聚类分析算法——K-means聚类 详解
K-means 聚类是一种常用的基于距离的聚类算法,旨在将数据集划分为 个簇。算法的目标是最小化簇内的点到簇中心的距离总和。下面,我们将从 K-means 的底层原理、算法步骤、数学基础、距离度量方法、参数选择、优缺点 和 源代码实现 等角度进行详细解析。
1. K-means 的核心思想
K-means 的目标是将数据集划分为 个簇(clusters),使得每个数据点属于距离最近的簇中心。通过反复调整簇中心的位置,K-means 不断优化簇内的紧密度,从而获得尽量紧凑、彼此分离的簇。
核心思想
- 簇(Cluster):K-means 通过最小化簇内距离的平方和,使得数据点在簇内聚集。
- 簇中心(Centroid):簇中心是簇中所有点的平均值,表示簇的中心位置。
- 簇分配和更新:K-means 通过不断更新簇分配和簇中心,来逐步收敛。
2. K-means 的算法步骤
K-means 聚类的流程分为两个主要步骤:分配(Assignment)和更新(Update)。以下是详细步骤:
-
选择 K 值:
设定簇的数量。
-
初始化簇中心:
随机选择 -
分配步骤(Assignment Step):
对于数据集中的每个点,将它分配到最近的簇中心对应的簇。这里的“距离”通常使用欧氏距离(Euclidean distance)。 -
更新步骤(Update Step):
根据当前的簇分配,重新计算每个簇的中心,即计算簇内所有点的均值作为新的簇中心。 -
重复 3 和 4 步:
不断重复分配和更新步骤,直到簇中心不再发生变化(收敛)或达到指定的最大迭代次数。
3. K-means 的数学公式
K-means 的目标是最小化簇内平方误差和(Within-Cluster Sum of Squares,WCSS),即每个点到其所属簇中心的距离的平方和,公式如下:

其中:
是第
个簇的点集。
是属于
是第
表示数据点
欧氏距离
K-means 通常采用欧氏距离来衡量点到簇中心的距离,其公式为:

其中 n 是数据的维度。
4. K-means 的伪代码
KMeans(X, K):1. 随机选择 K 个点作为初始簇中心2. 重复以下步骤,直到簇中心不再发生变化:a. 分配每个点到最近的簇中心b. 重新计算每个簇的中心,作为簇内所有点的均值3. 返回最终的簇分配和簇中心
分配步骤(Assignment Step)
对于每个数据点,找到距离最近的簇中心 μj:

