Elasticsearch 中的高效按位匹配
作者:来自 Elastic Alexander Marquardt

探索在 Elasticsearch 中编码和匹配二进制数据的六种方法,包括术语编码(我喜欢的方法)、布尔编码、稀疏位位置编码、具有精确匹配的整数编码、具有脚本按位匹配的整数编码以及使用 ESQL 进行按位匹配的整数编码,并提供实际示例和用例。
简介
二进制编码是现代应用中的一项重要技术,尤其是在物联网设备监控等领域,这些领域需要持续处理大量二进制传感器数据或操作标志。高效管理和搜索此类数据对于实时分析和决策至关重要。为了实现这一点,按位匹配是一种基于二进制值进行过滤的强大工具,可以实现精确的数据提取。通过正确的数据建模,Elasticsearch 不仅支持按位匹配,而且性能极佳。
在撰写本文时,Elasticsearch 没有用于按位匹配的原生运算符,而 Lucene 也不直接支持按位匹配。为了克服这一限制,本文介绍了 Elasticsearch 中的六种二进制编码和按位匹配方法:术语编码(我首选的方法)、布尔编码、稀疏位位置编码、带精确匹配的整数编码、带脚本按位匹配的整数编码以及带 ESQL 的按位匹配整数编码。
术语编码 - terms encoding
使用术语进行二进制表示可利用 Elasticsearch 优化的基于术语的查询。此方法涉及将每个位表示为存储在关键字字段中的术语。
术语编码的优点
基于术语的方法允许 Elasticsearch 使用优化的数据结构,从而即使对于大型数据集也能实现高效查询。此外,此方法在需要频繁查询不同位组合的情况下具有很好的扩展性,因为每个位都被视为可以索引和搜索的独立实体。
术语编码的缺点
此方法要求在将数据存储在 Elasticsearch 中之前对数据进行预处理以将其转换为术语编码格式。此外,按位查询必须构建为一系列术语匹配,如下所示。此外,由于每个二进制序列由多个术语表示,因此这可能会占用比整数表示所需的更多存储空间。
设置术语编码的环境
定义关键字表示的映射:
PUT test_terms_encoding
{"mappings": {"properties": {"terms_encoded_bits": {"type": "keyword"}}}
}使用术语编码对文档进行索引
使用二进制位表示对文档进行索引:
POST test_terms_encoding/_doc/1
{"terms_encoded_bits": ["b3=0", "b2=1", "b1=1", "b0=0"] // binary 0110
}
POST test_terms_encoding/_doc/2
{"terms_encoded_bits": ["b3=1", "b2=0", "b1=1", "b0=0"] // binary 1010
}
使用术语编码进行查询
查询 b3 为真、b0 为假的文档(即上面的 _id=2 的文档)
GET test_terms_encoding/_search
{"query": {"bool": {"filter": [{"term": {"terms_encoded_bits": "b3=1"}},{"term": {"terms_encoded_bits": "b0=0"}}]}}
}
布尔编码
此方法对每个位使用单独的布尔字段,提供对特定位的清晰直接访问。
布尔编码的优点
布尔编码方法具有 “术语编码” 方法的所有优点,有些人可能发现这种方法更直观。对于某些数据集,它可能需要的存储空间也略少,因为每个字段只存储一个布尔值,而不是字符串。
布尔编码的缺点
这具有 “术语编码” 方法列出的所有缺点。这种方法的另一个缺点是,由于我们为每个位创建了一个新字段,这会导致映射爆炸。
设置布尔编码的环境
使用布尔字段定义映射:
PUT test_boolean_encoding
{"mappings": {"properties": {"b3": { "type": "boolean" },"b2": { "type": "boolean" },"b1": { "type": "boolean" },"b0": { "type": "boolean" }}}
