大数据-154 Apache Druid 架构与原理详解 基础架构、架构演进
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(正在更新…)
章节内容
上节我们完成了如下的内容:
- Apache Druid 从 Kafka 中加载数据
- 实际测试 可视化操作

基础架构

Coordinator Node
主要负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期,协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、负责均衡移动数据
Coordinator是周期运行的(由 druid.coordinator.period 配置指定,默认间隔60秒),Coordinator需要维护和ZooKeeper的连接,以获取集群的信息。Segment和Rule的信息保存在元数据中,所以也需要维护与元数据库的连接。
Overlord Node
进程监视MiddleManager进程,并且是Druid数据摄入的主节点,负责将提取任务分配给MiddleManagers并协调Segment发布,包括接受、拆解、分配Task,以及创建Task相关的锁,并返回Task的状态。
Historical Node
加载生成好的数据文件,以供数据查询。Historical Node是整个集群查询性能的核心所在,Historical会承担绝大部分的Segment查询。
- Historical 进程从 Deep Storage 中下载 Segment,并响应有关这些Segment的查询请求(这些请求来自Broker进程)
- Historical 进程不处理写入请求
- Historical 进程采用了无共享架构设计,它知道如何去加载和删除 Segment,以及如何基于 Segment 来响应查询。即便底层的深度存储无法正常工作,Historical 进程还是能针对其已同步的 Segments,正常提供查询服务。
- 底层的深度存储无法正常工作,Historical进程还是能针对其已同步的 Segments,正常提供查询服务。
MiddleManager Node
及时摄入实时数据,生成Segment数据文件
- MiddleManager 进程是执行提交任务的工作节点,MiddleManagers将任务转发给在不同JVM中运行的Peon进程
- MiddleManager、Peon、Task的对应关系是:每个Peon进程一次只能运行一个Task任务,但一个MiddleManager却可以管理多个Peon进程
Broker Node
接收客户端查询请求,并将这些查询转发给 Histo 和 MiddleManagers。当Brokers从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者。
- Broker 节点负责转发Client查询请求的
- Broker 通过 ZooKeeper 能够知道哪个 Segment 在哪些节点上,将查询转发给相应节点
- 所有节点返回数据后,Broker会所有节点的数据进行合并,然后返回给Client
Router Node
(可选)
负责将路由转发到Broker、Coordinator、Overlords
- Router进程可以在 Broker、Overlords、Coordinator进程之上,提供一层统一的API网关
- Router进程是可选的,如果集群数据规模已经到达了TB级别,需要考虑启动(druid.router.managerProxy.enable=true)
- 一旦集群规模达到一定数量级,那么发生故障的概率就会变得不容忽视,而Router支持将请求只发送给健康的节点,避免请求失败。
- 同时,查询的响应时间和资源消耗,也会随着数据量的增长而变高,而Router支持设置查询的优先级和负载均衡策略,避免了大查询造成的队列堆积或查询热点等问题
如何分类
Druid的进程可以被任意部署,为了理解与部署组织方便,这些进程分为了三类:
- Master:Coordinator、Overlord 负责数据可用性和摄取
- Query:Broker、Router 负责处理外部请求
- Data:Historical、MiddleManager,负责实际的Ingestion负载和数据存储
其他依赖
Deep Storage
存放生成的 Segment 数据文件,并供历史服务器下载,对于单节点集群可以是本地磁盘,而对于分布式集群一般是HDFS。
- Druid使用 Deep Storage来做数据的备份,也作为Druid进程之间在后台传输数据的一种方式
- 当相应查询时,Historical首先从本地磁盘读取预取的段,这也意味着需要在Deep Storage和加载的数据Historical中拥有足够的磁盘空间。
Metadata Storage
存储Durid集群的元数据信息,如Segment的相关信息,一般使用MySQL。
ZooKeeper
为Durid集群提供以执行协调任务,如内部服务的监控,协调和领导者选举
- Coordinator 节点的 Leader 选举
- Historical 节点发布 Segment 的协议
- Coordinator 和 Historical 之间 load、drop Segment的协议
- Orverlord节点的Leader选举
- Overlord和MiddleManger之间Task管理
架构演进
初始版本~0.6.0
2012-2013年

