深入理解Transformer的笔记记录(精简版本)NNLM → Word2Vec
文章的整体介绍顺序为:
NNLM → Word2Vec → Seq2Seq → Seq2Seq with Attention → Transformer → Elmo → GPT → BERT
自然语言处理相关任务中要将自然语言交给机器学习中的算法来处理,通常需要将语言数学化,因为计算机机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的数学性质的东西,基本上可以说向量是人对机器输入的主要方式了。词向量是对词语的向量表示,这些向量能捕获词语的语义信息,如相似意义的单词具有类似的向量。
假定我们有一系列样本(x,y),其中的 x 是词语,y 是它们的词性,我们要构建f(x) to y的映射:
首先,这个数学模型 f(比如神经网络、SVM)只接受数值型输入;
而 NLP 里的词语是人类语言的抽象总结,是符号形式的(比如中文、英文、拉丁文等等);
如此一来,便需要把NLP里的词语转换成数值形式,或者嵌入到一个数学空间里;
进一步,可以把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量
在各种词向量中,有一个简单的词向量是one-hot encoder。所谓one-hot编码,本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语,不是所有的编码都是01编码,且one-hot编码无法反应词与词之间的语义相似度。

如单词“king”的词嵌入(在维基百科上训练的GloVe向量):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
1、NNLM
神经网络语言模型(Neural Network Language Model,简称NNLM)的核心是一个多层感知机(Multi-Layer Perceptron,简称MLP),它将词向量序列映射到一个固定长度的向量表示,然后将这个向量输入到一个softmax层中,计算出下一个词的概率分布。

第一步就是Look up Embedding,首先构建词映射矩阵,即一个映射单词表所有单词的矩阵,也称词嵌入矩阵,在这个映射矩阵(词嵌入矩阵)中查询输入的单词(即Look up embeddings)
构建映射矩阵(词嵌入矩阵): 先是获取大量文本数据,然后建立一个可以沿文本滑动的窗(例如一个窗里包含三个单词),利用这样的滑动窗就能为训练模型生成大量样本数据,当这个窗口沿着文本滑动时,就能生成一套用于模型训练的数据集。(类似一个统计问题,根据前两个单词预测下一个单词出现的概率)
第二步则是计算出预测值
第三步则输出结果

2 、Word2Vec详解
Word2Vec模型的核心思想是通过词语的上下文信息来学习词语的向量表示。具体来说,Word2Vec模型通过训练一个神经网络模型,使得给定一个词语的上下文时,能够预测该词语本身(CBOW模型),或者给定一个词语时,能够预测其上下文(Skip-gram模型)。Word2Vec的训练模型本质上是只具有一个隐含层的神经元网络。它的输入是采用One-Hot编码的词汇表向量,它的输出也是One-Hot编码的词汇表向量。使用所有的样本,训练这个神经元网络,等到收敛之后,从输入层到隐含层的那些权重,便是每一个词的采用Distributed Representation的词向量。

Word2Vec包括两种模型:主要包括CBOW和Skip-gram模型。 CBOW模型是根据上下文去预测目标词来训练得到词向量,而Skip-gram模型则是根据目标词去预测上下文来训练得到词向量。CBOW适合于数据集较小的情况,而Skip-gram在大型语料中表现更好。 如下图所示:

(1)输入层:输入的是单词的one-hot representation(考虑一个词表V,里面的每一个词 i 都有一个编号i∈{1,...,|V|},那么词的one-hot表示就是一个维度为|V|的向量,其中第i个元素值非零,其余元素全为0);
词向量是用来将语言中的词进行数学化的一种方式,词向量就是把一个词表示成一个向量。 我们都知道词在送到神经网络训练之前需要将其编码成数值变量,常见的编码方式有两种:One-Hot Representation 和 Distributed Representation。
One-Hot Representation 容易受维数灾难的困扰,词汇鸿沟,不能很好地刻画词与词之间的相似性;强稀疏性; 向量中只有一个非零分量,非常集中
Distributed Representation 向量中有大量非零分量,相对分散,把词的信息分布到各个分量中去了。
(2)隐藏层:输入层到隐藏层之间有一个权重矩阵W,隐藏层得到的值是由输入X乘上权重矩阵得到的(one-hot编码向量乘上一个矩阵,就相当于选择了权重矩阵的某一行,如图:假设输入的向量X是[0,1,0,0,0,0],W的转置乘上X就相当于从矩阵中选择第2行[0.1, 0.2, 0.3]作为隐藏层的值);隐藏层h的值为多个词乘上权重矩阵之后加和求平均值。
用一个9×3的矩阵来表示,初始化为
从输入层到隐藏层,进行矩阵乘法
隐藏层到输出层也有一个权重矩阵W',因此,输出层向量y的每一个值,其实就是隐藏层的向量点乘权重向量W'的每一列,比如输出层的第二个数,就是向量[0.1, 0.2, 0.3]和列向量点乘之后的结果
从隐藏层到输出层,我们可以用一个3×9的矩阵来表示,初始化为

