[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp
目录
一、前言
二、项目的相关背景
三、搜索引擎的宏观原理
四、搜索引擎技术栈和项目环境
五、正排索引 VS 倒排索引--原理
正排索引
分词
倒排索引
六、编写数据去除标签和数据清洗模块 Parser
1.数据准备
parser
编码
1.枚举文件 EnumFile
2.去标签ParseHtml()
测试
使用SCP命令在两台Linux服务器之间传输文件
适用场景
命令格式
示例
将scp任务放入后台执行
Boost搜索引擎项目的九个步骤~
- 项目的相关背景
- 搜索引擎的相关宏观原理
- 搜索引擎技术栈和项目环境
- 正排索引 vs 倒排索引 - 搜索引擎具体原理
- 编写数据去标签与数据清洗的模块Parser
- 编写建立索引的模块 Index
- 编写搜索引擎模块 Searcher
- 编写http server模块
- 编写前端模块
准备分几篇文章讲解,持续更新中(●'◡'●),会在最后一篇文章中放上项目的gitee~本篇文章先从这几个部分进行实现

一、前言
在日常使用浏览器搜索时,服务器返回的是与搜索关键字相关的网站信息,包括网站标题、内容简述和URL。点击标题后会跳转到对应的网页。常见的搜索引擎如百度、谷歌等覆盖全网信息,而我们的项目是一个小范围的站内搜索引擎,用 boost库 实现的 boost站内搜索
二、项目的相关背景
什么是Boost库?
- Boost库是C++的准标准库,提供许多高级功能。
- 许多Boost组件已被纳入C++11标准。如:哈希、智能指针
- 更多详情可访问Boost官网。
什么是搜索引擎?
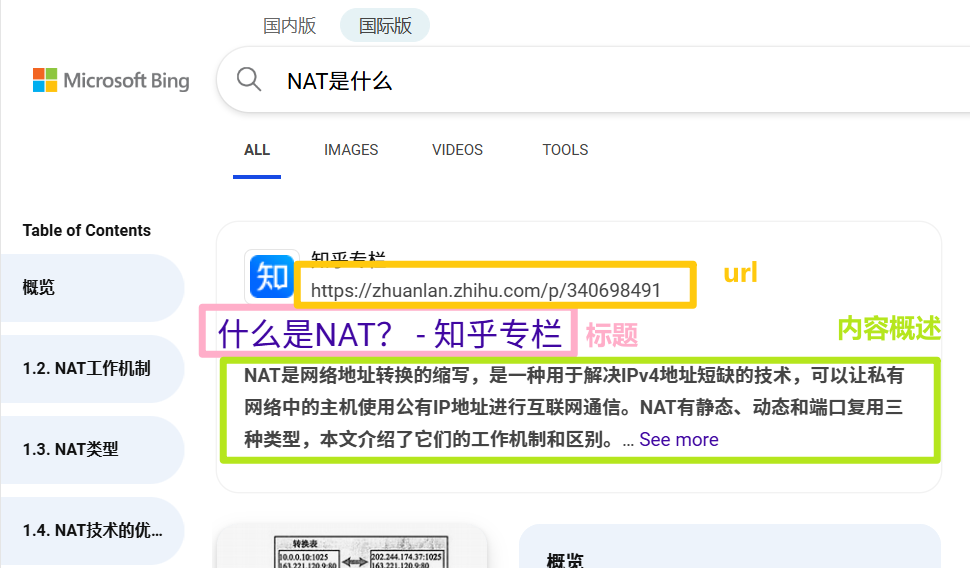
- 搜索引擎如百度、360、搜狗展示的信息通常 包括网页标题、摘要和URL。
- 我们设计的搜索引擎将 不包含图片、视频或广告等扩展内容。
- 搜出来的结果展示都是以,标题+内容摘要+url 组成
为什么要做Boost搜索引擎?
- Boost库缺乏站内搜索功能。
- 实现一个类似cplusplus官网的站内搜索功能是有意义的

