【人工智能】掌握深度学习中的时间序列预测:深入解析RNN与LSTM的工作原理与应用

深度学习中的循环神经网络(RNN)和长短时记忆网络(LSTM)在处理时间序列数据方面具有重要作用。它们能够通过记忆前序信息,捕捉序列数据中的长期依赖性,广泛应用于金融市场预测、自然语言处理、语音识别等领域。本文将深入探讨RNN和LSTM的架构及其对序列数据进行预测的原理与优势,使用数学公式描述其内部工作机制,并结合实际案例展示它们在预测任务中的应用。此外,文章还将讨论如何优化这些模型以提高预测精度。
目录
- 引言
- 循环神经网络(RNN)的基础
- RNN的架构与工作原理
- 序列数据与时间步的关系
- RNN的局限性:梯度消失问题
- LSTM的原理与改进
- LSTM的架构与记忆单元
- 输入门、遗忘门、输出门的作用
- LSTM如何解决长依赖问题
- 数学公式解析
- RNN的计算过程
- LSTM的内部状态更新
- 梯度计算与优化
- RNN与LSTM在时间序列预测中的应用
- 股票价格预测
- 语音与自然语言处理
- 传感器数据与时序分析
- LSTM的变体与改进
- 双向LSTM
- GRU与LSTM的对比
- 深层LSTM与多层RNN的应用
- 模型训练与优化
- 超参数调优
- 过拟合与正则化技术
- 提升训练速度与稳定性的技巧
- 实例讲解:构建LSTM进行序列预测
- 数据预处理与特征工程
- LSTM的实现与代码示例
- 性能分析与模型评估
- 未来展望:序列预测中的新兴技术
- Transformer对比LSTM的优势
- 自监督学习在序列数据中的潜力
- 结论
1. 引言
在深度学习中,序列数据是一类具有时间依赖关系的特殊数据,广泛存在于金融市场、语音识别、文本生成、物联网等领域。传统的神经网络模型在处理独立的、非时间相关的数据时表现良好,但在处理序列数据时难以捕捉数据的时间依赖性。为了解决这个问题,循环神经网络(RNN)应运而生,它可以通过内存机制保持上下文信息。然而,RNN存在着梯度消失的问题,导致它在处理长时间依赖时效果不佳。
为了弥补这一缺陷,长短时记忆网络(LSTM)被提出。LSTM是一种特殊的RNN结构,能够有效记住长期依赖信息并避免梯度消失问题。本文将从RNN和LSTM的基础架构入手,逐步深入讲解它们的工作原理,并展示它们在时间序列数据预测中的实际应用。
2. 循环神经网络(RNN)的基础
RNN的架构与工作原理
循环神经网络(Recurrent Neural Network, RNN)是深度学习中的一种重要模型,专门用于处理具有时间依赖关系的序列数据。与传统前馈神经网络不同,RNN具有循环连接的结构,这使得它能够处理变长的输入序列,并在处理当前时间步时结合前一时间步的信息。
RNN的基本架构如下:
h t = σ ( W h x x t + W h h h t − 1 + b h ) h_t = \sigma(W_{hx}x_t + W_{hh}h_{t-1} + b_h) ht=σ(Whxxt+Whhht−1+bh)
y t = σ ( W h y h t + b y ) y_t = \sigma(W_{hy}h_t + b_y) yt=σ(Whyht+by)
其中:
- ( h_t ) 是隐藏状态,存储了时间步 ( t ) 的上下文信息;
- ( x_t ) 是输入序列在时间步 ( t ) 时的输入;
- ( W_{hx} )、( W_{hh} ) 分别是输入与隐藏状态之间、隐藏状态之间的权重矩阵;
- ( b_h )、( b_y ) 是偏置项;
- ( \sigma ) 是激活函数(如tanh或ReLU);
- ( y_t ) 是输出。
RNN通过将前一个时间步的隐藏状态 ( h_{t-1} ) 和当前输入 ( x_t ) 结合在一起,生成新的隐藏状态 ( h_t ),从而捕捉序列数据中的动态变化。
序列数据与时间步的关系
RNN在每个时间步处理一个序列中的数据。对于时间序列数据,时间步对应于每个时间点的数据。例如,在预测股票价格时,每天的股价是一个时间步的数据输入。在语音识别任务中,RNN处理的每个时间步可能代表一个声音帧。
时间步之间的信息传递使得RNN能够捕捉序列中的模式。RNN适用于许多应用场景,包括语音识别、文本生成、机器翻译等。
RNN的局限性:梯度消失问题
