Flask-SQLAlchemy:在Flask应用中优雅地操作数据库
在Python的Web开发领域,Flask是一个备受欢迎的轻量级Web框架,它以简洁、灵活而著称。而当我们需要在Flask应用中与数据库进行交互时,Flask-SQLAlchemy就成为了一个强大而便捷的工具。它将Flask的简洁性与SQLAlchemy的强大数据库抽象能力完美结合,让我们能够轻松地在Flask应用中进行数据库操作,无论是简单的查询还是复杂的数据库事务管理,都能得心应手。
引言
在现代Web应用开发中,数据库是存储和管理数据的核心组件。我们需要一种高效、可靠且易于使用的方式来与数据库进行交互,以便实现数据的存储、检索、更新和删除等操作。Flask-SQLAlchemy为我们提供了这样的解决方案,它简化了数据库操作的流程,同时还提供了一系列强大的功能,如数据库迁移、模型关系定义等,大大提高了开发效率。
Flask-SQLAlchemy的基础概念
SQLAlchemy简介
SQLAlchemy是一个强大的Python SQL工具包,它提供了一套完整的企业级持久化模式,用于将数据库操作抽象为Python代码。它允许我们使用面向对象的方式来操作数据库,而不必编写繁琐的SQL语句。SQLAlchemy支持多种数据库,包括MySQL、PostgreSQL、SQLite等,这使得我们在切换数据库时只需修改少量配置,而无需更改大量的代码。
Flask与SQLAlchemy的结合:Flask-SQLAlchemy
Flask-SQLAlchemy是一个为Flask应用专门设计的扩展,它将SQLAlchemy集成到Flask框架中,使得在Flask应用中使用SQLAlchemy变得更加简单和便捷。它提供了一些Flask特定的功能和约定,例如与Flask的配置系统集成,自动处理数据库连接和会话管理等,让我们能够更加专注于业务逻辑的开发,而不必过多关注数据库连接的细节。
安装与配置
- 安装
要使用Flask-SQLAlchemy,首先需要在Python环境中安装它。可以使用pip命令进行安装:
pip install flask-sqlalchemy
- 配置
在Flask应用中,需要进行一些配置来告诉Flask-SQLAlchemy如何连接到数据库。通常在Flask应用的配置文件中进行设置,例如:
from flask import Flaskapp = Flask(__name__)# 配置数据库连接
app.config['SQLALCHEMY_DATABASE_URI'] ='sqlite:///your_database.db' # 使用SQLite数据库为例
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # 关闭不必要的跟踪# 其他Flask配置...if __name__ == '__main__':app.run()
这里的SQLALCHEMY_DATABASE_URI指定了数据库的连接字符串,不同的数据库类型有不同的连接字符串格式。例如,对于MySQL数据库,可能是mysql://username:password@host:port/database_name。SQLALCHEMY_TRACK_MODIFICATIONS设置为False是为了避免一些不必要的警告,在生产环境中通常建议这样设置。
使用Flask-SQLAlchemy进行数据库建模
定义模型类
在Flask-SQLAlchemy中,我们使用Python类来定义数据库表的结构,这些类被称为模型类。每个模型类对应着数据库中的一个表,类中的属性则对应着表中的列。例如,我们要创建一个用户表和一个文章表,可以定义如下的模型类:
from flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()class User(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True, nullable=False)email = db.Column(db.String(120), unique=True, nullable=False)class Article(db.Model):id = db.Column(db.Integer, primary_key=True)title = db.Column(db.String(200), nullable=False)content = db.Column(db.Text, nullable=False)user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)author = db.relationship('User', backref='articles')
在上述代码中,User和Article是两个模型类,分别对应着用户表和文章表。db.Column用于定义表中的列,其中参数如db.Integer、db.String等指定了列的数据类型,primary_key=True表示该列是主键,unique=True表示该列的值必须唯一,nullable=False表示该列不能为空。Article模型中的user_id列是外键,通过db.ForeignKey关联到User模型的id列,表示一篇文章属于一个用户。author属性是一个关系属性,通过db.relationship定义,它使得我们可以从文章对象方便地获取到对应的用户对象,反之亦然。
模型之间的关系
Flask-SQLAlchemy支持多种模型之间的关系定义,除了上面示例中的一对多关系(一个用户可以有多篇文章),还包括多对多关系等。例如,如果我们要实现一个用户可以关注多个其他用户,并且一个用户也可以被多个用户关注的功能,可以这样定义模型:
class User(db.Model):#... 其他属性和方法following = db.relationship('User', secondary='followers',primaryjoin='User.id == Followers.follower_id',secondaryjoin='User.id == Followers.followed_id',backref=db.backref('followers', lazy='dynamic'))class Followers(db.Model):follower_id = db.Column(db.Integer, db.ForeignKey('user.id'), primary_key=True)followed_id = db.Column(db.Integer, db.ForeignKey('user.id'), primary_key=True)
