Go 标准库
本篇内容是根据2016年9月份The Go Standard Library音频录制内容的整理与翻译,
BoltDB 的创建者 Ben Johnson 参加了节目,讨论 NoSQL 与 SQL 数据库、两者之间的权衡以及选择其中之一。我们还讨论了 Ben 的数据秘密生活项目,可视化数据结构,并回顾了他的 Go 标准库博客文章系列Go Walkthrough的动机和计划。
过程中为符合中文惯用表达有适当删改, 版权归原作者所有.
Erik St. Martin: 我们回来了,这是 GoTime 播客的第 15 期。今天的节目里有我自己,Erik St. Martin,Brian Ketelsen 也在这里……
Brian Ketelsen: 大家好。
Erik St. Martin: 还有 Carlisia Campos
Carlisia Thompson: 嗨。
Erik St. Martin: 今天我们的特别嘉宾在行业内非常有名,推出了很多有趣的项目和文章。请欢迎 Ben Johnson。
Ben Johnson: 大家好。感谢邀请我来。
Brian Ketelsen: Erik,我真的是超级激动。我必须告诉你。
Erik St. Martin: 我也是,我的意思是……
Brian Ketelsen: Ben 是 Go 社区的中流砥柱,是世界上最聪明的人之一。可能也是最友好的人---也许他和 Matt Holt 是并列的。今天的节目一定很精彩。
Erik St. Martin: 我是说……
Brian Ketelsen: 真的。
Erik St. Martin: 我记得有一件事---那是好多年前了---他曾经说:“我要实现 Raft 协议。” [笑声]
Ben Johnson: 那可不一定是个好主意。
Erik St. Martin: 但这是个学习的过程,对吧?
Ben Johnson: 绝对是一次学习体验。
Erik St. Martin: Brian 可以告诉你,我对数据库也上瘾。
Ben Johnson: 数据库确实很有趣,真的很有趣。
Erik St. Martin: 所以我想我们可以从一些较新的内容开始……首先,我想谈谈你最近发布的系列文章和教程。
Ben Johnson: 哦,当然。
Brian Ketelsen: 哇哦,太棒了。
Erik St. Martin: 是的。
Ben Johnson: 这真是一次很酷的体验。我本来想详细解释一些东西。我经常使用标准库。很多人曾经为此取笑我,因为我倾向于不使用他们的私人库(即使有时我应该用),而是选用标准库。所以我以为我已经了解大部分内容了,但在这个过程中我也学到了很多。比如 Unicode 中的大小写折叠、IO 包、bytes 包和 strings 包中的一些小细节,都是你意想不到的东西,即使它们看起来是最简单的部分。
Erik St. Martin: 我觉得这就是制作内容的有趣之处,对吧?无论是准备演讲、写文章、写书还是制作教学视频,你总是希望确保自己不会说错话,因此你会做更多的研究,甚至是那些你觉得自己已经很了解的主题,这也迫使你学到新的东西。
Ben Johnson: 是的,这也让你意识到自己对一个话题的无知之处。这的确可以帮助你成长。
Brian Ketelsen: 我真的很喜欢这些文章的深度,太棒了。我不认为我读过比这更好的博客文章。今天我说话不太利索 [笑声]。我们应该重新开始这期节目,换一副更好的嘴。
我真的很喜欢这些文章的知识深度。它写得不会让我感觉像个傻瓜,语气和技术细节都拿捏得恰到好处。我非常喜欢这个系列。
Ben Johnson: 哦,谢谢。
Erik St. Martin: 我们会把这些文章的链接放在节目笔记里,但我们现在也会把它们发布到 GoTimeFM 的 Slack 频道上,供大家查看,如果有人还没有看到这些文章的话。
Carlisia Thompson: 这些内容非常经典,可能永远都会有用。我们只需要不时地重新推荐这些文章。
Ben Johnson: 标准库的好处是它几乎不会改变。他们会修复一些漏洞,让它更快,但你不需要去重新审视它。除非有一天 Go 出现 2.0 版本。
Brian Ketelsen: 永远不会有。
Ben Johnson: 是的,我同意。
Erik St. Martin: 我觉得我们需要更多类似的内容,深入解析标准库并展示使用案例。你可以浏览 Go Docs,或者去 Go 的官网查阅这些东西,但那并不会真正展示……我们之前讨论过 Sourcegraph 工具,对吧?当你开始使用某些东西时,能够看到这些功能的使用实例真的很有帮助。比如 Bill Kennedy 前几天发了一篇关于读取字节流的文章,还有你最近的文章,讲的是如何使用 io.Reader、Writer、TeeReader 和 MultiWriter 等。它真的可以让人意识到这些函数和包的存在,很多人可能之前都没有注意到。
译者注:
—注释开始—
在 Go 语言中,io.Reader 和 io.Writer 是两个非常重要的接口,广泛用于处理 I/O 操作。TeeReader 和 MultiWriter 是 Go 标准库提供的工具,分别用于将读取的数据进行复制和将写入的数据分发到多个目的地。下面我们详细介绍它们的使用方法。
1. io.Reader 和 io.Writer
io.Reader 接口
io.Reader 是一个接口,定义了一个读取数据的方法:
type Reader interface {Read(p []byte) (n int, err error)
}
p []byte: 接收读取数据的缓冲区。n int: 实际读取的字节数。err error: 读取过程中可能遇到的错误,如果读到文件末尾通常会返回io.EOF。
io.Writer 接口
io.Writer 是一个接口,定义了一个写入数据的方法:
type Writer interface {Write(p []byte) (n int, err error)
}
p []byte: 要写入的数据。n int: 实际写入的字节数。err error: 写入过程中可能遇到的错误。
2. io.TeeReader
io.TeeReader 是一个有用的工具,它允许你在读取数据的同时,将读取的数据写入另一个 io.Writer。它的典型应用场景是当你需要将数据读取并传递给某个地方,同时还想记录或检查读取的数据。
使用 io.TeeReader
package mainimport ("fmt""io""os""strings"
)func main() {// 创建一个字符串 readerreader := strings.NewReader("Hello, Go!")// 创建一个 TeeReader,它会将读取的数据同时写入标准输出teeReader := io.TeeReader(reader, os.Stdout)// 缓冲区buf := make([]byte, 8)// 从 TeeReader 中读取数据,数据会被输出到标准输出for {n, err := teeReader.Read(buf)if err == io.EOF {break}if err != nil {fmt.Println("Error:", err)return}fmt.Printf("\nRead %d bytes: %s\n", n, string(buf[:n]))}
}
输出:
Hello, Go!
Read 8 bytes: Hello, G
Read 3 bytes: o!
在这个例子中,TeeReader 将读取的数据既传递给程序处理,也将其写入标准输出。
3. io.MultiWriter
io.MultiWriter 允许你将写入的数据同时写入多个 io.Writer。例如,你可以将数据同时写入文件和标准输出。
使用 io.MultiWriter
package mainimport ("io""os"
)func main() {// 打开一个文件file, err := os.Create("output.txt")if err != nil {panic(err)}defer file.Close()// 创建一个 MultiWriter,将数据同时写入标准输出和文件multiWriter := io.MultiWriter(os.Stdout, file)// 将数据写入 MultiWriterdata := []byte("Hello, Go and File!")_, err = multiWriter.Write(data)if err != nil {panic(err)}
}
输出:
Hello, Go and File!
同时,output.txt 文件也会包含相同的内容。
4. 综合使用示例
下面是一个综合的示例,使用 TeeReader 和 MultiWriter:
package mainimport ("fmt""io""os""strings"
)func main() {// 创建一个字符串 readerreader := strings.NewReader("Hello, Go!")// 打开一个文件用于写入file, err := os.Create("output.txt")if err != nil {panic(err)}defer file.Close()// 创建一个 MultiWriter,将数据写入标准输出和文件multiWriter := io.MultiWriter(os.Stdout, file)// 创建一个 TeeReader,将读取的数据同时写入 multiWriterteeReader := io.TeeReader(reader, multiWriter)// 缓冲区buf := make([]byte, 8)// 从 TeeReader 中读取数据,数据会被输出到标准输出和文件for {n, err := teeReader.Read(buf)if err == io.EOF {break}if err != nil {fmt.Println("Error:", err)return}fmt.Printf("\nRead %d bytes: %s\n", n, string(buf[:n]))}
}
程序运行结果:
Hello, Go!
Read 8 bytes: Hello, G
Read 3 bytes: o!
同时,output.txt 文件也会包含 Hello, Go!。
总结
io.Reader用于读取数据,io.Writer用于写入数据。io.TeeReader可以将读取的数据同时写入另一个io.Writer。io.MultiWriter可以将写入的数据同时写入多个io.Writer。
通过结合使用这些工具,你可以轻松地处理 I/O 操作并实现类似“复制”或“分发”数据的功能。
—注释结束—
Ben Johnson: 是的,没错。你看这些包,它们是按字母顺序排列的,如果你知道自己要找什么,那很好。但我觉得有趣的是,把它们分门别类,理解它们的子分类以及它们的外观。我觉得这让它们更容易理解和应用。
Brian Ketelsen: 我喜欢这个过程中传达出的潜在信息---虽然不是直接的,但间接地让我更加意识到 Go 中小型接口的重要性。我知道在实际工作中,很多人把接口看得很复杂。“我有一个接口来保存用户到数据库。” 但这并不是 Go 的惯用接口风格。Go 的惯用接口是像 io.Writer 这样的,它非常小,只做一件事。通过这些博客文章,我更加深刻地意识到这一点。
Erik St. Martin: 是的,尤其是那个关于标准包布局的文章。我在看它的时候,每种方法的负面影响都提到了。我能想到很多包和项目,它们大量使用这些方法。你会发现,“是的……” 我曾经遇到过循环依赖问题,这些都是基于类似 Rails 风格的布局导致的。
Ben Johnson: 我也会这样去思考。Go 的标准库总是非常合理,所有的命名和包布局都非常清晰。这也是一个巨大的灵感来源。他们做对了什么?我们又如何将这些应用到更具体的应用开发中?我认为这是两个不同的世界,但有很多可以相互借鉴的地方,你知道吗?