尽管RNN可以有效地处理短期依赖,但它在处理长时间依赖时表现不佳。这主要是由于梯度消失问题。当RNN进行反向传播时,梯度需要通过时间逐步传递。然而,在深度序列中,由于权重矩阵的反复相乘,梯度可能会快速衰减至接近零,导致模型无法学习到长距离时间依赖。
梯度消失现象使得RNN难以捕捉序列中长时间跨度的信息,例如在预测未来股票走势时需要综合过去几个月的数据。
3. LSTM的原理与改进
LSTM的架构与记忆单元
为了解决RNN的梯度消失问题,Hochreiter和Schmidhuber在1997年提出了长短时记忆网络(LSTM)。LSTM通过引入特殊的记忆单元(Memory Cell),能够在较长的时间跨度内保存信息。
LSTM的结构比RNN更加复杂,它引入了三种门控机制:输入门、遗忘门和输出门,用于控制信息在记忆单元中的流动。
LSTM的核心公式如下:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC)
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t Ct=ft⋅Ct−1+it⋅C~t
h t = o t ⋅ tanh ( C t ) h_t = o_t \cdot \tanh(C_t) ht=ot⋅tanh(Ct)
其中:
- ( f_t ) 是遗忘门的输出,决定记忆单元中哪些信息需要丢弃;
- ( i_t ) 是输入门的输出,决定哪些新信息会被存储到记忆单元;
- ( o_t ) 是输出门的输出,决定记忆单元的内容如何用于生成输出;
- ( C_t ) 是记忆单元的状态;
- ( h_t ) 是隐藏状态。
输入门、遗忘门、输出门的作用
LSTM中的门控机制是其成功的关键:
- 遗忘门:通过遗忘门,LSTM可以选择性地“忘记”之前时间步中不再重要的信息。这使得LSTM可以动态调整它需要保留的历史信息。
- 输入门:输入门控制新信息如何进入记忆单元。通过输入门,LSTM能够有效学习新输入对预测任务的影响。
- 输出门:输出门控制从记忆单元流出的信息,即生成隐藏状态 ( h_t ) 的内容。
LSTM如何解决长依赖问题
LSTM通过遗忘门、输入门和输出门有效管理记忆单元中的信息流动,确保关键的长距离信息能够被保留并用于后续时间步的预测。这种设计使得LSTM可以解决RNN中的长时间依赖问题,避免梯度消失,能够在诸如文本生成和时间序列预测中表现出色。
4. 数学公式解析
RNN的计算过程
在RNN中,每个时间步的隐藏状态和输出可以通过以下公式计算:
h t = σ ( W h x x t + W h h h t − 1 + b h ) h_t = \sigma(W_{hx}x_t + W_{hh}h_{t-1} + b_h) ht=σ(Whxxt+Whhht−1+bh)
y t = σ ( W h y h t + b y ) y_t = \sigma(W_{hy}h_t + b_y) yt=σ(Whyht+by)
其中, h t h_t ht是第 t 个时间步的隐藏状态,代表当前时间步的记忆或上下文信息。输入 x t x_t xt代表在 t 时刻输入序列的数据 y t y_t yt是模型输出。
LSTM的内部状态更新
LSTM中的记忆单元 ( C_t ) 由遗忘门 ( f_t ) 和输入门 ( i_t ) 控制,它通过以下公式更新:
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t Ct=ft⋅Ct−1+it⋅C~t
其中,遗忘门 ( f_t ) 控制前一时间步的记忆 ( C_{t-1} ) 在当前时间步中保留的程度,而输入门 ( i_t ) 控制当前时间步输入信息 ( \tilde{C}_t ) 的流入。通过这种方式,LSTM可以选择性地保留长时间跨度的记忆,而不会遭遇RNN中常见的梯度消失问题。
LSTM的输出隐藏状态 ( h_t ) 则由输出门 ( o_t ) 控制,公式如下:
h t = o t ⋅ tanh ( C t ) h_t = o_t \cdot \tanh(C_t) ht=ot⋅tanh(Ct)
这里,输出门 ( o_t ) 决定记忆单元 ( C_t ) 中的信息有多少会传递给下一个时间步,同时 ( \tanh ) 函数用于对信息进行非线性处理。
梯度计算与优化