}
使用布尔编码对文档进行索引
使用每个位的布尔值对文档进行索引:
POST test_boolean_encoding/_doc/1
{"b3": false, "b2": true,"b1": true,"b0": false
} // binary 0110 – integer 6
POST test_boolean_encoding/_doc/2
{"b3": true,"b2": false,"b1": true,"b0": false
} // binary 1010 – integer 10
使用布尔编码进行查询
要查询 b3 为真、b0 为假的文档(即上面的 _id=2 的文档):
GET test_boolean_encoding/_search
{"query": {"bool": {"filter": [{"term": {"b3": true}},{"term": {"b0": false}}]}}
}
稀疏位位置编码 - Sparse Bit Position Encoding
此方法仅对数组中设置为 true 的位的位置进行编码。
稀疏位位置编码的优点
如果绝大多数文档通常没有任何位设置为 true,那么与以前的方法相比,这种方法在存储方面可能更有效。例如,你可以想象,表示警告标志的位很少为 true 的数据集,这将导致位位置编码数组为空(因此节省空间),而这些数组对于很大一部分文档而言都是空的。
稀疏位位置编码的缺点
此方法的一个缺点是,查询不为 true 的位需要使用 must_not 运算符。但是,使用 must_not 进行查询可能会导致性能开销,因为 Elasticsearch 需要扫描文档以验证某些值的缺失,这比直接查询特定术语的存在效率更低。在大型数据集中,这可能会减慢处理速度。另一个缺点是,如果数据始终有许多位设置为 true,那么这将需要一长串整数来表示,这会增加存储要求。最后,与其他方法一样,此方法需要预处理数据,将其转换为稀疏位位置编码,然后再将其存储在 Elasticsearch 中。
设置稀疏位位置编码的环境
定义整数数组的映射:
PUT test_sparse_encoding
{"mappings": {"properties": {"sparse_bit_positions": {"type": "integer"}}}
}
使用稀疏位位置编码对文档进行索引
使用位位置编码为整数对文档进行索引:
POST test_sparse_encoding/_doc/1
{"sparse_bit_positions": [2, 1] // binary 0110
}
POST test_sparse_encoding/_doc/2
{"sparse_bit_positions": [3, 1] // binary 1010
}
使用稀疏位位置编码进行查询
要查询 b3 为真、b0 为假的文档(即上面的 _id=2 的文档):
GET test_sparse_encoding/_search
{"query": {"bool": {"must": [{"term": {"sparse_bit_positions": 3}}],"must_not": [{"term": {"sparse_bit_positions": 0}}]}}
}
带精确匹配的整数编码
在这种方法中,二进制值被编码为整数。这是一种直观的方法,特别是当你需要高效地存储和查询完整的二进制序列(即整数)时。
带精确匹配的整数编码的优点
在迄今为止讨论的方法中,这种方法最有可能直接映射到源系统中数据存储的方式,源系统通常将二进制序列表示为整数。因此,使用这种方法存储文档可能比其他方法需要更少的预处理。
带精确匹配的整数编码的缺点
这种方法仅讨论表示二进制序列的整数值的精确匹配。它不解决整数内的按位匹配问题。它还要求你在将二进制值存储在 Elasticsearch 中之前将其转换为整数。
