Scrapy 爬虫的大模型支持
使用 Scrapy 时,你可以轻松使用大型语言模型 (LLM) 来自动化或增强你的 Web 解析。
有多种使用 LLM 来帮助进行 Web 抓取的方法。在本指南中,我们将在每个页面上调用一个 LLM,从中抽取我们定义的一组属性,而无需编写任何选择器或训练任何模型。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、启动 Scrapy 项目
按照 Web 抓取教程的启动 Scrapy 项目页面上的说明启动 Scrapy 项目。
2、安装 LLM 依赖项
本指南将使用 LiteLLM 作为 LLM 的 API。
出于本指南的目的,我们将通过 Ollama 运行 Mistral 7B LLM,但 LiteLLM 几乎可以运行任何 LLM,正如你稍后将看到的那样。
首先安装 html2text、LiteLLM 和 Ollama:
pip install html2text litellm ollama然后启动 Ollama 服务器:
ollama serve打开第二个终端,安装 Mistral 7B:
ollama pull mistral3、在你的爬虫程序中使用 LLM
现在你有一个包含简单爬虫程序和 LLM 的 Scrapy 项目可供使用,请在 tutorial/spiders/books_toscrape_com_llm.py 中使用以下代码创建第一个爬虫程序的替代方案:
import json
from json.decoder import JSONDecodeError
from logging import getLoggerimport ollama
from html2text import HTML2Text
from litellm import acompletion
from scrapy import Spiderhtml_cleaner = HTML2Text()
logger = getLogger(__name__)async def llm_parse(response, prompts):key_list = ", ".join(prompts)formatted_scheme = "\n".join(f"{k}: {v}" for k, v in prompts.items())markdown = html_cleaner.handle(response.text)llm_response = await acompletion(messages=[{"role": "user","content": (f"Return a JSON object with the following root keys: "f"{key_list}\n"f"\n"f"Data to scrape:\n"f"{formatted_scheme}\n"f"\n"f"Scrape it from the following Markdown text:\n"f"\n"f"{markdown}"),},],model="ollama/mistral",)data = llm_response["choices"][0]["message"]["content"]try:return json.loads(data)except JSONDecodeError:logger.error(f"LLM returned an invalid JSON for {response.url}: {data}")return {}class BooksToScrapeComLLMSpider(Spider):name = "books_toscrape_com_llm"start_urls = ["http://books.toscrape.com/catalogue/category/books/mystery_3/index.html"]def parse(self, response):next_page_links = response.css(".next a")yield from response.follow_all(next_page_links)book_links = response.css("article a")yield from response.follow_all(book_links, callback=self.parse_book)async def parse_book(self, response):prompts = {"name": "Product name","price": "Product price as a number, without the currency symbol",}llm_data = await llm_parse(response, prompts)yield {"url": response.url,**llm_data,}在上面的代码中:
首先定义了一个 llm_parse 函数,它接受 Scrapy 响应和要提取的字段字典及其字段特定提示。
然后,将响应转换为 Markdown 语法,以便 LLM 更轻松地解析,并向 LLM 发送一个提示,要求输入具有相应字段的 JSON 对象。
注意:构建一个以预期格式获取预期数据的提示是此过程中最困难的部分。此处的示例提示适用于 Mistral 7B 和 books.toscrape.com,但可能不适用于其他 LLM 或其他网站。
如果是有效的 JSON,则返回 LLM 结果。
使用字段提示调用 llm_parse 来提取名称和价格,并在包含非来自 LLM(url)的额外字段后生成结果字典。
现在可以运行你的代码:
scrapy crawl books_toscrape_com_llm -O books.csv在大多数计算机上,执行将需要很长时间。运行 ollama serve 的终端中的日志将显示你的 LLM 如何获取提示并为其生成响应。
执行完成后,生成的 books.csv 文件将包含 books.toscrape.com 神秘类别中所有书籍的记录(CSV 格式)。您可以使用任何电子表格应用程序打开 books.csv。
4、后续步骤
以下是一些后续步骤的想法:
- 尝试其他 LLM。
上述代码中的以下一行通过 Ollama 的本地实例确定要使用的 LLM 是 Mistral 7B:
model="ollama/mistral"如果你可以访问其他 LLM,则可以将此行更改为使用其他 LLM,并查看更改如何影响速度、质量和成本。
请参阅 LiteLLM 文档,了解许多不同 LLM 的设置说明。
- 看看你是否可以获得与 Zyte API 自动提取相同的输出(例如产品),同时具有可比的速度、质量和成本。
- 看看你是否还可以自动化抓取部分并实现与 Zyte 的 AI 驱动蜘蛛可以做的事情类似的目标。
- 尝试提取源 HTML 中无法以结构化方式获得的数据,例如书籍作者,有时可以在书籍描述中找到。
- 尝试提取源 HTML 中无法直接获得的数据,例如书籍语言(英语)、货币代码(GBP)或书籍描述的摘要。
- 尝试不同的 HTML 清理方法,或者根本不进行清理。
上面的代码将响应 HTML 转换为 Markdown,因为这允许 Mistral 7B 按预期工作。其他 LLM 可能适用于原始 HTML,可能在经过一些清理之后(请参阅 clear-html),从而能够提取转换为 Markdown 时可能丢失的一些额外数据。
但请注意,LLM 的上下文长度有限,可能需要清理和修剪 HTML 才能将 HTML 放入提示中,而不会超过该上下文长度。
- 如果你可以访问支持图像解析的 LLM,请查看是否可以扩展蜘蛛以下载书籍封面,并从中提取其他信息,例如书籍作者。
- 不要每页使用一个 LLM,而是使用 LLM 根据第一页的原始 HTML 为所需字段生成 CSS 选择器,并使用这些选择器解析所有其他页面。
这样可以最大限度地减少 LLM 的使用,以获得更好的速度和成本,但对于具有多种不同布局或执行某些布局 A-B 测试的网站,或者网站在抓取过程中更改布局的不幸情况,可能会影响质量。
原文链接:Scrapy 大模型爬虫 - BimAnt
相关文章:
Scrapy 爬虫的大模型支持
使用 Scrapy 时,你可以轻松使用大型语言模型 (LLM) 来自动化或增强你的 Web 解析。 有多种使用 LLM 来帮助进行 Web 抓取的方法。在本指南中,我们将在每个页面上调用一个 LLM,从中抽取我们定义的一组属性,而无需编写任何选择器或…...