Erik St. Martin: 我觉得我们需要一个服务,叫“库组织即服务”。“这是我的项目,[笑声] 你告诉我应该如何布局。”
Carlisia Thompson: 这正是我觉得可以从标准包布局那篇博客文章中衍生出来的会议演讲的名字。“包即服务” [笑声]。
Brian Ketelsen: 真棒!
Ben Johnson: 应该像一个包布局工厂。
Erik St. Martin: “把你的项目发给 Ben,他会告诉你应该如何布局……”
Brian Ketelsen: 这太棒了;只要 50 美元,他就会帮你重新组织所有的包。
Erik St. Martin: 看他已经开始压低价格了 [笑声]。
Brian Ketelsen: 好吧,Ben 是超级英雄,他只需要 10 分钟就能搞定。这已经是个不错的利润率了。
Erik St. Martin: 没错,如果他每 10 分钟能做一个,那真是个不错的时薪 [笑声]。
Ben Johnson: 到目前为止,我在 Slack 频道上收到了一些人的消息,他们向我询问设计方面的问题,这很不错。你可以给他们一些快速的反馈。早点做这些事情很好,因为项目可能会进行多年,得到早期的反馈可以让后面的工作变得更加轻松。
Erik St. Martin: 这确实很难,对吧?有句俗话说,“在行驶中的公交车上换轮子很难。” 尤其是对那些大型项目来说,当你走上一条路时,就好像被困在那条路上了。重新组织或以正确的方式抽象出某些东西需要投入大量精力,这会变得非常艰难。所以从一开始就走对路真的很重要。
Carlisia Thompson: 我特别喜欢 Ben 在 GopherCon 上做的闪电演讲,当时我就在现场,我心想,“好!这就是我要的!我需要学习如何做这些事情。” 因为我看过很多 Go 项目,很多项目都有个叫 model 的包,这让我很不舒服。我不知道为什么会不舒服,但在学习之后,我现在开始明白了。
当我看到 model 包时,里面不仅有模型信息,还包含了数据库实现信息,这让我不喜欢 [笑]。所以我真的很喜欢 Ben 如何组织项目,把每个部分分开。最近,我从头开始组织了一个项目。我对 Go 不算是特别有经验,但我思考了很久,因为我觉得我需要把一切都组织好。如果我不知道该把东西放在哪里,那我就不知道自己在做什么,我需要搞清楚。这是我工作流程的一部分。
Brian Ketelsen: 这让我想到了一个有趣的问题,我在 Go 包的使用上总是挣扎。一个包应该有多大?包的边界应该在哪里?我总是创建太多的包,不知道这是不是因为我有 Ruby 或 Java 的背景,但我总是创建太多的包,然后立刻后悔。
Ben Johnson: 我曾经在这方面摇摆不定。我以前非常倾向于使用单一包,像是“把所有东西都放进去吧,试图把所有东西分开是一件麻烦事。” 我也走过了另一个极端。我不认为代码的大小或者行数是衡量包大小的好标准。有时候一个巨大的包感觉还不错,而有时候却很难处理。我不知道,按照依赖关系来拆分对我来说效果还不错。这通常适用于中型项目吧。如果你有一个非常庞大的项目,可能需要进一步细分。我在这个光谱的各个端点上都走过。
Brian Ketelsen: 这就是我在想的问题的反例。当你想到一个大型 Go 项目,比如 Docker 或 Kubernetes,我真的不知道该从哪里开始划分这些边界;它太复杂了。你再想想依赖关系……天哪,Kubernetes 的依赖关系有多少?我不知道。也许这对我来说太复杂了,不适合现在去思考。
Erik St. Martin: 但我觉得你可以回到一些基本原则,对吧?我记得这些年我经常推荐给别人的两本书是 Robert Martin 的《代码整洁之道》和《程序员修炼之道》。两本书都提倡……首先,你希望你的代码不要高度耦合,但包应该具有内聚性,对吧?包里的所有东西应该有意义。它们都应该操作同样的数据。如果两个包之间相互了解太多,那么你可能把代码放错地方了,对吧?
Ben Johnson: 是的,这是个好观点。
Brian Ketelsen: 我们的 Slack 频道里的 Nathan Youngman 说,“一个包应该代表一个单一的想法”,这是他在某个演讲中听到的建议。如果你能很好地定义什么是“想法”,那就是个好建议。如果“想法”不是定义得太宽泛的话,这可能会有效。
Erik St. Martin: 那么,谈谈你这个系列文章的动机吧。你会继续写下去吗?这似乎跟你之前谈论的内容有些不同,对吧?前两次 GopherCon 演讲分别是关于高性能数据库的开发和静态代码分析的,现在你似乎转向了回归基础,讨论项目组织和库的使用。
Ben Johnson: 我觉得我总是在低级别和高级别之间来回切换。我现在更关注项目结构和这些高级概念。我最近做了更多应用层的工作,试图弄清楚 Go 应用该如何组织。一直有一种说法让我很困扰,就是有人说你不能用 Go 写网站和 Web 应用,Go 只是个 API 工具,但这不是真的。你完全可以用它构建真正的 Web 应用。我觉得现在大家开始意识到如何正确组织项目了。我想找到一种更好的方式来实现这一点。部分灵感来自我在做 Bolt 项目时的经验。在我看来,至少在我们的行业中,我们有容器技术和 Kubernetes---这些工具在大规模应用中确实很棒,尤其是当你需要高可用性和复杂需求时。但我认为,对于大概 90% 的应用来说,完全可以在单台服务器上运行并处理每秒数十万次请求,这可能就是大多数人的负载需求,比如使用 Bolt 或其他键值数据库。我在尝试简化技术栈,摆脱传统的 SQL 数据库等。
Erik St. Martin: 确实存在一种“害怕错过”的心理。所有这些新技术不断涌现,让你觉得必须去使用它们。
Ben Johnson: 是的,完全同意。
Erik St. Martin: 否则你会觉得自己已经过时了,跟不上潮流。但正如你所说,大多数人的系统并不需要那么大的扩展能力。并不是每个人都有 Kubernetes 级别的问题。如果你只是在管理三个节点,我认为你可能不需要 Kubernetes。用 Puppet 和 Ansible 之类的工具处理这些问题非常简单。当然它们也有自己的问题。我真的很喜欢 Kubernetes,但它也带来了独特的问题和限制。你需要管理、设置和配置更多的东西,这会增加认知负担,而你可能根本不需要这些东西,只是为了说自己在用它而用它。
Ben Johnson: 我完全同意。
Carlisia Thompson: 说回 Ben 刚才提到的一件事……Ben,当别人说“Go 并不适合用于 Web 应用;我甚至不知道它适不适合用于 API”时,你会怎么想或怎么说?你听到人们这么说过吗?
Ben Johnson: 我认为 Go 在处理 API 方面做得很好。我在 GopherCon 开幕派对上做过一个演讲,里面谈到……Go 不擅长的两个方面是模板和 SQL 数据库。我的意思是,它不是很好用。你可以用,但体验并不好。演讲的核心观点是,很多人正在从 SQL 数据库转向键值存储或 NoSQL 数据库,所以这不再是个问题。而且,随着前端开始使用像 React 这样的工具,我们与 API 交互,不再需要模板系统。我觉得行业的转变实际上更有利于 Go 的应用。
Carlisia Thompson: 是的,甚至 Amber 框架---我昨天刚学到,它们有一个功能可以生成 JSON API,如果你有一个模式,我认为它们可以自动生成代码。有人说这非常简单,我们当然也可以用 Go 来做 API。现在,我得跟进你刚才提到的另一件事。为什么 Go 不适合用来处理 SQL?我从没听说过这个说法。
Ben Johnson: 如果你使用像……我在用 Go 之前是做 Rails 的,那是我使用的最后一门语言。
Erik St. Martin: 你来对地方了。我们都是前 Ruby on Rails 开发者。
Ben Johnson: 当你只需要做一些不需要高性能的简单 Web 应用时,Rails 非常棒。你只需要写几行迁移代码,然后就可以开始编码,很多东西都是现成的。你几乎不需要直接与 SQL 交互。Go 有一些 ORM 工具,但我已经很久没用了。我并不是 SQL 数据库的超级粉丝。我曾经做过多年 Oracle 数据库管理员,所以我觉得 SQL 数据库在某些应用场景下真的很棒,但我越深入研究,就越觉得我们在数据存取和转换上做了很多不必要的事。我们在应用程序中做的事情和 SQL 数据库中的东西并不匹配。
你不得不拆解数据,然后再重新构建。整个过程就像是把字符串发送到数据库,数据库需要解析它们、优化它们、把它们保存在查询缓存里,然后再进行规划和执行……使用 SQL 真的涉及到很多复杂的步骤。虽然现在这已成为日常工作,但如果你深入思考一下,我们为了把数据存入 SQL 数据库而做的事情真是有点疯狂。相比之下,我可以举个对象数据库的例子,或者像用 Bolt 这样的键值数据库,只需要将对象序列化为字节并保存,这是一件相对容易理解和实现的事情。令我惊讶的是,我们的行业还没有更多地采用这些非常简单的工具。
Erik St. Martin: 我需要找到我之前看过的 YouTube 演讲,可能我记错了他参与的项目,但我相信他曾经参与过 DB2 的开发。他做了一个关于历史会重演的演讲,提到了大家对键值存储的热情。他说,“这就是数据库刚出来时的样子……”
Brian Ketelsen: 是的,在 60 年代。
Erik St. Martin: 是的,那个时候数据库是嵌入在主机应用程序里的,它就是这么工作的。他们有维护窗口来更新数据库,当互联网兴起时,这些系统需要更长时间在线,不能再承受停机。最初是银行系统,所以在非工作时间下线是可以接受的。