设置整数编码的环境
定义整数编码的映射:
PUT test_integer_encoding
{"mappings": {"properties": {"integer_representation": {"type": "integer"}}}
}
使用整数编码对文档进行索引
通过将二进制序列转换为整数来对文档进行索引:
POST test_integer_encoding/_doc/1
{"integer_representation": 6 // binary 0110
}
POST test_integer_encoding/_doc/2
{"integer_representation": 10 // binary 1010
}
使用整数编码进行查询
以下查询检索二进制表示等于特定值的文档 - 在此示例中,文档包含整数表示 0110 且 _id=1:
GET test_integer_encoding/_search
{"query": {"term": {"integer_representation": 6 // binary 0110}}
}
使用脚本按位匹配进行整数编码
在这种方法中,我们扩展了将二进制值编码为整数的概念,并利用 scripted query 功能来查询整数值中设置的各个位。本文将对这种方法进行讨论,以保证完整性,但请记住,大量使用脚本查询将给集群带来额外的工作负载,并且可能比其他方法更慢、效率更低。
使用脚本按位匹配进行整数编码的优点
这种方法具有“使用精确匹配进行整数编码”方法的优点。另一个优点是可以匹配各个位。
使用脚本按位匹配进行整数编码的缺点
这种按位匹配方法没有利用 Elasticsearch 构建的数据结构来确保快速高效的查询。因此,这种方法可能会导致查询速度变慢,并且比前面提到的方法需要更多的资源。因此,我通常会推荐前面讨论的方法。
设置和索引文档
在本节中,我们将使用在第二个名为 “精确匹配的整数编码” 的章节中填充的相同索引。
查询
要查询 b3 为真且 b0 为假的文档(即上面的 _id=2 的文档),我们可以使用脚本查询。以下查询满足这些要求,并附有注释以解释逻辑:
GET test_integer_encoding/_search
{"query": {"bool": {"filter": {"script": {"script": {"source": """// b3 is true // i.e. "integer_representation" AND 1000 == 1000// Keep in mind that 1000 binary == 8 in integer((doc['integer_representation'].value & 8) == 8) && // b0 false // i.e. "integer_representation" AND 0001 == 0((doc['integer_representation'].value & 1) == 0)""" }}}}}
}
使用 ES|QL 进行整数编码以进行按位匹配
与 “使用脚本按位匹配进行整数编码” 方法一样,此方法也可以匹配单个位,但它利用的是 ES|QL 而不是脚本查询。本文将对此方法进行讨论,以保证完整性,但大量使用此方法可能会在集群上产生额外的工作负载,并且可能比其他方法更慢、效率更低。
使用 ES|QL 进行整数编码以进行按位匹配的优势
此方法具有与 “使用脚本按位匹配进行整数编码” 相同的优势。另一个优势是它利用了在设计时考虑了性能的 ES|QL。
使用 ES|QL 进行整数编码以进行按位匹配的缺点
尽管此方法利用了 ES|QL,但它无法直接使用预构建的数据结构进行按位匹配。因此,此方法可能会导致查询速度变慢,并且比许多其他方法需要更多的资源。
设置和索引文档
在本节中,我们将使用在第二个名为“精确匹配的整数编码”的章节中填充的相同索引。
查询