数据仓库简介(一)
数据仓库概述 1. 什么是数据仓库? 数据仓库(Data Warehouse,简称 DW)是由 Bill Inmon 于 1990 年提出的一种用于数据分析和挖掘的系统。它的主要目标是通过分析和挖掘数据,为不同层级的决策提供支持,构成…...

Kafka和RabbitMQ区别
RabbitMQ的消息延迟是微秒级,Kafka是毫秒级(1毫秒1000微秒) 延迟消息是指生产者发送消息发送消息后,不能立刻被消费者消费,需要等待指定的时间后才可以被消费。 Kafka的单机呑吐量是十万级,RabbitMQ是万级…...

go-zero学习
go-zero官网: https://go-zero.dev/docs/tasks 好文: https://blog.csdn.net/m0_63629756/article/details/136599547 视频: https://www.bilibili.com/video/BV18JxUeyECg 微服务基础 根目录下,一个文件夹就是一个微服务。如果微…...
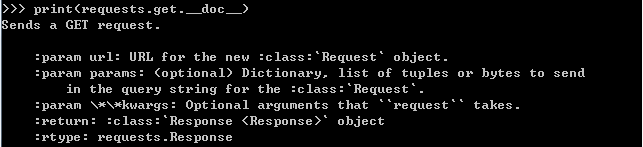
python如何查询函数
1、通用的帮助函数help() 使用help()函数来查看函数的帮助信息。 如: import requests help(requests) 会有类似如下输出: 2、查询函数信息 ★查看模块下的所有函数: dir(module_name) #module_name是要查询的函数名 如: i…...
)
计算机视觉与深度学习 | 从激光雷达数据中提取地面点和非地面点(附matlab代码)
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 激光雷达数据 使用velodyneFileReader函数从P...
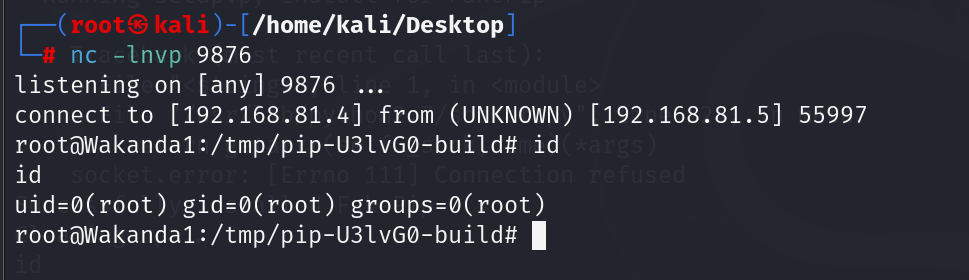
vulnhub-wakanda 1靶机
vulnhub:wakanda: 1 ~ VulnHub 导入靶机,放在kali同网段,扫描 靶机在192.168.81.5,扫描端口 四个端口,详细扫描一下 似乎没什么值得注意的,先看网站 就这一个页面,点按钮也没反应,扫…...