更新步骤(Update Step)
更新每个簇的中心 为簇内所有点的均值:
5. K-means 的时间复杂度分析
- 每次分配步骤:需要计算每个点到
。
- 更新步骤:重新计算每个簇的中心,需要遍历所有点,复杂度也是
- 总复杂度:若迭代次数为
,则总体复杂度为
。
6. K-means 的优缺点
优点
- 简单高效:在样本数量较少或维度较低时效果很好。
- 收敛速度快:在适合的初始中心选择下,K-means 通常可以较快收敛。
缺点
- 对初始点敏感:初始簇中心的选择对最终结果影响较大。
- 只能发现球形簇:K-means 假设每个簇是凸形且大小相近,不能处理非球形的簇。
- 对离群点敏感:离群点会影响簇的中心计算。
7. K 值的选择
确定最佳的簇数 是 K-means 聚类中的一个难点。常用的选择方法有:
-
肘部法(Elbow Method):
绘制不同 K 值下的 WCSS 图,寻找“肘部”点作为最佳 -
轮廓系数(Silhouette Coefficient):
衡量聚类结果的紧密度和分离度。通常,轮廓系数越高,聚类效果越好。 -
Calinski-Harabasz 指数:
衡量簇内的方差与簇间方差之比,值越大越好。
8. Python 实现 K-means
我们可以使用 scikit-learn 中的 KMeans,以及手动实现以便更深入理解。
8.1 使用 scikit-learn 实现 K-means
from sklearn.cluster import KMeans
import numpy as np# 生成示例数据
X = np.array([[1, 2], [2, 2], [3, 3], [8, 7], [8, 8], [25, 80]])# 初始化并训练 KMeans 模型
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)# 获取簇标签和簇中心
labels = kmeans.labels_
centroids = kmeans.cluster_centers_print("Cluster labels:", labels)
print("Centroids:", centroids)
输出:
Cluster labels: [0 0 0 1 1 1]
Centroids: [[ 2. 2.33333333][13.66666667 31.66666667]]
8.2 手动实现 K-means 算法
以下是 K-means 的核心逻辑手动实现:
import numpy as npdef initialize_centroids(X, k):indices = np.random.choice(len(X), k, replace=False)return X[indices]def closest_centroid(X, centroids):distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=2)return np.argmin(distances, axis=1)def update_centroids(X, labels, k):return np.array([X[labels == i].mean(axis=0) for i in range(k)])def kmeans(X, k, max_iters=100, tol=1e-4):centroids = initialize_centroids(X, k)for i in range(max_iters):labels = closest_centroid(X, centroids)new_centroids = update_centroids(X, labels, k)if np.all(np.abs(new_centroids - centroids) < tol):breakcentroids = new_centroidsreturn labels, centroids# 示例数据
X = np.array([[1, 2], [2, 2], [3, 3], [8, 7], [8, 8], [25, 80]])# 运行 K-means
labels, centroids = kmeans(X, k=2)
print("Cluster labels:", labels)
print("Centroids:", centroids)
9. 收敛性与初始中心的选择
K-means 的收敛性受到初始簇中心选择的影响。K-means++ 是一种改进的初始化方法,可以帮助选择更合理的初始中心,减少陷入局部最优的风险。
K-means++ 初始中心选择步骤
- 随机选择一个点作为第一个中心。
- 对于每个点,计算其与已选择中心的最小距离。
- 根据与最近中心的距离平方值选择下一个中心,概率越大则越有可能成为下一个中心。
10. 总结
K-means 是一种简单、快速的聚类算法,广泛应用于数据聚类任务。通过反复优化簇中心位置,K-means 不断收敛并找到数据的聚类结构。然而,它对初始条件敏感,对簇形状有限制,适合于球形且均匀分布的簇。在实际应用中,可通过结合 K-means++、肘部法和轮廓系数等手段改进其效果。
相关文章:
聚类分析算法——K-means聚类 详解
K-means 聚类是一种常用的基于距离的聚类算法,旨在将数据集划分为 个簇。算法的目标是最小化簇内的点到簇中心的距离总和。下面,我们将从 K-means 的底层原理、算法步骤、数学基础、距离度量方法、参数选择、优缺点 和 源代码实现 等角度进行详细解析。…...
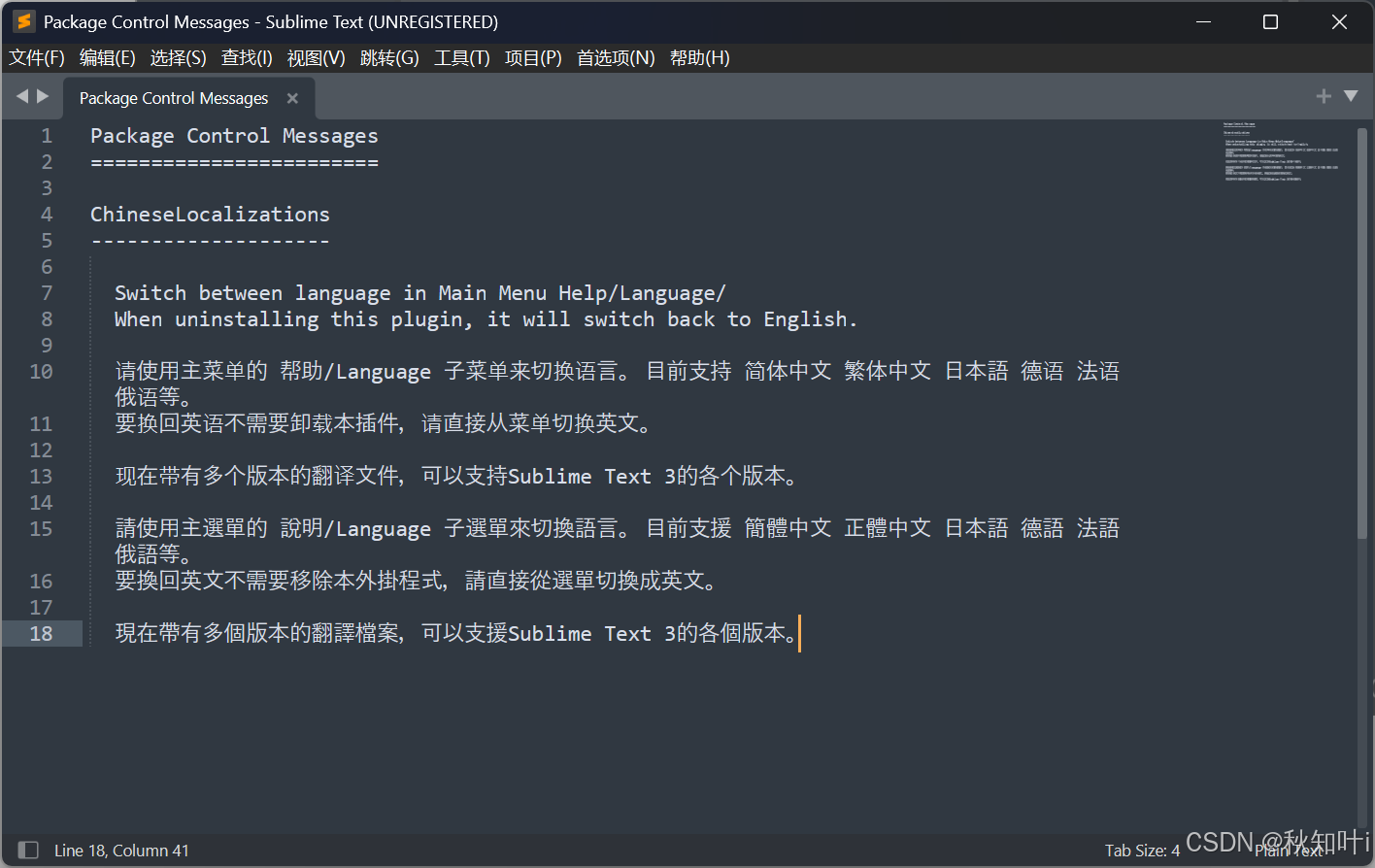
【Sublime Text】设置中文 最新最详细
在编程的艺术世界里,代码和灵感需要寻找到最佳的交融点,才能打造出令人为之惊叹的作品。而在这座秋知叶i博客的殿堂里,我们将共同追寻这种完美结合,为未来的世界留下属于我们的独特印记。 【Sublime Text】设置中文 最新最详细 开…...
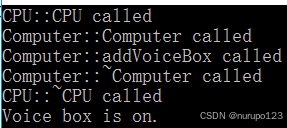
C++学习路线(二十四)
静态成员函数 类的静态方法: 1.可以直接通过类来访问【更常用】,也可以通过对象(实例)来访问。 2.在类的静态方法中,不能访问普通数据成员和普通成员函数(对象的数据成员和成员函数) 1)静态数据成员 可以直接访问“静态数据成员”对象的成…...