要查询 b3 为真且 b0 为假的文档(即上面的 _id=2 的文档),我们可以使用 ES|QL。以下查询满足这些要求,并附有注释以解释逻辑:
POST /_query?format=txt
{"query": """FROM test_integer_encoding METADATA _index, _id// The following uses division to shift the bit we are interested // in, to the right. ie. dividing by 8 (or b1000 - corresponding to b3) // shifts b3 to the least significant bit position, or b0. // Additionally, the rightmost bits are dropped.// Then the modulus by 2 checks if the new (post shift) // value of b0 (formerly b3)is odd or even (1 or 0)| WHERE (integer_representation / 8 % 2 == 1) // b3 is true| WHERE (integer_representation / 1 % 2 == 0) // b0 is false| KEEP _id, integer_representation"""
}
结论
在本文中,我们探讨了六种按位匹配方法 —— 术语编码(我首选的方法)、布尔编码、稀疏位位置编码、精确匹配的整数编码、脚本按位匹配的整数编码以及使用 ES|QL 进行按位匹配的整数编码。这展示了如何应用不同的方法来有效地处理 Elasticsearch 中的按位匹配。每种方法都有其优点和权衡,具体取决于应用程序的特定要求。
对于需要单独位匹配的场景,基于术语和布尔字段的方法效果很好,应该是有效的。在整数数组中表示真实位位置为稀疏位序列提供了一种紧凑而灵活的解决方案。将二进制序列编码为整数可能适合整个序列操作,但代价是失去有效查询单个位的能力。我们还可以使用脚本查询或 ES|QL 查询整数中的单个位,但这些方法可能不如其他方法有效。
致谢
感谢 Honza Kral 提出使用术语和整数对单个位进行编码的想法,感谢 Alexis Charveriat 建议使用 ES|QL 进行按位匹配的方法,感谢 Carly Richmod 在技术审查过程中提出的宝贵建议。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证?了解下一期 Elasticsearch 工程师培训何时开始!
原文:Efficient bitwise matching in Elasticsearch - Search Labs
相关文章:
Elasticsearch 中的高效按位匹配
作者:来自 Elastic Alexander Marquardt 探索在 Elasticsearch 中编码和匹配二进制数据的六种方法,包括术语编码(我喜欢的方法)、布尔编码、稀疏位位置编码、具有精确匹配的整数编码、具有脚本按位匹配的整数编码以及使用 ESQL 进…...
,是一种特殊的循环神经网络(RNN)结构)
LSTM,全称长短期记忆网络(Long Short-Term Memory),是一种特殊的循环神经网络(RNN)结构
关于lstm超参数设置,每个参数都有合适的范围,超过这个范围则lstm训练不再有效,loss不变,acc也不变 LSTM,全称长短期记忆网络(Long Short-Term Memory),是一种特殊的循环神经网络&am…...
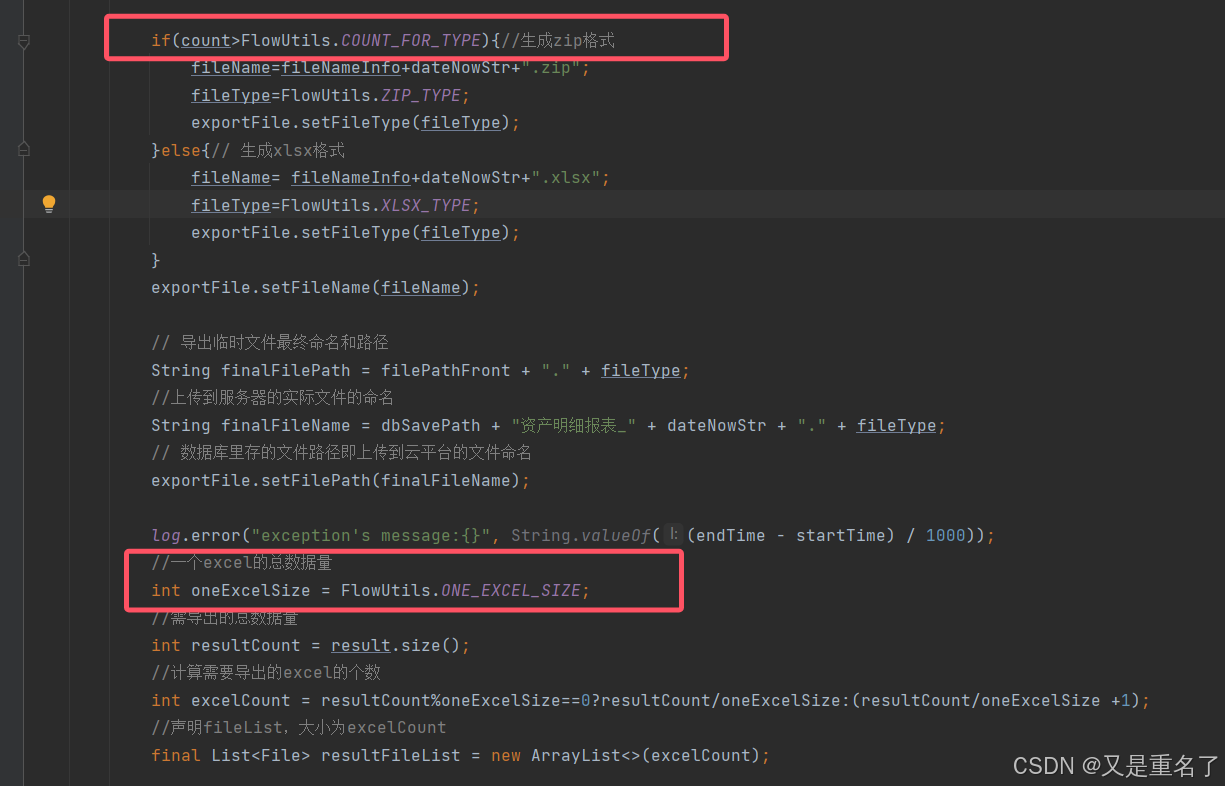
导出问题处理
问题描述 测试出来一个问题,使用地市的角色,导出数据然后超过了20w的数据,提示报错,我还以为是偶然的问题,然后是发现是普遍的问题,本地环境复现了,然后是,这个功能是三套角色&…...

