导出BERT句子模型为ONNX并推理
在深度学习中,将模型导出为ONNX(Open Neural Network Exchange)格式并利用ONNX进行推理是提高推理速度和模型兼容性的一种常见做法。本文将介绍如何将BERT句子模型导出为ONNX格式,并使用ONNX Runtime进行推理,具体以中文文本处理为例。
1. 什么是ONNX?
ONNX 是一种开放的神经网络交换格式,旨在促进深度学习模型在不同平台和工具之间的共享和移植。它支持包括PyTorch、TensorFlow等多种主流框架,可以通过ONNX Runtime库高效推理。通过将模型转换为ONNX格式,我们可以获得跨平台部署的优势,并利用ONNX Runtime加速推理过程。
2. 准备工作
在导出和推理之前,需要安装以下库:
pip install torch transformers onnx onnxruntime
3. 导出BERT句子模型为ONNX
首先,我们将使用HuggingFace的transformers库加载一个预训练的BERT句子模型(text2vec-base-chinese),然后将其导出为ONNX格式。以下是导出模型的步骤和代码:
3.1 导出模型的代码
import torch
from transformers import BertTokenizer, BertModel# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('shibing624/text2vec-base-chinese')
model = BertModel.from_pretrained('shibing624/text2vec-base-chinese')# 读取要处理的句子
with open("corpus/words_nlu.txt", 'rt', encoding='utf-8') as f:nlu_words = [line.strip() for line in f.readlines()]
nlu_words.insert(0, "摄像头打开一下") # 插入要比较的句子# 对句子进行编码
encoded_input = tokenizer(nlu_words, padding=True, truncation=True, return_tensors='pt')# 设置ONNX模型的保存路径
onnx_model_path = "text2vec-base-chinese.onnx"
model.eval()# 导出模型为ONNX格式
with torch.no_grad():torch.onnx.export(model,(encoded_input['input_ids'], encoded_input['attention_mask']),onnx_model_path,input_names=['input_ids', 'attention_mask'],output_names=['last_hidden_state'],opset_version=14,dynamic_axes={'input_ids': {0: 'batch_size', 1: 'sequence_length'},'attention_mask': {0: 'batch_size', 1: 'sequence_length'},'last_hidden_state': {0: 'batch_size', 1: 'sequence_length'}})
print(f"ONNX模型已导出到 {onnx_model_path}")
在这段代码中,我们将text2vec-base-chinese模型导出为ONNX格式,指定了输入和输出的名称,并使用了动态轴设置(如批大小和序列长度),这样可以处理不同长度的句子。
4. 使用ONNX进行推理
导出模型后,我们可以使用ONNX Runtime进行推理。以下是基于ONNX的推理代码。该代码实现了对输入文本进行预处理、调用ONNX模型进行推理、以及对模型输出进行均值池化处理。
4.1 ONNX推理代码
import numpy as np
from onnxruntime import InferenceSessionclass PIPE_NLU:def __init__(self, model_path="text2vec-base-chinese.onnx", vocab_path="vocab.txt") -> None:self.model_path = model_pathself.vocab_path = vocab_pathself.vocab = self.load_vocab(vocab_path)self.onnx_session = InferenceSession(model_path)print("成功加载NLU解码器")def load_vocab(self, vocab_path):"""加载BERT词汇表"""vocab = {}with open(vocab_path, 'r', encoding='utf-8') as f:for idx, line in enumerate(f):token = line.strip()vocab[token] = idxreturn vocabdef tokenize(self, text):"""将文本分词为BERT的input_ids"""tokens = ['[CLS]']for char in text:if char in self.vocab:tokens.append(char)else:tokens.append('[UNK]')tokens.append('[SEP]')input_ids = [self.vocab[token] if token in self.vocab else self.vocab['[UNK]'] for token in tokens]return input_idsdef preprocess(self, texts, max_length=128):"""对输入文本进行预处理"""input_ids_list = []attention_mask_list = []for text in texts:input_ids = self.tokenize(text)if len(input_ids) > max_length:input_ids = input_ids[:max_length]else:input_ids += [0] * (max_length - len(input_ids))attention_mask = [1 if idx != 0 else 0 for idx in input_ids]input_ids_list.append(input_ids)attention_mask_list.append(attention_mask)inputs = {'input_ids': np.array(input_ids_list, dtype=np.int64),'attention_mask': np.array(attention_mask_list, dtype=np.int64)}return inputsdef mean_pooling_numpy(self, model_output, attention_mask):"""对模型输出进行均值池化"""token_embeddings = model_outputinput_mask_expanded = np.expand_dims(attention_mask, -1).astype(float)return np.sum(token_embeddings * input_mask_expanded, axis=1) / np.clip(np.sum(input_mask_expanded, axis=1), a_min=1e-9, a_max=None)def compute_embeddings(self, texts):"""计算输入文本的句子嵌入"""onnx_inputs = self.preprocess(texts)onnx_outputs = self.onnx_session.run(None, onnx_inputs)last_hidden_state = onnx_outputs[0]sentence_embeddings = self.mean_pooling_numpy(last_hidden_state, onnx_inputs['attention_mask'])sentence_embeddings = sentence_embeddings / np.linalg.norm(sentence_embeddings, axis=1, keepdims=True)return sentence_embeddings
4.2 推理流程
- 加载ONNX模型:通过
InferenceSession加载ONNX模型。 - 加载词汇表:读取BERT的词汇表,用于将输入文本转化为模型可接受的
input_ids格式。 - 文本预处理:将输入的文本进行分词、截断或填充为固定长度,并生成相应的注意力掩码
attention_mask。 - 模型推理:通过ONNX Runtime调用模型,获取句子的最后隐藏状态输出。
- 均值池化:对最后的隐藏状态进行均值池化,计算出句子的嵌入向量。
- 归一化嵌入:将句子嵌入向量进行归一化,使得向量长度为1。
5. 总结
通过将BERT模型导出为ONNX并使用ONNX Runtime进行推理,我们可以大幅度提升推理速度,同时保持了高精度的句子嵌入计算。在实际应用中,ONNX Runtime的跨平台特性和高性能表现使其成为模型部署和推理的理想选择。
使用上述步骤,您可以轻松将BERT句子模型应用到各种自然语言处理任务中,如语义相似度计算、文本分类和句子嵌入等。
相关文章:

导出BERT句子模型为ONNX并推理
在深度学习中,将模型导出为ONNX(Open Neural Network Exchange)格式并利用ONNX进行推理是提高推理速度和模型兼容性的一种常见做法。本文将介绍如何将BERT句子模型导出为ONNX格式,并使用ONNX Runtime进行推理,具体以中…...

Unity Apple Vision Pro 自定义手势识别交互
Vision Pro 是可以使用Unity 提供的XR Hand SDK,可通过XR Hand制作自定义手势识别,通过识别出不同的手势做自定义交互 效果预览 在VisionPro中看VisionPro|手势交互|自定义手势识别 Unity Vision Pro 中文课堂教程地址: Unity3D Vision Pro 开发教程【…...

【Javaee】网络原理—TCP协议的核心机制
前言 TCP/IP五层协议是互联网中的主流模型,为网络通信提供了一个稳固的框架。 主要包含了应用层,传输层,网络层,数据链路层,物理层。 本篇主要介绍传输层的TCP协议的核心机制 一. 确认应答(ack…...

Unity插件-Intense TPS 讲解
目录 关于TPS 打开场景:WeaponTest.unity, 只要把这些枪点,打开(默认隐藏,不知道为何), 一开始不能运行如何修复 总结 关于TPS 个人不是TPS,FPS的射击游戏爱好者, 不过感觉这个枪感&…...

【p2p、分布式,区块链笔记 Blockchain】truffle001 以太坊开发框架truffle初步实践
以下是通过truffle框架将智能合约部署到Ganache的步骤 Truffle简介环境准备:智能合约 编写 & 编译部署合约本地服务器ganache配置网络配置部署合约: 运行Truffle迁移(部署):与智能合约交互: 以下是通过truffle框架将智能合约部署到Ganach…...
网站被浏览器提示“不安全”,如何快速解决
当网站被浏览器提示“不安全”时,这通常意味着网站存在某些安全隐患,需要立即采取措施进行解决。 一、具体原因如下: 1.如果网站使用的是HTTP协议,应立即升级HTTPS。HTTPS通过使用SSL证书加密来保护数据传输,提高了网…...

java -jar启动 报错: Error: Unable to access jarfile
是JDK版本不对,即运行项目所需JDK与本机所装JDK版本不同 解决方法: 修改JDK版本即可。 jarfile 其后的路径不对 解决方法 修改正确的路径 将绝对路径修改为相对路径或者将相对路径修改为绝对路径,尝试一下...