SQL 出现是因为它对商业人士来说是可以销售的。你可以很快教会一个业务人员 SQL 的基础知识,尽管复杂的连接和索引需要更深入的学习,但如果某人想要查询类似电子表格的数据,他们可以很快上手。这就是当时的转变。他还谈到了分布式数据库,他说,“是的,我们以前也有分布式数据库,只不过我们当时称之为联邦数据库。” [笑声] 这就是历史的重演。现在我们需要性能,所以我们又回到了老路上,只不过名字变了。
Ben Johnson: 是的,完全正确。如果你看看 SQL 数据库……SQL 只是一个抽象层,底层实际上运行的是某种引擎,本质上仍然是从行 ID 到某种字节编码的行的键值存储。仔细看看这些层次非常有趣。
Erik St. Martin: 性能问题的困难在于,由于这种抽象层,它必须从磁盘上读取大量数据,才能进入执行过滤的层。我知道 MySQL 尤其会过度获取数据。至少这些操作是在机器层上完成的,而不是全部数据都被传回去。
Ben Johnson: 是的。
Erik St. Martin: 我喜欢我们开始以不同的方式思考问题的这种方法。我喜欢列式数据库的概念,比如… Cassandra 是一个我比较喜欢的例子。你可以有非常宽的行,可以沿着这些行进行扫描,只读取你需要的部分,这是一种全新思维方式来解决问题。这些东西非常有趣,不过大多数人并没有做太复杂的数据处理。他们也许可以在现有的键/值逻辑上自行编写一些简单的处理逻辑。
Carlisia Thompson: 我想说,如果你使用过 NoSQL 数据库,并且你有相关经验,知道如何做出权衡,那就很棒了。但如果你没有太多经验,并且想知道“我有这样的数据模型,我应该考虑 NoSQL 风格或架构吗?”这真的很难搞清楚。因为你上网搜索---还能去哪里呢?结果各个方向都有各种意见,你根本无法做出决定。如果没有实际经验,学习如何判断、决定是否可以安全地走这条路真的很难。你可能会担心自己错过了什么。如果有人能告诉你如何判断“我可以安全地选择 NoSQL,并且将来不会有问题”,那就好了。
Erik St. Martin: 我认为 NoSQL 也是一种抽象。实际上,NoSQL 也是与键/值存储交互。它只是使用某种概率算法来定位数据。因此,这也是一种抽象。
选择数据库是很困难的。你必须仔细考察你的数据模型和访问模式。如果你经常按键查找数据,那么使用 SQL 数据库的开销就不太合理。但这还涉及到开发速度。每件事都是权衡。如果你要做很多汇总操作,比如计算平均值、统计数量之类的,这会导致你不得不读取大量数据、并自行执行这些计算。如果你能接受开发时间换取性能的权衡,这可能是合理的。但如果你只是想快速推出一个原型,这可能不是最佳选择。我也非常想听听 Ben 的看法。
Ben Johnson: 是的,我认为 NoSQL 和 SQL 的区别… NoSQL 不一定是键/值存储,而是更多地… 很多数据库尝试为特定领域进行优化,我猜这就是它们的亮点所在。如果你有一个时间序列数据库,你可以在这方面做很大的优化。如果你有一个专门的搜索数据库,也可以在这方面表现出色。这些特定领域的数据库在某些方面比通用 SQL 更加优异。我认为这就是它们的优势所在。
至于汇总操作… 如果你需要快速推出一个原型,并且你非常熟悉 SQL,我会毫不犹豫地选择 SQL。学习一门新语言或系统来做一些快速简单的事情通常不值得。
我特别喜欢键/值存储的一点是,很多你认为只是 SQL 数据库的功能,比如“哦,你有一个模式!”其实在键/值存储中,模式可以只是一个序列化库。ProtoBufs 就是一个很好的序列化库,它为你提供版本控制、快速编码和解码等功能。你可以将其应用在键/值存储的基础上,开始构建自己的数据库。虽然简单,但这是一件好事。
另一个方面是,当你想到 SQL 和 SQL 语言---我使用 SQL 多年了,但当你深入到更复杂的查询时,SQL 仍然让我感到非常沮丧。使用键/值存储时,你的查询语言实际上是 Go,这很棒,因为你可以在 Go 中做任何你想做的事情。如果你需要扫描一个表,或扫描一组键和值,你可以在键/值存储中创建一个索引,这些操作实际上都是用 Go 代码来处理的。因此,你可以做很多优化操作。你不再需要像查询规划这样的概念。你的查询规划是在编译前完成的,而你编写的代码实际上就是执行查询的代码。
Erik St. Martin: 人们常常忽略一些事情,比如索引。很多人会惊讶地发现,一个查询只能使用一个索引。他们以为索引了两个字段,并且在两个字段上进行搜索时,数据库会合并这些索引并加快查询速度,但实际上它只会选择其中一个索引,而这个选择可能是错误的。
Ben Johnson: 哦,是的。根据你如何排列索引字段的顺序,它可能会使用,也可能不会使用索引,这取决于统计数据,而这些统计数据会随着时间的推移而变化,从而改变你的查询计划。SQL 数据库中的很多未知因素和复杂操作已经成为我们习以为常的事情,但我觉得一旦你转向更简单的存储方式,这一切就会变得更加简单。
Erik St. Martin: 当你不确定如何处理数据时,问题的难点就来了。使用 SQL 数据库时,你可以轻松打开一个命令行应用程序或你最喜欢的图形界面应用程序,随便浏览数据,开始尝试查询,并发现你想要做的事情,然后再将其实现到代码中。而在键/值存储中,这种操作会更加困难。但我认为,开发角度上的最大难点---Brian 可能会同意这一点,因为我们看过很多数据库---其实是操作层面的问题。
我可能同意,键/值存储非常适合我的使用场景,但困难在于,如何管理备份和恢复等操作问题?如果你要在生产环境中部署它,还需要解决操作层面的事情。除此之外,你还需要为与键/值存储交互编写自己的代码,同时还需要编写管理数据库的工具,比如修复损坏的文件等。
Ben Johnson: 是的,我完全同意。我认为在教育方面也有很多欠缺。如果你要进入这个领域,没有太多可以借鉴的东西来学习。我希望这种情况能有所改善。我肯定会为此写一些博客文章。
Carlisia Thompson: 这是你给 Brian 的行动号召啊 [笑声]。
Brian Ketelsen: 没错。Ben,我有个问题要问你。这可能是一个有点离谱的问题。通常当你有一个项目时,你会对人们如何使用它有个大致的了解。那么,你见过用 BoltDB 做的最疯狂的事情是什么?
Ben Johnson: 我可以马上回答这个问题。这很简单。在 GopherCon 上,我和 Marty Schoch 聊过---我不知道他的姓氏是不是这么发音。他做了 Bleve---我一直以为是读作 BLEEVE。但 Bleve 是 Go 中的全文搜索工具。
Brian Ketelsen: 没错。
Ben Johnson: 他实际上用 Bolt 实现了一个 LSM 树;就像是有多个 Bolt 在运行时被合并。关于键/值存储,它们通常是 LSM 树,比如 LevelDB 或 RocksDB。它们有不同层次的数据存储,并在查询时合并,在压缩时进行各种操作。这类数据库通常非常复杂。而 B+ 树,比如 Bolt,往往是非常简单的数据库。他实际上使用 Bolt 的 B+ 树构建了一个 LSM 树,实现了合并操作。我觉得这实在太疯狂了。
Brian Ketelsen: 那它是如何工作的?每一层都是一个 Bolt 数据库吗?
Ben Johnson: 是的。
Brian Ketelsen: 哇。
Ben Johnson: 很酷吧。他真的让它工作了。我记得他是在写入性能方面做了改进。我不记得具体细节了,但他有一个闪电演讲,非常棒。
Erik St. Martin: 嗯,LSM 树在写入性能方面非常高效。这就是为什么像 RocksDB 这样的数据库写入速度非常快。
Ben Johnson: 是的,没错。
Brian Ketelsen: 我很好奇… 他实现了布隆过滤器之类的东西来判断…?
Ben Johnson: 我不知道他是否做到了那一步。如果做到了,那就太酷了。
Erik St. Martin: 是的,我也想看看。如果你有相关链接,我非常感兴趣,因为这些东西真的让我很感兴趣。我们可以用一周的时间来讨论 B 树、LSM 树等等这些东西。
当我们提到 LSM 时,指的是日志结构合并树,这实际上就是数据访问模式,它通过存储不同的层级并在需要时将它们合并。Cassandra 也是 LSM 树的一个大用户。
Ben Johnson: 是的,它们在很多使用场景下都表现得很好。它们通常在操作上更加复杂,但在随机写入时,写入速度比 B+ 树要快得多。如果你需要执行范围扫描,遍历一组有序的键,它们通常会慢得多,因为它们需要在不同的层级之间跳来跳去。总之,这一切都是权衡。
Erik St. Martin: 现在 Bolt 的最大用户是 InfluxDB 吧?
Ben Johnson: 不,Influx 最终… 他们为时间序列开发了自己更高效的存储格式。Bolt 更多是一个过渡方案。关于数据的分布、查询语言等方面有很多工作要做。我们已经不再使用 Bolt 作为主要存储。我们现在有一个叫做 TSM-1 的东西。
Erik St. Martin: 好的。我记得最初你们有多个可替换的存储引擎。我想你们后来决定支持所有这些引擎的开销太大了。
Ben Johnson: 当时人手不多,所以支持这些引擎的开销确实太大了。而且我们使用的一些其他库在操作上出现了一些问题,而不是性能问题。至于最大的用户,我不确定… 其实我不知道这个公司有多少信息是公开的;我知道有一家公司使用它… 我发现他们有一个三四 TB 的 Bolt 数据库。我在 Gophers 的 Slack 频道中发布了这个消息,说:“嘿,真是疯狂,有人用 Bolt 做了一个三四 TB 的数据库。” 结果有很多人回应,他们说:“哦,我也有!”他们使用了这些相当大的数据库,而且运行得很好。
Brian Ketelsen: 哇。那么,操作员如何管理如此大的 BoltDB 数据库呢?如何备份这个文件?使用 BoltDB 时有哪些操作上的顾虑?