通过cv库智能切片 把不同的分镜切出来 自媒体抖音快手混剪
用 手机自动化脚本,从自媒体上获取视频,一个商品对应几百个视频,我们把这几百个视频下载下来,进行分镜 视频切片,从自媒体上下载视频,通过cv库用直方图识别每个镜头进行切片。 下载多个图片进行视频的伪原…...
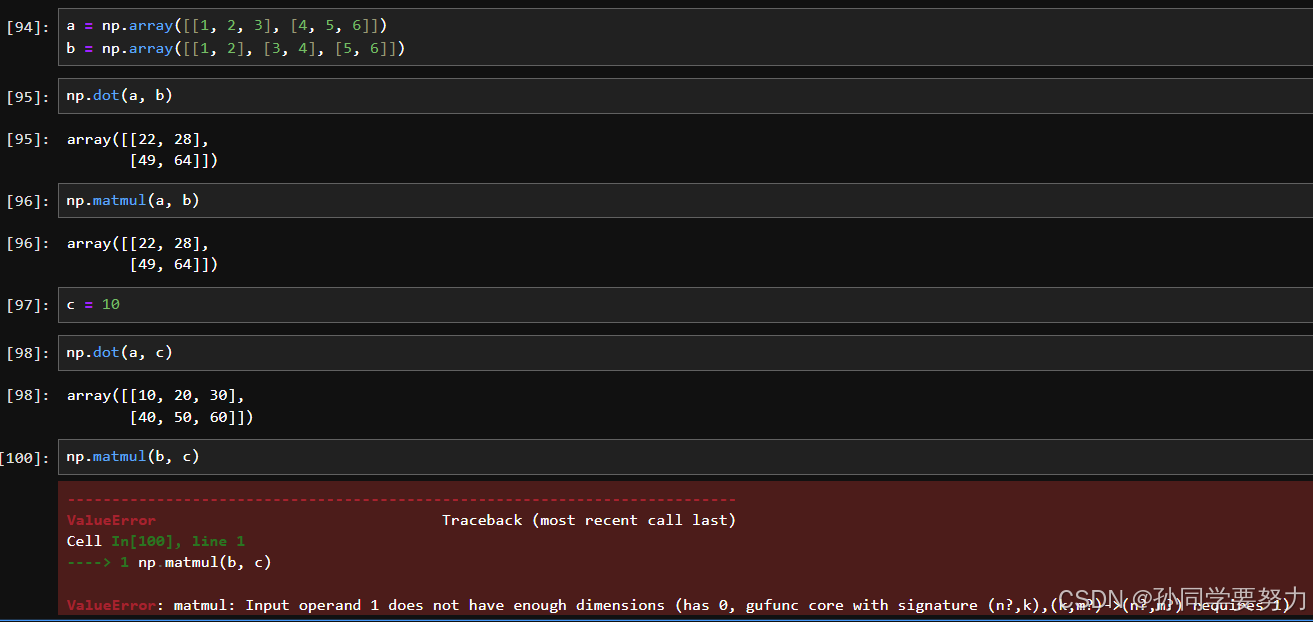
【机器学习】——numpy教程
文章目录 1.numpy简介2.初始化numpy3.ndarry的使用3.1numpy的属性3.2numpy的形状3.3ndarray的类型 4numpy生成数组的方法4.1生成0和1数组4.2从现有的数组生成4.3生成固定范围的数组4.4生成随机数组 5.数组的索引、切片6.数组的形状修改7.数组的类型修改8.数组的去重9.ndarray的…...
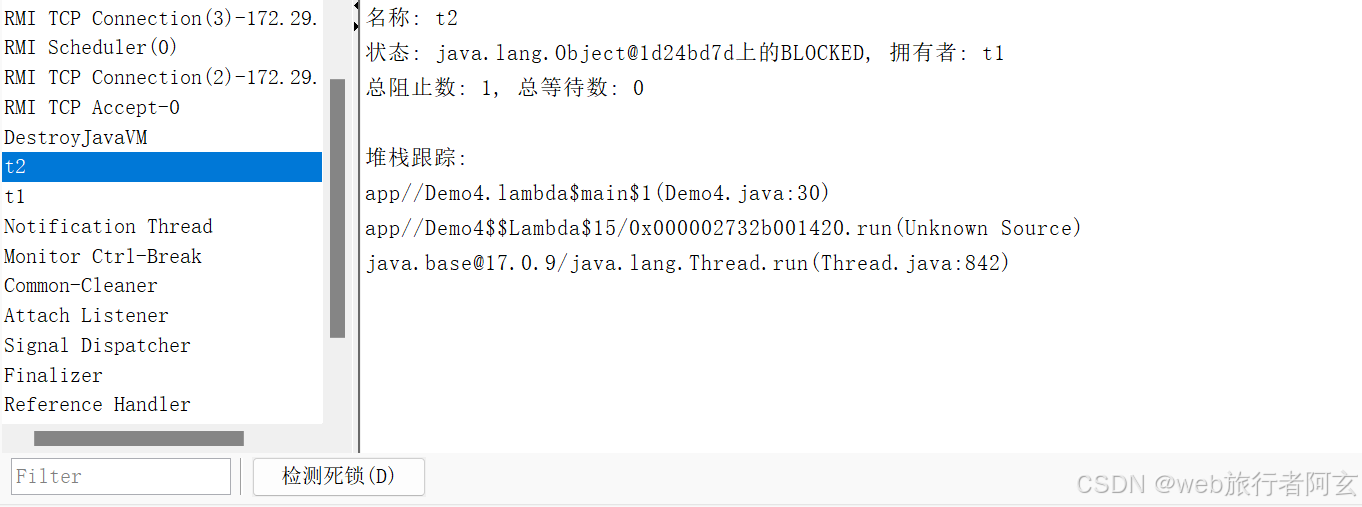
多线程——线程的状态
线程状态的意义 线程状态的意义在于描述线程在执行过程中的不同阶段和条件,帮助开发者更好地管理和调度线程资源。 线程的多种状态 线程的状态是一个枚举类型(Thread.State),可以通过线程名.getState()…...
)
