正则表达式 | Python、Julia 和 Shell 语法详解
正则表达式在网页爬虫、脚本编写等众多任务中都有重要的应用。为了系统梳理其语法,以及 Python、Julia 和 Shell 中与正则表达式相关的工具,本篇将进行详细介绍。
相关学习资源:编程胶囊。
基础语法
通用语法
在大多数支持正则表达式的语言中,以下规则是一致的,适用于 Shell、Python 和 Julia。
-
匹配位置
^匹配字符串开头,$匹配字符串结尾,例如:^ab匹配abc,abcd,abb,ab^ab不匹配aab,aac,babab$匹配aab,ab,ababab$不匹配aabb,b,abb^ab$精确匹配ab
-
匹配字符
匹配符 说明 .匹配除回车外的任意一个字符 ( )字符串分组 [ ]定义字符类,匹配括号中的任意一个字符 \转义字符 *匹配前一个字符若干次(包括 0 次) ?字符出现 0 次或 1 次 +字符至少出现一次 {n,}字符至少出现 n 次 {n, m}字符至少出现 n 次,最多 m 次 {m}字符正好出现 m 次 -
示例
^a.c$匹配abc,a.c,aec^a.c$不匹配abbc,ac,.c^a\.c精确匹配a.c^a*c匹配c,ac,aac等^a?c$仅匹配c,ac^a+c$匹配ac,aac等
-
中括号表示匹配一个字符,其内部规则:
-表示区间,注意右区间不能小于左区间,否则匹配无效。例如:[2-8]匹配数字2到8[a-c]匹配字母a,b,c
^表示取反,例如[^1-3]匹配除了1,2,3以外的字符\用于匹配特殊字符,例如[\-]匹配-,[\[]匹配[
贪婪匹配
-
?的多重含义- 放在字符后,表示匹配 0 次或 1 次
- 放在分组前,
?:表示不捕获分组内容 - 用于断言时,
?=,?!,?<=,?<!表示正向/反向断言 - 放在可变长匹配后,表示非贪婪匹配,即尽可能少地匹配字符
-
示例
reg1 = r"a{2,}" reg2 = r"a{2,}?" collect(eachmatch(reg1, "aaaaa")) # 贪婪匹配,匹配到一个元素 "aaaaa" collect(eachmatch(reg2, "aaaaa")) # 非贪婪匹配,匹配到两个 "aa", "aa" -
贪婪匹配 vs 即停匹配
比起“非贪婪匹配”,更合适的说法是“匹配即停”。
对于可变长规则,贪婪匹配会尽可能多地匹配字符,而即停匹配在成功匹配到最短的子串后立即停止。reg1 = r"a.*b" reg2 = r"a.*?b" collect(eachmatch(reg1, "aaaaabaab")) # 贪婪匹配,匹配到 "aaaaabaab" collect(eachmatch(reg2, "aaaaabaab")) # 即停匹配,匹配到 "aaaaab" 和 "aab"
特殊匹配
-
以下规则在 Python 和 Julia 中一致,并与 Linux 的 Perl 兼容,而 shell 中的
grep使用 POSIX 特殊字符,需要单独处理。 -
常见特殊字符
\w匹配单词字符,包括[a-zA-Z0-9_]和汉字等,不包括符号\d匹配数字,等价于[0-9]\s匹配空白字符,包括空格、制表符、换行符等\b匹配单词边界- 例如:
\babc匹配以abc开头的单词abc,abcd,.abcdef - 不匹配
aabc,_abc,ababc \b\w{4}\b匹配长度为 4 的单词
- 例如:
\W,\D,\S分别匹配\w,\d,\s的反例
分组
正则表达式提供了一种将表达式分组的机制,当使用分组时,除了获得整个匹配,还能够在匹配中选择每一个分组。
-
分组用括号抓取,比如
(\d{4})-(\d{2})-(\d{2})匹配并提取数据2022-02-28中的日期,一共三个分组
## Python 正则 re.findall(r'(\d{4})-(\d{2})-(\d{2})', '2022-02-282321-02-21') # [('2022', '02', '28'), ('2321', '02', '21')]## Julia 正则 collect(eachmatch(r"(\d{4})-(\d{2})-(\d{2})", "2022-02-282321-02-21")) # RegexMatch("2022-02-28", 1="2022", 2="02", 3="28") # RegexMatch("2321-02-21", 1="2321", 2="02", 3="21") -
分组内,使用“或”运算
|,比如(\.jpg|\.png)匹配.jpg或.png(\.(jpg|png))嵌套匹配,两个分组,组1为.jpg或.png,组2为jpg或png
