yolov11 部署 TensorRT,预处理和后处理用 C++ cuda 加速,速度快到飞起
之前搞过不少部署,也玩过tensorRT部署模型(但都是模型推理用gpu,后处理还是用cpu进行),有网友问能出一篇tensorRT用gpu对模型后处理进行加速的。由于之前用的都是非cuda支持的边缘芯片,没有写过cuda代码,这个使得我犹豫不决。零零总总恶补了一点cuda编程,于是就有了这篇博客【yolov11 部署 TensorRT,预处理和后处理用 C++ cuda 加速,速度快到飞起】。既然用cuda实现,就不按照部署其他芯片(比如rk3588)那套导出onnx的流程修改导出onnx代码,要尽可能多的操作都在cuda上运行,这样导出onnx的方式就比较简单(yolov11官方导出onnx的方式)。
rtx4090显卡、模型yolov11n(输入分辨率640x640,80个类别)、量化成FP16模型,最快1000fps
本示例中,包含完整的代码、模型、测试图片、测试结果。
后处理部分用cuda 核函数实现,并不是全部后处理都用cuda实现【cuda实现后处理代码】;纯cpu实现后处理部分代码分支【cpu实现后处理代码】
使用的TensorRT版本:TensorRT-8.6.1.6
cuda:11.4
显卡:RTX4090
cuda 核函数主要做的操作
由于按照yolov11官方导出的onnx,后处理需要做的操作只有nms了。mns流程:选出大于阈值的框,在对这些大于阈值的框进行排序,在进行nms操作。这几部中最耗时的操作(对类别得分选出最大对应的类别,判断是否大于阈值)是选出所有大于阈值的框,经过这一步后实际参加nms的框没有几个(比如图像中有30个目标,每个目标出来了15个框,也才450个框),因此主要对这一步操作“选出所有大于阈值的框”用cuda实现。当然后续还可以继续优化,把nms的过程用cuda核函数进行实现。
核函数的实现如下:模型输出维度(1,(4+80),8400),主要思想流程用8400个线程,实现对80个类别选出最大值,并判断是否大于阈值。
__global__ void GetNmsBeforeBoxesKernel(float *SrcInput, int AnchorCount, int ClassNum, float ObjectThresh, int NmsBeforeMaxNum, DetectRect* OutputRects, int *OutputCount)
{/***功能说明:用8400个线程,实现对80个类别选出最大值,并判断是否大于阈值,把大于阈值的框记录下来后面用于参加mnsSrcInput: 模型输出(1,84,8400)AnchorCount: 8400ClassNum: 80ObjectThresh: 目标阈值(大于该阈值的目标才输出)NmsBeforeMaxNum: 输入nms检测框的最大数量,前面申请的了一块儿显存来装要参加nms的框,防止越界OutputRects: 大于阈值的目标框OutputCount: 大于阈值的目标框个数***/int ThreadId = blockIdx.x * blockDim.x + threadIdx.x;if (ThreadId >= AnchorCount){return;}float* XywhConf = SrcInput + ThreadId;float CenterX = 0, CenterY = 0, CenterW = 0, CenterH = 0;float MaxScore = 0;int MaxIndex = 0;DetectRect TempRect;for (int j = 4; j < ClassNum + 4; j ++) {if (4 == j){MaxScore = XywhConf[j * AnchorCount];MaxIndex = j; } else {if (MaxScore < XywhConf[j * AnchorCount]){MaxScore = XywhConf[j * AnchorCount];MaxIndex = j; }} }if (MaxScore > ObjectThresh){int index = atomicAdd(OutputCount, 1);if (index > NmsBeforeMaxNum){return;}CenterX = XywhConf[0 * AnchorCount];CenterY = XywhConf[1 * AnchorCount];CenterW = XywhConf[2 * AnchorCount];CenterH = XywhConf[3 * AnchorCount ];TempRect.classId = MaxIndex - 4;TempRect.score = MaxScore;TempRect.xmin = CenterX - 0.5 * CenterW;TempRect.ymin = CenterY - 0.5 * CenterH;TempRect.xmax = CenterX + 0.5 * CenterW;TempRect.ymax = CenterY + 0.5 * CenterH;OutputRects[index] = TempRect;}
}导出onnx模型
按照yolov11官方导出的方式如下:
from ultralytics import YOLO
model = YOLO(model='yolov11n.pt') # load a pretrained model (recommended for training)
results = model(task='detect', source=r'./bus.jpg', save=True) # predict on an imagemodel.export(format="onnx", imgsz=640, simplify=True)编译
修改 CMakeLists.txt 对应的TensorRT位置