开源数据库 - mysql - 组织结构(与oracle的区别)
组织形式区别 mysql(Schema -> Table -> Column -> Row) Schema(方案): Scheme是关于数据库和表的布局及特性的信息。它可以用来描述数据库中特定的表以及整个数据库和其中表的信息,如表的一些特…...
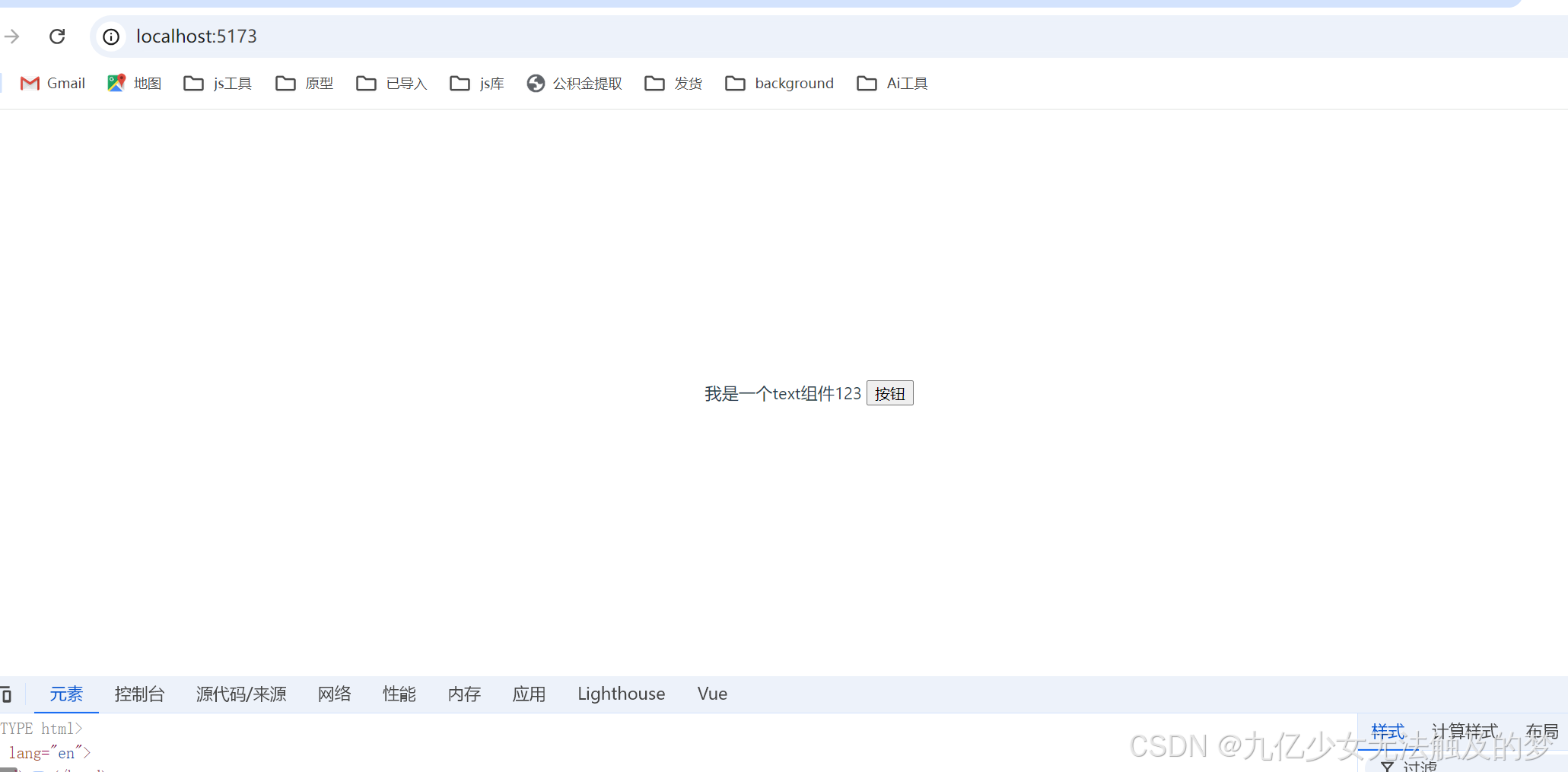
vue3+vite 部署npm 包
公司需要所以研究了一下怎么部署安装,比较简单 先下载个vue项目 不用安准路由,pinna 啥的,只需要一个最简单的模版 删掉App.vue 中的其它组件 npm create vuelatest 开始写自定义组件 新建一个el-text 组件, name是重点,vue3中…...
华为鸿蒙HarmonyOS应用开发者高级认证视频及题库答案
华为鸿蒙开发者高级认证的学习资料 1、课程内容涵盖HarmonyOS系统介绍、DevEco Studio工具使用、UI设计与开发、Ability设计与开发、分布式特性、原子化服务卡片以及应用发布等。每个实验都与课程相匹配,帮助加深理解并掌握技能 2、学习视频资料 华为HarmonyOS开发…...