0.7.0~0.12.0
2013年-2018年

集群管理

0.13.0~当前版本

Lambda架构
从大的架构上看,Druid是一个Lambda架构。
Lambda架构是由Storm坐着Nathan Marz提出的一个实时大数据处理框架,Lambda架构设计是为了处理大规模数据时,同时发挥流处理和批处理的优势:
- 通过批处理提供全面、准确的数据
- 通过流处理提供低延迟的数据
从而达到平衡延迟、吞吐量和容错性的目的,为了满足下游的及时查询,批处理和流处理的结果会合并。
Lambda架构包含三层:BatchLayer、SpeedLayer、Serving Layer
- BatchLayer:批处理层,对离线的历史数据进行预计算,为了下游能够快速查询想要的结果,由于批处理基于完成的历史数据集,准确性可以得到保证,批处理层可以用Hadoop、Spark、Flink等框架计算。
- SpeedLayer:加速处理层,处理实时的增量数据,这一层重点在于低延迟,加速层的数据不如批处理层那样完整和准确,但是可以填补批处理高延迟导致的数据空白。加速层可以使用Storm、Spark Streaming和Flink等框架计算。
- ServingLayer:合并层,将历史数据、实时数据合并在一起,输出到数据库或者其他介质,供下游分析

流式数据链路
Raw Data - Kafka - Streaming Processor(Optional 实时ETL)- Kafka(Optional)- Druid - Application/User
批处理数据链路
Raw data - Kafka(Optional) - HDFS - ETL Process(Optional)- Druid - Application/User
相关文章:
大数据-154 Apache Druid 架构与原理详解 基础架构、架构演进
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

centos9 nginx 版本
centos9 安装 ssh -V OpenSSH_8.7p1, OpenSSL 3.2.2 4 Jun 2024 openssl version OpenSSL 3.2.2 4 Jun 2024 (Library: OpenSSL 3.2.2 4 Jun 2024) sudo yum install nginx Installing:nginx x86_64 2:1.20.1…...

https访问报错:net::ERR_CERT_DATE_INVALLD
目录 简介异常排查原因解决补充 简介 访问https资源出现报错 异常 排查 将地址拿到浏览器进行访问,可以很清晰的看到出现该问题的原因 原因 1、SSL证书已过期 2、服务器日期不准,不在证书有效期 解决 1、重新申请SSL证书,并配置 2、校正…...

cat用来查看文件内容、合并文件,或者将文件内容输出到终端
cat 是 Unix 和 Linux 系统中的一个命令,它的名称来源于 “concatenate”(连接),主要用来查看文件内容、合并文件,或者将文件内容输出到终端。 常用用法 查看文件内容 cat filename输出 filename 的内容到终端中。 例…...

基于ssm大学生自主学习网站的设计与实现
文未可获取一份本项目的java源码和数据库参考。 1、毕业论文(设计)的背景及意义: (1)研究背景 目前,因特网是世界上最大的计算机互联网络,它通过网络设备将世界各地互相独立的不同规模的局域…...
C++11基于范围的for循环)
C++基础补充(01)C++11基于范围的for循环
文章目录 1. 基本语法1.1 decalaration默认获取值引用&自动类型推导(auto) 1.2 container数组STL容器初始化列表自定义类型返回容器的函数 2. 其他示例2.1 遍历数组2.2 遍历vector,并修改元素2.3 使用常量引用遍历,防止容器中…...

qt6 使用QPSQL
检查可用的数据库驱动: // iteator all database driverQStringList drivers QSqlDatabase::drivers();QStringList::iterator it;for (it drivers.begin(); it ! drivers.end(); it){qDebug() << *it;} qt6 自带pg数据库驱动: pro文件加个说明&…...
和窗口函数)
【PostgreSQL】提高篇——公用表表达式(CTE)和窗口函数
在这篇文章中,我将详细介绍 PostgreSQL 中的公用表表达式(CTE)和窗口函数,帮助你理解如何使用它们进行复杂的数据分析。我将通过具体的示例来演示这些概念的实际应用,并在每个示例中提供详细的解释和注释。 1. 公用表…...

【min25筛】【CF2020F】Count Leaves
题目 定义 f ( n , 0 ) 1 f(n,0)1 f(n,0)1, f ( n , d ) ∑ k ∣ n f ( k , d − 1 ) f(n,d)\sum_{k|n}f(k,d-1) f(n,d)∑k∣nf(k,d−1) 给出 n , k , d n,k,d n,k,d,你需要求出: ∑ i 1 n f ( i k , d ) m o d ( 1 0 9 7 ) \sum_{i1}^n f(i^k…...