MySQL-存储过程/函数/触发器
文章目录 什么是存储过程存储过程的优缺点存储过程的基本使用存储过程的创建存储过程的调用存储过程的删除存储过程的查看delimiter命令 MySQL中的变量系统变量用户变量局部变量参数 if语句case语句while循环repeat循环loop循环游标cursor捕获异常并处理存储函数触发器触发器概…...
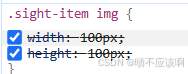
前端页面样式没效果?没应用上?
当我们在开发项目时会有很多个页面、相同的标签,也有可能有相同的class值。样式设置的多了,分不清哪个是当前应用的。我们可以使用网页的开发者工具。 在我们开发的网页中按下f12或: 在打开的工具中我们可以使用元素选择器,单击我…...

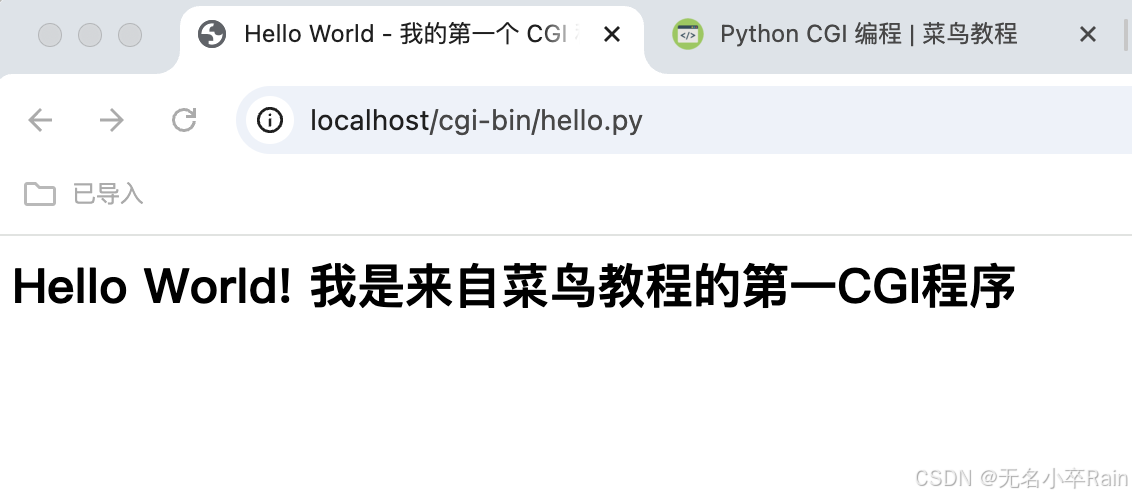
Mac apache配置cgi环境-修改httpd.conf文件、启动apache
Mac自带Apache,配置CGI,分以下几步: 找到httpd.conf。打开终端,编辑以下几处,去掉#或补充内容。在这个路径下写一个测试文件.py格式的,/Library/WebServer/CGI-Executables,注意第一行的python…...
多厂商的实现不同vlan间通信
Cisco单臂路由 Cisco路由器配置 -交换机配置 -pc配置 华三的单臂路由 -路由器配置 -华三的接口默认是打开的 -pc配置及ping的结果 -注意不要忘记配置默认网关 Cisco-SVI -交换机的配置 -创建vlan -> 设置物理接口对应的Acess或Trunk -> 进入vlan接口,打开接…...