【计网】从零开始认识IP协议 --- 认识网络层,认识IP报头结构
从零开始认识IP协议 1 网络层协议1.1 初步认识IP协议1.2 初步理解IP地址 2 IP协议报头3 初步理解网段划分 1 网络层协议 1.1 初步认识IP协议 我们已经熟悉了传输层中的UDP和TCP协议,接下来我们来接触网络层的协议: 网络层在计算机网络中的意义主要体现…...

大一物联网要不要转专业,转不了该怎么办?
有幸在2014年,踩中了物联网的风口,坏消息,牛马的我,一口汤都没喝上。 依稀记得,当时市场部老大,带我去上海参加电子展会,印象最深的,一些物联网云平台,靠着一份精美PPT&a…...

LeetCode题练习与总结:4的幂--342
一、题目描述 给定一个整数,写一个函数来判断它是否是 4 的幂次方。如果是,返回 true ;否则,返回 false 。 整数 n 是 4 的幂次方需满足:存在整数 x 使得 n 4^x 示例 1: 输入:n 16 输出&am…...

ubuntu GLEW could not be initialized : Unknown error
原因 某些ubuntu版本默认使用wayland协议,glew不支持 解决方法 1、编辑GDM3配置文件 sudo nano /etc/gdm3/custom.conf 2、修改配置文件 去掉#WaylandEnablefalse前的# 3、重启GDM3服务 sudo systemctl restart gdm3 修改后默认使用X11协议。...

51c~目标检测~合集1
我自己的原文哦~ https://blog.51cto.com/whaosoft/12371248 #目标检测x1 又一个发现 都不知道是第几了 是一个高效的目标检测 动态候选较大程度提升检测精度 目标检测是一项基本的计算机视觉任务,用于对给定图像中的目标进行定位和分类。 论文地址:…...

前端工程化面试题
说一下模块化方案 模块化是为了解决代码的复用和组织问题,可以说有了模块化才让前端有了工程的概念,模块化要解决两大问题 代码隔离和依赖管理,从node.js最早发布的commonjs 到浏览器端的 AMD,CMD 规范以及兼容的 UMD 规范,再到现…...
【Visual Studio】下载安装 Visual Studio Community 并配置 C++ 桌面开发环境的图文教程
引言 Visual Studio 是一个面向 .NET 和 C 开发人员的综合性 Windows 版 IDE,可用于构建 Web、云、桌面、移动应用、服务和游戏。 安装步骤 访问 Visual Studio 的官方下载页面: https://visualstudio.microsoft.com/zh-hans/downloads/运行已下载的 V…...
010Editor:十六进制编辑器
介绍 世界上最好的十六进制编辑器和出色的文本编辑器 010 Editor 是用于处理文本和二进制数据的终极工具包。 添加模板 模板库https://www.sweetscape.com/010editor/repository/templates/ 先下载一个ELF 模板 运行模板...

