Java避坑案例 - 高并发场景下的分布式缓存策略
文章目录
- 概述
- 缓存常见问题及解决方案
- 把 Redis 当作数据库
- 常用的数据淘汰策略
- 如何选择合适的驱逐算法
- 缓存雪崩
- 问题复现
- 解决方案
- 缓存击穿(热点缓存失效)
- 问题复现
- 解决方案
- 缓存穿透
- 问题复现
- 解决方案
- 缓存穿透 vs 缓存击穿
- 缓存与数据库的一致性
- 先更新缓存,再更新数据库(不推荐)
- 先更新数据库,再更新缓存 (不推荐)
- 先删除缓存,再更新数据库,访问的时候按需加载数据到缓存(不推荐)
- 先更新数据库,再删除缓存,访问的时候按需加载数据到缓存 (推荐)
- 小结

概述
通常我们会使用更快的介质(比如内存)作为缓存,来解决较慢介质(比如磁盘)读取数据
慢的问题,缓存是用空间换时间,来解决性能问题的一种架构设计模式。
更重要的是,磁盘上存储的往往是原始数据,而缓存中保存的可以是面向呈现的数据。这样一来,缓存不仅仅是加快了 IO,还可以减少原始数据的计算工作
使用 Redis 或其他缓存系统的确能有效解决系统性能问题,但设计和实现缓存策略时必须仔细考虑潜在问题,否则会适得其反。让我们具体看看这些常见的缓存问题及解决方案。
缓存常见问题及解决方案
把 Redis 当作数据库
通常,我们会使用 Redis 等分布式缓存数据库来缓存数据,但是千万别把 Redis 当做数据库来使用。因为 Redis 中数据消失导致业务逻辑错误,并且因为没有保留原始数据,业务都无法恢复
因此,把 Redis 用作缓存,我们需要注意两点。
-
第一,从客户端的角度来说,缓存数据的特点一定是有原始数据来源,且允许丢失,即使设置的缓存时间是 1 分钟,在 30 秒时缓存数据因为某种原因消失了,我们也要能接受。当数据丢失后,我们需要从原始数据重新加载数据,不能认为缓存系统是绝对可靠的,更不能认为缓存系统不会删除没有过期的数据。
-
第二,从 Redis 服务端的角度来说,缓存系统可以保存的数据量一定是小于原始数据的。首先,我们应该限制 Redis 对内存的使用量,也就是设置
maxmemory参数;其次,我们应该根据数据特点,明确 Redis 应该以怎样的算法来驱逐数据
常用的数据淘汰策略
allkeys-lru,针对所有 Key,优先删除最近最少使用的 Key;volatile-lru,针对带有过期时间的 Key,优先删除最近最少使用的 Key;volatile-ttl,针对带有过期时间的 Key,优先删除即将过期的 Key(根据 TTL 的值);allkeys-lfu(Redis 4.0 以上),针对所有 Key,优先删除最少使用的 Key;volatile-lfu(Redis 4.0 以上),针对带有过期时间的 Key,优先删除最少使用的 Key
这些算法是 Key 范围 +Key 选择算法的搭配组合,其中范围有
allkeys和volatile两种,算法有LRU、TTL 和 LFU三种。
如何选择合适的驱逐算法
首先,从算法角度来说,Redis 4.0 以后推出的 LFU 比 LRU 更“实用”。
如果一个 Key 访问频率是 1 天一次,但正好在 1 秒前刚访问过,那么 LRU 可能不会选择优先淘汰这个 Key,反而可能会淘汰一个 5 秒访问一次但最近 2 秒没有访问过的 Key,而 LFU 算法不会有这个问题。而 TTL 会比较“头脑简单”一点,优先删除即将过期的 Key,但有可能这个 Key 正在被大量访问
然后,从 Key 范围角度来说,
allkeys可以确保即使 Key 没有 TTL 也能回收,如果使用的时候客户端总是“忘记”设置缓存的过期时间,那么可以考虑使用这个系列的算法。volatile会更稳妥一些,万一客户端把 Redis 当做了长效缓存使用,只是启动时候初始化一
次缓存,那么一旦删除了此类没有 TTL 的数据,可能就会导致客户端出错
所以,不管是使用者还是管理者都要考虑 Redis 的使用方式,使用者需要考虑应该以缓存的姿势来使用 Redis,管理者应该为 Redis 设置内存限制和合适的驱逐策略,避免出现 OOM。
缓存雪崩
问题:大量缓存集中在某个时间段失效,导致瞬时大量请求涌入数据库,可能引发系统崩溃。
问题复现
/*** 在Bean初始化完成后执行的方法,用于错误的初始化缓存* 此方法的目的是预热缓存,将数据库中的城市信息加载到Redis中*/
@PostConstruct
public void badInit() {// 使用Stream API循环将数据库中的城市信息加载到Redis缓存中 , 所有缓存数据有效期30秒IntStream.rangeClosed(1, 1000).forEach(i -> stringRedisTemplate.opsForValue().set("city" + i, getCityFromDb(i), 30, TimeUnit.SECONDS));// 日志记录缓存初始化完成log.info("Cache init finished");// 使用单线程调度执行器定期执行任务,记录数据库查询每秒请求数(QPS)Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {// 日志记录当前QPS,并重置计数器log.info("DB QPS : {}", atomicInteger.getAndSet(0));}, 0, 1, TimeUnit.SECONDS);
}private String getCityFromDb(int cityId) {atomicInteger.incrementAndGet();return "citydata" + System.currentTimeMillis();}/*** 根据城市ID获取城市信息* 该方法首先尝试从Redis缓存中获取城市信息,如果未命中,则从数据库中查询* 使用缓存的目的在于减少数据库的访问压力,提高响应速度* * @return 城市信息字符串,如果找不到则返回空字符串*/
@GetMapping("city")
public String city() {// 使用ThreadLocalRandom生成一个1到1000之间的随机数作为IDint id = ThreadLocalRandom.current().nextInt(1000) + 1;// 构造Redis中的键名String key = "city" + id;// 尝试从Redis中获取城市信息String data = stringRedisTemplate.opsForValue().get(key);// 如果Redis中没有该城市的信息,则从数据库中查询if (data == null) {// 从数据库中获取城市信息data = getCityFromDb(id);// 如果数据库中查到了城市信息,则将其存入Redis缓存中,有效期30秒if (!StringUtils.isEmpty(data))stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);}// 返回获取到的城市信息return data;
}使用 wrk 工具,设置 10 线程 10 连接压测 接口
wrk -c10 -t10 -d 100s http://localhost:12345/cacheinvalid/city
启动程序 30 秒后缓存过期,回源的数据库 QPS 最高达到了 700 多

