深度学习基础及技巧
机器学习中的监督学习
监督学习是通过对数据进行分析,找到数据的表达模型,对新输入的数据套用该模型做决策
主要分为训练和预测两个阶段
训练阶段:根据原始数据进行特征提取,然后使用决策树、随机森林等模型算法分析数据之间的特征或关系,最终得到关于输入数据的模型
预测阶段:按照同样特征工程的方法提取数据后,使用训练阶段得到的模型对特征向量进行预测,得到所属标签
深度学习
深度学习是机器学习的分支,属于监督学习的一种。然而深度学习不需要我们自己去提取特征,而是自动提取数据高维特征,大量节约时间
神经网络:
反向传播算法能够有效解决感知机异和回路的问题,使得训练多层的神经网络模型变成现实
非线性激活函数使得神经元模型能够解决非线性复杂数据分布问题
训练阶段:准备好原始数据和与之对应的分类标签数据,通过训练得到模型A
预测阶段:对新的数据套用该模型,预测新输入数据类别
训练阶段
对输入和输出数据进行量化
输入层神经元节点数为输入数据的个数
输出层神经元节点数为需要分类的个数
隐层神经元节点数目越多,神经网络的非线性越显著,增强神经网络的健壮性
训练阶段目标:通过算法不断修正权值向量W和偏置b,使其尽可能与真实模型接近
做法:使损失函数尽可能小,变为优化问题,使用反向传播算法求得网络模型所有参数的梯度,通过梯度下降算法对网络的参数进行更新
预测阶段
此时神经网络结构中所有参数都已知,只需要将向量化后的数据从神经网络输入层开始输入,顺着数据流动的方向在网络中进行计算,最终得到分类结果
梯度下降算法
沿着与梯度向量(损失函数对变量求偏导)相反的方向更新变量减少最快,直至损失收敛到最小值(梯度接近0),其中学习率控制梯度下降幅度或快慢。
越接近目标值,变化越小,梯度下降速度越慢
常见梯度下降算法
批量梯度下降算法Batch Gradient Descent
所有样本都参与参数的更新
优点:易于得到全局最优解;总体迭代次数不多
缺点:当样本数目很多时,训练时间过长,收敛速度变慢
随机梯度下降算法Stochastic Gradient Descent
从m个样本中随机抽取n个样本求解梯度
优点:训练速度快 ,每次迭代计算量少
缺点:准确度下降,得到的不一定是全局最优;总体迭代次数比较多
小批量随机梯度下降算法 Min-batch SGD
前两种算法的折衷,每次随机从m个样本中抽取k个进行迭代求梯度,每一次抽取方式是随机的,因此部分样本会重复。好处是计算梯度使让数据与数据之间产生关联,避免数据最终只能收敛到局部最优解
比较BGD与Min-batch SGD
BGD下降轨迹平滑,经过多次迭代后达到全局最优解处
Min-batch SGD在下降过程中有持续的小幅震荡,但每次迭代数据量少,能够更快找到全局最优解
反向传播算法
用于求解网络参数的梯度,利用链式求导法则,求出网络模型中的每个参数的导数
神经网络训练过程
从网络的输出层开始,反向计算神经网络中每一个参数的梯度,通过梯度下降算法,以一定的学习率对参数进行更新,接着运行一次向前传播算法,得到新的损失值
激活函数
激活函数性质
(1)单调可微
(2)限制输出值的范围。根据极限值判断是否需要激活神经元
(3)非线性
Sigmoid函数
是一种在不删除数据的情况下,减少数据的极值或异常值的函数。未激活值为0,完全饱和的激活值为1。
优点:
输出值映射在[0,1]范围内;
易于求导;
输出值为独立概率 ,可以用在输出层
缺点:
函数容易饱和,导致训练结果不佳
输出不是零均值,数据存在偏差,分布不均匀
双曲正切函数Tanh
归一化范围[-1,1]
可以更容易处理负数
0均值,数据分布平均