cd yolov11_tensorRT_postprocess_cuda
mkdir build
cd build
cmake ..
make
运行
# 运行时如果.trt模型存在则直接加载,若不存会自动先将onnx转换成 trt 模型,并存在给定的位置,然后运行推理。
cd build
./yolo_trt
测试效果
onnx 测试效果

tensorRT 测试效果

tensorRT 时耗(cuda实现部分后处理)
示例中用cpu对图像进行预处理(由于本台机器搭建的环境不匹配,不能用cuda对预处理进行加速)、用rtx4090显卡进行模型推理、用cuda对后处理进行加速。使用的模型yolov11n(输入分辨率640x640,80个类别)、量化成FP16模型。以下给出的时耗是:预处理+模型推理+后处理。
cpu做预处理+模型推理+gpu做后处理

tensorRT 时耗(纯cpu实现后处理)【cpu实现后处理代码分支】
cpu做预处理+模型推理+cpu做后处理
替换模型说明
修改相关的路径
std::string OnnxFile = "/root/autodl-tmp/yolov11_tensorRT_postprocess_cuda/models/yolov11n.onnx";std::string SaveTrtFilePath = "/root/autodl-tmp/yolov11_tensorRT_postprocess_cuda/models/yolov11n.trt";cv::Mat SrcImage = cv::imread("/root/autodl-tmp/yolov11_tensorRT_postprocess_cuda/images/test.jpg");int img_width = SrcImage.cols;int img_height = SrcImage.rows;std::cout << "img_width: " << img_width << " img_height: " << img_height << std::endl;CNN YOLO(OnnxFile, SaveTrtFilePath, 1, 3, 640, 640);auto t_start = std::chrono::high_resolution_clock::now();int Temp = 2000;int SleepTimes = 0;for (int i = 0; i < Temp; i++){YOLO.Inference(SrcImage);std::this_thread::sleep_for(std::chrono::milliseconds(SleepTimes));}auto t_end = std::chrono::high_resolution_clock::now();float total_inf = std::chrono::duration<float, std::milli>(t_end - t_start).count();std::cout << "Info: " << Temp << " times infer and gpu postprocess ave cost: " << total_inf / float(Temp) - SleepTimes << " ms." << std::endl;预处理用cuda加速
代码中已实现用CUDA_npp_LIBRARY进行预处理,如果有环境可以打开进一步加速(修改位置:CMakelist.txt 已进行了注释、用CPU或GPU预处理打开对应的宏 #define USE_GPU_PREPROCESS 1))
重新搭建了一个支持用gpu对预处理进行加速的环境:rtx4090显卡、模型yolov11n(输入分辨率640x640,80个类别)、量化成FP16模型。对比结果如下:这台机器相比上面贴图中时耗更短,可能是这台机器的cpu性能比较强。以下给出的时耗是:预处理+模型推理+后处理。
cpu做预处理+模型推理+cpu做后处理

cpu做预处理+模型推理+gpu做后处理

gpu做预处理+gpu做后处理

后续优化点
1、把nms过程也用cuda实现,参加nms的框不多,但也是一个优化点,持续更新中
相关文章:
yolov11 部署 TensorRT,预处理和后处理用 C++ cuda 加速,速度快到飞起
之前搞过不少部署,也玩过tensorRT部署模型(但都是模型推理用gpu,后处理还是用cpu进行),有网友问能出一篇tensorRT用gpu对模型后处理进行加速的。由于之前用的都是非cuda支持的边缘芯片,没有写过cuda代码&am…...

国际期货收费行情源CTP推送式/期货配资软件开发对接行情源的技术性说明
在现代金融市场中,期货交易因其高风险和高回报特性而备受关注。为了满足期货交易者的需求,开发高效、稳定和安全的期货交易软件变得尤为重要。本文将对国际期货收费行情源CTP推送式及期货配资软件的开发对接行情源的技术细节进行详细说明。 一、CTP&…...