解决方案
- 设置缓存过期时间的随机性:避免大量缓存同时失效。目的是差异化缓存过期时间,不要让大量的 Key 在同一时间过期
/*** 初始化城市缓存的方法* 该方法使用@PostConstruct注解标记,表示在依赖注入完成后执行该方法* 它通过模拟数据库查询并使用Redis缓存结果来初始化缓存* 此外,它还设置了一个定时任务来定期记录数据库查询的每秒请求数量(QPS)*/
@PostConstruct
public void goodInit1() {// 缓存的过期时间是30秒+10秒内的随机延迟IntStream.rangeClosed(1, 1000).forEach(i -> stringRedisTemplate.opsForValue().set("city" + i, getCityFromDb(i), 30 + ThreadLocalRandom.current().nextInt(10), TimeUnit.SECONDS));// 日志记录缓存初始化完成log.info("Cache init finished");// 创建一个单线程的ScheduledExecutorService,定时执行任务Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {// 日志记录每秒的数据库查询数量(QPS),并重置计数器log.info("DB QPS : {}", atomicInteger.getAndSet(0));}, 0, 1, TimeUnit.SECONDS);
}
-
多级缓存策略:在缓存服务器或节点出现问题时,系统可以从其他层次的缓存获取数据。
-
限流和降级:在系统负载过高时,可以使用限流机制,或短暂返回默认数据以确保系统稳定。
-
缓存不过期:让缓存不主动过期。初始化缓存数据的时候设置缓存永不过期,然后启动一个后台线程 30 秒一次定时把所有数据更新到缓存,而且通过适当的休眠,控制从数据库更新数据的频率,降低数据库压力
/*** 在Bean初始化完成后执行的方法* 该方法用于初始化缓存,并定期更新缓存中的城市信息* 同时,定期记录数据库查询每秒请求数(QPS)*/
@PostConstruct
public void goodInit2() throws InterruptedException {// 创建一个计数器,用于等待缓存初始化完成CountDownLatch countDownLatch = new CountDownLatch(1);// 创建一个定时任务,定期更新缓存Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {// 遍历1到1000,从数据库获取城市信息,并存入Redis缓存IntStream.rangeClosed(1, 1000).forEach(i -> {String data = getCityFromDb(i);try {// 模拟处理时间TimeUnit.MILLISECONDS.sleep(20);} catch (InterruptedException e) {// 异常处理}// 如果获取到的城市信息不为空,则存入缓存if (!StringUtils.isEmpty(data)) {stringRedisTemplate.opsForValue().set("city" + i, data);}});// 日志输出缓存更新完成信息log.info("Cache update finished");// 计数器减一,表示缓存初始化完成countDownLatch.countDown();}, 0, 30, TimeUnit.SECONDS);// 创建另一个定时任务,定期记录数据库QPSExecutors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {// 日志输出当前数据库QPS,并重置计数器log.info("DB QPS : {}", atomicInteger.getAndSet(0));}, 0, 1, TimeUnit.SECONDS);// 等待计数器归零,确保缓存初始化完成后再继续执行countDownLatch.await();
}
缓存永不过期,同样需要在查询的时候,确保有回源的逻辑。 我们无法确保缓存系统中的数据永不丢失
缓存击穿(热点缓存失效)
问题:某个热点数据在过期瞬间,大量请求同时访问,导致请求集中打到数据库。
在某些 Key 属于极端热点数据,且并发量很大的情况下,如果这个 Key 过期,可能会在某个瞬间出现大量的并发请求同时回源,相当于大量的并发请求直接打到了数据库。这种情况,就是我们常说的缓存击穿或缓存并发问题。
问题复现
在程序启动的时候,初始化一个热点数据到 Redis 中,过期时间设置为 5 秒,每隔 1 秒输出一下回源的 QPS
@PostConstructpublic void init() {stringRedisTemplate.opsForValue().set("hotsopt", getExpensiveData(), 5, TimeUnit.SECONDS);Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {log.info("DB QPS : {}", atomicInteger.getAndSet(0));}, 0, 1, TimeUnit.SECONDS);}private String getExpensiveData() {atomicInteger.incrementAndGet();return "important data";}@GetMapping("wrong")
public String wrong() {String data = stringRedisTemplate.opsForValue().get("hotsopt");if (StringUtils.isEmpty(data)) {data = getExpensiveData();// 重新加入缓存,过期时间还是5秒stringRedisTemplate.opsForValue().set("hotsopt", data, 5, TimeUnit.SECONDS);}return data;}测试:每隔 5 秒数据库都有 20 左右的 QPS