### 匹配到两段信息,元组长度分别为 1 collect(eachmatch(r"\d(\.jpg|\.png)", "1.jpg, 2.png")) # RegexMatch("1.jpg", 1=".jpg") # RegexMatch("2.png", 1=".png") ### 匹配到两端信息,元组长度分别为 2 collect(eachmatch(r"\d(\.(jpg|png))", "1.jpg, 2.png")) # RegexMatch("1.jpg", 1=".jpg", 2="jpg") # RegexMatch("2.png", 1=".png", 2="png") -
有时候,我们并不需要捕获某个分组的内容,但是又想使用分组的特性(比如或运算)。这个时候就可以使用非捕获组
(?:表达式),从而不捕获数据,还能使用分组的功能,比如匹配前缀和后缀,但只捕获前缀的分组## Julia collect(eachmatch(r"(\w)\.(?:jpg|png)", "1.jpg, 2.png")) # RegexMatch("1.jpg", 1="1") # RegexMatch("2.png", 1="2")# Python re.findall(r"(\w)\.(?:jpg|png)", "1.jpg, 2.png") # ['1', '2'] -
分组的回溯引用,
\N表示表达式的第 N 个分组,比如collect(eachmatch(r"(\w)(\w)\2\1", "abbaddadda")) # RegexMatch("abba", 1="a", 2="b") # RegexMatch("adda", 1="a", 2="d")re.findall(r"(\w)(\w)\2\1", "abbaddadda") # [('a', 'b'), ('a', 'd')]
断言
正则表达式中的断言(Assertions)与 ^(匹配字符串开头)、$(匹配字符串结尾)或 \b(匹配单词边界)一样,都是用于匹配字符串中的某个位置,而不是匹配具体的字符。由于它们只匹配位置而不消耗字符,因此也称为“零宽断言”。
1. 断言类型
断言可以分为四种类型:
- 正向先行断言:
(?=pattern) - 负向先行断言:
(?!pattern) - 正向后行断言:
(?<=pattern) - 负向后行断言:
(?<!pattern)
2. 正向先行断言
正向先行断言 (?=pattern) 匹配的是这样一个位置:该位置之后的字符序列可以匹配给定的 pattern。例如:
在字符串 a regular expression 中,我们想匹配单词 regular 中的 re,但不匹配 expression 中的 re,可以使用以下正则表达式:
re(?=gular)
这个表达式限定了匹配的 re 之后必须跟着 gular,但并不消耗 gular 这些字符。如果修改为 re(?=gular)g,则会匹配 reg,因为在 re 和 g 之间的位置满足了 gular 的条件。
3. 负向先行断言
负向先行断言 (?!pattern) 匹配的是这样一个位置:该位置之后的字符序列不能匹配给定的 pattern。例如:
在字符串 regex represents regular expression 中,如果我们想匹配 regex 和 regular 中的 re,但排除 represents 和 expression 中的 re,可以使用:
re(?!g)
这个表达式表示 re 之后不能有字母 g。
4. 正向后行断言
正向后行断言 (?<=pattern) 匹配的是这样一个位置:该位置之前的字符序列可以匹配给定的 pattern。例如:
在字符串 regex represents regular expression 中,假设我们想匹配单词中的 re,但不匹配出现在单词开头的 re,可以使用:
(?<=\w)re
这里的断言要求 re 之前必须有一个单词字符(\w),所以不会匹配 regex 中的 re。
5. 负向后行断言
负向后行断言 (?<!pattern) 匹配的是这样一个位置:该位置之前的字符序列不能匹配给定的 pattern。例如:
在字符串 regex represents regular expression 中,如果我们想排除匹配 represents 和 expression 中的 re,但匹配 regex 中的 re,可以使用:
(?<!\w)re
这表示 re 之前不能有任何单词字符。
6. 断言总结
- 正向断言用
=,表示断言的条件必须成立; - 负向断言用
!,表示断言的条件不能成立; - 先行断言从当前位置开始向后匹配,限定该位置之后的字符;
- 后行断言从当前位置开始向前匹配,限定该位置之前的字符。
7. 断言示例
为了更好地理解断言,我们可以以字符串 regex represents regular expression 为例,尝试几种断言组合:
- 正向先行断言:
re(?=g)限定re之后必须有g,因此匹配regex和regular中的re,排除了represents和expression中的re。 - 负向先行断言:
re(?!s|p)限定re之后不能是s或p,匹配了regex和regular的re,排除了represents和expression。 - 正向后行断言:
