【Linux】解锁进程间通信奥秘,高效资源共享的实战技巧
管道、共享内存、消息队列、信号量
- 1. 进程间通信
- 1.1. 目的
- 1.2. 概念和本质
- 1.3. 分类
- 2. 管道
- 2.1 概念
- 2.2. 4种情况
- 2.3. 4种特性
- 2.4. 匿名管道
- 2.4.1. 原理
- 2.4.2. 概念
- 2.4.3. 创建 — pipe()
- 2.4.4. 应用场景 — 进程池
- 2.5. 命名管道
- 2.5.1. 概念和原理
- 2.5.2. 创建 — mkfifo()
- 2.5.3. 应用场景 — server&client通信
- 2.6. 命名管道与匿名管道的区别
- 3. System V 共享内存
- 3.1. 概念和原理
- 3.2. 共享内存函数
- 3.3. shmget — 创建共享内存
- 3.4. shmat — 进程挂接共享内存
- 3.5. shmdt — 断开共享内存连接
- 3.6. shmctl — 删除共享内存
- 3.7. 应用场景 — server&client通信
- 3.8. 命令行查看共享内存
- 3.9. 优缺点
- 4. 消息队列
- 4.1. 原理与概念
- 4.2. 消息队列函数
- 5. System V中IPC资源在内核中的设计
- 6. 信号量
- 6.1. 储备知识
- 6.2. 原理与概念
1. 进程间通信
1.1. 目的
-
数据传输:一个进程需要将它的数据发送给另一个进程。
-
资源共享:多个进程之间共享同样的资源。
-
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
-
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另 一个进程的所有陷入和异常,并能够及时知道它的状态改变。
总结:为了实现多个进程之间的协同工作,以便共同完成某项任务或处理复杂的数据交互。
1.2. 概念和本质
问:一个进程可以直接访问另一个进程的数据吗?
不能,因为进程具有独立性,包括数据结构和内存数据的独立性,因此进程间直接数据访问是不可能的,这就需要通过OS提供的IPC机制来实现进程之间的信息传递。
-
进程间通信(简称为IPC):是指在计算机系统中,多个进程之间传输数据或者信号的一种机制或方法。
-
进程间通信的本质或前提:让不同的进程,看到同一份由OS提供的资源,作为交换数据的空间。
这一前提是进程间通信能够得以实现的基础。
OS提供的空间有不同的"样式",就决定了有不同的通信方式。
1.3. 分类
-
管道:匿名管道pipe、 命名管道。
-
System V IPC :System V 消息队列 、 System V 共享内存 、 System V 信号量。
-
POSIX IPC :消息队列 、 共享内存 、 信号量 、 互斥量 、 条件变量 、 读写锁。
2. 管道
2.1 概念
- 管道的概念:它允许一个进程的标准输出(stdout)直接连接到另一个进程的标准输入(stdin),形成的一个数据流通道,即:它允许一个进程将数据写入管道的一端(写端),另一个进程从管道的另一端(读端)读取数据,如:ls -l | grep test,|为管道。
管道是进程间通信的一种方式,常用于unix系统和Linux系统中。

- 管道是一种特殊的文件类型,它并不在磁盘上占用实际的物理空间来存储数据,管道的数据存在于内核的缓冲区中,这些缓冲区是内存的一部分,即:它是内存级的文件,数据交换是在内存中直接进行的,无需将数据写入到磁盘再进行读取。
基于文件的,让不同进程看到同一份资源的通信方式,叫做管道。
💡Tips:管道只能进行单向通信!但可以通过创建两个管道来实现双向通信。
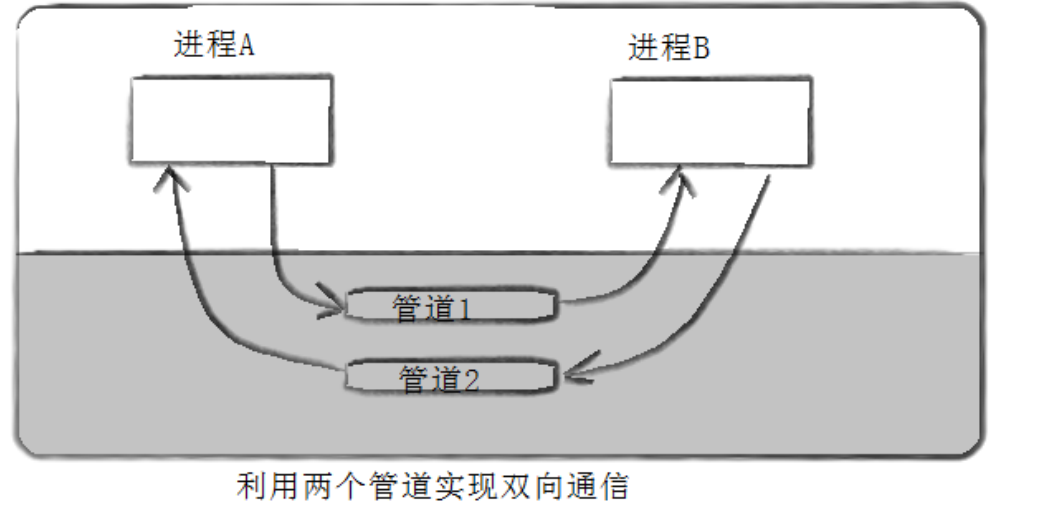
2.2. 4种情况
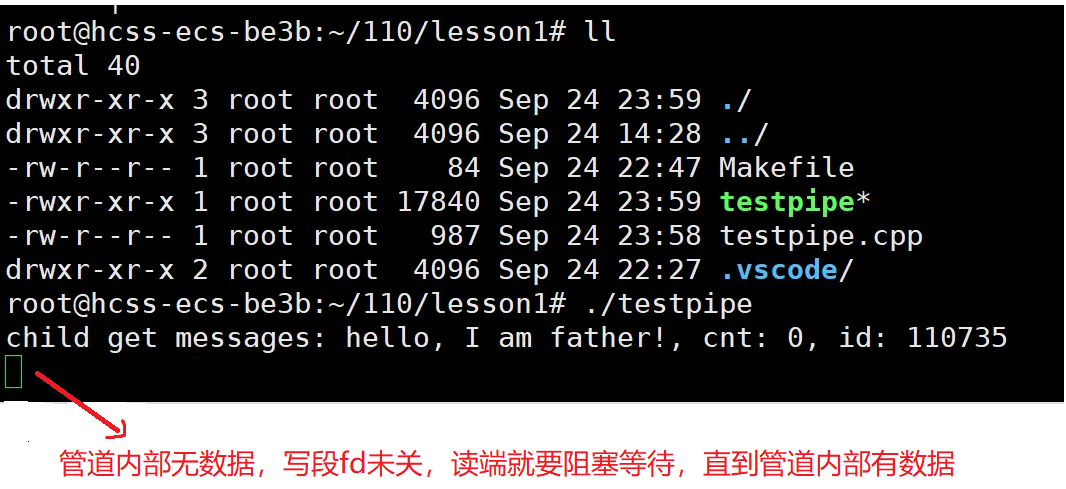
- 管道内部没有数据,且(父进程)没有关闭写端fd,读端(子进程)就要阻塞等待,直到管道内部有数据。
#include<iostream>
#include<cstdio>
#include<unistd.h>
#include<cstring>using namespace std;void writer(int wfd) //父进程写
{int cnt = 0;char str[128] = "hello, I am father!";while(1){char buffer[128]; snprintf(buffer, sizeof(buffer), "%s, cnt: %d, id: %d", str, cnt++, getpid()); write(wfd, buffer, strlen(buffer));sleep(100); //情况一:管道内部没有数据,且(父进程)没有关闭写端fd,读端(子进程)就要阻塞等待,直到管道内部有数据}
}void reader(int rfd) //子进程读
{while(1){char buffer1[128];read(rfd, buffer1, sizeof(buffer1));printf("child get messages: %s\n", buffer1);}
}int main()
{//1.父进程创建管道int pipefd[2];int n = pipe(pipefd);if(n == -1) return 1;//2.父进程创建子进程pid_t id = fork();if(id == 0){//子进程关闭写,进行读close(pipefd[1]);reader(pipefd[0]);}//父进程关闭读,进行写close(pipefd[0]);writer(pipefd[1]);return 0;
}
- 管道内部被写满,且(子进程)未关闭读端fd,(父进程)写端就要阻塞等待,直到管道内部有空间。
💡Tips:管道的大小,通常为64kb,不同的OS值不同。
#include<iostream>
#include<cstdio>
#include<unistd.h>
#include<cstring>using namespace std;void writer(int wfd) //父进程写
{int cnt = 0;// char str[128] = "hello, I am father!";while(1){char buffer[128]; // snprintf(buffer, sizeof(buffer), "%s, cnt: %d, id: %d", str, cnt++, getpid()); // write(wfd, buffer, strlen(buffer));char c = 'A';write(wfd, &c, sizeof(c)); printf("pipe number:%d\n", cnt++); //测试管道在内核内存中维护的缓冲区大小,64kb}
}void reader(int rfd) //子进程读
{while(1){char buffer1[128];read(rfd, buffer1, sizeof(buffer1));printf("child get messages: %s\n", buffer1);sleep(100); //情况2:管道内部被写满,且(子进程)未关闭读端fd,(父进程)写端就要阻塞等待,直到管道内部有空间}
}int main()
{//1.父进程创建管道int pipefd[2];int n = pipe(pipefd);if(n == -1) return 1;//2.父进程创建子进程pid_t id = fork();if(id == 0){//子进程关闭写,进行读close(pipefd[1]);reader(pipefd[0]);}//父进程关闭读,进行写close(pipefd[0]);writer(pipefd[1]);return 0;
}
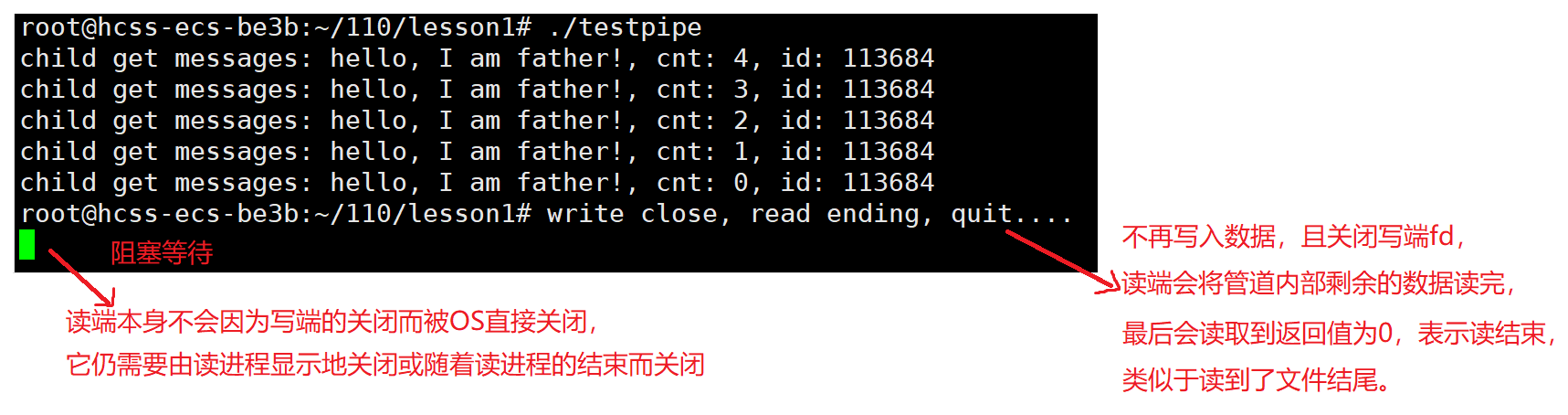
- 不再写入数据,且关闭写端fd,读端会将管道内部剩余的数据读完,最后会读取到返回值为0,表示读结束,类似于读到了文件结尾。
读端本身不会因为写端的关闭而被OS直接关闭,它仍需要由读进程显示地关闭或随着读进程的结束而关闭。
#include<iostream>
#include<cstdio>
#include<unistd.h>
#include<cstring>using namespace std;void writer(int wfd) //父进程写
{int cnt = 5;char str[128] = "hello, I am father!";while(cnt--){char buffer[128]; snprintf(buffer, sizeof(buffer), "%s, cnt: %d, id: %d", str, cnt, getpid()); write(wfd, buffer, strlen(buffer));sleep(1);// char c = 'A';// write(wfd, &c, sizeof(c)); // printf("pipe number:%d\n", cnt++); //测试管道在内核内存中维护的缓冲区大小,64kb}close(wfd); //情况3:不再写入数据,且关闭写端fd
}void reader(int rfd) //子进程读
{while(1){char buffer1[128];int n = read(rfd, buffer1, sizeof(buffer1));if(n > 0)printf("child get messages: %s\n", buffer1);else if(n == 0) //情况3:读端会将管道内部剩余的数据读完,最后会读取到返回值为0,表示读结束,类似于读到了文件结尾{printf("write close, read ending, quit....\n");break;}else {printf("read error\n");break;}//sleep(100); //情况2:管道内部被写满,且(子进程)未关闭读端fd,(父进程)写端就要阻塞等待,直到管道内部有空间}
}int main()
{//1.父进程创建管道int pipefd[2];int n = pipe(pipefd);if(n == -1) return 1;//2.父进程创建子进程pid_t id = fork();if(id == 0){//子进程关闭写,进行读close(pipefd[1]);reader(pipefd[0]);}//父进程关闭读,进行写close(pipefd[0]);writer(pipefd[1]);return 0;
}
- 不再读取,且关闭读端fd,写端仍在进行写入,OS会通过信号13:SIGPIPE直接终止进行写入的进程。

2.3. 4种特性
- 自带同步和互斥机制。
同步:确保两个或多个进程在运行过程中,按照预定的先后次序运行的一种机制,eg:一个任务的执行依赖于另一个任务产生的数据,管道中写操作必须先于读操作,以确保数据的正确传输和接收。
互斥:是保护共享资源,防止多个进程同时访问同一资源,导致数据不一致或错误的一种机制,即:公共资源在同一时刻只能被一个进程使用,不能被多个进程同时使用。eg:在管道中,互斥要求在同一时刻只有一个进程能够执行特定操作(r或w)。

- 面向字节流。
一个进程写入管道的数据是以字节序列(连续排列的字节,无固定大小)的形式存在的,而另一个进程从管道读取数据时,每次读取的字节数量是任意的,取决于此进程的读取操作。这种特性使得管道通信在很多情况下都表现得像是一种“流式服务"。
“流式服务”:意味着数据以连续不断的流的形式传输,接收方根据需要或能力来读取任意数量的数据。
- 管道的生命周期随进程。
管道的生命周期,与使用它的进程生命周期成正相关。当所有打开管道的文件描述符都关闭,且没有进程再引用管道时,管道就会被内核回收,其占用的资源也会被释放。
使用它的进程:包括创建它的进程,以及其他通过某种方式(如: fork)获得该管道引用的进程。
- 管道只能单向通信,是半双工通信的一种特殊情况。
半双工通信:允许数据在两个方向上传输,但在同一时刻只能在一个方向上进行。即:当一方正在发送数据,另一方不能同时发送数据,只能接收数据。如:对讲机。
全双工通信:允许数据在两个方向上同时传输,即:通信双方可以同时发送和接收数据。如:电话。
单工通信:数据只能单方向传输,即:一方固定为发送端,另一方固定为接收端。如:广告屏幕。
2.4. 匿名管道
2.4.1. 原理
一、补充知识:
- 如果一个进程同时连续两次以相同或不同的方式打开同一个文件,且第一个文件未被关闭,OS会创建两个文件描述符和文件结构体对象,但这两个文件描述符实际上指向的同一个磁盘文件和文件内核缓冲区。
即:无论你打开多次,只要文件名相同,文件系统不变,这些打开操作都指向同一个磁盘文件和文件内核缓冲区。
- 父进程创建子进程时,子进程会继承与进程相关的多种数据结构,如:task_struct、mm_struct、页表、文件描述符表。子进程并不会直接继承文件结构体对象,而是通过继承父进程的文件描述符来共享已经打开的文件结构体对象。
文件描述符表体现了有多少个文件和此进程相关联,是进程访问文件的接口,子进程继承父进程的文件描述符表,以便能够访问父进程打开的文件。
二、原理
为什么父进程一开始就要按照r、w方式,打开同一个文件呢?
若父进程以只读r或只写w方式打开一个文件,那么子进程继承这个文件描述符也只能以只读r或只写w方式访问这个文件,无法进行基于文件的进程间通信,因为通信需要至少一方能够写入数据,另一方能够读取数据。即:父进程一开始就要按照r、w方式为了后续能够灵活地设置通信方向。