- 实现目标:搜索一个关键字,就能够跳转到指定的网页,并显示出来
- 站内搜索的数据量相对较小且更垂直化。
三、搜索引擎的宏观原理
通过以下步骤实现:
- 数据准备:获取并存储Boost文档数据。我们可以直接将 boost库 对应版本的数据直接解压到我们对应文件里。
- 去标签 & 数据清洗:提取所需信息(标题、摘要、URL)。我们从boost库拿的数据其实就是对应文档html网页,但是我们需要的只是每个网页的标题+网页内容摘要+跳转的网址,所以才有了去标签和数据清洗(只拿我们想要的)
- 构建索引:对清洗后的数据建立索引(方便客户端快速查找);
- 用户请求处理:解析搜索关键词,检索索引,返回结果。
流程模拟:
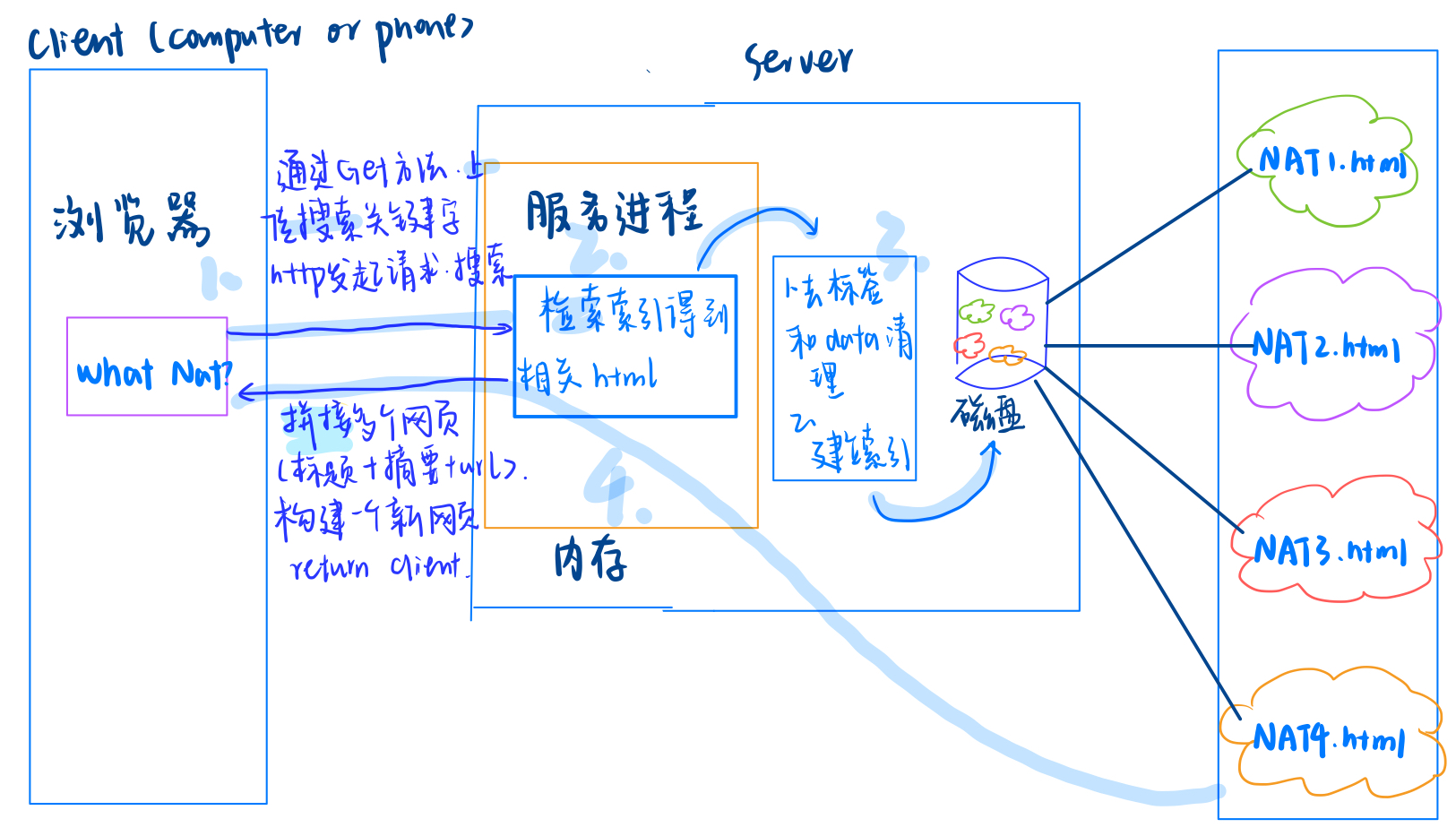
- 当服务器所以的工作都完成之后,客户端就发起http请求,
- 通过GET方法,上传搜索关键,
- 服务器收到了会进行解析,通过客户端发来的关键字 去检索已经构建好的索引,找到了相关的html后
- 将逐个的将每个网页的标题、摘要和网址拼接起来,构建出一个新的网页,响应给客户端
- 至此,客户就看到了相应的内容,点击网址就可以跳转到boost库相应的文档位置。
网页概述:
- tltle
- 内容摘要
- url
盈利方式:
- 推送广告,竞价排名收费
四、搜索引擎技术栈和项目环境
技术栈:
- C/C++/C++11, STL,
- 相关库
- Web 前端( HTML5, CSS, JavaScript), jQuery, Ajax。
相关库
- Boost库(文件遍历)
- Jsoncpp(json 处理)
- cppjieba(分词)
- cpp-httplib(网络库-http 服务)
项目环境
- Ubuntu 云服务器,
- vim/gcc/g++/Makefile
- VS2022 或 VSCode
五、正排索引 VS 倒排索引--原理
- 正排索引:文档ID-->文档关键词/ 内容。
- 倒排索引:文档的关键词-->文档ID。
分词
目标文档进行分词:目的:方便建立倒排索引和查找
停止词:了,吗,的,the,a,一般情况我们在分词的时候可以不考虑
正排索引
| 文档 1 | 我以后要养一只小猫 |
| 文档 2 | 我以后还要养一只小狗 |
分词
1:我 /以后 /要养/ 一只/ 小猫
2:我 /以后 /还要养 /一只 /小狗
倒排索引
| 我 | 文档 1,文档 2 |
| 以后 | 文档 1,文档 2 |
| 小猫 | 文档 1 |
| 小狗 | 文档 2 |
⭕模拟一次查找的过程:
用户输入:关键词->倒排索引中查找->提取出文档ID(1,2)->通过倒排数据找到正排ID->找到文档的内容->title+conent(desc)+url 文档结果进行摘要->通过 json字符串响应回去-->然后在用户的浏览器显示出一个个网页信息
代码实现逻辑:
下载Boost库 -> 解析HTML -> 数据清洗 -> 构建索引 -> 提供搜索接口 -> 显示结果。
- 数据准备:从Boost官网下载 boost 库,并解压至Linux目录。
- 选择所需文件:写一个解析程序从一个个html文件的源码中提取标题、内容和url,将他们保存到硬盘的一个data.txt文件中。
- 读取:读取data.txt文件,建立正排和倒排索引,提供索引的接口来获取正排和倒排数据
- 数据拷贝:写一个html页面,提供给用户一个搜索功能。然后模拟上述查找过程
六、编写数据去除标签和数据清洗模块 Parser
1.数据准备
- boost 官⽹: https://www.boost.org/
下载:
之后 rz -E,再解压
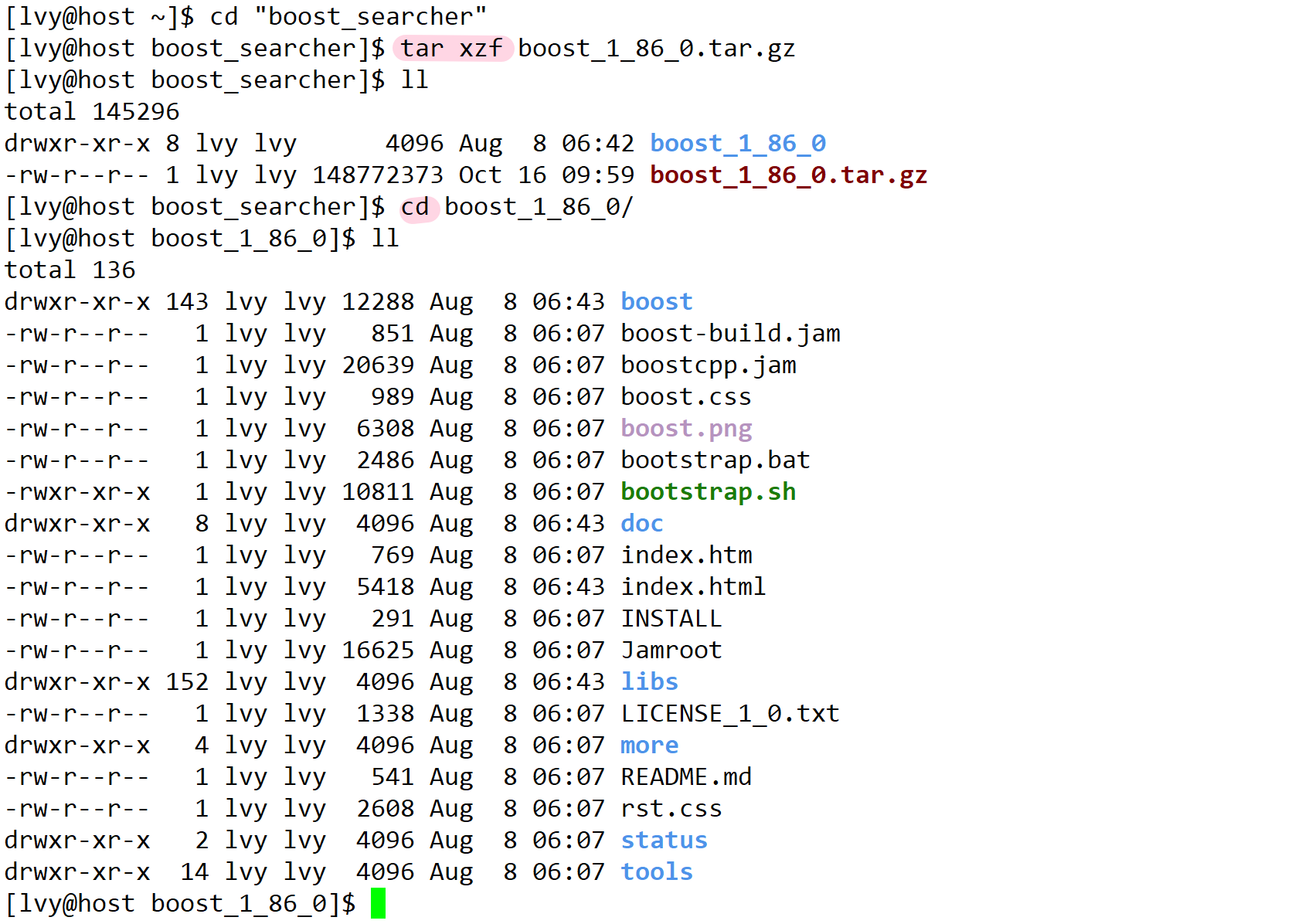
⽬前只需要boost_1_86_0/doc/html⽬录下的html⽂件,⽤它来进⾏建⽴索引
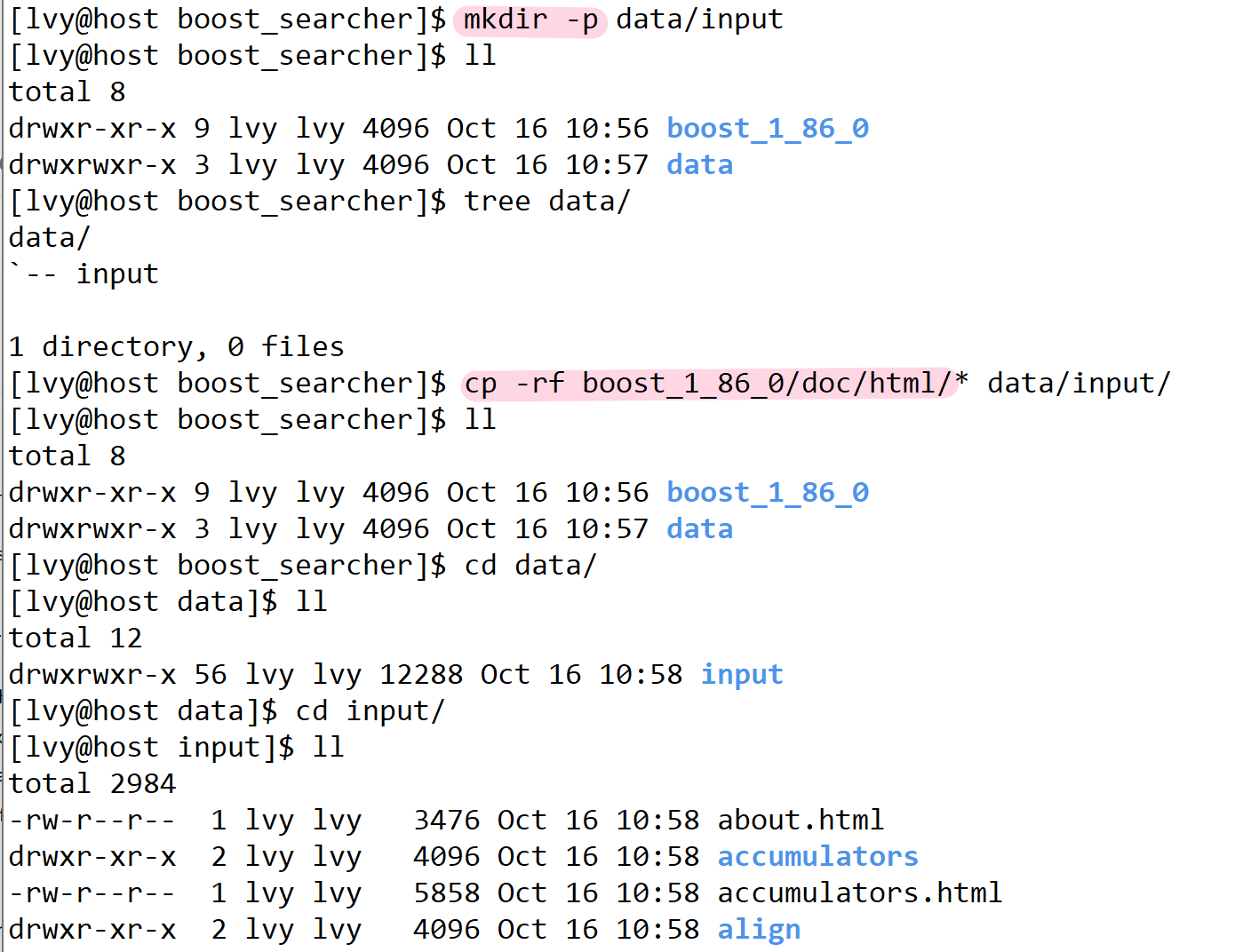
将我们所需要的数据源 拷贝到 data目录下的intput目录下--清洗数据完成
parser
这里我是在 vscode 下进行代码编写的,但是需要连接一下云服务器,与 Linux进行同步。 你也可以选择 vim。
基本框架:
- 将 data/input/ 所有后缀为 html 的文件筛选出来 ---- 清洗数据
- 然后对筛选好的html文件进行解析(去标签),拆分出标题、内容、网址 ---- 去标签
- 最后将去标签后的所有html文件的标题、内容、网址处理后,写入到 data/raw_html/raw.txt 下
什么是去标签呢?
举例 nano process.html 查看一下
对数据清洗之后,拿到的全都是 html 文件,此时还需要对 html 文件进行去标签处理,我们这里随便看一个html文件
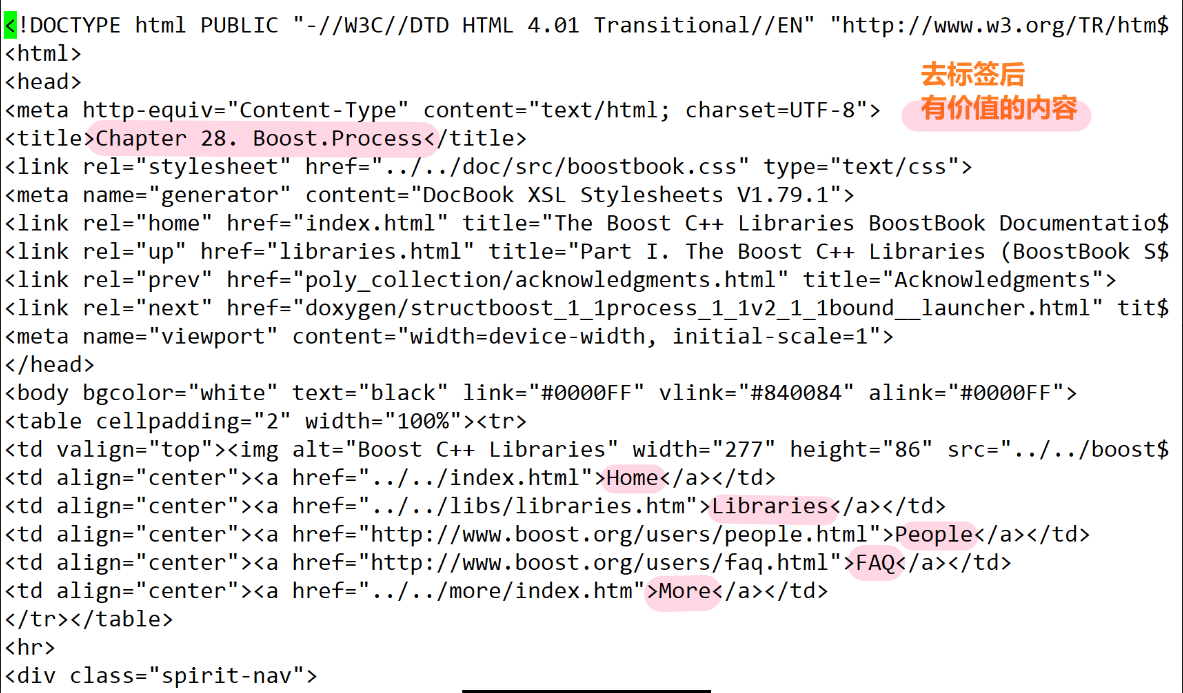
- 退出 nano 的方法: Ctrl + X 。做了修改并且想要保存,输入 Y(是),不保存,直接按 N(否)然后回车
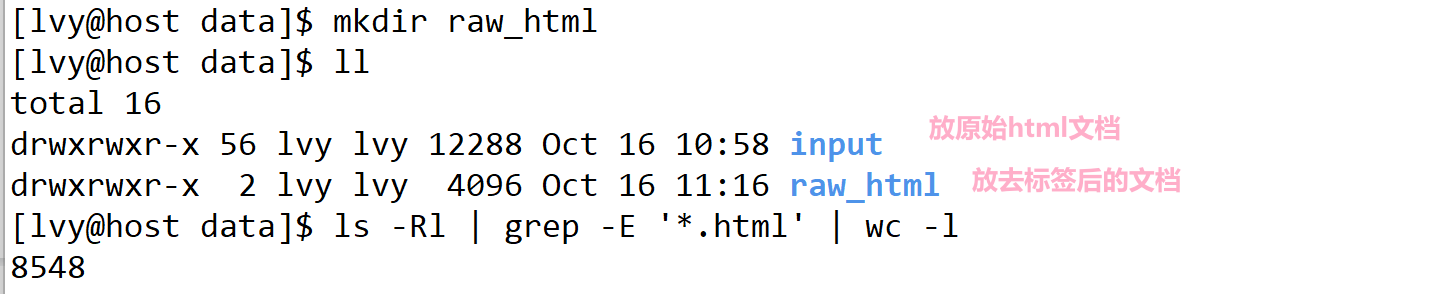
- 我们在 data目录 下的 raw_html目录下 创建有一个 raw.txt文件,用来存储干净的数据文档
- <> : html的标签,这个标签对我们进行搜索是没有价值的,需要去掉这些标签,一般标签都是成对出现的!但是也有单独出现的,我们也是不需要的。
采用下面的方案:
- 写入文件中,一定要考虑下一次在读取的时候,也要方便操作!
- 类似:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...
- 方便我们getline(ifsream, line),直接获取文档的全部内容:title\3content\3url
- 文件内按照 \3 作为分割符,每个文件再按照 \n 进行区分
note: vim 下的中文注释:ctrl+space
编码
在 Boost_Searcher 目录下创建 parser.cpp 文件开始编写框架
三步走:
- 第⼀步EnumFile(src_path, &files_list): 递归式的把每个html⽂件名带路径,保存到文件 files_list中,⽅便后期进⾏⼀个⼀个的 ⽂件进⾏读取(预处理