(?<=r)e限定e之前必须是r,匹配所有单词中的e。 - 负向后行断言:
(?<!p)re限定re之前不能是p,排除了represents和expression中的re。
8. 经典断言应用
我们可以用断言来匹配一个同时包含大小写字母的非空字符串。例如:
(?=.*?[a-z])(?=.*?[A-Z]).+
解释:
(?=.*?[a-z])匹配包含至少一个小写字母的位置;(?=.*?[A-Z])匹配包含至少一个大写字母的位置;- 最后的
.+表示字符串本身至少有一个字符。
通过这种方式,两个断言结合,确保字符串同时包含大写和小写字母。类似地,我们可以使用 (?=.*?[a-z]{m,}) 来匹配至少包含 m 个小写字母的位置。
Shell
-
grep -E和egrep命令
在 Shell 中,可以使用grep -E或egrep命令进行正则表达式匹配。需要注意的是,默认的grep是grep -e,而-e只支持基础正则表达式(BRE),这会导致一些高级的正则语法无法使用。例如,grep a?c在默认模式下不会匹配ac和c。 -
POSIX 特殊字符
POSIX 标准定义了一组特殊字符类,这些字符类可用于匹配特定的字符类型。在使用grep时,可以通过[:class:]来引用这些字符类。特殊字符 说明 [:alnum:]匹配任意字母字符和数字( 0-9a-zA-Z)[:alpha:]匹配任意字母字符(大写或小写) [:digit:]匹配数字 0-9[:graph:]匹配除空格外的所有可打印字符 [:lower:]匹配小写字母 a-z[:upper:]匹配大写字母 A-Z[:cntrl:]匹配控制字符 [:print:]匹配所有可打印字符,包括空格 [:punct:]匹配标点符号 [:blank:]匹配空格和制表符 [:xdigit:]匹配十六进制数字 [:space:]匹配所有空白字符(如换行符、空格、制表符) -
外层字符匹配
在使用 POSIX 字符类时,通常需要将它们放在方括号内。例如:grep '[[:alpha:]]' filename # 匹配文件中的字母字符
Julia
在 Julia 中,正则表达式通过 r 前缀表示,使用非常灵活,并且支持与 Python 类似的丰富功能。推荐参考 Julia 官方文档。
-
基本使用
在 Julia 中,使用r"..."来定义正则表达式。例如:re = r"^\s*(?:#|\$)" typeof(re) # 输出: Regex isconcretetype(Regex) # 输出: true该正则表达式匹配以若干空格开头,后跟
#或$的字符串。其具体语法为:^:匹配行首;\s*:匹配若干空白字符;(?:...):非捕获组,用于组合多个条件;#|\$:匹配#或$。
-
occursin和matchoccursin用于判断字符串中是否存在匹配项:
occursin(r"^\s*(?:#|\$)", "# a comment") # 输出: truematch用于获取具体的匹配结果:
m = match(r"(\d{2})([a-z]{2})", "aa12bb34cc") m.match # 输出: "12bb" m.captures # 输出: ["12", "bb"] m.offset # 匹配的起始位置 m.offsets # 每个捕获组的起始位置 -
分组命名和回溯引用
Julia 支持命名分组,并且允许通过名称或索引来引用分组:m = match(r"(?<tag>\d+):(\d+)", "12:45") m[:tag] # 使用标签调用分组,输出: "12" m[2] # 使用索引调用分组,输出: "45"同时,支持回溯调用分组内容:
m = match(r"(?P<hi>\d+):\g<hi>", "12:12") # 用 \g<hi> 调用分组 m = match(r"(?<hi>\d+):\g1", "12:12") # 使用分组序号 -
replace函数
replace函数在 Julia 中支持正则表达式,并允许使用捕获组中的内容:replace("--12:34--", r"(?<hour>\d+):(?<minute>\d+)" => s"\g<minute>") # 输出: "--34--" -
eachmatch函数
eachmatch返回一个RegexMatch对象的迭代器,用于多项匹配:collect(eachmatch(r"\d\d", "1234")) # 输出: 两个匹配项 ["12", "34"] -
换行匹配
.无法匹配换行符,要匹配换行符可以使用[\s\S]或[\w\W]:match(r"123[\s\S]321", "123\n22\n321") # 输出: RegexMatch("123\n22\n321")
Python
Python 自 1.5 版本起增加了 re 模块,它提供 Perl 风格的正则表达式模式。
-
match从字符起始位置开始匹配re.match(r"\d\d", "2a-2b\n20") # 返回 None,未匹配到 re.match(r"\w\w", "2a-2b\n20") # 返回匹配对象 # <re.Match object; span=(0, 2), match='2a'> -