上拉电阻和下拉电阻在电路中的作用(一)
上拉电阻和下拉电阻在电路中的作用(一) 1.什么是上下拉电阻2.上下拉电阻的作用:2.1.维持输入引脚处于稳定状态。2.2.配合三极管和MOS进行电平转换电路设计2.3.OC、OD电路(Open Collector集电极开路、Open Drain漏电极开路…...
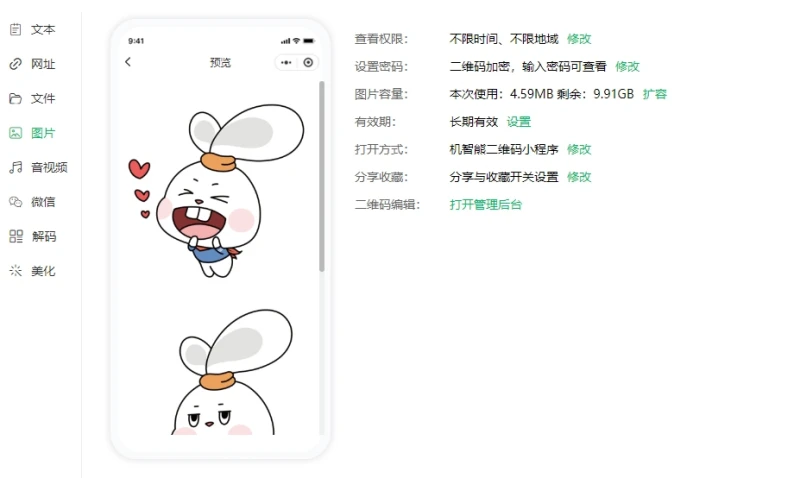
怎么轻松把图片存入二维码?图片生成二维码的简单3步技巧
进入数字化时代,图片是目前应用广泛的一种信息传递方式,可以通过看图来获取需要的内容,那么图片如何更快捷的在更多人之间传递呢?通过将图片生成二维码后分享,可以实现图片的快速传递,制作成本也比较低&…...

perl双引号内字符串的反斜线转义
perl双引号内字符串的反斜线转义 如题,下面表格列举了perl双引号内字符串的反斜线转义: 组合意义\n换行\r回车\t水平制表符\f换页符\b退格\a系统响铃\eEsc(ASCII编码的转义字符)\007八进制表示的ASCII值(此例中007表…...

【编程语言】Kotlin快速入门 - 伴生对象与懒加载
静态与顶层方法 静态方法(伴生对象) Java中有静态方法的概念,但是在Kotlin中这个静态方法被弱化了,还记得我们使用object创建一个单例类吗,创建的单例类我们当时可以使用像静态方法一样的调用方式取调用,…...

三、数据聚合和函数
在数据聚合和函数方面,数据库提供了许多功能强大的函数,可以帮助你处理和分析数据。以下是一些常用的函数及其功能的详细说明: COUNT函数: COUNT函数用于计算指定列中的行数。它可以用于统计表中满足特定条件的行数,也…...

Golang | Leetcode Golang题解之第500题键盘行
题目: 题解: func findWords(words []string) (ans []string) {const rowIdx "12210111011122000010020202" next:for _, word : range words {idx : rowIdx[unicode.ToLower(rune(word[0]))-a]for _, ch : range word[1:] {if rowIdx[unico…...
如何实现金蝶商品数据集成到电商系统的SKU
如何实现金蝶商品数据集成到电商SKU系统 金蝶商品数据集成到电商SKU的技术实现 在现代企业的数据管理中,系统间的数据对接与集成是提升业务效率和准确性的关键环节。本文将分享一个实际案例:如何通过轻易云数据集成平台,将金蝶云星辰V2中的商…...

100种算法【Python版】第4篇——回溯法
念念不忘,必有回响 1 回溯法原理2 示例说明2.1 生成子集2.1.1 回溯法思路2.1.2 Python3代码2.2 N皇后问题2.2.1 回溯法思路2.2.2 Python3代码3 回溯法应用3.1 组合3.1.1 回溯法思路3.1.2 Python3代码3.2 数独 Solver3.2.1 回溯法思路3.2.2 Python3代码3.3 多重背包问题3.3.1 P…...

R语言机器学习算法实战系列(九)决策树分类算法 (Decision Trees Classifier)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍教程下载数据加载R包导入数据数据预处理数据描述数据切割调节参数构建模型模型的决策树预测测试数据评估模型模型准确性混淆矩阵模型评估指标ROC CurvePRC Curve特征的重要性保存模…...
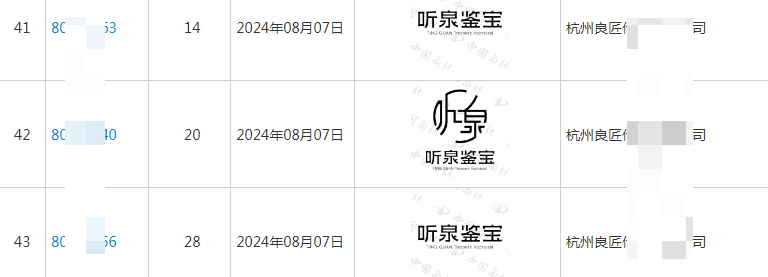
听泉鉴宝在三个月前已布局商标注册!
近日“听泉鉴宝”以幽默的风格和节目效果迅速涨粉至2500多万,连线出现“馆藏文物”和“盗墓现场”等内容,听泉鉴宝早在几个月前已布局商标注册。 据普推知产商标老杨在商标局网站检索发现,“听泉鉴宝”的主人丁某所持股的江苏灵匠申请了三十…...