Servlet(三)-------Cookie和session
一.Cookie和Session Cookie和Session都是用于在Web应用中跟踪用户状态的技术。Cookie是存储在用户浏览器中的小文本文件,由服务器发送给浏览器。当用户再次访问同一网站时,浏览器会把Cookie信息发送回服务器。例如,网站可以利用Cookie记住用…...
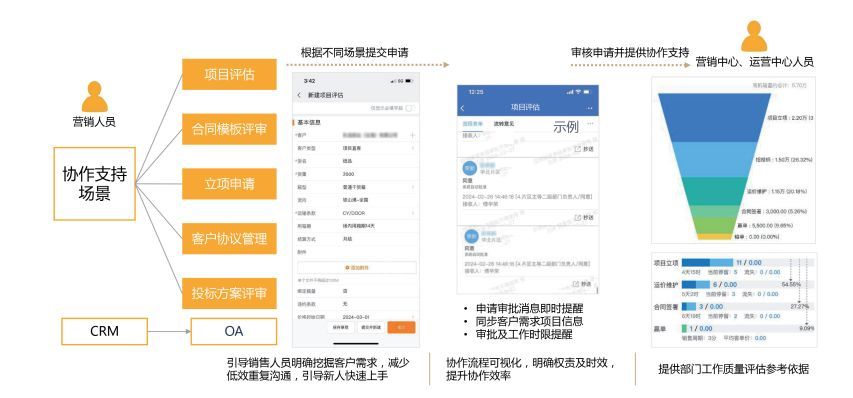
最新物流行业CRM系统应用数字化解决方案
因势利导 ——全球化物流的挑战与机遇 在全球经济一体化与互联网技术快速发展的双重驱动下,物流行业正经历着前所未有的变革时期。这一变革不仅影响 着行业的发展模式,还对运营效率和客户体验提出了新的要求。 随着市场需求的不断演变,物流行业已呈现出多元化和专业 化并行的发…...

[deadlock]死锁导致的设备登录无响应问题
[deadlock]死锁导致的设备登录无响应问题 一、问题现象二、初步观察三、继续深挖查看netlink相关信息查看warnd进程栈 四、再接再厉查看warnd 用户栈 后记 一、问题现象 实验室一台压力测试设备突然无法登录,无论web页面,ssh或者telnet登录,…...

2024年10月21日计算机网络,乌蒙第一部分
【互联网数据传输原理 |OSI七层网络参考模型】 https://www.bilibili.com/video/BV1EU4y1v7ju/?share_sourcecopy_web&vd_source476fcb3b552dae37b7e82015a682a972 mac地址相当于是名字,ip地址相当于是住址,端口相当于是发送的东西拿什…...

ESlint代码规范
这里写目录标题 ESlint代码规范解决代码规范错误 ESlint代码规范 代码规范:一套写代码的约定规则。例如:“赋值符号左右是否需要空格” “一行代码结束是否要加分号” JavaScript Standard Style规范说明:https://standardjs.com/rules-zhc…...

【Vue.js设计与实现】第三篇第11章:渲染器-快速 Diff 算法-阅读笔记
文章目录 11.1 相同的前置元素和后置元素11.2 判断是否需要进行 DOM 移动操作11.3 如何移动元素11.4 总结 系列目录:【Vue.js设计与实现】阅读笔记目录 非常快的Diff算法。 11.1 相同的前置元素和后置元素 不同于简单 Diff 算法和双端 Diff 算法,…...

材质变体 PSO学习笔记
学习笔记 参考各路知乎大佬文章 首先是对变体的基本认知 概括就是变体是指根据引擎中上层编写(UnityShaderLab/UE连连看)中的各种defines情况,根据不同平台编译成的底层shader,OpenGL-glsl/DX(9-11)-dxbc DX12-dxil/Vulkan-spirv,是打到游…...

2024年【烟花爆竹储存】考试及烟花爆竹储存复审模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 烟花爆竹储存考试参考答案及烟花爆竹储存考试试题解析是安全生产模拟考试一点通题库老师及烟花爆竹储存操作证已考过的学员汇总,相对有效帮助烟花爆竹储存复审模拟考试学员顺利通过考试。 1、【单选题】( …...

文件夹操作
文件夹操作 opendir closedir readdir write(fd,buf,strlen(buf)); return 0; } 作用 : 打开目录 opendir 所有头文件 : #include <sys/types.h> #include <dirent.h> 函数 : DIR *opendir(const char *name); 参数: name :目…...