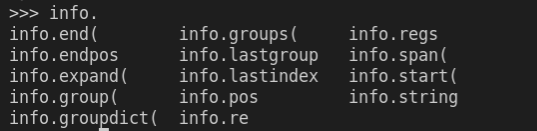
search扫描整个字符串,并返回第一个成功匹配的位置re.search(r"\d\d", "2a-2b\n20") # <re.Match object; span=(6, 8), match='20'> info = re.search(r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})", "ab2022-03-01cd") print(info.start()) # 2 | 匹配到的起始位置 print(info.end()) # 12 | 匹配到的终点位置 info.span() # (2, 12) | 起始 和 终点 print(info.groups()) # ('2022', '03', '01') | 分组内容 print(info.group(0)) # 2022-03-01 | 位置 0 代表匹配的字符串 info.group() # 等同于 info.group(0) info.group(1) # 2022 | 位置 1 代表分组第一个元素 info.regs # ((2, 12), (2, 6), (7, 9), (10, 12)) | 分组内容的索引 info.re # 返回使用的正则匹配规则 info.string # 返回被匹配的字符串 info.groupdict() # {'year': '2022', 'month': '03', 'day': '01'} | 字典形式返回匹配内容匹配对象的常用属性和方法
-
sub检索和替换# 提取日期,并将格式的 - 改为 / txt = "ab2022-03-01cd" reg = r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})" repl = r"\1/\2/\3" re.sub(reg, repl, txt) # 'ab2022/03/01cd' -
compile编译正则表达式,搭配其他函数使用reg = re.compile(r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})") # 编译正则表达式 reg.search("ab2022-03-01cd") # 返回查找对象 -
findall查找所有匹配的字符串re.findall("\w{2}", "2022-03-01") # 返回字符串构成的列表 # ['20', '22', '03', '01'] re.findall("(\w{2})-(\w{2})", "20-22-03-01") # 返回字符串元组构成的列表 # [('20', '22'), ('03', '01')] -
finditer返回迭代器形式的匹配信息list(re.finditer("\w{2}", "2022-03-01")) # [<re.Match object; span=(0, 2), match='20'>, # <re.Match object; span=(2, 4), match='22'>, # <re.Match object; span=(5, 7), match='03'>, # <re.Match object; span=(8, 10), match='01'>] -
split按匹配规则进行字符串拆分re.split("\d", "1bb3cc1dd") # ['', 'bb', 'cc', 'dd'] -
在使用以上函数时,支持修饰符,且多个修饰符用
|指定,比如re.findall(r"ab.*cd", "ab\ndd\nCD") # [] | 换行匹配不到 re.findall(r"ab.*cd", "ab\ndd\nCD", re.I | re.S) # ['ab\ndd\nCD'] | `.` 可以匹配换行,字母不分大小写 -
常见修饰符
| 修饰符 | 描述 |
|---|---|
re.I | 使匹配对大小写不敏感 |
re.L | 做本地化识别匹配 |
re.M | 多行匹配,影响 ^ 和 $ |
re.S | 使 . 匹配包括换行在内的所有字符 |
re.U | 根据 Unicode 字符集解析字符。这个标志影响 \w, \W, \b, \B |
re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
Python
Python 自 1.5 版本起引入了 re 模块,提供了类似 Perl 风格的正则表达式功能。以下是常用的正则操作:
-
match从字符串起始位置开始匹配:re.match(r"\d\d", "2a-2b\n20") # 返回 None,未匹配到 re.match(r"\w\w", "2a-2b\n20") # 返回匹配对象 # <re.Match object; span=(0, 2), match='2a'> -