比Sigmoid函数收敛速度更快,易于训练
没有改变Sigmoid函数由饱和性引起的梯度消失问题
ReLU函数
优点:
在随机梯度下降算法中能快速收敛
梯度为0或常数,缓解梯度消散问题
引入稀疏激活性,在无监督预训练时也有较好的表现
缺点:
神经元在训练中不可逆死亡
随着训练的进行,可能会出现神经元死亡、权值无法更新的现象,流经神经元的梯度从该点开始将永远是0
Softmax函数
本质将一个K维的任意实数向量压缩映射成另一个K维的实数向量,其中向量的每个元素取值介于(0,1)范围内
是对逻辑回归(处理二分类问题)的推广,用于处理多分类问题
一般使用softmax函数获得同分布最高概率最伟输出结果
Batch Normalization层
让下一层的输入数据有相同的分布
如果遇到神经网络训练时收敛速度慢,或梯度爆炸或梯度消失等无法训练的状况都可以尝试加入BN层观察训练结果
损失函数
回归损失函数
均方误差损失函数Mean Squared Error Loss MSE
可以看作欧式距离的计算公式,对异常值非常敏感,平方操作会放大异常值。如果异常值较多,可以使用平均绝对误差作为损失函数
一般先把输入数据归一化到一个合理范围内然后使用均方误差或平均绝对误差计算损失
因为小范围的数据方便GPU/CPU运算,并提高浮点运算精度,方便观察数据的变化趋势和变化形式
分类损失函数
Logistic损失函数
Logistic损失函数为每一个分类产生一个有效的概率,为了让某一分类的概率最大,引入最大似然估计函数。在最大似然估计函数中,定义一个损失函数为loss(Y,P(Y|X)),利用已知样本X的分布,找到最有可能的参数使得样本X属于Y 的概率P(Y|X)最大
负对数似然损失函数
将最大似然函数中的连乘转化为求和,在前面加一个负号,最大化概率等价于寻找最小化的损失
交叉熵损失函数
前两个损失函数都只能处理二分类问题,交叉熵损失函数可以处理多分类问题
常用的激活函数和损失函数组合
Leak ReLU+MSE
Leak ReLU可以减少梯度消失
Sigmiod Logistic
Softmax+交叉熵损失函数
超参数
也是调优参数,目的是让模型训练的效果更好,收敛速度更快
学习率
学习率过大:权重参数可能会越过最优值,在误差最小的一侧来回跳动
学习率过小:许哟啊很长优化时间,导致算法长时间无法收敛
好的学习率对应的误差曲线具有很好的平滑性
动量
物理意义:当把球推下山时,球会不断累积动量,速度越来越快,当上坡时动量减小
当梯度保持相同方向维度时动量不断增大;而梯度方向不断变化时动量持续减少,因此可以加快收敛速度并减少震荡
当前梯度方向与前一步的梯度方向一样,则增加这一步的权值更新,否则减少参数更新,最终达到在一定程度上增加稳定性,加快学习速率,并有一定的摆脱局部最优的能力
动量系数取值0-1,常用取值为0.5,0.9,0.95,0.99。在网络训练的起始阶段由于梯度可能很大,初始值设为0.5,当梯度下降到一定程度时,可以改为0.9或更大
数据集
原始数据分为训练集,验证集,测试集
训练集:训练网络模型或确定网络模型参数
测试集:测试已经训练好的网络模型的泛化能力,不能保证模型的正确性,仅用于检验该模型是否满足期望
验证集:辅助模型优化。在模型训练过程中,可以通过验证集来观察模型的拟合情况,还可以通过验证集确定一些超参数(根据验证集精确率确定迭代次数,收敛情况确定学习率)
划分数据
划分数据。让不同数据集之间各自的方差不会相差太大
可以将数据集按8:2划分为训练集和测试集,从测试集中随机抽取80%的数据进行多次训练,把训练集剩下的数据作为验证集,观察不同抽取结果在测试集中的性能,把最好的一次训练结果当作最终模型