Ben Johnson: 它是一个 B+ 树,所以随着它变得越来越大,取决于你如何构建存储桶,访问速度会变得稍微慢一些。我记得是 O(log n) 慢一点,别引用我这个说法。总之,它会随着时间的推移变慢。至于操作层面,Bolt 的事务实现了 io.Writer,因此你可以将一个 Writer 提供给它,用来写出整个数据库。我喜欢将它连接到 HTTP;所以如果我想使用 cURL 命令,我可以直接下载数据库。当然不能公开暴露这个端点,但这使得拍摄快照变得非常容易。
Brian Ketelsen: 哦,真不错。
Ben Johnson: 是的。完全可序列化,支持 ACID 等等。
Brian Ketelsen: 太棒了。
Ben Johnson: 这也是权衡之一。如果你使用 LSM 树,快照整个数据库会更加困难,因为你有多个文件和其他操作问题。没有好坏之分,还是权衡。
Erik St. Martin: 我认为几乎每个技术决策都是这样。你必须看你的问题,并确定哪种选择给你带来最大的好处,同时缺点最少,对吧?
Ben Johnson: 是的,完全同意。
Erik St. Martin: 我认为这正是我们刚刚讨论的,为什么像 Rails 这样的东西有吸引力。如果你是一家刚刚起步的公司,试图将产品推向市场,快速推出概念验证时,Rails 在多快部署一个概念验证网站方面有着巨大的吸引力。
Ben Johnson: 哦,是的,没错。
Erik St. Martin:尤其是当大部分内容都是CRUD操作时。你可以在一个周末内快速搞定一个还不错的网站,只要你加紧干。
Ben Johnson:这基本上就是黑客马拉松(hackathon)或创业周末的模式---就是在一两天内快速用Rails做出应用。你真的可以做出一些很棒的东西,一些概念就这样出来了。
Erik St. Martin:Brian,那些叫啥来着?那些Rails的活动?也在我们这儿办了几次,遍布全国,人们聚在一起组成团队,做点东西。它不叫黑客马拉松,叫别的什么……
Carlisia Thompson:我知道你说的是啥,Gopher Gala。Rails Rumble,我参加过一次……
Erik St. Martin:Rails Rumble,就是这个。我正说的就是这个。那次活动里出了一些很酷的东西,我真心希望它们能有后续发展。有些项目完全是搞笑的,比如:这想法是谁出的?
这让我想起最近看到的一个新数据库,叫noms,感觉像是本地Tampa Rails Rumble上的一个项目,叫Omnominator [笑]。
Brian Ketelsen:对,Omnominator,我记得。
Erik St. Martin:我不太记得它具体是做什么的,好像是跟找本地餐馆有关,但我超级喜欢这个名字 [笑]。
Brian Ketelsen:对,像是个美食车搜索引擎,或者类似搞笑的东西。
Erik St. Martin:我真想不起来了……我有段时间没关注Rails Rumble,也没怎么接触Rails圈子了。
Brian Ketelsen:无可奉告。
Erik St. Martin:Adam Stacoviak(来自Changelog)刚发了个链接。网站没了,但Omnominator的GitHub还在。
Carlisia Thompson:我想确认一下,我们得让Ben回答Erik问的问题。
Erik St. Martin:回答问题,Ben! [笑声]
Carlisia Thompson:你已经写了几篇非常详细的博客,介绍如何用Go标准库进行操作,你现在打算继续写更多吗?
Ben Johnson:哦,是的。我已经排了27篇文章,正在写。
Carlisia Thompson:哇。
Ben Johnson:我打算从整个栈的最底层开始,这就是我为什么先写了IO和bytes的原因,因为这些不太依赖Unicode之类的东西。但我想逐步往上,写一些更高级的东西,比如编码包之类的内容,循序渐进。
Erik St. Martin:不错。
Ben Johnson:是的。接下来就是编码包了。大多数人从未真正看过这个包,因为它只有四个接口,但我开始把它拆开,打算写一些关于里面其他包的概述,以及编码的含义,应该会不错。
Erik St. Martin:我觉得从IO包中的bytes和流处理开始是个非常好的切入点。尤其是对那些来自动态语言的人来说,他们习惯于只处理字符串,所以他们会大量使用字符串,创建许多副本,并将大量数据缓冲进内存,而其实不需要这样做。他们可以通过将这些reader和writer接口配合使用来避免这些问题。我认为这是一个很棒的起点,可以让人们以新的方式思考问题,而不是从某个地方读取所有数据,保存在内存中,然后再写到别的地方。
Ben Johnson:对,确实如此。谢谢。
Erik St. Martin:我想看你回应Bill的挑战。虽然不算是挑战,但他在寻求一种更好的方法……基本上是替换流中的字符串,在一个连续的流中。我开始写了一个解决方案,但一直没时间完成。
Ben Johnson:替换流?具体是什么例子呢?
Erik St. Martin:他在Go Playground上放了一段代码,基本上就是用bytes处理,当它看到流中的某些bytes时会进行替换。我在尝试做一个连续流,意思是无论读入多少字节,它都能判断并缓冲刚好足够的字节来查看下一个字符是否匹配,即便它只读到了一部分。
Ben Johnson:哦,明白了。
Erik St. Martin:因为这是人们使用reader时常犯的错误之一,他们认为一次读就能读到所有内容;但由于种种原因,读的数据可能不完整。所以我尝试实现一个方案,演示如果你在找“omnom” [笑]。
Ben Johnson:我经常找那个。
Erik St. Martin:是的,你可能在第一次读的时候只读到了“o”和“m”,剩下的在下一次读中,所以你不能仅仅看这次读出来的缓冲区内容。你得看整个流,并在字节流过时在内部构建一个小状态机,以判断是否找到了你要找的内容。
Ben Johnson:我想状态机是个不错的选择。
Erik St. Martin:我已经开始了一个方案,但没时间完成。我觉得完成它会很有趣,因为它能很好地展示你在Bytes Walkthrough和IO包中提到的许多要点。
Ben Johnson:哦,当然,没问题。
Brian Ketelsen:这种问题的好处在于,它有点像VimGolf(代码优化游戏),我们从一个实现开始,然后有人改进它,再有人进一步优化,最后有人做得非常出色。我就是这样学会的。我喜欢看到这种性能演进,尽管最初的方法已经足够了。很多时候,我们只做到这一步,因为这已经满足需求了。但当你真的需要那最后一点性能时,看到如何实现这一点是很有趣的。
译者注:
—注释开始—
VimGolf 是一个挑战平台,旨在帮助用户提高他们在 Vim 文本编辑器中的编辑技巧。它通过提出各种编辑任务,鼓励用户使用尽可能少的按键操作来完成任务,从而优化他们的 Vim 使用效率。
主要特点
- 挑战任务:VimGolf 平台会给出一段初始文本和一个目标文本,用户需要通过 Vim 或类似编辑器的操作,把初始文本编辑成目标文本。
- 按键最少:VimGolf 的目标是尽可能使用最少的按键来完成编辑。每次按键(包括按下每个字母、组合键、模式切换等)都会被计算在内。
- 社区参与:用户可以上传自己的解决方案并与其他用户比较,看看谁的按键数量最少。你也可以查看其他用户的解决方法,从中学习更高效的 Vim 操作技巧。
- 学习 Vim:通过不断地挑战和优化操作,用户可以深入理解 Vim 的各种命令、快捷键和编辑模式,从而更熟练地使用 Vim。
如何使用 VimGolf
- 注册账号:首先,你需要在 VimGolf 的网站上注册一个账号(vimgolf.com)。
- 选择挑战:浏览各种挑战,选择你想参加的任务。
- 完成挑战:在 Vim 或你喜欢的文本编辑器中完成编辑任务。记住,目标是使用最少的按键。
- 提交解决方案:使用 VimGolf 提供的命令行工具或通过网站上传你的操作步骤,平台会自动统计你的按键数。
- 查看排名:提交后,你可以看到自己的按键数排名,并与其他用户的解决方案进行比较。
例子
假设有一个 VimGolf 挑战,给定初始文本:
Hello World
目标是将其改为:
Hello, VimGolf!
你可以通过以下 Vim 操作完成任务:
- 在
Hello后插入逗号:ea, - 移动到
World并替换它为VimGolf:cwVimGolf - 在行尾插入感叹号:
A!
这三步操作使用了 9 个按键,VimGolf 会统计并显示你的按键数。
为什么使用 VimGolf
- 提高 Vim 技巧:通过不断优化你的编辑操作,你可以学会使用 Vim 的各种快捷键、命令和模式,极大提升编辑效率。
- 挑战自我:每个挑战都可以多次尝试,不断减少按键数,挑战自我极限。
- 学习高效操作:你可以从其他用户的解决方案中学到更高效的操作方式,帮助你提升 Vim 的使用水平。
—注释结束—
Erik St. Martin:这个问题有趣的地方在于,我原以为很简单---我可以构建一个小状态机。但让我没完成的原因是有很多小的边界情况,比如当你只读到一部分数据时,你需要暂时缓冲一下,因为你还不能把数据流到另一边,因为你还不知道是否需要进行替换。你已经有了前两个字母,这可能是目标单词,但也可能不是。你只在这种情况下需要一个小缓冲区,而当你知道正在读的字符不可能是你要替换的那部分时,你就不需要缓冲。所以做缓冲会有额外的开销。
我一直在尝试构建一个最有效的版本,结果总是遇到这些边界情况,基于读入的字节数,有时它能工作,有时却不行。我心里想着:“为什么?!” 编程真难啊。
Brian Ketelsen:确实是。
Ben Johnson:计算机真难。
Erik St. Martin:我们还有10到15分钟,你们想聊聊社区里其他事情或者有趣的项目吗?我提到了noms数据库,不知道你们有没有机会看看。
Ben Johnson: 没有,没看过。那是基于Git的吗?