Vscode中Github Copilot无法使用
现象 Copilot侧边栏显示要登录,但是点击"github登录"没有反应与Copilot对话,报错如下: Unexpected token o, "[object Rea"... is not valid JSON解决方案 在网上怎么找都没找到类似的问题,最后发现是Vsco…...

<项目代码>YOLOv8表情识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…...
利用Msfvenom实现对Windows的远程控制
1.实验准备 kali安装 Apache2(如果尚未安装): sudo apt install apache2 启动 Apache2 服务: sudo systemctl start apache2确认 Apache2 的默认网页可以访问: 打开浏览器并访问 http://<你的Kali IP>ÿ…...
✅)
计算机毕业设计:Python全国气象数据采集与可视化平台 Flask框架 可视化 数据分析 机器学习 天气 深度学习 AI 空气质量分析(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

终极启动盘制作工具:Deepin Boot Maker 完整使用指南
终极启动盘制作工具:Deepin Boot Maker 完整使用指南 【免费下载链接】deepin-boot-maker 项目地址: https://gitcode.com/gh_mirrors/de/deepin-boot-maker Deepin Boot Maker 是一款免费开源、简单快速的启动盘制作工具,专为新手和普通用户设计…...

Le Git Graph 终极指南:GitHub提交图谱可视化工具快速上手
Le Git Graph 终极指南:GitHub提交图谱可视化工具快速上手 【免费下载链接】le-git-graph Browser extension to add git graph to GitHub website. 项目地址: https://gitcode.com/gh_mirrors/le/le-git-graph Le Git Graph 是一款功能强大的浏览器扩展&…...

企业微信控制OpenClaw中文版完整图文教程
教程使用的openclaw中文版一键安装包版本 下载地址:openclaw简体中文一键安装包https://openclaw.ikidi.top/api/download/package/15?promoCodeIV0047777BE1 一、准备工作(企业微信端) 登录企业微信管理后台访问地址:https://w…...

SDMatte与3D引擎结合:实时渲染中的动态遮罩应用
SDMatte与3D引擎结合:实时渲染中的动态遮罩应用 1. 引言:当AI遮罩遇上实时渲染 想象一下,在游戏开发中需要让角色逐渐消失的特效,传统做法可能需要美术师逐帧绘制遮罩。现在,通过SDMatte与3D引擎的结合,我…...

直通大厂:腾讯二面高频考题,多Agent工作原理超详细拆解!
1. 题目分析 一个 Agent 能做的事情终归有限。当你试图让单个 Agent 去完成一个真正复杂的任务——比如从零开始做一次完整的市场调研并输出 PPT 报告——你会发现它要么因为上下文窗口塞满而"失忆",要么因为角色定位太泛而每一步都做得半吊子。这就像让…...

Windows 11/10下Genymotion与VirtualBox的‘网络适配器战争’:彻底解决启动报错与VirtualBox Host-Only Network #N泛滥问题
Windows 11/10下Genymotion与VirtualBox的网络适配器冲突全解析 每次启动Genymotion虚拟机时,你是否注意到系统里又悄悄多出一个带编号的VirtualBox Host-Only Network适配器?这背后隐藏着Windows网络管理机制与虚拟化软件之间一场看不见的"军备竞…...
)
Zotero与OneDrive云存储附件的高效整合方案(Zotero+OneDrive)
1. 为什么选择ZoteroOneDrive组合管理文献附件 作为一名长期与学术文献打交道的科研工作者,我深知文献管理工具的重要性。Zotero作为一款开源文献管理软件,其强大的文献收集、整理和引用功能深受研究者喜爱。但在实际使用中,文献附件的存储问…...

Profinet转MODBUS TCP在精细化工塔讯工业自动化中的应用方案
一、案例背景化工行业属于流程型工业,对生产过程中的压力、流量、液位等参数监控要求极高,安全生产是行业核心底线。某精细化工园区新建数字化生产车间,现场过程监测设备采用Profinet协议智能仪表,包括西门子SITRANS P系列压力仪表…...
:微动信号模型的构建与验证)
信号建模-从雷达回波到生命体征分离(三):微动信号模型的构建与验证
1. 雷达回波中的生命体征信号解码 第一次接触生物雷达信号时,我和大多数工程师一样被复杂的数学公式劝退。直到在智慧医疗项目中亲手调试设备才发现,那些看似深奥的相位变化曲线,其实就像医生听诊器里的呼吸节奏——只要找对方法,…...