这里通过secondary参数指定了一个中间表Followers来实现多对多关系。primaryjoin和secondaryjoin参数用于定义连接条件,backref参数则为反向关系提供了一个方便的访问方式。
数据库操作
创建数据库表
在定义好模型类后,我们需要创建数据库表。Flask-SQLAlchemy提供了一个方便的方法来创建表,只需在Flask应用的上下文环境中调用db.create_all()即可。例如:
from flask import Flask
from your_app import db, User, Article # 假设你的模型类在your_app模块中定义app = Flask(__name__)
# 配置数据库连接等...@app.before_first_request
def create_tables():with app.app_context():db.create_all()if __name__ == '__main__':app.run()
@app.before_first_request装饰器确保在应用首次收到请求之前创建数据库表。这样,当我们启动应用时,数据库表会自动根据模型类的定义进行创建。如果数据库表已经存在,再次调用db.create_all()不会产生任何影响,它是安全的。
插入数据
要向数据库表中插入数据,我们可以创建模型类的实例,并将其添加到数据库会话中,然后提交会话。例如:
from flask import Flask
from your_app import db, Userapp = Flask(__name__)
# 配置数据库连接等...@app.route('/add_user')
def add_user():new_user = User(username='john_doe', email='john@example.com')db.session.add(new_user)db.session.commit()return 'User added successfully!'if __name__ == '__main__':app.run()
在上述代码中,我们创建了一个User模型类的实例new_user,并设置了其username和email属性的值。然后通过db.session.add()将其添加到数据库会话中,最后调用db.session.commit()提交会话,将数据真正插入到数据库表中。
查询数据
Flask-SQLAlchemy提供了丰富的查询方法来检索数据库中的数据。我们可以使用query对象来执行各种查询操作。例如:
@app.route('/get_users')
def get_users():users = User.query.all()for user in users:print(user.username, user.email)return 'Users retrieved successfully!'
User.query.all()返回数据库中所有的用户记录,它是一个包含User模型类实例的列表。我们可以遍历这个列表来获取每个用户的信息。还可以根据条件进行查询,例如:
@app.route('/get_user_by_username')
def get_user_by_username():username = 'john_doe'user = User.query.filter_by(username=username).first()if user:print(user.username, user.email)else:print('User not found.')return 'User query completed!'
User.query.filter_by(username=username)根据username字段进行筛选,first()方法返回查询结果中的第一个匹配项。如果没有找到匹配的用户,first()会返回None。
更新数据
更新数据也很简单,首先获取要更新的记录,然后修改其属性值,最后提交会话。例如:
@app.route('/update_user_email')
def update_user_email():username = 'john_doe'user = User.query.filter_by(username=username).first()if user:user.email = 'new_email@example.com'db.session.commit()return 'User email updated successfully!'else:return 'User not found.'
这里我们先根据username找到用户记录,然后将其email属性修改为新的值,最后提交会话以保存更新。
删除数据
删除数据同样需要先获取要删除的记录,然后调用db.session.delete()方法将其从数据库中删除,并提交会话。例如:
@app.route('/delete_user')
def delete_user():username = 'john_doe'user = User.query.filter_by(username=username).first()if user:db.session.delete(user)db.session.commit()return 'User deleted successfully!'else:return 'User not found.'
数据库事务处理
在实际应用中,我们经常需要执行一系列的数据库操作,这些操作要么全部成功,要么全部失败,这就需要使用数据库事务。Flask-SQLAlchemy提供了方便的事务处理机制。例如:
@app.route('/transfer_money')
def transfer_money():from_user = User.query.filter_by(username='user1').first()to_user = User.query.filter_by(username='user2').first()amount = 100 # 假设转账金额为100with db.session.begin_nested():# 从from_user账户中扣除金额from_user.balance -= amount# 向to_user账户中增加金额to_user.balance += amounttry:# 提交事务db.session.commit()return 'Money transfer successful!'except:# 如果发生错误,回滚事务db.session.rollback()return 'Money transfer failed!'