在深度学习中,模型训练通过反向传播算法(Backpropagation Through Time, BPTT)进行。在BPTT中,RNN和LSTM会展开时间步进行反向传播,计算梯度并更新模型的权重。然而,RNN由于其简单的递归结构,容易遭遇梯度消失或梯度爆炸问题,这使得它难以在长序列数据上有效训练。
LSTM通过其门控机制,在反向传播过程中能够更好地保留梯度,因此在处理长序列时更加稳定。优化LSTM的训练过程可以使用以下技术:
- 梯度裁剪:防止梯度爆炸问题,通过限制梯度的最大值来保持训练稳定。
- 学习率调整:使用动态学习率,如学习率衰减或自适应学习率优化器(如Adam),提高模型收敛速度。
- 正则化:通过Dropout等正则化技术防止模型过拟合。
5. RNN与LSTM在时间序列预测中的应用
股票价格预测
在金融领域,时间序列数据(如股票价格、交易量等)包含大量的历史信息。通过RNN或LSTM,模型能够学习过去市场行为的模式,并预测未来的走势。LSTM由于其强大的长依赖记忆能力,通常在此类任务中表现优异。
例如,假设我们有一个股票的过去100天的价格数据,我们可以使用LSTM预测接下来的价格走势。通过将历史数据按时间步输入LSTM,模型可以生成未来时间步的价格预测。
语音与自然语言处理
RNN和LSTM在语音识别、文本生成和机器翻译等自然语言处理任务中扮演重要角色。由于语言具有复杂的上下文依赖性,LSTM能够记住长句子中的关键信息,在翻译或生成文本时做出更加合理的预测。
在语音识别中,LSTM能够分析连续的语音信号,并生成对应的文本。语音信号中的帧序列包含明显的时间依赖关系,LSTM能够捕捉这些特征并生成准确的语音转文字结果。
传感器数据与时序分析
在物联网(IoT)和工业应用中,传感器数据通常以时间序列形式呈现。RNN和LSTM能够处理这些数据,预测未来的趋势或检测异常。例如,在能源管理中,LSTM可以分析温度、湿度、电量等传感器数据,并预测未来的电力需求或故障可能性,从而提高系统的运行效率。
6. LSTM的变体与改进
双向LSTM
标准LSTM只能捕捉从过去到未来的时间依赖性,而双向LSTM通过引入两个LSTM层,一个处理正向序列,另一个处理反向序列,从而同时捕捉到过去和未来的上下文信息。
双向LSTM广泛应用于自然语言处理任务,如文本分类、情感分析和机器翻译。由于双向结构能够结合前后文信息,模型的预测效果得到显著提升。
GRU与LSTM的对比
门控循环单元(Gated Recurrent Unit, GRU)是LSTM的一种简化变体。与LSTM相比,GRU具有更简单的结构,没有单独的记忆单元,只使用两个门(更新门和重置门)来控制信息流动。GRU的公式如下:
z t = σ ( W z ⋅ [ h t − 1 , x t ] ) z_t = \sigma(W_z \cdot [h_{t-1}, x_t]) zt=σ(Wz⋅[ht−1,xt])
r t = σ ( W r ⋅ [ h t − 1 , x t ] ) r_t = \sigma(W_r \cdot [h_{t-1}, x_t]) rt=σ(Wr⋅[ht−1,xt])
h ~ t = tanh ( W h ⋅ [ r t ⋅ h t − 1 , x t ] ) \tilde{h}_t = \tanh(W_h \cdot [r_t \cdot h_{t-1}, x_t]) h~t=tanh(Wh⋅[rt⋅ht−1,xt])
h t = ( 1 − z t ) ⋅ h t − 1 + z t ⋅ h ~ t h_t = (1 - z_t) \cdot h_{t-1} + z_t \cdot \tilde{h}_t ht=(1−zt)⋅ht−1+zt⋅h~t
GRU在某些任务中可以提供与LSTM相当的性能,但计算复杂度更低,因此更适合处理较大规模的时序数据集。
深层LSTM与多层RNN的应用
为了提高模型的表现,开发者通常会使用多层LSTM或深层RNN,即在输入到输出的路径中堆叠多个LSTM层或RNN层。这种架构可以提取序列数据中的多层次特征,提升模型对复杂时序模式的捕捉能力。
多层LSTM在长文本生成、语音识别等任务中表现出色,能够更加准确地建模复杂的时间依赖关系。
7. 模型训练与优化
超参数调优
LSTM的超参数对其性能有着显著影响。常见的超参数包括:
- 隐藏层维度:LSTM隐藏层的维度决定了模型的表达能力,通常较大的维度能够捕捉更多特征,但会增加计算复杂度。
- 时间步长:输入序列的时间步数应根据任务的需求进行调整。较长的时间步能够保留更多历史信息,但也增加了梯度消失的风险。