sh与bash的区别
sh与bash的区别 结论:对于一般开发者,没有区别;对于要使脚本兼容较老系统,或者兼容其他shell(如ksh,dash),那么意义可能很重大,要确保自己代码没有bash扩展的特性。 区…...

D48【python 接口自动化学习】- python基础之类
day48 练习:开发自动咖啡(上) 学习日期:20241025 学习目标:类 -- 62 小试牛刀:如何开发自动咖啡机?(上) 学习笔记: 案例解析 定义类 定义属性和方法 clas…...

PostgreSQL(WINDOWS)下载、安装、简单使用
下载 PostgreSQL: Downloads PostgreSQL: Windows installers EDB: Open-Source, Enterprise Postgres Database Management 安装 注意密码要方便自己使用,不能忘记。 打开pgAdmin,输入密码 新建数据库 打开命令工具 新建表...

Git的初次使用
一、下载git 找淘宝的镜像去下载比较快 点击这里 二、配置git 1.打开git命令框 2.设置配置 git config --global user.name "你的用名"git config --global user.email "你的邮箱qq.com" 3.制作本地仓库 新建一个文件夹即可,然后在文件夹…...

rocketmq服务的docker启动和配置
rocketmq的默认启动参数占用的内存实在是太大了,小于8G的电脑无法启动,docker中的开发环境又不可能用这么大,通用的该法是改sh文件 修改文件如下 runbroker.sh 默认8G JAVA_OPT"${JAVA_OPT} -server -Xms${Xms} -Xmx${Xmx} -Xmn${Xmn…...

BLE和经典蓝牙相比,有什么优缺点
蓝牙低功耗(Bluetooth Low Energy,简称 BLE)和经典蓝牙(Bluetooth Classic,即 BR/EDR,Basic Rate/Enhanced Data Rate)是蓝牙技术的两种主要模式。两者都有各自的优缺点,具体如下&am…...

ECharts图表图例知识点小结
ECharts 图表图例简述 一、知识点 1. 作用: - 用于标识图表中的不同系列,帮助用户理解图表所展示的数据内容。 2. 位置: - 可以通过配置项设置图例的位置,如 top 、 bottom 、 left 、 right 等。 3. 显示状态控制:…...
LabVIEW非接触式模态参数识别系统开发
基于LabVIEW的模态参数识别系统采用非接触式声学方法,结合LabVIEW软件和高精度硬件,实现机械结构模态参数的快速准确识别。降低了模态分析技术门槛,提高测试效率和准确性。 项目背景与意义: 传统的模态分析方法,如锤击法&#x…...

厨艺爱好者的在线家园:基于Spring Boot的实现
1 绪论 1.1 研究背景 现在大家正处于互联网加的时代,这个时代它就是一个信息内容无比丰富,信息处理与管理变得越加高效的网络化的时代,这个时代让大家的生活不仅变得更加地便利化,也让时间变得更加地宝贵化,因为每天的…...

PostgreSQL使用clickhouse_fdw访问ClickHouse
Postgres postgres版本:16(测试可用)docker 安装 插件安装 clickhouse_fdw: https://github.com/ildus/clickhouse_fdw 安装命令 git clone gitgithub.com:ildus/clickhouse_fdw.git cd clickhouse_fdw mkdir build && cd build…...

docker 单节点arm架构服务器安装zookeeper、kafka并测试通信
kafka、zookeeper常用镜像介绍 kafka和zookeeper常见的镜像有以下三个:wurstmeister/zookeeper、kafka、confluentinc/cp-zookeeper、cp-kafka 和 bitnami/zookeeper、kafka。 wurstmeister/xxx: 由wurstmeister团队维护,提供的镜像适用于开发和测试环…...