从隐藏层到输出层,直接继续进行矩阵的乘法

(3)输出层:最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词。 而我们的训练样本是希望其对应的概率要尽量的高,也就是对应的概率要为1,其它的概率为0,这样模型的输出和真实的样本存在了偏差,那们我们就可以直接利用这个误差来进行反向传递,调整我们模型的参数,从而达到了学习调优的目的。
Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和,权重矩阵W'还是共享的。
Word2vec训练流程:不断缩小error
相关文章:
深入理解Transformer的笔记记录(精简版本)NNLM → Word2Vec
文章的整体介绍顺序为: NNLM → Word2Vec → Seq2Seq → Seq2Seq with Attention → Transformer → Elmo → GPT → BERT 自然语言处理相关任务中要将自然语言交给机器学习中的算法来处理,通常需要将语言数学化,因为计算机机器只认数学符号…...

优选算法第一讲:双指针模块
优选算法第一讲:双指针模块 1.移动零2.复写零3.快乐数4.盛最多水的容器5.有效三角形的个数6.查找总价格为目标值的两个商品7.三数之和8.四数之和 1.移动零 链接: 移动零 下面是一个画图,其中,绿色部分标出的是重点: 代码实现&am…...

智能优化算法-水循环优化算法(WCA)(附源码)
目录 1.内容介绍 2.部分代码 3.实验结果 4.内容获取 1.内容介绍 水循环优化算法 (Water Cycle Algorithm, WCA) 是一种基于自然界水循环过程的元启发式优化算法,由Shah-Hosseini于2012年提出。WCA通过模拟水滴在河流、湖泊和海洋中的流动过程,以及蒸发…...

基于SpringBoot的个性化健康建议平台
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理基于智能推荐的卫生健康系统的相关信息成为…...

Mapsui绘制WKT的示例
步骤 创建.NET Framework4.8的WPF应用在NuGet中安装Mapsui.Wpf 4.1.7添加命名空间和组件 <Window x:Class"TestMapsui.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winf…...

Modbus TCP 西门子PLC指令以太口地址配置以及 Poll Slave调试软件地址配置
1前言 本篇文章讲了 Modbus TCP通讯中的一些以太网端口配置和遇到的一些问题, 都是肝货自己测试的QAQ。 2西门子 SERVER 指令 该指令是让外界设备主动连接此PLC被动连接, 所以这里应该填 外界设备的IP地址。 这边 我因为是电脑的Modbus Poll 主机来…...

MySQL表的基本查询上
1,创建表 前面基础的文章已经讲了很多啦,直接上操作: 非常简单!下一个! 2,插入数据 1,全列插入 前面也说很多了,直接上操作: 以上插入和全列插入类似,全列…...

MySQL中什么情况下类型转换会导致索引失效
文章目录 1. 问题引入2. 准备工作3. 案例分析3.1 正常情况3.2 发生了隐式类型转换的情况 4. MySQL隐式类型转换的规则4.1 案例引入4.2 MySQL 中隐式类型转换的规则4.3 验证 MySQL 隐式类型转换的规则 5. 总结 如果对 MySQL 索引不了解,可以看一下我的另一篇博文&…...

数据治理的意义
数据治理是一套管理数据资产的流程、策略、规则和控制措施,旨在确保数据的质量、安全性、可用性和合规性。数据治理的目标通常包括但不限于以下几点: 1. **提高数据质量**:确保数据的准确性、一致性、完整性和可靠性。 2. **确保数据安全**…...