每个进程都有一个文件描述表,用于存储指向struct file结构体的指针,struct file允许多个进程通过指针指向它。 每个struct file内部都有一个引用计数,用来跟踪有多少个fd指向它,关闭文件时,OS会将struct file引用计数–,直到引用计数=0,OS会释放struct file对象,但磁盘上的文件仍在,删除文件系统中的文件需要通过系统调用unlink()、remove()。
2.4.2. 概念
- 匿名管道:也被称为无名管道,是用于进程间通信的特殊文件。
匿名管道没有显示的名称,所以在文件系统中找不到,也无法通过常规的文件操作(open、write等)来访问它,只能在创建它的进程及其子进程中有效。
- 匿名管道在内核内存中维护一个缓冲区(通常大小为64KB,用于暂存进程间传输的数据),它是一种临时的通信机制,只能用于在具有血缘关系的进程之间的单向通信。
临时性:匿名管道的生命周期,与创建它的进程及其子进程成正相关。一旦这些进程都退出,管道和缓冲区就会消失。
因为匿名管道,是通过子进程继承父进程的相关的数据结构,使得父子进程看到同一块资源,从而实现进程间通信,所以匿名管道只能在具有血缘关系的进程间通信。
- 本质:在linux中,它被视为内存级的文件,不属于任何文件系统,只存在于内存中,无需向磁盘中进行刷新。
2.4.3. 创建 — pipe()
int pipe(int pipefd[0]);
-
功能:创建一个匿名管道。
-
参数:pipefd是一个指向包含两个整数的数组指针,这两个整数将用作于管道的文件描述符,pipefd[0]为读端文件描述符、pipefd[1]为写端文件描述符。
-
返回值:成功时返回0,失败时返回-1,并设置错误码errno以指示错误原因。