Erik St. Martin:是的,正是那个。
Ben Johnson:好吧,我还没来得及看。
Erik St. Martin:我还没玩过,但觉得挺有趣的,因为它有一个让我很感兴趣的特点……它是内容可寻址的,这在存储中也逐渐流行起来,并且是只追加的,所以你只能得到版本控制。但我真正想尝试的是,因为我喜欢它的去中心化特性。尤其是当我们可以用Go构建客户端应用程序时。我们还在做GUI,对吧?但你仍然可以构建客户端应用程序,所以我喜欢它的去中心化特性。你可以在做某件事时,与其他人的工作合并。
Brian Ketelsen:这个让我想起了数据库的rebase操作,真是噩梦 [笑]。我绝不会对我的数据库做rebase。
Erik St. Martin:所以问题就在这儿,对吧?我还没玩过。别把这当成我鼓励你去试着用它。但它让我产生了想法,我想试试,看看它的效果如何。
Brian Ketelsen:我也好奇想看看。我还没时间读它的readme,但他们做出的权衡挺有意思的,因为数据库里的每件事都是权衡。你必须做出选择。那么他们试图解决的具体用例是什么呢?
Ben Johnson:对,我也在想他们的用例是什么。
Erik St. Martin:他们有Slack、邮件列表和Twitter。我们应该问问他们。
Brian Ketelsen:对,他们都有了,甚至还有个很可爱的logo。
Ben Johnson:通常我们提到这些东西时,总会有人恰好在Slack频道里,或者认识正在做这个项目的人,然后我们会实时收到信息 [笑]。
Brian Ketelsen:今天没发生。为什么noms的人不在GoTime FM的Slack里?有人快去修复这个问题。
Carlisia Thompson:说到可爱的logo,我今天想提的项目也跟数据库有关,它完全因为网站赢得了我的喜爱,因为网站和logo都很可爱,并且设计得很好,简单干净。所以,如果你想卖东西给我,你知道该怎么做 [笑声]。
Erik St. Martin:给它一个可爱的logo?
Carlisia Thompson:如果它可爱,还配色鲜明,那我就买账了。
Erik St. Martin:我有这片草叶,但它有个非常酷的logo。 [笑声]
Carlisia Thompson:没错。
Brian Ketelsen:成交!
Carlisia Thompson:我就这么容易被打动。所以,这不是一个ORM,而是Go中一个高效的数据访问层。我觉得很搞笑,因为在其他语言里,这种库都会说:“我们是ORM,我们是最好的ORM”,不管它的功能有多少。但在Go里,大家都说:“不不不,我们不是ORM!我们不是ORM”。 [笑]
Brian Ketelsen:在Go中,ORM是个脏字。
Carlisia Thompson:是个超级脏字,对吧?每次都让我发笑。
所以我最近在看非ORM和ORM的东西,今天我发现了这个---它其实是在Go的新闻通讯里,我想我会用它。它功能不算特别强大,也不会让我害怕。作为Go的新手,我觉得我无法识别出太多东西来做决定;如果一个包做的事情太多,我就会退缩。这是我现在的标准。但我想要一点功能。我有一个API,它会有过滤器和参数,我想只要把它们放进变量里,然后放进函数里,就好了。我不想手写SQL,做一堆手工活。我觉得我能提升一些速度,所以我打算用这个。
Brian Ketelsen:这是编程世界中人们总是不同意的地方。有人喜欢亲自手写SQL,精心调优,执行它,然后将结果映射回结构体,用于他们需要的地方。还有一类人根本不想考虑数据库的任何问题。这两类人中间的情况非常少见。
Carlisia Thompson:对。
Erik St. Martin:其实我大概处在中间的位置。
Brian Ketelsen:哦,你就是喜欢唱反调。
Carlisia Thompson:用这个工具,你完全可以直接发送SQL。所以我很喜欢这一点,因为我预料到自己会需要这样做。如果没有这个功能,我就不会用它。但我想这些库应该都会有这样的功能。我觉得它让你得到了两方面的优势。
Erik St. Martin:我在直接使用SQL时的一些痛点是……任何用过标准数据库SQL包的人都能证明这一点---扫描单个字段的过程会变得很痛苦。尤其是当你更改SQL时,如果你弄错了类型,所有这些问题都会让你感到头疼。所以我喜欢那些能让我轻松地将数据映射回类型并进行查询的工具。
但话说回来,我们刚才也提到了Rails。我喜欢Rails做这些事情的简单性,但这也是一把双刃剑。并不是说我不相信它,我真的认为快速原型开发是很棒的。但我偶尔会遇到两个问题。一是当你有一个复杂的查询时,通常你是在用真正的SQL做实验,确保数据集正确,然后你将其转换为Active Record格式,接着你需要修改它,然后再试图把它转回去。
这个转换过程可能会麻烦,不过如果你熟悉Active Record的话,这也不算大问题。但是对于新手来说,主要问题是像大多数ORM这样的工具可能是“泄漏的抽象”(即抽象不够完美)。当一切运行顺利时,它们是完美的抽象,但如果你不了解底层运行的SQL,它真的会影响性能。比如你可能会遇到N+1查询问题等。这会变得很棘手;完美的平衡点在哪儿?我不知道是否有一个明确的答案。我觉得自己大概处在中间地带。
Carlisia Thompson:对。如果你不了解底层的运作机制,可能会遇到性能问题。这也可能会是另一个问题,就是当你想做一些不同的事情时,怎么办?但我想你总是可以回到直接写SQL上吧。
Erik St. Martin:听起来,Ben,从你的角度来看,你似乎喜欢ORM这套东西;你认为这是Go可以改进的一个方面,能促进Go的推广?或者说是Go的采用率?
Ben Johnson:我甚至不一定会这么说。我觉得当你深入ORM时,除非你是在生成代码……很多ORM使用了很多接口,你因此失去了类型安全性,并且在这方面会遇到很多问题。我认为从对象映射到关系数据的过程中有一些根本性的问题是无法回避的。就我个人而言,我觉得如果你使用本地的键值存储,很多问题可以避免,但这并不适合所有人。你可以避免N+1查询;因为你不用从远程服务器获取数据,它们根本不存在。你也不会遇到SQL注入问题,因为你根本没有SQL。我认为这是一种不同的思维方式。
所以我不会说ORM是最佳选择。就我个人而言,如果可以的话,我会避免SQL。但这只是我个人的看法。
Erik St. Martin:全程使用键值存储。
Ben Johnson:对,全程。
Brian Ketelsen:如果你要避免SQL,如何构建一个系统,能够有多个数据库副本同时运行?可以用Bolt做到这一点吗?
Ben Johnson:多个副本……比如在集群中分布式部署?
Brian Ketelsen:对。
Ben Johnson:我觉得有一些方法可以处理。我认为不管是Bolt还是其他数据库,如果你需要横向扩展,通常你需要对数据进行分片。如果你在分布式系统(甚至是数据库)中有大量的协调工作,就会有锁和各种权衡。所以我认为你当然可以使用Bolt进行数据分片。Bolt目前缺少的一点是我正在开发的异步事务日志,这样你就可以将一个应用实例连接到另一个实例,并让它成为一个……
Brian Ketelsen:类似于备用节点?
Ben Johnson:对,备用节点。这是一个替代方案。
Brian Ketelsen:那么BoltDB现在有提供任何形式的复制日志吗?同步或异步的?
Ben Johnson:目前还没有,但这是我想要添加的功能之一。
Brian Ketelsen:不错。
Ben Johnson:因为我认为这可以解决大约95%的实际案例,提供一个数据库和备用节点,允许故障转移。这也是为什么很多人使用Postgres,因为它默认使用异步日志,我想。
Erik St. Martin:对。所以我觉得我们快到时间了,我希望我们有时间进入“Free Software Friday”(自由软件星期五),但还有一个你在做的项目,我想花点时间提一下,那就是《数据的秘密生活》(The Secret Lives of Data)。
Ben Johnson:对,没错。这是一个一直在进行的项目,虽然我有段时间没做出什么新内容了。我做了Raft的可视化(Raft 是一种分布式一致性协议)。它的意思是,如果你有一个节点集群,并且它们需要对一些数据达成一致,基本上就是一个事务日志,即使在故障转移或网络分裂的情况下,它们也需要在日志中的所有内容上达成一致---这是怎么实现的?这个协议是由斯坦福大学的Diego Ongaro和John Ousterhout(不知道我发音对不对 [笑声])提出的。我完全把名字念错了,对不起。
但对,他们试图做一个更简单的Paxos协议,你可以把它想象成一个多Paxos协议。但问题是,当你读这篇论文时,可能需要读好几遍,如果你不在分布式系统这个领域,很多概念可能根本不理解。我曾经在过去的工作中做过很多数据可视化,我非常喜欢D3可视化工具,所以我想把它应用到Raft和分布式计算系统中。所以这就是《数据的秘密生活》这个项目,它是对Raft工作原理的可视化展示。
Erik St. Martin:我非常喜欢这个项目,因为它让这些话题变得更容易理解。对于很多不在这个领域工作的人来说,当你提到“分布式一致性”这个词时,他们的眼睛会立刻翻白眼,觉得这是个完全无法理解的东西,只有MIT、伯克利等地方的博士生才会研究。我之前看过Paxos的白皮书,然后看到Raft。我记得当时看Raft的PDF有11或12页,解释了Raft的原理,我当时觉得:“哇,这让事情变得更容易理解了。” 然后我看到了《数据的秘密生活》,我想:“这让事情更加容易理解了。” 虽然这可能不足以让人立即实现一个Raft系统,但足以让人理解分布式一致性的工作原理,以及其中的一些问题。我看过你在GitHub上的计划,你计划讲解Kafka的工作原理,对吗?
Ben Johnson:对,那是我接下来要做的项目。我觉得在我们的行业中有很多“高大上”的词汇,实际上这些词汇背后通常意味着非常简单的概念。当你能直观地看到一个概念时,很多时候只需要五分钟,你就会完全明白:“哦,原来Kafka是这样工作的,或者分布式一致性是这么回事。” 这些词听起来吓人,但背后其实是非常简单的概念。
Brian Ketelsen:日志结构合并?