- 学习率:合理的学习率设置可以加速模型的收敛,同时避免陷入局部最优。
过拟合与正则化技术
为了防止模型在训练数据上过拟合,可以使用正则化技术,如:
- Dropout:在训练过程中随机丢弃部分神经元,避免模型过度依赖某些特征。
- L2正则化:通过惩罚权重的大小,防止模型过拟合。
提升训练速度与稳定性的技巧
为了提高LSTM模型的训练速度和稳定性,常用的技巧包括:
- 梯度裁剪:限制梯度的最大值,防止梯度爆炸问题。
- Batch Normalization:在每层LSTM后添加批量归一化,可以加速模型收敛并提高稳定性。
8. 实例讲解:构建LSTM进行序列预测
数据预处理与特征工程
在使用LSTM进行时间序列预测前,数据预处理是非常重要的步骤。数据预处理步骤通常包括归一化、填补缺失值和生成序列数据。例如,对于股票价格预测任务,我们可以将历史价格数据归一化,并按窗口滑动生成输入序列和目标值。
LSTM的实现与代码示例
下面是一个使用LSTM预测时间序列数据的简化代码示例,基于PyTorch框架:
import torch
import torch.nn as nn
import numpy as npclass LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x)out = self.fc(lstm_out[:, -1, :]) # 取最后一个时间步的输出returnout# 初始化模型
model = LSTMModel(input_size=1, hidden_size=64, output_size=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 假设有训练数据
train_data = np.sin(np.linspace(0, 100, 1000)) # 生成示例序列数据
train_data = torch.FloatTensor(train_data).view(-1, 10, 1) # 创建序列# 训练模型
for epoch in range(100):optimizer.zero_grad()output = model(train_data)loss = criterion(output, train_data[:, -1, :]) # 使用最后一步作为预测目标loss.backward()optimizer.step()if epoch % 10 == 0:print(f'Epoch {epoch}, Loss: {loss.item()}')
性能分析与模型评估
在训练完成后,可以通过均方误差(MSE)、平均绝对误差(MAE)等指标评估模型的预测性能。此外,模型的泛化能力可以通过交叉验证或使用未见过的数据进行测试来验证。
9. 未来展望:序列预测中的新兴技术
Transformer对比LSTM的优势
近年来,基于Transformer的架构在自然语言处理和时间序列预测中取得了显著的进展。相比LSTM,Transformer架构不依赖于递归结构,而是使用全局自注意力机制处理序列数据,能够更好地捕捉远距离的依赖关系。
Transformer虽然在长序列上表现优越,但其计算复杂度较高,因此在某些场景下LSTM仍具有一定优势。
自监督学习在序列数据中的潜力
自监督学习近年来成为机器学习中的热门方向。通过自监督学习,模型可以利用未标注数据进行预训练,极大地扩展了模型的训练数据量。应用于时间序列数据,自监督学习可以帮助模型学习更通用的特征,从而提高预测性能。
10. 结论
RNN和LSTM作为深度学习中的重要模型,已经在时间序列数据预测领域发挥了巨大作用。通过对LSTM的内部机制、应用场景以及优化方法的详细解析,我们可以更好地理解如何利用这些模型进行高效预测。尽管LSTM在序列数据上表现强大,但随着Transformer等新兴技术的发展,序列预测将迎来更多创新与突破。在未来,结合自监督学习和增强的深度网络结构,时间序列预测的精度和广泛性将进一步提升。
相关文章:
【人工智能】掌握深度学习中的时间序列预测:深入解析RNN与LSTM的工作原理与应用
深度学习中的循环神经网络(RNN)和长短时记忆网络(LSTM)在处理时间序列数据方面具有重要作用。它们能够通过记忆前序信息,捕捉序列数据中的长期依赖性,广泛应用于金融市场预测、自然语言处理、语音识别等领域…...