【d57】【sql】1661. 每台机器的进程平均运行时间
思路 一方面考察自连接,另一方面考察group by 这里主要说明 group by 用法: 1.在 SQL 查询中,GROUP BY 子句用于将结果集中的行分组,目的通常就是 对每个组应用聚合函数(如 SUM(), AVG(), MAX(), MIN(), COUNT() 等…...
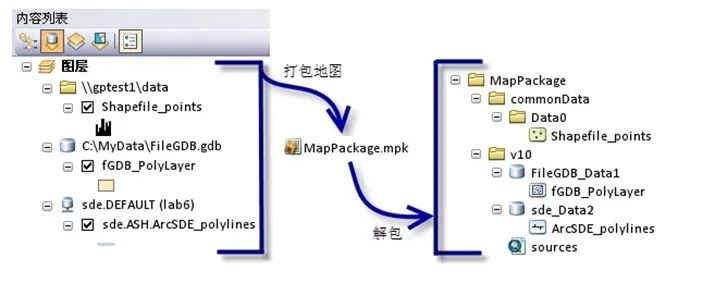
ArcGIS共享数据的最佳方法(不丢可视化、标注等各类显示信息一样带)
今天我们介绍一下ArcGIS数据共享的几个小妙招 我们时常要把数据发给对方,特别是很多新手朋友要将shp发给对方时只是发送了shp后缀的文件,却把shp的必要组成文件dbf、shx等等给落下了。 还有很多朋友给图层做好了符号化标注,但是数据一发给别…...
当前页面与navigateTo页面之间数据通信)
小程序this.getOpenerEventChannel()当前页面与navigateTo页面之间数据通信
this.getOpenerEventChannel() 是微信小程序中获取页面打开它的页面事件通道的方法。但是,这个方法只在页面是被wx.navigateTo打开的情况下才能使用。如果页面是通过其他方式打开的,比如wx.redirectTo,那么就无法使用这个方法。 解决方案&…...

调用飞书接口导入供应商bug
1、业务背景 财务这边大部分系统都是供应商项目,由于供应商的研发人员没有飞书项目的权限,涉及到供应商系统需求 财务这边都是通过多维表格进行bug的生命周期管理如图: 但多维表格没有跟飞书项目直接关联,测试组做bug统计的时候无…...

《深度学习》OpenCV 角点检测、特征提取SIFT 原理及案例解析
目录 一、角点检测 1、什么是角点检测 2、检测流程 1)输入图像 2)图像预处理 3)特征提取 4)角点检测 5)角点定位和标记 6)角点筛选或后处理(可选) 7)输出结果 3、邻域…...

golang grpc初体验
grpc 是一个高性能、开源和通用的 RPC 框架,面向服务端和移动端,基于 HTTP/2 设计。目前支持c、java和go,分别是grpc、grpc-java、grpc-go,目前c版本支持c、c、node.js、ruby、python、objective-c、php和c#。grpc官网 grpc-go P…...

基于小程序+Vue + Spring Boot的进销存库存出库入库统计分析管理系统
目录 一、项目背景及需求分析 1. 项目背景 2. 需求分析 二、系统架构设计 1. 技术选型 2. 模块划分 三、数据库设计数据库表结构 四、前端实现 五、后端实现 1. RESTful API设计 2. 数据库操作 六、安全性和性能优化 1. 安全性 2. 性能优化 七、测试与部署 1. …...

【数据结构与算法】时间复杂度和空间复杂度例题
文章目录 时间复杂度常数阶时间O(1)对数阶时间O(logN)线性阶时间O(n)线性对数阶时间O(nlogN)平方阶时间O(n*n) 空间复杂度常量空间O(1)线性空间O(n)二维空间O(n*n)递归空间 时间复杂度 常数阶时间O(1) 代码在执行的时候,它消耗的时间并不随着某个变量的增长而增长…...

停止模式下USART为什么可以唤醒MCU?
在MCU的停止模式下,USART之类的外设时钟是关闭的,但是USART章节有描述到在停止模式下可以用USART来对MCU进行唤醒: 大家是否会好奇在外设的时钟被关闭的情况下,USART怎么能通过接收中断或者唤醒事件对MCU进行唤醒的呢࿱…...

Web安全 - 路径穿越(Path Traversal)
文章目录 OWASP 2023 TOP 10导图定义路径穿越的原理常见攻击目标防御措施输入验证和清理避免直接拼接用户输入最小化权限日志监控 ExampleCode漏洞代码:路径穿越攻击案例漏洞说明修复后的安全代码代码分析 其他不同文件系统下的路径穿越特性Windows系统类Unix系统&a…...

JSR303微服务校验
一.创建idea 二.向pom.xml添加依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.7.RELEASE</version></parent><properties><java.vers…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...