如果回源操作特别昂贵,那么这种并发就不能忽略不计
解决方案
-
设置随机过期时间:避免大量缓存同时失效,减少同时失效的可能性。
-
双层缓存策略:使用一级缓存(如 JVM 内存)和 Redis 二级缓存相结合。
-
互斥锁:在缓存失效时让第一个请求去加载数据,其他请求等待锁释放。 使用
Redisson来获取一个基于 Redis 的分布式锁,在查询数据库之前先尝试获取锁
/*** 处理获取热点数据请求* 此方法首先尝试从Redis中获取热点数据如果数据不存在,则使用Redis锁机制来防止缓存击穿* 它确保在同一时间只有一个线程可以获取和设置热点数据,从而避免了数据的重复计算* * @return 热点数据的字符串表示*/
@GetMapping("right")
public String right() {// 尝试从Redis中获取热点数据String data = stringRedisTemplate.opsForValue().get("hotsopt");// 如果数据为空,则尝试获取锁以安全地更新数据if (StringUtils.isEmpty(data)) {// 获取Redis锁对象RLock locker = redissonClient.getLock("locker");// 尝试获取锁如果成功,则再次检查数据是否存在if (locker.tryLock()) {try {// 再次检查,以防止在等待锁时数据已被其他线程设置data = stringRedisTemplate.opsForValue().get("hotsopt");if (StringUtils.isEmpty(data)) {// 如果数据仍然为空,则进行昂贵的数据获取操作,并将结果存入Redisdata = getExpensiveData();stringRedisTemplate.opsForValue().set("hotsopt", data, 5, TimeUnit.SECONDS);}} finally {// 释放锁,确保资源的可用性locker.unlock();}}}// 返回获取到的数据return data;
}
这样,可以把回源到数据库的并发限制在 1
在真实的业务场景下,不一定要这么严格地使用双重检查分布式锁进行全局的并发限制,因为这样虽然可以把数据库回源并发降到最低,但也限制了缓存失效时的并发。可以考虑的方式是:
- 方案一,使用进程内的锁进行限制,这样每一个节点都可以以一个并发回源数据库;
- 方案二,不使用锁进行限制,而是使用类似 Semaphore 的工具限制并发数,比如限制 为 10,这样既限制了回源并发数不至于太大,又能使得一定量的线程可以同时回源
缓存穿透
问题:缓存穿透是指查询的数据在缓存和数据库中都不存在,导致请求不断打到数据库,可能引发数据库压力骤增。
缓存回源的逻辑都是当缓存中查不到需要的数据时,回源到数据库查询。这里容易出现的一个漏洞是,缓存中没有数据不一定代表数据没有缓存,还有一种可能是原始数据压根就不存在
问题复现
数据库中只保存有 ID 介于 0(不含)和 10000(包含)之间的用户,如果从数据库查询 ID 不在这个区间的用户,会得到空字符串,所以缓存中缓存的也是空字符串。如果使用 ID=0 去压接口的话,从缓存中查出了空字符串,认为是缓存中没有数据回源查询,其实相当于每次都回源
@GetMapping("wrong")public String wrong(@RequestParam("id") int id) {String key = "user" + id;String data = stringRedisTemplate.opsForValue().get(key);//无法区分是无效用户还是缓存失效if (StringUtils.isEmpty(data)) {data = getCityFromDb(id);stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);}return data;}private String getCityFromDb(int id) {atomicInteger.incrementAndGet();//注意,只有ID介于0(不含)和10000(包含)之间的用户才是有效用户,可以查询到用户信息if (id > 0 && id <= 10000) return "userdata";//否则返回空字符串return "";}压测后数据库的 QPS 达到了几千