- 第⼆步ParseHtml(files_list, &results): 按照files_list读取每个⽂件,并进⾏解析
- 第三步SaveHtml(results, output): 把解析完毕的各个⽂件内容,写⼊到output,按照\3作为每个⽂档的分割符
#include <iostream>
#include <string>
#include <vector>// 首先我们肯定会读取文件,所以先将文件的路径名 罗列出来
// 将 数据源的路径 和 清理后干净文档的路径 定义好const std::string src_path = "data/input"; // 数据源的路径
const std::string output = "data/raw_html/raw.txt"; // 清理后干净文档的路径//DocInfo --- 文件信息结构体
typedef struct DocInfo
{std::string title; //文档的标题std::string content; //文档的内容std::string url; //该文档在官网当中的url
}DocInfo_t;// 命名规则
// const & ---> 输入
// * ---> 输出
// & ---> 输入输出//把每个html文件名带路径,保存到files_list中
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list);//按照files_list读取每个文件的内容,并进行解析
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results);//把解析完毕的各个文件的内容写入到output
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);int main()
{std::vector<std::string> files_list; // 将所有的 html文件名保存在 files_list 中// 第一步:递归式的把每个html文件名带路径,保存到files_list中,方便后期进行一个一个的文件读取// 从 src_path 这个路径中提取 html文件,将提取出来的文件存放在 string 类型的 files_list 中if(!EnumFile(src_path, &files_list)) //EnumFile--枚举文件{std::cerr << "enum file name error! " << std::endl;return 1;}return 0;// 第二步:从 files_list 文件中读取每个.html的内容,并进行解析std::vector<DocInfo_t> results;// 从 file_list 中进行解析,将解析出来的内容存放在 DocInfo 类型的 results 中if(!ParseHtml(files_list, &results))//ParseHtml--解析html{std::cerr << "parse html error! " << std::endl;return 2;}// 第三部:把解析完毕的各个文件的内容写入到output,按照 \3 作为每个文档的分隔符// 将 results 解析好的内容,直接放入 output 路径下if(!SaveHtml(results, output))//SaveHtml--保存html{std::cerr << "save html error! " << std::endl;return 3;}return 0;
}
主要实现:枚举文件、解析html文件、保存html文件三个工作。
这三个工作完成是需要我们使用boost库当中的方法的,我们需要安装一下boost的开发库:
通过如上命令,我是已经安装过啦~
下图就是我们接下来编写代码需要用到的 boost库 当中的 filesystem方法。
1.枚举文件 EnumFile
- 使用 boost 枚举文件名
//在原有的基础上添加这个头文件
#include <boost/filesystem.hpp>//把每个html文件名带路径,保存到files_list中
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{// 简化作用域的书写namespace fs = boost::filesystem;fs::path root_path(src_path); // 定义一个path对象,枚举文件就从这个路径下开始// 判断路径是否存在if(!fs::exists(root_path)){std::cerr << src_path << " not exists" << std::endl;return false;}// 对文件进行递归遍历fs::recursive_directory_iterator end; // 定义了一个空的迭代器,用来进行判断递归结束 -- 相当于 NULLfor(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){// 判断指定路径是不是常规文件,如果指定路径是目录或图片直接跳过if(!fs::is_regular_file(*iter)){continue;}// 如果满足了是普通文件,还需满足是.html结尾的// 如果不满足也是需要跳过的// ---通过iter这个迭代器(理解为指针)的一个path方法(提取出这个路径)// ---然后通过extension()函数获取到路径的后缀if(iter->path().extension() != ".html"){continue;}//std::cout << "debug: " << iter->path().string() << std::endl; // 测试代码// 走到这里一定是一个合法的路径,以.html结尾的普通网页文件files_list->push_back(iter->path().string()); // 将所有带路径的html保存在files_list中,方便后续进行文本分析}return true;
}- makefile 中连接 boost 库
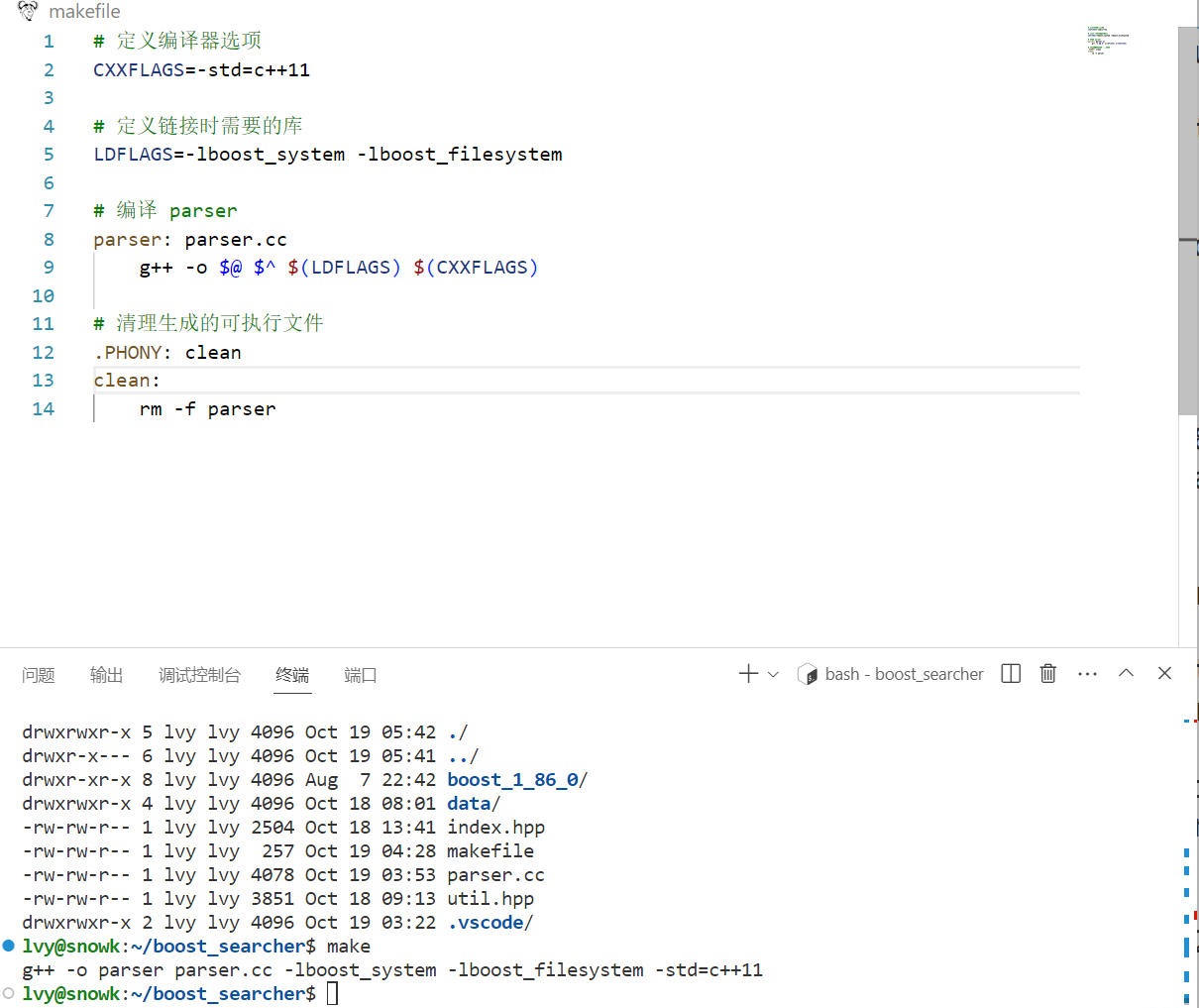
查看对外部库的连接:

运行:
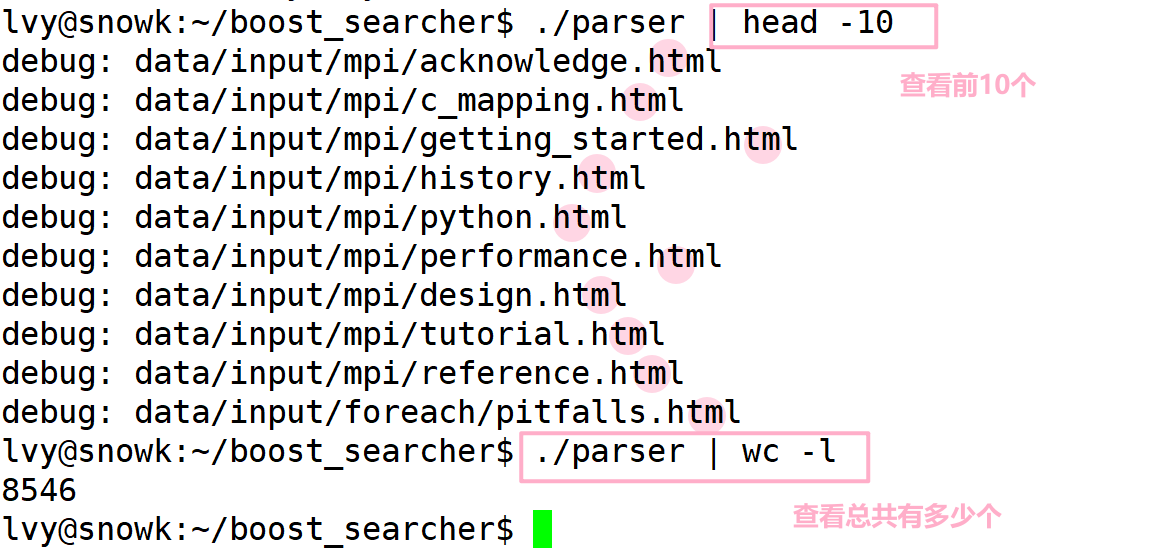
- 成功提取出了 html 文件~
- 测试成功后,将测试代码注释掉哦!
- 运行测试成功,继续编写下一个模块
2.去标签
ParseHtml()
解析html文件
- 读取刚刚枚举好的文件
- 解析html文件中的title
- 解析html文件中的content
- 解析html文件中的路径,构建url