如何制作一台自己想要的无人机?无人机改装调试技术详解
制作一台符合个人需求的无人机并对其进行改装调试,是一个既具挑战性又充满乐趣的过程。以下是从设计、选购材料、组装、调试到改装的详细步骤: 一、明确需求与设计 1. 明确用途与性能要求: 确定无人机的使用目的,如航拍、比赛、…...

Linux -- 进程间通信、初识匿名管道
目录 进程间通信 什么是进程间通信 进程间通信的一般规律 前言: 管道 代码预准备: 如何创建管道 -- pipe 函数 参数: 返回值: wait 函数 参数: 验证管道的运行: 源文件 test.c : m…...

网站的SSL证书快到期了怎么办?怎么续签?
网站的SSL证书即将到期时,需要续签一个新的证书以保持网站的安全性和信任度。以下是续签SSL证书的一般步骤: 1. 选择证书提供商 如果您之前使用的是免费证书,您可以选择继续使用同一提供商的免费证书服务进行续签。如果您需要更高级别的证书…...

解決爬蟲代理連接的方法
爬蟲在運行過程中常常會遇到代理連接的問題,這可能導致數據抓取的效率降低甚至失敗。 常見的代理連接問題 代理IP失效:這是最常見的問題之一。有些代理IP可能在使用一段時間後失效,導致連接失敗。 連接超時:由於網路不穩定或代…...

intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现
intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现 1. 测试背景与目的 在当今AI技术快速发展的背景下,代码生成已成为大语言模型的重要应用场景之一。本次测试旨在对比intv_ai_mk11与Qwen2.5两款模型在相同Prompt下的代码生成…...

Qwen3-TTS快速部署教程:一键启动Web服务,3分钟开始声音克隆
Qwen3-TTS快速部署教程:一键启动Web服务,3分钟开始声音克隆 1. 为什么选择Qwen3-TTS进行语音克隆 想象一下这样的场景:你需要为海外客户录制多语言产品介绍,但雇佣专业配音演员成本高昂;或者想为自己的视频内容添加个…...

Venera漫画阅读器:跨平台智能阅读的终极指南
Venera漫画阅读器:跨平台智能阅读的终极指南 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 想要在Android、iOS、Windows、macOS和Linux上享受无缝的漫画阅读体验吗?Venera漫画阅读器正是您需要的终极…...

XHS-Downloader:构建高效采集流程的无水印内容批量管理方案
XHS-Downloader:构建高效采集流程的无水印内容批量管理方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...

深度探索:开源工具OpenCore Legacy Patcher技术揭秘与完整指南
深度探索:开源工具OpenCore Legacy Patcher技术揭秘与完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 随着苹果系统持续演进,…...

多平台资源嗅探与下载工具:解决网络资源获取难题的技术方案
多平台资源嗅探与下载工具:解决网络资源获取难题的技术方案 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gitcod…...
)
UniApp跨平台开发入门:用现有Vue代码快速生成小程序/App(2023最新版)
UniApp跨平台开发实战:2023年Vue代码高效迁移指南 移动互联网时代,开发者常面临一个核心挑战:如何用最小成本将Web应用扩展到移动端。如果你手头已有成熟的Vue项目,UniApp可能是最经济的跨平台解决方案——它允许你复用80%以上的现…...

别再让单片机‘死机’!手把手教你用TPV6823设计一个靠谱的硬件看门狗电路
嵌入式系统守护者:TPV6823硬件看门狗电路实战指南 当电机控制板在工厂车间突然停止响应,或是工业传感器在雷雨天气后持续报错,许多工程师的第一反应往往是"程序又跑飞了"。这种嵌入式系统运行失控的现象,就像一台无人看…...

传统信号处理与AI结合:FUTURE POLICE模型前端预处理技术详解
传统信号处理与AI结合:FUTURE POLICE模型前端预处理技术详解 最近在做一个语音相关的AI项目,发现直接把麦克风录到的原始音频丢给模型,效果总是不太理想。背景的键盘声、远处的谈话声,甚至是空调的嗡嗡声,都会让模型的…...

COMSOL 薄膜型声学超材料是利用薄膜结构单元在声波激励下的反共振特性,实现高于质量隔声定律...
COMSOL 薄膜型声学超材料是利用薄膜结构单元在声波激励下的反共振特性,实现高于质量隔声定律的隔声 STL隔声量 隔声系数 消声系数【1】薄膜材料本身需有较大弹性,且在低厚度情况下有良好的抗拉压性能,综合选取硅橡胶材料; 【2】附…...