数据预处理
0均值:数据中每一维度的数据减去所在维度的数据均值
归一化:将0均值后的数据除以每一维的标准差
主成分分析:寻找有效表示数据主轴的方向,通过线性变换,将原始数据变化为一组各维度线性无关的数据,可用于提取数据的主要特征分量,常用于高维数据的降维,有效减少后续计算量,降低数据噪声
具体做法:
对数据进行0均值处理,然后计算协方差矩阵,得到数据不同维度之间的相关性,接着对协方差矩阵进行SVD分解,返回的U矩阵是按照特征值的大小排序的,通过选取前几个特征向量来降低数据的维度
白化:降低数据的冗余性,使得特征之间相关性较低,所有特征有相同的方差
将主成分分析去相关后的数据,从对角矩阵变成单位矩阵,使得数据有相同的方差
缺点:将数据的维度拉伸到相同的大小,扩大数据的噪声
网络的初始化
把模型的权重和偏置参数初始化为0是不科学的,为了让初始化的权重参数尽可能小但不是0,可以参考高斯分布函数,使用独立高斯随机变量来选择初始化模型的权重和偏置
在实际工程实践中,为了避免重新训练网络模型参数花费大量的时间,可以使用ImageNet数据集已经训练好的模型,加载到网络中开始训练,节省时间
网络过度拟合
泛化:指容错能力,可以接受一定的错误输入,经过内部纠正后输出正确的结果
出现过拟合后可以:
(1)增加训练集的数据,同时增加数据的多样性,但不够,因为提升过的数据仍可能是高度相关的
(2)关注网络模型允许存储的信息量(熵容量),只能存储少量信息的网络模型,其存储的特征将会集中在真正相关的特征上,使得网络拥有更好的泛化能力。可以调整模型的层数和每层的规模,也可以在网络权重更新时进行正则化约束
正则化方法
最大作用:防止过拟合,提高网络模型的泛化能力
做法:在损失函数中增加惩罚因子
由于特征过多而导致的过度拟合可以通过以下方法解决
(1)减少特征
(2)惩罚不重要特征(正则化)
正则化常见方法
L2正则化
在损失函数后加上L2正则化项(所有权值的平方和除以训练集中的样本大小n,正则化系数用来调节正则化项和原始损失值的比重)
L2正则化可以让权值变得更小,更小的权值表示神经网络的复杂度更低,网络模型相对简单,越简单引起的过拟合可能性越小
L1正则化
在损失函数后加上L1正则化项(权值w绝对值的和),当权值为正时,更新后的权值变小;当权值为负时,更新后的权值变大。目的是让权值趋于0,使得神经网络中的权值尽可能小,减小网络复杂度,防止过拟合
输入神经网络中的训练集数据越多,正则化系数的作用就越小,因为数据越多,出现过拟合的可能性就会降低
Dropout层
L1,L2正则化是通过修改损失函数实现的,而Dropout层是通过修改神经网络的模型实现的。
具体是在神经网络训练时让部分隐层神经元失效,进而不能对其权重参数和偏置进行更新。
因为在每次训练时,神经元之间随机地被移除,可以让一个神经元的出现不依赖于另一个神经元,阻止特征互相依赖,减少错误信息的传递,防止过度拟合
实际操作中Dropout的概率通常为50%
训练过程的技巧
精确率曲线和损失曲线
深度神经网络模型的训练时间长,不应该一直等待训练结束,应该持续观察精确率曲线和损失值曲线,不满足期望及时停止训练
在精确率曲线发现训练和验证集精确率差异越来越大,意味着模型过拟合;
如果验证集和训练集精确率曲线差别较少,但两者精度都无法提升,则意味着神经网络模型的学习能力差
网络微调fine-tune
将预先训练好的模型权重文件的整体或部分用到类似的任务中,称为网络模型的微调
优点:节省训练时间;当新数据集很小时,直接训练容易造成过度拟合,网络微调可以避免发生该情况
相关文章:

深度学习基础及技巧
机器学习中的监督学习 监督学习是通过对数据进行分析,找到数据的表达模型,对新输入的数据套用该模型做决策 主要分为训练和预测两个阶段 训练阶段:根据原始数据进行特征提取,然后使用决策树、随机森林等模型算法分析数据之间的特…...

Unity 外描边简单实现(Shader Graph)
1:原理 将物体的模型空间的位置(也就是顶点数据)放大,作为一个单独的渲染通道单独渲染,这时候模型是已经发大过的,要想看到外描边的效果,需要将正面显示的东西给去掉,显示背面渲染的…...

text2sql方法:NatSQL和DIN-SQL
NatSQL NatSQL出自2021年9月的论文《Natural SQL: Making SQL Easier to Infer from Natural Language Specifications》(github),它是一种SQL 中间表征(SQL intermediate representation(IR))方法。 NatSQL作者认为Text2SQL的关键挑战是自然语言描述和其对应的SQ…...

【新闻转载】Storm-0501:勒索软件攻击扩展到混合云环境
icrosoft发出警告,勒索软件团伙Storm-0501近期调整了攻击策略,目前正将目标瞄准混合云环境,旨在全面破坏受害者的资产。 该威胁行为者自2021年首次露面,起初作为Sabbath勒索软件行动的分支。随后,他们开始分发来自Hive…...
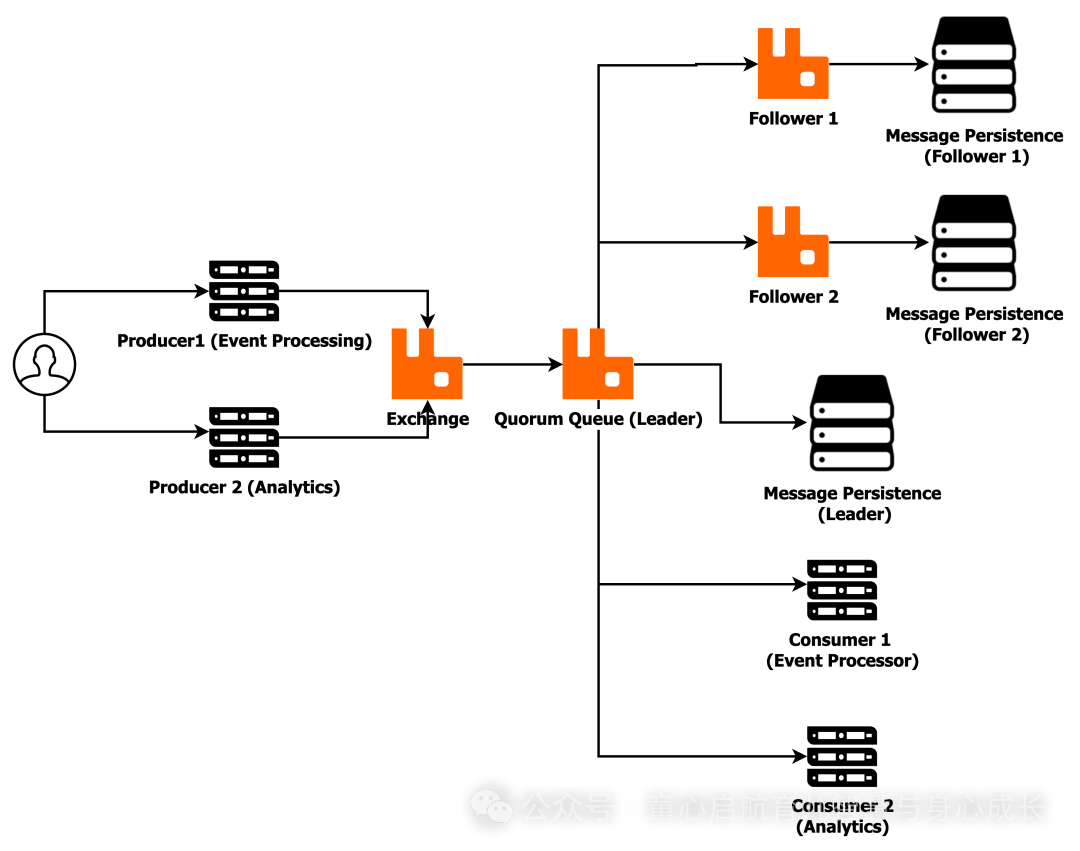
RabbitMQ 队列之战:Classic 和 Quorum 的性能洞察
RabbitMQ 是一个功能强大且广泛使用的消息代理,它通过处理消息的传输、存储和交付来促进分布式应用程序之间的通信。作为消息代理,RabbitMQ 充当生产者(发送消息的应用程序)和使用者(接收消息的应用程序)之…...