search扫描整个字符串并返回第一个匹配项:re.search(r"\d\d", "2a-2b\n20") # <re.Match object; span=(6, 8), match='20'> info = re.search(r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})", "ab2022-03-01cd") print(info.groups()) # ('2022', '03', '01') info.groupdict() # {'year': '2022', 'month': '03', 'day': '01'} -
sub查找并替换匹配的字符串:txt = "ab2022-03-01cd" reg = r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})" repl = r"\1/\2/\3" re.sub(reg, repl, txt) # 输出: 'ab2022/03/01cd' -
compile编译正则表达式,以提高效率:reg = re.compile(r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})") reg.search("ab2022-03-01cd") # 返回匹配对象 -
findall查找所有匹配的项并返回列表:re.findall(r"\w{2}", "2022-03-01") # 返回 ['20', '22', '03', '01'] -
finditer返回迭代器形式的匹配对象:matches = list(re.finditer(r"\w{2}", "2022-03-01")) for match in matches:print(match.group()) # 输出匹配的子串 -
split按照正则表达式拆分字符串:re.split(r"\d", "1bb3cc1dd") # 输出: ['', 'bb', 'cc', 'dd'] -
修饰符 支持多种正则修饰符,多个修饰符可用
|组合使用:re.findall(r"ab.*cd", "ab\ndd\nCD", re.I | re.S) # ['ab\ndd\nCD'] | `.` 可匹配换行且不区分大小写 -
常见修饰符表:
修饰符 说明 re.I匹配时忽略大小写 re.M多行模式,影响 ^和$re.S使 .匹配所有字符,包括换行符re.X允许更灵活的格式,使正则表达式更易于理解
Perl
Perl 是正则表达式的先驱语言之一,其强大的正则功能被很多现代编程语言借鉴。我们可以通过 Shell 中的 grep -P 来使用 Perl 风格的正则表达式。以下是 Perl 和 Python 正则表达式的一些比较和补充:
-
Perl 中的正则语法
Perl 使用类似于 Python 的正则表达式语法,但增加了一些独有的功能。比如,Perl 支持更复杂的嵌套分组和条件匹配。 -
捕获和命名分组
Perl 支持命名捕获组和回溯引用,类似于 Python:# Perl 写法 if ($str =~ /(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})/) {print "$+{year}/$+{month}/$+{day}\n"; # 使用命名分组 } -
正则表达式修饰符
Perl 提供了强大的修饰符功能,包括m(多行模式)、s(单行模式)、x(扩展模式)等,类似 Python 的修饰符机制:$str =~ /pattern/i; # 大小写不敏感匹配 $str =~ /pattern/s; # 允许 `.` 匹配换行符 -
grep -P
在 shell 中,grep -P允许你使用 Perl 的正则表达式语法来进行文本处理:grep -P '\d{4}-\d{2}-\d{2}' file.txt # 使用 Perl 风格的正则表达式匹配日期 -
扩展和嵌套正则
Perl 支持复杂的条件表达式和递归模式匹配,例如在括号匹配或 XML 解析等应用场景中非常强大。
相关文章:
正则表达式 | Python、Julia 和 Shell 语法详解
正则表达式在网页爬虫、脚本编写等众多任务中都有重要的应用。为了系统梳理其语法,以及 Python、Julia 和 Shell 中与正则表达式相关的工具,本篇将进行详细介绍。 相关学习资源:编程胶囊。 基础语法 通用语法 在大多数支持正则表达式的语…...
JavaScript全面指南(一)
🌈个人主页:前端青山 🔥系列专栏:JavaScript篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来JavaScript篇专栏内容:JavaScript全面指南(一) 1、介绍一下JS的内置类型有哪些? 基本数据类型…...