- 函数建构
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{for(const std::string &file : files_list){// 1.读取文件,Read()std::string result;if(!ns_util::FileUtil::ReadFile(file, &result)){continue;}// 2.解析指定的文件,提取titleDocInfo_t doc;if(!ParseTitle(result, &doc.title)){continue;}// 3.解析指定的文件,提取contentif(!ParseContent(result, &doc.content)){continue;}// 4.解析指定的文件路径,构建urlif(!ParseUrl(file, &doc.url)){continue; }// 到这里,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面results->push_back(std::move(doc)); // 本质会发生拷贝,效率肯能会比较低,这里我们使用move后的左值变成了右值,去调用push_back的右值引用版本}return true;
}主要完成 4件事:
①根据路径名依次读取文件内容,②提取title,③提取content,④构建url。
2.1读取文件ReadFile()
- 遍历 files_list 中存储的文件名,从中读取文件内容到 result 中,由函数
ReadFile()完成该功能。该函数定义于头文件 util.hpp的类 FileUtil中。
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <vector>namespace ns_util
{class FileUtil{ public:static bool ReadFile(const std::string &file_path, std::string *out){std::ifstream in(file_path, std::ios::in);if(!in.is_open()){std::cerr << "open file " << file_path << " error" << std::endl;return false;}std::string line;while(std::getline(in, line))
//如何理解getline读取到文件结束呢??getline的返回值是一个&,while(bool), 本质是因为重载了强制类型转化{*out += line;}in.close();return true;}};
}⭕ 重点理解:C++的流读取 && getline 的使用
2.2 提取title ——
ParseTitle()
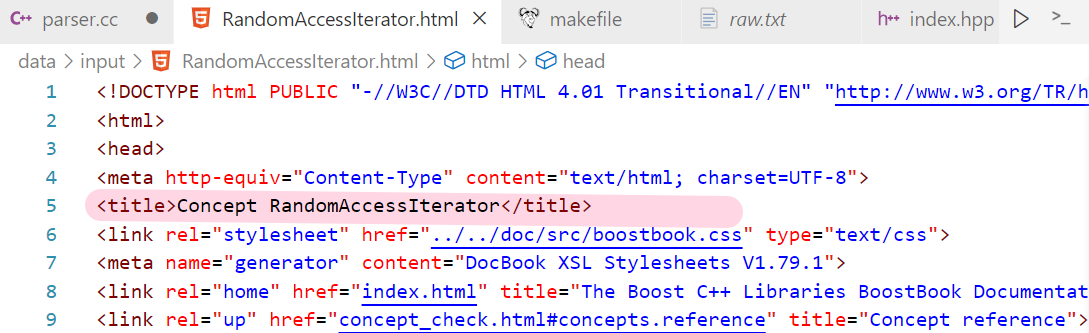
- 可以发现<title>标题</title> 构成的
- find(<title>)就能找到这个标签的左尖括号的位置
- 然后加上<title>的长度,此时就指向了标题的起始位置
- 同理,再去找到</title>的左尖括号,最后截取子串;
这里需要依赖函数 —— bool ParseTitle(const std::string& file,&doc.title),
//解析title
static bool ParseTitle(const std::string& file,std::string* title)
{// 查找 <title> 位置std::size_t begin = file.find("<title>");if(begin == std::string::npos){return false;}// 查找 </title> 位置std::size_t end = file.find("</title>");if(end == std::string::npos){return false;}// 计算中间的距离,截取中间的内容begin += std::string("<title>").size();if(begin > end){return false;}*title = file.substr(begin, end - begin);return true;
}2.3 提取content--
ParseContent()
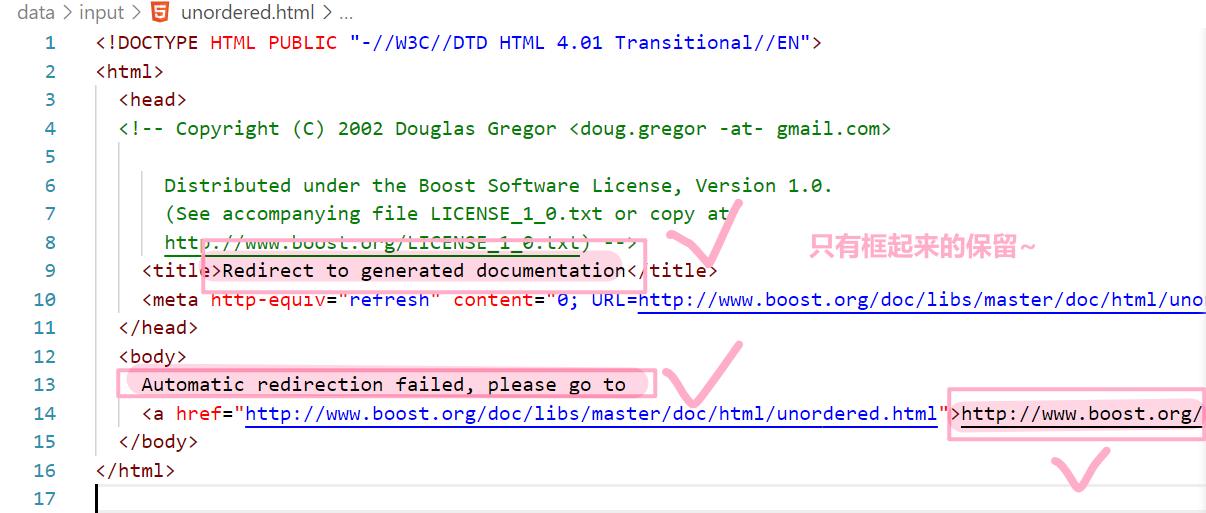
用一个简易的状态机来完成,状态机包括两种状态:LABLE(标签)和CONTENT(内容);
- 起始肯定是标签,我们逐个字符进行遍历判断
- 如果遇到“>”,表明下一个即将是内容了,我们将状态机置为CONTENT,接着将内容保存起来
- 如果此时遇到了“<”,表明到了标签了,我们再将状态机置为LABLE;
- 不断的循环,知道遍历结束;
//去标签 -- 数据清洗
static bool ParseContent(const std::string& file,std::string* content)
{//去标签,基于一个简易的状态机enum status // 枚举两种状态{ LABLE, // 标签CONTENT // 内容};enum status s = LABLE; // 刚开始肯定会碰到 "<" 默认状态为 LABLEfor(char c : file){// 检测状态switch(s){case LABLE:if(c == '>') s = CONTENT;break;case CONTENT:if(c == '<') s = LABLE;else {// 我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后的文本的分隔符if(c == '\n') c = ' ';content->push_back(c);}break;default:break;}}return true;
}2.4 解析 html 的 url
- boost库 在网页上的 url,和我们 下载的文档的路径 是 有对应关系的
探寻官方文档路径和我们路径的关系,以 Accumulators.html 为例