//从字符串buffer中读取数据,写入管道,读取管道,写到字符串buffer1中
#include<iostream>
#include<cstdio>
#include<unistd.h>
#include<cstring>using namespace std;void writer(int wfd)
{int cnt = 0;char str[128] = "hello, I am father!";while(1){char buffer[128]; snprintf(buffer, sizeof(buffer), "%s, cnt: %d, id: %d", str, cnt++, getpid()); write(wfd, buffer, strlen(buffer));sleep(1);}
}void reader(int rfd)
{while(1){char buffer1[128];read(rfd, buffer1, sizeof(buffer1));printf("child get messages: %s\n", buffer1);}
}int main()
{//1.父进程创建管道int pipefd[2];int n = pipe(pipefd);if(n == -1) return 1;//2.父进程创建子进程pid_t id = fork();if(id == 0){//子进程关闭写,进行读close(pipefd[1]);reader(pipefd[0]);}//父进程关闭读,进行写close(pipefd[0]);writer(pipefd[1]);return 0;
}
2.4.4. 应用场景 — 进程池
一、定义与组成
-
定义:是管理一组预先创建的进程的方法,这些进程处于空闲状态,等待接收并处理任务。
-
组成:主要是由资源进程和管理进程组成,管理进程负责创建资源进程、分配任务、回收资源,资源进程负责执行实际的任务。
二、工作原理
- 工作流程:初始化 -> 任务提交 -> 任务分配 -> 任务执行 -> 任务完成 -> 资源回收。
初始化:管理进程首先会创建一组预设数量的资源进程。这些进程在初始化时处于空闲状态,并等待接收任务。同时,管理进程会设置必要的通信机制(如管道),以便与子进程进行通信。
任务提交:用户或OS将需要执行的任务提交给管理进程。
任务分配:管理进程接收到任务后,会从进程池中取出一个空闲的进程,通过之前设置的通信机制(如管道)将任务发送给该进程。
任务执行:接收到任务的资源进程开始执行任务。在执行过程中,资源进程可能需要与管理进程或其他资源进程进行通信,以获取必要的数据或同步执行状态。
任务完成:当资源进程完成任务后,它会通过之前设置的通信机制(如管道),将执行结果发送给管理进程。
资源回收:任务完成后,资源进程会返回到进程池中,标记为空闲状态,以便再次接收新的任务。这样,进程池就可以持续地为新任务提供服务,而无需每次都重新创建进程。
三、优点
-
减少系统开销:预先创建进程,避免了频繁创建和销毁进程,从而减少了系统的开销。
-
提高资源利用率:进程池可以复用进程资源,从而提高了资源利用率。
-
简化任务管理:进程池提供了统一的任务分配机制,从而简化了任务管理。
四、应用场景:并发计算、Web服务器、批处理任务等。
五、代码实现
#pragma once#include<iostream>
#include<cstdio>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#include<cstring>
#include<vector>
#include<cstdlib>
#include<ctime>
#include"task.hpp"using namespace std;enum //匿名枚举,用来将错误码转化为错误信息
{UsageError = 1,ProcnumError,PipeError
};void Usage(const string& proc)
{cout << "Usage:" << proc << "proc_num" << endl;return ;
}class Channel //先描述(类)
{
public:Channel(int wfd, int id, string& name):_wfd(wfd),_id(id),_name(name){ }int Wfd(){ return _wfd; }string& Name(){ return _name;}int Id(){ return _id; }void Print(){cout << "_wfd: " << _wfd;cout << ",_id: " << _id;cout << ",_name: " << _name << endl;}~Channel(){ }
private:int _wfd;pid_t _id;string _name;
};class Processpol //进程池
{
public:Processpol(int proc_num) :_proc_num(proc_num){ }vector<int> fds; //用来关闭struct file被多个文件描述符指向int CreatProcess(work_t work) //1.创建一组子进程、命令行管道{for(int i = 0; i < _proc_num; i++){//父进程需要对管道进行管理,否则会被覆盖int pipefd[2]{0}; int n = pipe(pipefd);if(n == -1) return PipeError; //创建管道失败pid_t id = fork(); if(id == 0) //子进程{if (!fds.empty()) for (auto& fd : fds) close(fd);close(pipefd[1]); //关闭管道的写端dup2(pipefd[0], 0); //将标准输入重定向到管道读端work(pipefd[0]); //执行任务 —— 回调函数exit(0); //终止}//父进程close(pipefd[0]); //关闭管道的读端string name = "channel-" + to_string(i); //管道名字_channels.push_back(Channel(pipefd[1], id, name)); fds.push_back(pipefd[1]);}return 0;}//2.1.选择一个子进程、管道,来执行任务 —— 父进程'负载均衡'式的给子进程分配任务int NextChannel(){static int next = 0; //静态,不属于任何对象,全局, 用来定位进程池中的各个进程、管道int n = next;next++;next %= _channels.size(); //不可越界return n;}//2.3.发送任务编号到管道写端,以供子进程读取void SendTaskCode(int c_code, int t_code){cout << "send code " << t_code << " to " << _channels[c_code].Name() << " proc_id " << _channels[c_code].Id() << endl;write(_channels[c_code].Wfd(), &t_code, sizeof(t_code)); //父进程将数据写入管道的写端sleep(1);}//3.回收资源/*因为子进程会继承父进程的文件描述符表,子进程会将父进程中以w方式打开上一文件的fd,使得上一文件被多个指针指向,所以关闭父进程写端,此文件的struct file中引用计数--,并未全部关闭*/void RecycleProc(){for(auto& e : _channels){close(e.Wfd()); //关闭当前被打开文件(管道)的写端int rid = waitpid(e.Id(), NULL, 0); //回收子进程资源if(rid > 0) //等待成功cout << "wait process " << e.Id() << "sucess" << endl;cout << e.Name() << " close done. process " << e.Id() <<"quit now!" << endl; }}void Debug() //打印子进程、命令行管道相关信息{for(auto& e : _channels){e.Print();}}~Processpol(){ }private:vector<Channel> _channels; //再组织int _proc_num; //预先创建的子进程数量
};void CtrlProcessPool(Processpol* ptr, int cnt)
{while(cnt--){int c_code = ptr->NextChannel();int t_code = NextCode();ptr->SendTaskCode(c_code, t_code);}
}int main(int argc, char* argv[])