今日开放!24下软考机考「模拟练习平台」操作指南来啦!
2024年下半年软考机考模拟练习平台今日开放,考生可以下载模拟作答系统并登录后进行模拟练习,熟悉答题流程及操作方法。 一、模拟练习时间 2024年下半年软考机考模拟练习平台开放时间为2024年10月23日9:00至11月6日17:00,共15天。 考生可以在…...

合并.md文档
需求:将多个.md文档合并成一个.md文档。 方法一:通过 type 命令 参考内容:多个md文件合并 步骤: 把需要合并的 .md 文档放入到一个文件夹内。修改需要合并的 .md 文档名,可以在文档名前加上 1.2.3 来表明顺序&#x…...

10月18日笔记(基于系统服务的权限提升)
系统内核漏洞提权 当目标系统存在该漏洞且没有更新安全补丁时,利用已知的系统内核漏洞进行提权,测试人员往往可以获得系统级别的访问权限。 查找系统潜在漏洞 手动寻找可用漏洞 在目标主机上执行以下命令,查看已安装的系统补丁。 system…...

【STM32 Blue Pill编程实例】-控制步进电机(ULN2003+28BYJ-48)
控制步进电机(ULN2003+28BYJ-48) 文章目录 控制步进电机(ULN2003+28BYJ-48)1、步进电机介绍2、ULN2003步进电机驱动模块3、硬件准备及接线4、模块配置3.1 定时器配置3.2 ULN2003输入引脚配置4、代码实现在本文中,我们将介使用 STM32Cube IDE 使用 ULN2003 电机驱动器来控制28B…...

监督学习、无监督学习、半监督学习、强化学习、迁移学习、集成学习分别是什么对应什么应用场景
将对监督学习、无监督学习、半监督学习、强化学习、迁移学习和集成学习进行全面而详细的解释,包括定义、应用场景以及具体的算法/模型示例。 1. 监督学习 (Supervised Learning) 定义:监督学习是一种机器学习方法,其中模型通过已知的输入数…...

WSL2 Linux子系统调整存储位置
WSL2 默认不支持修改Linux 安装路径,官方提供的方式,只有通过导出、导入的方式实现Linux子系统的迁移。 修改注册表的方式官方不推荐,没有尝试过,仅提供操作方式(自行评估风险,建议备份好数据) 1. 打开 **注册表编辑器…...

Shiro授权
一、定义与作用 授权(Authorization),也称为访问控制,是确定是否允许用户/主体做某事的过程。在Shiro安全框架中,授权是核心组件之一,它负责控制用户对系统资源的访问权限,确保用户只能访问其被…...
算法题总结(十五)——贪心算法(下)
1005、K 次取反后最大化的数组和 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组: 选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。 重复这个过程恰好 k 次。可以多次选择同一个下标 i 。 以这种方式修改数组后,返回数组 可…...