如果这种漏洞被恶意利用的话,就会对数据库造成很大的性能压力。这就是缓存穿透。
解决方案
- 缓存空值:将查询不到的结果(如
null)也缓存一段时间,避免重复查询。
对于不存在的数据,同样设置一个特殊的 Value 到缓存中,比如当数据库中查出的用户信息为空的时候,设置 NODATA 这样具有特殊含义的字符串到缓存中。这样下次请求缓存的时候还是可以命中缓存,即直接从缓存返回结果,不查询数据库
/*** 根据用户ID获取用户信息* 首先尝试从Redis中获取缓存数据,如果未命中,则从数据库中查询* 如果查询到数据,将其缓存到Redis中;如果未查询到数据,则缓存一个标识"NODATA"* 此方法有效减少了数据库的访问压力,提高了系统响应速度** @param id 用户ID,用于标识特定的用户信息* @return 用户信息字符串或"NODATA"标识*/
@GetMapping("right")
public String right(@RequestParam("id") int id) {// 构造Redis键值,用于存储和获取特定用户的缓存数据String key = "user" + id;// 尝试从Redis中获取用户信息String data = stringRedisTemplate.opsForValue().get(key);// 如果Redis中未缓存该用户信息,则从数据库中查询if (StringUtils.isEmpty(data)) {// 从数据库中获取用户信息data = getCityFromDb(id);// 如果查询到了用户信息,则将其缓存到Redis中if (!StringUtils.isEmpty(data)) {stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);} else {// 如果未查询到用户信息,则缓存一个标识"NODATA",防止穿透缓存stringRedisTemplate.opsForValue().set(key, "NODATA", 30, TimeUnit.SECONDS);}}// 返回获取到的用户信息或"NODATA"标识return data;
}这种方式可能会把大量无效的数据加入缓存中,如果担心大量无效数据占满缓存的话还可以考虑方案二,即使用布隆过滤器做前置过滤
- 布隆过滤器:使用布隆过滤器快速判断请求数据是否存在,防止无效查询进入数据库。
可以把所有可能的值保存在布隆过滤器中,从缓存读取数据前先过滤一次;
如果布隆过滤器认为值不存在,那么值一定是不存在的,无需查询缓存也无需查询数据库;
对于极小概率的误判请求,才会最终让非法 Key 的请求走到缓存或数据库
/*** 在Bean初始化完成后执行的方法* 该方法调度一个定时任务,每隔一秒执行一次,用于记录数据库查询每秒的查询次数(QPS)* 同时,初始化一个布隆过滤器,用于高效地检查元素是否存在*/
@PostConstruct
public void init() {// 定时任务,每隔一秒执行一次,用于记录数据库查询每秒的查询次数(QPS)Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {log.info("DB QPS : {}", atomicInteger.getAndSet(0));}, 0, 1, TimeUnit.SECONDS);// 初始化布隆过滤器,容量为10000,误判率为1%bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000, 0.01);// 将1到10000的整数添加到布隆过滤器中IntStream.rangeClosed(1, 10000).forEach(bloomFilter::put);