在上述代码中,我们模拟了一个简单的转账操作,从一个用户账户中扣除一定金额并添加到另一个用户账户中。通过with db.session.begin_nested():开启一个嵌套事务,在事务块中进行数据库操作。如果在操作过程中发生错误,我们可以捕获异常并调用db.session.rollback()回滚事务,以保证数据的一致性。
数据库迁移
随着应用的发展,数据库结构可能会发生变化,例如添加新的表、修改列的数据类型等。手动处理这些数据库结构的变更可能会非常繁琐且容易出错。Flask-SQLAlchemy通常与数据库迁移工具如Alembic结合使用,来方便地管理数据库结构的变更。
- 安装Alembic
pip install alembic
- 初始化Alembic
在Flask应用的根目录下,运行以下命令来初始化Alembic:
alembic init alembic
这将创建一个alembic目录和一些配置文件。
- 修改配置文件
打开alembic.ini文件,修改其中的sqlalchemy.url配置项,使其指向你的Flask应用的数据库连接字符串。例如:
sqlalchemy.url = sqlite:///your_database.db
然后在alembic/env.py文件中,将target_metadata设置为你的Flask应用中的db.Model.metadata。例如:
from your_app import db
from sqlalchemy import MetaDatatarget_metadata = db.Model.metadata
- 创建迁移脚本
当你对数据库模型进行了修改后,例如添加了一个新的列,你可以运行以下命令来创建迁移脚本:
alembic revision -m "Add new column to user table"
这将生成一个新的迁移脚本文件,你可以在其中看到对数据库结构变更的描述。
- 升级数据库
要应用迁移脚本并更新数据库结构,运行以下命令:
alembic upgrade head
这将执行迁移脚本中的变更操作,更新数据库结构。
通过使用Alembic进行数据库迁移,我们可以轻松地管理数据库结构的版本,并且可以方便地回滚到之前的版本,如果需要的话。
性能优化与注意事项
查询优化
- 合理使用索引
在数据库表的列上创建合适的索引可以大大提高查询性能。例如,如果经常根据用户的username进行查询,可以在username列上创建索引。在Flask-SQLAlchemy中,可以通过在模型类的列定义中添加index=True来创建索引,例如:
class User(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True, nullable=False, index=True)email = db.Column(db.String(120), unique=True, nullable=False)
- 避免不必要的查询
在获取数据时,只查询需要的字段,避免查询不必要的大量数据。例如,如果只需要获取用户的username和email,可以使用query.with_entities()方法指定要查询的字段,如下所示:
users = User.query.with_entities(User.username, User.email).all()
- 分页查询
当查询大量数据时,一次性获取所有数据可能会导致性能问题。可以使用分页查询来分批获取数据。Flask-SQLAlchemy提供了paginate()方法来实现分页查询,例如:
@app.route('/get_users_paginated')
def get_users_paginated():page = int(request.args.get('page', 1)) # 获取当前页码,默认为1per_page = 10 # 每页显示的记录数users = User.query.paginate(page=page, per_page=per_page)return render_template('users.html', users=users)
在模板中,可以使用users.items来获取当前页的数据,users.has_prev和users.has_next来判断是否有上一页和下一页,users.prev_num和users.next_num来获取上一页和下一页的页码。
连接池管理
Flask-SQLAlchemy默认使用数据库连接池来管理数据库连接。连接池可以复用连接,减少连接创建和销毁的开销,提高性能。但是,如果连接池配置不当,也可能会导致性能问题。可以根据应用的实际情况调整连接池的大小等参数。一般来说,可以通过在Flask应用的配置中设置SQLALCHEMY_POOL_SIZE来指定连接池的大小,例如:
app.config['SQLALCHEMY_POOL_SIZE'] = 20 # 设置连接池大小为20
注意事项
- 数据一致性
在进行数据库操作时,要特别注意数据的一致性。例如,在处理多对多关系时,要确保中间表的数据正确更新,避免出现数据不一致的情况。 - 错误处理
要对数据库操作中的错误进行妥善处理,及时捕获异常并进行相应的处理,如回滚事务、返回错误信息给用户等。避免因为错误处理不当导致数据错误或应用崩溃。 - 安全问题
在使用Flask-SQLAlchemy时,要注意防止SQL注入等安全问题。不要直接将用户输入的数据拼接到SQL语句中,应该使用参数化查询或ORM提供的安全查询方法。例如,在查询用户时,应该使用filter_by等方法而不是手动拼接SQL语句。
总结
Flask-SQLAlchemy为我们在Flask应用中与数据库进行交互提供了一种简洁、高效且强大的方式。通过它,我们可以轻松地进行数据库建模、数据操作、事务处理以及数据库迁移等工作。在实际开发中,我们要充分利用它的功能,同时注意性能优化和安全问题,以构建出稳定、高效的Web应用。随着对Flask-SQLAlchemy的深入了解和熟练运用,我们能够更加得心应手地处理数据库相关的任务,为应用的开发和维护提供有力支持。无论是开发小型的个人项目还是大型的企业级应用,Flask-SQLAlchemy都能成为我们的得力助手,帮助我们在数据库操作的世界中畅游无阻,实现更加丰富和复杂的业务逻辑。希望通过这篇文章,你能对Flask-SQLAlchemy有一个全面的认识和了解,并在实际项目中运用它来提升开发效率和应用质量。
相关文章:

Flask-SQLAlchemy:在Flask应用中优雅地操作数据库
在Python的Web开发领域,Flask是一个备受欢迎的轻量级Web框架,它以简洁、灵活而著称。而当我们需要在Flask应用中与数据库进行交互时,Flask-SQLAlchemy就成为了一个强大而便捷的工具。它将Flask的简洁性与SQLAlchemy的强大数据库抽象能力完美结…...

智能巡检机器人 数据库
智能巡检机器人AI智能识别。无需人工。只需后台监控结果即可!...

Spring AOP异步操作实现
在Spring框架中,AOP(面向切面编程)提供了一种非常灵活的方式来增强应用程序的功能。异步操作是现代应用程序中常见的需求,尤其是在处理耗时任务时,它可以帮助我们提高应用程序的响应性和吞吐量。Spring提供了一种简单的…...

【2006.07】UMLS工具——MetaMap原理深度解析
文献:《MetaMap: Mapping Text to the UMLS Metathesaurus》2006 年 7 月 14 日 https://lhncbc.nlm.nih.gov/ii/information/Papers/metamap06.pdf MetaMap:将文本映射到 UMLS 元数据库 总结 解决的问题 自动概念映射问题:解决如何将文本…...

ros2 colcon build 构建后,install中的local_setup.bash 和setup.bash有什么区别
功能概述 在 ROS2 中,colcon build是用于构建软件包的工具。构建完成后会生成install文件夹,其中的setup.bash和local_setup.bash文件都与环境设置相关,但存在一些区别。setup.bash 作用范围 setup.bash文件用于设置整个工作空间的环境变量。…...