Spring Boot 集成 MySQL 的详细指南
在现代软件开发中,Spring Boot 因其简单易用而成为构建 Java 应用程序的热门选择。结合 MySQL这一常用关系型数据库,开发者可以快速构建出功能完善的后端服务。本文将详细介绍如何将 Spring Boot 与 MySQL 集成,提供从环境搭建到代码实现的全…...

python格式化输入输出
以下是使用 format()、f-string 和百分号 % 运算符进行 Python 数据格式化输入输出的示例代码。 1. 使用 format() 方法进行格式化 # 使用 format() 方法格式化数据并输出到文件 name "Alice" age 25 score 92.5# 格式化字符串 formatted_string "Name: {…...

音视频入门基础:FLV专题(10)——Script Tag实例分析
一、引言 在《音视频入门基础:FLV专题(9)——Script Tag简介》中对FLV文件的Script Tag进行了简介。下面用一个具体的例子来对Script Tag进行分析。 二、Script Tag的Tag header实例分析 用notepad打开《音视频入门基础:FLV专题…...

国外问卷调查匠哥已经不带人了,但是还可以交流
国外问卷调查匠哥已经不带人了,但是还可以来和匠哥交流, 为啥不带人了呢? 从今年年初开始,匠哥在带学员的过程中发现: 跟往年同样的收费,同样的教学,甚至我付出的时间精力比以前还多ÿ…...

Linux 进程的基本概念及描述
目录 0.前言 1. 什么是进程 1.1 进程的定义与特性 1.2 进程与线程的区别 2.描述进程 2.1 PCB (进程控制块) 2.2 task_struct 3.查看进程 3.1 查看进程信息 3.1.1 /proc 文件系统 3.1.2 ps 命令 3.1.2 top 和 htop 命令 3.2 获取进程标识符 3.2.1使用命令获取PID 3.2.2 使用C语言…...

【C++】透过STL源代码深度剖析vector的底层
✨ Blog’s 主页: 白乐天_ξ( ✿>◡❛) 🌈 个人Motto:他强任他强,清风拂山冈! 🔥 所属专栏:C深入学习笔记 💫 欢迎来到我的学习笔记! 参考博客:【C】透过STL源…...

ubuntu 开启root
sudo passwd root#输入以下命令来给root账户设置密码 sudo passwd -u root#启用root账户 su - root#要登录root账户 root 开启远程访问: 小心不要改到这里了:sudo nano /etc/ssh/ssh_config 而是:/etc/ssh/sshd_config sudo nano /etc/ssh…...
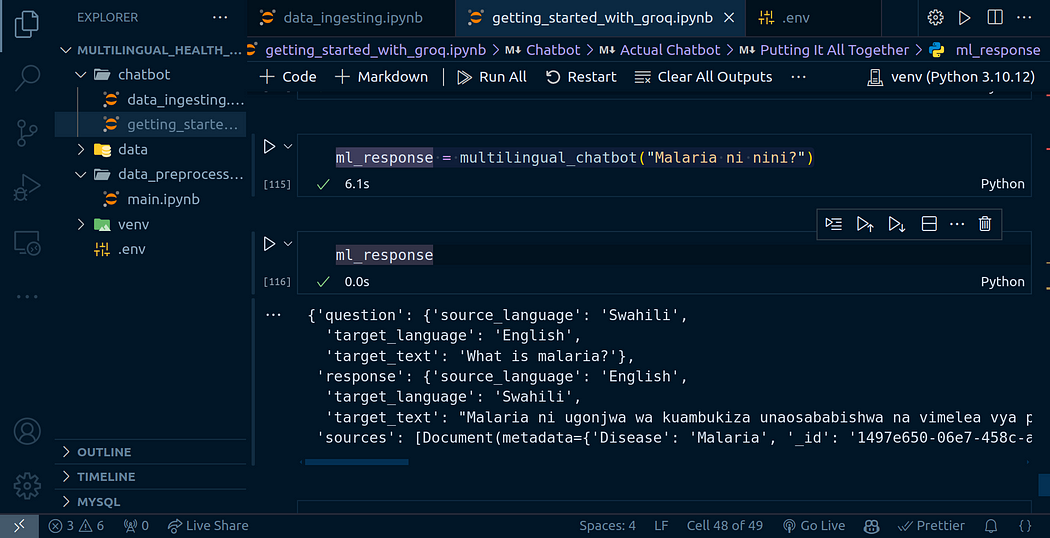
使用 Llama 3.1 和 Qdrant 构建多语言医疗保健聊天机器人的步骤
长话短说: 准备好深入研究: 矢量存储的复杂性以及如何利用 Qdrant 进行高效数据摄取。掌握 Qdrant 中的集合管理以获得最佳性能。释放上下文感知响应的相似性搜索的潜力。精心设计复杂的 LangChain 工作流程以增强聊天机器人的功能。将革命性的 Llama …...