}/*** 根据用户ID获取用户信息* 首先使用BloomFilter检查用户ID是否可能存在于缓存中,以减少不必要的缓存查询* 如果可能存在于缓存中,则尝试从Redis中获取用户信息* 如果Redis中不存在该用户信息,则从数据库中查询,并将结果缓存到Redis中* * @param id 用户ID* @return 用户信息字符串,如果没有找到则返回空字符串*/
@GetMapping("right2")
public String right2(@RequestParam("id") int id) {String data = "";// 使用BloomFilter检查用户ID是否可能存在于缓存中if (bloomFilter.mightContain(id)) {String key = "user" + id;// 从Redis中尝试获取用户信息data = stringRedisTemplate.opsForValue().get(key);// 如果Redis中没有该用户信息,则从数据库中查询if (StringUtils.isEmpty(data)) {data = getCityFromDb(id);// 将从数据库中查询到的用户信息缓存到Redis中,设置过期时间为30秒stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);}}// 返回用户信息字符串return data;
}- 有效的参数校验:提前验证请求参数的合法性,避免恶意请求绕过缓存。
缓存穿透 vs 缓存击穿
- 缓存穿透是指,缓存没有起到压力缓冲的作用;
- 缓存击穿是指,缓存失效时瞬时的并发打到数据库
缓存与数据库的一致性
问题:在更新数据库数据后,缓存数据可能未同步更新,导致缓存与数据库的数据不一致。
在实际情况下,修改了原始数据后,考虑到缓存数据更新的及时性,我们可能会采用主动更新缓存的策略。这些策略可能是:
先更新缓存,再更新数据库(不推荐)
“先更新缓存再更新数据库”策略不可行。数据库设计复杂,压力集中,数据库因为超时等原因更新操作失败的可能性较大,此外还会涉及事务,很可能因为数据库更新失败,导致缓存和数据库的数据不一致。
先更新数据库,再更新缓存 (不推荐)
“先更新数据库再更新缓存”策略不可行。一是,如果线程 A 和 B 先后完成数据库更新,但更新缓存时却是 B 和 A 的顺序,那很可能会把旧数据更新到缓存中引起数据不一致;二是,我们不确定缓存中的数据是否会被访问,不一定要把所有数据都更新到缓存中去
先删除缓存,再更新数据库,访问的时候按需加载数据到缓存(不推荐)
“先删除缓存再更新数据库,访问的时候按需加载数据到缓存”策略也不可行。在并发的情况下,很可能删除缓存后还没来得及更新数据库,就有另一个线程先读取了旧值到缓存中,如果并发量很大的话这个概率也会很大
先更新数据库,再删除缓存,访问的时候按需加载数据到缓存 (推荐)
先更新数据库再删除缓存,访问的时候按需加载数据到缓存”策略是最好的 . 虽然在极端情况下,这种策略也可能出现数据不一致的问题,但概率非常低,基本可以忽略。举一个“极端情况”的例子,比如更新数据的时间节点恰好是缓存失效的瞬间,这时 A 先读取到了旧值,随后在 B 操作数据库完成更新并且删除了缓存之后,A 再把旧值加入缓存
需要注意的是,更新数据库后删除缓存的操作可能失败,如果失败则考虑把任务加入延迟队列进行延迟重试,确保数据可以删除,缓存可以及时更新。因为删除操作是幂等的,所以即使重复删问题也不是太大,这又是删除比更新好的一个原因。
因此,针对缓存更新更推荐的方式是,缓存中的数据不由数据更新操作主动触发,统一在需要使用的时候按需加载,数据更新后及时删除缓存中的数据即可。
小结
Redis 缓存是提升系统性能的利器,但在设计时必须考虑缓存穿透、击穿、雪崩以及与数据库的一致性问题。适当的缓存策略、限流降级、锁机制和异步处理方案是保障高并发场景下缓存稳定运行的关键。