{//设置随机数生成的种子(起始值),若无srand,则每次程序启动随机数序列均相同,使用当前时间(时间戳)来初始化种子srand((uint64_t)time(nullptr)); //unit64_t为无符号64位整数,long long别名//输入错误if(argc != 2) {Usage(argv[0]);return UsageError;}//预设创建的进程数须>0int proc_num = stoi(argv[1]);if(proc_num <= 0) return ProcnumError;Processpol* ptr = new Processpol(proc_num); //创建一个进程池//1.创建一组子进程、命令行管道ptr->CreatProcess(Work);ptr->Debug(); //打印子进程、命令行管道相关信息//2.控制子进程CtrlProcessPool(ptr, 5);cout << "task finish......" << endl;//3.回收资源: 子进程先要退出(关闭写端),再回收子进程资源ptr->RecycleProc();return 0;
}
#include<cstdio>
#include<iostream>
#include<unistd.h>
#include <sys/types.h>using namespace std;//函数指针类型
typedef void(*work_t)(int rfd);
typedef void(*task_t)(int rfd, int id);//任务
void PrintLog(int rfd, int id)
{cout << "rfd: " << rfd << " process: " << id << " is working: " << " printf log task!" << endl;
}void ReloadConf(int rfd, int id)
{cout << "rfd: " << rfd << " process: " << id << " is working: " << " reload conf task!" << endl;
}void ConnectMysql(int rfd, int id)
{cout<< "rfd: " << rfd << " process: " << id << " is working: " << "Connect Mysql task!" << endl;
}task_t task[3] = {PrintLog, ReloadConf, ConnectMysql };int NextCode() //2.2.选择要执行任务的编号
{return rand() % 3; //生成一个伪随机数
}void Work(int rfd) //2.4.子进程接受并处理任务
{while(true){int code = 0; int n = read(0, &code, sizeof(code)); //子进程从管道的读端读取数据if(n > 0) {if(code >= 3) continue; task[code](rfd, getpid()); }else if(n == 0) //情况3,写端关闭,读取到了结尾{cout << "read ending!" << endl;break;}else {cout << "read error!" << endl;break;}sleep(1);}
}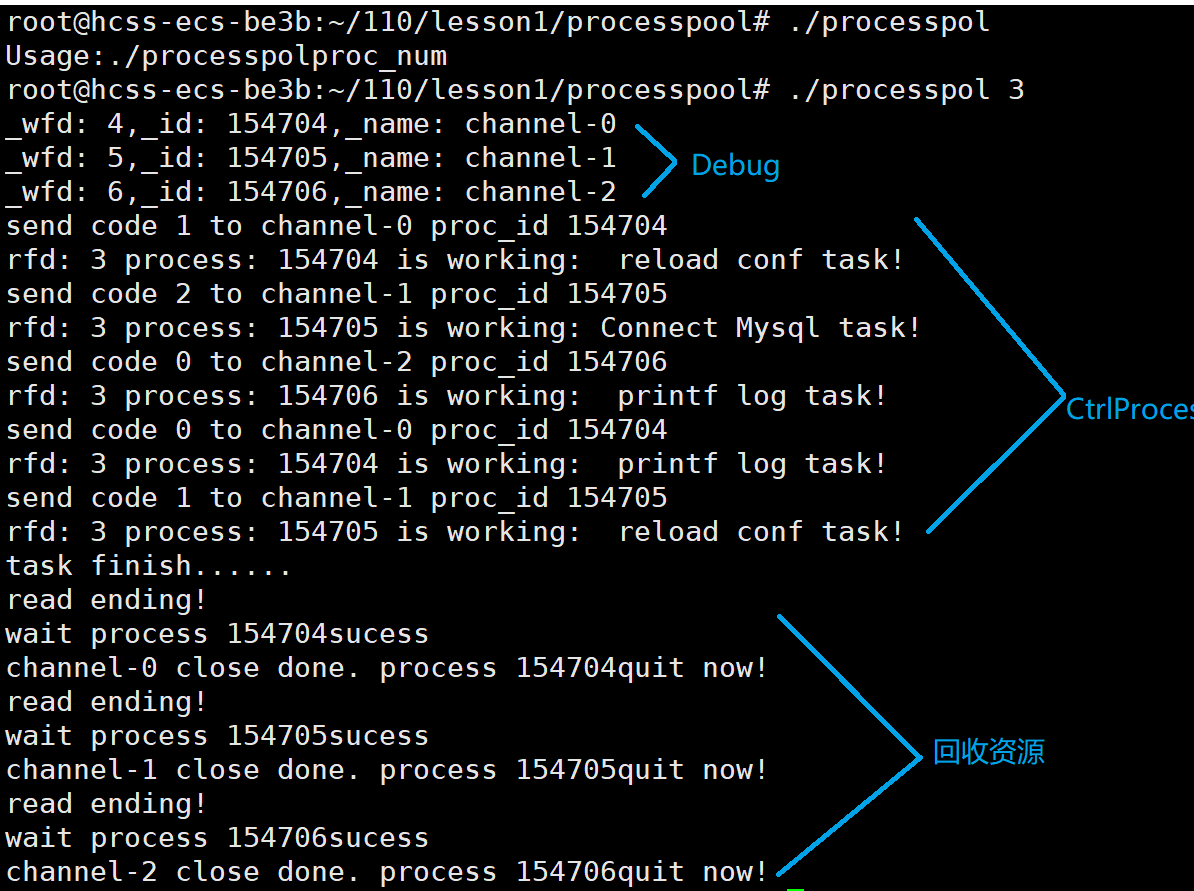
问1:为什么匿名管道的写端fd是4、5、6. . .(递增连续数字序列),读端fd一直是3?
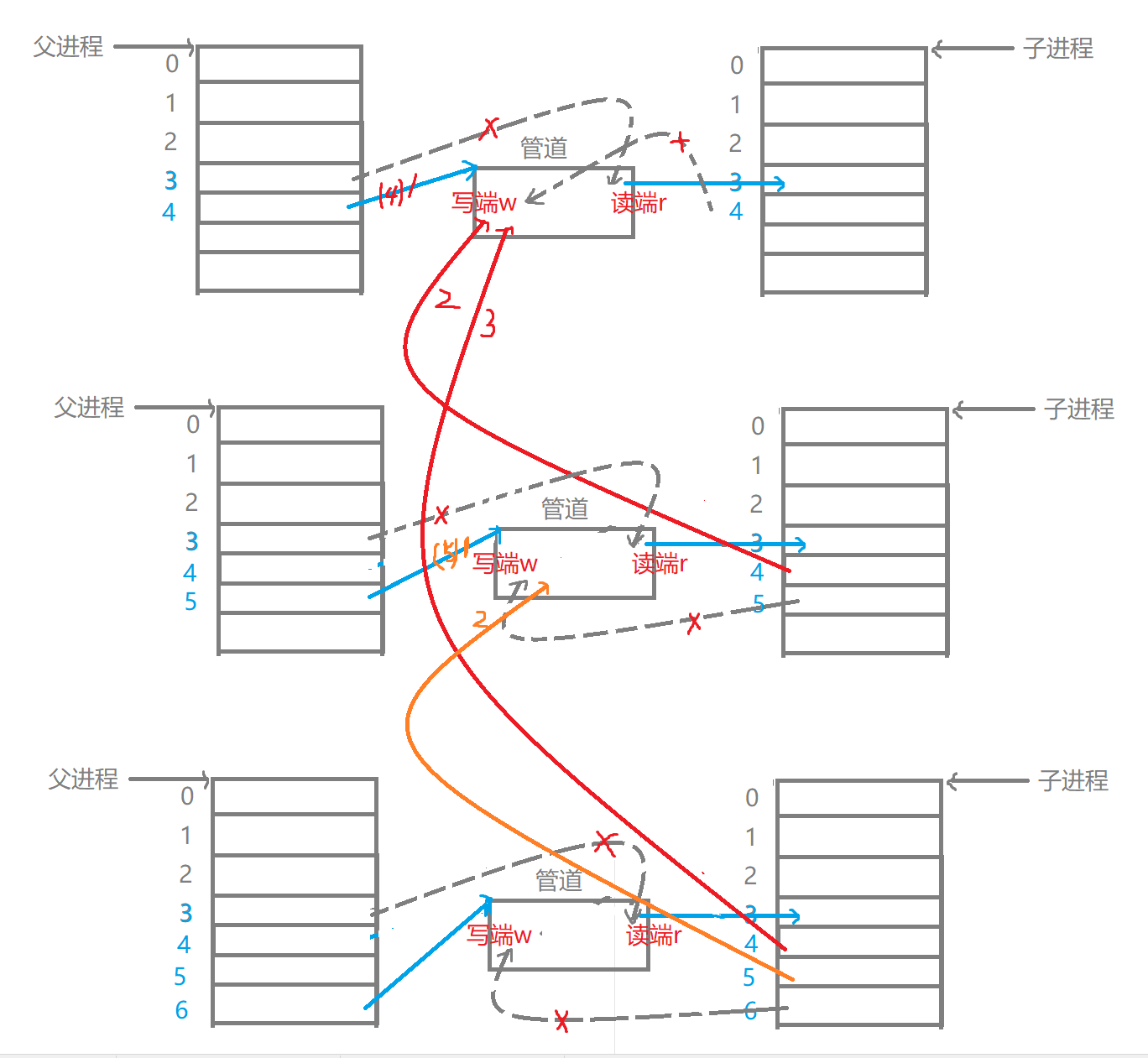
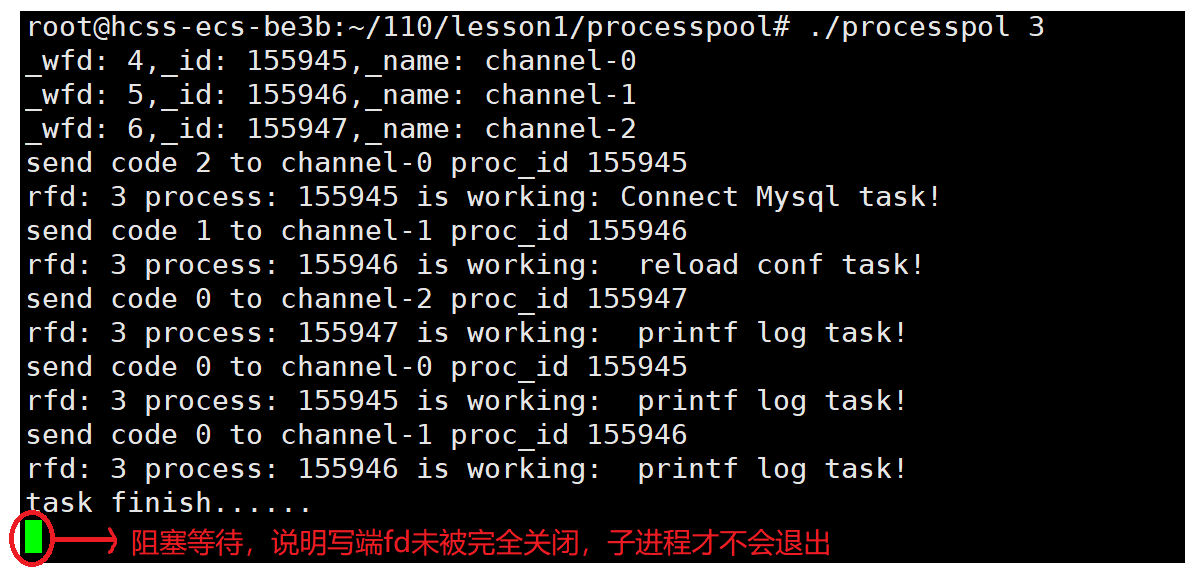
问2:如果关闭匿名管道写端一次,就回收资源,这样做能达到目的吗,会产生什么现象?
不能,当父进程连续打开不同的文件,因为子进程会继承父进程的文件描述符表,会导致管道的写端被多个子进程fd指向,所以关闭写端fd一次,并未做到写端被完全关闭,则子进程不会读取到结束位置就退出。
2.5. 命名管道
2.5.1. 概念和原理
-
命名管道:也称为FIFO文件,是一种特殊类型的文件,它允许不同的进程之间通过同一个文件路径名进行通信。
-
与匿名管道不同,命名管道具有独特的标识符(文件路径),意味着它在文件系统中以文件的形式存在,每个命名管道都有与之对应文件路径作为其标识符,这个标识符使得不同进程,可以通过打开同一个文件路径,来访问同一个命名管道,从而实现进程间的通信。
-
命名管道在文件系统上表现为一个特殊类型的文件,但它实际并不存储数据,而是作为数据流动的通道。尽管它在磁盘上有简单的映像,但这个映像的大小始终为0,因为它不会将数据刷新到磁盘上,而是直接在内存中进行数据传输。
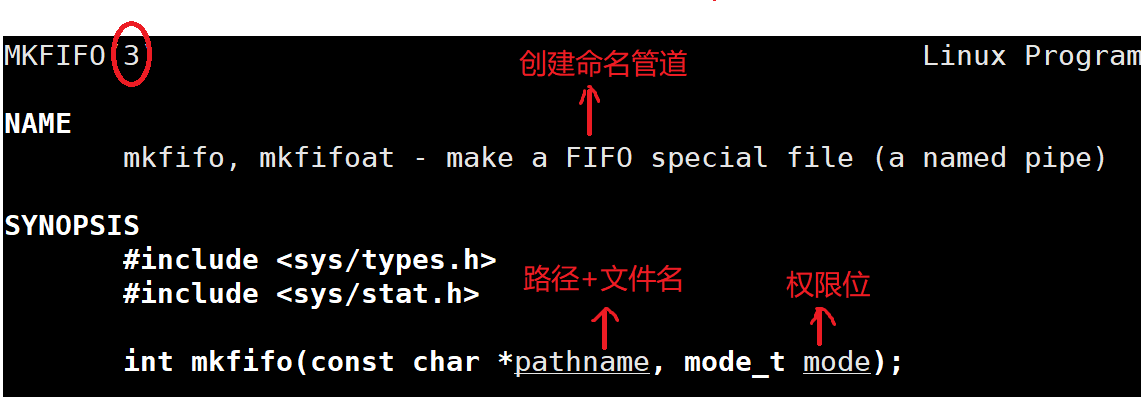
2.5.2. 创建 — mkfifo()
int mkfifo(const char* pathname,mode_t mode);
-
功能:创建一个命名管道。
-
参数:pathname为路径名(路径+文件名)、mode为权限位,用来指定文件权限(实际文件创建的权限还会受到umask影响)。
-
返回值:成功时返回0,失败时返回-1,并设置错误码errno以指示错误原。。
2.5.3. 应用场景 — server&client通信
- 工作流程
第一步:server进程先会创建命名管道,client进程通过打开与server进程创建的命名管道相同的文件路径名来获取命名管道,此时server进程可以与client进程通过命令行管道进行数据交换。
第二步:client以写w的方式打开命令行管道,server以读r的方式打开命令行管道。
第三步:server、client进程关闭命令行管道,以便释放资源(通过ulink()删除命令行管道)。
- 代码实现
#include<iostream>
#include<cstdio>
#include<sys/types.h>
#include<sys/stat.h>
#include<cstring>
#include<errno.h>
#include<unistd.h>#include <fcntl.h>using namespace std;#define Mode 0666 //指定命名管道的权限
#define Path "./fifo" //路径名class Fifo
{
public:Fifo(const string& path) :_path(path){umask(0);int n = mkfifo(Path, Mode); //创建命名管道if(n == 0) {cout << "mkfifo success!" << endl;}else{cout << "mkfifo failed! errno: " << errno << "errdesc: " << strerror(errno) << endl; }}~Fifo() {int n = unlink(Path); //删除命名管道if(n == 0){cout << "remove file success!" << endl;}else{cout << "remove file failed! errno: " << errno << "errdesc: " << strerror(errno) << endl; }}private:string _path;
};
#include"name_pipe.hpp"int main()
{//1.创建命名管道Fifo fifo(Path);//2.以读的方式打开命名管道int fd = open(Path, O_RDONLY);if(fd <= 0){cout << "open failed! errno: " << errno << "errdesc: " << strerror(errno) << endl;return 1;}cout << "open success!" << endl;//3.从命名管道中读取数据char buffer[128];while(1){int n = read(fd, buffer, sizeof(buffer));if(n > 0){buffer[n] = '\0';cout << "client say: " << buffer << endl;}else if(n == 0){cout << "client quit! me to...." << endl;break;}else{cout << "read failed! errno: " << errno << "errdesc: " << strerror(errno) << endl;break;}}
}
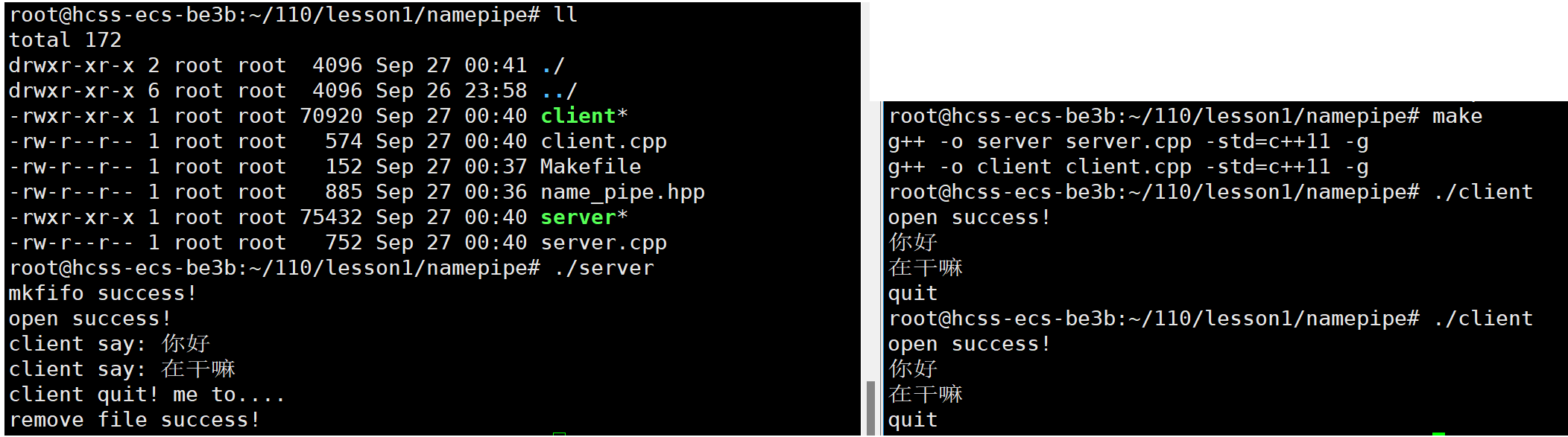
#include"name_pipe.hpp"int main()