docker-compose与docker
“docker-compose” 是一个用于定义和运行多容器 Docker 应用程序的工具。它使用一个名为 docker-compose.yml 的配置文件来描述应用程序的服务、网络和卷,然后通过简单的命令就可以管理整个应用。 以下是一些常用的 docker-compose 命令及其用法: 启动…...

DDPM浅析
在机器学习和人工智能领域,生成模型一直是一个备受关注的研究方向。近年来,一种新型的生成模型——扩散概率模型(Diffusion Probabilistic Models,简称DDPM)引起了广泛的关注。本文将探讨DDPM的原理、优势以及应用。 …...

力扣刷题-算法基础
hello各位小伙伴们,为了进行算法的学习,小编特意新开一个专题来讲解一些算法题 1.移除元素. - 力扣(LeetCode) 本题大概意思是给定一个数组和一个数val删除与val相同的元素,不要改变剩余元素的顺序,最后返回剩余元素的个数。 我们在这里使用双指针,这里的双指针并不是…...

理解 Python 中的 Hooks 和装饰器
Python 中的 hooks 和装饰器,虽然它们看起来都有些魔法加成,但实际上各有妙用。下面看看他们到底是做什么的吧。 什么是 Hooks? Hooks 是指在某些操作或事件发生时,可以将自定义的代码插入和执行的一种机制。它们常用于扩展和修…...