【Linux-基础IO】如何理解Linux下一切皆文件磁盘的介绍
目录 如何理解Linux系统上一切皆文件 1.物理角度认识磁盘 2.对磁盘的存储进行逻辑抽象 磁盘寻址 3.磁盘中的寄存器 如何理解Linux系统上一切皆文件 计算机中包含大量外设,操作系统想要管理好这些外设,就必须对这些外设进行先描述再组织,…...

Golang | Leetcode Golang题解之第436题寻找右区间
题目: 题解: func findRightInterval(intervals [][]int) []int {n : len(intervals)type pair struct{ x, i int }starts : make([]pair, n)ends : make([]pair, n)for i, p : range intervals {starts[i] pair{p[0], i}ends[i] pair{p[1], i}}sort.…...

微服务SpringSession解析部署使用全流程
目录 1、SpringSession简介 2、实现session共享的三种方式 1、修改Tomcat配置文件 2、Nginx负载均衡策略 3、redis统一存储 0、准备工作 1、本地服务添加依赖 2、修改本地服务配置文件 3、添加application.properties文件 4、添加nacos - redis配置 5、修改本地项目…...

自动驾驶 3DGS 学习笔记
目录 street_gaussians gsplat依赖项 运行报错: python>3.9 SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior 差分高斯光栅化 diff-gaussian-rasterization street_gaussians https://github.com/zju3dv/street_gaussians gsp…...

【C++笔试强训】如何成为算法糕手Day5
学习编程就得循环渐进,扎实基础,勿在浮沙筑高台 循环渐进Forward-CSDN博客 目录 循环渐进Forward-CSDN博客 第一题:游游的you 思路: 第二题:腐烂的苹果 思路: 第三题:孩子们的游戏 思路&…...

【Qt】无IDE的Gui程序快速开始
Qt安装 在 Windows 上安装 Qt 的步骤如下: 下载 Qt 安装程序 访问 Qt 的官方网站:Qt Downloads。点击“Download”按钮,下载 Qt Online Installer(在线安装程序)。 运行安装程序 双击下载的 QtInstaller.exe 文件…...

Python编码系列—Python备忘录模式:掌握对象状态保存与恢复技术
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

国产大模型新王登基?Qwen3.7-Max全球第五、编程Agent登顶,千问APP免费体验全攻略
AI前线观察 | 2026.05.25 就在刚刚过去的阿里云峰会上,通义千问甩出了一张“王炸”。万亿参数MoE架构的旗舰模型Qwen3.7-Max正式接入千问APP、PC端及网页端。这不仅仅是一次版本更新,更是国产大模型在权威第三方榜单中首次稳居全球前五、国产第一的里程碑…...

公共卫生机器学习项目中的算法公平性实践:ACAR框架详解
1. 项目概述:当机器学习遇见公共卫生,公平性为何成为“必答题”?在公共卫生领域,机器学习(ML)正以前所未有的速度渗透到疾病监测、风险分层和资源分配等核心环节。想象一下,一个模型被用来预测某…...

5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣
5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否正在寻找一款能够彻底改变Windows掌机游戏体验的控制软件…...

学习课程学习报告
本周主要学习了深度学习的基础理论,包括深度学习的数学本质、激活函数、前向传播与反向传播的原理。重点理解了非线性激活函数对模型表达能力的作用,掌握了前向传播的矩阵表示,并推导了反向传播的梯度计算过程,为后续神经网络训练…...