AnaTraf | 全面掌握网络健康状态:全流量的分布式网络性能监测系统
AnaTraf 网络性能监控系统NPM | 全流量回溯分析 | 网络故障排除工具AnaTraf网络流量分析仪是一款基于全流量,能够实时监控网络流量和历史流量回溯分析的网络性能监控与诊断系统(NPMD)。通过对网络各个关键节点的监测,收集网络性能…...
)
Python实战:用sklearn的mutual_info_classif快速筛选高价值特征(附避坑指南)
Python实战:用sklearn的mutual_info_classif快速筛选高价值特征(附避坑指南) 在电商用户行为分析中,我们常常面临成百上千个特征变量——从用户点击流、停留时长到购物车行为,每个特征都可能隐藏着影响转化的关键信号。…...

基于LingBot-Depth的YOLOv8目标检测:实现高精度空间感知
基于LingBot-Depth的YOLOv8目标检测:实现高精度空间感知 1. 引言 想象一下,自动驾驶汽车在雨天行驶时,摄像头被水珠遮挡,或者监控系统在夜间需要识别远距离物体。传统视觉系统在这些复杂环境下往往表现不佳,因为它们…...

从零构建RAG系统:小白程序员必备的全局观与收藏指南
本文旨在帮助读者建立RAG系统的全局观,从离线解析、Query理解、在线召回到上下文生成,详细阐述了四大模块及其间的六个关键联动点,如Chunk大小与LLM窗口的配合、Query解析结果对检索策略的指导等。文章强调模块间的相互影响,并通过…...

IT行业新风向!卷运维不如卷网络安全
在网络安全行业摸爬滚打这么多年,亲历了数不尽的技术面试,同时也见证了同行们职业生涯的起起伏伏,特别是运维领域。我发现最近很多从事运维的选择了辞职,转行到了网络安全这个发展路线。 运维,顾名思义就是运营和维护…...

KMP算法详解 [c++]
目录 前言 朴素的模式匹配算法 KMP模式匹配算法 KMP模式匹配算法的原理 next数组值的推导 KMP模式匹配算法的实现 KMP模式匹配算法的改进 nextval的推导 优化后的KMP模式匹配算法代码 零、前言 每年新闻周刊都会发布年度十大热词,这其实查询某个字符串在其…...

如何通过eluceo iCal 2创建重复事件与例外日期?
如何通过eluceo iCal 2创建重复事件与例外日期? 【免费下载链接】iCal iCal-creator for PHP 项目地址: https://gitcode.com/gh_mirrors/ic/iCal eluceo iCal 2是一款强大的PHP iCal创建工具,能够帮助开发者轻松生成符合iCalendar标准的日历文件…...
AudioSeal Pixel Studio部署案例:中小企业音视频内容安全防护轻量级方案
AudioSeal Pixel Studio部署案例:中小企业音视频内容安全防护轻量级方案 1. 引言:当声音也需要“身份证” 想象一下这个场景:你是一家小型内容创作公司,刚刚为一位重要客户制作了一段精美的品牌宣传音频。几天后,你发…...

【JDK17-HttpClient】 Selector/Channel 的NIO实现细节?与Netty的NIO实现有何异同?
深度拆解 JDK17 HttpClient NIO 架构:Selector/Channel 实现细节与 Netty 对比全解析 发布时间:2023-11-02 当前聚焦技术问题:Selector/Channel 的 NIO 实现细节?与 Netty 的 NIO 实现有何异同? 一、问题引入:NIO 黑盒引发的生产雪崩 在分布式系统的高并发场景中,HTTP…...

OBS怎么调美颜?OBS怎么打开美颜功能?
OBS Studio 实现美颜主要有内置滤镜、第三方插件、摄像头硬件美颜三种方式,今天主要介绍第三方插件的用法: 一、基础准备 确保已安装 OBS Studio 最新版(推荐 29.1.3 及以上,稳定性更佳)。 摄像头已连接并正常识别&a…...

利用ESP-WROOM-32实现双串口数据交互与OLED实时监控
1. ESP-WROOM-32双串口通信基础 ESP-WROOM-32作为乐鑫推出的明星级Wi-Fi/蓝牙双模模组,其内置的Xtensa双核处理器和丰富的外设接口让它成为物联网项目的首选。我最喜欢用它做串口中继器——因为这家伙天生自带三组硬件串口(UART0用于下载调试,…...