{//1.以写的方式打开命名管道int fd = open(Path, O_WRONLY);if(fd <= 0){cout << "open failed! errno: " << errno << "errdesc: " << strerror(errno) << endl;return 1;}cout << "open success!" << endl;//2.向命名管道中写入数据string str;while(1){getline(cin, str);if(str == "quit")break;int n = write(fd, str.c_str(), sizeof(str) - 1);if(n == -1){cout << "write failed! errno: " << errno << "errdesc: " << strerror(errno) << endl;break;}}
}
2.6. 命名管道与匿名管道的区别
- 创建与打开方式、存在形式
匿名管道:由pipe函数创建,同时管道的两端已经被被打开了,并返回调用进程两个fd,分别用于读写操作。它只存在与内存中,无文件名。
命名管道:由mkfifo函数创建,需要手动调用open打开。在文件系统中有对应的文件名(路径)。
2. 通信范围
匿名管道:具有血缘关系的两个进程间的通信。
命名管道:任意两个进程之间的通信,只要这两个进程可以访问到命名管道所在的文件系统路径。
- 生命周期
匿名管道:其生命周期随进程(父子进程)的结束而结束。
命名管道:其生命周期与文件系统中的文件相同,当文件被删除时,命名管道的生命周期结束,如果文件系统中的命名管道还在,它就可以被多个进程同时打开和访问。
3. System V 共享内存
3.1. 概念和原理
- 共享内存概念:是一种高效且快速的进程间通信的方式,它允许多个进程访问同一块物理内存区域,从而实现数据的共享和交换。
💡Tips:共享内存的生命周期随内核,管道的生命周期随进程!
- 共享内存进行通信的流程:创建共享内存 -> 构建映射 -> 进程通信 -> 解除映射 -> 删除共享内存。
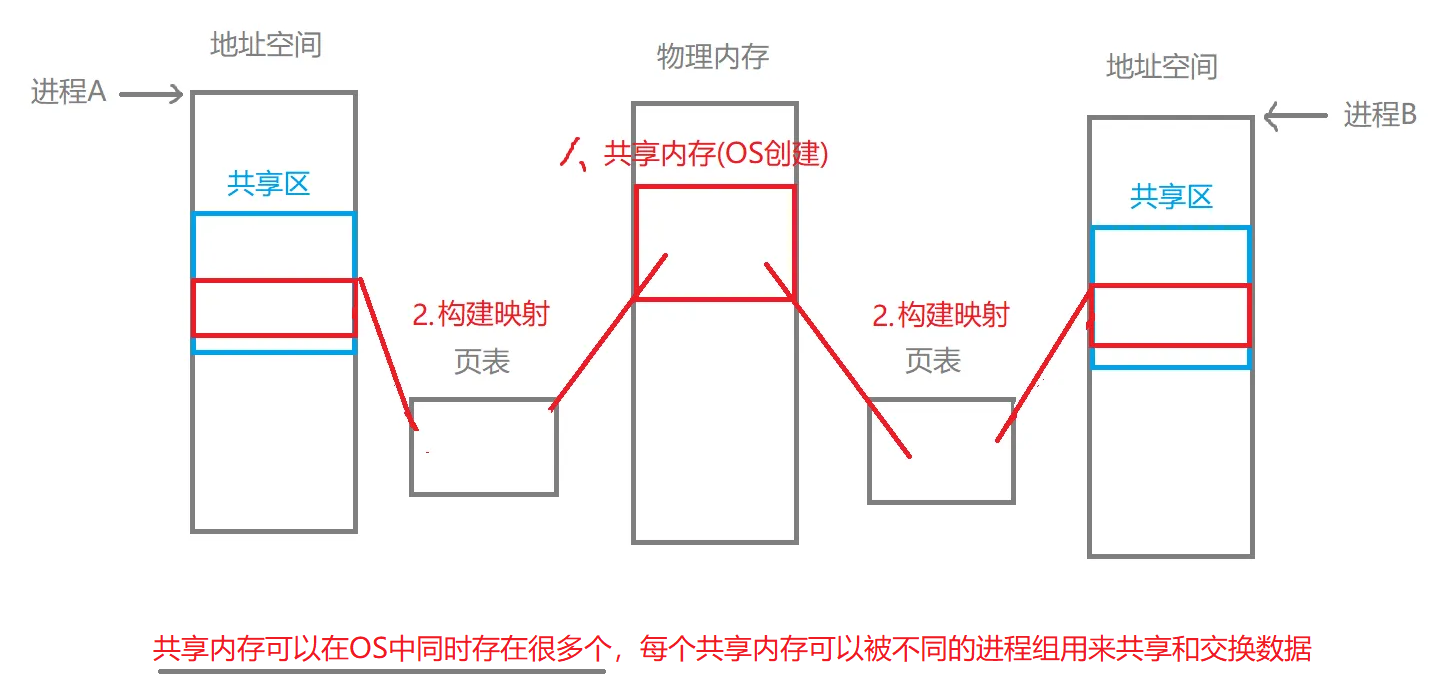
系统中有许多进程进行通信,所以共享内存可以在OS中同时存在多个,则OS需要管理所有被创建的共享内存,先描述,再组织。 为了实现进程间通信,得让不同进程看到同一个共享内存,就需要在OS中给共享内存提供唯一性的标识(key值)。
struct shmid_ds {struct ipc_perm shm_perm; /* operation perms */int shm_segsz; /* size of segment (bytes) */__kernel_time_t shm_atime; /* last attach time */__kernel_time_t shm_dtime; /* last detach time */__kernel_time_t shm_ctime; /* last change time */__kernel_ipc_pid_t shm_cpid; /* pid of creator */__kernel_ipc_pid_t shm_lpid; /* pid of last operator */unsigned short shm_nattch; /* no. of current attaches */unsigned short shm_unused; /* compatibility */void *shm_unused2; /* ditto - used by DIPC */void *shm_unused3; /* unused */
};struct ipc_perm{__kernel_key_t key; //共享内存的唯一性标识__kernel_uid_t uid;__kernel_gid_t gid;__kernel_uid_t cuid;__kernel_gid_t cgid;__kernel_mode_t mode;unsigned short seq;
};
3.2. 共享内存函数
3.3. shmget — 创建共享内存
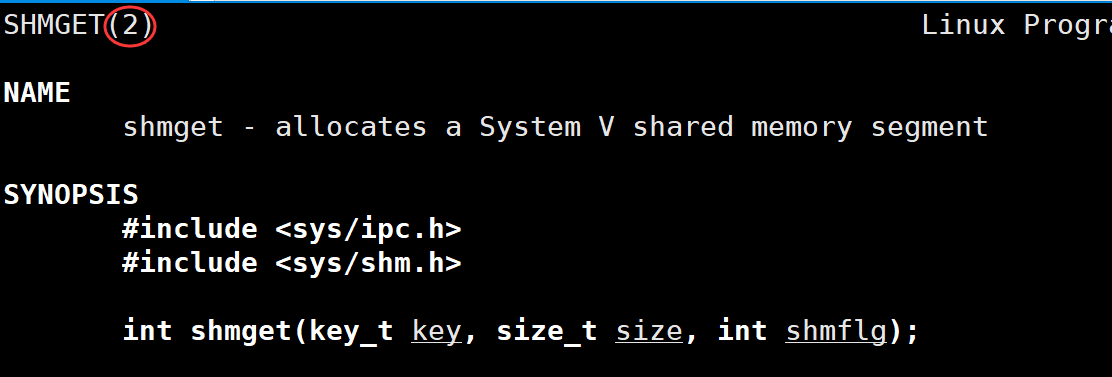
int shmget(key_t key, size_t size, int shmflg);
-
功能:创建一个新的共享内存 或 获取一个已存在的共享内存。
-
返回值:成功时,返回一个非负整数,表示共享内存的标识符(shmid);失败时,返回-1,并设置错误码errno以指示错误原因。
-
参数:key: 共享内存的键值, 用来唯一性标识共享内存; size: 共享内存的大小, 以字节为单位(共享内存大小通常以4KB为基本单位,建议申请大小为4KB的整数倍); shmflg: 标志位,用来指定函数行为和共享内存权限。
一、key
-
key:是一个键值,用来在OS中唯一标识一个共享内存。
-
key值的作用:区分共享内存、实现进程间通信。
区分共享内存:key值确保了在OS中每个共享内存都有一个唯一的标识,使得不同的共享内存可以在OS被区分开来,避免了不同进程误用其他进程的共享内存。
实现进程间通信:由于key值的唯一性,多个进程可以通过使用相同的key值来识别、访问同一个共享内存,从而实现进程间通信。这种通信方式,进程可以直接读写这块内存,避免了数据在进程间的复制,提高了通信效率。
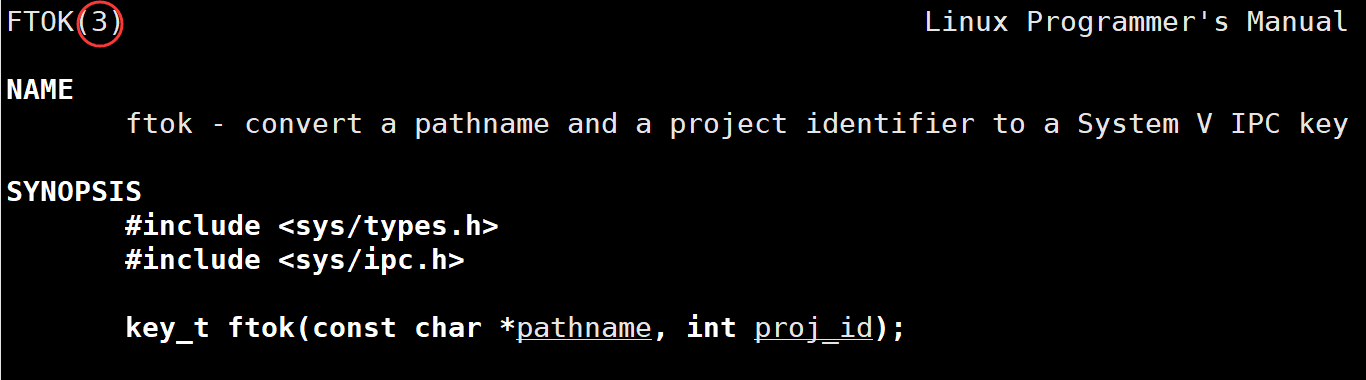
- key值的生成:在创建共享内存时,通常需要程序员提供一个key值,为了避免与OS中现有的共享内存key值冲突,一般不会自己随意取key值,而是通过系统调用接口ftok来生成唯一的key值,但频繁调用ftok,会出现键值冲突。
key_t ftok(const char* pathname, int proj_id);
-
功能:将一个已经存在的路径名pathname和一个项目标识符proj_id(非0整数),通过特定算法(数学运算),转化为一个唯一的键值,用来标识共享内存或其他IPC对象(消息队列、信号量集等),这个key会被填充到维护共享内存的数据结构中。
-
参数:pathname,指向文件名的指针,这个文件必须存在于文件系统中。 pro_id:是一个用户自定义的项目标识符,用于进一步区分同一文件的不同IPC资源,通常是8位整数(0~255)。
-
返回值:成功时返回一个具有唯一性的key值;文件不存在,失败返回-1,并设置错误码errno以指示错误原因。
-
使用场景:当多个进程需要共享同一块内存时,可以使用相同的文件路径和项目标识来调用ftok函数,从而生成相同的key值,然后,它们可以使用这个key值调用shmget函数,就可以访问到同一块共享内存。
为什么key值要让用户传入呢?
只要通信双方事先约定好了参数,两个进程可以基于相同的文件路劲和项目标识符来生成同一个key值,当它们分别调用shmget函数并传入相同的key,就能够看到同一个共享内存,从而实现进程间通信。如果key是由内核设定,进程之间不知道对方创建共享内存的key值,因为进程具有独立性,从而无法建立通信。
eg:进程A创建共享内存,其key值如果由OS自动生成,进程具有独立性,进程B无法知道进程A创建的共享内存的key值,因此进程B无法访问进程A创建的共享内存,从而无法建立通信。
二、shmflg
- 概念:是一组标志位,用于指定shmget函数的行为和设置共享内存的权限。
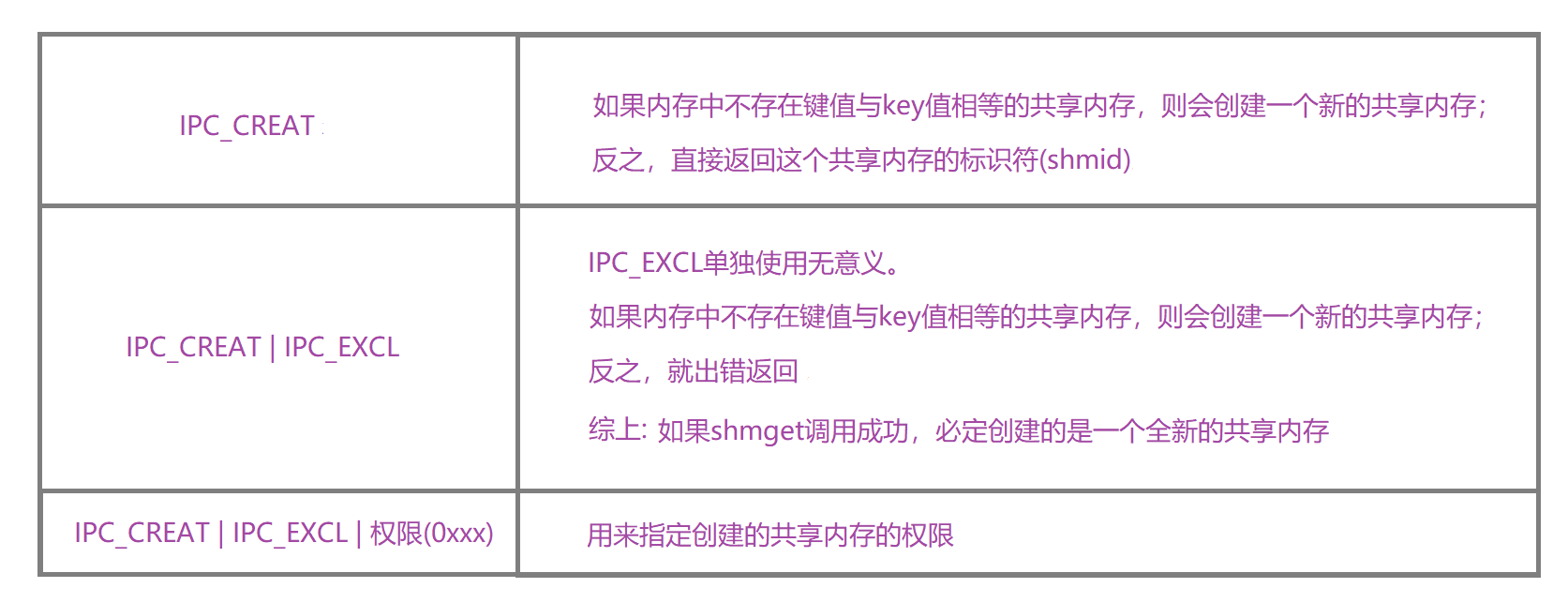
3.4. shmat — 进程挂接共享内存
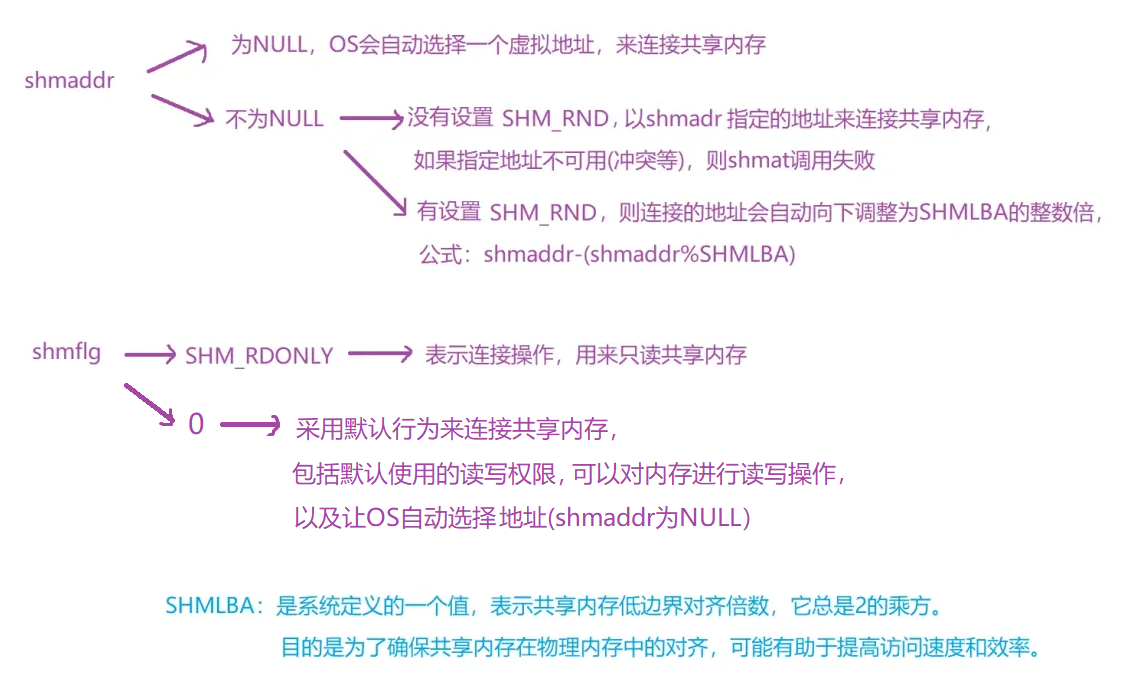
void* shmat(int shmid,const void* shmaddrr,int shmflg);
-
功能:将共享内存连接到进程地址空间,从而构建映射。
-
返回值:成功时,返回一个共享内存映射到地址空间中起始位置的地址(虚拟地址);失败时,返回-1并设置错误码errno以指示错误原因。
-
通过shmaddr的返回值,以及在shmget中设定的共享内存大小,就可以访问共享内存中任意位置的数据。
-
参数:shmid:共享内存的标识符;shmaddr:指定映射到地址空间的具体起始位置,通常设置为NULL让系统自动选择一个虚拟地址; shmflg:控制连接的标志位。
3.5. shmdt — 断开共享内存连接
int shmdt(const void* shmaddr);
-
功能:断开共享内存与调用进程的地址空间的连接,从而解除映射,并没有直接删除共享内存。
-
参数shmaddr:之前通过shmat连接共享内存的起始虚拟地址。
-
返回值:成功时,返回0;失败时,返回-1并设置错误码errno以指示错误原因。
3.6. shmctl — 删除共享内存
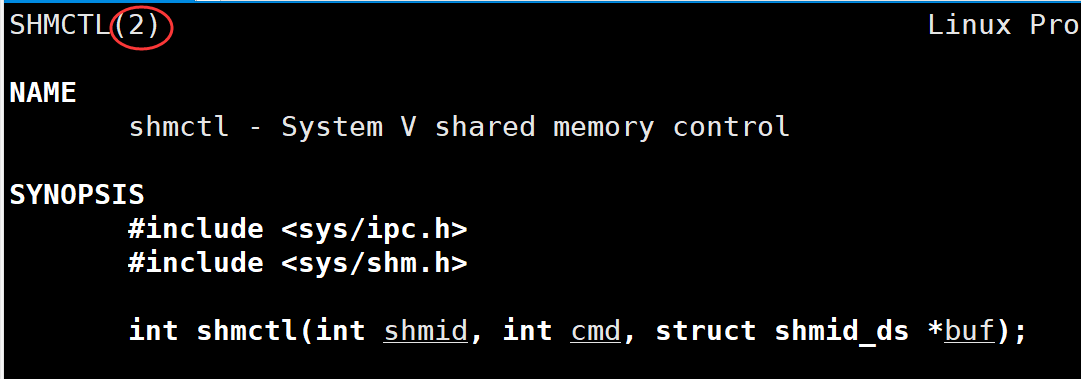
int shmctl(int shmid,int cmd,struct shmid_ds* buf);
-
功能:用来控制共享内存的各种属性,如:获取属性、设置属性、删除共享内存。
-
返回值:成功时,返回0;失败时,返回-1并设置错误码errno以指示错误原因。
-
参数:shmid:共享内存的标识符;cmd:要执行的操作。buf:指向一个保存着共享内存的模式状态和访问权限的数据结构shmid_ds,用于传递或接收共享内存的属性信息。