Thymeleaf基础语法
Thymeleaf 是一种用于 Web 和非 Web 环境的现代服务器端 Java 模板引擎。它能够处理 HTML、XML、JavaScript、CSS 甚至纯文本。以下是 Thymeleaf 的一些基础语法: 1. 变量表达式 <!-- 显示变量的值 --> <p th:text"${name}">Default Name&l…...

spring cloud alibaba学习路线
以下是一条学习Spring Cloud Alibaba的路线: 一、基础前置知识 1. Java基础 熟练掌握Java语言特性,包括面向对象编程、集合框架、多线程等知识。 2. Spring和Spring Boot基础深入理解Spring框架,如依赖注入(DI)、控…...
)
基于 Seq2Seq 的中英文翻译项目(pytorch)
项目简介 本项目旨在使用 PyTorch 构建一个基于 Seq2Seq(编码器-解码器架构)的中英文翻译模型。我们将使用双语句子对的数据进行训练,最终实现一个能够将英文句子翻译为中文的模型。项目的主要步骤包括: 数据预处理:从数据集中提取英文和中文句子,并进行初步清洗和保存。…...

部标主动安全(ADAS+DMS)对接说明
1.前言 上一篇介绍了部标(JT/T1078)流媒体对接说明,这里说一下如何对接主动安全附件服务器。 流媒体的对接主要牵扯到4个方面: (1)平台端:业务端系统,包含前端呈现界面。 &#x…...
迭代器)
C++ STL(1)迭代器
文章目录 一、迭代器详解1、迭代器的定义与功能2、迭代器类型3、示例4、迭代器失效4.1、vector 迭代器失效分析4.2、list 迭代器失效分析4.3、set 与 map 迭代器失效分析 5、总结 前言: 在C标准模板库(STL)中,迭代器是一个核心概念…...

uview表单校验不生效问题
最近几次使用发现有时候会不生效,具体还没排查出来什么原因,先记录一下解决使用方法 <u--formlabelPosition"top"labelWidth"auto":model"form":rules"rules"ref"uForm" ><view class"…...

前端开发设计模式——单例模式
目录 一、单例模式的定义和特点: 1.定义: 2.特点: 二、单例模式的实现方式: 1.立即执行函数结合闭包实现: 2.ES6类实现: 三、单例模式的应用场景 1.全局状态管理: 2.日志记录器: …...

行情叠加量化,占据市场先机!
A股久违的3000点,最近都没有更新,现在终于对我们的市场又来点信息。相信在座的朋友这几天都是喜笑颜开,对A股又充满信心。当前行情好起来了,很多朋友又开始重回市场,研究股票学习量化,今天我们给大家重温下…...

大厂面试真题-ConcurrentHashMap怎么保证的线程安全?
ConcurrentHashMap是Java中的一个线程安全的哈希表实现,它通过一系列精妙的机制来保证线程安全。以下是ConcurrentHashMap保证线程安全的主要方式: 分段锁(Segment Locking,Java 1.8之前): 在Java 1.8之前的…...