Ben Johnson:日志结构合并树(Log-structured merge-tree)。听起来像是个噩梦,但其实不是。当你深入理解时,它并不复杂。实现起来可能会复杂,但其背后的概念并不复杂。
至于Kafka,我已经开始做一些工作,尝试了很多不同的方法去可视化它。我想为博客文章做更多的可视化,但却不太合适。我想转向用视频的方式,因为每当你在网上发布任何内容,总会有很多人说它不好。关于《数据的秘密生活》的一个问题是,有人说它的节奏太慢了。所以我在想是否应该做一些视频,然后配上旁白,或者加上一些字幕之类的,让它的节奏更快一些。
Erik St. Martin:我觉得部分原因是……如果它的节奏不快,你可以让它更具互动性,这样反而会迫使人们慢下来,比如让用户自己提供数据,看看数据是如何流动的之类的。但我觉得教人的难点在于,如果你加快节奏,对一些人来说会太快。如果你放慢节奏,对另一些人来说会太慢。找到那个中间点真的非常难。这是我和Brian一直在努力解决的问题。任何试图教别人东西的人都会遇到这个问题,试图找到那个中间点,我觉得你总会让一部分人掉队,这真的很难,而且让你非常难过,因为你很想找到一个方法让每个人都能跟上。
Ben Johnson:对,我完全同意。
Erik St. Martin:也许你可以做个自动播放功能,不需要手动点击播放,它会按照设定的间隔自动过渡,然后你可以加一个滑块,让用户调整播放速度快一点或慢一点。
Ben Johnson:对,这也是个办法。还有就是,制作这个项目真的非常难,因为我必须实现---因为它是实时运行的,不是一个固定的时间---我必须在后台用JavaScript实现Raft。我一直在寻找一种更简单的方法来做可视化。
Erik St. Martin:[笑] 明白了,我之前没想到这一点。你竟然用JavaScript实现了Raft。
Ben Johnson:对,这简直是个糟糕的主意 [笑声]。
Erik St. Martin:Brian现在肯定在麦克风后面给你恶狠狠的眼神,我能感觉到 [笑声]。我知道他在想:“有人肯定会用这个做坏事。”
Brian Ketelsen:对,这肯定会发生。永远不要发布这个代码,Ben。
Ben Johnson:哦,不不不。
Brian Ketelsen:绝对不要!
Ben Johnson:绝对不会。
Erik St. Martin:我知道我们时间不多了,可能实际上已经超了几分钟。但我们每期节目都会有一个叫做“自由软件星期五”的环节,我们每个人会分享一些开源项目,这些项目曾经或现在让我们的生活变得更轻松。因为我们在与其他开源项目维护者交流时发现,大多数时候,他们只会看到负面的反馈,几乎看不到正面的反馈。所以我们想继续传递对这些项目的喜爱,因为它们让我们的生活更轻松。
那么,Brian,你想先来吗?
Brian Ketelsen:好的,我来开个头。我推荐Minikube;github.com/kubernetes/minikube。K-U-B-E。这是一个非常快速且简单的方法,可以在本地笔记本电脑上启动Kubernetes集群。如果你不想运行17个虚拟机来构建一个集群,它就非常棒。简单、轻量,而且非常好用。
Carlisia Thompson:我接着来。首先,我要提一下之前我说过的那个库,叫upper.io/database。
Brian Ketelsen:哦,之前提到的数据库库?
Carlisia Thompson:对。那个非ORM的库。还有,我想说的是,Ben之前做了一个远程聚会活动,展示了如何使用BoltDB,非常棒。
Erik St. Martin:哦,很酷,有录像吗?
Carlisia Thompson:有的。如果你访问remotemeetup.golangbridge.org,你会看到过去的活动,Ben的展示也在那里。我看过,非常不错。
Erik St. Martin:哇,太好了。
Carlisia Thompson:今天我想提到的自由软件叫做Stow,它是GNU项目的一部分……我不知道这个怎么发音……
Erik St. Martin:GNU。
Carlisia Thompson:对,GNU。我是通过看Brian和Erik的Dot文件才发现这个工具的。我都不知道自己做了这么久的程序员,居然不认识这个工具。
Erik St. Martin:其实它在很多工具的底层被用来管理新版本的库。
Carlisia Thompson:我以为它只用于处理符号链接?
Erik St. Martin:它确实处理符号链接。它基本上可以将一个动态库或静态库的默认版本符号链接到某个其他地方的最新版本。但它还用于类似的其他事情。
Carlisia Thompson:有意思。
Brian Ketelsen:但它对管理DOT文件非常有用。
Erik St. Martin:对。我用它来管理我的DOT文件 [笑]。
Carlisia Thompson:原来如此,原来如此。难怪它的说明和我预期的有些不同。但用来管理DOT文件……哇,实在是太简单了!简直不敢相信我以前不知道这个工具。现在我用它来管理我的符号链接。
Erik St. Martin:对,它的一个很酷的地方是,你可以层次化地管理符号链接。我在我的DOT文件里是这样设置的:我有一个GitHub上的DOT文件仓库,所有的配置文件都存储在这个DOT文件目录里,然后我用Stow来管理它们。路径结构和它们在我的主目录中的布局一致。然后,我只需要对某个目录(比如Git)运行Stow命令,它就会把所有的Git DOT文件符号链接到我的主目录里的DOT文件目录里。然后,我可以继续添加文件,并让它为这些符号链接重新Stow。如果某个目录已经存在于你的主目录中,它就会单独符号链接文件;如果目录不存在,它会符号链接整个目录。它非常酷,因为如果你有多个系统,比如Linux和Mac,你可以告诉它只符号链接那些在当前机器上需要的文件,而不是所有的DOT文件全都链接。
Brian Ketelsen:对,确实很好用。
Carlisia Thompson:我手动符号链接时最大的问题是记不住如何取消符号链接,但用Stow的话,有一个删除命令,非常简单。
Erik St. Martin:对,取消Stow?
Carlisia Thompson:是的,或者叫un-Stow;我不记得了,我只做过一次。我设置得非常快速,然后就不再需要管它了。这就是为什么我觉得它很棒。
Brian Ketelsen:好像是stow/d。
Erik St. Martin:对。
Brian Ketelsen:非常棒。
Erik St. Martin:我们又多了一个Stow的粉丝。
Brian Ketelsen:太棒了!
Carlisia Thompson:是的,谢谢你。Erik,你解释得非常清楚,谢谢。
Erik St. Martin:我很早之前就写了那个readme。当时,我记得Brian想要复制一些DOT文件,还有其他几个同事也想要,所以我写了一个说明,因为我总是跑去大家的桌子旁帮他们,写个说明方便多了。
那么,Ben,你有想要感谢的项目吗?
Ben Johnson: 我没有特定的项目,我更想感谢一位维护者。Kelsey Hightower,我觉得他……大家都知道他是Kubernetes的代表人物,遗憾的是,我其实不用Kubernetes,但我认为他在这个领域做得非常棒。他为这个社区做了很多,个人方面也给了我很多帮助,所以我想对他说声谢谢。我希望他能继续支持社区,支持大家。而且他在今年的GopherCon开场演讲非常精彩。我觉得他做得非常出色。
BRIAN KETELSEN:完全赞同。
Ben Johnson:等视频发布了,请一定去看看。
Erik St. Martin:我也听说了。Kelsey不仅是一个人,他的贡献,不论是文章还是示例代码,我们都可以钦佩并努力去学习。真的是个很棒的人。
Brian Ketelsen:我想成为像Kelsey那样的人。
Erik St. Martin:我也是。我长大后能成为Kelsey那样的人吗?
Brian Ketelsen:那需要付出很多努力。
Erik St. Martin:我这次的推荐项目,其实与Go开发无关。
Brian Ketelsen:什么?
Erik St. Martin:对,我准备这么做。作为一个业余爱好,除了迷恋数据库之外,我还痴迷于信息安全。很多人都会用到一个发行版,叫做Kali Linux,它是基于Debian的。但我一直是Arch用户,几乎所有地方都用Arch。所以在GopherCon之前,我发现了一个项目,叫做ArchStrike(archstrike.org)。它基本上是一个Arch仓库,里面有你在Kali Linux中可能会用到的所有信息安全工具,这非常酷。现在我可以继续用Arch,而不需要运行一个Kali虚拟机。我不知道有多少Go开发者也是信息安全爱好者,但我想应该有一些。
Brian Ketelsen:现在这两个人非常兴奋 [笑声]。
Erik St. Martin:你必须是一个听这播客的Go开发者,同时喜欢信息安全和ArchStrike。而且还是Arch Linux的用户。
Carlisia Thompson:但他们现在都不在Slack上,对不起 [笑声]。
Erik St. Martin:我想我们已经完成了“自由软件星期五”的环节。在结束节目之前,我想提一下,Changelog有一个新的播客,叫做Request for Commits,他们会和大家讨论开源项目的可持续性,以及代码背后的人文方面。比如项目的商业授权、财务支持等话题。你可以访问changelog.com/rfc。如果你喜欢我们的播客,或者喜欢Changelog的播客---谁不喜欢Changelog的播客呢?
Brian Ketelsen:对吧?
Erik St. Martin:肯定会有一个人。我知道总会有一个人。
Brian Ketelsen:总会有一个人。就像GopherCon的调查里有一个人觉得Renee的演讲不够好。说真的,关于Gopher的演讲?你被淘汰了。别回来了,我们不需要你。
Carlisia Thompson:哇,我觉得她的演讲很棒啊。
Erik St. Martin:我觉得那是一段非常好的脑力放松时间。你会忘记两天时间里大量的内容塞进你的大脑是多么令人疲惫。我觉得那个演讲很有趣,给我们提供了一个短暂的休息。
Brian Ketelsen:很棒的演讲。
Erik St. Martin:在结束之前,还有人想提点什么吗?