3.7. 应用场景 — server&client通信
#pragma once#include<iostream>
#include<cstdio>
#include<sys/types.h>
#include<sys/ipc.h>
#include<cerrno>
#include<cstring>
#include<cstdlib>
#include<sys/shm.h>
#include<unistd.h>using namespace std;#define PathName "/root/110" //在文件系统中存在的文件路径
#define Proj_Id 125
#define Size 4096 //共享内存大小,通常以4kb为基本单位,建议申请的大小为4kb的整数倍const string ToHex(key_t key) //将整数转化为十六进制
{char buffer[256];snprintf(buffer, sizeof(buffer), "0x%x", key);return buffer;
}key_t GetShmKeyorDie() //获取key值
{ int key = ftok(PathName, Proj_Id);if(key == -1) {cerr << "ftok failed, errno: " << errno << "error reason: " << strerror(errno) << endl;exit(1);}return key;
}int CreatShmorDie(key_t key, int size, int flag) //1.创建共享内存
{int shmid = shmget(key, size, flag);if(shmid == -1){cerr << "shmget failed, errno: " << errno << "error reason: " << strerror(errno) << endl;exit(2);}return shmid; //共享内存的标识符
}//Tips:使用共享内存通信,一定是一个进程创建新的共享内存,另一个进程直接获取共享内存
int CreatShm(key_t key) //服务端,创建共享内存
{umask(0);return CreatShmorDie(key, Size, IPC_CREAT|IPC_EXCL|0666); //设置权限
}int GetShm(key_t key) //客户端,使用共享内存
{return CreatShmorDie(key, Size, IPC_CREAT);
}void* AttShm(int shmid) //2.进程挂接共享内存,构建映射
{void* addr = shmat(shmid, nullptr, 0); //shmaddr为null,由OS自动生成虚拟地址if(addr == NULL){cerr << "shmat failed, errno: " << errno << "error reason: " << strerror(errno) << endl;return nullptr;}return addr;
}void DetachShm(void* addr) //4.断开共享内存的连接,解除映射
{int n = shmdt(addr); if(n == -1)cerr << "shmdt failed, errno: " << errno << "error reason: " << strerror(errno) << endl;
}void DelShm(int shmid) //5.删除共享内存
{int n = shmctl(shmid, IPC_RMID, nullptr);if(n == -1)cerr << "shmctl failed, errno: " << errno << "error reason: " << strerror(errno) << endl;elsecout << "shmctl delete success!" << endl;
}void ShmDebug(int shmid) //获取共享内存的属性信息
{struct shmid_ds shmds; int n = shmctl(shmid, IPC_STAT, &shmds);if(n == -1)cerr << "shmctl failed, errno: " << errno << "error reason: " << strerror(errno) << endl;else{cout << "nattch" << shmds.shm_nattch << endl;cout << "key" << shmds.shm_perm.__key << endl;cout << "attch time" << shmds.shm_atime << endl;cout << "detach time" << shmds.shm_dtime << endl;}
}
#include"Shm.hpp"
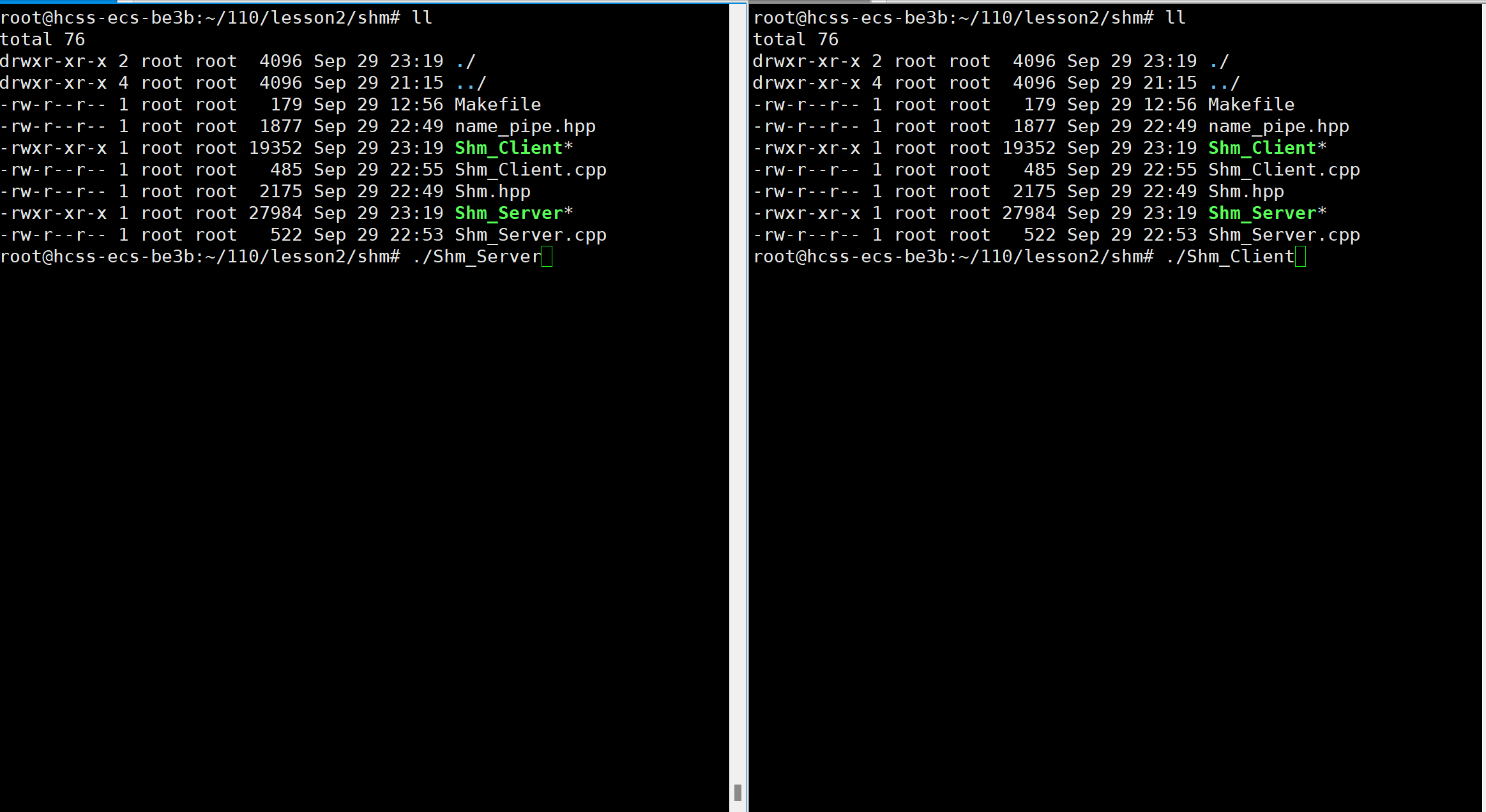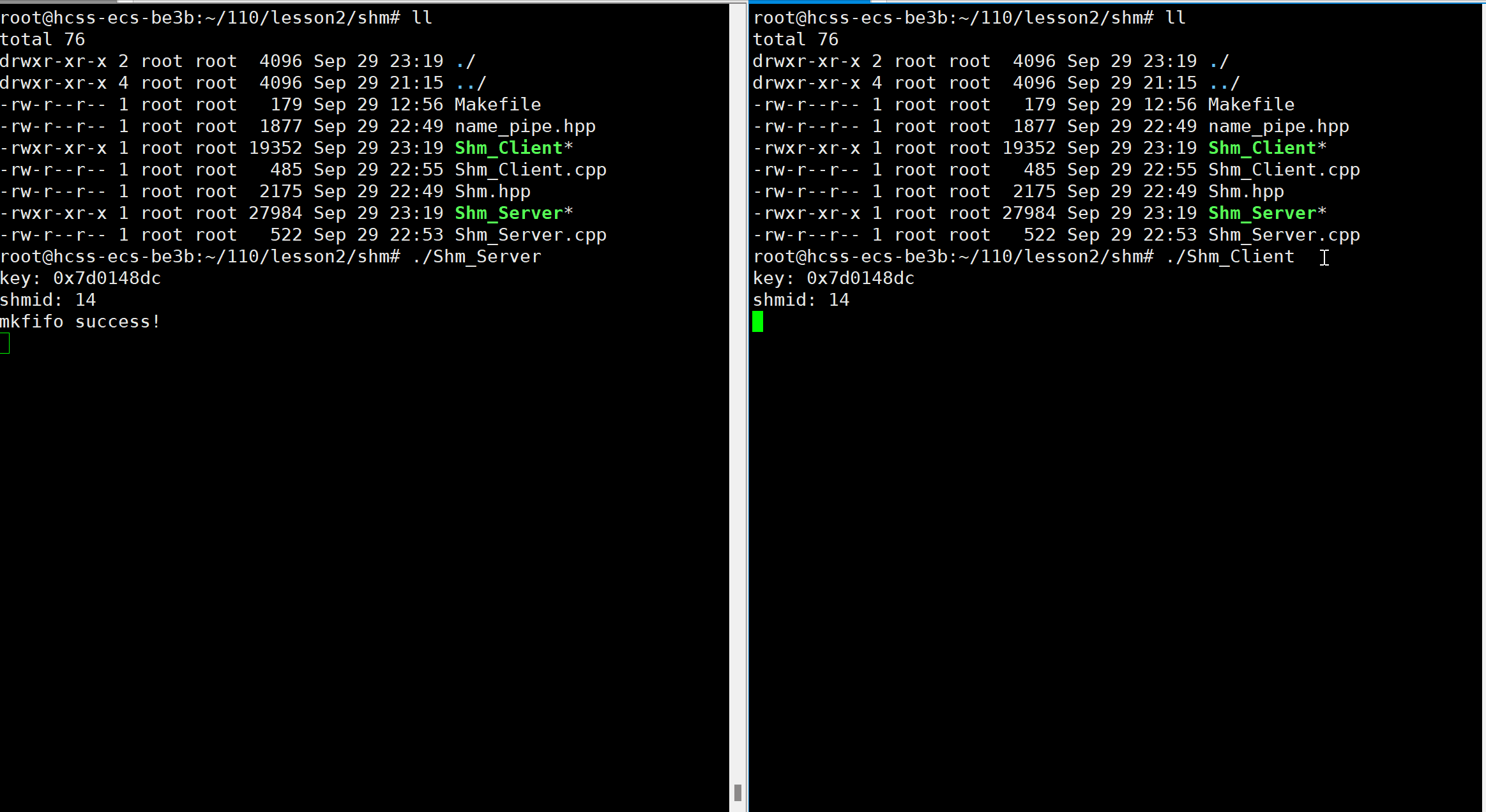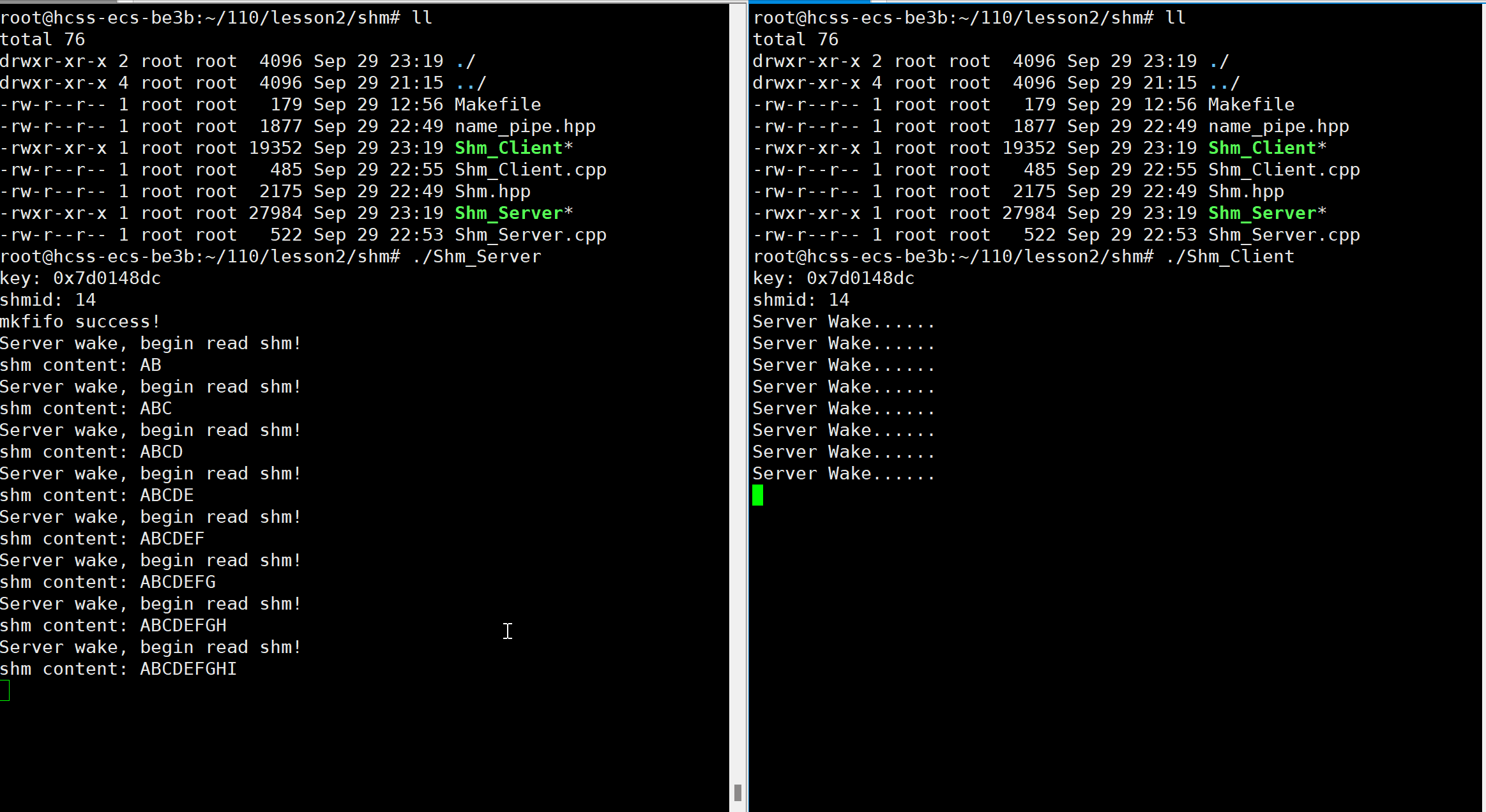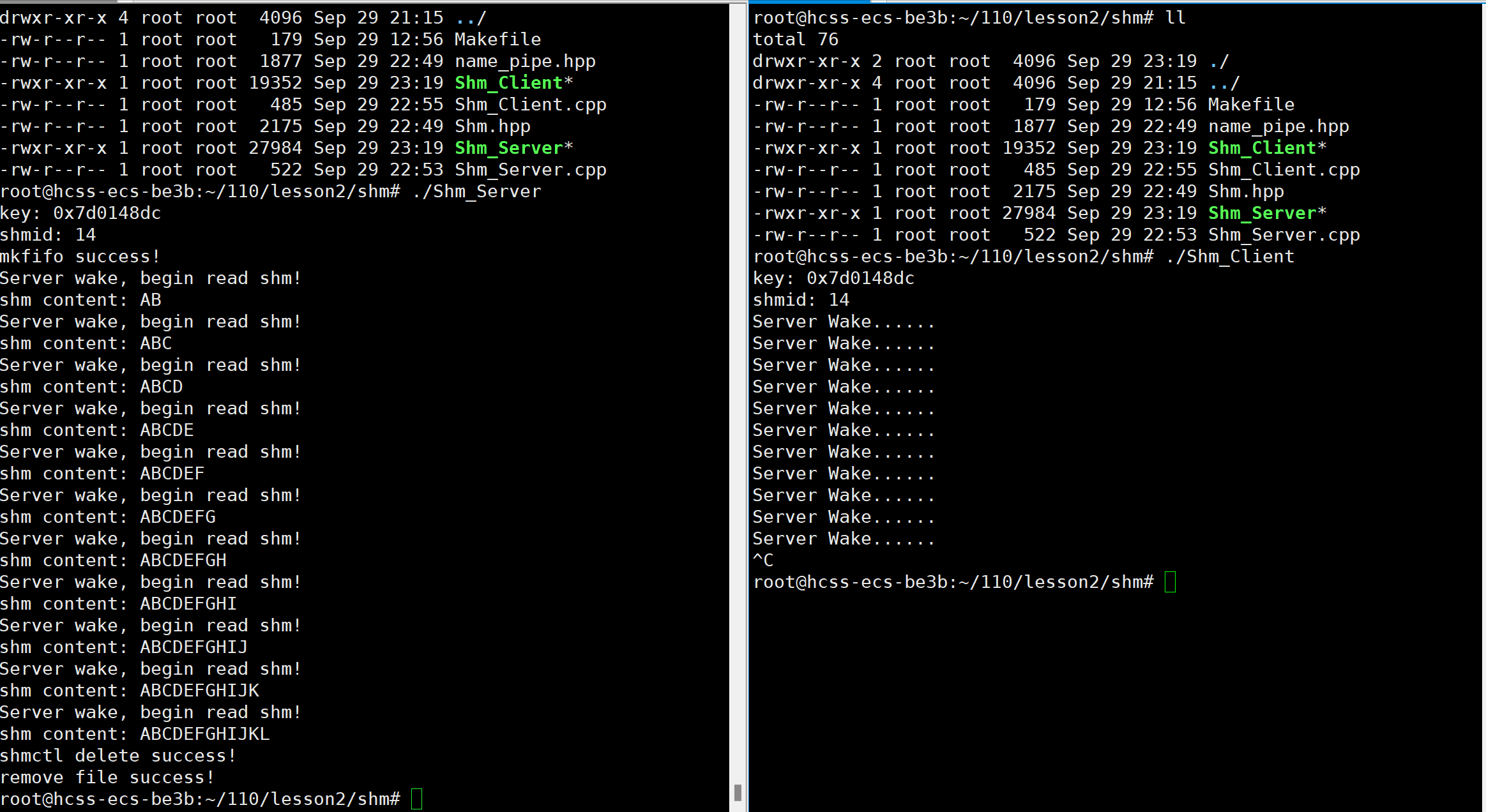
#include"name_pipe.hpp"int main()
{//获取key值int key = GetShmKeyorDie(); cout << "key: " << ToHex(key) << endl;//1.创建共享内存int shmid = CreatShm(key);cout << "shmid: " << shmid << endl;//2.进程连接到共享内存,构建映射char* addr = (char*)AttShm(shmid);//3.进程间通信 //共享内存不提供进程间协同的任何机制(同步、互斥机制,用来保护共享资源)Fifo fifo(Path); //管道内部自带同步、互斥机制Sysn sn; sn.OpenReadorDie(); //以只读的方式打开管道for(; ;){if(sn.Wait()) //等待客户端写完{cout << "shm content: " << addr << endl; sleep(1);}else break; }//4.断开共享内存的连接,解除映射DetachShm(addr);//5.删除共享内存DelShm(shmid);return 0;
}
#include"Shm.hpp"
#include"name_pipe.hpp"int main()
{//获取key值key_t key = GetShmKeyorDie();cout << "key: " << ToHex(key) << endl;//1.获取共享内存int shmid = GetShm(key);cout << "shmid: " << shmid << endl;//2.进程连接到共享内存,构建映射char* addr = (char*)AttShm(shmid);//3.进程间通信 Sysn sn;sn.OpenWriteorDie(); //以只写的方式打开管道memset(addr, '0', 1);for(char ch = 'A'; ch < 'Z'; ch++){addr[ch - 'A'] = ch;sleep(1);sn.Wakeup(); //写入完成,唤醒服务端}//4.断开共享内存的连接,解除映射DetachShm(addr);//5.删除共享内存DelShm(shmid);return 0;
}
#include<iostream>
#include<cstdio>
#include<sys/types.h>
#include<sys/stat.h>
#include<cstring>
#include<errno.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>using namespace std;#define Mode 0666 //指定命名管道的权限
#define Path "./fifo" //路径名class Fifo
{
public:Fifo(const string& path) :_path(path){umask(0);int n = mkfifo(Path, Mode); //创建命名管道if(n == 0) {cout << "mkfifo success!" << endl;}else{cout << "mkfifo failed! errno: " << errno << "errdesc: " << strerror(errno) << endl; }}~Fifo() {int n = unlink(Path); //删除命名管道if(n == 0){cout << "remove file success!" << endl;}else{cout << "remove file failed! errno: " << errno << "errdesc: " << strerror(errno) << endl; }}private:string _path;
};class Sysn //在共享内存中使用管道(包含同步、互斥机制),保护共享资源
{
public:Sysn():wfd(-1),rfd(-1){ }void OpenWriteorDie() //以只写的方式打开管道{wfd = open(Path, O_WRONLY);if(wfd < 0)exit(4);}void OpenReadorDie() //以只读的方式打开管道{rfd = open(Path, O_RDONLY);if(rfd < 0)exit(5);}bool Wait() //服务福端等待客服端写入完成{int flag = true;int c = 0;int n = read(rfd, &c, sizeof(c));if(n == sizeof(c))cout << "Server wake, begin read shm!" << endl;else if(n == 0)flag = false;elseflag = false;return flag;}void Wakeup() //客户端写完,唤醒服务端{int c = 0;int n = write(wfd, &c, sizeof(c));if(n == -1){cerr << "write failed" << endl;exit(3);}cout << "Server Wake......" << endl;}private:int wfd;int rfd;
};
3.8. 命令行查看共享内存
- ipcs
- ipcs:是显示和管理系统中进程间通信(IPC)资源的工具,包括共享内存、消息队列、信号量集。
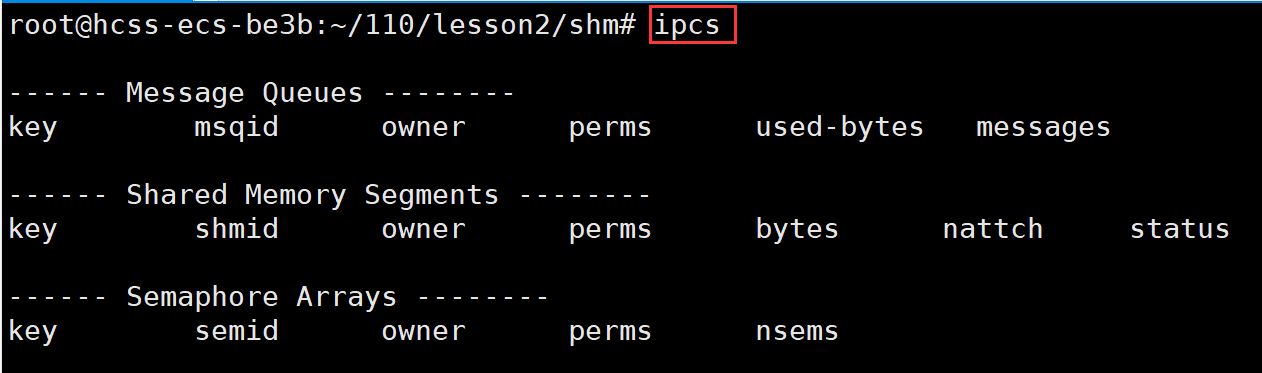
- 选项:-m:显示共享内存相关的信息、-q:显示消息队列相关的信息、-s:查看信号量级相关的信息。