快手游戏服务端C++开发一面-面经总结
1、tcp的重传机制有哪几种?具体描述一下 最基本的超时重传 超过时间就会重传 三个重复ACK 快速重传 减少等待超时、 接收方可以发送选择性确认 不用重传整段 乱序到达 可以通知哪些丢失 重复数据重传 2、override和final? override可写可不写 写出来就…...

git的学习使用(认识工作区,暂存区,版本区。添加文件的方法)
学习目标: 学习使用git,并且熟悉git的使用 学习内容: 必备环境:xshell,Ubuntu云服务器 如下: 搭建 git 环境认识工作区、暂存区、版本区git基本操作之添加文件(1):gi…...
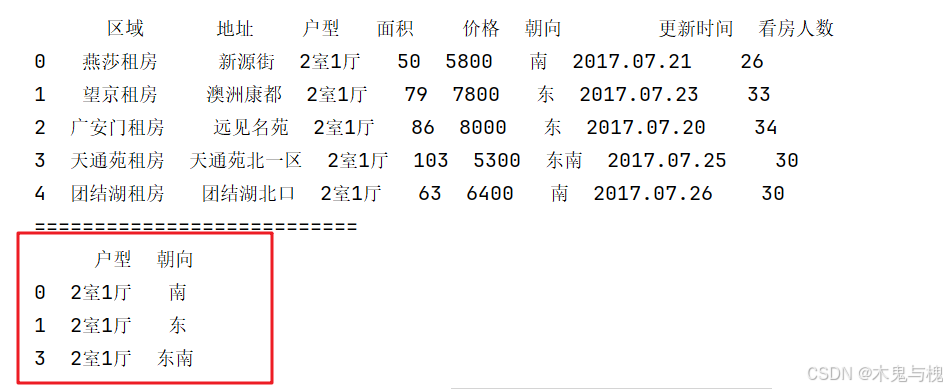
Series数据去重
目录 准备数据 Series数据去重 DataFrame数据和Series数据去重对比 在pandas中,Series.drop_duplicates(keep, inplace)方法用于删除Series对象中的重复值。 keep: 决定保留哪些重复值。可以取以下三个值之一: first(默认值&…...

Python语言核心12个必知语法细节
1. 变量和数据类型 Python是动态类型的,变量不需要声明类型。 python复制代码 a 10 # 整数 b 3.14 # 浮点数 c "Hello" # 字符串 d [1, 2, 3] # 列表 2. 条件语句 使用if, elif, else进行条件判断。 python复制代码 x 10 if x > 5: print(&q…...

解决ImageIO无法读取部分JPEG格式图片问题
解决ImageIO无法读取部分JPEG格式图片问题 问题描述 我最近对在线聊天功能进行了一些内存优化,结果在回归测试时,突然发现有张图片总是发送失败。测试同事把问题转到我这儿来看,我仔细检查了一下,发现是上传文件的接口报错&#…...

使用three.js 实现蜡烛效果
使用three.js 实现蜡烛效果 import * as THREE from "three" import { OrbitControls } from "three/examples/jsm/controls/OrbitControls.js"var scene new THREE.Scene(); var camera new THREE.PerspectiveCamera(60, window.innerWidth / window.in…...

手动在Linux服务器上部署并运行SpringBoot项目(新手向)
背景 当我们在本地开发完应用并且测试通过后,接着就要部署在服务器上启动。 步骤 1.先用maven将SpringBoot应用当成jar包 2.生成jar文件并复制此文件 3.xshell远程连接linux服务器,在xftp将文件粘贴到linux服务器,这里我放在/usr/local…...

自媒体短视频如何制作?
从0到1打造爆款短视频!300条视频创作经验分享,助你玩转自媒体! 想用短视频玩转自媒体却不知道从何下手?别担心!从21年开始接触短视频的我,断断续续创作了300多条视频,踩过不少坑,也收获了一些心得,核心秘诀就是:账号内容垂直化 + 明确受众群体! 我将从主题确定、脚本…...

2024年河南省职业技能竞赛(网络建设与运维赛项)
模块二:网络建设与调试 说明: 1.所网络设备在创建之后都可以直接通过 SecureCRT 软件 telnet 远程连接操作。 2.要求在全员化竞赛平台中保留竞赛生成的所有虚拟主机。 3.题目中所有所有的密码均为 Pass-1234,若未按照要求设置,涉 …...

git--git reset
HEAD 单独一个HEAD eg:git diff HEAD 表示当前结点。 HEAD~ HEAD~只处理当前分支。 注意:master分支的上一个结点是tmp分支的所在的结点fc11b74, 79f109e才是master的第二个父节点。 HEAD~ 当前结点的父节点。 HEAD~1 当前结点的父节点。 HEAD~n 当前结点索…...

Spring Boot的实用内置功能详解
Spring Boot作为一款备受欢迎的Java框架,以其简洁、高效和易用的特点,赢得了广大开发者的青睐。其内置的多种功能更是为开发者提供了极大的便利,本文将详细介绍Spring Boot中记录请求数据、请求/响应包装器、特殊的过滤器Filter以及Controlle…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...