在我们路径下的查找
![]()
在 input 中

我们之前已经定义好了两个路径嘛!源数据路径 和 清理后干净文档的路径
1. 拿 官网的部分网址作为 头部的 url
- url_head = "https://www.boost.org/doc/libs/1_86_0/doc/html"
2. 将我们项目的路径 data/input 删除后得到 /accumulators.html;
- url_tail = [data/input(删除)] /accumulators.html -> url_tail = /accumulators.html;
3. 将 url_head + url_tail == 官网的 url
//构建官网url :url_head + url_tail
static bool ParseUrl(const std::string& file_path,std::string* url)
{std::string url_head = "https://www.boost.org/doc/libs/1_85_0/doc/html"; std::string url_tail = file_path.substr(src_path.size());//将data/input截取掉 *url = url_head + url_tail;//拼接return true;
}到这里我们写的 ParseHtml 解析部分就已经写完啦,那定是我们要先测试一下它的正确性啦!
测试
- 向源代码中加入了 ShowDoc 测试代码,测试完注释掉即可
// for debug
void ShowDoc(const DocInfo_t& doc)
{std::cout<<"title: "<<doc.title<<std::endl;std::cout<<"content: "<<doc.content<<std::endl;std::cout<<"url: "<<doc.url<<std::endl;
}//按照files_list读取每个文件的内容,并进行解析
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{// 首先在解析文件之前,肯定需要 遍历 读取文件for(const std::string &file : files_list){// 1.读取文件,Read() --- 将文件的全部内容全部读出,放到 result 中std::string result;if(!ns_util::FileUtil::ReadFile(file, &result)){continue;}// 2.解析指定的文件,提取titleDocInfo_t doc;if(!ParseTitle(result, &doc.title)){continue;}// 3.解析指定的文件,提取contentif(!ParseContent(result, &doc.content)){continue;}// 4.解析指定的文件路径,构建urlif(!ParseUrl(file, &doc.url)){continue; }// 到这里,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面results->push_back(std::move(doc)); // 本质会发生拷贝,效率肯能会比较低,这里我们使用move后的左值变成了右值,去调用push_back的右值引用版本// for debug -- 在测试的时候,将上面的代码改写为 results->push_back(doc);ShowDoc(doc);break; // 只截取一个文件打印}return true;
}接下来就可以 make , 然后运行:
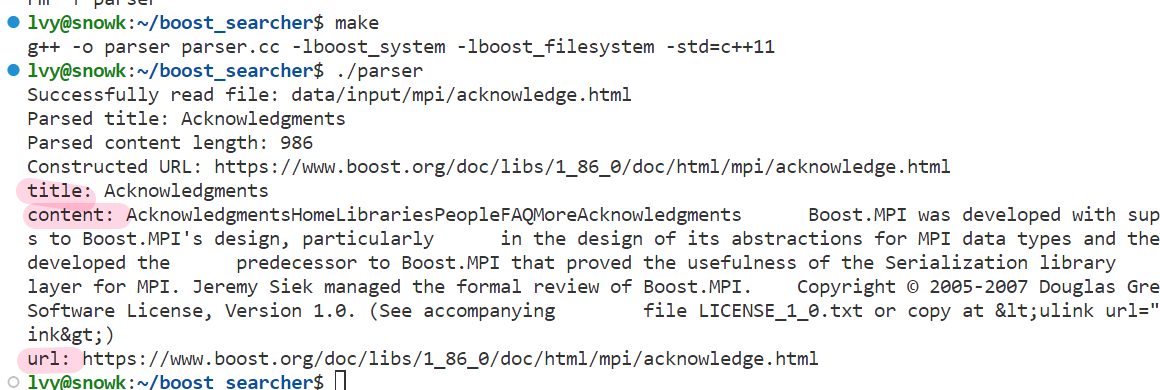
- 为了进一步验证正确性,我们可以将网页复制下来,在浏览器中打开,看是否成功
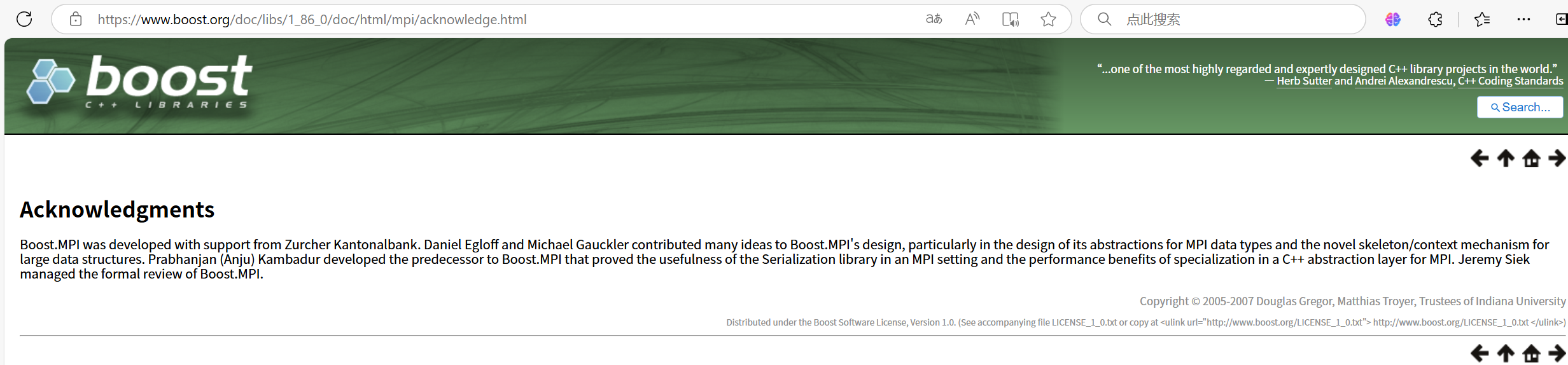
成功ヾ(≧▽≦*)o
对于项目写有一个重点,就是做好对错误的处理~
遇见的一个小问题:
之前的服务器 free -h 查看后发现,在 vscode 下内存有点不够用,然后换了一台朋友的服务器