相关文章:
Java避坑案例 - 高并发场景下的分布式缓存策略
文章目录 概述缓存常见问题及解决方案把 Redis 当作数据库常用的数据淘汰策略如何选择合适的驱逐算法 缓存雪崩问题复现解决方案 缓存击穿(热点缓存失效)问题复现解决方案 缓存穿透问题复现解决方案缓存穿透 vs 缓存击穿 缓存与数据库的一致性先更新缓存…...
、lstrip() 和 rstrip())
Python中的字符串修剪:strip()、lstrip() 和 rstrip()
Python中的字符串修剪 Python 中的字符串修剪:strip()、lstrip() 和 rstrip()strip()lstrip()rstrip()应用场景结论 Python 中的字符串修剪:strip()、lstrip() 和 rstrip() 在 Python 开发中,我们经常需要处理字符串,其中一项常见…...

K8S配置storage-class
简介 Kubernetes支持NFS存储,需要安装nfs-subdir-external-provisioner,它是一个存储资源自动调配器,它可将现有的NFS服务器通过持久卷声明来支持Kubernetes持久卷的动态分配。该组件是对Kubernetes NFS-Client Provisioner的扩展࿰…...

多线程——线程池
目录 前言 一、什么是线程池 1.引入线程池的原因 2.线程池的介绍 二、标准库中的线程池 1.构造方法 2.方法参数 (1)corePoolSize 与 maximumPoolSize (2)keepAliveTime 与 unit (3)workQueue&am…...

VScode插件:前端每日一题
大文件上传如何做断点续传? 在前端实现大文件上传的断点续传,通常会将文件切片并分块上传,记录每块的上传状态,以便在中断或失败时只上传未完成的部分。以下是实现断点续传的主要步骤和思路: 1. 文件切片 (File Slici…...

Android跨进程通信
1、跨进程通信的几种方式 在 Android 中,跨进程通信 (IPC, Inter-Process Communication) 方式有多种,主要用于在不同的应用或进程之间传递数据。常见的跨进程通信方式包括: AIDL (Android Interface Definition Language) • 描述ÿ…...

【初阶数据结构】计数排序 :感受非比较排序的魅力
文章目录 前言1. 什么是计数排序?2. 计数排序的算法思路2.1 绝对位置和相对位置2.2 根据计数数组的信息来确认 3. 计数排序的代码4. 算法分析5. 计数排序的优缺点6.计数排序的应用场景 前言 如果大家仔细思考的话,可能会发现这么一个问题。我们学的七大…...

前后双差速轮之LQR控制
在之前的代码中,我们实现了前后两对双差速轮AGV的运动学正解和逆解。但为了实现对AGV的精确路径跟踪和姿态控制,我们需要引入控制算法。线性二次型调节器(LQR)是一种常用的最优控制方法,可以有效地将系统的状态误差最小化。本文将详细说明如何在之前的C++代码中加入LQR控制…...