Brian Ketelsen:我肯定有忘记的东西。哦,昨天我发现了一个项目,你知道我有多喜欢在DSL中生成东西。这个项目叫做Quilt;github.com/NetSys/quilt。它是一个非常酷的方式,可以为你的容器部署生成容器编排。这有点超出了纯Go编程的范畴,但它非常符合我“生成所有东西”的理念。它是Docker Swarm、Kubernetes或Mesos的替代品。它使用声明式DSL来描述你的部署,然后你只需要运行它。很酷。
Erik St. Martin:这很有趣啊,我还没见过这个。
Brian Ketelsen:我总是能找到很酷的东西。
Erik St. Martin:好的,我觉得时间到了。我想感谢大家参加这次节目。感谢Brian、Carlisia和Ben,特别感谢Ben来参加节目,主要聊了很多关于数据库的话题。这期节目非常精彩。感谢所有听众,无论是直播听的,还是之后收听的。如果你还没有订阅,你可以去gotime.fm,或在Twitter上关注我们,地址是twitter.com/gotimefm。我们还有一个GitHub仓库,地址是github.com/gotimefm/ping,如果你想推荐嘉宾,或想参加节目,或者有问题想让我们问嘉宾,都可以在上面留言。我想就这些了,再次感谢大家。
Brian Ketelsen:谢谢,Ben!
Carlisia Thompson:谢谢!
Ben Johnson:谢谢你们邀请我参加。
相关文章:

Go 标准库
本篇内容是根据2016年9月份The Go Standard Library音频录制内容的整理与翻译, BoltDB 的创建者 Ben Johnson 参加了节目,讨论 NoSQL 与 SQL 数据库、两者之间的权衡以及选择其中之一。我们还讨论了 Ben 的数据秘密生活项目,可视化数据结构,…...

AUTOSAR_EXP_ARAComAPI的6章笔记(5)
☞返回总目录 相关总结:AUTOSAR 通信组的使用方法总结 6.5 通信组的使用方法 6.5.1. 设置 本节描述了使用 Communication Group Template(类别为 COMMUNICATION_GROUP)定义通信组的配置步骤。定义一个通信组需要指定三个项目:…...

Photoshop中的混合模式公式详解
图层混合简介 图层混合(blend)顾名思义,就是把两个图层混合成一个。 最基本的混合是alpha融合(alpha compositing),这是一个遵循光的反射与透射等(简化版)物理学原理的混合方式。 各…...

Vue 自定义指令 Directive 的高级使用与最佳实践
前言 Vue.js 是一个非常流行的前端框架,它的核心理念是通过声明式的方式来描述 UI 和数据绑定。除了模板语法和组件系统,Vue 还提供了一个强大的功能——自定义指令。 自定义指令可以让我们对 DOM 元素进行底层操作,下面让我们通过一个有趣的…...

万字图文实战:从0到1构建 UniApp + Vue3 + TypeScript 移动端跨平台开源脚手架
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🍃 vue-uniapp-template 🌺 仓库主页: Gitee 💫 Github …...
在WebStorm遇到Error: error:0308010C:digital envelope routines::unsupported报错时的解决方案
作者:CSDN-PleaSure乐事 欢迎大家阅读我的博客 希望大家喜欢 使用环境:WebStorm 目录 介绍 解决 分析 方法一:设置环境变量 使用WebStorm 使用其他编译器 方法二:使用nvm切换nodejs版本 方法三:更新依赖版本 介…...

数据库产品中SQL注入防护功能应该包含哪些功能
数据库产品中 SQL 注入防护功能应包含以下几方面: 输入验证与过滤功能: 数据类型和格式验证:检查用户输入的数据是否符合预期的数据类型,比如对于一个应该是整数类型的字段,检查输入是否为整数;对于字符串…...

Ribbon客户端负载均衡策略测试及其改进
文章目录 一、目的概述二、验证步骤1、源码下载2、导入IDE3、运行前修改配置4、策略说明5、修改策略 三、最终结论四、改进措施1. 思路分析2. 核心代码3. 测试页面 一、目的概述 为了验证Ribbon客户端负载均衡策略在负载节点失效的情况下,是否具有故障转移的功能&a…...
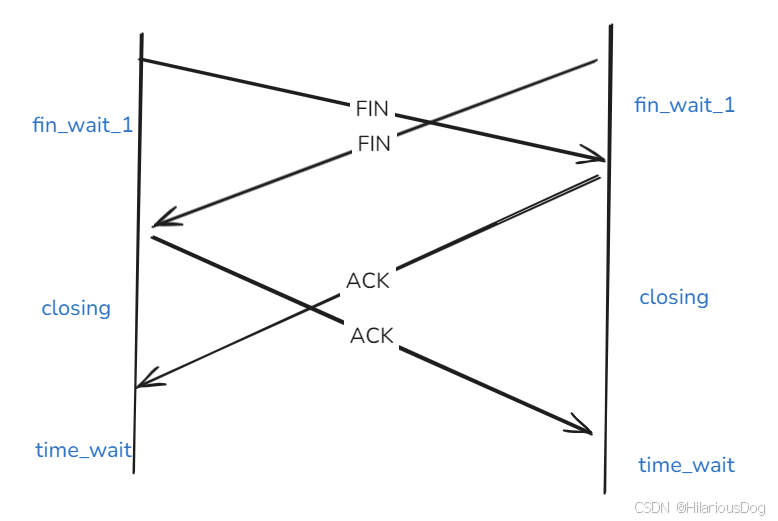
linux网络编程5——Posix API和网络协议栈,使用TCP实现P2P通信
文章目录 Posix API和网络协议栈,使用TCP实现P2P通信1. socket()2. bind()3. listen()4. connect()5. accept()6. read()/write(), recv()/send()7. 内核tcp数据传输7.1 TCP流量控制7.2 TCP拥塞控制——慢启动/拥塞避免/快速恢复/快速重传 8. shutdown()9. close()9…...

低代码平台中的功能驱动开发:模块化与领域设计
在现代软件开发中,尤其是在低代码平台的背景下,清晰地定义功能和模块是成功的关键。功能驱动开发强调功能的优先性,模块化设计则确保系统的可维护性和可扩展性。本文将探讨如何在低代码平台中有效地将功能与模块结合起来,形成一个…...

HTTP和HTTPS基本概念,主要区别,应用场景
HTTP和 HTTPS是用于在网络中传输数据的协议,虽然它们的功能类似,但在安全性上存在显著差异。 1. HTTP 的基本概念 定义:HTTP 是一种无状态的、面向请求-响应的协议,用于客户端(如浏览器)和服务器之间传输…...

node.js使用Sequelize ORM操作数据库
一、什么是ORM ORM是在数据库和编程语言之间建立一种映射关系,这样可以让我们有非常简单的代码,来实现各种数据库的操作。 例如:使用mysql去查找表(表名称为Articles) SELECT * FROM Articles;但是我们使用ORM的话&…...
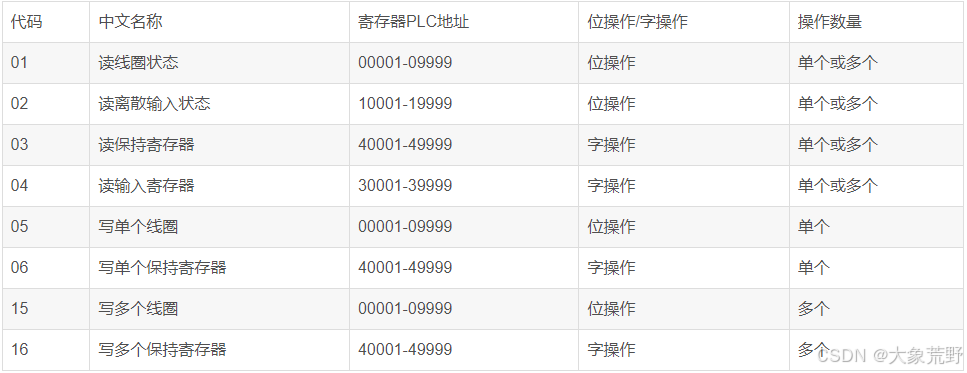
STM32-Modbus协议(一文通)
Modbus协议原理 RT-Thread官网开源modbus RT-Thread官方提供 FreeModbus开源。 野火有移植的例程。 QT经常用 libModbus库。 Modbus是什么? Modbus协议,从字面理解它包括Mod和Bus两部分,首先它是一种bus,即总线协议,和…...

100. 不同方向的投影视图
本节课给大家讲解,通过UI按钮界面交互改变threejs相机的观察视角。 x轴方向观察 // 通过UI按钮改变相机观察角度 document.getElementById(x).addEventListener(click, function () {camera.position.set(500, 0, 0); //x轴方向观察camera.lookAt(0, 0, 0); //重新…...