- key和shmid的区别:都是确保共享内存的唯一性和可访问性的重要机制。
key在内核中用于标识共享内存,确保其在系统内的唯一性,即:key在内核层面上保证了共享内存的唯一性。
shmid是在成功创建共享内存后由系统返回,用于在用户层面上唯一地标识共享内存,并作为后续对共享内存操作的参数,即:shmid在用户层面上提供了对共享内存的唯一标识和操作接口。
- ipcrm [-m|-q|-s] shmid
- 功能:删除已存在的IPC资源对象,包括共享内存、消息队列、信号量集。
3.9. 优缺点
- 优点:共享内存是所有进程间通信(IPC)方式中速度最快的。
减少拷贝次数:在管道通信中,数据通常要经过至少两次拷贝,数据从一个进程的缓冲区写入管道,然后从管道中读取到另一个进程的缓冲区中,这涉及两次数据在不同内存区域之间的复制操作。在共享内存中允许多个进程直接访问同一块内存区域,当一个进程将数据写入到共享内存中,其他进程可以立即看到,最多只会经历一次从进程的用户空间到共享内存的拷贝。
直接访问:进程可以直接对共享内存进行读写操作,无需通过OS进行数据中转,这大大减少了内核参与数据传输的开销,提高了通信效率。
-
缺点:共享内存不提供进程间协同的任何机制。
-
这会导致多个进程同时访问共享内存区域时,出现数据不一致和数据竞争等问题。因为没有内置的同步和互斥手段,不同进程可能在不可预测的时间点对共享内存进行读写操作,从而破坏数据的完整性。例如,一个进程正在写入数据时,另一个进程可能同时在读取,可能会读取到不完整的数据;或者两个进程同时写入,可能会导致数据覆盖混乱。所以需要额外的机制(管道、信号量等)来保证数据的完整性和一致性。
进程间协同机制:是确保多个进程在访问公共资源时能够正确地同步、互斥以及协调彼此的操作。协调彼此的操作则涉及更复杂的交互,例如一个进程等待另一个进程完成特定任务后再继续执行。
管道在操作系统中自带协同机制。如:管道的读写操作具有原子性,一次读写要么全部完成,要么全部失败,保证了数据的完整性。同时,阻塞机制也起到了协同的作用,当缓冲区满时,写操作被阻塞,防止数据溢出;当缓冲区为空时,读操作被阻塞,在一定程度上实现了同步和互斥的效果。
4. 消息队列
4.1. 原理与概念
- 消息队列:一种进程间通信(IPC)的机制,允许多个进程通过发送和接收带有类型的数据块(消息)进行通信,这些消息在队列中按照先进先出(FIFO)的顺序存储。
发送进程将消息添加到队列的末尾,接收进程从队列的头部读取信息。
💡Tips:消息队列的生命周期随内核,即:System V IPC资源的生命周期随内核!!!
- 特点
支持异步通信:是指在进行数据传输时,发送方和接收方无需同步,即:它们可以独立的工作,彼此之间无需等待对方的回应。如:发送方发送消息后继续执行,无需等待接收方的回应,接收方可以在任何时间接收消息,同时会触发一个事件来通知发送方,从而达到异步通信的目的。
提供了可靠的消息传递机制,确保了数据不会丢失。如:即使接收方暂时无法处理消息,消息也会保存到队列中,直到接收方读取成功。
灵活的消息格式:消息队列中的消息可以包含不同类型的数据,如:文本、二进制等。
- 基本组件:每个消息队列都有唯一的标识符(msgqid)、消息队列中每个消息都包含一个类型字段和数据字段。
消息中的类型字段可以用于标识消息的类型,以便接收进程可以根据类型来筛选和处理消息,而数据字段则包含实际要传递的数据。
- 发送方和接收方通过使用相同的key值来创建或获取消息队列,它们就可以访问到同一个消息队列,从而实现进程间通信。消息队列特别适用于异步消息传递和任务队列等场景。
4.2. 消息队列函数
- 创建或获取消息队列 —— msgget函数
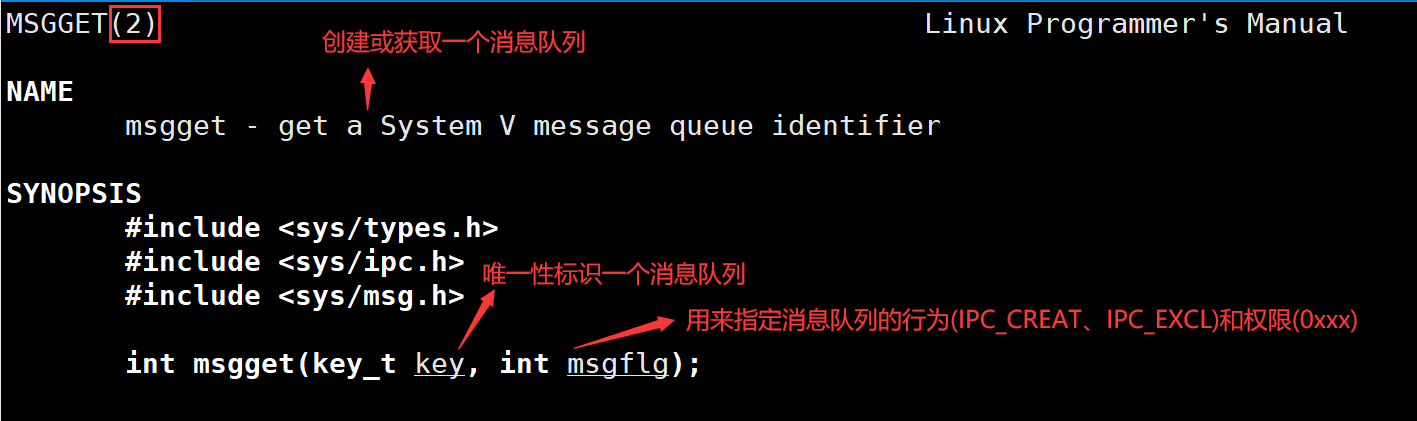
key_t key = ftok(".", MSG_KEY);
int msgid = msgget(key, IPC_CREAT|0666);
- 发送消息到消息队列 — msgsnd函数
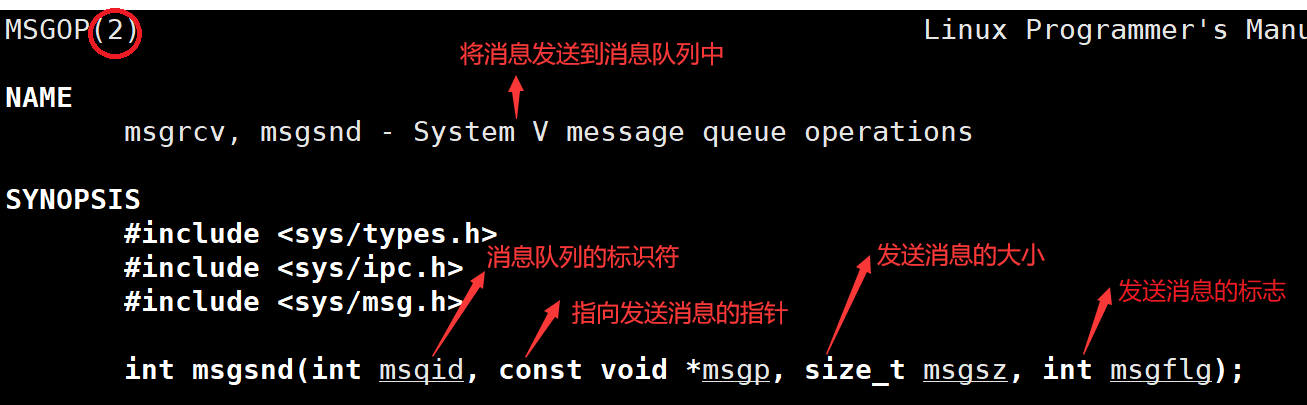
Message msg; //结构体,消息包含类型和数据
msg.mtype = 1; // 消息类型为 1
strcpy(msg.mtext, "Hello, World!"); //消息数据
if (msgsnd(msgid, &msg, sizeof(msg.mtext), 0) == -1) {perror("msgsnd");exit(1)
}
- 从消息队列接收消息 — msgrcv函数
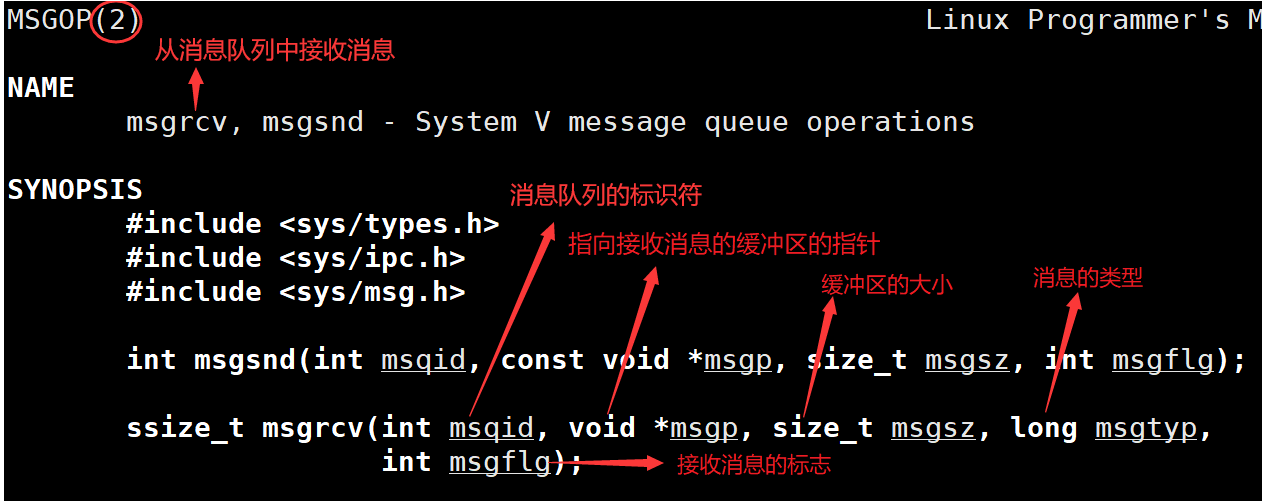
Message msg;
if (msgrcv(msgid, &msg, sizeof(msg.mtext), 1, 0) == -1) {perror("msgrcv");exit(2);
}
printf("Received message: %s\n", msg.mtext);
- 控制消息队列
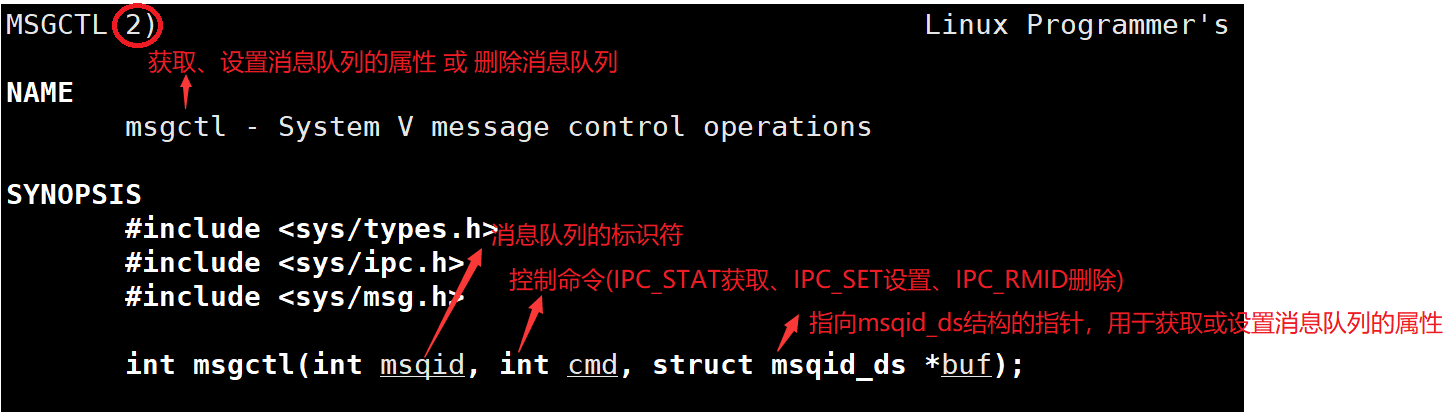
if (msgctl(msgid, IPC_RMID, NULL) == -1) {perror("msgctl");exit(3);
}
struct msqid_ds {struct ipc_perm msg_perm; /* Ownership and permissions */time_t msg_stime; /* Time of last msgsnd(2) */time_t msg_rtime; /* Time of last msgrcv(2) */time_t msg_ctime; /* Time of last change */unsigned long __msg_cbytes; /* Current number of bytes inqueue (nonstandard) */msgqnum_t msg_qnum; /* Current number of messagesin queue */msglen_t msg_qbytes; /* Maximum number of bytesallowed in queue */pid_t msg_lspid; /* PID of last msgsnd(2) */pid_t msg_lrpid; /* PID of last msgrcv(2) */
};The ipc_perm structure is defined as follows (the highlighted fields are settable using IPC_SET):struct ipc_perm {key_t __key; /* Key supplied to msgget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions */unsigned short __seq; /* Sequence number */
};
5. System V中IPC资源在内核中的设计
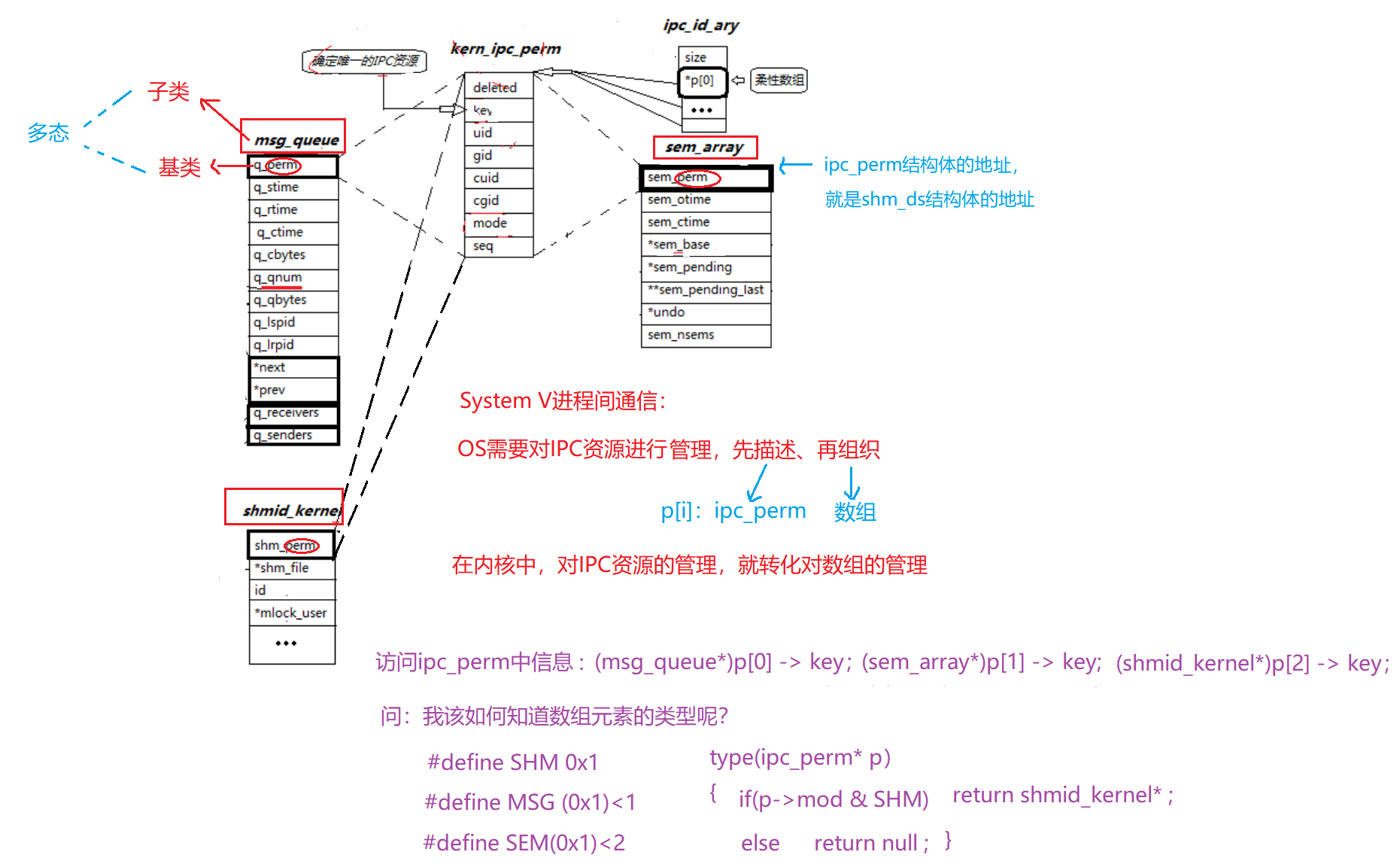
一、IPC资源的管理
-
在OS中,通过维护一个数组来管理不同的IPC资源,如:共享内存、消息队列、信号量。
-
每种IPC资源都有其特定的数据结构(如:shmid_ds、msqid_ds、semid_ds等),这些数据结构的第一个成员都是以ipc_perm结构体作为开头。
二、多态实现
-
ipc_perm包含了IPC资源共有的属性,内核层面上称为kern_ipc_perm、用户层面上称为ipc_perm,所以可以将ipc_perm视为基类,不同的IPC资源数据结构(如:shmid_ds、msqid_ds等)作为ipc_perm的子类,扩展了额外的特定于该资源的属性。
-
通过将数组的元素类型定为ipc_perm*,OS就可以实现对不同IPC资源的统一管理和访问。当需要访问特定资源的额外属性时,可以通过强制类型转化来实现,如:(shmid_ds*)array[i]->额外属性。
三、资源的标识和访问
-
每个IPC资源在创建时都会分配唯一的标识符(如:shmid、msgid等),这个标识符实际上就是数组的下标。
-
标识符的增长是线性递增的,即使资源被释放,新的资源也会获得比上一个资源更大的标识符,为了避免数组越界,OS提供了回绕机制。
6. 信号量
6.1. 储备知识
- 在多执行流场景下,共享资源可能同时被多个执行流尝试访问、修改,如果不加以保护,这可能会导致数据不一致、资源竞争和死锁等问题。
常见的保护机制主要包括同步和互斥机制。同步机制确保执行流按照预定的顺序进行交互,互斥机制确保共享资源在任何一个时刻只能被一个执行流访问。
-
临界资源:被保护起来且任何时刻只允许一个执行流访问的公共资源,称为临界资源。eg:一个全局变量在多个线程同时读写时,如果不加以保护,可能会出现数据错误,这个全局变量就称为临界资源。
-
临界区:访问临界资源的代码称为临界区。 非临界区:除临界区之外的代码称为非临界区。
程序员需要特别关注和保护临界区,以确保在任何时刻只有一个执行流,能够进入临界区访问临界资源,以防止其他执行流同时访问。
-
保护临界资源,本质是保护临界区,确保在任何时刻只有一个执行流能够访问临界区,从而保护数据的一致性和正确性。
-
原子性:一个操作被认为是原子的,此操作要么完全执行成功,要么完全不执行,不存在中间状态,即:此操作不可分割(一旦开始执行,它必须连续执行完成,中途不能被打断),不能被其他执行流中断。
在并发编程中,原子性用于确保多个线程或进程对共享资源进行操作,不会导致数据不一致、不确定的结果。
6.2. 原理与概念
信号量在进程间通信IPC中扮演着重要的角色,尽管它的目的不是直接传递字符串或数据内容,而是通过维护一个计数器来实现对共享资源的协同访问。
- 信号量:是一种用于控制多个进程对共享资源访问的同步机制,主要用于解决互斥和同步问题,确保在任何时候只有有限数量的进程可以访问特定的资源。
- 本质是一个整形计数器,表示可用的临界资源数目。
- 当进程或线程需要访问临界资源时:都必须先申请信号量 -> 再进行访问 -> 最后释放信号量。
- 信号量核心操作:PV操作,是原子性操作,既可以改变信号量值,又可以用于保护信号量这个共享资源,确保多个进程能够正确地协调对其他共享资源的访问,实现对进程间同步和互斥的控制。
P操作:用于申请临界资源。如果信号量值>0,则将其-1,并允许进程继续执行;如果信号量值=0,则进程被阻塞,等待其他进程释放资源。
V操作:用于释放临界资源。将信号量值+1。
相关文章:
【Linux】解锁进程间通信奥秘,高效资源共享的实战技巧
管道、共享内存、消息队列、信号量 1. 进程间通信1.1. 目的1.2. 概念和本质1.3. 分类 2. 管道2.1 概念2.2. 4种情况2.3. 4种特性2.4. 匿名管道2.4.1. 原理2.4.2. 概念2.4.3. 创建 — pipe()2.4.4. 应用场景 — 进程池 2.5. 命名管道2.5.1. 概念和原理2.5.2. 创建 — mkfifo()2.…...