Linux之远程连接服务器
1、远程连接服务器简介 (1)什么是远程连接服务器 远程连接服务器通过文字或图形接口方式来远程登录系统,让你在远程终端前登录linux主机以取得可操作主机接口(shell),而登录后的操作感觉就像是坐在系统前面…...

k8s 部署 nexus3 详解
创建命名空间 nexus3-namespace.yaml apiVersion: v1 kind: Namespace metadata:name: nexus-ns创建pv&pvc nexus3-pv-pvc.yaml apiVersion: v1 kind: PersistentVolume metadata:name: nfs-pvnamespace: nexus-ns spec:capacity:storage: 3GiaccessModes:- ReadWriteM…...

从“摸黑”到“透视”:AORO A23热成像防爆手机如何改变工业检测?
在工业检测领域,传统的检测手段常因效率低下、精度不足和潜在的安全风险而受到诟病。随着科技的不断进步,一种新兴的检测技术——红外热成像技术,正逐渐在该领域崭露头角。近期,小编对一款集成红外热成像技术的AORO A23防爆手机进…...
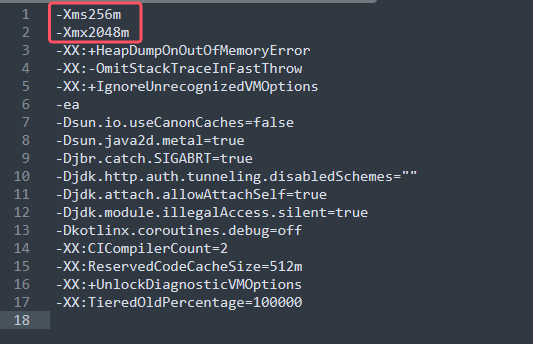
让你的 IDEA 使用更流畅 | IDEA内存修改
随着idea使用越来越频繁,笔者最近发现使用过程中有时候会出现卡顿现象,例如,启动软件变慢,打开项目的速度变慢等: 因此如果各位朋友觉得最近也遇到了同样的困惑,不妨跟着笔者一起来设置IDEA的内存大小吧~ …...

docker run 命令解析
docker run 命令解析 docker run 命令用于从给定的镜像启动一个新的容器。这个命令可以包含许多选项,下面是一些常用的选项: -d:后台运行容器,并返回容器ID;-i:以交互模式运行容器,通常与 -t …...

[Unity Demo]从零开始制作空洞骑士Hollow Knight第十七集:制作第一个BOSS苍蝇之母
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、战斗场景Battle Scene相关逻辑处理 1.防止玩家走出战斗场景的门2.制作一个简单的战斗场景二、制作游戏第一个BOSS苍蝇之母 1.导入素材和制作相关动画2.制作…...

【Nginx系列】499错误
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

Springboot项目控制层注释
Springboot主流的 ----------------------- 简略写法 package com.dx.wlmq.controller;import com.dx.wlmq.domain.Address; import com.dx.wlmq.service.AddresssService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.b…...

从Docker容器中备份整个PostgreSQL
问题 现在需要从Docker容器中备份整个PostgreSQL后,然后,使用备份文件在另外一个pg的docker容器中恢复过来。 步骤 备份旧容器中的PG # 登录到旧的PG容器中 docker exec -it postgres bash # 备份数据库 pg_dumpall -c -U postgres > dump_date %…...

从小需求看大格局:如何用技术智慧赢得客户信任
时间:2024年 10月 26日 作者:小蒋聊技术 邮箱:wei_wei10163.com 微信:wei_wei10 音频:从小需求看大格局:如何用技术智慧赢得客户信任 欢迎大家回到“小蒋聊技术”,这是一个不只是教你如何写…...

模型 支付矩阵
系列文章 分享 模型,了解更多👉 模型_思维模型目录。策略选择的收益分析工具。 1 支付矩阵的应用 1.1 支付矩阵在市场竞争策略分析中的应用 支付矩阵是一种强大的决策工具,它在多个领域的应用中都发挥着重要作用。以下是一个具体的应用案例…...

擎创科技声明
近日,我司陆续接到求职者反映,有自称是擎创科技招聘人员,冒用“上海擎创信息技术有限公司”名义,用“126.com”的邮箱向求职者发布招聘信息,要求用户下载注册APP,进行在线测评。 对此,我司郑重…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...