《深度学习》【项目】自然语言处理——情感分析 <下>
目录 一、了解项目 1、任务 2、文件内容 二、续接上篇内容 1、打包数据,转化Tensor类型 2、定义模型,前向传播函数 3、定义训练、测试函数 4、最终文件格式 5、定义主函数 运行结果: 一、了解项目 1、任务 对微博评论信息的情感分…...

postgresql是国产数据库吗?
PostgreSQL不是国产数据库。但是PostgreSQL对国产数据库的发展有着重要影响,许多国产数据库产品是基于PostgreSQL进行二次开发的。 PostgreSQL的开源特性也是其受欢迎的重要原因之一。开源意味着任何人都可以查看、修改和使用PostgreSQL的源代码。这使得PostgreSQL…...
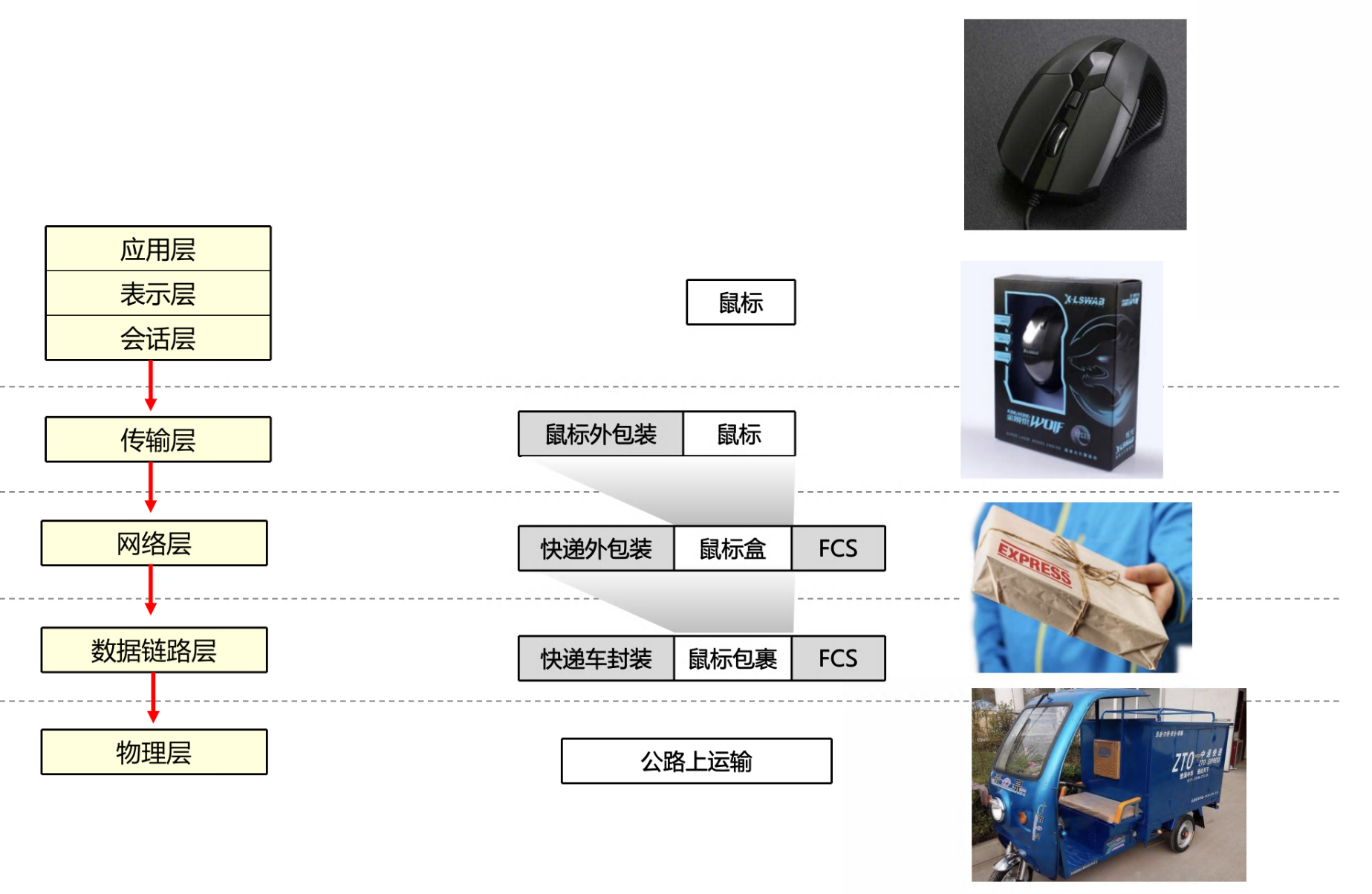
软考——计算机网络概论
文章目录 🕐计算机网络分类1️⃣通信子网和资源子网2️⃣网络拓扑结构3️⃣ 计算机网络分类3:LAN MAN WAN4️⃣其他分类方式 🕑OSI 和 TCP/IP 参考模型1️⃣OSI2️⃣TCP/IP🔴TCP/IP 参考模型对应协议 3️⃣OSI 和 TCP/IP 模型对应…...