O1 Nano:OpenAI O1模型系列的简化开源版本
概览 O1 Nano 是一个开源项目,它实现了 OpenAI O1 模型系列的简化版本。O1 模型是一个高级语言模型,它在训练和推理过程中整合了链式思维和强化学习。这个实现版本,称为 O1-nano,专注于解决算术问题,以展示模型的能力。…...

浅谈人工智能之Llama3微调后使用cmmlu评估
浅谈人工智能之Llama3微调后使用cmmlu评估 引言 随着自然语言处理(NLP)技术的发展,各类语言模型如雨后春笋般涌现。其中,Llama3作为一个创新的深度学习模型,已经在多个NLP任务中展示了其强大的能力。然而,…...

为什么需要MQ?MQ具有哪些作用?你用过哪些MQ产品?请结合过往的项目经验谈谈具体是怎么用的?
需要使用MQ的主要原因包括以下几个方面: 异步处理:在分布式系统中,使用MQ可以实现异步处理,提高系统的响应速度和吞吐量。例如,在用户注册时,传统的做法是串行或并行处理发送邮件和短信,这…...

Flutter项目打包ios, Xcode 发布报错 Module‘flutter barcode_scanner‘not found
报错图片 背景 flutter 开发的 apple app 需要发布新版本,但是最后一哆嗦碰到个报错,这个小问题卡住了我一天,之间的埪就不说了,直接说我是怎么解决的,满满干货 思路 这个报错 涉及到 flutter_barcode_scanner; 所…...
)
RWSENodeEncoder, KER_DIM_PE(lrgb文件中的encoders文件中的kernel.py)
该代码实现了一个基于核的节点编码器 KernelPENodeEncoder,用于在图神经网络中将特定的核函数编码(例如随机游走结构编码 RWSE)与节点特征相结合。通过将预先计算的核统计信息(如 RWSE 等)与原始节点特征结合,该编码器可以帮助模型捕捉图中节点的结构信息。该代码还定义了…...

技术文档:基于微信朋友圈的自动点赞工具开发
概述 该工具是一款基于 Windows 平台的自动化操作工具,通过模拟人工点击,实现微信朋友圈的自动点赞。主要适用于需频繁维护客户关系的用户群体,避免手动重复操作,提高用户的互动效率。 官方地址: aisisoft.top 一、开发背景与技术…...

kubernetes_pods资源清单及常用命令
示例: apiVersion: v1 kind: Pod metadata:name: nginx-podnamespace: defaultlabels:app: nginx spec:containers:- name: nginx-containerimage: nginx:1.21ports:- containerPort: 80多个容器运行示例 apiVersion: v1 kind: Pod metadata:name: linux85-nginx-…...

科目二侧方位停车全流程
科目二侧方位停车是驾考中的重要项目,主要评估驾驶员将车辆准确停放在道路右侧停车位的能力。以下是对科目二侧方位停车的详细解析: 请点击输入图片描述(最多18字) 一、考试要求 车辆需在库前右侧稳定停车,随后一次性…...

2024源鲁杯CTF网络安全技能大赛题解-Round2
排名 欢迎关注公众号【Real返璞归真】不定时更新网络安全相关技术文章: 公众号回复【2024源鲁杯】获取全部Writeup(pdf版)和附件下载地址。(Round1-Round3) Misc Trace 只能说题出的太恶心了,首先获得一…...

10.24学习
1.const 在编程中, const 关键字通常用来定义一个常量。常量是程序运行期间其值不能被改变的变量。使用 const 可以提高代码的可读性和可靠性,因为它可以防止程序中意外修改这些值。 不同编程语言中 const 的用法可能略有不同,以下是一…...

社交媒体与客户服务:新时代的沟通桥梁
在数字化时代,社交媒体已成为人们日常生活中不可或缺的一部分,它不仅改变了人们的沟通方式,也深刻影响着企业的客户服务模式。从传统的电话、邮件到如今的社交媒体平台,客户服务的渠道正在经历一场前所未有的变革。社交媒体以其即…...

设置虚拟机与windows间的共享文件夹
在 VMware Workstation 或 VMware Fusion 中设置共享文件夹的具体步骤如下: 1. 启用共享文件夹 对于 VMware Workstation 打开 VMware Workstation: 启动 VMware Workstation,找到你要设置共享文件夹的虚拟机。 设置虚拟机: 选…...
微信小程序性能优化 ==== 合理使用 setData 纯数据字段
目录 1. setData 的流程 2. 数据通信 3. 使用建议 3.1 data 应只包括渲染相关的数据 3.2 控制 setData 的频率 3.3 选择合适的 setData 范围 3.4 setData 应只传发生变化的数据 3.5 控制后台态页面的 setData 纯数据字段 组件数据中的纯数据字段 组件属性中的纯数据…...
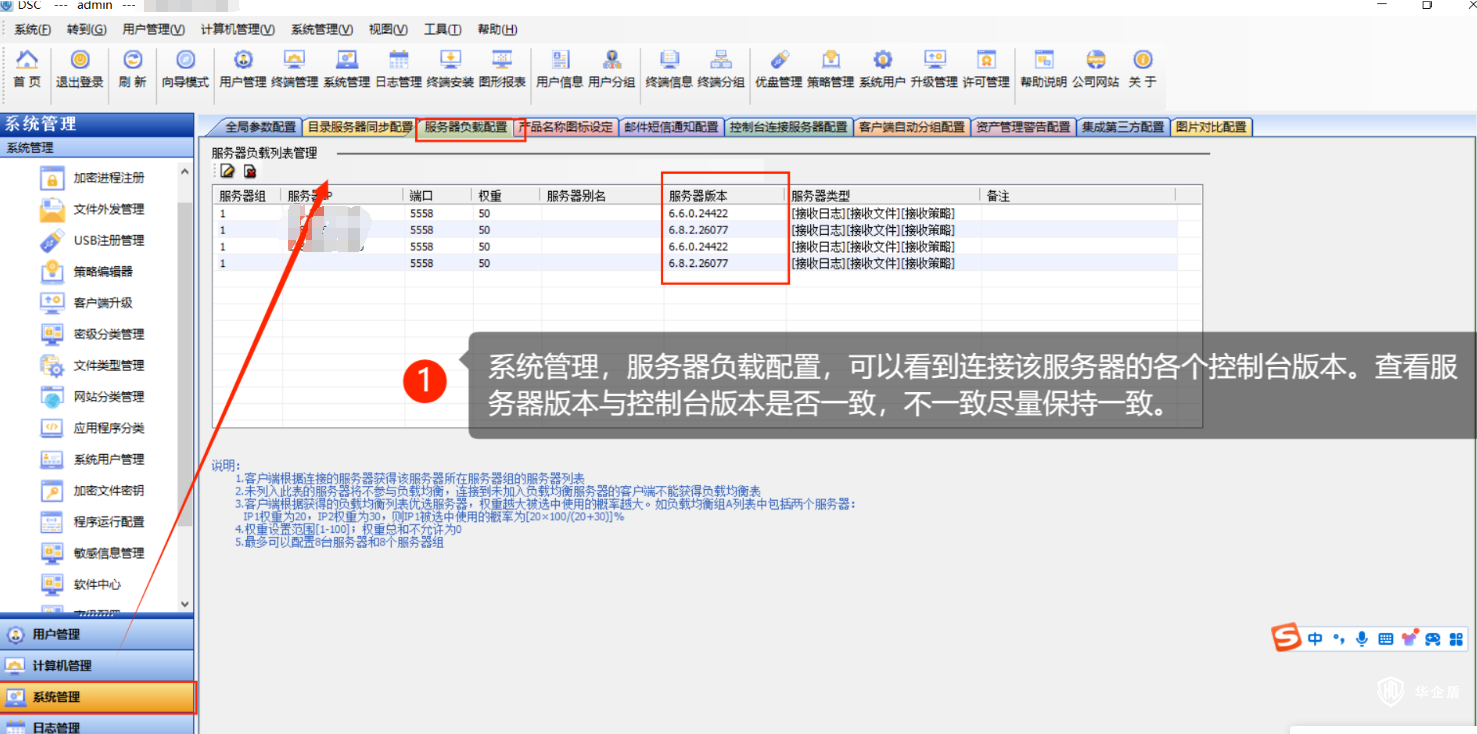
【加密系统】华企盾DSC服务台提示:请升级服务器,否则可能导致客户端退回到旧服务器的版本
华企盾DSC服务台提示:请升级服务器,否则可能导致客户端退回到旧服务器的版本 产生的原因:控制台版本比服务器高导致控制台出现报错 解决方案 方法:将控制台回退到原来的使用版本,在控制台负载均衡查看连接该服务器各个…...

直连南非,服务全球,司库直联再进一步
yonyou 在全球化经济背景下,中国企业不断加快“走出去”的步伐,寻求更广阔的发展空间。作为非洲大陆经济最发达的国家之一,南非以其丰富的自然资源、完善的金融体系和多元化的市场,成为中国企业海外投资与合作的热门目的地。 作为…...

【spring】从spring是如何避免并发下获取不完整的bean引发的思考 什么是双重检查锁 什么是java内存模型
本文将通过简述spring是如何避免并发下获取不完整的bean,延伸出双重检查锁、volatile、JMM的概念,将这些知识点都串联起来; 若发现错误,非常欢迎在评论区指出;csdn博主:孟秋与你 文章目录 双重检查锁(Doubl…...

【计算机网络一】网络学习前置知识
目录 网络中必备概念 1.什么是局域网与广域网? 2.什么是IP地址 3.什么是端口号 4.什么是协议 5.OSI七层模型 6.TCP/IP四层模型 网络中必备概念 本篇文章旨在分享一些计算机网络中的常见概念,对于初学者或者准备学习计算机网络的人会有帮助。 1.什么…...

nuScenes数据集使用的相机的外参和内参
因为需要用不同数据集测试对比效果,而一般的模型代码里实现的检测结果可视化都是使用open3d的Visualizer在点云上画的3d框,展示出来的可视化效果很差,可能是偷懒,没有实现将检测结果投影到各相机的图像上,所以检测效果…...

数据结构与算法:贪心算法与应用场景
目录 11.1 贪心算法的原理 11.2 经典贪心问题 11.3 贪心算法在图中的应用 11.4 贪心算法的优化与扩展 总结 数据结构与算法:贪心算法与应用场景 贪心算法是一种通过选择当前最佳解来构造整体最优解的算法策略。贪心算法在很多实际问题中都取得了良好的效果&am…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...
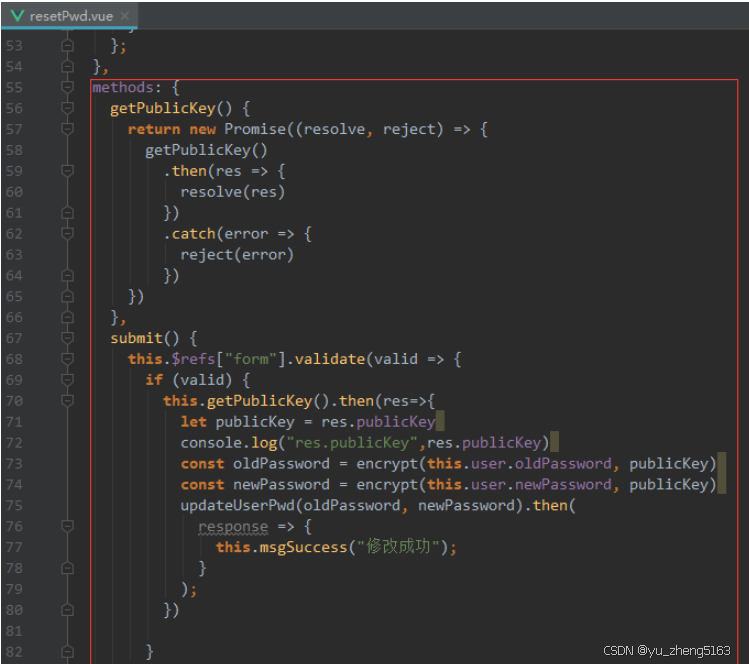
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...
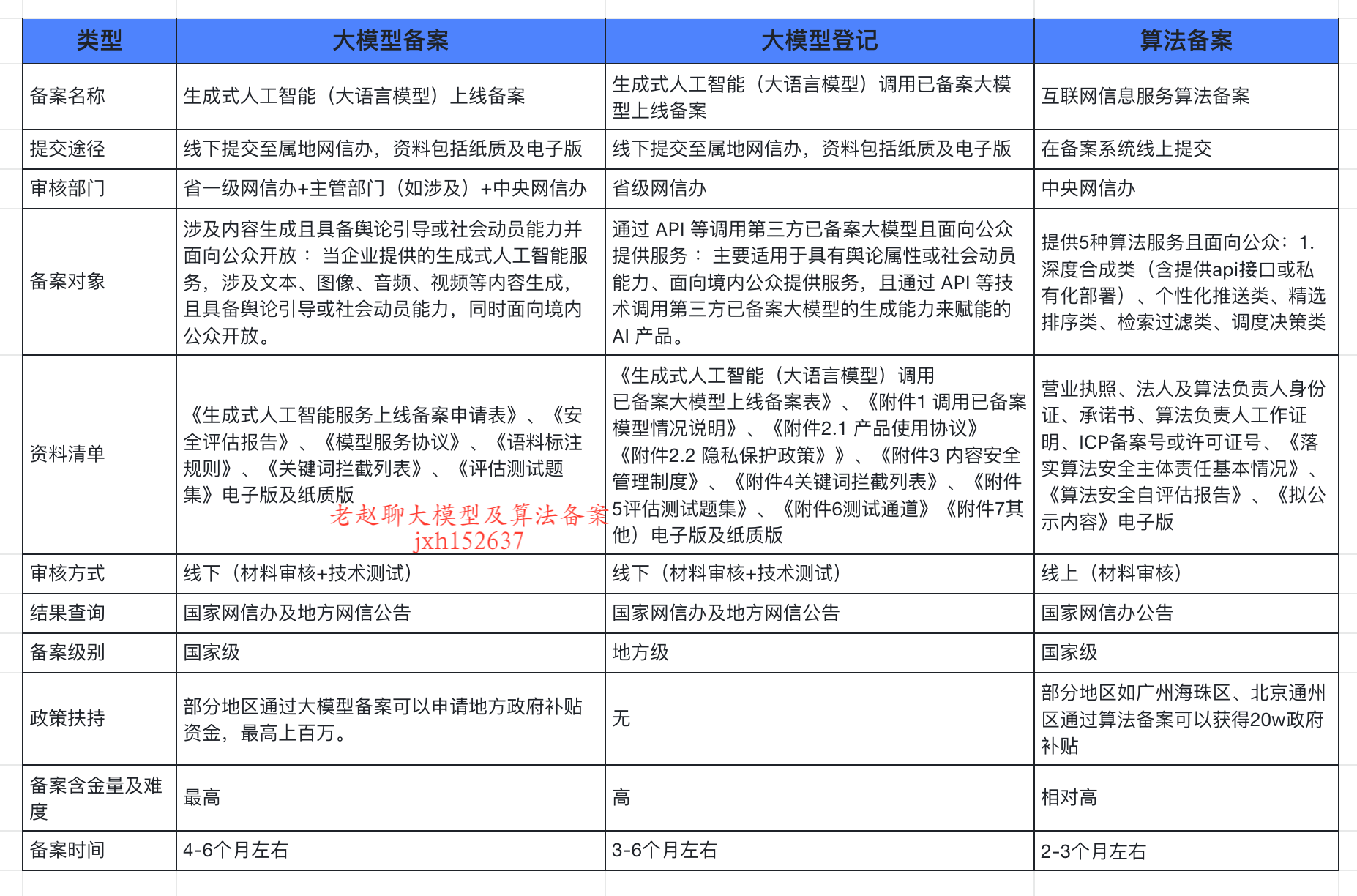
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...