【RabbitMQ】消息堆积、推拉模式
消息堆积 原因 消息堆积是指在消息队列中,待处理的消息数量超过了消费者处理能力,导致消息在队列中不断堆积的现象。通常有以下几种原因: 消息生产过快:在高流量或者高负载的情况下,生产者以极高的速率发送消息&…...
)
MySQL常用SQL语句(持续更新中)
文章目录 数据库相关表相关索引相关添加索引 编码相关系统变量相关 收录一些经常用到的sql 数据库相关 建数据库 CREATE DATABASE [IF NOT EXISTS] <数据库名> [[DEFAULT] CHARACTER SET <字符集名>] [[DEFAULT] COLLATE <校对规则名>];例如: C…...
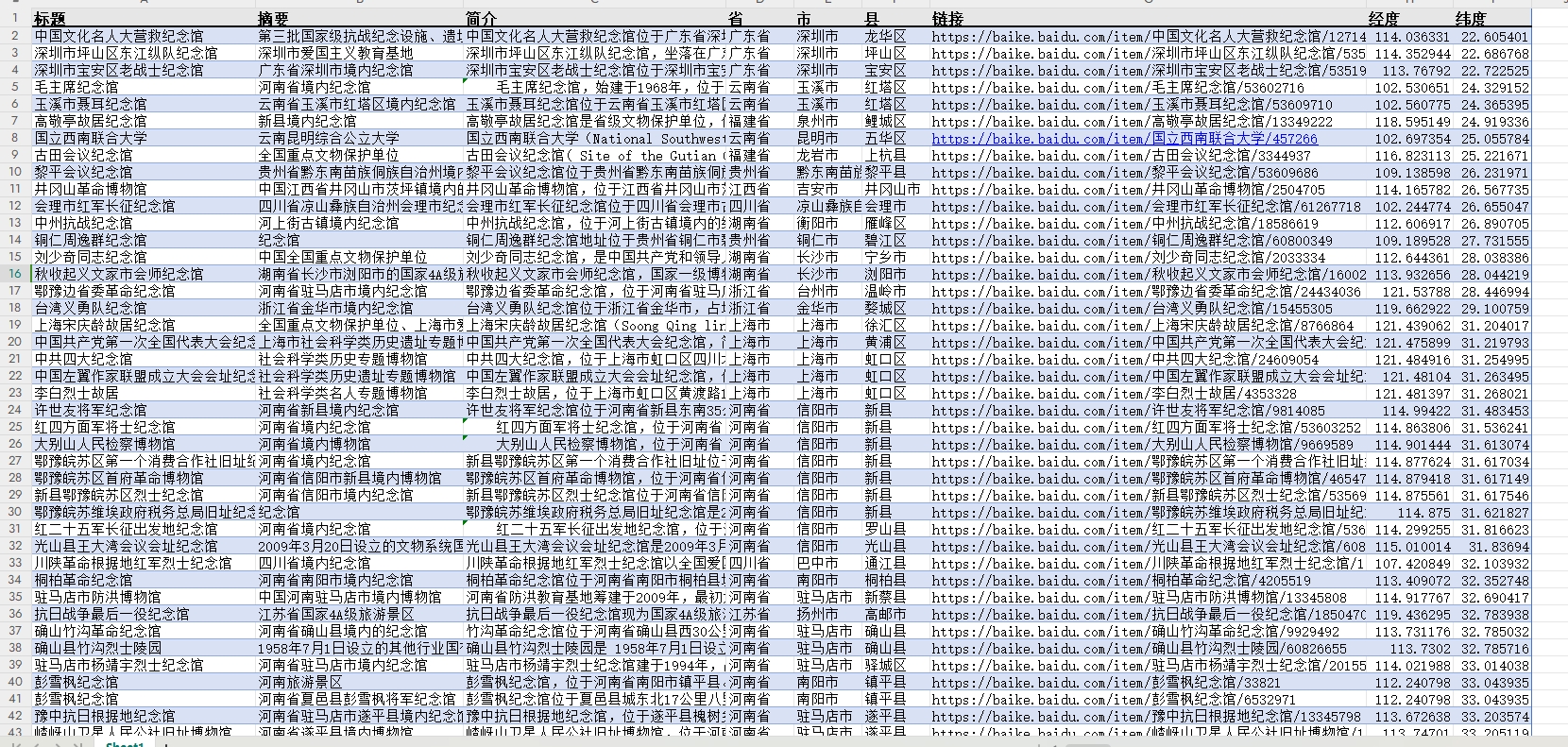
【更新】红色文化之红色博物馆数据集(经纬度+地址)
数据简介:红色博物馆作为国家红色文化传承与爱国主义教育的重要基地,遍布全国各地,承载着丰富的革命历史与文化记忆。本数据说明旨在汇总并分析全国范围内具有代表性的红色博物馆的基本信息,包括其地址、特色及教育意义࿰…...

Python项目Flask框架整合Redis
一、在配置文件中创建Redis连接信息 二、 实现Redis配置类 import redis from config.config import REDIS_HOST, REDIS_PORT, REDIS_PASSWD, REDIS_DB, EXPIRE_TIMEclass RedisDb():def __init__(self, REDIS_HOST, REDIS_PORT, REDIS_DB, EXPIRE_TIME, REDIS_PASSWD):# 建立…...