vscode设置特定扩展名文件的打开编码格式
用vscode 编辑c语言或者Verilog代码, 由于其它开发工具的文件编码格式无法修改,默认只能是gb2312, 与我们国内奉行的统一 utf8 不一致. 所以只能是更改特殊文件的打开方式. 配置方式如下. 关键配置如下: {"git.openRepositoryInParentFolders": "never",…...
Linux——动态卷的管理
确保已经设置了对应的动态卷的驱动(provisioner 制备器)基于动态驱动创建对应的存储类创建PVC (PVC 将会自动根据大小、访问模式等创建PV)Pod的spec 中通过volumes 和 volumemounts 来完成pvc 的绑定和pvc对应pv的挂载删除pod 不…...

第三季度中国游戏市场收入创历史新高;京东物流与淘宝天猫达成合作;YouTube 上线“用相机拍摄”标签....|网易数智日报
第三季度中国游戏市场收入917.66亿,创历史新高 中国音数协游戏工委今日发布了最新的 2024 年第三季度中国游戏产业季度报告。 数据显示,2024 年第三季度中国游戏市场收入 917.66 亿元,环比增长 22.96%,同比增长 8.95%。 中国音…...

智慧城管综合管理系统源码,微服务架构,基于springboot、vue+element+uniapp技术开发,支持二次开发
智慧城管源码,智慧城管执法办案系统源码 智慧城管综合执法办案平台是智慧城市框架下,依托物联网、云计算、多网融合等现代化技术,运用数字基础资源、多维信息感知、协同工作处置、智能化辅助决策分析等手段,形成具备高度感知、互联…...

2024Flutter面试题
1.Dart是值传递还是引用传递? dart是值传递。 每次调用函数,传递过去的都是对象的内存地址,而不是这个对象的赋值。 2.简述Dart语音特性 在Dart中,一切都是对象,所有的对象都是继承自Object Dart是强类型语言&#…...

MySQL-23.多表查询-内连接
一.内连接 -- 多表查询 select * from tb_emp,tb_dept where tb_emp.dept_id tb_dept.id;-- 内连接 -- A.查询员工的姓名,及所属的部门名称(隐式内连接实现) select tb_emp.name as 员工姓名,tb_dept.name as 部门名称 from tb_emp,tb_dep…...

实用的 Python 小脚本
一、引言 在日常办公和电脑使用中,我们经常会遇到一些重复性的任务或需要快速获取特定信息的情况。Python 作为一种强大而灵活的编程语言,可以用来编写各种小脚本,以自动化这些任务并提高工作效率。本文将介绍一些 Python 常用的小脚本&…...
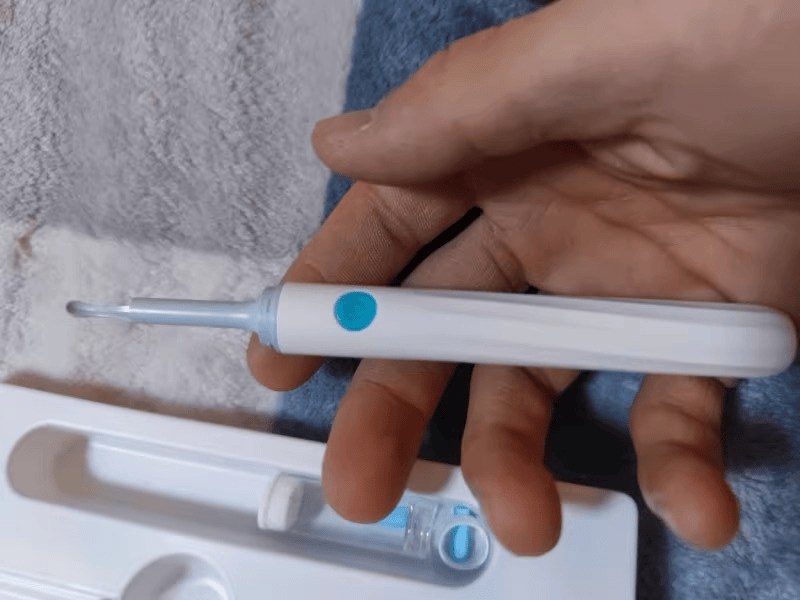
哪种掏耳朵方式好?正确的掏耳工具!
人体的耳屎会随着活动量加大而增加,如果长期不清理,耳屎堆积在耳道深处很有可能会堵塞鼓膜甚至影响听力。但如果需要清理耳屎的话,哪种掏耳朵方式好呢?可视挖耳勺可以帮助我们在全程可视的情况下,精准有效地完成采耳&a…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...