所以要传一下之前写的文件
使用SCP命令在两台Linux服务器之间传输文件
适用场景
当你需要将大文件从一台服务器直接传输到另一台服务器,而不想通过本地中转时,可以使用scp(secure copy)命令。
命令格式
scp -r [源文件路径] [目标用户名]@[目标IP]:[目标路径]-r:递归复制整个目录。[源文件路径]:要传输的文件或目录的完整路径。[目标用户名]:接收文件服务器上的用户名。[目标IP]:接收文件服务器的IP地址。[目标路径]:在接收方服务器上存放文件的路径。
示例
假设你要把位于/usr/local/testFile/目录下的所有内容复制到IP为100.10.20.30的目标服务器的/root/目录下,并且目标服务器的登录用户名是root,那么你可以运行以下命令:
scp -r /usr/local/testFile/* root@100.10.20.30:/root/执行这个命令后,系统会提示你输入目标服务器的用户密码。
将scp任务放入后台执行
如果文件量很大,传输可能需要很长时间。为了不阻塞终端,可以将scp进程放到后台执行:
- 暂停任务:按下
Ctrl + Z暂停当前正在执行的scp任务。 - 查看任务:使用
jobs查看已暂停的任务及其编号。 - 后台继续执行:使用
bg %a命令让任务在后台继续执行,其中a是jobs返回的任务编号。 - 再次检查状态:再次运行
jobs可以看到任务现在处于“Running”状态,表示它正在后台执行。
这样,即使关闭终端窗口,文件传输也会继续进行,直到完成。如果你想要终止后台任务,可以使用kill命令加上相应的进程ID。
请注意,在执行任何文件传输操作之前,请确保你有权限访问源和目标服务器,并且目标路径对于指定的用户是可写的。

相关文章:
[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp
目录 一、前言 二、项目的相关背景 三、搜索引擎的宏观原理 四、搜索引擎技术栈和项目环境 五、正排索引 VS 倒排索引--原理 正排索引 分词 倒排索引 六、编写数据去除标签和数据清洗模块 Parser 1.数据准备 parser 编码 1.枚举文件 EnumFile 2.去标签ParseHtml(…...

PL/I语言的起源?有C语言,有B语言和A语言吗?为什么shell脚本最开始可能有#!/bin/bash字样?为什么不支持嵌套注释?
PL/I语言的起源 在20世纪50~60年代,当时主流的编程语言是COBOL/FORTRAN/ALGOL等,IBM想要设计一门通用的编程语言,已有的编程语言无法实现此要求,故想要设计一门新语言,即是PL/I. PL/I是Programming Language/One的缩写…...

gin入门教程(3):创建第一个 HTTP 服务器
首先设置golang github代理,可解决拉取git包的时候,无法拉取的问题: export GOPROXYhttps://goproxy.io再查看自己的go版本: go version我这里的版本是:go1.23.2 linux/arm64 准备工作做好之后就可以进行开发了 3.…...

Vue+ECharts+iView实现大数据可视化大屏模板
Vue数据可视化 三个大屏模板 样式还是比较全的 包括世界地图、中国地图、canvas转盘等 项目演示: 视频: vue大数据可视化大屏模板...

el-table 表格设置必填项
el-table 表格设置必填项 要在 el-table 中集成 el-form 来设置必填项,并进行表单验证,可以使用 Element UI 提供的表单验证功能。下面是一个详细的示例,展示了如何在 el-table 中使用 el-form 来设置必填项,并进行验证。 示例代…...

vivo 轩辕文件系统:AI 计算平台存储性能优化实践
在早期阶段,vivo AI 计算平台使用 GlusterFS 作为底层存储基座。随着数据规模的扩大和多种业务场景的接入,开始出现性能、维护等问题。为此,vivo 转而采用了自研的轩辕文件系统,该系统是基于 JuiceFS 开源版本开发的一款分布式文件…...

Vue学习笔记(四)
事件处理 我们可以使用 v-on 指令 (通常缩写为 符号) 来监听 DOM 事件,并在触发事件时执行一些 JavaScript。用法为 v-on:click"methodName" 或使用快捷方式 click"methodName" 事件处理器的值可以是: 内联事件处理器࿱…...

发送短信,验证码
短信 注册阿里云的账号 开通短信服务 测试短信服务是否可用 导入jar <!-- 短信相关 --><dependency><groupId>com.aliyun</groupId><artifactId>aliyun-java-sdk-core</artifactId><version>4.6.0</version><…...

国内大语言模型哪家更好用?
大家好,我是袁庭新。 过去一年,AI大语言模型在爆发式增长,呈现百家争鸣之态。国内外相关厂商积极布局,并相继推出自家研发的智能化产品。 我在工作中已习惯借助AI来辅助完成些编码、创作、文生图等任务,甚至对它们产…...