完整网络模型训练(一)
文章目录 一、网络模型的搭建二、网络模型正确性检验三、创建网络函数 一、网络模型的搭建 以CIFAR10数据集作为训练例子 准备数据集: #因为CIFAR10是属于PRL的数据集,所以需要转化成tensor数据集 train_data torchvision.datasets.CIFAR10(root&quo…...

高效便捷,体验不一样的韩语翻译神器
嘿,大家好啊!今天想跟大家聊聊我用过的几款翻译神器,特别是它们在翻译韩语时的那些小感受。作为一个偶尔需要啃啃韩语资料或者跟韩国朋友聊天的普通人,我真心觉得这些翻译工具简直就是我的救星! 一、福昕在线翻译 网址…...

2026年游戏主题海报制作复盘:从找图卡壳到快速出稿的全过程
我是个游戏社群的运营,这周五前要给周末的线上活动赶一张主题海报。主题是经典的游戏角色风格,类似大家熟知的“马里奥”那种。听起来不难,但真动起手来,我卡了两天,主要是找不到风格统一、清晰度又够用的素材。直接用…...

ArduinoIDE调试ESP32的5个隐藏技巧:从串口监视器到错误定位的实战手册
ArduinoIDE调试ESP32的5个隐藏技巧:从串口监视器到错误定位的实战手册 当你在深夜赶项目时,突然遇到ESP32编译报错却找不到问题所在;当你精心编写的代码上传后,串口监视器却一片空白;当你试图追踪变量值时,…...
)
PyTorch钩子方法实战:如何用register_forward_hook提取中间层特征图(附代码避坑指南)
PyTorch钩子方法实战:如何用register_forward_hook提取中间层特征图(附代码避坑指南) 在深度学习的模型开发与调试过程中,中间层特征图的可视化与分析是理解模型行为的关键手段。PyTorch提供的register_forward_hook方法ÿ…...

OpCore Simplify:自动化配置黑苹果系统部署的创新方法——从配置困境到高效部署的转变
OpCore Simplify:自动化配置黑苹果系统部署的创新方法——从配置困境到高效部署的转变 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 作为…...

如何解决Sublime Text乱码问题:编码转换工具完全指南
如何解决Sublime Text乱码问题:编码转换工具完全指南 【免费下载链接】ConvertToUTF8 A Sublime Text 2 & 3 plugin for editing and saving files encoded in GBK, BIG5, EUC-KR, EUC-JP, Shift_JIS, etc. 项目地址: https://gitcode.com/gh_mirrors/co/Conv…...

Qwen2.5-VL-7B-Instruct新手入门:从安装到第一个图文对话
Qwen2.5-VL-7B-Instruct新手入门:从安装到第一个图文对话 1. 环境准备与快速部署 1.1 硬件要求 Qwen2.5-VL-7B-Instruct是专为RTX 4090显卡优化的多模态大模型,需要满足以下硬件条件: 显卡:NVIDIA RTX 4090(24GB显…...

ESP32 WiFi-AP 模式实战:从零搭建智能设备热点连接方案
1. ESP32 WiFi-AP模式入门指南 第一次接触ESP32的WiFi功能时,我被它的灵活性惊艳到了。这块小小的开发板不仅能连接现有WiFi网络,还能自己创建热点,就像个迷你无线路由器。今天我要分享的是如何让ESP32变身热点,让你的手机、电脑直…...

【C++】一篇带你了解C++中的动态内存管理
首先我们先了解一下C/C程序内存分配的几个区域:代码语言:javascriptAI代码解释int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] { 1, 2, 3, 4 };char char2[] "abcd"…...

【MySQL 的 ONLY_FULL_GROUP_BY 模式】
引言: 作为一个菜鸟,当写sql中涉及到group by这样简单的语句时,也会出现问题,我在牛客网上做sql题时,总报这个错:ONLY_FULL_GROUP_BY 到底是什么东西呢? 今天写篇文章解释一下。一、GROUP BY使用…...
)
【2026年最新600套毕设项目分享】springboot躲猫猫书店管理系统(14147)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...