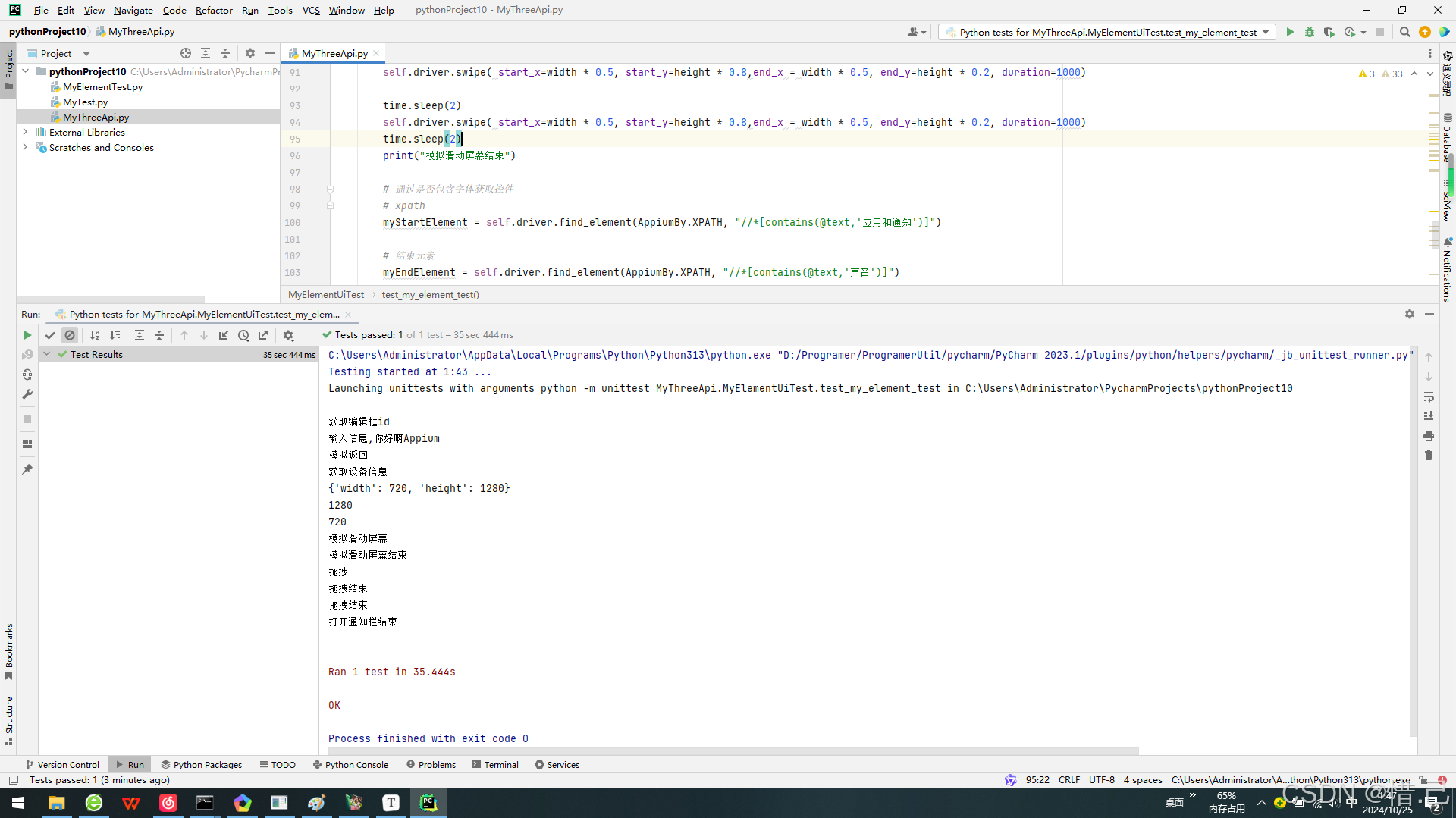
Appium中的api(三)
目录 Appium中的api(三) 1.输入和清空内容 1--输入内容 2--清空内容 2.获取文本内容 3.获取文本位置 4.获取文本的大小(即获取控件的宽和高) 5.滑动api 6.拖拽api 7.如何获取手机分辨率 8.如何截图 9.模拟按键事件api 10.操作通知栏 案例:App自动化模拟 …...

踩坑:关于使用ceph pg repair引发的业务阻塞
概述 在某次故障回溯中,发现引发集群故障,slow io,pg stuck的罪魁祸首竟是做了一次ceph pg repair $pgid。然而ceph pg repair作为使用频率极高的,用来修复pg不一致的常用手段,平时可能很少注意其使用规范和可能带来的…...
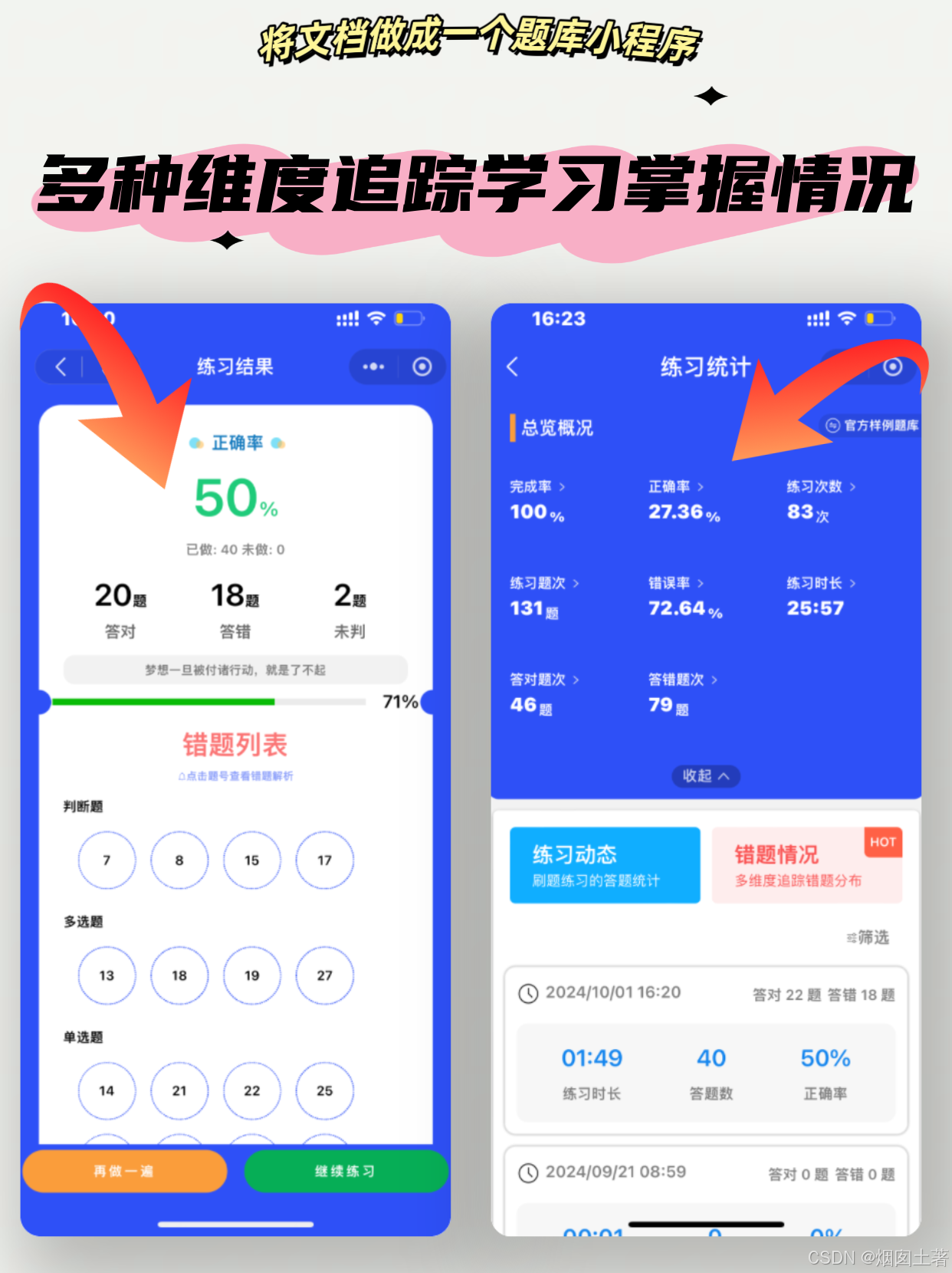
瞬间升级!电子文档华丽变身在线题库,效率翻倍✨
👋嘿小伙伴们,有个超赞的秘籍要告诉你们——土著刷题能将你的电子文档一键变身在线题库!😉 你还没发现这个宝藏功能吗?快来瞧瞧! 🌟是不是常被一堆电子版的学习资料搞得头昏脑涨,学习…...
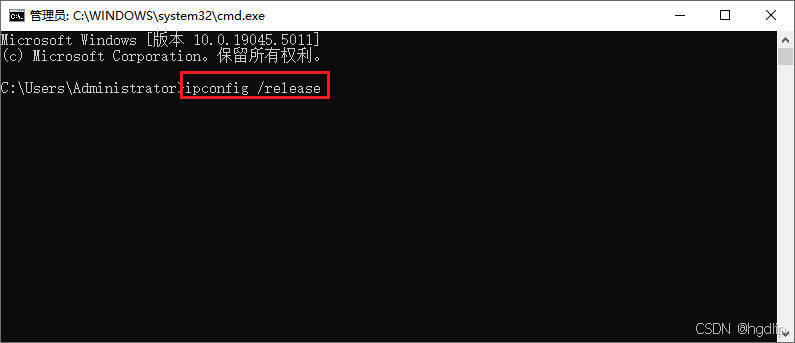
如何动态改变本地的ip
在当今数字化时代,网络连接已成为我们日常生活和工作中不可或缺的一部分。无论是出于隐私保护、突破地域限制,还是为了测试和优化网络应用,动态改变本地IP地址的需求日益增多。本文将详细介绍如何安全、有效地实现这一目标,旨在帮…...
Spring Boot框架在中小企业设备管理中的创新应用
4系统概要设计 4.1概述 本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示: 图4-1系统工作原理…...

Ceph入门到精通-Osd db扩容
ceph-bluestore-tool 是一个在 BlueStore 实例上执行低级管理操作的实用程序。 以下命令可用于 ceph-bluestore-tool 语法 ceph-bluestore-tool COMMAND [ --dev DEVICE … ] [ -i OSD_ID ] [ --path OSD_PATH ] [ --out-dir DIR ] [ --log-file | -l filename ] [ --deep ]c…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
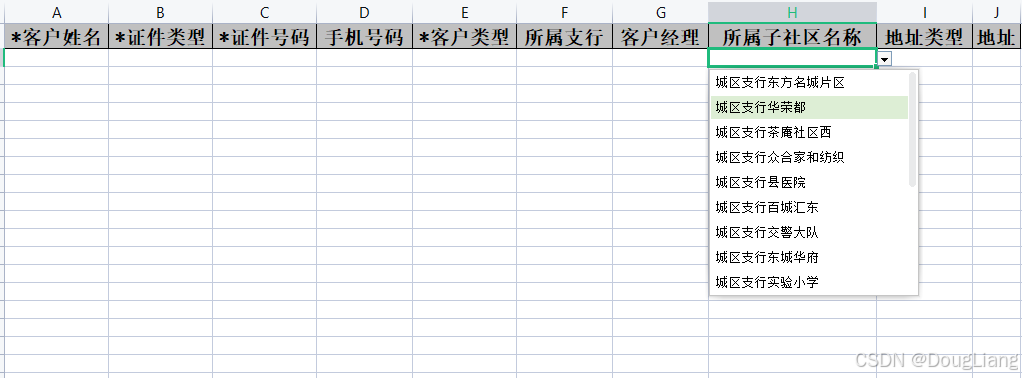
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...