OTP一次性密码、多因子认证笔记
文章目录 双因子认证(多因子认证)otp算法(ONE-TIME PASSWORD)otp算法大概分为几部 otp的机制服务端客户端(app端)两种主流算法otp流程图 otp是通用的吗 手机验证码天天在用,但是居然不知道这个是otp,伤自尊了,必须弄清原理。 先要知道几个概念…...

玉米生长阶段检测系统源码&数据集全套:改进yolo11-dysample
改进yolo11-DLKA等200全套创新点大全:玉米生长阶段检测系统源码&数据集全套 1.图片效果展示 项目来源 人工智能促进会 2024.10.24 注意:由于项目一直在更新迭代,上面“1.图片效果展示”和“2.视频效果展示”展示的系统图片或者视…...

【机器学习】决策树算法
目录 一、决策树算法的基本原理 二、决策树算法的关键概念 三、决策树算法的应用场景 四、决策树算法的优化策略 五、代码实现 代码解释: 在机器学习领域,决策树算法是一种简单直观且易于理解的分类和回归方法。它通过学习数据特征和决策规则&#…...

P2818 天使的起誓
天使的起誓 题目描述 Tenshi 非常幸运地被选为掌管智慧之匙的天使。在正式任职之前,她必须和其他新当选的天使一样要宣誓。 宣誓仪式是每位天使各自表述自己的使命,他们的发言稿放在 n n n 个呈圆形排列的宝盒中。这些宝盒按顺时针方向被编上号码 1…...

数字信号处理实验简介
数字信号处理(Digital Signal Processing,简称DSP)是电子工程、通信、计算机科学等领域中的一个重要分支,它涉及到对离散时间信号进行分析、处理和合成的理论和方法。数字信号处理课程的实验环节通常旨在帮助学生将理论知识应用于实际问题中,通过实践加深对DSP概念和技术的…...

Flask-SQLAlchemy 组件
一、ORM 要了解 ORM 首先了解以下概念。 什么是持久化 持久化 (Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中,…...

Could not retrieve mirrorlist http://mirrorlist.centos.org错误解决方法
文章目录 背景解决方法 背景 今天在一台新服务器上安装nginx,在这个过程中需要安装相关依赖,在使用yum install命令时,发生了以下报错内容: Could not retrieve mirrorlist http://mirrorlist.centos.org/?release7&archx8…...

最新PHP网盘搜索引擎系统源码 附教程
最新PHP网盘搜索引擎系统源码 附教程,这是一个基于thinkphp5.1MySQL开发的网盘搜索引擎,可以批量导入各大网盘链接,例如百度网盘、阿里云盘、夸克网盘等。 功能特点:网盘失效检测,后台管理功能,网盘链接管…...

SpringBoot面试热题
1.Spring IOC(控制反转)和AOP(面相切面编程)的理解 控制反转意味着将对象的控制权从代码中转移到Spring IOC容器。 本来是我们自己手动new出来的对象,现在则把对象交给Spring的IOC容器管理,IOC容器作为一个对象工厂,管理对象的创建和依赖关系…...

ASP.NET Core8.0学习笔记(二十三)——EF Core自引用
一、什么是自引用 1.在常见的树状目录中,其结构如下: 每一个菜单可能有父级菜单,也可能有子菜单。但是无论是哪一级菜单,他们都是同属于菜单对象。将这个菜单对象使用代码进行描述: 在上面的代码中,主…...

springboot童装销售管理系统-计算机毕业设计源码92685
摘 要 童装销售管理系统是为童装店商家提供的在线销售管理系统,本系统的研发设计能够增加童装店商家的童装宣传和推广,提升客流量和订单量,增加商家的营业收益。原有的童装品销售系统管理采用手工管理的方式,各种童装品宣传和订单…...

拆解RTX4090 24G GPU服务器,一文摸清硬件搭配逻辑
RTX4090 24G GPU凭借NVIDIA Ada Lovelace架构优势,以16384个CUDA核心、24GB GDDR6X显存、1008GB/s显存带宽的核心参数,成为个人开发者、中小企业、科研机构的首选算力核心,广泛应用于大模型训练、AI推理、工业仿真、视频渲染等场景。据IDC 20…...

终极指南:3步快速备份QQ空间完整历史记录,永久保存青春回忆
终极指南:3步快速备份QQ空间完整历史记录,永久保存青春回忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 还在为QQ空间里那些珍贵的青春记忆可能随时消失而担忧…...

如何通过ImageToSTL实现图像三维化?解锁创意设计新可能
如何通过ImageToSTL实现图像三维化?解锁创意设计新可能 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side.…...

社区医院信息平台信息管理系统源码-SpringBoot后端+Vue前端+MySQL【可直接运行】
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 随着信息技术的快速发展,医疗行业对信息化管理的需求日益增长。传统的社区医院管理模式存在信息孤岛、数据冗余、效率低下等问题&#…...
)
WinForms界面美化:用SunnyUI的UILight控件做个状态指示灯(附完整代码)
WinForms界面美化实战:用SunnyUI的UILight控件打造专业状态指示灯 在桌面应用开发中,状态指示是用户界面不可或缺的元素。传统的WinForms控件往往显得单调乏味,而SunnyUI的UILight控件为我们提供了一种简单高效的解决方案。这个圆形指示灯控…...

Qwen3-14B制造业工艺文档生成:设备操作SOP自动编写与版本管理
Qwen3-14B制造业工艺文档生成:设备操作SOP自动编写与版本管理 1. 引言:制造业文档自动化的迫切需求 在制造业生产现场,设备操作标准作业程序(SOP)是确保产品质量和生产安全的关键文档。传统SOP编写方式面临三大痛点: 人力成本高…...

Phi-4-mini-reasoningGPU算力适配:A10/A100/T4多卡环境下的推理吞吐调优
Phi-4-mini-reasoning GPU算力适配:A10/A100/T4多卡环境下的推理吞吐调优 1. 模型特性与部署概述 Phi-4-mini-reasoning 是一款专注于推理任务的文本生成模型,特别擅长处理数学题、逻辑题等需要多步分析和简洁结论输出的场景。与通用聊天模型不同&…...
Pixel Aurora Engine基础教程:8-BIT音效视觉化——将MIDI转像素动态图初探
Pixel Aurora Engine基础教程:8-BIT音效视觉化——将MIDI转像素动态图初探 1. 认识Pixel Aurora引擎 Pixel Aurora是一款专为像素艺术创作设计的AI绘图工作站,它将现代AI技术与复古游戏美学完美融合。这款引擎最独特之处在于能将音乐数据转化为动态像素…...

OpenClaw技能共享:将Qwen2.5-VL-7B定制插件发布到ClawHub
OpenClaw技能共享:将Qwen2.5-VL-7B定制插件发布到ClawHub 1. 为什么需要共享OpenClaw技能 去年我开发了一个基于Qwen2.5-VL-7B的图片分析插件,能够自动识别截图中的UI元素并生成操作指令。当我发现这个插件在团队内部被反复复制粘贴使用时,…...

Qwen3-VL-2B-Instruct保姆级教程:视觉对话机器人部署
Qwen3-VL-2B-Instruct保姆级教程:视觉对话机器人部署 1. 环境准备与快速部署 想要体验AI视觉对话的神奇能力吗?Qwen3-VL-2B-Instruct让你不用昂贵的显卡也能拥有一个能"看懂"图片的智能助手。这个教程将手把手带你完成整个部署过程ÿ…...