Android 原生程序使用gdb, addr2line, readelf调试
Platform: RK3368 OS: Android 6.0 Kernel: 3.10.0 文章目录 一 gdb1. 原生程序添加调试符号2. 主机上adb push 编译好的原生程序到设备3. 设备上使用gdbserver运行原生程序4. 主机上设置adb端口转发5. 主机上运行gdb调试 二 addr2line三 readelf 一 gdb GDB(GNU…...
 的作用)
PHP 函数 func_num_args() 的作用
func_num_args() 是 PHP 中的一个内置函数,用于获取传递给当前用户定义函数的参数个数。这个函数特别有用于处理可变数量的参数(也称为可变参数列表)。 语法 int func_num_args ( void ) 返回值 func_num_args() 返回一个整数,…...

深入解析单片机原理及其物联网应用:附C#示例代码
深入解析单片机原理及其物联网应用:附C#示例代码 随着物联网技术的快速发展,单片机作为嵌入式系统的核心,已经广泛应用于各类智能设备中。本文将从单片机的原理出发,结合C#编程的物联网示例,带你深入了解如何利用单片…...

HTTP 和 WebSocket
目录 HTTP是什么HTTP局限性(HTTP1.1)请求和响应HTTP的主要特点:HTTP版本: HTTP与TCP关系数据封装传输过程1. **协议层次模型**:2. **封装过程**:1. **应用层(HTTP)**:2. …...

科技云报到:大模型时代下,向量数据库的野望
科技云报到原创。 自ChatGPT爆火,国内头部平台型公司一拥而上,先后发布AGI或垂类LLM,但鲜有大模型基础设施在数据层面的进化,比如向量数据库。 在此之前,向量数据库经历了几年的沉寂期,现在似乎终于乘着Ch…...
贪吃蛇游戏(代码篇)
我们并不是为了满足别人的期待而活着。 前言 这是我自己做的第五个小项目---贪吃蛇游戏(代码篇)。后期我会继续制作其他小项目并开源至博客上。 上一小项目是贪吃蛇游戏(必备知识篇),没看过的同学可以去看看…...

数控走心机系统可以定制吗
当然,走心机系统是可以定制的。随着数控技术的不断发展,走心机的数控系统越来越灵活,可以根据用户的具体需求进行定制和优化。下面,我将从几个方面来详细解答这个问题: 一、系统定制的必要性 1. 满足不同加工需求…...

PHP实现OID(Object identifier)的编码和解码
转载于:https://bkssl.com/document/php_oid_encode_decode.html <?phpclass ASN1ObjectIdentifier {/*** OID字符串编码为二进制数据* param string $oid 字符串形式的OID* return string*/public static function encode($oid){$parts explode(., $oid);$pa…...

架构设计笔记-12-信息系统架构设计理论与实践
目录 知识要点 案例分析 1.Java企业级应用系统 2.c/s架构,b/s架构 知识要点 软件架构风格是描述某一特定应用领域中系统组织方式的惯用模式。架构风格定义了一类架构所共有的特征,主要包括架构定义、架构词汇表和架构约束。 数据挖掘是从数据库的大…...

【Power Compiler手册】15.多角多模式设计中的功耗优化
多角多模式设计中的功耗优化 可以使用多个运行条件和多种模式进行综合的设计被称为多角多模式设计。Design Compiler Graphical工具扩展了拓扑技术,以分析和优化这些设计。 有关多角多模式技术支持的综合工具的更多信息,请参见以下主题: • 优化多角多模式设计 • 报告命…...

关于HalconDeeplearn中的语义分割的实现
1.读取数据和数据集 read_dl_model (C:/Users/user/Desktop/大蒜测试/包裹/model_训练-240926-191345_opt.hdl, DLModelHandle) read_dict(C:/Users/user/Desktop/大蒜测试/包裹/model_训练-240926-162708_opt_dl_preprocess_params.hdict,[], [], DLDataset) 2.读取识别图片 I…...

【STL】AVLTree模拟实现
AVLTree模拟实现 1 前言2 AVL树的插入2.1 平衡因子不继续向上更新的情况2.2 平衡因子变为2或者-2,发生旋转2.2.1 左单旋2.2.2 右单旋2.2.3 左右双旋2.2.4 右左双旋 3 代码 1 前言 二叉搜索树的不足:如果出现极端情况,效率会变得很低。 AVL&am…...

无极低码课程【tomcat部署windows环境厂家乱码处理】
windows 下tomcat安装 下载地址一:https://tomcat.apache.org/download-90.cgi 下载地址二:https://archive.apache.org/dist/tomcat/ 解压tomcat,进入bin目录运行startup.bat...

注册安全分析报告:惠农网
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...