qwen3-14B私有部署镜像是专为芯片设计工程师打造的AI辅助工具,基于通义千问大语言模型优化定制。该镜像完美适配RTX 4090D 24GB显存配置,预装了完整的…...

Phi-3-mini-4k-instruct-gguf开发者案例:为微信小程序后端提供的轻量API服务
Phi-3-mini-4k-instruct-gguf开发者案例:为微信小程序后端提供的轻量API服务 1. 项目背景与需求 在开发微信小程序时,我们经常需要为前端提供智能文本处理能力,比如自动生成商品描述、智能客服回复、内容摘要等。传统方案要么需要调用第三方…...

Umi-OCR:重新定义本地化文字识别的工作流范式
Umi-OCR:重新定义本地化文字识别的工作流范式 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 …...