Bilibili视频如何保存到本地
Bilibili(哔哩哔哩)作为中国领先的视频分享平台之一,汇聚了大量的优质内容,从搞笑动画、综艺节目到专业教程,应有尽有。许多用户时常会遇到这样的需求:希望将视频保存到本地,方便离线观看或者保存珍藏。由于版权保护等…...

C++之多线程
前言 多线程和多进程是并发编程的两个核心概念,它们在现代计算中都非常重要,尤其是在需要处理大量数据、提高程序性能和响应能力的场景中。 多线程的重要性: 资源利用率:多线程可以在单个进程中同时执行多个任务,这可以更有效地利用CPU资源,特别是在多核处理器上。 性…...

《C++音频降噪秘籍:让声音纯净如初》
在音频处理领域,降噪是一项至关重要的任务。无论是录制音乐、语音通话还是音频后期制作,都需要有效地去除背景噪声,以获得清晰、纯净的音频效果。在 C中实现高效的音频降噪处理,可以为音频应用带来更高的质量和更好的用户体验。本…...

C(十)for循环 --- 黑神话情景
前言: "踏过三界宝刹,阅过四洲繁华。笑过五蕴痴缠,舍过六根牵挂。怕什么欲念不休,怕什么浪迹天涯。步履不停,便是得救之法。" 国际惯例,开篇先喝碗鸡汤。 今天,杰哥写的 for 循环相…...

记录一次docker报错无法访问文件夹,权限错误问题
记录一次docker报错无法访问文件夹,权限错误问题 1. 背景 使用docker安装photoview,为其分配了一个cache目录,用户其缓存数据。在运行过程中,扫描文件后显示如下错误 could not make album image cache directory: mkdir /app/c…...
 useEffect)
react crash course 2024(8) useEffect
引入 import { useEffect } from react; useEffect – React 中文文档useEffect 是一个 React Hook,它允许你 将组件与外部系统同步。 有些组件需要与网络、某些浏览器 API 或第三方库保持连接,当它们显示在页面上时。这些系统不受 React 控制࿰…...

GEE开发之Modis_NDWI数据分析和获取
GEE开发之Modis_NDWI数据分析和获取 0 数据介绍NDWI介绍MOD09GA介绍 1 NDWI天数据下载2 NDWI月数据下载3 NDWI年数据下载 前言:本文主要介绍Modis下的NDWI数据集的获取。归一化差异水指数 (NDWI) 对植被冠层液态水含量的变化很敏感。它来自近红外波段和第二个红外波…...

netty之NettyClient半包粘包处理、编码解码处理、收发数据方式
前言 Netty开发中,客户端与服务端需要保持同样的;半包粘包处理,编码解码处理、收发数据方式,这样才能保证数据通信正常。在前面NettyServer的章节中我们也同样处理了;半包粘包、编码解码等,为此在本章节我们…...