01 设计模式-创造型模式-工厂模式
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一,它提供了一种创建对象的方式,使得创建对象的过程与使用对象的过程分离。 工厂模式提供了一种创建对象的方式,而无需指定要创建的具体类。 通过使用工厂模式…...

ComnandLineRunner接口, ApplcationRunner接口
ComnandLineRunner接口, ApplcationRunner接口 介绍: 这两个接口都有一个run方法,执行时间在容器对象创建好后,自动执行run ( )方法。 创建容器的同时会创建容器中的对象,同时会把容器中的对象的属性赋上值: 举例&…...

Swift用于将String拆分为数组的components与split的区别
根据特定分隔符拆分字符串 在 Swift 中,components(separatedBy:) 和 split(separator:) 都可以用于将字符串拆分为数组,但它们有一些关键区别。下面将从返回值类型、性能和功能等角度进行对比。 1. 返回值类型 components(separatedBy:):…...
)
docker之redis安装(项目部署准备)
创建网络 docker network create net-ry --subnet172.68.0.0/16 --gateway172.68.0.1 redis安装 #创建目录 mkdir -p /data/redis/{conf,data} #上传redis.conf文件到/data/redis/conf文件夹中 #对redis.conf文件修改 # bind 0.0.0.0 充许任何主机访问 # daemonize no #密码 # …...

使用Maven前的简单准备
目录 一、Maven的准备 1、安装jdk1.8或以上版本 2、下载Maven 3、安装Maven 二、Maven目录的分析 三、Maven的环境变量配置 1、设置MAVEN_HOME环境变量 2、设置Path环境变量 3、验证配置是否完成 一、Maven的准备 1、安装jdk1.8或以上版本 jdk的安装 2、下载Maven…...

Java | Leetcode Java题解之第494题目标和
题目: 题解: class Solution {public int findTargetSumWays(int[] nums, int target) {int sum 0;for (int num : nums) {sum num;}int diff sum - target;if (diff < 0 || diff % 2 ! 0) {return 0;}int neg diff / 2;int[] dp new int[neg …...

阅读笔记 Contemporary strategy analysis Chapter 13
来源:Robert M. Grant - Contemporary strategy analysis (2018) Chapter 13 Implementing Corporate Strategy: Managing the Multibusiness Firm Ⅰ Introduction and Objectives 多业务公司 multibusiness firm由多个独立的业务部门组成,如业务单元…...
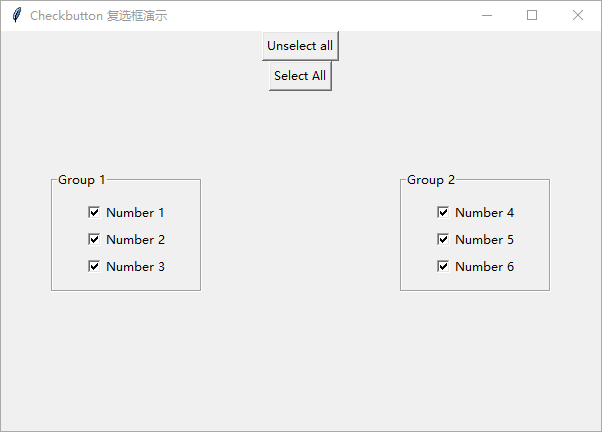
Python GUI 编程:tkinter 初学者入门指南——复选框
在本文中,将介绍 tkinter Checkbox 复选框小部件以及如何有效地使用它。 复选框是一个允许选中和取消选中的小部件。复选框可以保存一个值,通常,当希望让用户在两个值之间进行选择时,可以使用复选框。 要创建复选框,…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...