Linux:文件描述符介绍
文章目录速览 1、虚拟地址空间(1)What(什么是虚拟地址空间)(2)Why(为什么需要虚拟地址空间) 2、文件描述符(1)What(什么是文件描述符)(2)文件描述符表 1、虚拟地址空间 (1)What(什么是虚拟地址…...

stm32f103调试,程序与定时器同步设置
在调试定时器相关代码时,注意到定时器的中断位总是置1,怀疑代码有问题,经过增大定时器的中断时间,发现定时器与代码调试并不同步,这一点对于调试涉及定时器的代码是非常不利的,这里给出keil调试stm32使定时…...
《Python编程:从入门到实践》数据可视化
一、项目 数据可视化学习 二、库依赖 matplotlib,pygal, 三、生成数据 1.绘制简单的折线图 import matplotlib.pyplot as pltsquares [1, 4, 9, 16, 25] plt.plot(squares) plt.show() 模块pyplot包含很多用于生成图表的函数。 (1&am…...

github/git密钥配置与使用
零、前言 因为要在ubuntu上做点东西,发现git clone 的时候必须输账户密码,后来发现密码是token,但是token一大串太烦了,忙了一天发现可以通过配置 公钥 来 替代 http 的 部署方式。 一、生成 ssh 密钥对 我们先测试下能不能 连接…...
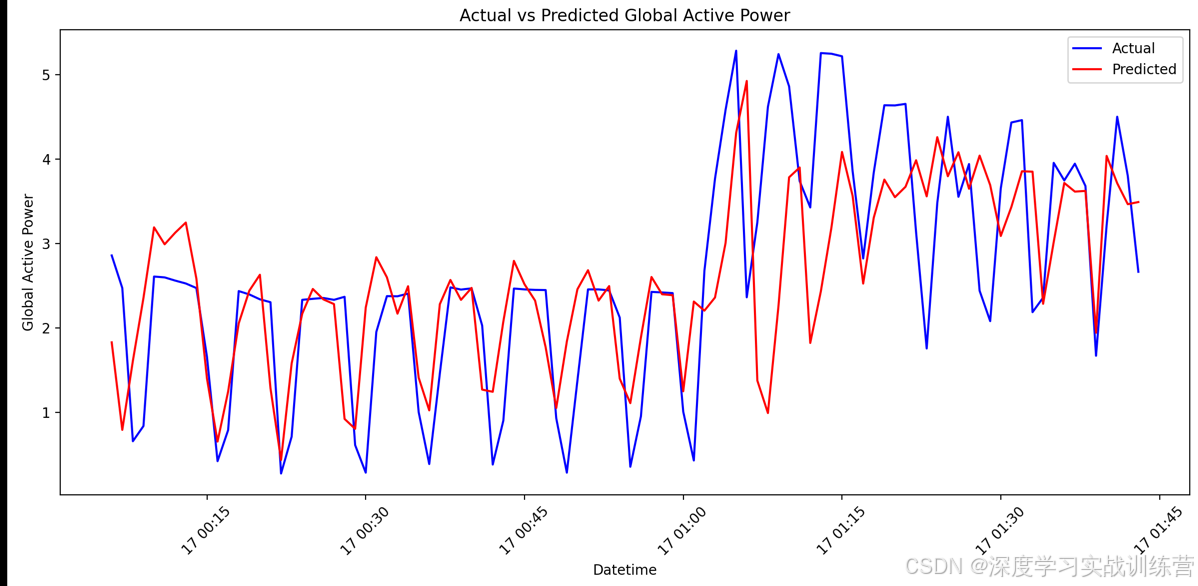
BiLSTM模型实现电力数据预测
基础模型见:A020-LSTM模型实现电力数据预测 1. 引言 时间序列预测在电力系统管理、负荷预测和能源优化等领域具有重要意义。传统的单向长短期记忆网络(LSTM)因其在处理时间序列数据中的优势,广泛应用于此类任务。然而࿰…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...

codeforces C. Cool Partition
目录 题目简述: 思路: 总代码: https://codeforces.com/contest/2117/problem/C 题目简述: 给定一个整数数组,现要求你对数组进行分割,但需满足条件:前一个子数组中的值必须在后一个子数组中…...

软件测试—学习Day11
今天学习下兼容性 1.App兼容性常见问题 以下是关于 App 兼容性问题的常见举例,涵盖界面展示、操作逻辑、性能差异三大维度,涉及不同系统、设备及网络环境的兼容性场景: 一、界面展示问题 界面展示兼容性问题主要由操作系统版本差异、屏幕…...